Güvenilirlik izleme için hedefleri ve kapsamı belirleyin
Metrikleri veya panoları seçmeden önce uygulamanın ne için sorumlu olduğunu—ve ne olmadığını—belirleyin. Net bir kapsam, aracın kimsenin güvenmediği bir “ops portalı” haline gelmesini önler.
Neyi izleyeceğinizi tanımlayın
Uygulamanın kapsayacağı iç araçları (örn. ticketing, bordro, CRM entegrasyonları, veri boru hatları) ve bu araçların sahipleri ya da onlara bağımlı olan ekipleri listeleyerek başlayın. Sınırları açıkça belirtin: “müşteri odaklı web sitesi” kapsam dışı olabilir, ama “iç yönetici konsolu” kapsam dahilinde olabilir.
Burada “güvenilirlik”in ne anlama geldiği konusunda anlaşın
Organizasyonlar bu kelimeyi farklı kullanır. Çalışan bir tanımı sade bir dille yazın—genelde şunların bir karışımı olur:
- Erişilebilirlik: gerektiğinde insanlara ulaşılabiliyor mu?
- Gecikme: kullanılabilir olmak için yeterince hızlı mı?
- Hatalar: kullanıcıların fark ettiği şekillerde mi başarısız oluyor (zaman aşımı, iş başarısızlıkları, hatalı yanıtlar)?
Ekipler anlaşmazsa uygulamanız elma ile armut karşılaştırır.
İstediğiniz sonuçları belirleyin
1–3 ana sonuç seçin, örneğin:
- Sorunların daha hızlı tespiti (daha kısa “fark etme süresi”)
- Yöneticiler ve paydaşlar için daha net raporlama
- Daha iyi takip sayesinde tekrar eden olayların azaltılması
Bu sonuçlar daha sonra ne ölçeceğinizi ve nasıl sunacağınızı yönlendirecek.
Kullanıcıları ve rolleri tanımlayın
Uygulamayı kimlerin kullanacağını ve hangi kararları verdiklerini listeleyin: olay araştıran mühendisler, destek ekibi yükseltenler, eğilimleri inceleyen yöneticiler ve durum güncellemesi isteyen paydaşlar. Bu, terminoloji, izinler ve her görünümün göstermesi gereken ayrıntı düzeyini şekillendirir.
Önemli güvenilirlik metriklerini seçin (SLI/SLO)
Güvenilirlik izleme, herkesin “iyi”nin ne olduğunu kabul etmesiyle işler. Önce üç benzer terimi ayırın.
SLI vs SLO vs SLA (basitçe)
Bir SLI (Service Level Indicator) ölçümdür: “İsteklerin yüzde kaçı başarılı oldu?” veya “Sayfaların yüklenme süresi neydi?”
Bir SLO (Service Level Objective) bu ölçüm için hedeftir: “30 gün içinde %99.9 başarı.”
Bir SLA (Service Level Agreement) sonuçları olan bir taahhüttür; genelde dışa dönüktür (kredi, ceza). İç araçlar için çoğunlukla SLO'lar belirlenir; bu, beklentileri hizalar ama güvenilirliği sözleşme hukukuna dönüştürmez.
Her araç için küçük, tutarlı bir SLI seti seçin
Araçlar arasında karşılaştırılabilir ve açıklaması kolay tutun. Pratik bir temel şunlardır:
- Çalışma süresi/erişilebilirlik: araç erişilebilir miydi?
- Yanıt süresi: ana sayfalar veya uç noktalar ne kadar hızlı yanıt verdi?
- Hata oranı: kontrollerin veya isteklerin hangi oranı başarısız oldu (5xx, zaman aşımı, bilinen hata durumları)?
Eklemeye başlamadan önce “Bu metrik hangi kararı yönlendirecek?” sorusunu cevaplayabiliyor olun.
İnsanların nasıl düşündüğüne uygun zaman pencereleri seçin
Skor kartlarının sürekli güncellenmesi için kayan pencereler kullanın:
- 7 gün: regresyonları hızlı yakalar
- 30 gün: aylık raporlama ve trendler
- 90 gün: çeyreklik istikrar
Olayları net şiddet seviyeleriyle tanımlayın
Uygulamanız metrikleri eyleme dönüştürmeli. Seviyeleri (örn. Sev1–Sev3) ve açık tetikleyicileri tanımlayın:
- Sev1: araç kapalı veya kritik iş akışı X dakika boyunca bloke
- Sev2: büyük bozulma (örn. hata oranı Y% üzerinde Z dakika)
- Sev3: küçük veya aralıklı sorunlar
Bu tanımlar uyarı, olay zaman çizelgeleri ve hata bütçesi takibini ekipler arasında tutarlı kılar.
