26 Kas 2025·7 dk
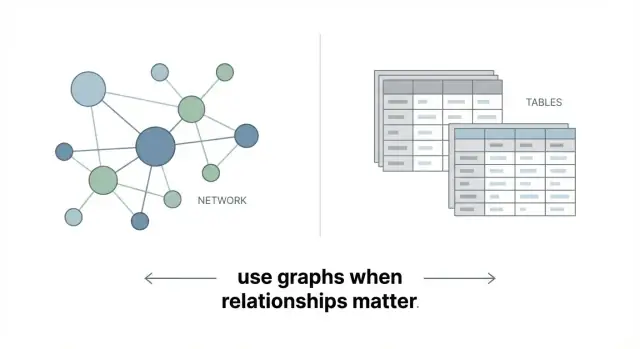
Graf Veritabanları İlişkilerde Neden Üstündür — Her Şey İçin Değil
Bağlantıların sorularınızı yönlendirdiği durumlarda graf veritabanları parlıyor. En uygun kullanım durumlarını, takasları ve ne zaman ilişkisel veya doküman tabanlı veritabanlarının daha uygun olduğunu öğrenin.