22 Eyl 2025·8 dk
Kafka nedir ve modern sistemlerde nasıl kullanılır?
Apache Kafka'nın ne olduğunu, konular ve partition'ların nasıl çalıştığını ve Kafka'nın gerçek zamanlı olaylar, loglar ve veri boru hatlarında modern sistemlerde nerede kullanıldığını öğrenin.
Kafka basitçe açıklama
Apache Kafka, dağıtık bir olay akışı platformudur. Basitçe söylemek gerekirse, birçok sistemin ne olduğuna dair gerçekleri yayınlamasına ve diğer sistemlerin bu gerçekleri—hızlı, ölçeklenebilir ve sıralı şekilde—okumasına izin veren, paylaşılan, dayanıklı bir “boru” gibidir.
Ekipler, verinin sistemler arasında güvenilir şekilde taşınması gerektiğinde Kafka'yı kullanır. Bir uygulamanın başka bir uygulamayı doğrudan çağırması (ve bunun yavaş ya da kapalı olması durumunda başarısız olması) yerine üreticiler olayları Kafka'ya yazar. Tüketiciler hazır olduklarında bunları okur. Kafka olayları yapılandırılabilir süreyle saklar; böylece sistemler kesintilerden kurtulabilir ve geçmişi yeniden işleyebilir.
Karşınıza çıkacak birkaç terim
- Olay / Mesaj: Olmuş bir şeyin kaydı (örneğin “OrderPlaced” veya “PaymentFailed”). Kafka kullanıcıları genellikle “mesaj” der, ama “olay” bunun gerçek dünya değişimini temsil ettiğini vurgular.
- Akış: Zaman içinde devam eden olay akışı.
- Günlük (Log): Kafka olayları ekleme-yalnızca bir günlük olarak düzenler—yeni olaylar sona eklenir ve okuyucular kendi hızlarında ilerler.
Bu kılavuz kimler için (ve ne öğreneceksiniz)
Bu kılavuz, pratik bir Kafka zihinsel modeli edinmek isteyen ürün odaklı mühendisler, veri uzmanları ve teknik liderler içindir.
Temel yapı taşlarını (producers, consumers, topics, brokers), Kafka'nın partition'larla nasıl ölçeklendiğini, olayları nasıl saklayıp yeniden oynattığını ve olay tabanlı mimaride nerede durduğunu öğreneceksiniz. Ayrıca yaygın kullanım senaryoları, teslimat garantileri, güvenlik temelleri, operasyon planlaması ve Kafka'nın ne zaman (ve ne zaman değil) doğru araç olduğuna dair bilgiler de olacak.
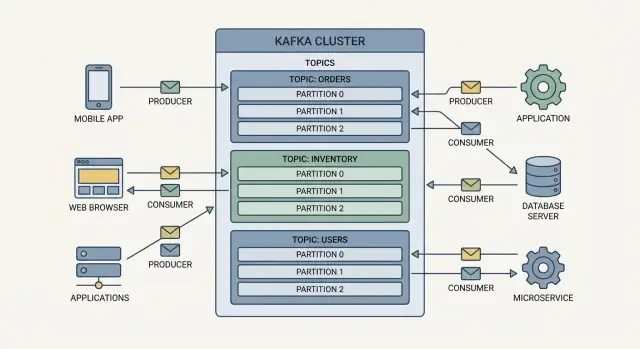
Temel Kavramlar: Producers, Consumers, Topics, Brokers
Kafka, bir paylaşılan olay günlüğü olarak en kolay anlaşılır: uygulamalar olayları yazar, diğer uygulamalar bu olayları daha sonra okur—çoğu zaman gerçek zamanlı, bazen saatler veya günler sonra.
Producers ve consumers
Producers yazanlardır. Bir producer “sipariş verildi”, “ödeme onaylandı” veya “sıcaklık ölçümü” gibi bir olay yayınlayabilir. Producers olayları doğrudan belirli uygulamalara göndermez—onları Kafka'ya yollar.
