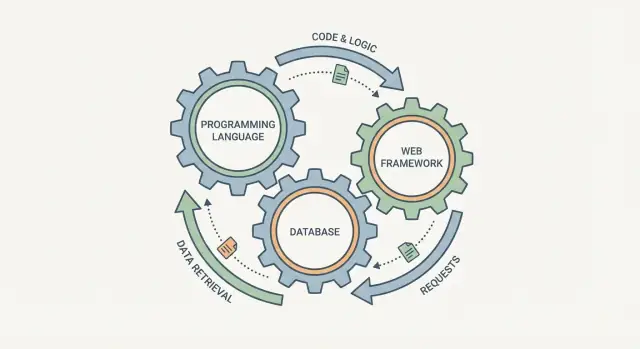
Neden Bunlar Ayrı Seçimler Değil\n\nProgramlama dili, veritabanı ve web çerçevesini üç bağımsız onay kutusu gibi seçmek cazip gelebilir. Gerçekte, bunlar birbirine geçen dişliler gibidir: birini değiştirirsiniz, diğerleri bunu hisseder.\n\nBir web framework isteklerin nasıl işlendiğini, verinin nasıl doğrulandığını ve hataların nasıl gösterildiğini etkiler. Veritabanı “kolayca saklanabilecek” şeyin ne olduğunu, bilgiyi nasıl sorgulayacağınızı ve birden çok kullanıcının aynı anda davrandığında hangi garantileri alacağınızı belirler. Dil, bunun ortasında durur: kuralları ne kadar güvenli ifade edebileceğinizi, eşzamanlılığı nasıl yöneteceğinizi ve hangi kütüphane ile araç setlerine güvenebileceğinizi belirler.\n\n### “Tek sistem” ne anlama geliyor\n\nYığını tek bir sistem olarak ele almak, her parçayı izole optimize etmediğiniz anlamına gelir. Bir kombinasyon seçersiniz ki:\n\n- Verinizi doğal şekilde temsil etsin (sürekli dönüşümlerle uğraşmayın)\n- Tutarlılık ihtiyaçlarınızı desteklesin (hatalar kenar durumlarında saklanmasın)\n- Ekibinizin iş akışına uyum sağlasın (gönderme ve bakım öngörülebilir olsun)\n\nBu yazı pratik kalır ve kasıtlı olarak çok teknik olmaktan kaçınır. Veritabanı teorisini veya dil iç yapısını ezberlemeniz gerekmez—sadece seçimlerin tüm uygulama boyunca nasıl dalga etkisi yarattığını görün.\n\nKısa bir örnek: çok yapılandırılmış, rapor ağırlıklı iş verisi için şemasız bir veritabanı kullanmak genellikle kuralların uygulama koduna dağılmasına ve sonrasında kafa karıştırıcı analizlere yol açar. Aynı alanı ilişkisel bir veritabanı ve tutarlı doğrulamaları ile göçleri teşvik eden bir framework ile eşleştirmek daha iyi uyum sağlar; böylece ürün gelişirken veriniz tutarlı kalır.\n\nYığını birlikte planladığınızda, üç ayrı bahisten ziyade bir takas seti tasarlamış olursunuz.\n\n## Basit Bir Zihinsel Model: İstek Girer, Veri Çıkar\n\nYığını “boru hattı” olarak düşünmek yardımcı olur: bir kullanıcı isteği sisteminize girer ve bir yanıt (artı saklanan veri) çıkar. Programlama dili, web framework ve veritabanı bağımsız seçimler değildir—aynı yolculuğun üç parçasıdır.\n\n### Tek bir isteğin yolculuğu\n\nBir müşterinin teslimat adresini güncellediğini hayal edin.\n\n1. İstek girer: Framework bir HTTP isteğini alır. Yönlendirme hangi işleyicinin çalışacağını belirler (örn. /account/address). Doğrulama girdinin eksiksiz ve makul olduğunu kontrol eder.\n2. İş yapılır: Uygulama kodunuz (seçtiğiniz dilde yazılmış) iş kurallarını çalıştırır: “Kullanıcı giriş yapmış mı?”, “Bu adres formatı kabul edilebilir mi?”, “Bu siparişi yeniden kontrol için işaretlemeli miyiz?”\n3. Veri çıkar: Veritabanı katmanı kayıtları okur ve yazar—çoğunlukla bir transaction içinde—böylece güncelleme ya tamamen uygulanır ya da hiç uygulanmaz.\n4. Yanıt çıkar: Framework sonucu (HTML/JSON) biçimlendirir, durum kodlarını ayarlar ve kullanıcıya döner.\n5. Sonrasında: Arka plan işler çalışabilir (onay e-postası gönderme, arama indeksini güncelleme, depo bildirme).\n\n### Her bir seçimin gerçekten sorumlu olduğu şey\n\n- Dil: Kodun nasıl çalıştığı (runtime/eşzamanlılık modeli), test ve hata ayıklamanın ne kadar kolay olduğu, ekibinizin becerileri ve araçların değişiklikleri ne kadar güvenli ve hızlı yapacağı.