18 Ağu 2025·8 dk
Chris Lattner'ın LLVM'i: Modern Araç Zincirlerinin Sessiz Motoru
Chris Lattner'ın LLVM'i, diller ve araçların arkasındaki modüler derleyici platformu nasıl oldu — optimizasyonlar, daha iyi tanılama ve hızlı derlemeleri nasıl sağladığını öğrenin.
LLVM Nedir, Basitçe Açıklama
LLVM, birçok derleyici ve geliştirici aracının paylaştığı “motor odası” olarak düşünülmelidir.
C, Swift veya Rust gibi bir dille kod yazdığınızda, o kodu CPU'nuzun çalıştırabileceği komutlara çevirecek bir şeye ihtiyaç vardır. Geleneksel bir derleyici genellikle bu hattın her parçasını kendisi kurardı. LLVM farklı bir yaklaşım benimsiyor: pahalı ve zor kısmı—optimizasyon, analiz ve çeşitli işlemciler için makine kodu üretimi—yapan yüksek kaliteli, yeniden kullanılabilir bir çekirdek sunuyor.
Birçok dil için paylaşılan bir temel
LLVM çoğu zaman doğrudan “kullanılan” tek bir derleyici değildir. O, derleyici altyapısıdır: dil ekiplerinin bir araç zincirine birleştirebileceği yapı taşları. Bir ekip sözdizimi, anlambilim ve geliştiriciye yönelik özelliklere odaklanabilir, sonra ağır işleri LLVM'e devredebilir.
Bu paylaşılan temel, modern dillerin on yılların derleyici çalışmalarını yeniden icat etmeden hızlı, güvenli araç zincirleri sunabilmesinin önemli bir nedenidir.
Eğer derleyici uzmanı değilseniz bile neden önemi var
LLVM günlük geliştirici deneyiminde kendini gösterir:
- Hız: yüksek seviyeli kodu farklı platformlarda verimli makine koduna dönüştürebilir.
- Daha iyi hatalar ve hata ayıklama: LLVM etrafındaki ekosistem daha zengin tanılama ve daha iyi araçlar sağlar.
- Sadece “derleme” değil: statik analiz, sanitizers, kod kapsamı ve diğer geliştirici yardımcıları genellikle aynı temel gösterim ve kütüphaneler üzerine kurulur.
Bu makale ne yapacak (ve ne yapmayacak)
Bu, Chris Lattner'ın başlattığı fikirlerin rehberli bir turudur: LLVM'in nasıl yapılandığı, neden orta katmanın önemli olduğu ve nasıl optimizasyonlar ve çoklu platform desteği sağladığı. Bu bir ders kitabı değil—odak sezgi ve gerçek dünya etkisine olacak, resmi teoriye değil.
Chris Lattner'ın Orijinal Vizyonu
Chris Lattner, 2000'lerin başında lisansüstü öğrenciyken LLVM'i pratik bir sıkıntıdan dolayı başlatan bir bilgisayar bilimci ve mühendistir: derleyici teknolojisi güçlüydü ama yeniden kullanılması zordu. Yeni bir programlama dili, daha iyi optimizasyonlar veya yeni bir CPU desteği istiyorsanız, sıkı bağlı “her şey bir arada” bir derleyiciyi kurcalamanız gerekirdi; her değişikliğin yan etkileri olurdu.
Çözmek istediği problem
O zamanlar birçok derleyici tek, büyük makineler gibi inşa edilmişti: dili anlayan kısım, optimize eden kısım ve makine kodu üreten kısım derinlemesine iç içeydi. Bu onları orijinal amaçları için etkili kılıyordu ama uyarlamayı pahalı hale getiriyordu.
Lattner'ın hedefi “tek bir dil için derleyici” değildi. Amacı, birçok dili ve aracı çalıştırabilecek paylaşılan bir temel oluşturmaktı—herkesin aynı karmaşık parçaları tekrar tekrar yeniden yazmasına gerek kalmadan. Ara boru hattını standartlaştırabilirseniz, kenarlarda daha hızlı yenilik yapabileceğinizin bahisiydi.
