Bir gözlemlenebilirlik aracı, tipik olarak grafikler, loglar veya bir sorgu sonucu göstererek sistemle ilgili belirli soruları yanıtlamanıza yardımcı olur. Bir sorun olduğunda “kullandığınız” şeydir.
Bir gözlemlenebilirlik platformu ise daha geniştir: telemetri toplama yöntemlerini, ekiplerin bunu nasıl keşfettiğini ve olayların uçtan uca nasıl ele alındığını standartlaştırır. Bir kuruluşun birçok servis ve ekip boyunca her gün “çalıştırdığı” şey haline gelir.
Grafiklerden çıktılara
Çoğu ekip panolarla başlar: CPU grafikleri, hata oranı grafikleri, belki birkaç log araması. Bu faydalıdır, ama asıl hedef daha güzel grafikler değil—daha hızlı tespit ve daha hızlı çözümdür.
Platforma geçiş, “Bunu grafikleyebilir miyiz?” sormak yerine şunları sormaya başladığınızda olur:
- Çağrıdaki mühendis kök nedeni dakikalar içinde bulabiliyor mu, saatler içinde değil mi?
- Doğru uyarı otomatik olarak doğru takıma yönlendirilebiliyor mu?
- Tekrarlayan olay desenlerini tekrarlanabilir playbook'lara dönüştürebiliyor muyuz?
Bunlar sonuç odaklı sorulardır ve görselleştirmenin ötesinde şeyler gerektirir. Ortak veri standartları, tutarlı entegrasyonlar ve telemetriyi eyleme bağlayan iş akışları gerekir.
Gerçekte satın aldığınız üç temel sütun
Datadog gibi platformlar gelişirken, “ürün yüzeyi” sadece panolar değildir. Üç iç içe geçen sütundur:
- Telemetri: güvenilir sayılabilecek şekilde tutarlı toplanmış, iyi etiketlenmiş loglar, metrikler ve trace'ler.
- Entegrasyonlar: benimsemeyi kolaylaştıran, özel bağlantı ihtiyacını azaltan hazır bağlantılar.
- İş akışları: olay yanıtlama, uyarı yönlendirme, sahiplik ve takip—öğrenmenin birikmesini sağlar.
Tek bir pano tek bir ekibe yardımcı olabilir. Bir platform her servis eklendikçe, her entegrasyon eklendikçe ve her iş akışı standartlaştırıldıkça güçlenir. Zamanla bu, daha az kör nokta, daha az tekrarlanan araç ve daha kısa olay süreleri anlamına gelir—çünkü her iyileştirme tek seferlik değil, yeniden kullanılabilir olur.
Telemetri Ürün Yüzeyi Haline Gelir
Gözlemlenebilirlik “sorguladığımız bir araç” olmaktan “üzerine inşa ettiğimiz bir platform”a kaydığında, telemetri ham egzoz olmaktan çıkar ve ürün yüzeyi gibi davranmaya başlar. Ne yayınlamayı seçtiğiniz—ve bunu ne kadar tutarlı yaptığınız—ekiplerin ne görebileceğini, neyi otomatikleştirebileceğini ve neye güvenebileceğini belirler.
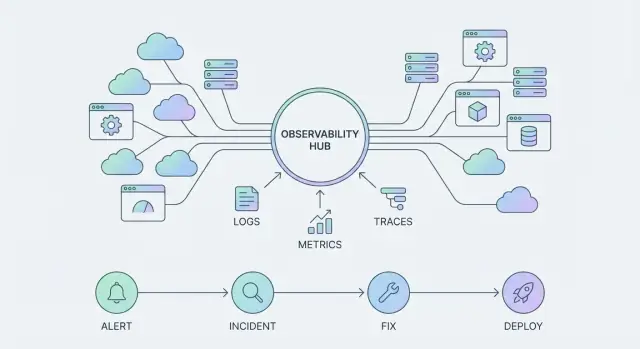
Temel telemetri türleri (ve ne için oldukları)
Çoğu ekip küçük bir sinyal seti etrafında standardize olur:
- Metrikler: zaman içindeki sayısal eğilimler (latency, hata oranı, doygunluk).
- Loglar: inceleme ve denetim için detaylı, insan tarafından okunabilir kayıtlar.
- Trace'ler: zaman ve hataların nerede oluştuğunu bulmak için servisler arası istek yolları.
- Event'ler: ayrı "bir şey değişti" kayıtları (deploy'lar, feature flag'ler, olaylar).
- Profil'ler: pahalı kod yollarını tespit etmek için CPU/heap davranışı.
