07 Ağu 2025·8 dk
Dağıtık Veritabanları: Tutarlılığı Erişilebilirlikle Takas Etmek
Dağıtık veritabanlarının neden çoğu zaman tutarlılığı gevşetip erişilebilirliği koruduğunu, CAP ve quorum mantığını ve hangi yaklaşımı ne zaman seçmeniz gerektiğini öğrenin.
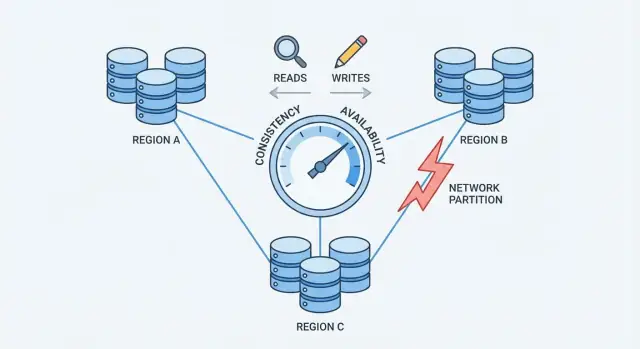
Tutarlılık ve Erişilebilirlik Gerçekte Ne Anlatıyor
Bir veritabanı birden çok makineye (replikalara) bölündüğünde hız ve dayanıklılık elde edersiniz—ama aynı zamanda bu makinelerin her zaman tam olarak aynı fikirde olmadığı veya güvenilir şekilde iletişim kuramadığı dönemler ortaya çıkar.
Tutarlılık (basit anlamı)
Tutarlılık demek: başarılı bir yazmadan sonra herkes aynı değeri okur. Profil e-posta adresinizi güncellerseniz, sonraki okuma—hangi replika cevap verirse versin—yeni e-posta adresini döndürür.
Pratikte, tutarlılığı öncelikleyen sistemler arızalar sırasında bazı istekleri geciktirebilir veya reddedebilir ki çelişkili cevaplar dönülmesin.
Erişilebilirlik (basit anlamı)
Erişilebilirlik demek: sistem her isteğe yanıt verir, bazı sunucular kapalı veya bağlantısız olsa bile. Aldığınız cevap en güncel veri olmayabilir ama bir cevap alırsınız.
Pratikte, erişilebilirliği öncelikleyen sistemler replikalar anlaşmazlık içindeyken bile yazmaları kabul edip okumaları cevaplayabilir ve farkları sonra uzlaştırır.
Bu ödün gerçek uygulamalar için ne demek
Bir ödün şu demektir: her hata senaryosunda her iki hedefi de aynı anda en üst düzeye çıkaramazsınız. Replikalar koordine olamıyorsa veritabanı ya:\n
- Tek bir, üzerinde anlaşılmış gerçeği korumak için bazı istekleri bekletir/başarısız kılar (tutarlılığı tercih eder), ya da\n- Kullanıcılara cevap vermeye devam eder, ama bu eski veya çelişkili verilerle sonuçlanma riski taşır (erişilebilirliği tercih eder)
Basit bir örnek: alışveriş sepeti vs banka havalesi
- Alışveriş sepeti: Sepet sayınız başka bir cihazda kısa süreliğine 1 eksik görünüyorsa bu can sıkıcı ama genellikle kabul edilebilir. Birçok ekip daha yüksek erişilebilirliği tercih edip sonra eşleştirir.
- Banka havalesi: 500$ transfer ettiğinizde bakiyenizin geçici olarak iki farklı gösterim göstermesi ciddi bir sorundur. Burada, zaman zaman "lütfen tekrar deneyin" hatası yaşatmak güçlü tutarlılık için genellikle göze alınır.
Tek doğru seçim yok
Doğru denge, hangi hataları tolere edebileceğinize bağlıdır: kısa bir kesinti mi yoksa kısa süreli yanlış/eski veri mi. Çoğu gerçek sistem arada bir nokta seçer ve bu ödünü açıkça belirtir.
Neden Dağıtım Kuralları Değiştirir
Bir veritabanı, veriyi birden çok makinede (düğümlerde) sakladığında ve hizmet verdiğinde “dağıtık” olur. Uygulama için hâlâ tek bir veritabanı gibi görünebilir—ama altyapıda istekler farklı düğümler tarafından, farklı yerlerde işlenebilir.
Replikasyon: ekiplerin düğüm ekleme nedeni
Çoğu dağıtık veritabanı veriyi çoğaltır: aynı kayıt birden çok düğümde saklanır. Bu yüzden ekipler bunu yapar ki:
- bir makine bozulduğunda hizmet devam etsin
- kullanıcılara yakın bir düğümden hizmet verip gecikmeyi düşürsün
- okumaları (ve bazen yazmaları) daha fazla donanım üzerinde ölçeklendirsin
Replikasyon güçlüdür, ama hemen bir soru getirir: iki düğüm aynı verinin bir kopyasına sahipse, onların her zaman aynı fikirde olduklarını nasıl garanti edersiniz?