Veri kaynaklarını ve alım yaklaşımını planlayın
Güvenilirlik takip uygulaması, arkasındaki verilere ne kadar güvenilirse o kadar güvenilir olur. Alım boru hatlarını kurmadan önce hangi sinyali "gerçek" sayacağınızı haritalayın ve her sinyalin hangi soruyu yanıtladığını yazın (erişilebilirlik, gecikme, hatalar, deploy etkisi, olay yanıtı).
Halihazırdaki veri kaynaklarını haritalayın
Çoğu ekip temeli şu karışımla karşılayabilir:
- Durum kontrolleri / sentetik probe'lar (çalışma süresi ve temel yanıt süresi)
- Metrikler (gecikme yüzdeleri, hata oranları, doygunluk)
- Loglar (hata sayıları, en çok başarısız olan uç noktalar)
- Traceler (gecikmenin bağımlılıklar arasında nerede harcandığı)
- Bilet/olay araçları (olay başlangıç/bitiş, şiddet, sahibi, postmortem bağlantıları)
Hangi sistemlerin yetkili olduğunu açıkça belirtin. Örneğin “uptime SLI” yalnızca sentetik probe'lardan alınabilir, sunucu loglarından değil.
Push vs pull kararı (ve ne sıklıkla)
- Pull API'ler için iyi çalışır (Prometheus, bulut izleme, ticketing): uygulamanız düzenli olarak çeker.
- Push yüksek hacimli olaylar için daha uygundur (deploy'lar, olaylar, uyarılar): sistemler webhook/event aracılığıyla gönderir.
Kullanım durumuna göre güncelleme sıklığını ayarlayın: panolar her 1–5 dakikada yenilenebilir; skor kartları saatlik/günlük hesaplanabilir.
Tanımlayıcıları ve sahipliği normalleştirin
Araç/hizmet, ortam (prod/ stage) ve sahipler için tutarlı ID'ler oluşturun. “Payments-API”, “payments_api” ve “payments” gibi varyantların üç ayrı varlık olmaması için adlandırma kurallarında erken anlaşın.
Saklama ve gizlilik
Ne kadar süreyle ne saklanacağını planlayın (örn. ham olaylar 30–90 gün, günlük toplamlar 12–24 ay). Hassas yükleri almaktan kaçının; güvenilirlik analizinde gereken meta verileri saklayın (zaman damgaları, durum kodları, gecikme bucket'ları, olay etiketleri).
Veri modelini ve veritabanı şemasını tasarlayın
Şemanız iki şeyi kolaylaştırmalı: günlük sorulara cevap vermeyi (“bu araç sağlıklı mı?”) ve bir olay sırasında ne olduğunu yeniden inşa etmeyi (“belirtiler ne zaman başladı, kim ne değiştirdi, hangi uyarılar tetiklendi?”). Küçük bir çekirdek varlık setiyle başlayın ve ilişkileri açık tutun.
Çekirdek varlıklar (minimal başlayın)
- Tool/Service: izlenen iç araç (isim, açıklama, ortam, kritiklik).
- Check: araca bağlı özel bir uptime veya sentetik kontrol (tür, hedef URL, program, etkin).
- Metric: araca veya check'e bağlı zaman-serisi veri noktaları (gecikme, başarı oranı, hata sayısı).
- SLO: hedef ve değerlendirme penceresi (ör. 30 gün içinde %99.9) ve hata bütçesi ayarları.
- Incident: güvenilirliği etkileyen olay (şiddet, durum, başlangıç/bitiş, özet).
- Event: olay için zaman çizelgesi kaydı (durum değişiklikleri, notlar, uyarı alındı, uygulanacak hafifletmeler).
- Owner: aracın sorumlusu takım veya birey.
Sorguları basit tutan ilişkiler
Pratik bir başlangıç:
- Tool'un birden fazla Check'i olur (ve birçok SLO'su olabilir).
- Check'in birçok Metric'i (veya metrik akışı) olur.
