Prototipten SaaS'e: karışıklığın başladığı yer
Bir prototip bir fikri doğrular. Bir SaaS ise gerçek kullanıma dayanmak zorundadır: pik trafik, karmaşık veri, yeniden denemeler ve her aksaklığı fark eden müşteriler. İşler burada karışır; çünkü soru "çalışıyor mu?"dan "çalışmaya devam ediyor mu?"ya döner.
Gerçek kullanıcılarla birlikte "dün çalışıyordu" mazereti sık sık işe yaramaz. Arka plan işi beklenenden daha geç çalışır. Bir müşteri test verinizin 10 katı büyüklüğünde dosya yükler. Bir ödeme sağlayıcı 30 saniye takılır. Bunların hiçbiri egzotik değildir, ama bir sistemin parçaları birbirine bağımlı olduğunda dalga etkileri yükselir.
Çoğu karmaşıklık dört yerde ortaya çıkar: veri (aynı olgu birden fazla yerde var olur ve sapar), gecikme (50 ms çağrılar bazen 5 saniye sürer), hatalar (zaman aşımı, kısmi güncellemeler, yeniden denemeler) ve ekipler (farklı kişiler farklı hizmetleri farklı takvimlerde yayınlar).
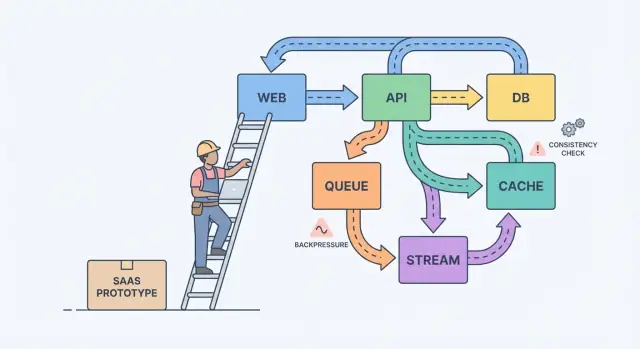
Basit bir zihinsel model yardımcı olur: bileşenler, mesajlar ve durum.
Bileşenler iş yapar (web uygulaması, API, worker, veritabanı). Mesajlar bileşenler arasında işi taşır (istekler, olaylar, işler). Durum hatırladığınız şeydir (siparişler, kullanıcı ayarları, fatura durumu). Ölçeklendirme ağrısı genellikle bir uyumsuzluktur: mesajları bir bileşene onun işleyebileceğinden daha hızlı gönderirsiniz veya durumu iki yerde güncellersiniz ama net bir gerçeğin kaynağı yoktur.
Klasik bir örnek faturalama: Prototip tek istekte bir fatura oluşturup e-posta gönderir ve kullanıcının planını günceller. Yük altında e-posta yavaşlar, istek zaman aşımına uğrar, istemci yeniden dener ve artık iki fatura ve bir plan değişikliğiyle karşılaşırsınız. Güvenilirlik çalışması çoğunlukla bu günlük hataların müşteri gözüne batan hatalara dönüşmesini engellemekle ilgilidir.
Kavramları yazılı kararlara dönüştürün
Çoğu sistem anlaşma olmadan büyüdüğünde zorlaşır: neyin doğru olması gerektiği, neyin hızlı olmasının yeterli olduğu ve bir şey başarısız olduğunda ne olması gerektiği konusunda uzlaşma yoktur.
Kullanıcılara ne vaat ettiğinizin etrafına bir sınır çizin. O sınırın içinde her seferinde doğru olması gereken eylemleri adlandırın (para hareketleri, erişim kontrolü, hesap sahipliği). Sonra "sonunda doğru" olmasının yeterli olduğu alanları adlandırın (analitik sayıları, arama indeksleri, öneriler). Bu ayrım bulanık teoriyi önceliklere dönüştürür.
Sonra kaynağınızı (source of truth) yazın. Orası olguların bir kez, kalıcı olarak, açık kurallarla kaydedildiği yerdir. Diğer her şey hız veya kullanım kolaylığı için türetilmiş veridir. Bir türetilmiş görünüm bozulursa, onu kaynak-kaynağından yeniden oluşturabilmelisiniz.
