04 May 2025·8 dk
Jeffrey Ullman’ın Hızlı, Ölçeklenebilir Sorguların Arkasındaki Veritabanı Teorisi
Jeffrey Ullman'ın temel fikirlerinin modern veritabanlarını nasıl güçlendirdiği: ilişkisel cebir, optimizasyon kuralları, join'ler ve sistemlerin ölçeklenmesine yardımcı olan derleyici tarzı planlama.
Neden Ullman Modern Veri İşlerinde Önemli
SQL yazan, gösterge tabloları oluşturan veya yavaş bir sorguyu inceleyen çoğu kişi, adını hiç duymamış olsa bile Jeffrey Ullman’ın çalışmalarından faydalanmıştır. Ullman, veritabanlarının veriyi nasıl tanımladığı, sorguları nasıl anladığı ve bunları verimli şekilde nasıl çalıştırdığı konusunda araştırmaları ve ders kitaplarıyla önemli katkılar yapmış bir bilgisayar bilimci ve eğitimcidir.
Günlük araçların arkasındaki sessiz etki
Bir veritabanı motoru SQL’inizi hızlı çalıştırılabilir bir şeye dönüştürdüğünde, bunu hem kesin hem de uyarlanabilir fikirler üzerine kurar. Ullman, sorguların anlamını formalize etmeye yardımcı oldu (sistemin güvenle yeniden yazabilmesi için) ve veritabanı düşüncesini derleyici düşüncesiyle bağladı (sorgunun ayrıştırılması, optimize edilmesi ve yürütülebilir adımlara çevrilmesi için).
Bu etki görünür bir buton ya da bulut konsolunda bir özellik olarak ortaya çıkmaz. Bunun yerine şunlarda kendini gösterir:
- Bir index eklediğinizde veya bir
JOIN’i yeniden yazdığınızda hızlı çalışan sorgular - Veriler büyüdükçe farklı planlar seçen optimizer’lar
- Sistemlerin, sorgunuzun döndürdüğü sonucu değiştirmeden ölçeklenebilmesi
Bu yazıda neler öğreneceksiniz (matematik yükü olmadan)
Bu yazı, Ullman’ın temel fikirlerini pratikte en çok önem taşıyan veritabanı içyapılarına bir rehber tur olarak kullanır: ilişkisel cebirin SQL’in altında nasıl durduğu, sorgu yeniden yazımlarının anlamı nasıl koruduğu, maliyet tabanlı optimizer’ların neden belli seçimleri yaptığı ve join algoritmalarının bir işin saniyeler içinde mi yoksa saatler içinde mi tamamlanacağını nasıl belirlediği.
Ayrıca ayrıştırma, yeniden yazma ve planlama gibi derleyici benzeri birkaç kavramı da dahil edeceğiz; çünkü veritabanı motorları birçok kişinin sandığından daha çok sofistike derleyicilere benzer davranır.
Kısa bir söz: tartışmayı doğru tutacağız ama ağır kanıtlardan kaçınacağız. Amaç, bir dahaki performans, ölçekleme ya da kafa karıştıran sorgu davranışı ortaya çıktığında iş yerinizde uygulayabileceğiniz zihinsel modeller vermektir.
Ullman’ın Pekiştirdiği Veritabanı Temelleri
Eğer hiç SQL yazdıysanız ve sorgunuzun “tek bir anlamı olduğunu” varsaydınız, büyük olasılıkla Jeffrey Ullman’ın popülerleştirdiği ve formalize ettiği fikirlere dayanıyorsunuz: veri için temiz bir model ve bir sorgunun ne istediğini kesin biçimde tanımlamanın yolları.
İlişkisel model basitçe
Özünde ilişkisel model veriyi tablolar (relation) olarak ele alır. Her tablonun satırları (tuple) ve sütunları (attribute) vardır. Şimdi bariz görünüyor olabilir, ama önemli olan disiplin şudur:
- Anahtarlar satırları tanımlar. Bir primary key her kaydın “isim etiketi” gibidir.
- İlişkiler tabloları foreign key ile birbirine bağlar; böylece gerçekleri tek yerde tutup başka yerlerden referans verebilirsiniz.
Bu çerçeve, el yordamıyla konuşmak yerine doğruluk ve performans hakkında mantık yürütmeyi mümkün kılar. Bir tablonun neyi temsil ettiğini ve satırların nasıl tanımlandığını bildiğinizde, join’lerin ne yapması gerektiğini, tekrarların ne anlama geldiğini ve belirli filtrelerin neden sonuçları değiştirdiğini öngörebilirsiniz.