- Incident bir Tool'a aittir, ve Incident'in birçok Event'i zaman çizelgesi için olur.
- Tool, Owner'a bağlıdır (veya paylaşılıyorsa many-to-many olabilir).
Bu yapı panoları (“tool → güncel durum → son olaylar”) ve derinlemesine incelemeyi (“olay → etkinlikler → ilgili kontroller ve metrikler”) destekler.
Denetim alanları ve etiketleme
Sorumluluk ve geçmiş için her yerde denetim alanları ekleyin:
created_by, created_at, updated_atstatus artı durum değişikliği takibi (ya Event tablosunda ya da özel bir tarihçe tablosunda)
Ayrıca filtreleme ve raporlama için esnek etiketler ekleyin (örn. takım, kritiklik, sistem, uyumluluk). Bir tool_tags join tablosu (tool_id, key, value) etiketlemeyi tutarlı kılar ve sonraki skor kartları ile roll-upları kolaylaştırır.
Teknoloji yığını ve dağıtım modelini seçin
Güvenilirlik takipçiniz en iyi anlamda sıkıcı olmalı: çalıştırması kolay, değiştirmesi kolay ve desteklemesi kolay. “Doğru” yığın genelde ekibinizin kahramanlık yapmadan sürdürebileceği yığındır.
Ekipten gelen bilişle başlayın
Ekiplerin iyi bildiği ana akım web framework'lerinden birini seçin—Node/Express, Django veya Rails sağlam seçeneklerdir. Öncelik verin:
- Yeni katkı sağlayanların kaybolmaması için net konvansiyonlar
- Kimlik doğrulama, arka plan işleri ve grafikler için iyi kütüphaneler
- Öngörülebilir yükseltme yolları
İç sistemlerle (SSO, ticketing, chat) entegrasyon yapıyorsanız, bu entegrasyonların en kolay olduğu ekosistemi seçin.
Hızlı ilk yineleme istiyorsanız Koder.ai gibi bir vibe-coding platformu pratik bir başlangıç olabilir: varlıklarınızı (tools, checks, SLOs, incidents), iş akışlarınızı (alert → incident → postmortem) sohbetle tarif edip çalışan bir web uygulaması iskeleti hızlıca oluşturabilirsiniz. Koder.ai genelde frontend için React, backend için Go + PostgreSQL hedeflediği için birçok ekibin tercih ettiği “sıkıcı, bakımı kolay” varsayılan yığına uyar—ve daha sonra tamamen manuel bir boru hattına geçmek isterseniz kaynak kodunu dışa aktarabilirsiniz.
Önce veritabanı, sonra yardımcı parçalar
Çoğu iç güvenilirlik uygulaması için PostgreSQL doğru varsayılandır: ilişkisel raporlama, zaman bazlı sorgular ve denetim için iyidir.
Gerçek bir sorunu çözdüğünde ek bileşenler ekleyin:
- Panolar yavaşsa veya üst sistemler tarafından rate limitleniyorsanız cache (örn. Redis)
- Uptime poll'lamak, bildirim göndermek ve rapor oluşturmak için kuyruk/arka plan işleri (Redis + worker, Sidekiq, Celery, BullMQ)
Barındırma ve dağıtım modeli
Karar verin:
- İç bulut / Kubernetes: iç servislere daha sıkı ağ erişimi gerekiyorsa
- PaaS: daha basit operasyon ve hızlı yineleme istiyorsanız
Hangi yolu seçerseniz seçin, dev/staging/prod standartlaştırın ve dağıtımları otomatikleştirin (CI/CD), böylece değişiklikler güvenilirlik sayılarını sessizce değiştirmez. Platform yaklaşımı (Koder.ai dahil) kullanıyorsanız ortamlara ayırma, dağıtım/barındırma ve hızlı rollback (snapshot) gibi özellikler arayın ki yinelemeler tracker'ı bozmasın.
Güvenilir yapılandırma yönetimi
Çalıştırma ile ilgili yapılandırmayı tek yerde belgeleyin: environment değişkenleri, sırlar ve feature flag'ler. “Yerel nasıl çalıştırılır” rehberi ve kısa bir runbook (alım durursa, kuyruk birikirse veya veritabanı sınırlarına ulaşırsa ne yapılır) bulundurun. /docs içinde kısa bir sayfa genelde yeterlidir.