Neden “modüler altyapı” taze bir fikirdi
Ana değişim, derlemeyi net sınırları olan ayrı yapı taşları olarak ele almaktı. Modüler bir dünyada:
- bir dil ekibi ayrıştırma ve geliştiriciye dönük özelliklere odaklanabilir,
- bir optimizasyon ekibi performansı bir kez iyileştirip genişçe paylaşabilir,
- donanım desteği her şeyi yeniden tasarlamadan eklenebilir.
Bu ayrım şimdi bariz görünüyor olabilir, ama o zamanki birçok üretim derleyicisinin nasıl evrildiğinin ruhuna aykırıydı.
Açık kaynak, başkalarının kullanması için inşa edildi
LLVM erken dönemde açık kaynak olarak yayınlandı; bu önemliydi çünkü paylaşılan bir altyapı, birden fazla grup onu güvenilir, incelenebilir ve genişletilebilir bulmazsa işe yaramaz. Zamanla üniversiteler, şirketler ve bağımsız katkıcılar hedefler ekleyerek, köşe durumlarını düzelterek, performansı iyileştirerek ve etrafında yeni araçlar oluşturarak projeyi şekillendirdiler.
Bu topluluk yönü sadece iyi niyet değildi—tasarımın bir parçasıydı: çekirdeği genişçe kullanışlı yap, birlikte korumaya değer hale gelsin.
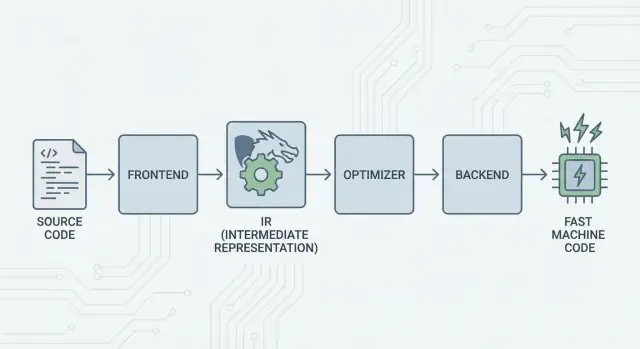
Büyük Fikir: Önyüzler, Paylaşılan Çekirdek ve Arka Uçlar
LLVM'in temel fikri basit: bir derleyiciyi üç ana parçaya ayırın ki birçok dil en zor işi paylaşabilsin.
1) Önyüzler: “Programcı ne demek istedi?”
Bir önyüz belirli bir programlama dilini anlar. Kaynak kodunuzu okur, kuralları (sözdizimi ve tipleri) kontrol eder ve bunu yapılandırılmış bir gösterime çevirir.
Önemli nokta: önyüzlerin tüm CPU ayrıntılarını bilmesine gerek yoktur. İşleri, dil kavramlarını—fonksiyonlar, döngüler, değişkenler—daha evrensel bir şeye çevirmektir.
2) Paylaşılan orta: N×M iş yerine ortak bir çekirdek
Geleneksel olarak, bir derleyici inşa etmek aynı işi tekrar tekrar yapmak demekti:
- N dil ve M CPU hedefi ile N×M kombinasyonu desteklemek zorunda kalırsınız.
LLVM bunu şuna indirger:
- N önyüz kodu paylaşılan bir forma çevirir
- M arka uç paylaşılan formdan makine koduna çevirir
Bu “paylaşılan form” LLVM'in merkezidir: optimizasyonların ve analizlerin yer aldığı ortak bir boru hattı. Ortadaki iyileştirmeler (daha iyi optimizasyonlar veya daha iyi hata ayıklama bilgisi gibi) birçok dile aynı anda fayda sağlayabilir, her bir derleyicide yeniden uygulanmak zorunda kalmaz.
3) Arka uçlar: “Bunu o CPU'da nasıl hızlı çalıştırırız?”
Bir arka uç paylaşılan gösterimi alır ve makineye özgü çıktılar üretir: x86, ARM gibi işlemciler için talimatlar. Bu kısımda kayıtlar, çağrı kuralları ve talimat seçimi gibi ayrıntılar önem kazanır.
Boru hattının sezgisel resmi
Derlemeyi bir seyahat rotası olarak düşünün:
- Kaynak kod dil-spesifik bir ülkede başlar (önyüz).