\n- Framework: İstekler için “trafik kontrolü”—yönlendirme, doğrulama, kimlik doğrulama kancaları, hata işleme ve yerleşik arka plan işi desenleri.\n- Veritabanı: Verinin nasıl saklandığı ve sorgulandığı, kötü veriyi hangi kısıtların engellediği ve transactionların ilgili güncellemeleri nasıl tutarlı tuttuğu.\n\nBu üçü uyumlu olduğunda, bir istek temiz akar. Uyumlu olmadıklarında sürtünme çıkar: garip veri erişimi, sızan doğrulamalar ve ince tutarlılık hataları.\n\n## Veri Modeli Öncelikli: Yığının Uyumunu Gizlice Belirleyen\n\nÇoğu “yığın” tartışması dil veya veritabanı markasıyla başlar. Daha iyi bir başlangıç noktası veri modelinizdir—çünkü bu, doğrulama, sorgular, API'ler, göçler ve hatta ekip iş akışı dahil olmak üzere her yerde neyin doğal (veya acı verici) olacağını sessizce belirler.\n\n### Veri şekilleri: nesneler, satırlar, belgeler, olaylar\n\nUygulamalar genellikle dört şekli aynı anda idare eder:\n\n- Kod içindeki nesneler (sınıflar, struct'lar, tipli kayıtlar)\n- İlişkisel tablolardaki satırlar\n- JSON tarzı depolama ya da API'lerdeki dokümanlar\n- Log/stream içindeki olaylar (“OrderPlaced”, “EmailSent”)\n\nİyi bir uyum, gün boyunca şekiller arasında çeviri yapmak zorunda kalmadığınız zamandır. Çekirdek veriniz çok bağlıysa (kullanıcılar ↔ siparişler ↔ ürünler), satırlar ve join'ler mantığı basit tutabilir. Veriniz çoğunlukla “her varlık için bir blob” ve değişken alanlara sahipse, dokümanlar töreni azaltabilir—ta ki çapraz varlık raporlamaya ihtiyaç duyana kadar.\n\n### Şema vs esnek yapı (ve kuralların nerede yaşadığı)\n\nVeritabanı güçlü bir şemaya sahipse birçok kural veriye yakın yerde yaşayabilir: tipler, kısıtlar, yabancı anahtarlar, benzersizlik. Bu genellikle servisler arasında çoğaltılmış kontrolleri azaltır.\n\nEsnek yapıda kurallar yukarı, uygulama katmanına kayar: doğrulama kodu, sürümlü yükler, backfill'ler ve dikkatli okuma mantığı (“alan varsa, sonra…”). Bu ürün gereksinimleri haftalık değiştiğinde işe yarayabilir, ama framework ve test yükünü artırır.\n\n### Modelleme seçimlerinin kod karmaşıklığına etkisi\n\nModeliniz kodunuzun çoğunlukla ne yaptığına karar verir:\n\n- Sorgulama ve join'ler (ilişkisel-ağırlıklı)\n- İç içe JSON dönüşümleri (doküman-ağırlıklı)\n- Olayları yeniden oynatma ve toplama (olay-ağırlıklı)\n\nBu da dil ve framework ihtiyaçlarını etkiler: güçlü tipleme JSON alanlarındaki ince sürüklenmeyi önleyebilirken, olgun göç araçları şemalar sık değişiyorsa daha önemli olur.\n\n### Örnekler: kullanıcı profili, siparişler, denetim kaydı\n\n- Kullanıcı profili: genellikle doküman-benzeri (tercihler, isteğe bağlı alanlar) ama kimlik ve benzersizlik için ilişkisel kısıtlardan fayda sağlar.\n- Siparişler: genellikle ilişkisel (satır öğeleri, toplamlar, durumlar) çünkü tutarlılık ve raporlama önemlidir.\n- Denetim kaydı: doğal olarak olay biçimli—nadiren güncellenen, zaman/öznitelik/varlığa göre sorgulama için optimize edilmiş ekleme-odaklı kayıtlar.\n\nModeli önce seçin; “doğru” framework ve veritabanı seçimi genellikle bundan sonra daha netleşir.\n\n## Transactionlar ve Tutarlılık: Hataların Sık Başladığı Yer\n\nTransactionlar uygulamanızın sessizce dayandığı “hepsi veya hiçbiri” garantileridir. Bir ödeme işlemi başarılı olduğunda, sipariş kaydı, ödeme durumu ve stok güncellemesinin ya hepsinin ya da hiçbirinin gerçekleşmesini beklersiniz. Bu vaat olmadan en zor tür hatalar ortaya çıkar: nadir, pahalı ve tekrarlanması zor.