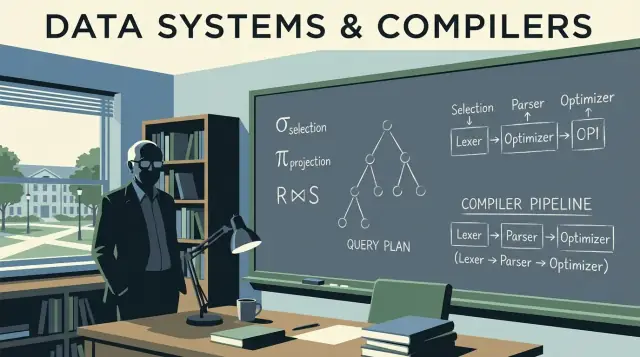
İlişkisel cebir: sorgular için bir hesap makinesi
Ullman’ın öğretilerinde sıkça kullanılan ilişkisel cebir, bir çeşit sorgu hesap makinesi gibidir: seçme, projeksiyon, join, union, difference gibi bir dizi temel operasyonla ne istediğinizi ifade edersiniz.
Neden SQL ile çalışırken önemli: veritabanları SQL’i cebirsel bir forma çevirir ve sonra onu eşdeğer başka bir forma yeniden yazar. Görünüşte farklı iki sorgu cebirsel olarak aynı olabilir—işte optimizer’ların join’leri yeniden sıralayabilmesi, filtreleri öne itebilmesi veya gereksiz işi kaldırabilmesi bu sayede mümkün olur.
Cebir vs. kalkülüs (yüksek seviyede)
- İlişkisel cebir daha çok “nasıl”: sonucu hesaplamak için bir işlem dizisi.
- İlişkisel kalkülüs daha çok “ne”: istediğiniz sonucu tanımlar.
SQL büyük oranda “ne”dir, ama motorlar genellikle optimizasyon için cebirsel “nasıl”ı kullanır.
Temel, bir dialekti ezberlemekten üstündür
SQL dialektleri değişir (Postgres vs. Snowflake vs. MySQL), ancak temel ilkeler değişmez. Anahtarları, ilişkileri ve cebirsel eşdeğerliği anlamak, bir sorgunun mantıksal olarak yanlış mı yoksa sadece yavaş mı olduğunu, ve hangi değişikliklerin anlamı koruyacağını gösterebilir.
İlişkisel Cebir: SQL’in Altındaki Gizli Dil
İlişkisel cebir, SQL’in “altındaki matematik”tir: istediğiniz sonucu tanımlayan küçük operatör seti. Jeffrey Ullman’ın çalışmaları bu operatör bakışını netleştirmeye ve öğretilebilir kılmaya yardımcı oldu—hala çoğu optimizer’ın kullandığı zihinsel model budur.
Temel operatörler (ve ne anlama geldikleri)
Bir veritabanı sorgusu birkaç yapı taşının boru hattı olarak ifade edilebilir:
- Select (σ): satırları filtreler (
WHEREfikri) - Project (π): belirli sütunları tutar (
SELECT col1, col2fikri) - Join (⋈): tabloları bir koşula göre birleştirir (
JOIN ... ON ...) - Union (∪): aynı yapıda sonuçları üst üste koyar (
UNION) - Difference (−): A’da olup B’de olmayan satırlar (
EXCEPTgibi)
Kümenin küçük olması, doğruluk üzerine mantık yürütmeyi kolaylaştırır: iki cebirsel ifade eşdeğerse, herhangi bir geçerli veritabanı durumunda aynı tabloyu döndürürler.
SQL’in cebre nasıl haritalandığı (kavramsal)
Tanıdık bir sorguyu ele alalım:
SELECT c.name
FROM customers c
JOIN orders o ON o.customer_id = c.id
WHERE o.total > 100;
Kavramsal olarak bu şudur:
-
önce customers ve orders’ın bir joini:
customers ⋈ orders -
yalnızca 100’den büyük olan siparişleri seç:
σ(o.total > 100)(...) -
istediğiniz tek sütunu projekte et:
π(c.name)(...)
Bu her motorun kullandığı tam dahili notasyon olmayabilir, ama doğru fikir budur: SQL bir operatör ağacına dönüşür.
Eşdeğerlik: optimizasyona açılan kapı
Birçok farklı ağaç aynı sonucu verebilir. Örneğin, filtreler genellikle daha erken uygulanabilir (büyük bir join’den önce σ uygula) ve projeksiyonlar kullanılmayan sütunları daha erken atabilir (π).
Bu eşdeğerlik kuralları veritabanının sorgunuzu daha ucuz bir plana yeniden yazmasını anlamı değiştirmeden sağlar. Sorguları cebirsel olarak gördüğünüzde, “optimizasyon” sihir olmaktan çıkar ve kural-odaklı güvenli bir yeniden şekillendirme haline gelir.
SQL’den Sorgu Planlarına: Anlamı Koruya Yeniden Yazımlar
SQL yazdığınızda, veritabanı onu "yazıldığı gibi" yürütmez. İfadenizi bir sorgu planına çevirir: yapılacak işin yapılandırılmış bir temsili.\
İyi bir zihinsel model, operatör ağacıdır. Yapraklar tabloları veya index’leri okur; iç düğümler satırları dönüştürür ve birleştirir. Yaygın operatörler arasında scan, filter (selection), project, join, group/aggregate ve sort bulunur.
