Dağıtık SQL Ne Anlama Gelir (Abartısız)
“Dağıtık SQL”, tablolar, satırlar, join’ler, işlemler ve SQL gibi tanıdık bir ilişkisel veritabanı deneyimi sunan, ancak birçok makine (ve sıklıkla birden fazla bölge) üzerinde çalışan ve yine de tek bir mantıksal veritabanı gibi davranacak şekilde tasarlanmış bir veritabanıdır.
Bu kombinasyon önemlidir çünkü üç şeyi aynı anda sağlamaya çalışır:
- SQL ve ilişkisel modelleme: tanıdık şemalar, kısıtlar ve sorgu araçları.
- Yatay ölçek: kapasiteyi artırmak için düğüm eklemek, “daha büyük bir sunucu almak” yerine.
- Güçlü tutarlılık: veriler dağılmış olsa bile okuma ve yazmalar net işlem kurallarına uyar.
Klasik RDBMS ile NoSQL arasında
Klasik bir RDBMS (PostgreSQL veya MySQL gibi) genellikle her şeyin tek bir birincil düğümde yaşadığı durumda çalıştırması en kolay olanıdır. Okumaları replika ile ölçeklendirebilirsiniz, ancak yazmaları ölçeklendirmek ve bölgesel kesintilerden kurtulmak genellikle ek mimari (sharding, manuel failover ve dikkatli uygulama mantığı) gerektirir.
Birçok NoSQL sistemi tam tersini yaptı: öncelikle ölçek ve yüksek kullanılabilirlik, bazen tutarlılık garantilerini gevşeterek veya daha basit sorgu modelleri sunarak.
Dağıtık SQL ise ortada bir yol hedefler: ilişkisel modeli ve ACID işlemleri korur, ancak büyümeyi ve hataları otomatik olarak yönetmek için veriyi dağıtır.
Ne çözmeye çalışıyor
Dağıtık SQL veritabanları şu tür sorunlar için inşa edilmiştir:
- Birden fazla bölgede kullanıcıları olan küresel uygulamalar, gecikme ve çalışma süresinin ikisi de önemli olduğunda.
- Manuel, karmaşık failover prosedürleri olmadan yüksek kullanılabilirlik.
- Zaman içinde büyüme, kapasiteyi kademeli olarak artırmak ve tek bir veritabanı arabirimini korumak istediğinizde.
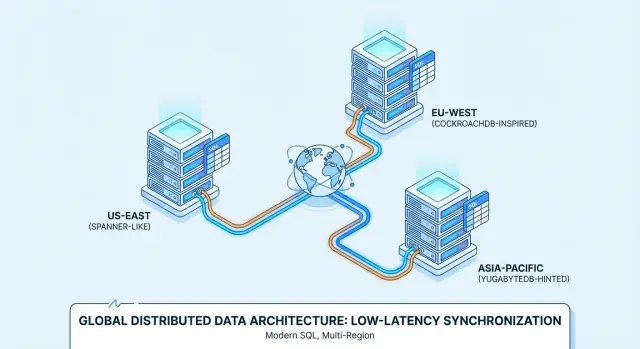
Bu nedenle Google Spanner, CockroachDB ve YugabyteDB gibi ürünler genellikle çok bölgeli dağıtım ve sürekli hizmet ihtiyaçları için değerlendirilir.
Beklentileri ayarla (varsayılan değil)
Dağıtık SQL otomatik olarak “daha iyi” değildir. Daha fazla hareketli parça ve farklı performans gerçekleri (ağ atlamaları, konsensüs, bölge arası gecikme) kabul ediyorsunuz, karşılığında dayanıklılık ve ölçek elde ediyorsunuz.
Eğer iş yükünüz tek bir iyi yönetilen veritabanına sığıyorsa ve basit bir replika kurulumu iş görüyorsa, geleneksel bir RDBMS daha basit ve daha ucuz olabilir. Dağıtık SQL, alternatifin özel sharding, karmaşık failover veya çok bölgeli tutarlılık ve çalışma süresi gerektiren iş gereksinimleri olduğu durumlarda kendini haklı çıkarır.
Dağıtık SQL İçten Nasıl Çalışır
Dağıtık SQL, tanıdık bir SQL veritabanı hissi vermeyi hedeflerken veriyi birçok makineye (ve sıklıkla birçok bölgeye) dağıtır. Zor kısım, birçok bilgisayarı koordine edip güvenilir tek bir sistem gibi davranmalarını sağlamaktır.
Replikasyon + konsensüs: düğümlerin anlaşması
Her veri parçası genellikle birkaç düğüme kopyalanır (replikasyon). Bir düğüm arızalanırsa, başka bir kopya okumaları sunmaya ve yazmaları kabul etmeye devam edebilir.