Kısmi arıza normaldir, istisna değil
Tek bir sunucuda “kapalı” genelde açıktır: makine çalışır ya da çalışmaz. Dağıtık bir sistemde arıza genellikle kısmi olur. Bir düğüm canlı ama yavaş olabilir. Bir ağ bağlantısı paket kaybedebilir. Bir rafın tamamı bağlantısını kaybedebilirken kümenin geri kalanı çalışmaya devam edebilir.
Bu önemlidir çünkü düğümler diğerinin gerçekten kapalı mı, geçici olarak ulaşılamaz mı yoksa sadece gecikmiş mi olduğunu anında bilemez. Ne olup bittiğini anlamaya çalışırken gelen okuma ve yazma istekleriyle ne yapacaklarına karar vermeleri gerekir.
İletişim garantisi yoksa garantiler değişir
Tek sunucuda bir kaynak gerçekliktir: her okuma en son başarılı yazıyı görür.
Birden çok düğümde “en son” koordinasyona bağlıdır. Eğer bir yazma Node A'da başarılı oldu ama Node B'ye ulaşılamıyorsa, veritabanı şunu yapmalı mı:
- Yazmayı B onaylayana kadar bloklayıp beklemeli mi (tutarlılığı korumak için), yoksa
- Yazmayı yine de kabul etmeli mi (erişilebilirliği korumak için)?
Bu gerilim—kusurlu ağlarla gerçek hale gelen—dağıtımın kuralları değiştirmesinin nedenidir.
Ağ Bölünmeleri: İşin Özeti
Bir ağ bölünmesi, birlikte bir veritabanı gibi çalışması gereken düğümler arasındaki iletişimin kırılmasıdır. Düğümler hâlâ çalışıyor ve sağlıklı olabilir, ancak bir anahtarın arızalanması, aşırı yüklü bir bağlantı, yanlış yönlendirme değişikliği, hatalı bir güvenlik duvarı kuralı veya bulut ağında gürültülü bir komşu gibi sebeplerle mesajlar güvenilir şekilde geçemez.
Ölçeklenince bölünmeler neden kaçınılmazdır
Sistem birkaç makineye (genellikle raflara, bölgelere veya bölgelere) yayıldığında artık aralarındaki her hopu kontrol edemezsiniz. Ağlar paket düşürür, gecikme ekler ve bazen “ada”lara bölünür. Küçük ölçekte bu olaylar nadir olur; büyük ölçekte rutinleşir. Kısa bir kesinti bile önemlidir, çünkü veritabanlarının olup biteni kabul etmesi ve üzerinde anlaşması için sürekli koordinasyona ihtiyacı vardır.
Bölünmeler “en son” veriyi nasıl çelişkili hale getirir
Bir bölünme sırasında her iki taraf da istek almaya devam eder. Kullanıcılar her iki tarafta da yazabiliyorsa, her taraf diğerinin görmediği güncellemeleri kabul edebilir.
Örnek: Node A bir kullanıcının adresini “Yeni Sokak” olarak günceller. Aynı anda Node B adresi “Eski Sokak Apt 2” olarak günceller. Her taraf kendi yazmasının en güncel olduğuna inanır—çünkü gerçek zamanlı olarak notları karşılaştıramazlar.
Kullanıcıya görünen semptomlar
Bölünmeler temiz hata mesajları olarak değil, kafa karıştırıcı davranışlar olarak ortaya çıkar:
- Zaman aşımı: veritabanı bir yazma veya okuma için başka bir düğümün onayını bekler.\n- Eski okumalar: yenileme yaptığınızda hâlâ eski veriyi görürsünüz çünkü güncellemeyi kaçırmış bir replika ile karşılaştınız.\n- Split-brain davranışı: hangi tarafa ulaştığınıza bağlı olarak farklı kullanıcılar farklı “gerçeklikleri” görür.
Bu, baskı noktasıdır: ağ iletişimini garanti edemediğinde dağıtık veritabanı tutarlılığı mı yoksa erişilebilirliği mi önceliklendireceğine karar vermelidir.
Teknik Jargonu Olmadan CAP Teoremi
CAP, bir veritabanı birden çok makineye yayıldığında ne olacağını özetleyen kısa bir yoldur.
Üç terim (düz İngilizce/Türkçe)
- Tutarlılık (C): yazdıktan sonra, sonraki herhangi bir okuma o aynı değeri döner.\n- Erişilebilirlik (A): bazı sunucular sorun yaşasa bile her isteğe hata olmayan bir cevap döner.\n- Bölünme toleransı (P): ağ ayrıldığında ve sunucular güvenilir şekilde konuşamadığında sistem çalışmaya devam eder.
Temel çıkarım
Bölünme yokken, birçok sistem hem tutarlı hem erişilebilir gibi davranabilir.
