28 Ara 2025·6 dk
Claude Code ile performans incelemeleri: ölçümlü bir iş akışı
Claude Code ile performans incelemeleri için tekrarlanabilir bir döngü kullanın: ölçün, hipotez kurun, küçük değişiklik yapın ve yayınlamadan önce yeniden ölçün.
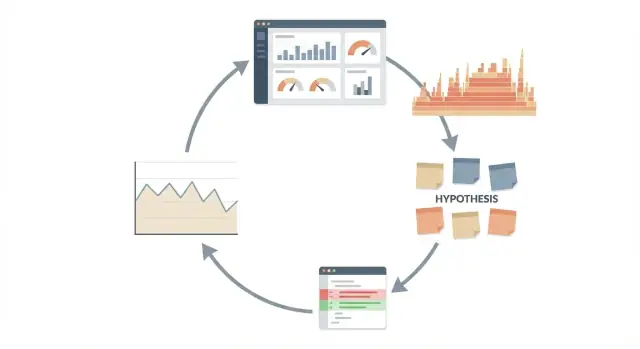
Claude Code ile performans incelemeleri için tekrarlanabilir bir döngü kullanın: ölçün, hipotez kurun, küçük değişiklik yapın ve yayınlamadan önce yeniden ölçün.
Performans hataları tahmine davet eder. Birisi bir sayfanın yavaş hissettirdiğini ya da bir API'nin zaman aşımına uğradığını fark eder ve en hızlı hamle genellikle kodu "düzeltmek", önbellek eklemek veya bir döngüyü yeniden yazmaktır. Sorun şu ki "yavaş hissetme" bir metrik değildir ve "daha temiz" her zaman daha hızlı demek değildir.
Ölçüm yoksa ekipler yanlış şeyi değiştirerek saatler harcar. Sıcak yol (hot path) veritabanında, ağda veya beklenmedik bir tahsisatta olabilirken ekip neredeyse hiç çalışma yapmayan kodu parlatır. Daha kötüsü, akıllıca görünen bir değişiklik performansı kötüleştirebilir: sık döngüde ekstra logging, belleği artıran bir önbellek veya kilit yarışına yol açan paralel işler.
Tahmin yürütmek ayrıca davranışın bozulma riskini artırır. Hızı artırmak için kodu değiştirdiğinizde sonuçları, hata işleyişini, sıralamayı veya tekrar denemeleri etkileyebilirsiniz. Doğruluk ve hızı birlikte tekrar kontrol etmezseniz, bir kıyaslamada "kazanıp" sessizce bir hata gönderme riskiniz olur.
Performansı tartışma gibi değil deney gibi ele alın. Döngü basit ve tekrarlanabilirdir:
Birçok kazanım mütevazıdır: p95 gecikmeden %8 kesinti, tepe bellek kullanımında 50 MB azalma veya bir veritabanı sorgusunun kaldırılması. Bu kazanımlar yine de önemlidir; ama yalnızca ölçüldüklerinde, doğrulandıklarında ve tekrarlanabildiklerinde.
Bu bir döngü olarak çalıştığında en etkilidir, tek seferlik "daha hızlı yap" isteği değil. Döngü sizi dürüst tutar çünkü her eylem kanıta ve izleyebileceğiniz bir sayıya bağlanır.
Açık bir sıra:
Her adım farklı bir yanıltmayı engeller. Önce ölçmek, gerçek bir problem olmayanı "düzeltmenizi" engeller. Yazılı bir hipotez, aynı anda beş şeyi değiştirip hangisinin etkili olduğunu tahmin etmeyi engeller. Minimal değişiklikler davranışı bozma veya yeni darboğazlar ekleme riskini azaltır. Yeniden ölçmek, ısınmış önbellekten kaynaklanan sahte kazanımları yakalar ve gerilemeleri açığa çıkarır.
"Bitti" bir his değildir. Sonuçtur: hedef metrik doğru yönde hareket etti ve değişiklik belirgin gerilemelere (hatalar, daha yüksek bellek, kötüleşen p95, ya da çevre uç noktaların yavaşlaması) neden olmadı.