Replikaların ayrışmaması için Dağıtık SQL sistemleri konsensüs protokollerini kullanır—en yaygın olarak Raft (CockroachDB, YugabyteDB) veya Paxos (Spanner). Üst düzeyde konsensüs şunu ifade eder:
- Bir replika grup için bir “lider” görevi görür.
- Yazmalar lidere gider.
- Lider, çoğunluk replika onayı alınana kadar yazıyı onaylamaz.
Bu “çoğunluk oyu” size güçlü tutarlılık verir: bir işlem taahhüt edildiğinde, diğer istemciler daha eski bir veri görmez.
Sharding/partitioning: verinin nerede durduğu
Hiçbir tek makine her şeyi saklayamaz, bu yüzden tablolar daha küçük parçalara bölünür—shard/partition olarak (Spanner bunlara splits, CockroachDB ranges, YugabyteDB tablets der).
Her partition konsensüs ile çoğaltılır ve belirli düğümlere yerleştirilir. Yerleştirme rastgele değildir: politikalarla etkileşim kurabilirsiniz (örneğin AB müşterilerini AB bölgelerinde tutmak veya sıcak partitionları daha hızlı düğümlerde bulundurmak). İyi yerleştirme ağ üzerindeki yolculukları azaltır ve performansı daha öngörülebilir kılar.
Düğümler arası işlemler (ve neden gecikme getirir)
Tek düğümlü bir veritabanında bir işlem genellikle yerel disk çalışmasıyla kabul edilebilir. Dağıtık SQL’de bir işlem birden fazla partition’a dokunabilir—farklı düğümlerde olabilir.
Güvenli bir şekilde commit etmek genellikle ek koordinasyon gerektirir:
- İlgili partitionlarda kilitleme veya doğrulama
- Yazıların konsensüs yoluyla çoğaltılması (çoğunluk onayları)
- Tüm katılımcıların kabul ettiği commit kararının sonuçlandırılması
Bu adımlar ağ turu ekler; bu yüzden dağıtık işlemler genellikle gecikme ekler—özellikle veri bölgeler arası olduğunda.
Çok bölgeli davranış: yerellik farkındalığı
Dağıtımlar bölgeler arasında olduğunda sistemler işlemleri kullanıcılara “yakın” tutmaya çalışır:
- Yerel okuma gerektiğinde yakın replikalardan servis edilebilir.
- Yerel yazma liderleri tercih edilen bir bölgede yönlendirilebilir veya liderleri birincil yazanlara yakın konumlandırabilirsiniz.
Bu çok bölgeli denge işinin özü: yerel tepki sürelerini optimize edebilirsiniz, ama uzun mesafelerde güçlü tutarlılık hala ağ maliyeti ödetecektir.
Ne Zaman Gerçekten Gerekir (Ve Ne Zaman Gerekmez)
Dağıtık SQL’e yönelmeden önce temel ihtiyaçlarınızı kontrol edin. Tek bir birincil bölgeniz, öngörülebilir yükünüz ve küçük bir operasyon ekibiniz varsa, geleneksel bir ilişkisel veritabanı (veya yönetilen Postgres/MySQL) genellikle hızlıca özellik sunmanın en basit yoludur. Tek bölge kurulumunu replika, önbellekleme ve dikkatli şema/index çalışmasıyla uzun süre idare edebilirsiniz.
Dağıtık SQL’in kendini haklı çıkardığı net tetikleyiciler
Dağıtık SQL’i ciddi şekilde düşününce değer kazandığı durumlar:
- Gerçek kullanıcılarınız birden fazla bölgede ve veritabanının onlara yakın olmasını istiyorsunuz, uygulama düzeyinde karmaşık sharding kurmadan.
- Çok yüksek uptime gereksinimleri var (ör. bölge/zone arızasını atlatmak) ve tek bir birincil bölge kabul edilemez risk.
- Veri hacmi veya yazma toplamı dikey ölçeklemeyi aşıyor ve SQL semantiğini koruyarak yatay ölçek istiyorsunuz.
- Çekirdek işlemler için güçlü tutarlılık gerekir (siparişler, bakiyeler, rezervasyonlar) ve birden çok sistemi birleştirmek istemiyorsunuz.
- Uyumluluk coğrafi yerleşim zorunluluğu gerektiriyor ama yine de tek bir mantıksal veritabanına ihtiyaç var.
Anti-tetikleyiciler: genellikle yanlış hamle olduğu durumlar
Dağıtık sistemler karmaşıklık ve maliyet ekler. Dikkatli olun eğer:
- Ekip küçükse ve yeni hata modlarını, operasyonel desenleri öğrenmeye zaman yoksa.
- Trafik düşük veya düzensizse ve yakın zamanda tek bölgeyi aşmayacaksanız.
