12 Eyl 2025·4 dk
Gün bir için üretim izlenebilirliği başlangıç paketi
Gün bir için üretim izlenebilirliği başlangıç paketi: eklemeniz gereken asgari loglar, metrikler ve izler ile “yavaş” raporları için basit bir triage akışı.
Gün bir için üretim izlenebilirliği başlangıç paketi: eklemeniz gereken asgari loglar, metrikler ve izler ile “yavaş” raporları için basit bir triage akışı.
Genelde tüm uygulama birden gözden kaybolmaz. Çoğunlukla bir adım aniden yoğunlaşır, testlerde sorunsuz olan bir sorgu üretimde takılır veya bir bağımlılık zaman aşımına girer. Gerçek kullanıcılar gerçek çeşitlilik getirir: daha yavaş telefonlar, dalgalanan ağlar, beklenmedik girişler ve uygun olmayan zamanlardaki trafik sıçramaları.
Birisi “yavaş” dediğinde çok farklı şeylerden bahsediyor olabilir. Sayfa çok uzun sürede yükleniyor olabilir, etkileşimler gecikiyor olabilir, bir API çağrısı zaman aşımına uğruyor olabilir, arka plan işler birikiyor olabilir veya üçüncü taraf bir servis her şeyi yavaşlatıyor olabilir.
Bu yüzden panolardan önce sinyallere ihtiyacınız var. İlk gün, her uç nokta için mükemmel grafiklere gerek yok. Zamanın nereye gittiğini hızlıca cevaplayacak kadar log, metrik ve iz yeterlidir.
Erken aşamada aşırı enstrümantasyonun da gerçek bir riski vardır. Çok fazla etkinlik gürültü yaratır, maliyet getirir ve uygulamayı yavaşlatabilir. Daha da kötüsü, ekipler telemetriye güvenmeyi bırakır çünkü dağınık ve tutarsız hisseder.
Gerçekçi bir gün-bir hedefi basit olmalı: bir “yavaş” raporu geldiğinde, 15 dakikadan kısa sürede yavaş adımı bulabilmelisiniz. Tıkanmanın istemci render'ında mı, API handler ve bağımlılıklarında mı, veritabanı/önbellekte mi yoksa arka plan işlerinde/dış serviste mi olduğunu söyleyebilmelisiniz.
Örnek: yeni bir ödeme akışı yavaş hissediliyor. Dağ gibi araçlar olmadan bile “zamanın %95'i ödeme sağlayıcı çağrılarında” veya “sepet sorgusu çok fazla satır tarıyor” diyebilmek istersiniz. Koder.ai gibi araçlarla hızlıca uygulama geliştiriyorsanız bu gün-bir temel daha da önemli olur; çünkü hızlı göndermek, hızlı debug edebildiğinizde işe yarar.
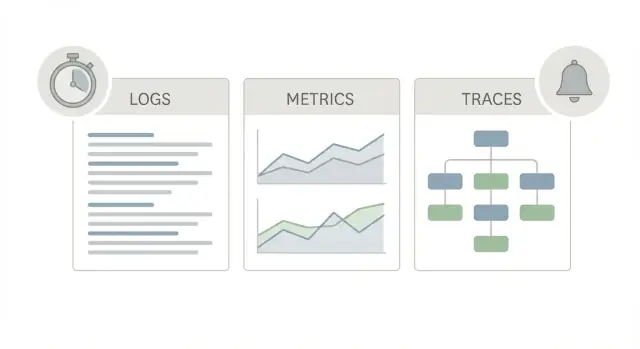
İyi bir üretim izlenebilirliği başlangıç paketi aynı uygulamanın üç farklı “görünümünü” kullanır; çünkü her biri farklı bir soruya yanıt verir.
Loglar hikayedir. Bir istek, bir kullanıcı veya bir arka plan işi için ne olduğunu söyler. Bir log satırı “order 123 için ödeme başarısız” veya “DB zaman aşımı 2s sonra” gibi ifadeler içerebilir; ayrıca request_id, user_id ve hata mesajı gibi detaylar da bulunur. Garip tekil bir sorun rapor edildiğinde, loglar genellikle bunun olup olmadığını ve kimi etkilediğini doğrulamanın en hızlı yoludur.