Bölünme olduğunda, neyi önceliklendireceğinize karar vermeniz gerekir:
- Tutarlılığı seçin: sunucular anlaşana kadar bazı istekleri reddedin veya geciktirin.\n- Erişilebilirliği seçin: her iki tarafta da istekleri kabul edin; cevaplar geçici olarak uyuşmayabilir.
Görselleştirebileceğiniz basit bir zaman çizelgesi
- 10:00 İstemci
balance = 100yazmasını Server A'ya gönderir.\n- 10:01 Ağ bölünmesi: Server A Server B'ye ulaşamaz.\n- 10:02 İstemci Server B'den okuma yapar.\n - Eğer Tutarlılığı önceliklendirirseniz, Server B ya reddetmeli ya da beklemeli.\n - Eğer Erişilebilirliği önceliklendirirseniz, Server B cevap verir amabalance = 80gibi eski bir değeri dönebilir.
Yaygın yanlış anlama
CAP, kalıcı bir “sürekli olarak sadece iki tanesini seç” kuralı değildir. Anlamı şudur: bölünme sırasında, hem Tutarlılık hem de Erişilebilirlik aynı anda garanti edilemez. Bölünme dışında, çoğu sistem çoğu zaman her iki garantiye de yakın davranabilir—ta ki ağ yanlış davranana kadar.
Tutarlılığı Seçmek: Kazanımlar ve Kayıplar
Tutarlılığı seçmek, veritabanının “herkes aynı gerçeği görsün” ilkesini “her zaman cevap ver” önceliğinin üstünde tutması demektir. Pratikte bu genellikle güçlü tutarlılık (linearizable) davranışa işaret eder: bir yazma onaylandığında, daha sonraki herhangi bir okuma (herhangi bir yerden) o değeri döner, sanki tek bir güncel kopya varmış gibi.
Bölünme sırasında ne olur
Ağ bölünmesi olduğunda ve replikalar güvenilir şekilde konuşamadığında, güçlü tutarlı bir sistem bağımsız güncellemeleri her iki tarafta da güvenli şekilde kabul edemez. Doğruluğu korumak için genelde:
- İstekleri engeller ya da koordinasyon bekler, ya da\n- İstekleri reddeder (hata/zaman aşımı döner) eğer gereken replikalara/lidere ulaşılamıyorsa.
Kullanıcı perspektifinden bu, bazı makineler hâlâ çalışıyor olsa bile bir kesinti gibi görünebilir.
Ne kazanırsınız
Ana fayda düşünmeyi sadeleştirir. Uygulama kodu sanki tek bir veritabanıyla konuşuyormuş gibi davranabilir; replikalar arasında çelişkiler olacağı korkusu azalır. Bu, şu gibi tuhaf durumları azaltır:
- Başarılı bir güncellemeden hemen sonra daha eski veri okumak\n- Hangi replikaya denk geldiğinize göre aynı kaydın iki farklı değeri görünmesi\n- Eşzamanlı çakışan yazılardan dolayı invariantların kaybı (ör. fazla satış)
Ayrıca faturalama, denetim ve ilk seferde doğru olması gereken her şey için daha temiz zihinsel modeller elde edersiniz.
Ne kaybedersiniz
Tutarlılığın gerçek maliyetleri vardır:
- Daha yüksek gecikme: birçok işlem koordinasyon (çoğunlukla makineler veya bölgeler arası) için beklemek zorunda kalır.\n- Arızalar sırasında daha fazla hata: bölünmeler, yavaş replikalar veya lider sorunları zaman aşımına veya “sonra tekrar deneyin” hatalarına dönüşebilir.
Ürününüz kısmi kesintiler sırasında başarısız istekleri tolere edemezse, güçlü tutarlılık pahalı gelebilir—ancak doğruluk için doğru seçim olabilir.
Erişilebilirliği Seçmek: Kazanımlar ve Kayıplar
Bölünmeleri basitçe simüle edin
Bölünmeleri, eski okumaları ve çatışmaları göstermek için minimal bir replika simülasyonu oluşturun.
Erişilebilirliği seçmek, basit bir vaadi optimize etmek demektir: sistem yanıt verir, altyapının bir kısım sağlıksız olsa bile. Pratikte “yüksek erişilebilirlik” hiç hata olmayacağı anlamına gelmez—anlamı, düğüm hataları, aşırı yüklenmiş replikalar veya bozuk ağ bağlantıları sırasında çoğu isteğin yine de yanıt aldığıdır.
Ağ bölünmesi sırasında ne olur
Ağ ayrıldığında replikalar güvenilir şekilde konuşamaz. Erişilebilirliğe öncelik veren bir veritabanı genellikle ulaşılabilir taraftan hizmet vermeye devam eder:
- Okumalar mevcut replikadan yerel olarak cevaplanır.\n- Yazmalar yerelde kabul edilir ve bağlantı geri geldiğinde sıraya alınıp çoğaltılır.