Mantıksal plan vs. fiziksel plan (ne vs. nasıl)
Veritabanları tipik olarak planlamayı iki katmana ayırır:
- Mantıksal plan: hangi sonucu hesaplayacağını anlatır; soyut operatörlerle (filter, join, aggregate) ifade edilir.
- Fiziksel plan: bunu gerçek depolama ve donanım üzerinde nasıl çalıştıracağını seçer (index scan vs full scan, hash join vs nested-loop join, paralel vs tek iş parçacıklı).
Ullman’ın etkisi, anlamı koruyan dönüşümlere verilen vurguda kendini gösterir: mantıksal planı birçok şekilde yeniden düzenleyin ama cevabı değiştirmeyin, sonra verimli fiziksel stratejiyi seçin.
İş yükünü azaltan kural-tabanlı yeniden yazımlar
Final yürütme yaklaşımını seçmeden önce optimizer’lar cebirsel “temizlik” kuralları uygular. Bu yeniden yazımlar sonucu değiştirmez; gereksiz işi azaltır.
Yaygın örnekler:
- Selection pushdown: filtreleri mümkün olduğunca erken uygula, böylece sonraki adımlara daha az satır gider.
- Projection pruning: yalnızca gereken sütunları tut, I/O ve belleği azalt.
- Join reordering: güvenliyse daha küçük ara sonuçları önce birleştir.
Basit bir yeniden yazım örneği
Kullanıcıların bir ülkedeki siparişlerini almak istiyorsunuz:
SELECT o.order_id, o.total
FROM users u
JOIN orders o ON o.user_id = u.id
WHERE u.country = 'CA';
Naif bir yorum tüm kullanıcıları tüm siparişlerle birleştirip sonra Kanada filtresi uygulayabilir. Anlamı bozmadan filtreyi öne itmek join’in daha az satırla çalışmasını sağlar:
- Önce
country = 'CA'ile kullanıcıları filtrele - Sonra bu kullanıcıları orders ile join et
- Sonra sadece
order_idvetotalprojekte et
Plan terimleriyle optimizer şöyle bir dönüşüm yapmaya çalışır:
Join(Users, Orders) → Filter(country='CA') → Project(order_id,total)
yerine daha yakın bir şeye:
Filter(country='CA') on Users → Join(with Orders) → Project(order_id,total)
Aynı cevap. Daha az iş.
Bu yeniden yazımlar, siz onları yazmadığınız için kolayca gözden kaçabilir—yine de aynı SQL’in bir veritabanında hızlı, diğerinde yavaş çalışmasının başlıca nedenlerinden biridir.
Jargon Olmadan Maliyet Tabanlı Optimizasyon
Bir SQL sorgusu çalıştırdığınızda, veritabanı aynı sonucu veren birden fazla yolu dikkate alır ve sonra en ucuz olması beklenenini seçer. Bu sürece maliyet tabanlı optimizasyon denir—Ullman tarzı teorinin günlük performansta en pratik şekilde göründüğü yerlerden biridir.
“Maliyet modeli” gerçekte nedir
Maliyet modeli, optimizer’ın alternatif planları karşılaştırmak için kullandığı bir puanlama sistemidir. Çoğu motor maliyeti şu çekirdek kaynaklarla tahmin eder:
- İşlenen satırlar (iş genellikle her adımda akan veri miktarıyla ölçeklenir)
- I/O (disk veya SSD’den okuma, ayrıca cache etkileri)
- CPU (filtreleme, hash’leme, sıralama, toplama)
- Bellek (bir operasyon RAM’e sığıyor mu, diske taşma oluyor mu)
Modelin mükemmel olması gerekmez; yeterince sık yönlendirici olacak şekilde doğru olması yeterlidir.
Kardinalite tahmini, basitçe
Planları puanlamadan önce optimizer her adımda şu soruyu sorar: bu adım kaç satır üretecek? Buna cardinality estimation denir.
Eğer WHERE country = 'CA' filtreliyorsanız, motor tablonun hangi oranının eşleştiğini tahmin eder. Müşterileri siparişlere join ediyorsanız, eşleşecek kaç çift olduğunu tahmin eder. Bu satır sayısı tahminleri, index taramayı mı yoksa tam taramayı mı seçeceğini, hash join mi nested loop mu olacağını ya da bir sıralamanın küçük mü yoksa devasa mı olacağını belirler.
İstatistiklerin önemi (ve yanlış gittiğinde ne olur)
Optimizer’ın tahminleri istatistikler tarafından yönlendirilir: sayımlar, değer dağılımları, null oranları ve bazen sütunlar arası korelasyonlar.
İstatistikler güncel değilse veya eksikse, motor satır sayısını katlarca yanlış tahmin edebilir. Kağıt üzerinde ucuz görünen bir plan gerçekte pahalı olabilir—klasik belirtiler arasında veri büyüdükten sonra ani yavaşlamalar, “rastgele” plan değişiklikleri veya beklenmedik disk spill’leri yer alır.