Metrikler skor tablosudur. Trendleyip alarmla besleyebileceğiniz sayılardır: istek hızı, hata oranı, gecikme yüzdelikleri, CPU, kuyruk derinliği. Metrikler bir şeyin nadir mi yoksa yaygın mı olduğunu ve kötüleşip kötüleşmediğini gösterir. Eğer gecikme herkes için 10:05’te arttıysa, metrikler bunu gösterecektir.
İzler (traces) haritadır. Bir trace tek bir isteği sisteminizde takip eder (web -> API -> veritabanı -> üçüncü taraf). Zamanın hangi adımda harcandığını adım adım gösterir. Çünkü “yavaş” neredeyse hiç büyük bir gizem değildir; genelde tek bir yavaş halka vardır.
Bir olay sırasında pratik bir akış şöyle görünür:
Basit bir kural: birkaç dakika sonra tek bir darboğaz işaret edemiyorsanız, daha fazla alarm eklemeye değil, daha iyi izlere ve izleri loglara bağlayan tutarlı ID'lere ihtiyacınız var.
Çoğu “bulamıyoruz” vakası verinin eksikliğinden ziyade aynı şeyin hizmetler arasında farklı şekilde kaydedilmesinden kaynaklanır. Gün birde birkaç ortak kural logların, metriklerin ve izlerin hızlıca hizalanmasını sağlar.
Başlamak için her deploy edilebilir birim için tek bir servis adı seçin ve bunu sabit tutun. Eğer checkout-api panoların yarısında checkout oluyorsa geçmişi kaybedersiniz ve alarmlar bozulur. Ortam etiketleri için de aynı şeyi yapın: küçük bir set seçin (prod ve staging gibi) ve her yerde kullanın.
Sonra her isteği takip etmeyi kolaylaştırın. Kenarda (API gateway, web sunucusu veya ilk handler) bir request_id oluşturun ve bunu HTTP çağrıları, mesaj kuyrukları ve arka plan işlerinde iletin. Bir destek bileti “10:42’de yavaşladı” diyorsa, tek bir ID ile tam logları ve trace'i tahmin etmeden çekebilirsiniz.
Gün birde işe yarayan bir kural seti:
request_id\n- Temel etiketler: rota (veya handler), method, status code, ve çok kiracılı iseniz tenant/org ID\n- İzleme operasyonları: operasyon adlarını endpoint veya arka plan işleri olarak adlandırın (rastgele fonksiyon isimleri değil)\n- Tutarlılık: tek bir isimlendirme stili ve zaman birimiZaman birimlerinde erken anlaşın. API gecikmesi için milisaniye, uzun işler için saniye seçin ve ona bağlı kalın. Karışık birimler görsellerin iyi görünmesine rağmen yanlış hikaye anlatır.
Somut örnek: her API duration_ms, route, status ve request_id logluyorsa, “tenant 418 için checkout yavaş” gibi bir rapor hızlıca filtrelenir, tartışma değil.
Eğer tek bir şey yapacaksanız logları aranabilir yapın. Bu yapılandırılmış loglarla (genelde JSON) ve her hizmette aynı alanlarla başlar. Düz metin loglar yerelde yeterli olabilir ama gerçek trafik, retry'ler ve birden fazla instance olunca gürültüye dönüşür.
İyi bir kural: bir olay sırasında gerçekten kullanacağınız şeyleri loglayın. Çoğu ekip şu soruları yanıtlamalı: Bu hangi istekti? Bunu kim yaptı? Nerede başarısız oldu? Neye dokundu? Bir log satırı bu sorulardan birine yardımcı olmuyorsa büyük olasılıkla gereksizdir.
Gün bir için küçük ve tutarlı alan seti filtreleme ve servisler arası birleştirme yapmanızı sağlar:
request_id, varsa trace_id)\n- Kim/nerede (user_id veya session_id, rota, method)\n- Sonuç (status code, duration_ms)\n- Dağıtım bağlamı (region/instance, release veya commit)Bir hata olduğunda, onu bir kez bağlamla loglayın. Bir hata tipi (veya kod), kısa bir mesaj, sunucu hataları için stack trace ve ilişkili upstream bağımlılığı (ör. postgres, payment provider, cache) ekleyin. Aynı stack trace'i her retry'de tekrar etmekten kaçının; bunun yerine request_id ekleyin ki zinciri takip edebilin.