Ekipler takıldığında genellikle şu sorular hangi şeylerin önemli olduğunu yüzeye çıkarır:
- Hangi veri asla kaybolmamalı, hatta bu yavaşlamaya neden olsa bile?
- Hangi veri diğer verilerden yeniden oluşturulabilir, saatler alsa bile?
- Bir kullanıcının bakış açısından ne kadar süreyle veriler eski olabilir?
- Hangi hata sizin için daha kötüdür: çiftler, eksik olaylar yoksa gecikmeler?
Bir kullanıcı fatura planını güncellediğinde bir pano gecikebilir. Ama ödeme durumu ile gerçek erişim arasında uyuşmazlığa katlanamazsınız.
Akışlar, kuyruklar ve loglar: işin doğru biçimini seçmek
Bir kullanıcı bir düğmeye tıklayıp sonucu hemen görmesi gerekiyorsa (profili kaydetme, panoyu yükleme, izinleri kontrol etme), normal request-response API genelde yeterlidir. Doğrudan tutun.
İş daha sonra yapılabiliyorsa, asenkrona taşıyın. E-posta gönderme, kart tahsil etme, rapor oluşturma, yük yeniden boyutlandırma veya veriyi aramaya senkronize etme gibi işleri düşünün. Kullanıcının bunları beklememesi ve API’nizin bunlar çalışırken meşgul olmaması gerekir.
Kuyruk bir yapılacaklar listesi gibidir: her görev bir işçi tarafından bir kez işlenmelidir. Bir akış (veya log) ise bir kayıttır: olaylar sıralı tutulur, böylece birden çok okuyucu bunları yeniden oynatabilir, yakalayabilir veya üreticiyi değiştirmeden yeni özellikler oluşturabilir.
Pratik bir seçim yolu:
- Kullanıcı anlık bir yanıt gerektiğinde ve iş küçükse request-response kullanın.
- Yeniden denemelerle bir işin arka planda yapılması ve her işin yalnızca bir işçi tarafından yapılması gerekiyorsa kuyruğu kullanın.
- Replay, denetim izi veya birbirine bağlı olmaması gereken birden fazla tüketici gerektiğinde stream/log kullanın.
Örnek: SaaS’inizde bir “Fatura Oluştur” düğmesi var. API girişi doğrular ve faturayı Postgres’e kaydeder. Sonra bir kuyruk “fatura e-posta gönder” ve “kartı çek” işlerini halleder. Sonradan analitik, bildirimler ve dolandırıcılık kontrolleri eklerseniz, InvoiceCreated olay akışı her özelliğin abone olmasına izin verir ve çekirdek servisinizi bir labirente dönüştürmez.
Olay tasarımı: ne yayınlarsınız ve neyi saklarsınız
Ürün büyüdükçe olaylar “olmazsa olmaz” hale gelir ve bir güvenlik ağı olur. İyi olay tasarımı iki soruya indirgenir: hangi olguları kaydediyorsunuz ve diğer parçalar tahmin etmeden nasıl tepki verebilir?
Önce küçük bir iş olayları setiyle başlayın. Kullanıcılar ve para için önemli anları seçin: UserSignedUp, EmailVerified, SubscriptionStarted, PaymentSucceeded, PasswordResetRequested.
İsimler kodun ömrünü aşar. Tamamlanmış olgular için geçmiş zaman kullanın, spesifik tutun ve UI dili kullanmaktan kaçının. PaymentSucceeded kuponlar, yeniden denemeler veya birden çok ödeme sağlayıcı ekleseniz bile anlamlı kalır.
Olayları sözleşme gibi görün: her sprint’te değişen alanlarla dolu bir “UserUpdated” yakalama olayından kaçının. Yıllarca arkasında durabileceğiniz en küçük olguyu tercih edin.
Güvenli evrim için, eklemeli değişiklikleri (yeni isteğe bağlı alanlar) tercih edin. Kırıcı bir değişiklik gerekirse, yeni bir olay adı (veya açık sürüm) yayınlayın ve eski tüketiciler gitene kadar her ikisini de çalıştırın.
Ne saklamalısınız? Eğer sadece veritabanında son satırları tutuyorsanız, oraya nasıl geldiğinizin hikayesini kaybedersiniz.