Tek tek her sinyal faydalıdır. Birlikte, panolarınızda, uyarılarda, olay zaman çizelgelerinde ve postmortem'lerde gördüğünüz tek bir arayüz olurlar.
Tutarlılık hacmi yener
Yaygın bir başarısızlık modu, “her şeyi” toplamak ama tutarsız adlandırma yapmaktır. Bir servis userId kullanırken, diğeri uid kullanıyorsa ve bir başkası hiç loglamıyorsa, veriyi güvenilir şekilde dilimleyemez, sinyalleri birleştiremez veya yeniden kullanılabilir monitörler oluşturamazsınız.
Ekipler, ingest hacmini ikiye katlamaktanse birkaç konvansiyonda—servis adları, ortam etiketleri, istek ID'leri ve standart bir özellik seti—uzlaşarak daha çok değer elde eder.
Yüksek-kardinalitenin gerçekte ne anlama geldiği (ve neden önemli olduğu)
Yüksek-kardinalite alanlar birçok olası değere sahip özniteliklerdir (ör. user_id, order_id, session_id). Tek müşteriyle sınırlı hataları debug etmek için güçlüdürler, ama her yerde kullanılırsa maliyeti artırır ve sorguları yavaşlatır.
Platform yaklaşımı kasıtlıdır: yüksek-kardinaliteyi net araştırma değeri sağladığı yerde tutun ve küresel agregatlar için olduğunda kaçının.
Birleşik bağlam korelasyon işini azaltır
Kazanç hızdır. Metrikler, loglar, trace'ler, event'ler ve profil'ler aynı bağlamı paylaştığında (service, version, region, request ID), mühendisler kanıtları birleştirmekle daha az, gerçek problemi çözmekle daha çok zaman harcar. Araçlar arasında atlamak ve tahmin etmek yerine, semptomdan kök nedene tek bir ipi takip edersiniz.
Veri Toplamadan Telemetri Stratejisine
Çoğu ekip gözlemlenebilirliğe “veri sokarak” başlar. Bu gerekli ama strateji değildir. Bir telemetri stratejisi, onboarding'i hızlı tutar ve verinizi paylaşılan panoları, güvenilir uyarıları ve anlamlı SLO'ları besleyecek kadar tutarlı kılar.
Yaygın ingest yolları (ve ne için iyi oldukları)
Datadog genellikle telemetriyi birkaç pratik yolla alır:
- Host/VM üzerine agent'lar: altyapı metrikleri, loglar ve APM'i minimal kod değişikliğiyle toplamanın en hızlı yolu.
- Collector'lar ve gateway'ler (ör. OpenTelemetry Collector): merkezi kontrol, çoklu hedef yönlendirme, redaksiyon veya standart işleme gerektiğinde kullanışlıdır.
- APİ'ler ve doğrudan SDK'lar: özel event'ler, iş metrikleri veya bir agent mümkün olmadığında faydalıdır.
- Serverless entegrasyonları: altında host kontrolü olmadığında kullanışlıdır; ancak ne yayınladığınıza kasıtlı davranmanız gerekir.
Hız vs. standardizasyon: ne için optimize edeceğinize karar verin
Başlangıçta hız kazanır: ekipler agent kurar, birkaç entegrasyonu açar ve hemen değer görür. Risk, her ekibin kendi etiketlerini, servis adlarını ve log formatlarını icat etmesidir—bu da servisler arası görünümleri karmaşıklaştırır ve uyarıları güvenilmez kılar.
Basit bir kural: "hızlı başlangıca" izin verin, ama 30 gün içinde standartlaştırmayı zorunlu kılın. Bu ekiplerin ivme kazanmasını sağlar, kaosa kilitlenmeyi önler.
Hafif bir adlandırma ve etiketleme konvansiyonu
Büyük bir taksonomiye gerek yok. Her sinyalin (loglar, metrikler, trace'ler) taşıması gereken küçük bir setle başlayın:
service: kısa, stabil, küçük harf (ör. checkout-api)env: prod, staging, devteam: sahiplik takımı kimliği (ör. payments)version: deploy versiyonu veya git SHA
Hızlı bir getiri isteyenler için tier (frontend, backend, data) eklemek filtrelemeyi basitleştirir.
Örnekleme, saklama ve maliyete duyarlı varsayılanlar
Maliyet sorunları genellikle çok cömert varsayılanlardan gelir:
- Trace'ler: yüksek hacimli uçlar için head-based sampling ile başlayın; kritik akışlarda %100 tutun.