Örnek: bir kullanıcı ayarları kaydedemiyor diyor. Bir request_id araması PATCH /settings üzerinde 500 gösteriyor, sonra Postgres zaman aşımı ve duration_ms bulunuyor. Tam payloadlara gerek yoktu; rota, kullanıcı/oturum ve bağımlılık adı yeterliydi.
Gizlilik loglamanın bir parçasıdır, sonradan yapılacak bir iş değil. Parolaları, tokenları, auth header'ları, tam istek gövdelerini veya hassas PII'yı loglamayın. Kullanıcıyı tanımlamanız gerekiyorsa, e-posta veya telefon yerine sabit bir kimlik veya hash'lenmiş bir değer loglayın.
Koder.ai üzerinde uygulama inşa ediyorsanız (React, Go, Flutter), bu alanları her üretilen servise baştan dahil etmek yararlı olur; böylece ilk olay sırasında “loglamayı düzeltmek” zorunda kalmazsınız.
İyi bir başlangıç paketi, sistemin şu an sağlıklı olup olmadığını ve eğer değilse nerede sorun olduğunu hızlıca cevaplayan küçük bir metrik setiyle başlar.
Çoğu üretim sorunu dört “altın sinyal”den biri olarak görünür: latency (cevaplar yavaş), traffic (yük değişti), errors (başarısızlıklar) ve saturation (paylaşılan bir kaynak doldu). Uygulamanızın her ana parçası için bu dört sinyali görebiliyorsanız, çoğu olayı tahmin etmeden triage edebilirsiniz.
Gecikme yüzdelikler olmalı, ortalamalar değil. p50, p95 ve p99 takip edin ki küçük bir kullanıcı grubunun kötü deneyimini görsün. Trafik için istek/s veya worker'lar için işler/dk ile başlayın. Hatalar için 4xx ve 5xx'u ayırın: 4xx artışı genelde istemci davranışı veya doğrulamaya işaret eder; 5xx artışı uygulama veya bağımlılıklara işaret eder. Doyma, “bir şeyimizin tükeniyor” sinyalidir (CPU, bellek, DB bağlantıları, kuyruk backlog).
Çoğu uygulamayı kapsayan minimum set:
Somut örnek: kullanıcılar “yavaş” dediğinde API p95 yükselip trafik sabit kalıyorsa, doyma kontrolü için DB havuzu kullanımına bakın. Eğer DB havuzu maksimuma yakınsa ve zaman aşımı artıyorsa muhtemel darboğaz orasıdır. DB normal görünüyorsa ama kuyruk derinliği hızla artıyorsa arka plan işler kaynakları yiyor olabilir.
Koder.ai ile uygulama geliştiriyorsanız, bu checklist'i gün bir bitmişlik tanımınızın parçası olarak ele alın. Uygulama küçükken bu metrikleri eklemek, ilk gerçek olay sırasında eklemekten daha kolaydır.
Bir kullanıcı “yavaş” dediğinde loglar genelde ne olduğunu söyler, metrikler ne sıklıkta olduğunu gösterir. İzler ise bu isteğin içinde zamanın nereye gittiğini söyler. Bu tek zaman çizgisi bulanık bir şikayeti net bir düzeltmeye çevirmek için kritiktir.
Sunucu tarafından başlayın. Gelen istekleri uygulamanın ilk handler'ında instrument edin ki her istek bir trace üretebilsin. İstemci tarafı izleme bekleyebilir.
Gün bir için iyi bir trace, genelde slowness yaratan parçalara karşılık gelen span'lara sahip olur:
İzleri aranabilir ve karşılaştırılabilir kılmak için birkaç anahtar özniteliği tutarlı yakalayın.
Gelen istek spanı için route (şablon formunda), HTTP methodu, status kodu ve gecikmeyi kaydedin. DB spanları için DB sistemi (PostgreSQL, MySQL), işlem tipi (select, update) ve tablo adı eklenebilir. Dış çağrılarda bağımlılık adı (payments, email, maps), hedef host ve durum bilgisi olsun.
Örnekleme gün birde önemlidir; aksi halde maliyet ve gürültü hızla artar. Basit bir baş-temelli kural kullanın: tüm hataların ve yavaş isteklerin %100'ünü trace edin (SDK destekliyorsa) ve normal trafiğin küçük bir yüzdesini örnekleyin (1–10%). Trafik düşükken daha yüksek başlayın, sonra azaltın.