Ham olaylar denetim, yeniden oynatma ve hata ayıklama için iyidir. Anlık görünümler hızlı okuma ve hızlı kurtarma için uygundur. Birçok SaaS ürünü her ikisini kullanır: kritik iş akışları için ham olayları saklayın (faturalama, yetkilendirme) ve kullanıcıya gösterilen ekranlar için anlık görünümler tutun.
Kullanıcıların gerçekten hissettiği tutarlılık ödünleri
Tutarlılık şu anlarda görünür: “Planımı değiştirdim, neden hâlâ Ücretsiz görünüyor?” veya “Bir davet gönderdim, neden takım arkadaşım henüz giriş yapamıyor?” gibi.
Güçlü tutarlılık demek, başarı mesajını aldıktan sonra her ekranın yeni durumu hemen yansıtmasıdır. Sonunda tutarlılık (eventual consistency) demek değişikliğin zaman içinde yayıldığı ve kısa bir pencerede uygulamanın farklı bölümlerinin anlaşamayabileceğidir. Hiçbiri otomatik olarak “daha iyi” değildir. Hangi uyuşmazlığın zarar vereceğine göre seçim yaparsınız.
Güçlü tutarlılık genelde para, erişim ve güvenlik için uygundur: kart çekme, şifre değiştirme, API anahtarlarını iptal etme, koltuk limitlerini uygulama. Sonunda tutarlılık ise genelde etkinlik akışları, arama, analiz panoları, “son görüldü” ve bildirimler için uygundur.
Eğer eski olmayı kabul ediyorsanız, bunu gizlemek yerine tasarlayın. UI’yı dürüst tutun: yazma sonrası onay gelene kadar “Güncelleniyor…” durumu gösterin, listeler için elle yenileme sunun ve yalnızca geri alması kolay ise iyimser UI (optimistic UI) kullanın.
Yeniden denemeler tutarlılığı sinsileştirir. Ağlar düşer, istemciler çift tıklar ve işçiler yeniden başlar. Önemli işlemler için istekleri idempotent yapın ki aynı eylemi tekrarlamak iki fatura, iki davet veya iki iade yaratmasın. Yaygın yaklaşım her eylem için bir idempotency anahtarı ve tekrarlar için orijinal sonucu döndüren sunucu tarafı kuralıdır.
Backpressure: sistemin erimesini engellemek
Backpressure, istekler veya olaylar sisteminizin işleyebileceğinden daha hızlı geldiğinde ihtiyaç duyduğunuz şeydir. Yoksa işler bellekte yığılır, kuyruklar büyür ve en yavaş bağımlılık (genelde veritabanı) her şeyin ne zaman başarısız olacağını belirler.
Basitçe: üretici konuşmaya devam ederken tüketici boğuluyordur. Daha fazla işi kabul etmeye devam ederseniz sadece yavaşlamazsınız. Zaman aşımı ve yeniden denemeler zincir reaksiyonuyla yükü çarpan şekilde artırırsınız.
Uyarı işaretleri genelde bir kesinti öncesi görünür: backlog sürekli büyür, gecikme ani sıçramalar veya deploylardan sonra yükselir, yeniden denemeler zaman aşımıyla artar, ilgisiz uç noktalar bir bağımlılık yavaşladığında başarısız olur ve veritabanı bağlantıları limitte takılır.
Bu noktaya geldiğinizde, dolu olduğunuzda ne olacağına dair net bir kural seçin. Amaç her şeyi her koşulda işlemek değil. Amaç hayatta kalmak ve hızla toparlanmaktır. Ekipler genelde bir veya iki kontrol ile başlar: (kullanıcı veya API anahtarı başına) hız sınırlamaları, belirli bir sınırı olan kuyruklar ve açık bir düşür/ertele politikası, başarısız bağımlılıklar için devre kesiciler ve etkileşimli isteklerin arka plan işlerinin önüne geçmesi için öncelikler.
Önce veritabanını koruyun. Bağlantı havuzlarını küçük ve öngörülebilir tutun, sorgu zaman aşımı koyun ve ad-hoc raporlar gibi pahalı uç noktalara sert limitler getirin.