- Ortak, standartlaştırılmış bir “orta dil”e (LLVM'in çekirdek gösterimi ve geçişleri) geçer.
- Ardından belirli bir hedef makineye ulaşmak için yerel bir tren sistemine biner (hedef makine için arka uç).
Sonuç modüler bir araç zinciridir: diller fikirleri açıkça ifade etmeye odaklanırken, LLVM'in paylaşılan çekirdeği bu fikirleri birçok platformda verimli çalıştırmaya odaklanır.
LLVM IR: Yeniden Kullanımı Sağlayan Orta Katman
LLVM IR (Ara Gösterim), bir programlama dili ile CPU'nuzun çalıştıracağı makine kodu arasındaki “ortak dil”dir.
Bir derleyici önyüzü (örneğin C/C++ için Clang) kaynak kodunuzu bu paylaşılan forma çevirir. Sonra LLVM'in optimizatörleri ve kod üreteçleri IR üzerinde çalışır, orijinal dil üzerinde değil. Son olarak bir arka uç IR'yi belirli bir hedefe (x86, ARM vb.) dönüştürür.
Araçlar ve CPU'lar arasında ortak bir dil
LLVM IR'i şu şekilde düşünebilirsiniz:
- Üstünde: birçok kaynak dil (C, C++, Rust, Swift, Julia vb.) bağlanabilir.
- Altında: birçok CPU hedeflenebilir.
- Ortada: aynı analiz ve optimizasyon araçları yeniden kullanılabilir.
Bu yüzden insanlar LLVM'i genellikle “bir derleyici” değil “derleyici altyapısı” olarak tanımlar. IR, o altyapıyı yeniden kullanılabilir kılan ortak sözleşmedir.
Neden IR yeniden kullanım sağlar (ve herkesten iş tasarrufu eder)
Kod bir kez LLVM IR'ye dönüştüğünde, çoğu optimizasyon geçişinin kodun C++ şablonları, Rust iteratorleri veya Swift generic'leriyle başlayıp başlamadığını bilmesine gerek yoktur. Onları daha çok ilgilendiren evrensel fikirler vardır:
- “Bu değer sabittir.”
- “Bu hesaplama tekrar ediliyor; sonucu yeniden kullanabilir miyiz?”
- “Bu bellek yüklemesi güvenle taşınabilir veya kaldırılabilir mi?”
Bu yüzden dil ekipleri kendi tam optimizer yığınılarını kurmak (ve sürdürmek) zorunda kalmaz. Önyüze—ayrıştırma, tip kontrolü, dil-spesifik kurallar—odaklanır, sonra ağır işleri LLVM'e devrederler.
Kavramsal olarak nasıl “görünür”
LLVM IR, makine koduna temiz bir şekilde haritalanacak kadar düşük seviyeli, ama analiz edilecek kadar yapılandırılmıştır. Kavramsal olarak; basit talimatlar (add, compare, load/store), açık kontrol akışı (branch'ler) ve güçlü tiplendirilmiş değerlerden oluşur—insanların tipik olarak yazdığı bir dilden çok, derleyiciler için tasarlanmış düzenli bir assembly diline benzer.
Optimizasyonlar Nasıl Çalışır (Matematik Olmadan)
İnsanlar “derleyici optimizasyonları” duyduğunda genellikle gizemli numaralar hayal ederler. LLVM'de çoğu optimizasyon daha çok programın anlamını koruyan ve onu daha hızlı (veya daha küçük) yapmayı amaçlayan güvenli, mekanik yeniden yazımlar olarak anlaşılır.
Bunu icat etmek değil, düzenlemek gibi düşünün
LLVM, kodunuzu (LLVM IR içinde) alır ve küçük iyileştirmeleri tekrar tekrar uygular; taslağı cilalamak gibi:
- Tekrarlanan işleri kaldırma: Bir değer iki kez hesaplanıyorsa ve arada değişiklik yoksa, LLVM bunu bir kez hesaplayıp sonucu yeniden kullanabilir.
- Açık mantığı basitleştirme: Sabit ifadeler erken katlanabilir (ör.