- Loglar: varsayılan olarak “hata + önemli iş event'leri” tutun, sonra bilgi/debug seviyesini süreli olarak ekleyin.
- Saklama: yüksek çözünürlüklü veriyi kısa tutun (günler), önemli agregatları daha uzun (haftalar/aylar) saklayın.
Amaç daha az toplamak değil—doğru veriyi tutarlı şekilde toplamak, böylece kullanım ölçeklenirken sürpriz olmamasıdır.
Entegrasyonlar Gerçek Dağıtım Kanalıdır
Çoğu kişi gözlemlenebilirlik araçlarını “kurduğunuz bir şey” olarak düşünür. Gerçekte, iyi konnektörler bir kuruluşta bir entegrasyonla yayılır: bir entegrasyon bir seferde.
“Entegrasyon” gerçekte ne demektir
Bir entegrasyon sadece veri hattı değildir. Genellikle üç parça vardır:
- Veri kaynakları: zaten çalıştırdığınız sistemlerden metrik, log, trace, event ve topoloji çekme (bulut servisleri, Kubernetes, DB'ler, CI/CD, SaaS araçlar).
- Zenginleştirme: telemetrinin hemen kullanılabilir olması için servis adları, ortamlar, sahiplik etiketleri, sürümler ve bulut meta verisi ekleme.
- Aksiyonlar: öğrendiklerinizle bir şeyler yapma—ticket oluşturma, on-call'a sayfa atma, deploy notu ekleme, kaynak ölçekleme veya runbook tetikleme.
Son kısım entegrasyonları dağıtıma çevirir. Araç sadece okursa, dashboard hedefidir. Aynı zamanda yazıyorsa, günlük işin parçası olur.
Entegrasyonlar benimsemeyi neden hızlandırır
İyi entegrasyonlar kurulum süresini azaltır çünkü makul varsayılanlarla gelirler: önceden hazırlanmış panolar, önerilen monitörler, parsing kuralları ve ortak etiketler. Her ekip kendi "CPU panosunu" veya "Postgres uyarılarını" icat etmek yerine, en iyi uygulamalara uygun bir başlangıç noktası elde eder.
Ekipler yine özelleştirir—ama paylaşılan bir temel üzerinden özelleştirirler. Bu standardizasyon, araçları konsolide ederken önemlidir: entegrasyonlar yeni servislerin kopyalayabileceği tekrarlanabilir desenler oluşturur, bu da büyümeyi yönetilebilir kılar.
İki yönlü entegrasyonlara öncelik verin
Seçenekleri değerlendirirken sorun: sinyali alabilir mi ve aksiyon alabilir mi? Örnekler: ticket açmak, olay kanallarını güncellemek veya bir trace bağlantısını PR veya deploy görünümüne eklemek. İki yönlü kurulumlar iş akışlarının “yerel” hissetmesini sağlar.
Basit bir öncelik listesi yöntemi
Küçük ve öngörülebilir başlayın:
- Kritik altyapı ilk (bulut sağlayıcı, Kubernetes, yük dengeleyiciler, temel DB'ler).
- Ardından deploy hattı (CI/CD, feature flag, sürüm takibi) ki telemetri değişikliklerle hizalansın.
- Etiketleme ve sahiplik kuralları stabil olduktan sonra ekip bazlı SaaS entegrasyonlarını ekleyin.
Kuralı isterseniz: hemen olay yanıtını iyileştiren entegrasyonlara öncelik verin, sadece daha fazla grafik ekleyenlere değil.
Standart Görünümler: Servisler, Panolar ve Monitörler
Standart görünümler bir gözlemlenebilirlik platformunu günlük kullanılabilir hale getirir. Ekipler aynı zihinsel modele (bir “servis”in ne olduğu, “sağlıklı”nın ne olduğu ve ilk tıklanacak yer) sahip olduğunda, debug daha hızlı olur ve devralmalar daha temiz olur.
Altın sinyallerle başlayın (ve görünür kılın)
Küçük bir “altın sinyaller” seti seçin ve her biri için somut, yeniden kullanılabilir bir pano haritalayın. Çoğu servis için bu şunlardır:
- Latency (önemli uç noktalar için p95/p99)
- Trafik (saniye başına istek, işlenen işler)
- Hatalar (oran ve en yaygın hata türleri)
- Doygunluk (CPU, bellek, kuyruk derinliği, DB bağlantıları)
Tutarlılık anahtardır: servisler arasında işe yarayan tek bir pano düzeni, on tane özel panodan daha iyidir.