Consumers okuyanlardır. Bir consumer gösterge panosunu besleyebilir, sevkiyat iş akışını tetikleyebilir veya verileri analitiklere yükleyebilir. Tüketiciler olaylarla ne yapacaklarına karar verir ve kendi hızlarında okuyabilirler.
Konular: olayları organize etmek
Kafka'daki olaylar konulara (topics) gruplanır; bunlar temelde adlandırılmış kategorilerdir. Örneğin:
orderssiparişle ilgili olaylar içinpaymentsödeme olayları içininventorystok değişiklikleri için
Bir topic, o türdeki olaylar için “gerçeğin kaynağı” akışı olur; bu da birçok ekibin aynı veriyi özel çözümler yazmadan yeniden kullanmasını kolaylaştırır.
Brokerlar ve cluster'lar
Bir broker, olayları depolayan ve tüketicilere sunan bir Kafka sunucusudur. Gerçekte Kafka, daha fazla trafikle başa çıkmak ve bir makine arızalansa bile çalışmaya devam etmek için bir cluster (birden çok broker) olarak çalışır.
Consumer grupları: iş tekrar etmeden okuyucuları ölçeklendirmek
Tüketiciler genellikle bir consumer group içinde çalışır. Kafka, okuma işini grup arasında dağıtır; böylece işleme kapasitesini arttırmak için daha fazla tüketici örneği ekleyebilirsiniz—her örneğin aynı işi yapmasına gerek kalmaz.
Konular ve Partition'lar Kafka'yı Nasıl Ölçeklendirir
Kafka, işi ilgili olay akışları olan konulara bölerek ve ardından her konuyu o akışın daha küçük, bağımsız dilimleri olan partition'lara ayırarak ölçeklendirir.
Partition'lar = paralellik ve throughput
Tek partition'lı bir topic, bir consumer grubunda aynı anda yalnızca bir tüketici tarafından okunabilir. Daha fazla partition ekleyin, daha fazla tüketici ekleyin ve olayları paralel olarak işleyebilirsiniz. Bu, Kafka'nın yüksek hacimli olay akışı ve gerçek zamanlı veri boru hatları için nasıl darboğaz yaratmadan çalıştığını gösterir.
Partition'lar ayrıca yükü broker'lara yaymaya yardımcı olur. Bir topic için tüm yazma/okuma işlemlerini tek bir makinenin yapması yerine, farklı partition'lar farklı broker'larda barınabilir ve trafiği paylaşabilir.
Sıralama: Kafka'nın neyi garanti ettiği (ve neyi etmediği)
Kafka, tek bir partition içinde sıralamayı garanti eder. Eğer A, B ve C olayları aynı partition'a bu sırayla yazıldıysa, tüketiciler onları A → B → C şeklinde okur.
Partition'lar arasında sıralama garanti edilmez. Eğer belirli bir varlık için (müşteri veya sipariş gibi) katı sıralama gerekiyorsa, o varlığa ait tüm olayların aynı partition'a gitmesini sağlarsınız.
Anahtarlar olayların nereye gideceğini belirler
Producer'lar bir olay gönderirken bir key (örneğin order_id) ekleyebilir. Kafka bu anahtarı, ilgili olayları tutarlı olarak aynı partition'a yönlendirmek için kullanır. Bu, o anahtar için tahmin edilebilir sıralama sağlar ve yine de genel konu birçok partition'a yayılabilir.
Replikalar veriyi ulaşılabilir kılar
Her partition başka broker'lara replike edilebilir. Bir broker arızalanırsa, replikalardan biri devralabilir. Replikasyon, Kafka'nın kritik iş yükleri için neden güvenilir olduğunun büyük nedenlerinden biridir: erişilebilirliği artırır ve uygulamaların kendi failover mantıklarını yazmasını gerektirmeden hata toleransı sağlar.
Depolama, Retention ve Olayları Yeniden Oynatma
Apache Kafka'daki kilit fikir, olayların sadece iletilip unutulmadığıdır. Olaylar, sıralı bir günlük olarak diske yazılır; böylece tüketiciler şimdi ya da daha sonra okuyabilir. Bu, Kafka'yı sadece veriyi taşımak için değil, aynı zamanda ne olduğunu gösteren dayanıklı bir geçmiş tutmak için de kullanışlı kılar.