Kaçınılmaz takas: doğruluk vs. planlama süresi
Daha iyi tahminler genellikle daha fazla iş gerektirir: daha detaylı istatistikler, örneklem alma veya daha fazla aday planı keşfetme. Ancak planlama işlemi de zaman alır, özellikle karmaşık sorgular için.
Bu yüzden optimizer’lar iki hedefi dengeler:
- Etkileşimli iş yükleri için yeterince hızlı planlama
- Felaket seçimlerden kaçınacak kadar akıllı planlama
EXPLAIN çıktısını yorumlarken bu takası anlamak yardımcı olur: optimizer zekice davranmaya çalışmıyor—kısıtlı bilgiler altında tahmin edilebilir şekilde doğru olmaya çalışıyor.
Join Algoritmaları ve Sorgu Performansının Kalbi
Show the plan to your team
Share your performance-focused prototype with teammates on a domain they recognize.
Ullman’ın çalışmaları, SQL’in “koşulduğu”ndan çok çevirildiği fikrini popülerleştirdi. Bu, join’lerde en açık şekilde görülür. Aynı satırları döndüren iki sorgu, motorun seçtiği join algoritması ve join sırası nedeniyle çalışma süresi açısından çok farklı olabilir.
Nested loop, hash join, merge join—her birinin uygun olduğu durumlar
Nested loop join fikri basittir: soldaki her satır için sağdaki eşleşen satırları bul. Sol taraf küçük ve sağ tarafta kullanılabilir bir index varsa hızlı olabilir.
Hash join bir girişten (genellikle daha küçük olandan) bir hash tablosu oluşturur ve diğer tarafla probe eder. Eşitlik koşullarında (ör. A.id = B.id) büyük, sırasız girdiler için iyidir, ama bellek ister; diske taşma avantajı yok edebilir.
Merge join iki girişi sıralı olarak yürür. Her iki taraf da zaten sıralıysa (veya ucuzca sıralanabiliyorsa) iyi çalışır; örneğin index’ler join anahtarına göre sıralı satırlar verebiliyorsa.
Join sırası neden performansı domine eder
Üç veya daha fazla tablo olduğunda olası join sırası sayısı patlar. İlk iki büyük tabloyu birleştirmek büyük bir ara sonuç üretebilir ve her şeyi yavaşlatır. Daha iyi bir sıra genellikle en seçici filtreden başlayıp dışarıya doğru join etmektir; böylece ara sonuçlar küçük kalır.
Index’ler uygun plan seçeneklerini değiştirir
Index’ler sadece aramaları hızlandırmaz—bazı join stratejilerini mümkün kılar. Join anahtarında bir index, pahalı bir nested loop’u hızlı bir “satır başına seek” modeline çevirebilir. Öte yandan, eksik veya kullanılamayan index’ler motoru hash join’lere veya merge join için büyük sıralamalara zorlayabilir.
Pratik kontrol listesi: kötü bir join planının belirtileri
- Veri biraz büyüdüğünde çalışma süresi dramatik biçimde artıyor (join sırası ara sonuçları büyütüyor olabilir).
- Planda tahmin edilen satırlar ile gerçek satırlar arasında büyük farklar var (kötü kardinalite tahminleri yanlış join seçimlerine yol açar).
- Büyük sıralamalar veya hash spill’ler görüyorsunuz (bellek baskısı veya destekleyici index eksik).
- Küçük filtrelenmiş bir tablo geç katmanlarda join ediliyor (filtreler yeterince erken uygulanmıyor).
- Join predicate’i uyumlu tiplerde temiz bir eşitlik değil (etkili hash/merge davranışını engeller).
Derleyici Fikirleri Veritabanı Motorlarının İçinde
Veritabanları sadece "SQL çalıştırmaz." Onu derlerler. Ullman’ın etkisi veritabanı teorisi ile derleyici düşüncesinin kesişimine kadar uzanır ve bu bağlantı, sorgu motorlarının neden programlama dili araç zincirlerine benzediğini açıklar: çevirmek, yeniden yazmak ve çalıştırmadan önce optimize etmek.
Ayrıştırma ve sözdizim ağaçları: SQL nasıl okunur
Sorguyu gönderdiğinizde ilk adım bir derleyicinin önden ayrıştırmayla (front end) yaptığına benzer. Motor anahtar kelimeleri ve tanımlayıcıları token’lara ayırır, grameri kontrol eder ve bir parse tree (çoğu zaman basitleştirilmiş bir abstract syntax tree) oluşturur. Burada eksik virgüller, belirsiz sütun adları ve geçersiz grouping kuralları gibi temel hatalar yakalanır.
Yararlı bir zihinsel model: SQL, “program”u döngüler yerine veri ilişkilerini tanımlayan bir programlama dilidir.
Parse tree’den mantıksal operatörlere
Derleyiciler sözdizimini ara temsile çevirir. Veritabanları da benzer şekilde SQL sözdizimini mantıksal operatörlere çevirir:
- Seçim (satır filtreleme)
- Projeksiyon (sütun seçme)
- Join (tabloları birleştirme)
- Aggregation (
GROUP BY)
Bu mantıksal form SQL metninden daha çok ilişkisel cebire yakındır; bu da anlam ve eşdeğerlik üzerinde düşünmeyi kolaylaştırır.