Servis katalogları paylaşılan sahiplik yaratır
Hafif bir servis katalogu bile “birinin buna bakması gerekir”i “bu takım sahip” haline çevirir. Servisler sahipler, ortamlar ve bağımlılıklar ile etiketlendiğinde, platform şu soruları anında cevaplayabilir: Bu servise hangi monitörler uygulanır? Hangi panoları açmalıyım? Kim sayfalanır?
Bu netlik olay sırasında Slack ping-pong'unu azaltır ve yeni mühendislerin self-serve olmasına yardımcı olur.
Ölçeklenen yapı taşları
Bunları isteğe bağlı ekstralar değil, standart varlıklar olarak düşünün:
- Altın sinyaller ve ana bağımlılıklar için panolar
- SLO'lara veya kullanıcı etkisine bağlı monitörler
- İncelemeler ve olay zaman çizelgeleri için notebook'lar
- İlk 5–10 dakika yanıt için bağlanmış runbook'lar
Kaçınılması gereken anti-paternler
Vanity panolar (karar arkasında mantık olmayan güzel grafikler), aceleyle oluşturulmuş tek seferlik uyarılar ve belgesiz sorgular (sadece bir kişi sihirli filtreyi anlıyor) platform gürültüsü yaratır. Bir sorgu önemliyse, kaydedin, adlandırın ve başkalarının bulabileceği bir servis görünümüne ekleyin.
İş Akışları: Gözlemlenebilirliğin İş Değerini Teslim Ettiği Yer
Telemetri Maliyetlerini Öngörülebilir Kılın
Takım bazında log, trace ve saklama ayarlarını gözden geçirmenizi sağlayan küçük bir uygulama prototipi oluşturun.
Gözlemlenebilirlik, bir problemi çözme ile ilgili zamanı ve güvendiğiniz çözümü kısalttığında iş için “gerçek” olur. Bu, sinyalden eyleme ve eylemden öğrenmeye götüren tekrarlanabilir yollar—iş akışları—aracılığıyla olur.
Olay yolculuğu: uyarı → triage → iletişim → hafifletme → öğrenme
Ölçeklenebilir bir iş akışı yalnızca birini sayfalamaktan daha fazlasıdır.
Bir uyarı odaklanmış bir triage döngüsü başlatmalıdır: etkiyi doğrula, etkilenen servisi belirle ve en alakalı bağlamı çek (son deploy'lar, bağımlılık sağlığı, hata sıçramaları, doygunluk sinyalleri). Ardından iletişim, teknik bir olayı koordine bir yanıta çevirir—olayın sahibi kim, kullanıcılar ne görüyor ve bir sonraki güncelleme ne zaman olacak.
Hafifletme, elinizin altında "güvenli hamleler" olmasını istediğiniz yerdir: feature flag'ler, trafik kaydırma, rollback, rate limit'ler veya bilinen bir geçici çözüm. Son olarak, öğrenme döngüyü kapatır: ne değişti, ne işe yaradı ve bir sonraki adımda ne otomatikleştirilmeli kısa bir inceleme ile.
Olay araçları + ChatOps = kahramanlığa değil işbirliğine dayalı süreç
Datadog gibi platformlar, olay kanalları, durum güncellemeleri, devir teslimler ve tutarlı zaman çizelgeleri desteklediğinde değer katar. ChatOps entegrasyonları uyarıları yapılandırılmış konuşmalara dönüştürebilir—olay oluşturma, roller atama ve kilit grafiklerle sorguları doğrudan thread'e gönderme gibi—böylece herkes aynı kanıtı görür.
İyi bir runbook aslında neler içerir
Yararlı bir runbook kısa, kesin ve güvenlidir. Şunları içermelidir: hedef (servisi geri getirmek), net sahipler/on-call rotasyonları, adım adım kontroller, doğru panolara/monitörlere bağlantılar ve riski azaltan “güvenli eylemler” (rollback adımlarıyla). Eğer 03:00'te çalıştırılması güvenli değilse, tamamlanmamıştır.
Olayları deploy'larla ve değişikliklerle ilişkilendirin
Olaylar otomatik olarak deploy'lar, konfigürasyon değişiklikleri ve feature flag flip'leri ile korelasyonlandığında kök neden daha hızlı bulunur. "Ne değişti?" görünümünü ilk sınıf yapın ki triage kanıta dayansın, tahmine değil.
SLO'lar ve Hata Bütçeleri Bir Ekip İşletim Sistemi Olarak
SLO nedir (ve neden “yeşil panolardan” daha iyidir)
Bir SLO (Service Level Objective) belirli bir zaman penceresinde kullanıcı deneyimi hakkında basit bir vaatdir—ör. “30 gün içinde isteklerin %99.9'u başarılı olacak” veya “p95 sayfa yüklenmesi 2 saniyenin altında.”