İyi bir görünüm: bir trace'te hikayeyi baştan sona okuyabiliyor olmanız. Örnek: GET /checkout 2.4s sürdü; DB 120ms, cache 10ms, dış ödeme çağrısı 2.1s ve retry içeriyordu. Artık sorun bağımlılıkta olduğu için doğru yere odaklanabilirsiniz. Bu, üretim izlenebilirliği başlangıç paketinin özü.
Birisi “yavaş” dediğinde en hızlı kazanç o belirsiz hissi birkaç somut soruya çevirmektir. Bu başlangıç paketi triage akışı uygulamanız çok yeni olsa bile işe yarar.
Sorunu daraltıp sonra kanıtı sırayla takip edin. Doğrudan veritabanına atlamayın.
Stabilize ettikten sonra bir küçük iyileştirme yapın: ne olduğunu yazın ve eksik olan bir sinyali ekleyin (ör. bölge etiketi, daha açıklayıcı sorgu etiketi vb.).
Kenardan (API gateway, web sunucusu veya ilk handler) başlayın.\n\n- Bir request_id ekleyin ve tüm iç çağrılara iletin.\n- Her istek için route, method, status ve duration_ms kaydedin.\n- Her rota için p95 gecikme ve 5xx oranını izleyin.\n\nBunlar genellikle sizi hızlıca belirli bir uç noktaya ve zaman aralığına götürür.
Varsayılan hedef şu olsun: 15 dakikadan kısa sürede yavaş adımı tespit edebilmelisiniz.\n\nİlk günde mükemmel panolara ihtiyacınız yok. Cevaplamanız gereken yeterli sinyal şu sorulara yanıt vermeli:\n\n- İstemci tarafı mı, API tarafı mı, veritabanı/önbellek mi, arka plan işleri mi yoksa dış bir bağımlılık mı soruna neden oluyor?\n- Hangi rota veya iş türü etkilendi?\n- Bu deploy veya konfigürasyon değişikliğinden sonra mı başladı?
Birlikte kullanın; her biri farklı soru cevaplar:\n\n- Metrikler: “Bu yaygın mı ve kötüleşiyor mu?” (oranlar, yüzdelikler, doyma)\n- İzler (traces): “Bu isteğin içinde zaman nereye harcanıyor?” (yavaş adım)\n- Loglar: “Bu kullanıcı/istek için tam olarak ne oldu?” (hatalar, bağlam)\n\nOlay sırasında: etkisini metriklerle doğrulayın, darboğazı izlerle bulun, açıklamayı loglarla yapın.
Küçük bir kurallar seti seçin ve her yerde uygulayın:\n\n- Sabit , (ör. /) ve \n- Kenarda üretilen ve çağrılar ile işlerde taşınan bir \n- Tutarlı etiketler: , , , ve çok kiracılıysa \n- Süreler için tek bir zaman birimi (ör. )\n\nAmaç, bir filtreyle hizmetler arasında gezinmek, her seferinde yeniden başlamamak.
Varsayılan olarak (çoğunlukla JSON) ve her yerde aynı anahtarlarla başlayın.\n\nGünlük olaylarda hemen işe yarayan minimum alanlar:\n\n- , , , , \n- (varsa )\n- , , , \n- veya (sabit bir kimlik, e-posta yerine)\n\nHataları bir kez, bağlamla birlikte loglayın (hata türü/kodu + mesaj + bağımlılık adı). Tekrarlanan denemelerde aynı stack trace'i çoğaltmayın.
Her ana bileşen için küçük bir metrik setiyle başlayın; temel soru: sistem şu an sağlıklı mı, değilse neresi acıyor?\n\nAltın sinyaller (golden signals):\n\n- Gecikme: p50/p95/p99 (ortalama değil)\n- Trafik: istekler/saniye (veya işler/dakika)\n- Hatalar: 4xx vs 5xx\n- Doyma: paylaşılan kaynak sınırı (CPU, bellek, DB bağlantıları, kuyruk)\n\nBileşen bazlı minimum kontrol listesi:\n\n- HTTP/API: istekler/s, p50/p95/p99 gecikme, 4xx oranı, 5xx oranı\n- Veritabanı: sorgu gecikmesi (en az p95), bağlantı havuzu kullanımı, zaman aşımları, yavaş sorgu sayısı\n- Worker/kuyruk: kuyruk derinliği, iş çalışma süresi p95, retry/ölü-mesaj sayısı\n- Kaynaklar: CPU %, bellek kullanımı, disk kullanımı, container yeniden başlatmaları\n- Dağıtım sağlığı: mevcut sürüm, deploy sonrası hata oranı, yeniden başlatma döngüleri\n\nÖrnek: p95 gecikme yükselip trafik sabit kalıyorsa DB havuzu doyuma ulaşmış olabilir. Koder.ai ile uygulama geliştiriyorsanız, bu checklist'i gün bir tanımı olarak kabul edin.