Kullanıcı deneyimini tasarlayın: panolar, derinleşme ve iş akışları
Kaynağı istediğiniz zaman dışa aktarın
Taşınmak istediğinizde tam kontrol için kodu istediğiniz zaman dışa aktarın.
Bir güvenilirlik takip uygulaması başarılı olduğunda insanlar iki soruyu saniyeler içinde yanıtlayabilir: “Durumumuz iyi mi?” ve “Sonraki adım nedir?” Görünümleri bu kararlar etrafında düzenleyin: genel görünüm → belirli araç → belirli olay.
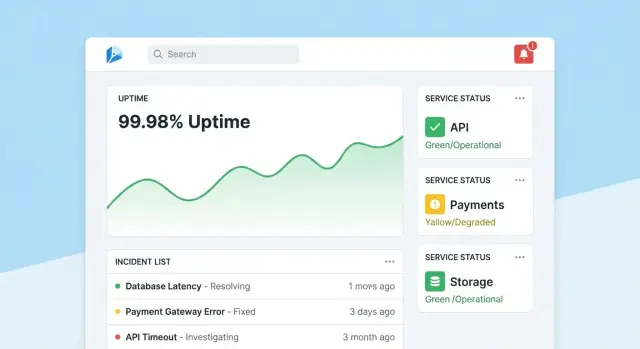
Anasayfa: hızlı bir sağlık özeti
Anasayfayı kompakt bir komuta merkezi haline getirin. Genel sağlık özetiyle başlayın (örn. SLO'ları karşılayan araç sayısı, aktif olaylar, en büyük riskler), sonra durum rozetleriyle son olayları ve uyarıları gösterin.
Varsayılan görünümü sakin tutun: sadece dikkat gerektirenleri vurgulayın. Her kartın ilgili araç veya olaya doğrudan derinleşme bağlantısı olsun.
Araç sayfası: durumdan eyleme
Her araç sayfası “Bu araç yeterince güvenilir mi?” ve “Neden/Neden değil?” sorularına cevap vermeli. İçerik:
- Basit bir geç/güncelleme ile mevcut SLO durumu ve kalan hata bütçesi
- Seçilebilir zaman aralıklarında çalışma süresi, gecikme veya hata oranı grafikleri
- Son değişiklikler (deploy'lar, yapılandırma düzenlemeleri, check güncellemeleri)
- Çalıştırma kitapları ve sahipler: “Ne yapmalı” bölümü ve iletişim bilgilerinin öne çıkarılması
Grafikleri uzman olmayanlar için tasarlayın: birimleri etiketleyin, SLO eşiklerini işaretleyin ve yoğun teknik kontroller yerine küçük açıklamalar (tooltip) ekleyin.
Olay sayfası: ortak bağlam ve zaman çizelgesi
Olay sayfası yaşayan bir kayıt olmalı. Zaman çizelgesi (otomatik yakalanan etkinlikler: uyarı tetiklendi, onaylandı, hafifletildi), insan güncellemeleri, etkilenen kullanıcılar ve alınan aksiyonlar olsun.
Güncelleme yayınlamayı kolaylaştırın: tek bir metin kutusu, ön tanımlı durumlar (Investigating/Identified/Monitoring/Resolved) ve isteğe bağlı dahili notlar. Olay kapatıldığında “Postmortem başlat” eyleği zaman çizelgesinden gerçekleri ön doldurmalı.
Yönetici sayfaları: sahiplik ve tutarlılık
Yöneticiler araçları, kontrolleri, SLO hedeflerini ve sahipleri yönetmek için basit ekranlara ihtiyaç duyar. Doğruluk için optimize edin: mantıklı varsayılanlar, doğrulama ve raporlamayı etkileyen değişikliklerde uyarılar. İnsanların sayılara güvenmesi için görünür bir “son düzenleyen” izi ekleyin.
Kimlik doğrulama, yetkilendirme ve denetim günlüklerini uygulayın
Güvenilirlik verileri ancak insanlar onlara güvendiğinde kullanılmaya devam eder. Bu, her değişikliği bir kimlikle bağlamayı, kimlerin yüksek etkili düzenlemeler yapabileceğini sınırlamayı ve incelemelerde başvurulacak net bir geçmiş tutmayı gerektirir.