Bu, panoların genellikle sistem sağlığını (CPU, bellek, kuyruk derinliği) göstermesinin ötesine geçer ve kullanıcı etkisini ölçmeye zorlar. Bir servis panoda yeşil görünebilir ama kullanıcıları etkiliyor olabilir (ör. bir bağımlılık zaman aşımına uğruyor veya hatalar belirli bir bölgede yoğunlaşıyor). SLO'lar ekibi kullanıcıların gerçekten hissettiği şeyi ölçmeye zorlar.
Hata bütçeleri: riski konuşmanın ortak yolu
Bir hata bütçesi, SLO'nuzun izin verdiği başarısızlık miktarıdır. Eğer 30 gün içinde %99.9 başarı vaat ediyorsanız, o pencere için yaklaşık 43 dakika hata “hakkınız” var demektir.
Bu kararlar için pratik bir işletim sistemi yaratır:
- Bütçe sağlıklıysa: özellik gönderin, deneyler yapın, makul riske izin verin.
- Bütçe tükeniyorsa: sürümleri yavaşlatın, güvenilirlik çalışmalarına odaklanın, değişiklikleri azaltın.
- Bütçe tükendiyse: riskli deploy'ları durdurun ve en büyük hata kaynaklarını gidermeye odaklanın.
Yayın toplantısında görüşlerin tartışılması yerine, herkesin görebildiği bir sayıyı tartışırsınız.
Ham spike'lar yerine burn rate üzerinde uyarı verin
SLO uyarıları, burn rate (hata bütçesinin ne kadar hızlı tüketildiği) üzerine kurulu olduğunda en iyi sonucu verir, ham hata sayıları üzerine değil. Bu gürültüyü azaltır:
- Kendi kendine düzelmeyen kısa bir spike kimseyi sayfalamayabilir.
- Hata bütçesini yakında tüketebilecek sürekli bir sorun ise net, eyleme geçirilebilir bir uyarı tetikler.
Birçok ekip iki pencere kullanır: hızlı burn (hızlıca sayfa) ve yavaş burn (ticket/bildirim).
Tipik bir web servisi için hafif SLO başlangıç seti
Küçük başlayın—kullanacağınız iki ila dört SLO:
- Kullanılabilirlik: 30 gün içinde başarılı isteklerin yüzdesi (ör. HTTP 2xx/3xx).
- Gecikme: p95 istek gecikmesi belirli eşik altında.
- Checkout / kritik uç nokta: iş açısından en önemli yolun başarı oranı.
- Tazelik (varsa): arka plan işler X dakika içinde tamamlanıyor.
Bunlar stabil olduktan sonra genişletebilirsiniz—aksi halde sadece başka bir pano duvarı inşa etmiş olursunuz. Daha fazlası için SLO izleme temellerine bakın.
İnsanları Yakmadan Ölçeklenen Uyarılama
Postmortemleri Tekrarlanabilir Hale Getirin
Ne değiştiğini ve bir sonraki otomasyona hangi adımların alınması gerektiğini yakalayan bir olay sonrası inceleme formu oluşturun.
Uyarılama birçok gözlemlenebilirlik programının tıkandığı yerdir: veri var, panolar güzel görünüyor ama on-call deneyimi gürültülü ve güvenilmez oluyor. İnsanlar uyarıları görmezden gelmeyi öğrenirse, platform işinizi koruma yetisini kaybeder.
Uyarı yorgunluğu neden olur (ve sinyaller neden çoğalır)
En yaygın nedenler şaşırtıcı derecede tutarlıdır:
- Aksiyon gerektirmeyen çok fazla “FYI” uyarı
- Bağlam olmadan servisler arasında kopyalanmış eşik değerleri (aynı CPU kuralı çok farklı iş yükleri için)
- Aynı semptom için birden fazla araç veya takımın uyarı vermesi—ör. bir APM hata oranı monitörü ve log tabanlı hata monitörü aynı olay için sayfa atıyor.
- Gürültülü metrikler (spike yapan latency percentilleri, autoscaling etkileri) gerçek problemlere değil dalgalanmalara tetik verir.
Datadog terimleriyle, çoğaltılmış sinyaller genellikle farklı “yüzeylerden” (metrikler, loglar, trace'ler) oluşturulan monitörlerle görünür; hangi yüzeyin canonical sayfaya çıkacağına karar verilmemiştir.