3 * 4'ü12'ye çevirmek), böylece CPU çalışma zamanında daha az iş yapar. - Döngüleri düzene sokma: Döngüyle ilgili geçişler tekrarlanan kontrolleri azaltabilir, döngü dışına taşınabilecek değişmez işleri çıkarabilir veya daha verimli çalıştırılabilecek desenleri tanıyabilir.
Bu değişiklikler kasıtlı olarak temkinlidir. Bir geçiş ancak yeniden yazımın programın anlamını değiştirmeyeceğini kanıtlayabildiğinde uygular.
İlişkilendirilebilir örnekler
Programınız kavramsal olarak şunu yapıyorsa:
- Döngü her yinelemede aynı yapılandırma değerini okuyor
- Aynı girdiler üzerinde birkaç yerde aynı hesaplamayı yapıyor
- Belirli bir bağlamda her zaman doğru/yanlış olan bir koşulu kontrol ediyor
…LLVM bunu “hazırlığı bir kez yap”, “sonuçları yeniden kullan” ve “ölü dalları sil” haline getirmeye çalışır. Bu sihirden çok ev işi gibidir.
Gerçek takas: derleme zamanı vs. çalışma zamanı
Optimizasyon ücretsiz değildir: daha fazla analiz ve daha fazla geçiş genellikle daha yavaş derleme demektir, final program daha hızlı çalışsa bile. Bu yüzden araç zincirleri “biraz optimize et” ile “agresifçe optimize et” gibi seviyeler sunar.
Profiller burada yardımcı olabilir. Profile-guided optimization (PGO) ile programı çalıştırır, gerçek kullanım verisi toplar ve sonra yeniden derlersiniz; böylece LLVM çabalarını gerçekten önemli yollar üzerinde yoğunlaştırır—takas daha öngörülebilir olur.
Arka Uçlar: Her Şeyi Yeniden Yazmadan Birçok CPU'ya Ulaşmak
Çapraz Platforma Geçin
Web ve sunucu parçalarınızla birlikte bir Flutter mobil uygulaması oluşturun.
Bir derleyicinin iki çok farklı görevi vardır. Birincisi, kaynak kodunuzu anlamak; ikincisi, belirli bir CPU'nun çalıştırabileceği makine kodu üretmek. LLVM arka uçları bu ikinci işe odaklanır.
Bir arka uç gerçekte ne yapar
LLVM IR'i “evrensel tarif” olarak düşünün: arka uç bu tarifi belirli işlemci ailesinin kesin talimatlarına çevirir—masaüstü ve sunucular için çoğu yerde x86-64, birçok telefonda ve yeni dizüstülerde ARM64 veya WebAssembly gibi hedefler.
Somut olarak bir arka uçun sorumlulukları:
- Talimat seçimi: IR operasyonlarını gerçek CPU talimatlarına eşlemek
- Register tahsisi: Hangi değerlerin hızlı CPU registerlarında, hangi değerlerin bellekte tutulacağını seçmek
- Zamanlama: CPU'nun verimli çalışabilmesi için talimatları sıralamak
- Assembly/objekt çıktısı: Linker ve işletim sisteminin anlayacağı kodu üretmek
Paylaşılan altyapı yeni donanım desteğini neden kolaylaştırır
Paylaşılan çekirdek olmadan her dil desteklemek istediği her CPU için bunların hepsini yeniden uygulamak zorunda olurdu—muazzam bir iş ve sürekli bakım yükü. LLVM bunu tersine çevirir: önyüzler (örneğin Clang) LLVM IR'yi bir kere üretir ve arka uçlar son mil görevini hedef başına yapar. Yeni bir CPU desteği eklemek genellikle tek bir arka uç yazmak (veya mevcut birini genişletmek) anlamına gelir, tüm derleyicilerin yeniden yazılması değil.
Birden fazla platforma gönderim yapan ekipler için taşınabilirlik
Windows/macOS/Linux üzerinde, x86 ve ARM'de veya hatta tarayıcıda çalışması gereken projeler için LLVM'in arka uç modeli pratik bir avantajdır. Tek bir kod tabanı ve büyük ölçüde tek bir derleme hattını koruyabilirsiniz, sonra farklı bir arka uç seçerek (veya çapraz derleyerek) hedefi değiştirebilirsiniz.