\n\n### Transactionlar gerçekte ne yapar\n\nBir transaction birden fazla veritabanı işlemini tek bir iş birimi olarak gruplar. Orta kısımda bir şey başarısız olursa (doğrulama hatası, zaman aşımı, işlem çökmesi), veritabanı önceki güvenli duruma geri dönebilir.\n\nBu para akışlarının ötesinde önemlidir: hesap oluşturma (kullanıcı satırı + profil satırı), içerik yayınlama (gönderi + etiketler + arama indeks göstergeleri) veya birden çok tabloyu etkileyen herhangi bir iş akışı gibi.\n\n### Tutarlılık vs hız (basitçe)\n\nTutarlılık “okumaların gerçeklikle eşleşmesi” demektir. Hız “bir şeyi hızlı döndürme” demektir. Birçok sistem burada ödünler verir:\n\n- Güçlü tutarlılık: kullanıcılar en son commit edilmiş veriyi görür, daha az sürpriz, genellikle daha yüksek koordinasyon maliyeti\n- Nihai tutarlılık: güncellemeler zaman içinde yayılır, genelde daha hızlı ve ölçeklemesi kolaydır, ancak uygulamanız geçici tutarsızlıklarla başa çıkmalıdır\n\nYaygın hata deseni, nihai tutarlılık seçip sonra sanki güçlü tutarlılık varmış gibi kod yazmaktır.\n\n### Frameworkler ve ORM'ler sonuçları nasıl etkiler\n\nFrameworkler ve ORM'ler birden fazla save çağırdınız diye otomatik olarak transaction oluşturmaz. Bazıları açık transaction blokları gerektirir; بعضları ise istek başına bir transaction başlatır ki bu da performans sorunlarını gizleyebilir.\n\nTekrarlar da karmaşıktır: ORM'ler deadlock veya geçici hatalarda yeniden deneme yapabilir, ama kodunuz iki kez çalıştırılmaya uygun olmalıdır.\n\n### Yaygın tuzaklar\n\nKısmi yazımlar, A'yı güncelledikten sonra B güncellenemediğinde olur. Yinelenen işlemler, bir istek zaman aşımından sonra yeniden denendiğinde (özellikle bir kartı çektiyseniz veya e-posta gönderdiyseniz) ortaya çıkar.\n\nBasit bir kural yardımcı olur: yan etkileri (e-postalar, webhooklar) database commit'inden sonra yapın ve benzersizlik kısıtları veya idempotency anahtarları kullanarak işlemleri tekrarlanabilir hale getirin.\n\n## Veritabanı Erişim Katmanı: ORM, Sorgular ve Göçler\n\nBu, uygulama kodunuz ile veritabanınız arasındaki “çeviri katmanıdır”. Buradaki seçimler genellikle günlük işte veritabanı markasından daha fazla fark yaratır.\n\n### ORM vs sorgu oluşturucu vs ham SQL (basitçe)\n\nBir ORM (Object-Relational Mapper) tabloları nesne gibi ele almanızı sağlar: bir User oluşturun, bir Post güncelleyin ve ORM arka planda SQL üretir. Bu üretkenlik sağlayabilir çünkü ortak görevleri standardize eder ve tekrarlı altyapıyı gizler.\n\nBir sorgu oluşturucu daha açıklayıcıdır: bir SQL-benzeri sorguyu kodla (zincirler veya fonksiyonlar) inşa edersiniz. Hâlâ “join'ler, filtreler, gruplar” düşünürsünüz ama parametre güvenliği ve bileşenlik elde edersiniz.\n\nHam SQL gerçek SQL'i kendiniz yazmaktır. Karmaşık raporlama sorguları için çoğunlukla en doğrudan ve en net olandır—daha fazla elle iş ve konvansiyon gerektirir.\n\n### Dil özellikleri erişim desenlerini nasıl şekillendirir\n\nGüçlü tiplemeye sahip diller (TypeScript, Kotlin, Rust) genellikle sorguları ve sonuç şekillerini erken doğrulayabilecek araçlara yönlendirir. Bu çalışma zamanındaki sürprizleri azaltabilir, ama aynı zamanda tiplerin sürüklenmemesi için veri erişimini merkezileştirmeye baskı yapar.