Kimlik doğrulama: şirketinizin kullandığı sistemi kullanın
İç araç için varsayılan olarak SSO (SAML) ya da IdP üzerinden OAuth/OIDC (Okta, Azure AD, Google Workspace) kullanın. Bu, parola yönetimini azaltır ve işe alım/çıkarma süreçlerini otomatikleştirir.
Pratik detaylar:
- MFA'yi IdP üzerinden zorunlu kılın (kendi başınıza yeniden uygulamayın).
- IdP gruplarını uygulama rollerine girişte eşleyin.
- Kısa oturum süreleri uygulayın ve manuel çıkışı destekleyin.
İzinler: korumalı eylemlerle rol tabanlı erişim
Basit rollere başlayın, gerektiğinde daha ince izinler ekleyin:
- Viewer: paydaşlar için sadece okunur panolar ve skor kartları
- Editor: kontrolleri, olayları ve notları oluştur/güncelle
- Admin: SLO tanımları, eşikler, entegrasyonlar ve kullanıcı/rol eşlemelerini yönet
Raporlama veya güvenilirlik sonuçlarını değiştirebilecek eylemleri koruyun:
- SLO hedeflerini, uyarı eşiklerini veya veri kaynağı eşlemelerini sadece Admin'ler değiştirebilsin.
- Olayları kapatma veya “çözüldü” işaretleme işlemlerini kısıtlayın ve bir çözüm özetini zorunlu kılın.
Denetim günlükleri: değişimin değiştirilemez geçmişi
SLO'lar, kontroller ve olay alanlarındaki her düzenlemeyi kaydedin:
- kim yaptı (kullanıcı + rol)
- ne zaman oldu (zaman damgası)
- ne değişti (önce/sonra değerleri)
- nereden geldi (UI, API, otomasyon)
Denetim günlüklerini ilgili detay sayfalarından aranabilir ve görünür yapın (örn. bir olay sayfası kendi tam değişiklik geçmişini gösterir). Bu, incelemeleri nesnel yapar ve postmortem sırasında tartışmaları azaltır.
İzleme kontrolleri ve uptime toplama oluşturun
İzleme, güvenilirlik uygulamanızın “sensör katmanıdır”: gerçek davranışı güvenebileceğiniz verilere dönüştürür. İç araçlarda sentetik kontroller genellikle en hızlı yol çünkü “sağlıklı” olmanın ne anlama geldiğini siz tanımlarsınız.
Araç başına sentetik kontroller tanımlayın
Çoğu iç uygulamayı kapsayan küçük bir kontrol setiyle başlayın:
- HTTP ping: servis yanıt veriyor mu (durum kodu, TLS, temel headerlar).
- Uç nokta doğrulama: bilinen bir URL'i çağırıp anlamlı bir şeyi doğrulayın (beklenen JSON şekli, HTML içinde anahtar bir dize veya sağlık uç noktası yükü).
- Giriş gerektirmeyen “smoke” yolu: mümkünse kullanıcı deneyimini yansıtan bir okuma yolu test edin (örn. pano sayfasını yükleyip render olup olmadığını doğrulayın).
Kontroller deterministik olsun. Doğrulama içeriği değişebileceği için hata yaratıyorsa gürültü oluşturur ve güven sarsılır.
Uptime ve gecikmeyi toplayın (ve akıllıca saklayın)
Her kontrol çalıştırması için yakalayın:
- Zaman damgası (başlangıç ve bitiş)
- Sonuç: up/down/unknown
- Gecikme: toplam süre (opsiyonel olarak DNS/connect/TTFB ölçümleri)
- Sebep: hata kodu, zaman aşımı, doğrulama hatası veya istisna mesajı
Veriyi ya zaman-serisi olayları (her kontrol çalıştırması için bir satır) ya da agregat aralıklar (ör. dakikalık rollup'lar ile sayılar ve p95 gecikme) olarak saklayın. Ham olay verisi hata ayıklama için harika; rollup'lar ise hızlı panolar için uygundur. Birçok ekip her ikisini de yapar: ham olayları 7–30 gün saklayıp uzun vadeli raporlama için rollup'ları tutar.