Bu uygulamaları hareket halinde tutar, ancak farklı replikaların geçici olarak farklı gerçeklikleri kabul etmesine neden olur.
Ne kazanırsınız
Daha iyi çalışır halde kalma süresi elde edersiniz: kullanıcılar hâlâ göz atabilir, sepete ürün ekleyebilir, yorum yapabilir veya olayları kaydedebilir—bir bölge izole olsa bile.
Ayrıca stres altındayken daha yumuşak bir kullanıcı deneyimi elde edersiniz. Zaman aşımı yerine uygulamanız “güncellemeniz kaydedildi” gibi davranıp sonra senkronize edebilir. Birçok tüketici ve analiz iş yükü için bu ödün değer.
Ne kaybedersiniz
Fiyatı, veritabanının eski okumalar döndürebilme olasılığıdır. Bir kullanıcı bir replikada profilini güncelleyip hemen başka bir replikadan okursa eski değeri görebilir.
Ayrıca yazma çatışmaları riski vardır. İki kullanıcı (veya aynı kullanıcı iki konumdan) aynı kaydı farklı tarafta güncelleyebilir. Bölünme iyileştiğinde sistem farklı geçmişleri uzlaştırmalıdır. Kurallara göre bir yazı “kazanabilir”, alanlar birleştirilebilir veya çatışma uygulama mantığı gerektirebilir.
Erişilebilirlik odaklı tasarım, geçici anlaşmazlığı kabul edip daha sonra onu tespit edip onarma üzerine yatırım yapmaktır.
Quorumlar ve Oylama: Orta Yol
Quorumlar, çoğaltılmış veritabanlarının tutarlılık ile erişilebilirlik arasında denge kurmak için kullandığı pratik bir “oylama” tekniğidir. Sisteme tek bir replika yerine yeterli replikanın katılımı istenir.
(N, R, W) fikri
Quorumlar genellikle üç sayı ile anlatılır:
- N: bir veri parçası için kaç replika var\n- W: bir yazmanın başarılı sayılması için kaç replikanın onay vermesi gerekiyor\n- R: bir okuma için kaç replikayla kontrol ediliyor
Basit bir kural: R + W > N ise her okuma en az bir replika üzerinden en son başarılı yazıyla kesişir; bu da eski veri okuma şansını azaltır.
Sezgisel örnekler
Eğer N=3 replika varsa:
- Tek replika yaklaşımı (R=1, W=1): Hızlı ve çok erişilebilir, ama kolayca eski bir replika okunabilir.\n- Çoğunluk oylaması (R=2, W=2): Bir yazının başarılı sayılması için 2 replikanın ulaşması gerekir ve bir okuma 2 replika ile kontrol edilir. Bu, okuma ile yazma kümelerinin örtüşme olasılığını artırarak en yeni değeri görme ihtimalini yükseltir.
Bazı sistemler daha güçlü tutarlılık için W=3 (tüm replikalar) seçer; ancak bu herhangi bir replika yavaş veya kapalıysa daha fazla yazma hatasına yol açabilir.
Bölünmeler sırasında quorumlar ne yapar
Quorumlar bölünme sorunlarını ortadan kaldırmaz—ama ilerleme yapan tarafı tanımlar. Eğer ağ 2–1 şeklinde bölünürse, 2 replikanın olduğu taraf R=2 ve W=2 şartlarını sağlayabilirken izole tek replika sağlayamaz. Bu çakışan güncellemeleri azaltır, ama bazı istemcilerin hata veya zaman aşımı görmesi anlamına gelir.
Ödünler
Quorumlar genelde daha yüksek gecikme (daha fazla düğüme dokunma), daha yüksek maliyet (düğüm arası trafik) ve daha nüanslı hata davranışı (zaman aşımının kullanılabilirlik kaybı gibi görünmesi) demektir. Faydası ise ayarlanabilir bir orta yol olmasıdır: R ve W değerlerini daha taze okumalar veya daha yüksek yazma başarısı lehine ayarlayabilirsiniz.
Nihai Tutarlılık ve Yaygın Anormallikler
Nihai tutarlılık, replikaların geçici olarak senkron olmayabileceğini, ancak sonunda aynı değere yakınsaması gerektiğini kabul eder.
Somut bir benzetme
Bir zincir kahveci mağazası ortak bir “tükendi” tabelasını güncelliyor gibi düşünün. Bir mağaza tükendi diye işaretler ama bu güncelleme diğer mağazalara birkaç dakika sonra ulaşır. O pencere boyunca başka bir mağaza hâlâ “var” gösterip sonuncuyu satabilir. Sistemde bir bozukluk yok—güncellemeler sadece yetişiyor.