Ne zaman durulacağını bilmek iş akışının bir parçasıdır. Kazançlar düzleştiğinde, metrik kullanıcılar için yeterince iyi olduğunda veya bir sonraki fikir büyük refaktörler gerektirip küçük fayda sağlayacağında durun. Performans çalışması her zaman fırsat maliyeti taşır; döngü zamanı kazandıran yerlere odaklanmanıza yardımcı olur.
Aynı anda beş şeyi ölçerseniz neyin iyileştiğini bilemezsiniz. Bu inceleme için bir birincil metrik seçin ve diğerlerini destekleyici sinyaller olarak değerlendirin. Kullanıcıya dönük birçok problem için bu metrik gecikmedir. Batch işler için throughput, CPU süresi, bellek kullanımı veya hatta çalıştırma başına bulut maliyeti olabilir.
Senaryoya özgü olun. "API yavaş" çok belirsizdir. "3 öğelik tipik bir sepet ile POST /checkout" ölçülebilir. Girdileri sabit tutun ki sayılar bir anlam taşısın.
Koda dokunmadan önce baz değeri ve ortam detaylarını yazın: veri seti boyutu, makine tipi, build modu, feature flagler, eşzamanlılık ve ısınma. Bu baz değerinizin demiridir. Onsuz her değişiklik ilerleme gibi görünebilir.
Gecikme için ortalamaya değil yüzdeliklere (percentiles) güvenin. p50 tipik deneyimi, p95 ve p99 ise kullanıcıların şikâyet ettiği acı veren kuyruğu gösterir. p50 iyileşirken p99 kötüleşirse sistem yine de daha yavaş hissedilebilir.
"Anlamlı" olmanın ne demek olduğunu baştan kararlaştırın ki gürültüyü kutlamayın:
Bu kurallar konulduktan sonra, fikirleri test ederken hedefi kaydırmazsınız.
Güvenebileceğiniz en kolay sinyal ile başlayın. Bir isteğin tek bir zamanlaması, gerçek bir problemin olup olmadığını ve kabaca ne kadar büyük olduğunu söyleyebilir; neden yavaş olduğunu açıklamak için derin profilleme saklayın.
İyi kanıt genellikle bir karışım kaynaklardan gelir:
Soru "daha yavaş mı ve ne kadar?" ise basit metrikler kullanın. Soru "zaman nereye gidiyor?" ise profilleme kullanın. Bir deploy sonrası p95 iki katına çıktıysa önce regresyonu onaylamak ve kapsamlamak için zamanlamalar ve loglarla başlayın. Zamanlamalar gecikmenin çoğunun uygulama içinde olduğunu gösteriyorsa (DB değil), bir CPU profiler veya flame graph hangi fonksiyonun büyüdüğünü gösterebilir.
Ölçümleri güvenli tutun. Performansı debug etmek için gerekeni toplayın, kullanıcı içeriğini değil. Ham payloadlar yerine özetleri (süreler, sayılar, boyutlar) tercih edin ve varsayılan olarak tanımlayıcıları gizleyin.
Gürültü gerçek olduğundan birden çok örnek alın ve aykırı değerleri not edin. Aynı isteği 10 ila 30 kez çalıştırın ve tek en iyi çalıştırma yerine medyan ve p95'i kaydedin.
Tam olarak aynı testi tekrarlayabilmeniz için test tarifini yazın: ortam, veri seti, uç nokta, istek gövde boyutu, eşzamanlılık seviyesi ve sonuçları nasıl aldığınız.
Semptomu adlandırarak başlayın: "p95 gecikme trafik zirvelerinde 220 ms'den 900 ms'ye çıkıyor", "CPU iki çekirdekte %95'te oturuyor" veya "bellek saatte 200 MB artıyor." "Yavaş hissetme" gibi belirsiz semptomlar rastgele değişikliklere yol açar.
Sonra ölçtüklerinizi şüpheli bir alana çevirin. Bir flame graph çoğu zamanı JSON serileştirmede gösteriyor olabilir, bir trace yavaş bir çağrı yolunu gösterebilir veya veritabanı istatistikleri tek bir sorgunun toplam zamanın çoğunu kapsadığını gösterebilir. Maliyetin çoğunu açıklayan en küçük alanı seçin: bir fonksiyon, tek bir SQL sorgusu veya bir dış çağrı.