\n\nRuby, Python gibi esnek metaprogramlama sunan diller ORMs'i doğal ve hızlı iterasyona uygun hissettirir—ta ki gizli sorgular veya örtük davranışlar zor anlaşılır olana kadar.\n\n### Göçler: kod ve şemayı senkron tutmak\n\nGöçler şemanız için versiyonlanmış değişiklik betikleridir: bir kolon ekle, indeks oluştur, veriyi doldur. Amaç basittir: herkes uygulamayı deploy ettiğinde aynı veritabanı yapısına sahip olsun. Göçleri gözden geçirilmesi, test edilmesi ve gerektiğinde geri alınması/ilerletilmesi gereken kod olarak ele alın.\n\n### “Kolay” soyutlamalar zarar verdiğinde\n\nORM'ler gizlice N+1 sorguları üretebilir, ihtiyacınız olmayan büyük satırları çekebilir veya join'leri garipleştirebilir. Sorgu oluşturucular okunaksız “zincirlere” dönüşebilir. Ham SQL çoğaltılabilir ve tutarsız hale gelebilir.\n\nİyi bir kural: niyeti açık tutacak en basit aracı kullanın—ve kritik yollar için gerçekten çalışan SQL'i inceleyin.\n\n## Performans Sistem Özelliğidir, Veritabanı Özelliği Değil\n\nBir sayfanın yavaş hissetmesinin sorumlusu genellikle “veritabanı” değildir. Kullanıcıya görünen gecikme, genellikle tüm istek yolundaki küçük beklemelerin toplamıdır.\n\n### Gecikme gerçekten nereden gelir\n\nTek bir istek tipik olarak şunların bedelini öder:\n\n- Ağ zamanı (istemci → load balancer → uygulama → veritabanı ve geri)\n- Sorgu zamanı (yavaş SQL, eksik indeks, çok fazla round trip)\n- Serileştirme/deserileştirme (JSON kodlama, ORM nesne eşleme, sıkıştırma)\n- Uygulama mantığı (doğrulama, izinler, şablon render, harici API çağrıları)\n\nVeritabanınız 5 ms cevap veriyor olsa bile, bir istek 20 sorgu yapıyorsa, I/O'da engelleniyor veya büyük bir yanıtı 30 ms içinde serileştiriyorsa hala yavaş hissedilir.\n\n### Bağlantı havuzlama: sessiz performans çarpanı\n\nYeni bir veritabanı bağlantısı açmak pahalıdır ve yük altında veritabanını bunaltabilir. Bir bağlantı havuzu mevcut bağlantıları yeniden kullanır, böylece istekler bu kurulum maliyetini tekrar tekrar ödemez.\n\nYakalanacak nokta: “doğru” havuz boyutu runtime modelinize bağlıdır. Yüksek eşzamanlı async sunucu büyük eşzamanlı talep oluşturabilir; havuz sınırları yoksa kuyruklanma, zaman aşımı ve gürültülü hatalar yaşarsınız. Çok sıkı havuz limitleri ise uygulamayı darboğaz yapar.\n\n### Önbellekleme: neyi düzeltir—neyi düzeltmez\n\nÖnbellekleme tarayıcıda, CDN'de, süreç içi önbellekte veya paylaşılan önbellekte (Redis gibi) olabilir. Aynı sonuca ihtiyaç duyan birçok istek olduğunda yardımcı olur.\n\nAma önbellekleme kurtaramaz:\n\n- Verimsiz yazma yollarını\n- Çok kişiselleştirilmiş yanıtları\n- Harici API çağrılarının hakim olduğu yavaş uç noktaları\n\n### Runtime önemli: thread vs async\n\nProgramlama dili runtime'ınız verimliliği şekillendirir. İstek başına thread modelleri I/O beklerken kaynak israfına yol açabilir; async modeller eşzamanlılığı artırabilir ama backpressure (havuz limitleri gibi) kritik hale gelir. Bu yüzden performans ayarı bir yığın kararıdır, yalnızca veritabanı kararı değil.\n\n## Güvenlik ve Güvenilirlik: Yığının Paylaşılan Sorumluluğu\n\nGüvenlik, bir framework eklentisi veya veritabanı ayarıyla “eklenebilecek” bir şey değildir. Dil/runtime, web framework ve veritabanı arasında bir anlaşmadır: bir geliştirici hata yaptığında veya yeni bir uç nokta eklendiğinde neyin her zaman doğru olması gerektiği.