Kesintiler ile eksik veriyi ayrı değerlendirin
Eksik kontrol sonucu otomatik olarak “down” anlamına gelmemeli. Aşağıdaki durumlar için açık bir unknown durumu ekleyin:
- checker worker durdu
- checker ile hedef arasındaki ağ bölümlemesi
- yapılandırma çalıştırma sırasında kaldırıldı
Bu, şişirilmiş çalışma süresi rakamlarını engeller ve “izleme boşluklarını” kendi operasyonel sorunu olarak görünür kılar.
Kontrolleri arka plan işleriyle zamanlayın
Kontrolleri sabit aralıklarla çalıştırmak için arka plan worker'ları (cron benzeri zamanlama, kuyruklar) kullanın (ör. kritik araçlar için 30–60 saniye). Zaman aşımı, geri deneme (backoff) ve eşzamanlılık sınırları ekleyin ki checker iç servisleri aşırı yüklemesin. Her çalıştırma sonucunu—başarısızlıklar dahil—kalıcı hale getirin ki uptime panonuz hem güncel durumu hem de güvenilir geçmişi gösterebilsin.
Uyarı ve bildirim akışları oluşturun
Yapınızı paylaşın, kredi kazanın
Koder.ai ile oluşturduğunuz şeyi yayınlayınca kredi kazanma programına katılın.
Uyarılar güvenilirlik izlemeyi eyleme dönüştüren noktadır. Amaç basittir: doğru kişiyi, doğru bağlamla, doğru zamanda bilgilendirmek—herkesi boğmadan.
Uyarıları SLO'lara bağlayın (sadece eşiklere değil)
Uyarı kurallarını doğrudan SLI/SLO'larınıza eşleyin. İki pratik desen:
- Burn-rate uyarıları: hata bütçesi, SLO'yu kaçırma riski yüksek hızda tükeniyorsa devreye girer.
- Eşik ihlalleri: bir metrik net bir sınırı aştığında uyarı verir (örn. 15 dakikada erişilebilirlik %99.5'in altına düştü).
Her kural için “neden”i de saklayın: hangi SLO etkileniyor, değerlendirme penceresi ve hedeflenen şiddet.
Bildirimleri eyleme dönük yapın
Ekiplerin zaten yaşadığı kanallardan bildirim gönderin (email, Slack, Microsoft Teams). Her mesaj şunları içermeli:
- Tek satırlık özet (servis + semptom + şiddet)
- İlgili pano görünümüne doğrudan bağlantı (örn. /services/payments?window=1h)
- Olay oluşturulduysa olay sayfasına bağlantı (örn. /incidents/123)
Ham metrik dökümü göndermekten kaçının. Kısa bir “sonraki adım” ekleyin: “Son deployları kontrol et” veya “Logları açın.”
Gürültüyü azaltmak için dedupe, gruplayıcı ve sessiz saatler uygulayın
- Deduplication (aynı uyarı parmak izi → mevcut konuyu güncelle)
- Gruplama (bir olay birden fazla ilgili uyarıyı toplayabilir)
- Sessiz saatler ve yönlendirme kuralları ile düşük şiddetli uyarılar çağrı nöbetini uyandırmasın
Eskalasyon ve nöbet yönlendirmesini destekleyin
İç araç bile olsa insanlar kontrol sahibi olmak ister. Uyarı/olay sayfasında manuel eskalasyon düğmesi ekleyin ve varsa on-call araçlarıyla (PagerDuty/Opsgenie eşdeğerleri) entegrasyon yapın; yoksa en azından uygulamada yapılandırılabilen bir dönüşümlü liste saklayın.
Olay yönetimi ve postmortem özellikleri ekleyin
Olay yönetimi “bir uyarı gördük”ten paylaşılan, izlenebilir bir yanıta dönüşmeyi sağlar. Bu akışı uygulamanın içine yerleştirerek insanlar sinyalden koordinasyona geçerken araçlar arasında zıplamasın.
Tek tıklamayla olay oluşturma
Bir uyarıdan, servis sayfasından veya uptime grafiğinden doğrudan olay oluşturmayı mümkün kılın. Önemli alanları (servis, ortam, uyarı kaynağı, ilk görüldüğü zaman) ön doldurun ve benzersiz olay ID'si atayın.
İyi bir varsayılan alan seti hafif olmalı: şiddet, etki (hangi iç takımlar etkilendi), mevcut sahip ve tetikleyici uyarıya bağlantılar.