Bu taşınabilirlik LLVM'in her yerde görülmesinin nedenlerinden biridir: sadece hızla ilgili değil—aynı zamanda takımların yavaşlatan, platforma özel tekrar işleri yapmaktan kaçınmalarını sağlar.
Clang: Birçok Geliştiricinin LLVM'i İlk Kez Hissedeceği Yer
Clang, LLVM'e bağlanan C, C++ ve Objective-C önyüzüdür. LLVM paylaşılan motor ise Clang, kaynak dosyalarınızı okuyan, dil kurallarını anlayan ve yazdıklarınızı LLVM'in çalışabileceği bir forma dönüştüren parçadır.
Neden Clang fark edildi
Birçok geliştirici LLVM'i derleyici makalelerini okuyarak keşfetmedi—ilk kez farklı bir derleyiciye geçtiğinde geri bildirimin aniden iyileştiğini gördüklerinde fark ettiler.
Clang'ın tanılama mesajları daha okunabilir ve daha spesifik olmasıyla bilinir. Belirsiz hata mesajları yerine genellikle problemi tetikleyen doğru tokeni işaret eder, ilgili satırı gösterir ve ne beklediğini açıklar. Bu, günlük işte önemlidir çünkü “derle, düzelt, tekrarla” döngüsünü daha az sinir bozucu hale getirir.
Clang ayrıca libclang ve daha geniş Clang tooling ekosistemi aracılığıyla temiz, iyi belgelenmiş arayüzler sunar. Bu da editörlerin, IDE'lerin ve diğer geliştirici araçlarının derin dil anlayışını yeniden icat etmeden entegre etmesini kolaylaştırdı.
Günlük iş akışlarında nasıl görünür
Bir araç kodunuzu güvenilir şekilde ayrıştırıp analiz edebildiğinde, artık metin düzenlemeden ziyade yapılandırılmış bir programla çalışıyormuşsunuz gibi hissettiren özellikler elde etmeye başlarsınız:
- Büyük, makro ağırlıklı C++ projelerinde bile doğru kod gezintisi (“tanıma atla”, “referansları bul”)
- Sadece arama-ve-değiştir değil semboller ve kapsamları anlayan yeniden düzenleme desteği
- Gerçek sözdizimi ve tip bilgisine dayanan satır içi ipuçları ve hızlı düzeltmeler
Bu yüzden Clang genellikle LLVM için ilk “dokunma noktası”dır: pratik geliştirici deneyimi iyileştirmelerinin kaynağıdır. LLVM IR veya arka uçlar hakkında hiç düşünmeseniz bile editörünüzün otomatik tamamlama özelliği daha akıllı olduğunda, statik kontroller daha hassas olduğunda ve derleme hataları düzeltilmesi daha kolay olduğunda faydasını görürsünüz.
Neden Birçok Modern Dil LLVM Üzerine Kurulur
LLVM, dil ekipleri için çekici bir neden sunar: dile odaklanmalarını sağlar, üretim kalitesinde bir optimize edici derleyici yeniden icat etmek yerine.
Piyasaya daha hızlı çıkmak
Yeni bir dil inşa etmek zaten ayrıştırma, tip denetimi, tanılar, paketleme araçları, dokümantasyon ve topluluk desteği gerektirir. Eğer ayrıca üretim kalitesinde bir optimizer, kod üreteci ve platform desteğini sıfırdan yapmanız gerekirse, yayımlama gecikebilir—bazen yıllarla.
LLVM hazır bir derleme çekirdeği sağlar: register tahsisi, talimat seçimi, olgun optimizasyon geçişleri ve yaygın CPU hedefleri. Ekipler frontendlerini LLVM IR'ye indirger, sonra var olan boru hattına güvenerek macOS, Linux ve Windows için yerel kod üretebilirler.
“Kahramanlık” olmadan yüksek performans
LLVM'in optimizatörü ve arka uçları uzun vadeli mühendislik ve gerçek dünya testi sonuçudur. Bu, LLVM'i benimseyen diller için güçlü bir temel performans sağlar—çoğu zaman başlangıçta yeterince iyi ve LLVM geliştikçe daha da iyi olabilir.