İyi bir hipotez bir cümle, test edilebilir ve bir öngörüye bağlıdır. Yardım isterken bir aracın sihirli şekilde her şeyi hızlandırmasını istemiyorsunuz; fikir test edilecek şekilde sunulmalı.
Bu formatı kullanın:
Örnek: "Profil CPU'nun %38'ini SerializeResponse içinde gösterdiği için her istek başına yeni bir buffer tahsisi CPU spike'larına neden oluyor. Eğer buffer'ı yeniden kullanırsak, p95 gecikme yaklaşık %10-20 düşmeli ve CPU aynı yük altında %15 azalmalı."
Kodu değiştirmeden önce alternatifleri de isimlendirerek dürüst kalın. Yavaş bölüm aslında upstream bağımlılık olabilir, kilit yarışması, önbellek vuruş oranı değişimi veya payload boyutunu artıran bir rollout olabilir.
2-3 alternatif açıklamayı yazın, sonra kanıtın en iyi desteklediğiyle başlayın. Değişiklik metrikleri hareket ettirmezse zaten bir sonraki hipoteziniz hazır olur.
Claude, performans çalışmalarında dikkatli bir analist gibi kullanıldığında en faydalıdır, kehanet mercii gibi değil. Her öneriyi ölçtüğünüzle ilişkilendirin ve her adımın yanlışlanabilir olduğundan emin olun.
Vagu olmayan, gerçek girdiler verin. Küçük, odaklanmış kanıtları yapıştırın: bir profilleme özeti, yavaş isteğe ait birkaç log satırı, bir sorgu planı ve spesifik kod yolu. "Önce" sayıları (p95, CPU zamanı, DB zamanı) dahil edin ki başlangıç bilgisi olsun.
Veri ne önerdiğini ve neyi desteklemediğini açıklamasını isteyin. Sonra rakip açıklamaları zorlayın. Kullanışlı bir prompt şu cümleyle bitmeli: "Bana 2-3 hipotez ver, ve her biri için neyle yanlışlanacağını söyle." Bu, ilk makul hikâyeye takılmayı engeller.
Herhangi bir şeye dokunmadan önce en küçük deneyi isteyin ki önder hipotezi doğrulanabilsin. Hızlı ve geri alınabilir olsun: bir fonksiyonun etrafına zamanlayıcı ekleyin, bir profiler flag'i açın ya da bir DB sorgusunu EXPLAIN ile çalıştırın.
Çıktı için sıkı bir yapı istiyorsanız şu şekilde isteyin:
Eğer belirli bir metrik, yer ve beklenen sonuç adımı yoksa yine tahmine dönmüşsünüz demektir.
Kanıtınız ve hipoteziniz olduktan sonra her şeyi "temizlemeye" kalkışmayın. Performans çalışması en güvenilir olduğunda kod değişikliği küçük ve kolay geri alınabilir olmalıdır.
Aynı anda birden fazla şeyi değiştirmeyin. Bir sorguda ince ayar yapıp aynı commit'te önbellek ekleyip döngüyü refactor ederseniz hangi değişikliğin etkili olduğunu bilemezsiniz. Tek değişkenli değişiklikler bir sonraki ölçümü anlamlı kılar.
Koda dokunmadan önce sayısal beklentinizi yazın. Örnek: "p95 gecikme 420 ms'den 300 ms altına düşmeli ve DB zamanı yaklaşık 100 ms azalmalı." Sonuç bu hedefin altında kaldıysa hipotezin zayıf veya eksik olduğunu çabuk öğrenirsiniz.
Değişiklikleri geri alınabilir tutun:
"Minimal" önemsiz demek değildir; odaklanmış demektir: pahalı bir fonksiyonun sonucunu önbelleğe almak, sık döngüde tekrar eden bir tahsisi kaldırmak veya gereksiz işleri istekler için yapmayı durdurmak.