- Tek anahtar yazmalar için çok sıkı gecikme bütçeniz varsa ve güçlü tutarlığın getirdiği koordinasyon yükünü kaldıramıyorsanız.
- İş yükünüz analitik ağırlıklıysa (büyük taramalar, karmaşık raporlar). OLTP’yi analitikten ayırmak daha iyi olabilir.
Hızlı karar kontrol listesi
İki veya daha fazlasına “evet” diyorsanız, dağıtık SQL değerlendirmeye değer:
- Çok bölge kullanıcılarıyla tutarlı veriye ihtiyacınız var mı?
- Otomatik failover’a ihtiyacınız var mı (zone/region across)?
- Ölçekleme sık bir kriz haline geldi mi?
- Sharding, veritabanının kendisinden daha fazla mühendislik yükü mü yaratır?
- Tek bir operasyon modeliyle veri yerleşimini zorunlu kılıyor musunuz?
Tutarlılık, Kullanılabilirlik ve Gecikme: Temel Takaslar
Dağıtık SQL “her şeyi aynı anda al” gibi görünür, ama gerçek sistemler seçim yaptırır—özellikle bölgeler birbirleriyle güvenilir konuşamıyorsa.
Ürün kararları için CAP
Ağ bölünmesini bölge bağlantılarının kesildiği veya güvensiz olduğu an olarak düşünün. O anda bir veritabanı öncelik verebilir:
- Tutarlılık: herkes aynı, güncel cevabı görür (veya işlem başarısız olur).
- Kullanılabilirlik: uygulama her bölgede okumaları/yazmaları kabul etmeye devam eder (cevaplar geçici olarak farklı olabilir).
Dağıtık SQL sistemleri genellikle işlemler için tutarlılığı tercih edecek şekilde inşa edilir. Takımlar bunu genellikle ister—ta ki bir bölünme bazı işlemlerin beklemesi veya başarısız olması gerektiğini görene kadar.
Güçlü tutarlılık (neden para ve envanter için önemli)
Güçlü tutarlılık demek, bir işlem commit olduktan sonra sonraki her okumanın o commit edilmiş değeri döndürmesidir—“bir bölgede oldu ama diğerinde olmadı” gibi durumlar olmaz. Bu şu durumlar için kritiktir:
- Ödemeler ve bakiyeler (çifte harcamayı veya yanlış toplamları önler)
- Envanter / rezervasyonlar (son ürünü fazla satmayı engeller)
Eğer ürün vaadiniz “onayladığımızda gerçek” ise, güçlü tutarlılık bir özellik, lüks değil.
Yazdıktan sonra kendini okuma ve izolasyon
İki pratik davranış önemlidir:
- Yazdıktan sonra kendini okuma: kullanıcı profilini güncelledikten sonra bir sonraki ekranda yeni durumu görmeli, daha eski bir replika değil.
- İşlem izolasyonu: aynı anda gerçekleşen işlemler nasıl etkileşir. Daha güçlü izolasyon, iki müşterinin aynı koltuğu rezervasyon yapması gibi ince hataları önler.
Bölge arası konsensüsün gecikme maliyeti
Bölgeler arası güçlü tutarlılık genellikle konsensüs gerektirir (çoğunluk replikanın commit onayı). Kıtalar arasındaki yazmalar her seferinde on, yüz milisaniyeler ekleyebilir. Basitçe: coğrafi güvenlik ve doğruluk genellikle daha yüksek yazma gecikmesi demektir—yine de verinin nerede yaşadığını ve işlemlerin nerede commit edileceğini dikkatle seçerseniz bunu azaltabilirsiniz.
Spanner vs CockroachDB vs YugabyteDB: Pratik Bir Bakış
Google Spanner, esas olarak Google Cloud’da yönetilen bir hizmet olarak sunulan dağıtık SQL veritabanıdır. Tek bir mantıksal veritabanı isteyen, veriyi düğümler ve bölgeler arasında çoğaltan çok bölgeli dağıtımlar için tasarlanmıştır. Spanner iki SQL lehçesi seçeneği sunar—yerel GoogleSQL ve PostgreSQL uyumlu bir lehçe—bu yüzden taşınabilirlik, seçtiğiniz lehçeye ve uygulamanızın hangi özelliklere bağımlı olduğuna bağlı olarak değişir.
CockroachDB, PostgreSQL’e aşina ekiplerin rahat hissedebileceği bir dağıtık SQL veritabanı olmayı hedefler. PostgreSQL wire protokolünü kullanır ve PostgreSQL tarzı SQL’in büyük bir alt kümesini destekler, ancak birebir Postgres yerine geçmez (bazı uzantılar ve kenar durum davranışları farklıdır). Yönetilen bir hizmet (CockroachDB Cloud) olarak veya kendi altyapınızda self-hosted çalıştırabilirsiniz.