Bu yüzden birkaç tanınmış dil bunun etrafında inşa edilmiştir:
- Swift Apple platformlarında yüksek optimize edilmiş yerel ikili dosyalar üretmek için LLVM'i kullanır.
- Rust kod üretimi ve birçok mimari hedef için LLVM'e güvenir.
- Julia hızlı sayısal kod ve özel iş yükleri için çalışma zamanında derleme dahil LLVM'i kullanır.
Her dilin LLVM'e ihtiyacı yok
LLVM'i seçmek bir takastır, zorunluluk değil. Bazı diller küçük ikili dosyaları, son derece hızlı derlemeyi veya tüm araç zinciri üzerinde sıkı kontrolü önceliklendirebilir. Bazılarının zaten yerleşik derleyicileri (ör. GCC tabanlı ekosistemler) vardır veya daha basit arka uçları tercih ederler.
LLVM popülerdir çünkü güçlü bir varsayılan sunar—tek geçerli yol olduğu için değil.
JIT ve Çalışma Zamanı Derleme: Hızlı Geri Bildirim Döngüleri
Paylaşmayı Krediye Çevirin
Yarattıklarınızı paylaşarak veya başkalarını davet ederek kredi kazanın.
“Just-in-time” (JIT) derleme en kolay tanımıyla çalıştırırken derlemedir. Tüm kodu baştan sonuna derlemek yerine, JIT motoru bir kod parçasına gerçekten ihtiyaç duyulana kadar bekler, sonra o kısmı anında derler—çoğunlukla gerçek çalışma zamanı bilgilerini (doğru tipler, veri boyutları gibi) kullanarak daha iyi seçimler yapar.
Neden JIT hızlı hissettirebilir
Her şeyi önden derlemek zorunda olmadığınız için JIT sistemleri etkileşimli işler için hızlı geri bildirim sunabilir. Biraz kod yazarsınız veya üretirsiniz, hemen çalıştırırsınız ve sistem sadece şu an gerekli olan kısımları derler. Aynı kod tekrar tekrar çalışırsa, JIT derlenmiş sonucu önbelleğe alabilir veya “sıcak” bölümleri daha agresif yeniden derleyebilir.
Çalışma zamanında derlemenin pratik faydaları
JIT dinamik veya etkileşimli iş yüklerinde öne çıkar:
- REPL'ler ve not defterleri: Parçaları anında değerlendirin, ağır döngüler için yine de yerel hızda yürütme elde edin.
- Eklentiler ve uzantılar: Uygulamalar çalışma zamanında kullanıcı kodunu yükleyip ana makineye uygun şekilde derleyebilir.
- Dinamik iş yükleri: Girdiler çok değişkense, çalışma zamanı profillemesi hangi yolların optimizasyona değer olduğunu gösterebilir.
- Bilimsel hesaplama: Belirli matris boyutu, model şekli veya donanım özelliği için üretilen çekirdekler talep üzerine derlenebilir.
LLVM'in rolü (abartmadan)
LLVM her programı sihirli şekilde hızlandırmaz ve tek başına tam bir JIT değildir. Sağladığı şey bir araç setidir: iyi tanımlanmış bir IR, geniş bir optimizasyon geçişleri seti ve birçok CPU için kod üretimi. Projeler bu yapı taşları üstüne JIT motorları inşa edebilir, başlangıç zamanı, tepe performans ve karmaşıklık arasında doğru takası seçerek.
Performans, Öngörülebilirlik ve Gerçek Dünya Takasları
LLVM tabanlı araç zincirleri son derece hızlı kod üretebilir—ama “hızlı” tek, sabit bir özellik değildir. Derleyici sürümü, hedef CPU, optimizasyon ayarları ve hatta derleyicinin program hakkında yaptığı varsayımlar buna etki eder.