Şüpheli darboğazın etrafına hafif zamanlayıcı ekleyin ki neyin hareket ettiğini görün. Bir çağrı öncesi ve sonrası zaman damgası (loglanan veya metrik olarak yakalanan) değişikliğin gerçekten yavaş kısmı hedefleyip hedeflemediğini doğrular.
Bir değişiklikten sonra baz değeri aldığınız ile aynı senaryoyu tekrar çalıştırın: aynı girdiler, ortam ve yük şekli. Testiniz önbelleklere veya ısınmaya bağlıysa bunu açıkça belirtin (örneğin: "ilk deneme cold, sonraki 5 deneme warm"). Aksi halde şanslı bir iyileşmeyi gerçekmiş gibi bulabilirsiniz.
Aynı metrik ve aynı yüzdelikleri kullanarak karşılaştırın. Ortalamalar acıyı gizleyebilir; p95 ve p99 gecikmeye, throughput ve CPU zamanına dikkat edin. Sayıların yerleşip yerleşmediğini görmek için yeterli tekrarı çalıştırın.
Kutlamadan önce başlık sayının dışında gerilemeleri kontrol edin:
Sonra umudun değil kanıtın gösterdiğine göre karar verin. İyileşme gerçekse ve gerileme yoksa devam edin. Sonuç karışık veya gürültülü ise revert edin ve yeni hipotez kurun veya değişikliği daha da izole edin.
Koder.ai gibi bir platformda çalışıyorsanız, deneye başlamadan önce bir snapshot almak geri dönüşü tek adım yapabilir; bu da cesur fikirleri güvenle denemeyi kolaylaştırır.
Son olarak öğrendiklerinizi yazın: baz değer, değişiklik, yeni sayılar ve sonuç. Bu kısa kayıt bir sonraki turun aynı çıkmazları tekrarlamamasını sağlar.
Performans çalışması genellikle ölçtüğünüzle değiştirdikleriniz arasındaki bağlantıyı kaybettiğinizde sapar. Neyin daha iyi veya daha kötü yaptığını güvenle söyleyebilmeniz için kanıt zincirini temiz tutun.
Tekrarlayan hatalar:
Küçük bir örnek: bir uç nokta yavaş görünüyor, profilde serializer sıcak olduğu için onu ayarlıyorsunuz. Sonra daha küçük bir veri setiyle yeniden test edip daha hızlı olduğunu görüyorsunuz. Prod ortamında p99 kötüleşiyor çünkü veritabanı hâlâ darboğaz ve değişiklik payload büyüterek durumu kötüleştirmiş olabilir.
Claude Code kullanarak düzeltme önerileri alıyorsanız kısa bir leşe alın. Topladığınız kanıtlara uyan 1-2 minimal değişiklik isteyin ve bir yama kabul etmeden önce yeniden ölçme planı talep edin.
Test bulanıksa hız iddiaları çöker. Kutlamadan önce neyi ölçtüğünüzü, nasıl ölçtüğünüzü ve neyi değiştirdiğinizi açıklayabildiğinizden emin olun.
Bir metrik adımlayın ve baz değeri ortam notlarıyla yazın (donanım, konfig, veri, build modu, feature flag, önbellek durumu). Yarın aynı ortamı yeniden oluşturamıyorsanız baz değeriniz yoktur.
Kontrol listesi:
Sayılar daha iyi görünüyorsa hızlı bir regresyon kontrolü yapın: doğruluk, hata oranı ve zaman aşımı kontrolü. Daha yüksek bellek, CPU spike'ları, daha yavaş başlatma veya daha fazla DB yükü gibi yan etkileri izleyin. p95'i iyileştirip belleği iki katına çıkaran bir değişiklik yanlış bir takastır.
Bir ekip GET /orders'ın geliştirmede iyi göründüğünü, ancak orta yükte staging'de yavaşladığını bildiriyor. Kullanıcılar zaman aşımından şikâyet ediyor, ama ortalama gecikme hâlâ "kabul edilebilir" görünüyor ki bu klasik bir tuzaktır.