\n\n### Kimlik doğrulama vs yetkilendirme: Farklı katmanlar, aynı sonuç\n\nKimlik doğrulama (bu kim?) genellikle framework kenarında yaşar: oturumlar, JWT, OAuth callback'leri, middleware. Yetkilendirme (ne yapmasına izin var?) hem uygulama mantığında hem de veri kurallarında tutarlı şekilde uygulanmalıdır.\n\nYaygın bir desen: uygulama niyeti belirler (“kullanıcı bu projeyi düzenleyebilir”), veritabanı sınırları uygular (tenant ID'leri, sahiplik kısıtları ve mantıklı yerlerde satır düzeyi politikalar). Eğer yetkilendirme sadece controller'larda varsa, arka plan işler ve iç betikler bunu kazara atlayabilir.\n\n### Doğrulama: Framework, veritabanı veya her ikisi?\n\nFramework doğrulaması hızlı geri bildirim ve iyi hata mesajları sağlar. Veritabanı kısıtları son güvenlik ağı sağlar.\n\nÖnemli olduğunda her ikisini de kullanın:\n\n- Framework: zorunlu alanlar, format kontrolü, kullanıcı dostu mesajlar.\n- Veritabanı: benzersizlik, yabancı anahtarlar, CHECK kısıtları, NOT NULL.
\nBu, iki istek yarıştığında veya yeni bir servis veriyi farklı yazdığında ortaya çıkan “imkansız durumları” azaltır.\n\n### Gizli bilgiler, şifreleme ve denetim\n\nGizli bilgiler runtime ve dağıtım iş akışı (env değişkenleri, gizli yönetimi) tarafından yönetilmelidir; kodda veya göçlerde sabit kodlanmamalıdır. Şifreleme uygulama tarafında (alan düzeyi şifreleme) ve/veya veritabanında (disk üzerinde şifreleme, yönetilen KMS) olabilir; ancak anahtarları kim döndürecek, kim değiştirecek ve kurtarma nasıl olacak gibi sorular net olmalıdır.\n\nDenetim de paylaşılan bir iştir: uygulama anlamlı olaylar üretmeli; veritabanı gerektiğinde (örn. ekleme-odaklı denetim tabloları, kısıtlı erişim) değişmez kayıtlar tutmalıdır.\n\n### Tipik hata modları\n\nUygulama mantığına aşırı güven klasik hatadır: eksik kısıtlar, sessiz null'lar, kontrolsüz “admin” bayrakları. Çözüm basittir: hataların olacağını varsayın ve veritabanının güvensiz yazıları (kendi kodunuzdan bile) reddedebileceği şekilde tasarlayın.\n\n## Ölçeklenme Yolları: Her Seçimin Neyi Açtığı veya Kapadığı\n\nÖlçeklenme nadiren “veritabanı bunu kaldıramaz” yüzünden başarısız olur. Yığın yük değiştiğinde tüm parçaların nasıl tepki verdiği kötü olduğunda başarısız olur: bir uç nokta popülerleşir, bir sorgu hot olur, bir iş akışı tekrar etmeye başlar.\n\n### Trafik arttıkça acı belirli yerlerde ortaya çıkar\n\nÇoğu ekip aynı erken darboğazlarla karşılaşır:\n\n- bir “popüler sayfa” veya gösterge tablosu sorgusu sürekli çalışır ve CPU/IO'yu domine eder.\n- güncellemeler birkaç satırın arkasında yığılır (stok sayacı, “last_seen”, kuyruk tabloları), her şeyi yavaşlatır.\n- uygulama işçileri çok fazla DB bağlantısı açar; veritabanı oturum yönetimiyle uğraşmak zorunda kalır.\n\nHızla cevap verebilmeniz, framework ve veritabanı araçlarının sorgu planlarını, göçleri, bağlantı havuzlamayı ve güvenli önbellekleme desenlerini ne kadar iyi gösterdiğine bağlıdır.\n\n### Okuma replika, shard'lama ve kuyruklar: ne zaman ortaya çıkar\n\nOrtak ölçek hamleleri genellikle şu sırayla gelir:\n\n1. okumalar yazılardan çoksa ve hafifçe eski veriyi tolere edebiliyorsanız. ORM/framework'ünüzün okuma/yazma ayrımını desteklemesi ya da sorguları yönlendirmeyi kolaylaştırması gerekir.