Neden “aynı kaynak, farklı sonuçlar” olur
Aynı C/C++ (veya Rust, Swift vb.) kaynağını okuyan iki derleyici yine de fark edilir şekilde farklı makine kodu üretebilir. Bunun bir kısmı kasıtlıdır: her derleyicinin kendi optimizasyon geçişleri, kestirimleri ve varsayılan ayarları vardır. LLVM içinde bile Clang 15 ile Clang 18 farklı inline kararları verebilir, farklı döngüleri vektörleştirebilir veya talimatları farklı zamanlayabilir.
Ayrıca bunun nedeni dilden kaynaklanan tanımsız davranış ve belirtilmemiş davranış olabilir. Programınız dilin garanti etmediği bir şeye (ör. C'de signed overflow) yanlışlıkla dayanıyorsa, farklı derleyiciler—veya farklı bayraklar—sonuçları değiştirecek şekilde “optimize edebilir”.
Determinizm, debug derlemeleri ve release derlemeleri
İnsanlar genellikle derlemenin deterministik olmasını bekler: aynı girdiler, aynı çıktılar. Pratikte, buna yakınsınız ama ortamlara göre tam olarak aynı ikili dosyalar her zaman oluşmayabilir. Yapı yolları, zaman damgaları, link sırası, profile-guided veriler ve LTO seçimleri final eseri etkileyebilir.
Daha büyük ve pratik ayrım debug vs. release tir. Debug derlemeler adım adım hata ayıklamayı ve okunabilir yığın izlerini korumak için genellikle birçok optimizasyonu kapatır. Release derlemeler agresif dönüşümleri etkinleştirir; bu performans için iyidir ama bazen hatayı ayıklamayı zorlaştırır.
Pratik tavsiye: tahmin etme, ölçün
Performansı bir ölçüm problemi olarak ele alın:
- Temsil eden donanım ve gerçekçi veri kümeleri üzerinde benchmark yapın.
- Önce cache'leri ısıtın ve birden çok yineleme çalıştırın.
- Karşılaştırmaları açık bayraklarla yapın (ör.
-O2vs-O3, LTO açma/kapama veya hedef seçimi-march).
Küçük bayrak değişiklikleri performansı her iki yönde de kaydırabilir. En güvenli iş akışı: bir hipotez seçin, ölçün ve benchmark'ları kullanıcılarınızın gerçekte çalıştırdığına yakın tutun.
Derlemenin Ötesindeki Araçlar: Analiz, Hata Ayıklama ve Güvenlik
Yapıdan Canlıya Geçin
Elle derleme adımlarını birleştirmeye gerek kalmadan barındırılan bir sürüm yayınlayın.
LLVM sıklıkla bir derleyici araç seti olarak tanımlanır, ama birçok geliştirici etkisini derleme çevresindeki araçlarda hisseder: analizörler, hata ayıklayıcılar ve testlerde açılabilen güvenlik kontrolleri.
Analiz ve enstrümantasyon “ekstra eklentiler” olarak
LLVM iyi tanımlanmış bir ara gösterim (IR) ve geçiş boru hattı sunduğu için, kodu hız veya güvenlik dışında amaçlarla inceleyen veya yeniden yazan ekstra adımlar eklemek doğaldır. Bir geçiş profil için sayaçlar ekleyebilir, şüpheli bellek işlemlerini işaretleyebilir veya kapsam verisi toplayabilir.
Ana nokta: bu özellikler her dil ekibinin aynı altyapıyı yeniden yazmasına gerek kalmadan entegre edilebilir.
Sanitizers: hataları kaynağa yakın yakalamak
Clang ve LLVM, testlerde yaygın hata sınıflarını tespit eden çalışma zamanı "sanitizer" ailesini popülerleştirdi—bellek dışı erişim, use-after-free, veri yarışları ve tanımsız davranış desenleri gibi. Bunlar sihirli kalkanlar değildir ve genellikle programları yavaşlattıkları için çoğunlukla CI ve sürüm öncesi testlerde kullanılır. Ancak tetiklendiğinde genellikle kesin bir kaynak konumu ve okunabilir bir açıklama gösterir; bu, geçici çökmeleri izlerken ekiplerin ihtiyacı olan şeydir.