YugabyteDB, PostgreSQL uyumlu bir SQL API (YSQL) ve ek olarak Cassandra uyumlu bir API (YCQL) sunan dağıtık bir veritabanıdır. CockroachDB gibi, Postgres-benzeri geliştirme ergonomisini isterken düğümler ve bölgeler arasında ölçeklenmek isteyen ekipler tarafından değerlendirilir. Hem self-hosted hem de yönetilen (YugabyteDB Managed) seçenekleri vardır.
Yönetilen vs self-hosted: ne değişir
Yönetilen hizmetler genellikle operasyonel işi azaltır (güncellemeler, yedekler, izleme entegrasyonları), self-hosting ise ağ, örnek tipleri ve verinin fiziksel nerede çalıştığı üzerinde daha fazla kontrol verir. Spanner genellikle GCP üzerinde yönetilen olarak kullanılır; CockroachDB ve YugabyteDB hem yönetilen hem de self-hosted olarak, çoklu bulut ve on-prem seçeneklerinde görülür.
Pratikte SQL uyumluluğu
Üçü de “SQL” konuşur, ama günlük uyumluluk lehçe seçimine (Spanner), Postgres özellik kapsamına (CockroachDB/YugabyteDB) ve uygulamanızın belirli Postgres uzantılarına veya işlem semantiklerine bağlıdır.
Planlamaya vakit ayırın: sorgularınızı, migration’larınızı ve ORM davranışınızı erken test edin; drop-in eşdeğerlik varsaymayın.
Kullanım Örneği: Bölgesel Kullanıcılara Sahip Küresel SaaS
Simulate Inventory Conflicts
Build a minimal booking app and pressure-test contention, hot keys, and consistency behavior.
Dağıtık SQL için klasik bir uyum B2B SaaS ürünüdür, müşterileri Kuzey Amerika, Avrupa ve APAC’e dağılmış—destek araçları, İK platformları, gösterge panoları veya pazar yerleri gibi.
İş gereksinimi basit: kullanıcılar “yerel uygulama” duyarlılığı istiyor, şirket ise tek mantıksal veritabanı ile her zaman erişilebilirlik istiyor.
Veri yerleşimi ve kiracı başına yerelleştirme
Birçok SaaS ekibi şu karışık gereksinimlerle karşılaşır:
- AB müşterileri verilerinin AB’de kalmasını bekler (GDPR, sözleşme taahhütleri).
- Bazı müşteriler ülke içinde depolama ister (ör. Almanya, Avustralya, Singapur).
- Diğerleri umursamaz ama düşük gecikme ister.
Dağıtık SQL, her kiracının birincil verisini belirli bir bölgede veya bölgeler kümesinde tutarak veri yerelleştirmesini temiz şekilde modelleyebilir. Böylece “bölge başına bir veritabanı” karmaşasından kaçınırken uyumluluk gereksinimlerini karşılayabilirsiniz.
Gecikmeyi en aza indirme: bölgesel okumalar ve yazma yerleşimi
Uygulamayı hızlı tutmak için genellikle hedef:
- Bölgesel okumalar: okuma ağırlıklı sorguları kullanıcının yakınındaki replikalardan sunmak.
- Yazma yerleşimi: yazma liderini kiracının yazılarının çoğunun geldiği bölgeye koymak.
Çünkü bölge arası round trip’ler kullanıcı algısını domine eder. Güçlü tutarlılık olsa bile, iyi yerellik tasarımı çoğu isteğin kıtalararası ağ maliyeti ödememesini sağlar.
Operasyonel gerçekler
Teknik kazanımlar, operasyon yönetilebilir kaldığında anlamlıdır. Küresel SaaS için planlayın:
- Çevrimiçi şema değişiklikleri: tabloları bölgeler arası kilitlemeden değiştirmek.
- Kiracı taşımaları: bir kiracıyı başka bir bölgeye düşük kesintiyle taşımak.
- İzleme ve uyarılar: replikasyon gecikmesi, hotspot’lar, yavaş sorgular ve bölge düzeyinde olaylar için.
İyi yapıldığında, dağıtık SQL tek bir ürün deneyimi sunar ama hâlâ yerel hissettirir—mühendis ekibinizi “AB yığını” ve “APAC yığını” olarak bölmek zorunda kalmazsınız.
Kullanım Örneği: Finansal İş Akışları ve Defterler
Finansal sistemlerde “er ya da geç tutarlılık” gerçek para kaybına dönüşebilir. Bir müşteri sipariş verdiğinde, ödeme yetkilendirildiğinde ve bakiye güncellendiğinde, bu adımların tek bir hakikat üzerinde anlaşması gerekir—hemen.