Olaylar transit değil, kalıcıdır
Producer bir olayı bir topic'e gönderdiğinde, Kafka bunu broker'da depolamaya ekler. Tüketiciler daha sonra bu depolanan günlükten kendi hızlarında okur. Bir tüketici bir saat boyunca kapalıysa, olaylar yine de vardır ve geri döndüğünde yakalanabilir.
Retention: Kafka veriyi ne kadar süre tutar
Kafka olayları retention politikalarına göre saklar:
- Zaman bazlı retention: olayları belirli bir süre için sakla (örneğin 7 gün).
- Boyut bazlı retention: günlük belirli bir boyuta ulaşana kadar sakla, sonra en eski verileri sil.
Retention konu başına yapılandırılır; bu sayede denetim (audit) konuları ile yüksek hacimli telemetri farklı şekilde ele alınabilir.
Kompaksiyon: her anahtar için en son değeri tutmak
Bazı konular tarihsel arşivden ziyade değişiklik günlüğü gibidir—örneğin “müşteri ayarları”. Log kompaksiyonu, her anahtar için en azından en güncel kaydı tutar; eski üstün gelen kayıtlar kaldırılabilir. Böylece en son duruma dair dayanıklı bir gerçek kaynağı elde ederken sınırsız büyümeden kaçınırsınız.
Olayları yeniden oynatma: durumu yeniden oluşturmak ve hatalardan kurtulmak
Olaylar saklandığı için onları yeniden oynatabilir ve durumu yeniden oluşturabilirsiniz:
- Bir arama dizinini veya materialize görünümü baştan inşa etmek
- Kötü bir dağıtım sonrası bir servisi yeniden işleyerek kurtarmak
- Yeni bir tüketiciyi işlemek için geçmiş verileri sağlamak
Uygulamada yeniden oynatma, bir tüketicinin nereden okumaya başladığını (offset) kontrol ederek yönetilir; bu, sistemler değişirken ekipler için güçlü bir güvenlik ağı sağlar.
Güvenilirlik ve Hata Toleransı Temelleri
Kafka, sistemin parçaları arızalansa bile verinin akmasını sağlamak üzere tasarlanmıştır. Bunu replikasyon, her partition için kimin “lider” olduğuna dair net kurallar ve yapılandırılabilir yazma onayları (acks) ile yapar.
Replikasyon: lider ve takipçiler (yüksek seviyede)
Her topic partition'ının bir lider broker'ı ve diğer broker'larda bir veya daha fazla follower replikası vardır. Producer ve consumer'lar o partition için lidere konuşur.
Takipçiler liderin verisini sürekli kopyalar. Eğer lider kapanırsa, Kafka yeterince güncel bir takipçiyi yeni lider yapabilir, böylece partition erişilebilir kalır.
Broker arızası durumunda kısa bir özet
Bir broker arızalanırsa, lider olduğu partition'lar kısa süreliğine erişilemez hale gelebilir. Kafka'nın controller'ı arızayı tespit eder ve o partition'lar için lider seçimi tetikler.
Eğer en az bir takipçi yeterince senkron ise devralabilir ve istemciler üretmeye/tüketmeye devam eder. Eğer senkron bir replik yoksa, ayarlarınıza bağlı olarak Kafka yazmayı durdurabilir; bu, onaylanmış veriyi kaybetmemek için yapılır.
Dayanıklılık: acknowledgments ve replication factor
İki ana ayar dayanıklılığı şekillendirir:
- Replication factor: her partition'ın kaç kopyası olduğu (örneğin 3 broker üzerinde 3 kopya).
- Acknowledgments (acks): producer'ın bir yazmayı ne zaman başarılı saydığı.
Kavramsal olarak:
- acks=0: producer beklemez—hızlı ama mesajlar kaybolabilir.
- acks=1: lider yazmayı onaylar—daha iyi ama lider başarısız olurken veri kaybı olabilir.