Durum yaşam döngüsü ve işbirliği
Ekiplerin gerçekte nasıl çalıştığına uyan basit bir yaşam döngüsü kullanın:
- Open → Investigating → Mitigated → Resolved
Her durum değişikliği kim tarafından ve ne zaman yapıldığını kaydetmeli. Zaman çizelgesi güncellemeleri (kısa, zaman damgalı notlar), ekler ve runbook/bilet bağlantılarını destekleyin (örn. /runbooks/payments-retries veya /tickets/INC-1234). Bu thread “ne oldu ve ne yapıldı” için tek kaynak haline gelir.
Postmortem'ler ve aksiyon maddeleri
Postmortem başlatmak hızlı ve tutarlı olmalı. Şablonlar sağlayın:
- Özet, etki, tespit ve kök neden
- Katkıda bulunan faktörler (süreç boşlukları dahil)
- Ne işe yaradı / ne yaramadı
- Sorumlular ve son tarihlerle takip maddeleri
Aksiyon maddelerini olaya bağlayın, tamamlanmayı takip edin ve geciken öğeleri ekip panolarında gösterin. "Öğrenme incelemeleri" destekliyorsanız, bireysel hataları suçlamayan (blameless) bir modu da mümkün kılın.
Raporlama ve güvenilirlik skor kartları
Olay zaman çizelgelerini hızlıca prototipleyin
Kod yazmak yerine rafine edebileceğiniz olay, etkinlik ve postmortem sayfaları oluşturun.
Raporlama güvenilirlik takibinin karar vermeye dönüşmesidir. Panolar operatörlere yardımcı olur; skor kartları liderlerin iç araçların iyileşip iyileşmediğini, hangi alanların yatırım gerektirdiğini ve “iyi”nin ne olduğunu anlamasını sağlar.
Skor kartında neler olmalı
Her araç (ve isteğe bağlı olarak her takım) için tekrar edilebilir bir görünüm oluşturun:
- SLO uyumu zaman içinde: cari dönem (hafta/ay/çeyrek) ve SLO hedefi ile karşılaştırmalı trend çizgisi
- En güvensiz araçlar: kaçırılan SLO, en fazla kesinti dakikası veya en yüksek hata bütçesi yakımı ile sıralama
- MTTR: median ve p90 onarma süresi (tek uzun olay desenleri gizlemesin diye)
- Olay sayıları: toplam olaylar ve şiddet dağılımı (Sev1–Sev3) ile önceki döneme karşılaştırma
Mümkünse hafif bağlam ekleyin: “SLO iki deploy nedeniyle kaçırıldı” veya “Çoğu kesinti bağımlılık X kaynaklı” gibi; ama raporu tam olay incelemesine çevürmeyin.
Liderlik raporlamasını kullanılabilir kılan filtreler
Liderler genelde "her şeyi" istemez. Takım, araç kritikliği (Tier 0–3) ve zaman penceresi için filtreler ekleyin. Aynı araç birden fazla rolü varsa (platform takımı sahibi, finans bağımlı) aynı araç farklı rolluplarda görünebilmeli.
Özetler ve dışa aktarımlar
Uygulama dışına paylaşılabilecek haftalık/aylık özetler sunun:
- Tek tıklama CSV dışa aktarımı
- Durum değerlendirmeleri için temiz PDF dışa aktarımı
Anlatıyı tutarlı tutun (“Önceki döneme göre ne değişti?” “Nerede bütçe aşılıyor?”). Paydaşlar için kısa bir primer gerekiyorsa, kısa bir rehbere bağlanın: blog/sli-slo-basics.
Güvenlik, veri kalitesi ve operasyonel sertleştirme
Güvenilirlik takipçisi hızla bir tek kaynak haline gelir. Üretim sistemi gibi ele alın: varsayılan olarak güvenli, kötü veriye karşı dayanıklı ve bir şey ters gittiğinde kurtarması kolay olsun.
Uygulama yüzeyini koruyun
Her uç noktayı kilitleyin—"sadece iç" görünümlü olanları bile.
- Sınırda girdileri doğrulayın (tipler, aralıklar, izin verilen enum'lar, maksimum payload boyutları) ve bilinmeyen alanları reddedin.
- Gönderen başına rate limiting ekleyin ki gürültülü istemciler alımı veya panoları bunaltmasın.
- Enjeksiyon hatalarını önlemek için parameterize sorgular ve güvenli ORM desenleri kullanın.