Güçlü tutarlılık kritiktir çünkü iki farklı bölge (veya iki farklı servis) makul bir karar verip daha sonra tutarsızlık yaratırsa yanlış defter oluşur.
Güçlü tutarlılık neden tartışılamaz
Tipik bir iş akışında—sipariş oluştur → fon rezerve et → ödemeyi yakala → bakiye/defteri güncelle—şu garantileri istersiniz:
- Ödeme yakalanmamışsa bir sipariş “ödenmiş” olarak işaretlenemez.
- İki işlem yarışınca bir bakiyenin negatif olması engellenir.
- Aynı işi iki kez yeniden deneme sonucu iki kez iade yapılmaz.
Dağıtık SQL burada uygundur çünkü düğümler arasında ACID işlemler ve kısıtlar sağlar; bu sayede defter invariant’ları hatalar sırasında bile korunur.
Idempotensi ve “çifte tahsilat yok” desenleri
Çoğu ödeme entegrasyonu tekrar denemeye dayanır: zaman aşımı, webhook yeniden denemeleri ve işlerin yeniden işlenmesi normaldir. Veritabanı tekrarları güvenli hale getirmeye yardımcı olmalı.
Pratik yaklaşım, uygulama düzeyinde idempotency anahtarlarını veritabanında benzersizlik kısıtlarıyla eşleştirmektir:
- Her ödeme denemesi için bir
idempotency_key saklayın.
(account_id, idempotency_key) gibi benzersiz bir kısıt ekleyin.- “Ödeme kaydı oluştur + defter girdilerini uygula”yı tek bir işlemde sarın.
Böylece ikinci deneme zararsız bir no-op olur, çift çekim oluşmaz.
Düzgünlük bozulmadan ani yükleri yönetme
Satış etkinlikleri ve bordro çalıştırmaları ani yazma patlamaları yaratabilir. Dağıtık SQL ile düğüm ekleyerek yazma verimini artırabilirsiniz; aynı tutarlılık modelini koruyarak.
Anahtar nokta sıcak anahtarları (örn. tek bir tüccar hesabına tüm trafik) planlamak ve yükü yayacak şema desenleri kullanmaktır.
Uyumluluk, denetimler ve saklama
Finansal iş akışları genellikle değiştirilemez denetim izleri, izlenebilirlik (kim/ne/ne zaman) ve öngörülebilir saklama politikaları gerektirir. Belirli düzenlemeleri adlandırmasak bile şu varsayımla ilerleyin: eklenebilir defter girdileri, zaman damgalı kayıtlar, kontrollü erişim ve arşivleme kuralları denetimi bozmayacak şekilde olmalı.
Kullanım Örneği: Envanter, Rezervasyon ve Booking
Model Reliable Events
Draft a transactional outbox workflow and iterate quickly on schema and handlers.
Envanter ve rezervasyon basit görünür ama aynı kıtada olmayan birçok bölge aynı kıtaya hizmet ettiğinde zorlaşır: son konser koltuğu, “sınırlı drop” ürünü veya belirli gece için bir otel odası.
Zor olan kısım müsaitliği okumak değil—aynı öğeyi neredeyse aynı anda iki kişinin talep etmesini önlemektir.
Çakışmalar nereden gelir
Güçlü tutarlılık olmayan çok bölgeli bir kurulumda, her bölge hafifçe eski verilere dayanarak geçici olarak stokun olduğunu düşünebilir. Farklı bölgelerden iki kullanıcı checkout yaparsa, her ikisi de yerel olarak kabul edilebilir ve daha sonra uzlaşma sırasında çakışma olabilir.
Bu, çapraz bölge aşırı satışın nasıl oluştuğudur: sistem “yanlış” olduğu için değil, geçici olarak farklı gerçekliklere izin verdiği için.
Dağıtık SQL veritabanları burada genellikle tercih edilir çünkü yazma-ağırlıklı tahsislerde tek, yetkili sonucu uygulayabilir—böylece “son koltuk” gerçekten bir kez tahsis edilir.
Somut örnekler
- Koltuk rezervasyonu: İki kullanıcı aynı koltuğa tıklar. Güçlü tutarlılıkla sadece bir işlem commit olur; diğeri hemen başarısız olur ve UI yenileme ister.
- Sınırlı droplar: 500 öğe satışa çıkıyor, binlerce checkout denemesi var. Atomik azaltma-ve-ayırma istersiniz, daha sonra iadeyle uğraşmak yerine.
- Otel rezervasyonları: Envanter bir oda değil, oda-gece birimidir. Tarih aralığı için çift rezervasyon yapmak pahalıdır ve geri almak zordur.