Neden optimizer’lar derleyici optimizasyonlarına benzer
Derleyici optimizasyonları program sonuçlarını aynı tutarken yürütmeyi ucuzlatır. Veritabanı optimizer’ları da benzer şekilde davranır, aşağıdaki tür kural sistemlerini kullanarak:
- Filtreleri daha erken itmek (işi daha erken azaltmak)
- Join’leri yeniden sıralamak (aynı sonuç, farklı maliyet)
- Gereksiz hesaplamaları kaldırmak
Bu, derleyicilerdeki “dead code elimination” felsefesinin veritabanı versiyonudur: aynı felsefe ama farklı teknikler—anlamı koru, maliyeti azalt.
Debugging: kodlanmış çıktıyı derlenmiş kod gibi okumak
Sorgunuz yavaşsa yalnızca SQL’e bakmayın. EXPLAIN çıktısını, derleyici çıktısını inceler gibi okuyun. Bir plan size motorun gerçekten ne seçtiğini söyler: join sırası, index kullanımı ve zamanın nerede harcandığı.
Pratik çıkarım: EXPLAIN çıktısını performansın “assembly listesi” gibi okumayı öğrenin. Bu, ayarlamayı tahmine dayalı işten kanıta dayalı hata ayıklamaya dönüştürür. Daha fazla uygulama alışkanlığı için practical-query-optimization-habits başlıklı yazıyı inceleyin.
Gerçek Performansı Etkileyen Şema Tasarım Teorisi
Design the schema before coding
Map tables, keys, and joins first, then let Koder.ai generate the implementation.
İyi sorgu performansı genellikle SQL yazmadan önce başlar. Ullman’ın şema tasarım teorisi (özellikle normalizasyon), veriyi doğru, öngörülebilir ve büyüdükçe verimli tutmak üzerine odaklanır.
Normalizasyonun amaçları (neden var)
Normalizasyonun hedefleri şunlardır:
- Anomalileri azaltmak (ör. bir müşteri adresini beş yerde güncelleme ve birini atlamak)
- Tutarlılığı artırmak: her gerçeğin bir “ev”i olması
- Kısıtların ifade edilebilir olmasını sağlamak (anahtarlar, foreign key’ler) böylece kurallar uygulama kodu yerine motor tarafından denetlenir
Bu doğruluk kazanımları daha sonra performans kazançlarına dönüşür: daha az tekrar eden alan, daha küçük index’ler ve daha az pahalı güncellemeler.
Normal formlar basitçe
Kanıtları ezberlemeye gerek yok, fikirleri kullanmak yeterli:
- 1NF: değerleri atomik sütunlarda saklayın (virgülle ayrılmış listeler yok). Bu filtrelemeyi ve indexlemeyi kolaylaştırır.
- 2NF: bileşik anahtara sahip tablolarda, her anahtar olmayan sütun tüm anahtara bağlı olmalı (sadece bir parçasına değil). Tekrarlayan özniteliklerden kaçınır.
- 3NF: anahtar olmayan sütunlar yalnızca anahtara bağlı olmalı, diğer anahtar olmayan sütunlara değil. Gizli tekrarları önler.
- BCNF: 3NF’in daha sıkı bir versiyonu; her belirleyenin aday anahtar olduğu durumlarda kullanışlıdır.
Ne zaman denormalizasyon makul
Denormalizasyon şu durumlarda akıllıca olabilir:
- Analitik ağırlıklı tablolar (geniş fact tabloları, raporlama)
- Join’lerin darboğaz olduğu ve kontrollü fazlalığın kabul edilebildiği durumlar
- Okuma hızına odaklanıp yenileme kuralları belirlediğiniz senaryolar (ör. gece toplu yenilemeler)
Anahtar nokta denormalize ederken kasıtlı olmak ve çoğaltmaları senkronize tutma sürecine sahip olmaktır.
Şema seçimlerinin optimizer ve ölçeklenme üzerindeki etkisi
Şema tasarımı optimizer’ın neler yapabileceğini şekillendirir. Açık anahtarlar ve foreign key’ler daha iyi join stratejilerine, daha güvenli yeniden yazımlara ve daha doğru satır tahminlerine imkan tanır. Fazla tekrar ise index’leri şişirir ve yazmaları yavaşlatır; çok değerli sütunlar ise etkili predikatları engeller. Veri hacmi büyüdükçe, bu erken modelleme kararları genellikle tek bir sorgunun mikro-optimizasyonlarından daha önem kazanır.
Teori Sistemler Ölçeklendiğinde Nasıl Görünür
Bir sistem “ölçeklendiğinde”, genellikle sadece daha büyük makineler eklemek değildir. Zor kısım, aynı sorgu anlamını korurken motorun çok farklı bir fiziksel strateji seçmesi gerektiğidir. Ullman’ın eşdeğerliklere verdiği vurgu, bu strateji değişikliklerinin sonucu değiştirmeden yapılmasını sağlar.