Kullanıcı “yavaş” dediğinde loglar ne olduğunu, metrikler ne sıklıkta olduğunu, izler (traces) ise isteğin içinde zamanın nereye gittiğini söyler. Bu tek zaman çizgisi bulanık bir şikayeti net bir düzeltmeye dönüştürür.\n\nSunucu tarafından başlayın. İsteğin uygulamaya ilk giriş noktası (ilk handler) instrumente edilirse her istek bir trace üretebilir. İstemci tarafı izleme bekleyebilir.\n\nGün bir için iyi bir trace şu span'ları içerir:\n\n- Tüm isteği kapsayan handler spanı\n- Her sorgu veya işlem için veritabanı spanı\n- Önbellek çağrıları (get/set) için span\n- Ara bağımlılık için HTTP çağrı spanı\n- Arka plan işi enqueuelendiğinde onun spanı\n\nAranan ve karşılaştırılabilir izler için bazı anahtar öznitelikleri tutarlı yakalayın. Gelen istek spanında rota (şablon formunda, ör. ), HTTP methodu, status kodu ve gecikmeyi kaydedin. DB spanlarında DB sistemi (PostgreSQL, MySQL), işlem tipi ve tablo adı (kolaysa) olsun. Dış çağrılarda bağımlılık adı (, , vs.), hedef host ve durum olsun.\n\nÖrnek iyi uygulama: tüm hataların ve yavaş isteklerin %100 trace edilmesi (SDK destekliyorsa), normal trafikten ise küçük bir örnekleme (1–10%). Trafik azsa başlangıçta örneklemeyi yüksek tutup zamanla azaltın.\n\n“İyi” bir örnek: bir trace'te hikayeyi baştan sona okuyabiliyorsunuz: 2.4s sürdü, DB 120ms, cache 10ms, ve dış ödeme çağrısı 2.1s sürdü — sorun bağımlılıktaydı.
Belirsiz bir hissi birkaç somut soruya dönüştürmek en hızlı kazançtır. Bu triage akışı yeni bir uygulama olsa bile işe yarar.\n\n5 adımlı triage:\n\n1. Kapsamı doğrulayın: bir kullanıcı mı, bir müşteri hesabı mı, bir bölge mi yoksa herkes mi etkilendi? Wi‑Fi ve hücreselde, farklı tarayıcı/cihazlarda oluyor mu?\n2. Önce ne değişti kontrol edin: istek hacmi mi arttı, hata oranı mı yükseldi, yoksa sadece gecikme mi arttı? Trafik sıçraması genelde kuyruğa neden olur; hata artışı dış bir bağımlılığa işaret eder.\n3. Yavaşlamayı rota/işe bölün: p95 gecikmeyi rota bazında kontrol edin ve en kötü rotayı bulun. Tek bir rotaysa ona odaklanın; hepsi yavaşsa paylaşılan bağımlılıklara bakın.\n4. Yavaş yol için bir trace açın: son 15 dakikadaki yavaş bir isteğin trace'ini alın ve span'ları süreye göre sıralayın. Amaç bir cümle: “Zamanın çoğu X'te.”\n5. Bağımlılıkları doğrulayın ve rollback kararını verin: DB doyumu, yavaş sorgular, önbellek isabet oranı ve üçüncü taraf yanıt sürelerini kontrol edin. Eğer sorun deploy sonrası başladıysa rollback genelde güvenli ilk adımdır.\n\nİstikrar sağlandıktan sonra küçük bir iyileştirme yapın: ne olduğunu yazın ve bir eksik sinyal ekleyin (ör. bölge etiketi, sorgu adı alanı vb.).