Görülen yaygın anomaliler
Veriler henüz yayılırken istemciler şu davranışları görebilir:
- Eski okumalar: henüz son yazıyı almamış bir replika eski veri döner.\n- Kendi yazını okuma boşlukları: bir güncelleme yaptıktan sonra hemen başka bir replikadan okuduğunuzda kendi değişikliğinizi görmeyebilirsiniz.\n- Sıradışı güncellemeler: iki güncelleme farklı replikalarda farklı sıralarla gelirse kısa süreli tutarsızlık oluşur.
Replikaların yakınsamasına yardımcı teknikler
Nihai tutarlılık sistemleri genelde tutarsızlık penceresini azaltmak için arka plan mekanizmaları ekler:
- Read repair: bir okuma farklı replikalarda uyuşmazlık algılarsa eski replikaları arka planda günceller.\n- Hinted handoff: bir replika kapalıysa başka bir düğüm yazma “ipuçlarını” geçici tutar ve geri geldiğinde iletir.\n- Anti-entropy (senkronizasyon): merkle ağaçları veya checksum'larla periyodik uzlaşma yaparak sürüklenmeyi düzeltir.
Nihai tutarlılık ne zaman iyi çalışır
Erişilebilirliğin tutarlı olmaktan daha önemli olduğu durumlarda iyidir: etkinlik akışları, görüntüleme sayaçları, öneriler, önbelleğe alınmış profiller, günlükler/telemetri ve “birkaç saniye içinde doğru olacak” verilerin yeterli olduğu diğer kritik olmayan veriler.
Çatışma Çözümü: Farklı Yazılar Nasıl Uzlaştırılır
CAP tercihlerini hızla prototipleyin
Sohbet içinde küçük bir dağıtık iş akışı oluşturun ve tutarlılık seçimlerinin davranışı nasıl etkilediğini görün.
Bir veritabanı birden fazla replikada yazmaları kabul edince, bölünme sırasında aynı öğeye bağımsız olarak yapılmış iki veya daha fazla güncelleme ile çatışmalar ortaya çıkabilir.
Klasik örnek: bir kullanıcı bir cihazında gönderim adresini değiştirirken diğer cihazında telefon numarasını değiştiriyor. Her güncelleme farklı replika üzerinde kabul edildiyse, replikalar veri alışverişi yaptığında sistem “gerçek” kaydı nasıl belirleyecek?
Son yazan kazanır (LWW): basit ama riskli
Birçok sistem last-write-wins ile başlar: en yeni zaman damgasına sahip olan güncelleme diğerlerini geçersiz kılar.
Uygulaması kolay ve hesaplaması hızlı olduğu için caziptir. Dezavantajı, veri kaybına yol açabilmesidir. “En yeni” olan kazanırsa, daha eski ama önemli bir değişiklik sessizce silinebilir—özellikle iki güncelleme farklı alanlara dokunduysa bile.
Ayrıca zaman damgalarının güvenilir olduğu varsayılır. Makine/istemci saatleri arasında kayma (clock skew) yanlış güncellemenin kazanmasına sebep olabilir.
Geçmişi tutmak: versiyon vektörleri ve benzerleri
Daha güvenli çatışma işleme genellikle nedensel geçmişi izlemeyi gerektirir.
Kavramsal olarak, versiyon vektörleri (ve daha basit varyantları) her kayda hangi replikaların hangi güncellemeleri gördüğünü özetleyen küçük bir metadata eki ekler. Replikalar versiyonları değiş tokuş ettiğinde, bir versiyonun diğerini içerip içermediğini (çatışma yok) veya ayrıştığını (çatışma var) algılayabilir.
Bazı sistemler, gerçek zaman saatine bağımlılığı azaltmak ama yine de sıralama ipucu sağlamak için Lamport saatleri veya hibrit mantıksal saatler kullanır.
Üzerine yazmak yerine birleştirmek
Çatışma tespit edildiğinde seçenekleriniz vardır:
- Uygulama düzeyinde birleştirmeler: uygulamanız alanları nasıl birleştireceğine, kullanıcıyı nasıl uyarmasına veya her iki versiyonu da saklamasına karar verir.\n- CRDT'ler (Conflict-Free Replicated Data Types): otomatik ve deterministik olarak birleşmeye uygun veri yapıları (sayıcılar, kümeler, işbirlikçi metin vb.) sağlar. Bunlar genellikle “kazanan-bir-olsun” davranışından kaçınırken yüksek erişilebilirliği korur.
En iyi yaklaşım, veriniz için “doğru”nun ne anlama geldiğine bağlıdır—bazen bir yazının kaybolması kabul edilebilir, bazen bu iş açısından kritik bir hata olur.
Kullanım Durumunuza Nasıl Karar Verilir
Tutarlılık/erişilebilirlik duruşunu seçmek felsefi değil, ürün odaklı bir karardır. Önce şu soruyu sorun: kısa süreli yanlış bir sonuç ne kadar maliyetli, ve "lütfen tekrar deneyin" demek ne kadar maliyetli?