Dağıtık SQL ile iyi giden desenler
Hold + confirm: Geçici bir hold (rezervasyon kaydı) bir işlemde konur, ardından ödeme ikinci adımda onaylanır.
Süre sonları: Hold’lar otomatik olarak süresi dolmalı (örn. 10 dakika) ki kullanıcı checkout’ı yarıda bıraktığında envanter sıkışmasın.
Transactional outbox: Bir rezervasyon onaylandığında, aynı işlem içinde bir “gönderilecek olay” satırı yazın; sonra bunu asenkron olarak e-posta, fulfillment veya mesaj kuyruğuna gönderin—böylece “kaydedildi ama onay gönderilmedi” boşluğu olmaz.
Sonuç: İşiniz bölgeler arası çifte tahsisi kaldıramıyorsa, güçlü işlemsel garantiler ürün özelliği haline gelir.
Kullanım Örneği: Yüksek Kullanılabilirlik ve Felaket Kurtarma
Yüksek kullanılabilirlik (HA), kesinti pahalıysa, öngörülemeyen arızalar kabul edilemezse ve bakımın sıkıcı olmasını istediğinizde Dağıtık SQL için uygundur.
Ama hedef “asla arızalanma” değil—belirli SLO’ları (ör. %99.9 veya %99.99 çalışma süresi) tutturmaktır; düğümler öldüğünde, zonelar karardığında veya güncellemeler uygulanırken bile.
“Her zaman açık” pratikte: SLO’lar, bakım, arızalar
“Her zaman açık”ı ölçülebilir beklentilere çevirin: aylık maksimum kesinti, kurtarma süresi hedefi (RTO) ve kurtarma noktası hedefi (RPO).
Dağıtık SQL sistemleri birçok yaygın arıza sırasında okumaları/yazmaları servis etmeye devam edebilir, ama sadece topoloji SLO’nuzla eşleşirse ve uygulamanız geçici hataları (retry, idempotency) düzgün ele alırsa.
Planlı bakım da önemlidir. Rolling upgrade ve örnek değiştirme, veritabanının liderlik/repikaları etkilenecek düğümlerden uzaklaştırabilmesiyle küme kapatılmadan daha kolay olur.
Çok zone vs çok bölge dayanıklılığı
Çok zone dağıtımlar tek bir AZ/zone arızasından ve birçok donanım hatasından korur, genellikle daha düşük gecikme ve maliyetle. Uyumluluk ve kullanıcı tabanınız çoğunlukla tek bölgedeyse yeterli olur.
Çok bölge dağıtımlar tam bölge arızasından korur ve bölge düzeyinde failover’ı destekler. Tradeoff, güçlü tutarlılık gerektiren işlemler için daha yüksek yazma gecikmesi ve daha karmaşık kapasite planlamasıdır.
Failover beklentileri (ve oyun günleriyle test)
Failover’ın anında veya görünmez olduğunu varsaymayın. Hizmetiniz için “failover”ın ne anlama geldiğini tanımlayın: kısa hata artışları mı? salt okunur dönemler mi? birkaç saniyelik artan gecikme mi?
“Game day”ler yapın:
- Bir düğümü, sonra bir zonu öldürün; SLO panellerinizi ve istemci hata bütçesini doğrulayın.
- Ağ bölünmelerini simüle edin ve lider/replika davranışını gözleyin.
- Bölge tahliyesi pratiği yapın ve gerçek RTO’yu ölçün.
Replikasyon yedek değildir
Senkron replika olsa bile yedekler ve geri yükleme tatbikatları yapın. Yedekler operatör hatalarına (kötü migration, yanlışlıkla silme), uygulama hatalarına ve çoğaltılabilecek bozulmalara karşı korur.
Point-in-time recovery (varsa), geri yükleme hızı ve üretime dokunmadan temiz bir ortama geri dönebilme yeteneğini doğrulayın.
Kullanım Örneği: Veri Yerleşimi ve Uyumluluk Odaklı Mimariler
Veri yerleşimi gereksinimleri, belirli kayıtların belirli ülke veya bölgede saklanması (ve bazen işlenmesi) gerektiğinde ortaya çıkar.
Bu kişisel veri, sağlık bilgisi, ödeme verisi, devlet işi veya sözleşmeyle yönlendirilen “müşteri sahibi verileri” için geçerli olabilir.
Dağıtık SQL, tek bir mantıksal veritabanını korurken veriyi fiziksel olarak farklı bölgelere koyabildiği için burada sıkça değerlendirilir—uygulama yığını bölgeler bazında tamamen ayrılmak zorunda kalmadan.