Yönlendirme: sahiplik, şiddet ve sessiz saatler
Uyarılama ölçeklenmesi insanlara mantıklı gelen yönlendirme kurallarıyla başlar:
- Sahiplik: her monitörün net bir sahibi (servis/takım) ve bir yükseltme yolu olmalı.
- Şiddet: sayfalama yalnızca acil, kullanıcıyı etkileyen konular için ayrılmalı; düşük öncelik için ticket veya chat bildirimi kullanın.
- Bakım pencereleri: planlı deploy'lar, migration'lar ve yük testleri sayfa üretmemeli.
Uyarıları eyleme geçirilebilir kılacak basit kurallar
Faydalı bir varsayılan: semptomlara uyarı verin, her metrik değişimine değil. Kullanıcıların hissettiği şeylere (hata oranı, başarısız checkout'lar, süreklilik gösteren gecikme, SLO burn) sayfa çekin; girdi niteliğindeki metriklere (CPU, pod sayısı) sadece güvenilir şekilde etkiyi öngörüyorsa sayfa çekin.
Gerçekten çalışan bir gözden geçirme ritmi
Monitör hijyenini operasyonun parçası yapın: aylık monitör temizleme ve ayarlama. Hiç tetiklenmeyen monitörleri kaldırın, çok sık tetiklenen eşikleri ayarlayın ve çoğaltmaları birleştirin ki her olayın birincil bir sayfası olsun ve destekleyici bağlamlar ekleyin.
İyi yapıldığında uyarılama, insanların güvendiği bir iş akışı olur—arka planda bir gürültü kaynağı değil.
Gözlemlenebilirliği “platform” olarak adlandırmak sadece loglar, metrikler, trace'ler ve birçok entegrasyonun aynı yerde olması demek değildir. Aynı zamanda yönetişim anlamına gelir: ekip sayısı, servisler, panolar ve uyarılar çoğaldıkça sistemi kullanılabilir kılan tutarlılık ve korumalar.
Yönetişim yoksa, Datadog (veya herhangi bir platform) gürültülü bir scrapboook'a dönüşebilir—yüzlerce benzer ama hafifçe farklı pano, tutarsız etiketler, belirsiz sahiplik ve kimsenin güvenmediği uyarılar.
Yönetişim bir insan ve süreç problemidir
İyi yönetişim kimin neye karar verdiğini ve platform karıştığında kimin sorumlu olduğunu netleştirir:
- Platform takımı: standartları (etiketleme, adlandırma, pano kalıpları) tanımlar, paylaşılan bileşenleri sağlar ve entegrasyonları korur.
- Servis sahipleri: servisleri için telemetri kalitesinden sorumludur ve monitörleri anlamlı tutar.
- Güvenlik ve uyumluluk: veri işleme kurallarını (PII, saklama, erişim sınırları) belirler ve yüksek riskli entegrasyonları inceler.
- Liderlik: yönetişimi iş öncelikleriyle (güvenilirlik hedefleri, olay yanıt beklentileri) hizalar ve işi finanse eder.
“Gözlemlenebilirlik yayılması”nı önleyen pratik kontroller
Birkaç hafif kontrol uzun politika belgelerinden daha fazlasını yapar:
- Varsayılan şablonlar: servis tipine göre başlangıç panoları ve monitör paketleri (API, kuyruk işçisi, DB) ekiplerin tutarlı başlamasını sağlar.
- Etiketleme politikası: küçük zorunlu set (
service, env, team, tier) ve opsiyonel etiketler için net kurallar. Mümkünse CI'de zorlayın.
- Erişim ve sahiplik: hassas veriler için rol tabanlı erişim ve panolar/monitörler için bir sahibi zorunlu kılın.
- Yüksek etkili değişiklikler için onay akışları: insanları sayfalayan monitörler, maliyeti etkileyen log pipeline'ları ve hassas veri çeken entegrasyonlar için inceleme adımları.
Yeniden kullanım icattan daha iyidir
Kalitenin ölçeklenmesinin en hızlı yolu işe yarayanları paylaşmaktır:
- Paylaşılan kütüphaneler: loglama alanlarını, trace özniteliklerini ve ortak metrikleri standardize eden dahili paketler veya snippet'ler.
- Yeniden kullanılabilir panolar ve monitörler: ekiplerin klonlayıp uyarlayabileceği merkezi "altın" pano ve monitör şablon kataloğu.
- Versiyonlanmış standartlar: ana varlıkları kod gibi ele alın—değişiklikleri belgeleyin, eski desenleri kullanımdan kaldırın ve güncellemeleri tek bir yerde duyurun.