İş riskini tutarlılık ihtiyaçlarına eşleyin
Bazı alanlar yazma anında tek ve otoriter bir cevaba ihtiyaç duyar çünkü “neredeyse doğru” bile yanlış sayılır:
- Para ve faturalama: çift fatura, hesaptan fazla çekme ve iadeler genelde güçlü tutarlılık gerektirir.\n- Kimlik ve izinler: giriş, şifre sıfırlama, erişim kontrolü ve rol değişiklikleri split-brain davranışından kaçınmalı.\n- Envanter ve kapasite: fazla satış kabul edilemezse (biletler, sınırlı stok), tutarlı olmayı tercih edin veya açık rezervasyon mekanizmaları tasarlayın.
Kısa süreli uyumsuzluğun etkisi düşük veya geri döndürülebilirse, genellikle daha erişilebilir tarafa eğilebilirsiniz.
Ne kadar eski veriyi tolere edebileceğinizi belirleyin
Pek çok kullanıcı deneyimi biraz eski okumayla çalışır:
- Akışlar ve zaman çizelgeleri: bir gönderinin birkaç saniye gecikmesi genelde kabul edilebilir.\n- Analitik ve panolar: toplu veya gecikmeli sayılar yaygındır.\n- Önbellekler ve arama dizinleri: kullanıcılar "henüz güncellenmedi" halini kabul eder ama hızlı ve kararlı olmasını bekler.
Açıkça belirtin ne kadar eskime kabul edilebilir: saniyeler, dakikalar veya saatler. Bu zaman bütçesi replikasyon ve quorum seçimlerinizi yönlendirir.
Kullanıcıların en az nefret edeceği hata modunu seçin
Replikalar anlaşamazsa genellikle üç UX sonucu ortaya çıkar:
- Dönme / bekleme (doğruluğu önceliklendirir, yavaş hissedilir)\n- Hata / tekrar deneme (dürüst ama kesintiye uğratıcı)\n- Eski sonuç (akıcı ama bazen şaşırtıcı)
Özelliğe göre en az zararlı olanı seçin; bu kararı tüm sisteme genelleştirmeyin.
Hızlı kontrol listesi
C (tutarlılık) eğilimi gösterin eğer: yanlış sonuçlar finansal/kanuni risk, güvenlik sorunları veya geri döndürülemez işlemler yaratıyorsa.\n A (erişilebilirlik) eğilimi gösterin eğer: kullanıcılar hız ve yanıt almayı tercih ediyor, eski veri tolere edilebilir ve çatışmalar sonradan güvenli şekilde çözülebiliyorsa.
Şüphede kaldığınızda sistemi bölün: kritik kayıtları güçlü tutarlı tutun, türetilmiş görünümler (akışlar, önbellekler, analizler) için erişilebilirliği önceliklendirin.
Ödünü Azaltmak için Tasarım Desenleri
Okuma ve yazma modlarını test edin
Sıkı yazmalar ve gevşek okumaları test etmek için bir React uygulaması ve Go API başlatın.
Tüm sistem için tek bir “tutarlılık ayarı” seçmek zorunda değilsiniz. Modern dağıtık veritabanlarının çoğu işlem başına tutarlılık seçmenize izin verir—ve akıllı uygulamalar bunu kullanarak kullanıcı deneyimini düz tutup ödün gerçeğini gizlemez.
İşlem başına tutarlılık seviyelerini kullanın
Tutarlılığı kullanıcı eylemine göre bir düğme gibi düşünün:
- Kritik güncellemeler (ödemeler, stok azaltmaları, şifre değişiklikleri): daha güçlü tutarlılık (ör. quorum/linearizable yazmalar).\n- Kritik olmayan okumalar (akışlar, panolar, “son görülme”): hız ve dayanıklılık için zayıf okumalara izin verin.
Böylece her şey için en güçlü maliyeti ödemek zorunda kalmazsınız; gerçekten gerekli işlemleri korumuş olursunuz.
Aynı akışta güçlü ve zayıfı karıştırın
Yaygın bir desen: yazmalarda güçlü, okumalarda zayıf:
- Yazmayı katı bir seviyede yapın ki sistem otoriter kaydı tutsun.\n- Okumayı gevşek düzeyde yapın; bir şeyin eksik olduğunu fark ederseniz güçlü bir okuma ile yenileyin veya “hala güncelleniyor” uyarısı gösterin.
Bazı durumlarda tersine de çalışır: hızlı yazmalar (sıraya alınmış/nihai) artı güçlü okumalar ile sonucu onaylamak (“Siparişim verildi mi?”).
Tekrarlar için tasarlayın: idempotentlik
Ağlar sallandığında istemciler tekrar dener. Tekrarları güvenli kılmak için idempotency anahtarları kullanın ki “siparişi gönder” iki kez çalıştırılsa iki sipariş oluşmasın. Aynı anahtar tekrar görüldüğünde ilk sonucu saklayın ve yeniden döndürün.