Yerleşim kuralları veritabanı tasarımını nasıl değiştirir
Regülatör veya müşteri “veri bölge içinde kalsın” isterse, sadece düşük gecikmeli replika yeterli değildir. Şunları garanti etmeniz gerekebilir:
- Belirli verinin birincil kopyası (veya tüm kopyaları) sadece onaylı bölgelerde saklanır
- Yedekler ve snapshot’lar aynı kurallara uyar
- Bölge dışındaki operatörler ve servisler ham veriye erişemez
Bu, konumun birinci sınıf kaygı olduğu mimarilere itebilir.
Kiracı başına yerleşim ve erişim kontrolleri (üst düzey)
SaaS’te yaygın desen, kiracı başına veri yerleşimidir. Örneğin: AB müşterilerinin satırları veya partition’ları AB bölgelerine sabitlenir, ABD müşterileri ABD’ye.
Genelde şu üçü birleşir:
- Veri yerleştirme kuralları (bir kiracının verisinin nerede bulunabileceği)
- Kimlik ve erişim kontrolleri (hangi servisler ve kişiler okuyabilir)
- Şifreleme ve anahtar yönetimi (bazen bölgeye bağlı anahtarlarla)
Amaç, operasyonel erişim, yedek geri yükleme veya bölge arası replika yoluyla yanlışlıkla yerleşim ihlalini zorlaştırmaktır.
Hukuki gereklilikler değişir—hukukçuyu dahil edin
Yerleşim ve uyumluluk yükümlülükleri ülkeye, sektöre ve sözleşmeye göre çok farklıdır ve zamanla değişir.
Veritabanı topolojisini uyumluluk programınızın parçası olarak ele alın ve varsayımları nitelikli hukuk danışmanları ve ilgili denetçilerle doğrulayın.
Çok bölgeli topolojinin raporlamaya etkisi
Yerleşim-dostu topolojiler küresel görünümleri karmaşıklaştırabilir. Müşteri verisi kasıtlı olarak ayrı bölgelerde tutuluyorsa, analiz ve raporlama şunları gerektirebilir:
- Bölgesel raporlama boru hatları (işlem, verinin bulunduğu yerde çalışır)
- Toplu dışa aktarmalar (sadece izin verilen metrikler bölge dışına çıkar)
- Küresel panolar için daha yüksek gecikme (küresel sorgular bölgeler arası olabileceği için)
Pratikte birçok ekip operasyonel iş yüklerini (güçlü tutarlılık, yerleşim farkındalığı) analitikten ayırır: analitik için bölgeye özel warehouse’lar veya kontrollü toplu veri setleri kullanılır.
Practice Failover Early
Deploy a test environment and run failure drills against realistic traffic.
Dağıtık SQL sizi acı kesintilerden ve bölgesel sınırlamalardan kurtarabilir, ama varsayılan olarak nadiren para tasarrufu sağlar. Önceden planlama, gereksiz “sigorta” için ödeme yapmaktan kaçınmanıza yardımcı olur.
Ana maliyet sürücüleri
Bütçeler genellikle dört kaleme ayrılır:
- Düğümler (compute): Birden fazla replikanın (genellikle her bölgede 3+) çevrimiçi tutulması gerekir; failover için ekstra kapasite gerekir. Çok bölgeli tasarımlar genellikle tek bölge Postgres’ten daha fazla kapasite gerektirir.
- Depolama: Replikasyon veri boyutunu çoğaltır. 2 TB veri üç replika ile ~6 TB eder, yedekler ve indeksler hariç.
- Bölge arası trafik: Bölge arası replikasyon, okumalar ve istemci trafiği anlamlı bir maliyet kalemi olabilir.
- Operasyon zamanı: Yönetilen teklifler bile çaba gerektirir: şema ve sorgu iyileştirme, olay yanıtı, kapasite planlama, upgrade testi, ve uyumluluk/yerleşim yönetimi.
Gerçek kullanıcı yolculuklarında gecikme etkisini tahmin etmek
Dağıtık SQL sistemleri koordinasyon ekler—özellikle güçlü tutarlı yazmalar için çoğunluk onayı gerektiğinde.
Etkisini tahmin etmenin pratik yolu:
- 2–3 ana yolculuk seçin (checkout, booking, "değişiklikleri kaydet").
- Kritik yoldaki kaç yazma işlemi ve yazma-sonrası-okuma adımı olduğunu sayın.
- Her adım için koordinasyon gerektiğinde bir bölge arası RTT varsayın. Bölge arası RTT 80–120 ms ise, iki ardışık yazma adımı uygulama zamanına 160–240 ms ekleyebilir.
Bu, “yapmayın” demek değil; ama yolculukları ardışık yazmalardan kaçınacak şekilde tasarlamak (batch, idempotent retry, daha az chatty transaction) gerekir.