Önce bir baz değer belirleyin. Sabit bir yük testi altında (aynı veri seti, aynı eşzamanlılık, aynı süre) kaydettiğiniz değerler:
Sonra kanıt toplayın. Hızlı bir trace, uç noktanın ana bir sipariş sorgusu çalıştırdığını, sonra her sipariş için ilişkili öğeleri döngüyle çektiğini gösteriyor. JSON yanıtı büyük, ama DB zamanı baskın.
Bunu test edilebilir hipotezlere çevirin:
En güçlü kanıta uyan minimal değişikliği isteyin: açık bir N+1 çağrısını kaldırarak order ID'lerine göre tek sorgu ile yüklenmesini sağlamak (veya yavaş sorgu planı tam taramayı gösteriyorsa eksik indexi eklemek). Değişiklik reversible ve odaklı bir commit olsun.
Aynı yük testiyle yeniden ölçün. Sonuçlar:
Karar: düzeltmeyi gönderin (açık kazanım), sonra kalan fark ve CPU spike'ları için ikinci turu başlatın çünkü DB artık ana sınırlayıcı değil.
Performans incelemelerinde daha hızlı gelişmenin en iyi yolu her deneyi küçük, tekrarlanabilir bir deney gibi ele almaktır. Süreç tutarlı olduğunda sonuçlar güvenilir, karşılaştırılabilir ve paylaşılabilir olur.
Basit bir tek sayfa şablon yardımcı olur:
Bu notların nerede tutulacağına karar verin ki kaybolmasın. Paylaşılan bir yer mükemmel araçtan daha önemlidir: servis yanında bir repo klasörü, ekip dokümanı veya ticket notları olabilir. Birinin "önbellek değişikliğinden sonra p95 spike'ı" gibi bir kaydı aylar sonra bulabilmesi gerekir.
Güvenli deneyleri alışkanlık haline getirin. Snapshot'lar ve kolay rollback kullanarak bir fikri korkmadan deneyin. Eğer Koder.ai ile geliştiriyorsanız, Planning Mode ölçüm planını, hipotezi ve değişiklik kapsamını tanımlamak için uygun bir yer olabilir; böylece sıkı bir diff üretilmeden önce yeniden ölçme planı hazır olur.
Bir ritim belirleyin. Olayları beklemeyin. Yeni sorgular, yeni uç noktalar, daha büyük payloadlar veya bağımlılık yükseltmeleri sonrası küçük performans kontrolleri ekleyin. Şimdi yapılacak 10 dakikalık bir baz kontrolü ileride bir günlük tahmin yürütmeyi engelleyebilir.
Start with one number that matches the complaint, usually p95 latency for a specific endpoint and input. Record a baseline under the same conditions (data size, concurrency, warm/cold cache), then change one thing and re-measure.
If you can’t reproduce the baseline, you’re not measuring yet—you’re guessing.
A good baseline includes:
Write it down before you touch code so you don’t move the goalposts.
Percentiles show the user experience better than an average. p50 is “typical,” but users complain about the slow tail, which is p95/p99.
If p50 improves but p99 gets worse, the system can feel slower even though the average looks better.
Use simple timings/logs when you’re asking “is it slower and by how much?” Use profiling when you’re asking “where is the time going?”
A practical flow is: confirm the regression with request timings, then profile only after you know the slowdown is real and scoped.
Pick one primary metric, and treat the rest as guardrails. A common set is:
This keeps you from “winning” one chart while quietly causing timeouts, memory growth, or worse tail latency.
Write a one-sentence hypothesis tied to evidence and a prediction:
If you can’t name the evidence and the expected metric movement, the hypothesis isn’t testable yet.
Make it small, focused, and easy to undo:
Small diffs make the next measurement meaningful and reduce the chance you break behavior while chasing speed.
Re-run the exact same test recipe (same inputs, load, environment, cache rules). Then check for regressions beyond the headline number:
If results are noisy, take more samples or revert and tighten the experiment.
Give it concrete evidence and force it to stay test-driven:
If the output doesn’t include a specific metric and re-test plan, you’re drifting back into guesswork.
Stop when:
Performance work has opportunity cost. The loop (measure → hypothesize → change → re-measure) helps you spend time only where the numbers prove it matters.