Yeniden yazmadan güvenilirliğe giden adım adım yol
Güvenilirlik nadiren büyük bir yeniden yazım gerektirir. Genelde hataları görünür, izole ve geri alınabilir yapan birkaç karardan gelir.
Güven kazandıran akışlarla başlayın, sonra özellik eklemeden önce güvenlik rayları ekleyin:
-
Map critical paths. Kayıt, giriş, şifre sıfırlama ve ödeme akışı gibi adımların tam listesini yazın. Her adım için bağımlılıkları (veritabanı, e-posta sağlayıcısı, arka plan worker) listeleyin. Bu neyin anında olması gerektiği ile neyin "sonunda" düzeltilebileceğini netleştirir.
-
Temel gözlemlenebilirliği ekleyin. Her isteğe loglarda görünen bir ID verin. Kullanıcı ağrısına denk küçük bir metrik seti izleyin: hata oranı, gecikme, kuyruk derinliği ve yavaş sorgular. Hizmetler arası isteklerde trace ekleyin.
-
Yavaş veya dalgalı işleri izole edin. Dış bir servisle konuşan veya düzenli olarak bir saniyeden fazla süren her şey işi ve workerları kullanmalıdır.
-
Yeniden denemeler ve kısmi hatalar için tasarlayın. Zaman aşımı olacağını varsayın. Operasyonları idempotent yapın, backoff kullanın, zaman limitleri koyun ve kullanıcıya gösterilen eylemleri kısa tutun.
-
Kurtarmayı pratiğe dökün. Yedekler sadece geri yükleyebiliyorsanız önemlidir. Küçük sürümler kullanın ve hızlı rollback yolları tutun.
Eğer aracınız snapshot ve rollback destekliyorsa (Koder.ai bunu destekliyorsa), bunu normal dağıtım alışkanlığı haline getirin, acil bir numaramış gibi değil.
Örnek: küçük bir SaaS'i güvenilir hale getirmek
Küçük bir SaaS düşünün: ekiplerin yeni müşterileri karşılamasına yardımcı oluyor. Akış basit: kullanıcı kaydolur, bir plan seçer, ödeme yapar ve karşılama e-postası ile birkaç "başlarken" adımı alır.
Prototipte her şey tek istekte olur: hesap oluştur, kartı tahsil et, kullanıcıyı "ücretli" yap, e-posta gönder. Trafik büyüyüp yeniden denemeler olunca ve dış servisler yavaşlayınca bu tasarım bozulur.
Güvenilir yapmak için ekip temel eylemleri olaylara çevirir ve eklenmeyen bir geçmiş (append-only) tutar. Birkaç olay tanımlarlar: UserSignedUp, PaymentSucceeded, EntitlementGranted, WelcomeEmailRequested. Bu onlara denetim izi verir, analitiği kolaylaştırır ve yavaş işlerin arka planda bloklamadan gerçekleşmesini sağlar.
Birkaç doğru seçim çoğu işi halleder:
- Erişim için kaynağı ödeme işlemi kabul edin, tek bir "ücretli" bayrağına güvenmeyin.
PaymentSucceeded üzerinden yetki verin ve yeniden denemeler iki kez vermesin diye açık bir idempotency anahtarı kullanın.- E-postaları ödeme sırasında değil, bir kuyruk/worker’dan gönderin.
- Bir işlem başarısız olsa bile olayları kaydedin ki replay ile kurtarılabilsin.
- Dış sağlayıcıların çevresine zaman aşımı ve devre kesici ekleyin.
Ödeme başarılı ama erişim henüz verilmemişse kullanıcı dolandırılmış gibi hisseder. Çözüm "her yerde mükemmel tutarlılık" değil. Hangi şeyin şimdi tutarlı olması gerektiğine karar verip bunu UI’da göstermek: EntitlementGranted gelene kadar "Planınız etkinleştiriliyor" gibi bir durum gösterin.
Kötü bir günde backpressure fark yaratır. Pazarlama kampanyası sırasında e-posta API’si takılırsa eski tasarım ödemeleri zaman aşımına uğratır, kullanıcılar yeniden dener ve çift ücretlendirme ile çift e-posta oluşur. Daha iyi tasarımda checkout başarılı olur, e-posta istekleri kuyruğa girer ve sağlayıcı toparlandığında replay işi backlog’u temizler.