- acks=all (veya -1): lider, "in-sync" replikaların onayını bekler—daha güvenli, genelde biraz daha yavaş.
Yeniden denemeler sırasında çoğaltmaları azaltmak için ekipler genellikle güvenli acks ile idempotent producer'ları ve sağlam tüketici işleme desenlerini birleştirir.
Gecikme vs güvenlik takası
Daha yüksek güvenlik genelde daha fazla onay beklemek ve daha çok replikanın senkron kalmasını gerektirir; bu da gecikmeyi artırıp tepe verimini düşürebilir.
Daha düşük gecikme ayarları telemetri veya clickstream gibi ara sıra veri kaybının kabul edilebilir olduğu durumlar için uygundur; ancak ödemeler, envanter ve denetim kayıtları genelde ekstra güvenliği haklı çıkarır.
Olay Tabanlı Mimaride Kafka'nın Rolü
Ship a consumer dashboard
Kafka'dan okuyan ve gecikme ile verim gösteren hafif bir iç gösterge panosu oluşturun.
Olay tabanlı mimari (EDA), işte meydana gelen şeylerin—bir sipariş verildi, bir ödeme onaylandı, bir paket gönderildi—sistemin diğer bölümlerinin tepki verebileceği olaylar olarak temsil edildiği bir sistem kurma yaklaşımıdır.
Olay yayınla, tüketicilerle tepki ver
Kafka genellikle EDA'nın merkezinde, paylaşılan “olay akışı” olarak konumlanır. Servis A, Servis B'yi doğrudan çağırmak yerine bir Kafka topic'ine (OrderCreated gibi) olay yayınlar. İstediğiniz sayıda diğer servis bu olayı tüketebilir ve eylem alabilir—e-posta gönderme, envanter ayırma, dolandırıcılık kontrolü başlatma—Servis A'nın bunların varlığını bilmesine gerek kalmadan.
Gevşek bağlılık (daha az doğrudan bağımlılık)
Servisler olaylarla iletişim kurduğunda, her etkileşim için request/response API'leri koordine etmek zorunda kalmazsınız. Bu, ekipler arası sıkı bağımlılıkları azaltır ve yeni özellik eklemeyi kolaylaştırır: mevcut bir olayı tüketen yeni bir tüketici eklemek genellikle üreticiyi değiştirmeyi gerektirmez.
Asenkron iş akışları ve trafik dalgalanmalarına direnç
EDA doğal olarak asenkrondur: producer'lar olayları hızlıca yazar, tüketiciler bunları kendi hızlarında işler. Trafik zirvelerinde Kafka, akışı tamponlayarak aşağı akış sistemlerin anında çökmesini engellemeye yardımcı olur. Tüketiciler yetişmek için yatay ölçeklenebilir; bir tüketici geçici olarak kapansa, kaldığı yerden devam edebilir.
Pratik zihinsel model
Kafka'yı sistemin “etkinlik akışı” olarak düşünün. Producers gerçekleri yayınlar; consumers ilgilendikleri gerçeklere abone olur. Bu desen gerçek zamanlı veri boru hatlarını ve olay tabanlı iş akışlarını mümkün kılarken servisleri daha basit ve bağımsız tutar.
Modern Sistemlerde Yaygın Kafka Kullanım Alanları
Kafka genellikle, birçok küçük "olmuş şey"in (olayların) sistemler arasında—hızlı, güvenilir ve birden çok tüketicinin yeniden kullanabileceği şekilde—taşınması gerektiğinde ortaya çıkar.
Etkinlik izleme ve denetim günlükleri
Uygulamalar genelde ekleme-yalnızca bir geçmişe ihtiyaç duyar: kullanıcı girişleri, izin değişiklikleri, kayıt güncellemeleri veya yönetici işlemleri. Kafka, bu olayların merkezi bir akışı olarak iyi çalışır; güvenlik araçları, raporlama ve uyumluluk dışa aktarımları aynı kaynağı okuyabilir. Olaylar bir süre saklandığı için, hatalar veya şema değişiklikleri sonrası denetim görünümünü yeniden oluşturmak için tekrar oynatılabilirler.