Ölçek genellikle fiziksel düzen + plan seçimi demektir
Küçük boyutlarda birçok plan “iş görür”. Ölçekte, bir tabloyu taramak, bir index kullanmak veya önhesaplanmış bir sonucu kullanmak arasındaki fark saniyeler ile saatler arasında olabilir. Teorik taraf önemlidir çünkü optimizer’ın güvenli bir yeniden yazım kümesine (ör. filtreleri öne itme, join’leri yeniden sıralama) sahip olması gerekir—bunlar sonucu değiştirmeden işi köklü şekilde değiştirir.
Partitioning, SQL aynı olsa bile çalıştırılan sorguyu değiştirir
Partitioning (tarihe, müşteriye, bölgeye göre) tek bir mantıksal tabloyu birçok fiziksel parçaya böler. Bu planlamayı etkiler:
- Hangi partition’ların atlanabileceği (partition pruning)
- Join’lerin partition içinde mi kaldığı yoksa düğümler arası veri taşıma mı gerektirdiği
- Gruplamanın yerel olarak mı yapılabileceği, sonra birleştirilip birleştirilmeyeceği
SQL metni değişmeyebilir, ama en iyi plan artık satırların nerede olduğuna bağlıdır.
Materialized view’ler: cebirsel kestirmeler olarak ön-hesaplama
Materialized view’ler temel olarak "kaydedilmiş alt ifadeler"dir. Motor, sorgunuzun saklanan bir sonuçla eşleştiğini (veya eşdeğer hale getirilebileceğini) ispatlayabilirse, pahalı işleri—tekrarlanan join ve agregasyonları—hızlı bir aramayla değiştirebilir. Bu, ilişkisel cebir düşüncesinin pratik uygulamasıdır: eşdeğerliği tanı, sonra yeniden kullan.
Cache: yardımcı ama yanlış işin şeklini düzeltemez
Cache tekrar eden okumaları hızlandırır, ama çok fazla veriyi taramak zorunda olan veya devasa ara sonuçlar üreten bir sorguyu kurtaramaz. Ölçek sorunları ortaya çıktığında genellikle çözüm: dokunulan veri miktarını azaltmak (düzen/partitioning), tekrarlayan hesaplamayı azaltmak (materialized view) veya planı değiştirmektir—sadece "cache ekle" değil.
Ullman’dan İlham Alan Pratik Optimizasyon Alışkanlıkları
Ullman’ın etkisi basit bir zihniyette görünür: yavaş bir sorguyu, veritabanının yeniden yazmaya serbest olduğu bir niyet ifadesi olarak ele alın ve sonra motorun gerçekten ne yapmaya karar verdiğini doğrulayın. Teorisyen olmanıza gerek yok—sadece tekrarlanabilir bir rutin gerekli.
1) Bir EXPLAIN planı okuyun: önce neye bakmalı
Zamanı genellikle domine eden parçalardan başlayın:
- Erişim yöntemi: beklediğiniz index araması yerine tüm tablo taraması mı yapılıyor?
- Tahmini vs gerçek satırlar (veritabanınız gösteriyorsa): büyük farklar genellikle beklenmedik yavaşlamaları açıklar.
- Join sırası: join’i hangi tablonun sürüklediği ve en seçici filtreden başlayıp başlamadığı
- Pahalı operatörler: sıralamalar, hash oluşturma, büyük nested loop’lar—bunlar genelde işin nerede olduğunu gösterir.
Sadece bir şey yapacaksanız, satır sayısının patladığı ilk operatörü belirleyin. Genellikle temel neden odur.
2) Optimizer’ları bozan yaygın anti-pattern’ler
Yazması kolay ama maliyeti yüksek olanlar:
- Index’lenmiş sütunlarda fonksiyon kullanmak:
WHERE LOWER(email) = ...index kullanımını engelleyebilir (normalize sütun veya destekliyorsa fonksiyonel index kullanın). - Eksik predicate’ler: tarih aralığı veya tenant filtresi unutmak hedefli sorguyu geniş taramaya çevirir.
- Kasıtlı olmayan cross join’ler: eksik join koşulu satırları katlar ve büyük ara sonuçlar üretir.
3) Cebirsel düşünceyle bir hipotez oluşturun
İlişkisel cebir iki pratik hareketi teşvik eder:
- Filtreleri daha erken uygulayın: mümkünse
WHEREkoşullarını join’lerden önce uygulayın. - Sütunları erken azaltın: özellikle join’lerden önce yalnızca gereken sütunları seçin.
İyi bir hipotez şöyle seslenir: “Bu join pahalı çünkü çok fazla satır birleştiriyoruz; ordersı önce son 30 güne filtrelersek join girişi küçülür.”
4) Index mi, yeniden yazım mı, yoksa şema değişikliği mi?