Ölçeklenirken sık düşülen tuzaklar
Çoğu kesinti tek bir kahraman hatasından kaynaklanmaz. Prototipte mantıklı olan küçük kararlar zamanla alışkanlığa dönüşür ve sorun yaratır.
Erken mikroservislere bölünmek yaygın bir tuzaktır. Hizmetler çoğunlukla birbirini çağırır, sahiplik belirsizdir ve değişiklikler beş deploy gerektirir.
Bir başka tuzak "eventual consistency"yi serbest bir geçiş olarak kullanmaktır. Kullanıcılar terimi umursamaz; Save’e tıklayıp sonra sayfanın eski veri göstermesinden şikayet ederler veya bir fatura durumu gidip geliyor olabilir. Gecikmeyi kabul ediyorsanız, yine de kullanıcıya geri bildirim, zaman aşımı ve her ekran için "yeterince iyi" tanımı sunmalısınız.
Diğer tekrar eden hatalar: olay yayınlayıp yeniden işleme planı yapmamak, olaylar sırasında kontrolsüz yeniden denemelerle yükün katlanması ve her hizmetin aynı veritabanı şemasına doğrudan erişmesine izin verip bir değişikliğin birçok takımı kırmasına olanak tanımak.
"Üretime hazır" demeden önce hızlı kontroller
"Üretime hazır" bir dizi karardır ve gece yarısı sorulduğunda işaret edebileceğiniz kararlardan oluşur. Netlik ustalığın önündedir.
Önce doğruluk kaynaklarınızı adlandırın. Her ana veri tipi için (müşteriler, abonelikler, faturalar, izinler) son kaydın nerede tutulduğunu belirleyin. Uygulamanız iki yerden "gerçek" okuyorsa, farklı kullanıcılara farklı yanıtlar gösterirsiniz.
Sonra yeniden denemelere bakın. Her önemli eylemin bir noktada iki kez çalışacağını varsayın. Aynı istek iki kez sisteme ulaşırsa, çift ücretlendirmeyi, çift göndermeyi veya çift oluşturmayı nasıl önlersiniz?
Çoğu acı verici hatayı yakalayan küçük bir kontrol listesi:
- Her veri tipi için bir kaynak-kaynağı gösterebiliyorsunuz ve türetileni adlandırabiliyorsunuz.
- Her önemli yazma güvenle yeniden denenebilir (idempotency anahtarı veya benzersiz kısıtlama).
- Asenkron işler kontrolsüzce büyüyemez (lag, en eski mesaj yaşı izleniyor ve kullanıcı fark etmeden önce alarm veriliyor).
- Değişiklik için bir planınız var (geri döndürülebilir migrasyonlar, olay versiyonlama).
- Geri alma ve geri yükleme pratiğiniz var çünkü bunu denediniz.
Sonraki adımlar: her seferinde bir karar alın
Sistem tasarımını bir teori yığını olarak değil, kısa bir karar listesi olarak gördüğünüzde ölçeklenme kolaylaşır.
Önümüzdeki ay karşılaşacağınız 3–5 kararı düz Türkçe ile yazın: "E-posta gönderimini arka işe mi taşıyoruz?", "Biraz eski analitikleri kabul ediyor muyuz?", "Hangi eylemler hemen tutarlı olmalı?" Bu liste ürün ve mühendisliği hizalamak için kullanın.
Sonra şu an senkron olan bir iş akışını seçin ve sadece onu asenkrona çevirin. Makbuzlar, bildirimler, raporlar ve dosya işleme yaygın ilk adımlardır. Değişiklikten önce ve sonra iki şeyi ölçün: kullanıcı yüzeyindeki gecikme (sayfa daha hızlı hissettirdi mi?) ve hata davranışı (yeniden denemeler çift oluşturdu mu veya kafa karışıklığına neden oldu mu?).
Hızlıca prototiplemek isterseniz, Koder.ai hızlı iterasyon için faydalı olabilir; React + Go + PostgreSQL içeren bir SaaS geliştirirken rollback ve snapshotları yakın tutar. Ölçüt basit kalmalı: bir iyileştirme gönderin, gerçek trafikten öğrenin, sonra bir sonraki kararı verin.