21 Eyl 2025·6 dk
Düşük gecikme için Disruptor deseni: öngörülebilir gerçek zamanlı tasarım
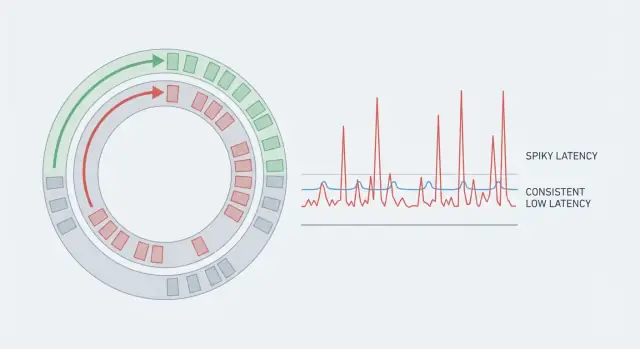
Disruptor desenini düşük gecikme için öğrenin ve kuyruklar, bellek ve mimari seçimlerle öngörülebilir yanıt sürelerine sahip gerçek zamanlı sistemleri nasıl tasarlayacağınızı keşfedin.