Hemen zaman kaybetmemeniz için üç açıklayıcı soru ile başlayın:\n\n- Kim etkilendi (bir kullanıcı, bir müşteri segmenti, herkes)?\n- Hangi eylem yavaş (sayfa yükleme, arama, checkout, giriş)?\n- Ne zamandan beri başladı (dakikalar önce, bir deploy sonrası, bu sabah)?\n\nSonra genelde sizi doğru yöne götüren birkaç sayıya bakın; mükemmel gösterge panosu aramayın, sadece “normalin üzeri” sinyalleri arayın:\n\n- Mevcut hata oranı\n- Etkilenen uç noktanın p95 gecikmesi\n- Doyma: CPU, bellek, DB bağlantıları veya kuyruk derinliği\n\nEğer p95 yükselmiş ama hatalar sabitse, son 15 dakikadaki yavaş rota için bir trace açın. Tek bir trace genelde zamanın DB, dış API veya kilit bekleme gibi nerede geçtiğini gösterir.\n\nSonra bir log araması yapın: kullanıcı raporu varsa request_id ile, yoksa aynı zaman aralığındaki en yaygın hata mesajını arayın.\n\nSon olarak, hemen hafifletme (scale up, rollback, özellik bayrağını kapatma) mı yoksa daha derin inceleme mi gerekeceğine karar verin.
Yayın sonrası birkaç saat içinde destekten “Checkout 20–30 saniye sürüyor” raporları gelirse ve kimse kendi makinelerinde üretemiyorsa, triage süreci işe yarar.\n\nAdımlar:\n\n- Metriklere gidin ve belirtileri doğrulayın: p95 gecikme yalnızca POST /checkout için artmışsa diğer rotalar normalse daraltma başladı demektir.\n- Yavaş için bir trace açın; su şelalesi (waterfall) suçu gösterir. İki yaygın sonuç:\n - spanı 18s sürüyor (çoğunluk bekleme).\n - spanı yavaş, sorgu dönmeden önce uzun bekleme var.\n- Trace'teki (veya trace_id) ile logları kontrol edin: “payment timeout reached” veya “context deadline exceeded” gibi uyarılar ve yeni sürümde eklenen retry'ler görüyorsanız sorun ödeme sağlayıcısıdır. DB yolunda ise kilit bekleme veya eşik üstü yavaş sorgu logları olabilir.\n\nÜç sinyal hizalandığında çözüm açık olur:\n\n- Sürümü geri alın.\n- Ödeme çağrısına açık bir timeout ekleyin ve retry sayısını sınırlayın.\n- Bağımlılık gecikmesi için p95 metriği ekleyin ve DB için p95 sorgu gecikmesini izleyin.\n\nMetrikler rotayı gösterdi, izler yavaş adımı gösterdi, loglar ise hata modunu ve tam isteği doğruladı—tahmin yok.
Çoğu zaman kaybı önlenebilir boşluklardan gelir: veri var ama gürültülü, riskli ya da ihtiyacınız olan tek detay eksik. Paket kullanılabilir kalmazsa kriz anında işe yaramaz.\n\nYaygın tuzaklar:\n\n- Çok fazla ham gövde loglamak (storage maliyeti, aramalar ağır, hassas veri sızıntısı riski).\n- Ortalama ile yetinmek; p95 ve p99'u kontrol etmemek.\n- Yüksek kardinaliteli etiketler (tam kullanıcı ID'leri, e-postalar) ile metrik serilerinin patlaması.\n- Kontekst içermeyen izler (rota adları ve bağımlılık isimleri yoksa görüntü anlamsız olur).\n- Sürüm işareti yoksa deploy'un tetikleyip tetiklemediğini bilemezsiniz.\n- Sahibinin belli olmadığı alarmlar; kimse ne yapacağını bilmiyorsa gürültüye dönüşür.\n\nKüçük örnek: checkout p95 800ms'den 4s'e çıktıysa iki soruyu dakikalar içinde yanıtlamak istersiniz: deploy sonrası mı başladı ve zaman uygulamanızda mı yoksa bağımlılıkta mı geçiyor? Yüzdelikler, sürüm etiketi ve izlerde rota ile bağımlılık isimleri varsa hızlıca yanıtlayabilirsiniz.
service_nameenvironmentprodstagingversionrequest_idroutemethodstatus_codetenant_idduration_mstimestamplevelservice_nameenvironmentversionrequest_idtrace_idroutemethodstatus_codeduration_msuser_idsession_id/orders/:idpaymentsemailGET /checkoutPOST /checkoutPaymentProvider.chargeDB: insert orderrequest_id