Basit bir karar kuralı kullanın:
- Index ekleyin: sorgu doğruysa, seçiciyse ve tekrar ediyorsa.
- Sorguyu yeniden yazın:
EXPLAINkaçınılabilir işi gösteriyorsa (gereksiz join’ler, geç filtreleme, non-sargable predicate’ler). - Şemayı değiştirin: iş yükü stabil ve aynı darboğazla sürekli mücadele ediyorsanız (ön-hesaplanmış agregat, denormalize edilmiş lookup alanları, zaman/tenant’a göre partitioning).
Amaç “zeki SQL” değil. Amaç öngörülebilir, daha küçük ara sonuçlar — Ullman’ın eşdeğerlik fikirlerinin tespit etmeyi kolaylaştırdığı türden iyileştirmeler.
Bu Fikirleri Gerçek Ürünlerde Uygulamak
Experiment safely with changes
Try a risky query rewrite, then roll back instantly if the plan gets worse.
Bu kavramlar sadece DBA’lar için değil. Bir uygulama yayımlıyorsanız, şema şekli, anahtar seçimleri, sorgu kalıpları ve veri erişim katmanı üzerinden veritabanı ve sorgu planlama kararları alıyorsunuz.
Eğer bir vibe-coding iş akışı kullanıyorsanız (örneğin sohbet arayüzünden bir React + Go + PostgreSQL uygulaması üretmek gibi) Koder.ai içinde Ullman benzeri zihinsel modeller pratik bir güven ağı sağlar: üretilen şemayı anahtarlar ve ilişkiler açısından gözden geçirebilir, uygulamanızın dayandığı sorguları inceleyebilir ve üretime geçmeden önce EXPLAIN ile performansı doğrulayabilirsiniz. "Sorgu niyeti → plan → düzeltme" döngüsünde ne kadar hızlı iterasyon yaparsanız, hızlandırılmış geliştirmeden o kadar çok değer elde edersiniz.
Daha Fazla Nereden Öğrenilir ve İş Yerinde Nasıl Uygulanır
Teori ayrı bir hobi olarak çalışmanıza gerek yok. Ullman temellerinden faydalanmanın en hızlı yolu, sorgu planlarını güvenle okuyacak kadar öğrenmek ve sonra bunu kendi veritabanınız üzerinde pratik etmektir.
Yeni başlayanlar için kaynaklar
Aşağıdaki kitap ve ders konularını arayabilirsiniz (bağlantısız, sadece yaygın başlangıç noktaları):
- “A First Course in Database Systems” (Ullman & Widom) — pratik bir çerçeveyle anlaşılır veritabanı temelleri.
- “Principles of Database and Knowledge-Base Systems” (Ullman) — daha fazla titizlik isterseniz derinlemesine teori.
- “Compilers: Principles, Techniques, and Tools” (Aho, Lam, Sethi, Ullman) — optimizer’ların neden derleyicilere benzediği bağlantısı için.
- Ders/aramada: ilişkisel cebir, sorgu yeniden yazımı, join sıralaması, maliyet tabanlı optimizasyon, indexler ve seçicilik, ayrıştırma ve sorgu dilleri.
Hafif bir öğrenme yolu
Küçük başlayın ve her adımı gözlemleyebileceğiniz bir şeye bağlayın:
- İlişkisel cebir: selection, projection, join ve eşdeğerlik kurallarını öğrenin.
- Planlar: plan düğümlerini (scan türleri, filtreler, join’ler, sıralamalar, agregatlar) okumayı öğrenin.
- Join’ler: nested loop vs hash join vs merge join ve hangi durumlarda hangisinin kazandığını anlayın.
- Maliyet modelleri: kararları etkileyen birkaç girdi (satır sayıları, seçicilik, I/O vs CPU) öğrenin.
Hızlı geri dönüş sağlayan küçük alıştırmalar
2–3 gerçek sorgu seçin ve yineleyin:
- Yeniden yazın:
INyerineEXISTSkullanma, predikatleri öne itme, gereksiz sütunları kaldırma, sonuçları karşılaştırma. - Planları karşılaştırın: "önce/sonra" planlarını alın ve ne değiştiğine (join sırası, join türü, scan türü) bakın.
- Index’leri değiştirin: bir seferde bir index ekleyip/çıkarıp tahmini vs gerçek satır sayılarını izleyin.
Bulguları ekip arkadaşlarınıza iletme
Net, plan-temelli bir dil kullanın:
- “Plan, filtre seçici olduğunda ardışık taramadan index taramasına geçti.”
- “Satır tahminleri 100× yanlış olduğundan optimizer yanlış join sırasını seçti.”
- “Bu yeniden yazım eşdeğer (aynı sonucu verir), ama predikat itmesini mümkün kılıyor ve join’e daha az satır gönderiyor.”
Ullman’ın temellerinin pratik getirisi budur: plan-temelli bir ortak dil sayesinde performansı tahmine dayalı işten açıklamalı kanıt temelli konuşmaya taşırsınız.
SSS
Who is Jeffrey Ullman, and why does his work matter if I only write SQL?