Daha iyi tanılar = daha hızlı adaptasyon
Araç kalitesi aynı zamanda iletişimle ilgilidir. Net uyarılar, uygulanabilir hata mesajları ve tutarlı hata ayıklama bilgisi yeni gelenlerin “gizem faktörünü” azaltır. Araç zinciri ne olduğunu ve nasıl düzelteceğini açıkladığında, geliştiriciler derleyici tuhaflıklarını ezberlemek yerine kod tabanını öğrenmeye daha fazla zaman harcar.
LLVM tek başına mükemmel tanılar veya güvenlik garanti etmez, ama bu geliştiriciye dönük araçların pratik olarak inşa edilmesini, sürdürülmesini ve birçok proje arasında paylaşılmasını sağlayan ortak bir temel sunar.
LLVM Ne Zaman Kullanılmalı (Ne Zaman Kullanılmamalı)
LLVM "kendi derleyicinizi ve araçlarınızı inşa edin" kiti olarak düşünülmelidir. Bu esneklik modern araç zincirlerini besleyen sebep—ama her proje için doğru cevap değil.
LLVM'in iyi uyduğu durumlar
LLVM, ciddi derleyici mühendisliğini yeniden icat etmeden yeniden kullanmak istediğinizde parıldar.
Yeni bir programlama dili inşa ediyorsanız, LLVM size kanıtlanmış bir optimizasyon boru hattı, birçok CPU için olgun kod üretimi ve iyi hata ayıklama desteği sunabilir.
Çapraz platform uygulamalar gönderiyorsanız, LLVM'in arka uç ekosistemi farklı mimarileri hedeflemeyi kolaylaştırır. Dilinize veya ürün mantığınıza odaklanın, farklı kod üreticiler yazmak yerine.
Geliştirici araçları—linter'lar, statik analiz, kod gezintisi, yeniden düzenleme—gibi hedefleriniz varsa LLVM (ve etrafındaki ekosistem) güçlü bir temel sunar çünkü derleyici zaten kod yapısını ve tipleri “anlıyor”.
Ne zaman aşırı gelebilir
LLVM, derleme boyutu, bellek ve derleme zamanı sıkı kısıtlıysa (ör. çok küçük gömülü sistemler) ağır olabilir.
Ayrıca genel amaçlı optimizasyonları istemediğiniz veya dilinizin sabit bir DSL'e daha yakın olduğu ve doğrudan makine koduna haritalamanın daha basit olduğu çok özel boru hatlarında da uygun olmayabilir.
Basit bir kontrol listesi
Bu üç soruyu sorun:
- Şimdi veya yakında birden çok platform/CPU hedeflememiz gerekiyor mu?
- Kendi optimizasyonlarımızı ve hata ayıklama bilgilerimizi inşa etmek yerine mevcut optimizasyonlar ve debug info işimize yarar mı?
- Minimal özel bir derleyici yerine bir ekosistem yolu (araçlar, entegrasyonlar, işe alım) mu istiyoruz?
Çoğuna “evet” yanıtı verdiyseniz, LLVM genellikle pratik bir tercihtir. Eğer amacınız dar bir problemi çözen en küçük, en basit derleyici ise daha hafif bir yaklaşım kazanabilir.
Ürün Ekipleri İçin Pratik Not: Derleyici Uzmanı Olmadan LLVM'in Faydaları
Çoğu ekip "LLVM benimseyeyim" diye bir proje yapmak istemez. Onların istediği sonuçlardır: çapraz platform derlemeler, hızlı ikililer, iyi tanılar ve güvenilir araçlar.
Bu yüzden Koder.ai gibi platformlar bu bağlamda ilgi çekicidir. İş akışınız daha yüksek seviyeli otomasyonla (planlama, iskelet üretme, sık döngüler) yönlendiriliyorsa bile, altta yatan araç zincirleri (LLVM/Clang ve arkadaşları, uygunsa) optimizasyon, tanılama ve taşınabilirlik gibi göz önünde olmayan işleri arka planda yapmaya devam eder. Koder.ai'nin sohbet tabanlı “vibe-coding” yaklaşımı ürünü daha hızlı ulaştırmaya odaklanırken modern derleyici altyapısı görünmez ama sağlam bir şekilde arkada çalışır.