Bunu kalıcı yapmak istiyorsanız, yönetilen yolu kolay yol yapın—daha az tıklama, daha hızlı kurulum ve daha net sahiplik.
Gözlemlenebilirlik bir platform gibi davrandığında platform ekonomilerine uyar: platformu benimseyen daha fazla ekip, daha fazla telemetri üretir ve bu da aracın daha yararlı olmasını sağlar.
Bu bir flywheel yaratır:
- Daha fazla servis eklendikçe → çapraz servis görünürlüğü ve korelasyon iyileşir
- Daha iyi görünürlük → daha hızlı teşhis, daha az tekrar eden olay, araca daha fazla güven
- Daha fazla güven → daha fazla ekip enstrüman eder ve entegre olur → daha fazla veri
Ancak aynı döngü maliyeti de artırır. Daha fazla host, container, log, trace, synthetic ve özel metrik bütçenizden hızlıca fazla olabilir; kasıtlı yönetim gerekir.
Sinyali öldürmeden pratik maliyet kolları
Her şeyi kapatmak zorunda değilsiniz. Veriyi şekillendirmeyle başlayın:
- Örnekleme: kritik uçlar için yüksek hassasiyetli trace'leri tutun, diğer yerlerde daha agresif örnekleyin.
- Saklama katmanları: ham, yüksek hacimli loglar için kısa saklama; güvenlik/denetim için küratörlü akışlarda daha uzun.
- Log filtreleme ve parsing: erken aşamada bariz gürültüyü atın (health check'ler, statik varlık istekleri) ve parsing'i standardize ederek özniteliklere göre yönlendirin.
- Metrik agregasyonu: per-user ID gibi sınırsız kardinalite yerine yüzdelikler, oranlar ve rollup'ları tercih edin.
Maliyeti çıktıya bağlayan KPI'lar
Platformun geri dönüşünü gösteren küçük bir ölçü seti izleyin:
- MTTD (ortalama tespit süresi)
- MTTR (ortalama çözüm süresi)
- Olay sayısı ve tekrarlayan olaylar (aynı kök neden)
- Deploy sıklığı (ve izliyorsanız change failure rate)
Üç aylık “değer vs maliyet” incelemesi yürütün (suçlama yok)
Bunu bir ürün incelemesi yapın, denetim değil. Platform sahiplerini, birkaç servis takımını ve finansı çağırın. Şunları gözden geçirin:
- Veri türü ve takım bazında en büyük maliyet sürücüleri (loglar/metrikler/trace'ler)
- En büyük kazanımlar: kısalan olaylar, önlenen kesintiler, kaldırılan tekrar iş yükü
- 2–3 kararlaştırılmış aksiyon (ör. örnekleme kurallarını ayarla, saklama katmanı ekle, gürültülü entegrasyonu düzelt)
Amaç ortak sahiplik: maliyet, gözlemlenebilirliği durdurmak için değil, daha iyi enstrümantasyon kararlarına girdi olsun.
Bu, Gözlemlenebilirlik Araç Yığınınız İçin Ne Anlama Geliyor
Platform Gluesunu Prototipleyin
Platform ekibiniz için hızlı bir React + Go prototipi bir öğleden sonra içinde oluşturun.
Gözlemlenebilirlik platforma dönüşüyorsa, “araç yığını” bir dizi nokta çözüm olmaktan çıkar ve paylaşılan altyapı gibi davranmaya başlar. Bu değişim, araç yaygınlaşmasını basit bir sıkıntı olmaktan çıkarır: enstrümantasyonun tekrarlanması, tutarsız tanımlar (hata nedir?) ve on-call yükünün artması—çünkü sinyaller loglar, metrikler, trace'ler ve olaylar arasında uyuşmaz.
Konsolidasyon otomatik olarak “her şey için tek satıcı” anlamına gelmez. Daha az kayıt sistemi, daha net sahiplik ve kesinti sırasında bakılması gereken daha az yer demektir.
Konsolidasyonun gerçekte çözdükleri
Araç yaygınlaşması genellikle üç yerde gizli maliyet yaratır: UI'lar arasında zaman kaybı, bakım gereken kırılgan entegrasyonlar ve parçalanmış yönetişim (adlandırma, etiketleme, saklama, erişim). Daha konsolide bir platform yaklaşımı bağlam geçişini azaltır, servis görünümlerini standardize eder ve olay iş akışlarını tekrarlanabilir kılar.