Mikroservis iletişimi olaylarla
Servisler birbirini doğrudan çağırmak yerine “sipariş oluşturuldu” veya “ödeme alındı” gibi olayları yayınlayabilir. Diğer servisler abone olur ve kendi zamanlarında tepki verir. Bu sıkı bağlılığı azaltır, kısmi arızalar sırasında sistemlerin çalışmaya devam etmesine yardımcı olur ve örneğin dolandırıcılık kontrolleri gibi yeni yetenekler eklemeyi kolaylaştırır.
Analitik ve veri ambarlarına veri boru hatları
Kafka, operasyonel sistemlerden analitik platformlarına veri taşımada sık kullanılan bir omurgadır. Ekipler uygulama verilerindeki değişiklikleri akış halinde alıp ambar veya data lake'e düşük gecikmeyle teslim edebilir; ağır analiz sorgularının üretim uygulamasını etkilemesini önler.
IoT ve patlamalı (bursty) telemetri
Sensörler, cihazlar ve uygulama telemetrisi sık sık zirveler halinde gelir. Kafka bu patlamaları emebilir, güvenli şekilde tamponlayabilir ve aşağı akış işlemenin yakalamasına izin verir—izleme, uyarı ve uzun vadeli analiz için kullanışlıdır.
Kafka Ekosistemi: Connect, Streams ve Araçlar
Kafka sadece brokerlar ve topic'lerden ibaret değildir. Çoğu ekip, günlük veri hareketi, akış işleme ve operasyonel işler için Kafka'yı pratik hale getiren yardımcı araçlara dayanır.
Kafka Connect: özel kod yazmadan veri taşımak
Kafka Connect, veriyi Kafka'ya getirmek (source) ve Kafka'dan çıkarmak (sink) için entegrasyon çerçevesidir. Tek seferlik boru hattı kodları inşa etmek yerine Connect'i çalıştırır ve konektörleri yapılandırırsınız.
Yaygın örnekler: veritabanlarından değişiklikleri çekmek, SaaS olaylarını almak veya Kafka verisini bir veri ambarına ya da obje depolamaya teslim etmek. Connect aynı zamanda yeniden denemeler, offset yönetimi ve paralellik gibi operasyonel konuları standardize eder.
Kafka Streams: uygulamalarınız içinde gerçek zamanlı işleme
Connect entegrasyon içindir; Kafka Streams hesaplama içindir. Uygulamanıza eklediğiniz bir kütüphane ile akışları gerçek zamanlı dönüştürebilirsiniz—olayları filtreleme, zenginleştirme, akışları birleştirme ve agregatlar oluşturma (ör. "dakikadaki siparişler").
Streams uygulamaları konulardan okur ve konulara yazar; bu nedenle olay tabanlı sistemlere doğal olarak uyar ve daha fazla örnek ekleyerek ölçeklenebilir.
Şema yönetimi: olayların tutarlılığını korumak
Birden çok ekip olay yayınladıkça tutarlılık önemlidir. Şema yönetimi (çoğunlukla bir şema kaydı aracılığıyla) bir olayın hangi alanlara sahip olması gerektiğini ve zaman içinde nasıl evrileceğini tanımlar. Bu, bir üreticinin bir alanın adını değiştirmesi gibi tüketiciyi bozacak hataların önlenmesine yardımcı olur.
Araçlar: önemli olanları izlemek
Kafka operasyonel olarak hassastır, bu yüzden temel izleme gereklidir:
- Consumer lag: tüketiciler geride mi kalıyor?
- Throughput: saniyede kaç olay akıyor?
- Hatalar: başarısız fetch/produce hataları, connector görev hataları
Çoğu ekip ayrıca dağıtım, konu yapılandırması ve erişim kontrol politikaları için yönetim UI'ları ve otomasyon kullanır (bakınız /blog/kafka-security-governance).
Teslimat Garantileri ve İşleme Desenleri
Own the codebase
Prototipin ötesine geçmeye hazır olduğunuzda kaynak kodunu dışa aktararak tam kontrolü elinizde tutun.