Jeffrey Ullman, veritabanlarının sorgu anlamını nasıl temsil ettiğini ve sorguları daha hızlı eşdeğerlerine nasıl dönüştürebileceğini formalize etmeye yardımcı oldu. Bir motor sorguyu yeniden yazdığında, join sırasını değiştirdiğinde veya farklı bir yürütme planı seçtiğinde bu temel bilgiler devreye girer ve aynı sonuç kümesini garantiler.
What is relational algebra, and how is it connected to SQL?
İlişkisel cebir, sorgu sonuçlarını kesin olarak tanımlayan küçük bir operatör kümesidir (select, project, join, union, difference). Motorlar genellikle SQL’i cebir-benzeri bir operatör ağacına çevirir; böylece optimizer’lar WHERE gibi filtreleri daha erken uygulamak gibi eşdeğerlik kurallarını güvenle uygulayabilir.
Why do “meaning-preserving” query rewrites matter in practice?
Çünkü optimizasyon, yeniden yazılmış sorgunun aynı sonuçları döndürdüğünü kanıtlamaya dayanır. Eşdeğerlik kuralları optimizer’ın şunları yapmasına izin verir:
WHEREfiltrelerini join’lerden önce itmek- Gereksiz sütunları erkenden ellemek
- Mantıksal olarak güvenliyse join sırasını değiştirmek
Bu değişiklikler işi dramatik biçimde azaltabilir, ama sonucu değiştirmez.
What’s the difference between a logical query plan and a physical query plan?
Mantıksal plan, hangi operasyonların gerektiğini (filtre, join, aggregate) depoladığı soyut bir tarif sunar. Fiziksel plan ise bunların nasıl çalıştırılacağını seçer (index scan vs full scan, hash join vs nested loop, paralelleştirme, sıralama stratejileri). Çoğu performans farkı fiziksel seçimlerden kaynaklanır; bu seçimler mantıksal yeniden yazımlarla mümkün olur.
What is cost-based optimization in plain English?
Maliyet tabanlı optimizasyon, birden fazla geçerli planı değerlendirir ve en düşük tahmini maliyete sahip olanını seçer. Maliyetler genellikle işlenen satır sayısı, I/O, CPU ve bellek (ör. hash veya sort’un diske taşınıp taşınmadığı) gibi pratik faktörlerle belirlenir.
What is cardinality estimation, and why does it cause unpredictable performance?
Cardinality estimation, optimizer’ın “bu adımdan kaç satır çıkacak?” sorusuna verdiği cevaptır. Bu tahminler join sırasını, join türünü ve index kullanımını etkiler. Tahminler yanlış olduğunda (çoğunlukla eski veya eksik istatistikler yüzünden) ani yavaşlamalar, büyük spill’ler veya beklenmedik plan değişiklikleri görülebilir.
When should I expect nested loop, hash join, or merge join to be fastest?
- Nested loop join: sol taraf küçükse ve sağ tarafta etkili bir index varsa iyi çalışır.
- Hash join: büyük, sırasız veriler için ve eşitlik koşullarında güçlüdür; ancak yeterli bellek gerekir.
- Merge join: her iki taraf da sıralıysa veya index’ler join anahtarına göre sıralı sonuç veriyorsa avantajlıdır.
How do I read an EXPLAIN plan without getting overwhelmed?
Aşağıdaki yüksek sinyalli göstergelere bakın:
- Satır sayısının nerede katlanarak arttığı (ilk büyük patlama genellikle temel nedendir)
- Tahmini vs gerçek satır farkları (kötü istatistikler)
- Pahalı operatörler (büyük sıralamalar, hash oluşturma, büyük nested loop’lar)
- Tarama tercihi (beklediğiniz index yerine tam tablo taraması)
Planı bir derleyicinin ürettiği kod gibi değerlendirin: motorun gerçekte ne seçtiğini gösterir.
How does normalization affect query performance, and when is denormalization acceptable?
Normalizasyon, tekrarları azaltır ve güncelleme anomalilerini önler; bu da çoğu zaman daha küçük tablolar, daha küçük index’ler ve daha güvenilir join’ler demektir. Denormalizasyon, analitik veya yoğun okuma gerektiren durumlarda kabul edilebilir, ancak kontrollü olmalı (yenileme kuralları, bilinen fazlalıklar) ki doğruluk zamanla bozulmasın.
What techniques help queries stay fast as data scales without changing results?
Özetle, ölçek genellikle sorgunun fiziksel stratejisinin değişmesini gerektirir; sorgu anlamı aynı kalırken motor tamamen farklı bir yürütme seçebilir. Yaygın araçlar:
- Partitioning ile pruning ve yerellik sağlamak
- Materialized view’lerle eşdeğer ara sonuçları yeniden kullanmak
- Veri büyüdükçe güncellenen istatistiklerle plan değiştirmek
Cache fayda sağlar ama çok fazla veriyi taramak zorunda olan veya büyük ara join’ler üreten sorguyu tek başına düzeltemez.