Karar kontrol listesi (hızlı ama pratik)
Yığınınızı değerlendirirken (Datadog veya alternatifler dahil) bunları sorgulayın:
- Olmazsa olmaz entegrasyonlar: bulut sağlayıcı, Kubernetes, CI/CD, olay yönetimi, paging ve kilit veri depoları—ve teslimat için "şimdi ship edemeyiz" dedirten iş sistemleri.
- İş akışları: uyarı → sahip → runbook → zaman çizelgesi → postmortem adımlarını manuel kopyala/yapıştır olmadan yapabiliyor musunuz?
- Yönetişim: etiketleme standartları, erişim kontrolleri, saklama ve pano/monitör yayılmasına karşı korumalar.
- Fiyatlandırma modeli: maliyeti ne tetikler (hostlar, container'lar, alınan loglar, indekslenen trace'ler)? Büyümeyi sürpriz olmadan öngörebilir misiniz?
Net bir başarı metriğiyle pilot çalışması yapın
Gerçek trafik olan bir veya iki servis seçin. Tek bir başarı metriği tanımlayın—ör. “kök nedeni belirleme süresi 30 dakikadan 10 dakikaya düşsün” veya “gürültülü uyarıları %40 azalt”. Sadece ihtiyaç duyduğunuzu enstrümente edin ve iki hafta sonra sonuçları gözden geçirin.
İç öğrenmeyi bir yerde toplayın—pilot runbook, etiket kuralları ve panoları merkezi bir dokümanda (örneğin gözlemlenebilirlik temelleri) bağlayın.
Kopyala/yapıştır Uygulanabilir Bir Benimseme Planı
Datadog'u bir kere "kurmazsınız". Küçük başlarsınız, standartları erken belirlersiniz, sonra işe yarayanı ölçeklersiniz.
30/60/90 günlük rollout
Gün 0–30: Onboard (hızla değeri kanıtlayın)
1–2 kritik servis ve bir müşteri yolculuğu seçin. Logları, metrikleri ve trace'leri tutarlı şekilde enstrümente edin ve zaten kullandığınız entegrasyonları bağlayın (bulut, Kubernetes, CI/CD, on-call).
Gün 31–60: Standardize (tekrarlanabilir hale getirin)
Öğrendiklerinizi varsayılanlara dönüştürün: servis adlandırma, etiketleme, pano şablonları, monitör adlandırma ve sahiplik. Altın sinyaller görünümleri oluşturun (latency, trafik, hatalar, doygunluk) ve en önemli uç noktalar için minimal SLO seti tanımlayın.
Gün 61–90: Ölçeklendir (kaosa izin vermeden genişletin)
Aynı şablonları kullanarak ek takımları onboard edin. Yönetişimi (etiket kuralları, zorunlu meta veri, yeni monitörler için inceleme süreci) uygulamaya başlayın ve platform sağlıklı kalsın diye maliyet vs kullanım takibini başlatın.
Koder.ai nerede uyar (pragmatik olarak)
Gözlemlenebilirliği platform olarak ele aldığınızda genellikle bunun etrafında küçük “yapıştırıcı” uygulamalar istersiniz: bir servis katalogu UI'si, runbook hub, olay zaman çizelgesi sayfası veya sahipleri → panolar → SLO'lar → playbook'ları bağlayan dahili bir portal.
Bunlar, genellikle chat üzerinden web uygulamaları üretebilen ve frontend'te React, backend'te Go + PostgreSQL gibi yaygın yığınları destekleyen Koder.ai gibi hafif araçlarla hızla prototiplenip dağıtılabilir. Ekipler bunu yönetişimi ve iş akışlarını kolaylaştıran operasyonel yüzeyleri hızlıca üretmek için kullanır, büyük bir ürün ekibini roadmap'ten çekmeden.
Bir haftada gönderilecek hızlı kazanımlar
- kullanılabilirlik, hata oranı, latency, doygunluk ve kilit bağımlılıklar için İlk 10 monitör
- panolarda ve trace'lerde anında değişiklik korelasyonu için deploy marker'ları (CI/CD'den)
- ne oldu, etki, zaman çizelgesi, sahipler, panolar/sorgular için linkler ve sonraki adımlar içeren olay şablonu
Tutacak eğitim
İki 45 dakikalık oturum düzenleyin: (1) “Burada nasıl sorgularız”—paylaşılan sorgu kalıpları ile (servise, env'e, bölgeye, versiyona göre) ve (2) “Sorun giderme playbook'u”—basit bir akış: etkiyi doğrula → deploy marker'ları kontrol et → servisi daralt → trace'leri incele → bağımlılık sağlığını doğrula → rollback/müdahale kararı.
Kopyala/yapıştır kontrol listesi