Kafka genelde "dayanıklı günlük + tüketiciler" olarak tanımlanır, ama ekiplerin gerçekten önem verdiği soru şudur: her olayı bir kez mi işleyeceğim ve bir şey ters giderse ne olacak? Kafka size yapı taşları verir; siz takasları seçersiniz.
Teslimat garantileri (yüksek seviyede)
At-most-once: olayları kaybedebilirsiniz ama çoğaltma olmaz. Bu, tüketici pozisyonunu (offset) önce commit edip sonra işini bitirmeden çökerse olur.
At-least-once: olayları kaybetmezsiniz ama tekrarlar olabilir (örneğin tüketici olayı işledikten sonra çöker ve yeniden işler). Bu en yaygın varsayılandır.
Exactly-once: hem kaybı hem de çoğaltmayı önlemeye çalışır. Kafka'da bu genelde transactional producer'lar ve uyumlu işleme (çoğunlukla Kafka Streams ile) gerektirir. Güçlüdür ama daha sınırlayıcıdır ve dikkatli kurulum ister.
İdempotentlik ve deduplama
Pratikte birçok sistem at-least-once'ı kabul eder ve ek önlemler alır:
- İdempotent yazmalar: "olayı uygula" adımını tekrar etmek güvenli olsun (ör. upsert, koşullu güncellemeler, benzersiz anahtarlar).
- Deduplama: bir olay kimliği veya iş anahtarı saklayıp belirli bir pencere içinde tekrarları yok sayma.
Tüketici offsetleri: sizin "yer imi"niz
Bir tüketici offset ile partition içindeki son işlenen kaydın konumunu belirtir. Offset commit etmek, "buraya kadar işledim" demektir. Çok erken commit kayba yol açar; çok geç commit tekrar işlemeye neden olur.
Yeniden denemeler ve zehirli (poison) mesajlar
Yeniden denemeler sınırlı ve görünür olmalıdır. Yaygın bir desen:
- Geçici hatalar için backoff ile yeniden dene,
- Başarısız kaydı inceleme ve yeniden oynatma için bir dead-letter topice gönder.
Bu, tek bir "zehirli mesaj"ın tüm consumer grubunu engellemesini önlerken veriyi ileride düzeltmek üzere saklar.
Güvenlik ve Yönetişim (Governance) Düşünceleri
Kafka genellikle iş açısından kritik olayları taşır (siparişler, ödemeler, kullanıcı etkinliği). Bu yüzden güvenlik ve yönetişim tasarımın bir parçası olmalıdır.
Kimlik doğrulama ve yetkilendirme
Kimlik doğrulama “sen kimsin?” sorusunu, yetkilendirme ise “ne yapmana izin var?” sorusunu yanıtlar. Kafka'da kimlik doğrulama genellikle SASL (ör. SCRAM veya Kerberos) ile yapılır; yetkilendirme ise topic, consumer group ve cluster seviyelerinde ACL'lerle uygulanır.
Pratik bir desen en az ayrıcalık (least privilege) prensibidir: üreticiler yalnızca sahip oldukları topic'lere yazsın, tüketiciler yalnızca ihtiyaç duydukları topic'leri okusun. Bu, kimlik bilgileri sızarsa hasarı sınırlar.
İletim sırasında şifreleme (TLS)
TLS, uygulamalar, broker'lar ve araçlar arasındaki veriyi şifreler. Olmadan, olaylar yalnızca genel internette değil, dahili ağlarda da ele geçirilebilir. TLS ayrıca broker kimliklerinin doğrulanmasına yardımcı olur ve MITM (ortadaki adam) saldırılarını zorlaştırır.
Çok kiracılı (multi-tenant) Kafka ve adlandırma kuralları
Birden çok ekip bir küme paylaşıyorsa, koruyucu önlemler önemlidir. Açık konu adlandırma kuralları (ör. <ekip>.<alan>.<olay>.<versiyon>) sahipliği görünür kılar ve politikaların tutarlı uygulanmasına yardımcı olur.
Adlandırmayı kota ve ACL şablonları ile eşleştirin ki gürültülü bir iş yükü diğerlerini tüketmesin ve yeni servisler güvenli varsayılanlarla başlasın.