Karmaşıklık vs daha basit alternatifler
Kullanıcılarınız çoğunlukla bir bölgede ise, tek bölgeli Postgres iyi replika, güçlü yedekleme ve test edilmiş failover planı ile daha ucuz ve daha basit olabilir—ve hızlıdır.
Dağıtık SQL, gerçekten çok bölgeli yazmalar, sıkı RPO/RTO veya yerleşim farkındalığı gerektiğinde maliyeti haklı çıkarır.
Basit bir ROI çerçevesi
Harcamayı şu şekilde değerlendirin:
- Kaçınan risk: gelir etkileyici kesintiler, veri kaybı riski, küresel olay hafta sonları.
- Korunan gelir: bölgesel kullanıcılar için daha düşük gecikme nedeniyle daha yüksek dönüşüm, daha güçlü kurumsal duruş (SLA, uyumluluk).
- Harcamalar: temel küme + replikasyon yükü + trafik + mühendislik zamanı.
Kaçınan kayıp (kesinti + churn + uyumluluk riski) süreklilik primi üzerindeyse, çok bölgeli tasarım haklıdır. Değilse, daha basit başla ve evrimleşme yolu bırakın.
Benimseme Kontrol Listesi ve Sonraki Adımlar
Dağıtık SQL’e geçiş “veritabanını taşımak”tan ziyade verinin ve konsensüsün düğümler (ve muhtemelen bölgeler) arasında dağıldığında iş yükünüzün iyi davrandığını kanıtlamakla ilgilidir. Hafif bir plan sürprizleri önler.
Odaklı bir PoC (proof-of-concept)
Gerçek acıyı temsil eden bir iş yükü seçin: örn. checkout/booking, hesap oluşturma, defter kaydı.
Başarı metriklerini baştan tanımlayın:
- Doğruluk: çift rezervasyon yok, kaybolan güncellemeler yok, öngörülebilir işlem davranışı
- Gecikme SLO’ları: en önemli 3 sorgu için p50/p95 (bölgeseler arası hedefleri dahil edin)
- Verim: doruk QPS ve bir güven payı (genelde 2–3×)
- Dayanıklılık: düğüm kaybında ve (varsa) bölge kaybında davranış
- Operasyonel çaba: simüle edilmiş bir olayı tespit, tanı ve kurtarma süresi
PoC aşamasında daha hızlı ilerlemek isterseniz, sentetik benchmark’lar yerine küçük bir gerçekçi uygulama yüzeyi (API + UI) oluşturmak yardımcı olur. Örneğin ekipler bazen Koder.ai kullanarak chat ile React + Go + PostgreSQL başlangıç uygulaması açıp, sonra veritabanı katmanını CockroachDB/YugabyteDB ile değiştirerek işlem desenlerini, retry’leri ve hata davranışını uçtan uca test ederler. Amaç starter stack değil—fikri “ölçülebilir iş yüküne” dönüştürme süresini kısaltmaktır.
Tasarım kontrol listesi (sonradan canınızı yakacak şeyler)
- Şema: yazmaları dağıtacak primer anahtarlar seçin; ardışık “sıcak” anahtarlardan kaçının
- İndeksler: sadece gerekli olanları tutun; ikincil indekslerin yazma amplifikasyonunu anlayın
- Partitioning/placement: erişim desenlerine göre partition anahtarları ve bölge/zone kuralları belirleyin
- Hot spot’lar: “ünlü satırlar”ı (küresel counter, tek kiracı tabloları) erken tespit edip yeniden tasarlayın
- Migration’lar: çevrimiçi şema değişiklikleri ve backfill yollarını planlayın; rollback senaryolarını test edin
Operasyonel temel öğeler (gün birinde olması gerekenler)
İzleme ve çalışma kitapları SQL kadar önemlidir:
- Gecikme, retry, contention, replikasyon/konsensüs sağlığı, disk ve compaction’lar için panolar
- Olay prosedürleri: yavaş sorgular, düğüm yeniden başlatma, başarısız replika, dengesiz yük
- Üretime benzer yük testleri (okuma/yazma karışımı, patlamalar, uzun işlemler)
- Yedekler + geri yükme tatbikatları (gerekiyorsa point-in-time recovery)
Sonraki adımlar
Bir PoC sprinti başlatın, sonra üretime hazır olma incelemesi ve kademeli geçiş (mümkünse çift yazma veya gölge okuma) için zaman ayırın.
Eğer PoC bulgularınızı, mimari takaslarınızı veya geçiş derslerinizi belgelerseniz, bunları ekibinizle (ve mümkünse kamuya) paylaşın: Koder.ai gibi platformlar eğitim içeriği oluşturduğunuzda kredi kazanma veya başkalarını yönlendirme gibi yollar sunabilir—bu da değerlendirme maliyetlerini azaltabilir.