Uzun iş akışları: sagalar ve telafi
Hizmetler arası çok adımlı işlemler için saga kullanın: her adımın bir telafi edici işlemi (iade, rezervasyonu serbest bırakma, gönderimi iptal etme) olsun. Bu, parçalar geçici olarak uyumsuz veya başarısız olduğunda sistemi kurtarılabilir tutar.
Tutarlılık vs Erişilebilirlik için Test ve Gözlemlenebilirlik
Tutarlılık/erişilebilirlik ödününü yönetemezsiniz eğer onu göremezseniz. Üretim problemleri genellikle “rastgele hatalar” gibi görünür; doğru ölçümler ve testler ekleyene kadar.
Ölçülecekler (ve neden)
Kullanıcı etkisine doğrudan bağlanan küçük bir metrik setiyle başlayın:
- Gecikme (p50/p95/p99): failover, lider değişimi veya quorum tekrar denemeleri sırasında sıçramaları izleyin.\n- Hata oranı: “sert” hataları (zaman aşımı, 5xx) “yumuşak” hatalardan (geri dönüşte fallback, kısmi sonuçlar) ayırın.\n- Eski okuma oranı: hedeflediğiniz eskime penceresinden (ör. 2 saniyeden daha eski) dönülen okumaların yüzdesi.\n- Çatışma oranı: eşzamanlı yazmaların ne sıklıkla uzlaştırma gerektirdiği (LWW üzerine yazmalar dahil).
Mümkünse metrikleri tutarlılık modu (quorum vs lokal) ve bölge/zon ile etiketleyin ki davranışın nerede farklılaştığını görün.
Bölünmeleri bilerek test edin
Gerçek kesintiyi beklemeyin. Staging'de kaos deneyleri yapın:
- replika arası paket düşürme ve yüksek gecikme\n- bir bölgenin ulaşılamaz olması\n- sadece bazı düğümlerin konuşabildiği kısmi bölünmeler
Sadece “sistem ayakta kalıyor”u doğrulamakla kalmayın; hangi garantilerin korunduğunu da doğrulayın: okumalar taze mi kalıyor, yazmalar bloklanıyor mu, istemciler net hatalar mı alıyor?
Erken yakalayan uyarılar
Şunlar için uyarılar ekleyin:\n
- replike gecikmesi tolerans pencerenizi aşıyorsa\n- quorum hataları (yeterli replika sağlanamıyor) ve artan tekrar deneme sayıları\n- artan yazma çatışmaları veya uzlaşma birikimi
Son olarak, garantileri açıkça dokümante edin: sisteminizin normal durumda ve bölünme sırasında ne vaat ettiğini yazın; ürün ve destek ekiplerini kullanıcının neler görebileceği ve nasıl yanıt verecekleri konusunda eğitin.
CAP Seçimlerini Hızlıca Prototipleme (Her Şeyi Yeniden İnşa Etmeden)
Yeni bir ürün üzerinde çalışıyorsanız, özellikle hata modları, tekrar davranışı ve "eski"nin UI'da nasıl gözüktüğünü erken doğrulamak faydalıdır.
Pratik bir yaklaşım, iş akışının (yazma yolu, okuma yolu, tekrar/idempotentlik ve bir uzlaşma işi) küçük bir versiyonunu prototiplemektir. Koder.ai ile ekipler sohbet odaklı bir iş akışı üzerinden web uygulamaları ve backend'ler hızlıca ayağa kaldırabilir, veri modelleri ve API'ler üzerinde hızlıca yineleyebilir ve farklı tutarlılık desenlerini (örneğin sıkı yazmalar + gevşek okumalar) geleneksel bir derleme hattının yükü olmadan test edebilir. Prototip istenen davranışla eşleştiğinde kaynak kodu dışa aktarabilir ve üretime doğru evriltmeye başlayabilirsiniz.
SSS
Neden dağıtık veritabanları tutarlılık ile erişilebilirlik arasında bir ödün veriyor?
Bir çoğaltılmış veritabanında aynı veri birden fazla makinede yaşar. Bu dayanıklılığı ve gecikme düşürmeyi artırır ama koordinasyon sorunlarını da beraberinde getirir: düğümler yavaşlayabilir, ulaşılamaz olabilir veya ağ tarafından bölünebilir; dolayısıyla her zaman en son yazıyı anında eşleştiremezler.
“Tutarlılık” basitçe ne anlama geliyor?
Tutarlılık şöyle demektir: başarılı bir yazmadan sonra, sonraki herhangi bir okuma aynı değeri döner—hangi replika olursa olsun. Pratikte sistemler bunu sağlamak için okumaları/yazmaları yeterli replika (veya lider) onayı gelene kadar geciktirir veya reddeder.
“Erişilebilirlik” basitçe ne anlama geliyor?
Erişilebilirlik şu anlama gelir: bazı düğümler kapalı olsa veya iletişim kuramasa bile sistem her isteğe bir hata olmayan yanıt döner. Yanıt güncel olmayabilir veya yerel bilgiye dayanabilir ama sistem kullanıcıları bloklamaktan kaçınır.