\n2. istek gecikmesine zarar verdiğinde (e-postalar, dışa aktarımlar, fatura çağrıları). Burada tekrarlar ve çoğaltma önleme (deduplication) gerçek gereksinimler olur.\n3. tek bir primary yazma veya depolama kapasitesinin yetmediğinde. Bu dikkatli veri modelleme ister: shard anahtarları, çapraz-shard sorgular ve transaction sınırları.\n\n### Arka plan işler ve idempotency framework özellikleridir, sonradan eklenmemelidir\n\nÖlçeklenebilir bir yığın, arka plan görevleri, zamanlama ve güvenli yeniden denemeler için birinci sınıf desteğe ihtiyaç duyar.\n\nİş sistemi sağlayamıyorsa (aynı iş iki kez çalıştığında çift ücretlendirme veya çift gönderim olmuyorsa), ölçeklendikçe veri bozulmasına doğru gidersiniz. Erken seçimler—örtük transactionlara, zayıf benzersizlik kısıtlarına veya opak ORM davranışlarına güvenmek—kuyruklar, outbox desenleri veya neredeyse-tek seferlik iş akışlarının temiz şekilde tanıtılmasını engelleyebilir.\n\nErken uyum kazandırır: tutarlılık ihtiyaçlarınıza uygun bir veritabanı seçin ve bir sonraki ölçek adımını (replikalar, kuyruklar, partitioning) destekleyen bir framework ekosistemi seçin; böylece yeniden yazım yerine düzgün bir yolunuz olsun.\n\n## Geliştirici Deneyimi ve Operasyon: Tek Bir İş Akışı\n\nBir yığın “kolay” hissettirir when geliştirme ve operasyon aynı varsayımları paylaştığında: uygulamayı nasıl başlattığınız, verinin nasıl değiştiği, testlerin nasıl çalıştığı ve bir şeyler bozulduğunda nasıl anlayacağınız. Bu parçalar uyumlu değilse ekipler yapıştırıcı kod, kırılgan betikler ve manuel runbook'larla zaman kaybeder.\n\n### Yerel geliştirme hızı\n\nHızlı yerel kurulum bir özelliktir. Yeni bir ekip üyesinin klonlayıp, kurup, göçleri çalıştırıp, gerçekçi test verisine birkaç dakikada (saat değil) ulaşabilmesi tercih edilir.\n\nBu genellikle şunları gerektirir:\n\n- Bağımlılıklarıyla uygulamayı ayağa kaldırmak için tek komut (genellikle konteynerler aracılığıyla).\n- Her makinede güvenilirce çalıştırılabilen göçler.\n- Üretim şeklini yansıtan seed verisi (sadece “hello world” satırları değil).\n\nFramework'ünüzün göç araçları veritabanı seçiminizle çatışıyorsa her şema değişikliği küçük bir proje olur.\n\n### Yığınla uyumlu test piramidi\n\nYığınınız doğal olarak şunları yazmayı kolaylaştırmalı:\n\n- veritabanı gerektirmeyenler\n- gerçek veritabanı şeması ve sorgularını vuranlar\n- tam istek yolunu egzersiz edenler\n\nYaygın bir hata: ekipler entegrasyon testleri yavaş veya kurulumu zor olduğu için birim testlerine fazla güvenir. Bu genellikle yığın/operasyon uyumsuzluğudur—test veritabanı tedariki, göçler ve fixture'lar kolaylaştırılmamıştır.\n\n### Gözlemlenebilirlik: uygulama ile veritabanı arasında iz sürme\n\nGecikme arttığında bir isteği frameworkten veritabanına kadar izleyebilmelisiniz.\n\nTutarlı , temel (istek oranı, hatalar, DB zamanı) ve sorgu zamanlamasını içeren arayın. Basit bir korelasyon ID'si bile uygulama loglarında ve veritabanı loglarında varsa tahmin etmeyi bulmaya çevirebilir.\n\n### Operasyonel uyum: güvenli değişiklik ve kurtarma\n\nOperasyon geliştirmeden ayrı değildir; onun devamıdır.\n\nAraçları şu konularda destekleyenleri seçin:\n\n- Test edilmiş (yalnızca yapılandırılmış değil)