Sırlar ve erişim kontrolü
Kimlik bilgilerini koddan ve log'lardan uzak tutun.
Sırları bir secret manager'da saklayın ve döndürün. Web uygulamasına en az ayrıcalık derecesinde veritabanı erişimi verin: okuma/yazma rolleri ayırın, sadece gerektiği tabloları erişime açın ve mümkünse kısa ömürlü kimlik bilgileri kullanın. Tarayıcı↔uygulama ve uygulama↔veritabanı arasındaki trafiği TLS ile şifreleyin.
Veri kalite koruyucuları
Güvenilirlik metrikleri ancak temel olaylar güvenliyse işe yarar.
Zaman damgaları için sunucu tarafı kontrolleri (zaman dilimi/saat kayması), zorunlu alanlar ve yeniden denemeleri dedupe etmek için idempotency anahtarları ekleyin. Kötü olayları panolara bulaştırmamak için ingestion hatalarını dead-letter kuyruğunda veya “karantina” tablosunda izleyin.
Operasyonel temeller (atlamayın)
Veritabanı migrasyonlarını ve rollback testlerini otomatikleştirin. Yedekleri planlayın, düzenli olarak geri yükleme testleri yapın ve minimal bir felaket kurtarma planı belgeleyin (kim, ne, ne kadar süre). Son olarak, takip uygulamasının kendisini güvenilir yapın: sağlık kontrolleri, kuyruk lagı ve DB gecikmesi için temel izleme ve alımın sessizce sıfıra düşmesi durumunda uyarı kurun.
Yayılma planı ve yineleme yol haritası
Bir güvenilirlik takip uygulaması insanların ona güvenmesi ve gerçekten kullanmasıyla başarılı olur. İlk sürümü bir öğrenme döngüsü olarak kabul edin, “büyük patlama” lansmanı olarak değil.
Odaklı bir pilot ile başlayın
Geniş kullanılan ve net sahipleri olan 2–3 iç araç seçin. Küçük bir kontrol seti uygulayın (örn: ana sayfa erişilebilirliği, giriş başarılı, kritik API uç noktası) ve şu soruyu yanıtlayan tek bir pano yayınlayın: “Çalışıyor mu? Değilse ne değişti ve kim sorumlu?”
Pilotu görünür ama sınırlı tutun: doğrulamayı yapmak için bir ekip veya küçük bir güç kullanıcı grubu yeterlidir.
En çok can yakan yerlerden geri bildirim toplayın
İlk 1–2 haftada aktif olarak şu konularda geri bildirim toplayın:
- Kafa karıştıran şeyler (metrik isimleri, grafikler, filtreler, tanımlar)
- Gürültülü olanlar (kullanıcı etkisine uymayan uyarılar)
- Eksik olanlar (sahiplik, runbook'lar, olay bağlantıları)
Geri bildirimi somut backlog öğelerine dönüştürün. Her grafikte küçük bir “Bu metrikle ilgili sorun bildir” düğmesi hızlı içgörüler sağlayabilir.
Entegrasyonlar ve otomasyonla yineleyin
Değeri katmanlı şekilde ekleyin: bildirimler için chat aracına bağlanın, sonra olay aracıyla otomatik bilet oluşturmayı ekleyin, ardından deploy işaretleri için CI/CD entegrasyonu yapın. Her entegrasyon manuel işi azaltmalı veya tanılama süresini kısaltmalı—aksi halde sadece karmaşıklık ekler.
Hızlı prototipleme yapıyorsanız, başlangıç kapsamını (varlıklar, roller, iş akışları) haritalandırmak için Koder.ai'nin planning modunu değerlendirin. Bu, MVP'yi sıkı tutmanın basit bir yoludur—ve snapshot/rollback özellikleriyle panoları ve alımları ekip tanımları netleştikçe güvenle yineleyebilirsiniz.
Başarı metriklerini tanımlayın ve genişletin
Daha fazla takıma açmadan önce gösterge panosu haftalık aktif kullanıcılar, tespit süresinin azalması, tekrarlı uyarıların azalması veya düzenli SLO incelemeleri gibi başarı metrikleri belirleyin. /blog/reliability-tracking-roadmap içinde hafif bir yol haritası yayınlayın ve araç bazında net sahipler ve eğitim oturumlarıyla genişletin.