Ağ bölünmesi nedir ve neden bu kadar önemli?
Ağ bölünmesi, tek sistem gibi davranması gereken düğümler arasındaki iletişimin kopmasıdır. Düğümler hâlâ sağlıklı olabilir; ancak mesajlar güvenilir şekilde geçemez. Bu durum veritabanını şu seçeneklerden birini seçmeye zorlar:
- tek bir gerçekliği korumak için istekleri engellemek/reddetmek (tutarlılık), veya
- her iki tarafta da isteklere cevap verip daha sonra uzlaşmak (erişilebilirlik).
Kullanıcılar bölünme veya replika uyumsuzluğu sırasında gerçekte ne yaşar?
Bir bölünme sırasında her iki taraf da güncellemeleri kabul edebilir; bunlar hemen paylaşılmaz. Bunun sonucunda görülenler şunlardır:
- Zaman aşımı: ulaşılmayan replika için bekleme
- Eski okumalar: geride kalmış bir replika eski veriyi döner
- Split-brain davranışı: hangi tarafa ulaştığınıza göre kullanıcıların farklı “gerçeklikleri” görmesi
Bunlar, replika koordinasyonu geçici olarak sağlayamadığında kullanıcıların deneyimlediği sonuçlardır.
CAP teoremi gerçekten üçünden sadece ikisini seçebileceğimizi mi söylüyor?
Hayır, CAP "kalıcı olarak sadece iki tanesini seç" demek değildir. Anlamı şudur: bir bölünme olduğunda hem:
- Tutarlılık (herkes en son onaylanmış yazıyı okur), hem de
- Erişilebilirlik (her isteğe yanıt verilir)
aynı anda garanti edilemez. Bölünme dışında birçok sistem çoğu zaman her iki özelliğe çok yakın davranabilir—ta ki ağ hatası olana kadar.
Quorumlar (N, R, W) tutarlılık ile erişilebilirlik arasında nasıl yardımcı olur?
Quorumlar, çoğaltılmış veritabanlarının tutarlılık ve erişilebilirlik arasında denge kurmak için kullandığı bir oy verme tekniğidir:
- N = veri için kaç replika olduğu
- W = bir yazının başarılı sayılması için kaç replikadan onay gerektiği
- R = bir okuma için kaç replika sorgulandığı
Yaygın bir kural: ise her okuma en az bir replika üzerinden en son başarılı yazıyla kesişir ve eski veri okuma olasılığını azaltır. Quorumlar bölünmeyi ortadan kaldırmaz; hangi tarafın ilerleyebileceğini tanımlar (ör. çoğunluğu olan taraf).
Nihai tutarlılık (eventual consistency) nedir ve hangi anomalilere hazırlıklı olmalıyım?
Nihai tutarlılık, replikaların geçici olarak senkron olmayabileceğini, ancak zamanla aynı değere yakınsaması gerektiğini kabul eder. Yaygın anomaliler:
- Eski okumalar
- Kendi yazını okuma boşlukları (yazdıktan hemen sonra kendi değişikliğini görmeme)
- Sıradışı/geliş sırası dışı güncellemeler
Bunları hafifletmek için , ve periyodik (merkle ağaçları gibi) gibi mekanizmalar kullanılır.
Bölünme iyileştiğinde çakışan yazılar nasıl uzlaştırılır?
Bölünme iyileştiğinde çatışmalar, farklı replikalarda bağımsız olarak kabul edilmiş farklı yazılar ortaya çıktığında oluşur. Çözüm stratejileri:
- Last-write-wins (LWW): en yeni zaman damgası kazananı geçerli sayar—kolay ama veri kaybına yol açabilir ve saat uyumsuzluğundan etkilenir
- Versiyon vektörleri / nedensel meta: gerçek çatışma ile bir sürümün diğerini içerip içermediğini ayırt etmeye yardımcı olur
- Birleştirme / CRDT'ler: belirli veri tipleri için deterministik otomatik birleşme sağlar
Doğru strateji, veriniz için “doğru”nun ne anlama geldiğine bağlıdır.
Uygulamam için doğru tutarlılık/erişilebilirlik duruşunu nasıl seçerim?
Kararınızı iş riski ve kullanıcıların hangi hatayı tolere edebileceği belirlemeli:
- Güçlü tutarlılığı tercih edin: para, faturalama, kimlik/izinler, stok/kapasite gibi yanlış sonuçların finansal/kanuni hasara yol açtığı durumlarda.
- Erişilebilirliği tercih edin: akışlar, analizler, önbellekler ve gecikmeli düzeltmenin kabul edilebilir olduğu durumlarda.
Pratik desenler: işlem bazında tutarlılık seviyeleri, idempotent tekrarlar, ve çok adımlı işlemler için sagalar ve telafi edici işlemler.