Veri yönetişimi: KVK/PII, retention ve uyum
Kafka'yı olay geçmişi için bir kayıt sistemi olarak ele almayı ancak niyetliyorsanız yapın. Olaylar PII içeriyorsa veri minimizasyonu yapın (tam profiller yerine ID gönderin), alan düzeyinde şifreleme düşünün ve hangi konuların hassas olduğunu belgeleyin.
Retention ayarları yasal ve iş gereksinimleriyle eşleşmeli. Politika "30 gün sonra sil" diyorsa, 6 ay boyunca veriyi "acaba lazım olur mu" diye tutmayın. Düzenli gözden geçirmeler ve denetimler konfigürasyonların evrimle uyumlu kalmasını sağlar.
Kafka'yı İşletmek: Ekiplerin Planlaması Gerekenler
Add a DLQ workflow
Zehirli mesajları ele alıp hataları tüketicileri engellemeden inceleyecek küçük bir uygulama oluşturun.
Apache Kafka'yı çalıştırmak "kur ve unut" işi değildir. Bir hizmet gibi davranır: birçok ekip buna bağlıdır ve küçük hatalar bile aşağı akış uygulamalarına yayılabilir.
Kapasite planlaması temelleri
Kafka kapasitesi çoğunlukla düzenli olarak tekrar değerlendirdiğiniz bir muhasebe problemidir. En büyük etkenler partition sayısı (paralellik), throughput (MB/s giren ve çıkan) ve depolama büyümesi (retention ile)dir.
Trafik iki katına çıkarsa, yükü broker'lara yaymak için daha fazla partition gerekebilir, retention için daha fazla disk gerekir ve replikasyon için daha fazla ağ bant genişliği gerekir. Pratik bir alışkanlık, tepe yazma oranını tahmin etmek, bunu retention ile çarpmak ve disk büyümesini tahmin etmek, sonra replikasyon ve beklenmeyen başarı için tampon eklemektir.
Günlük operasyonel görevler
Sunucuları ayakta tutmanın ötesinde rutin işler bekleyin:
- Güncellemeler: rolling upgrade planlayın, istemci uyumluluğunu test edin ve değişiklikleri trafik en düşükken uygulayın.
- Yük dengeleme (rebalancing): consumer group rebalance'ları kısa duraklamalara neden olabilir; güvenli dağıtım desenleri ve net sahiplik gerekir.
- Olay müdahalesi: broker arızaları, disk dolması, yanlış yapılandırılmış producer'ların bir konuyu doldurması için çalışma kitabı (playbook) hazırlayın.
Maliyet sürücüleri ve dağıtım tercihleri
Maliyetler diskler, ağ çıkışı ve broker sayısı/ebadı tarafından yönlendirilir. Yönetilen Kafka, personel yükünü azaltıp yükseltmeleri sadeleştirirken; kendi kendine barındırma, deneyimli operatörleriniz varsa ölçekte daha ucuz olabilir. Takas, kurtarma süresi ve on-call yüküdür.
Ölçülecekler (keşfediyor olmamak için)
Ekipler tipik olarak şunları izler:
- Uçtan uca gecikme (produce'dan consume'a kadar)
- Consumer lag (tüketicilerin ne kadar geride olduğu)
- Broker sağlığı (disk kullanımı, under-replicated partition'lar, istek hata oranları)
İyi panolar ve alarmlar Kafka'yı bir "gizem kutusu" olmaktan çıkarıp anlaşılır bir hizmet haline getirir.
Kafka Ne Zaman Kullanılır (ve Ne Zaman Kullanılmamalı)
Kafka, çok sayıda olayı güvenilir şekilde taşımak, bir süre saklamak ve birçok sistemin aynı veri akışına kendi hızlarında tepki vermesine izin vermek istediğinizde iyi bir seçenektir. Özellikle yeniden oynatma (backfill, audit, yeni servis kurulumunda) gerektiğinde ve zaman içinde daha fazla üretici/tüketici ekleneceğini bekliyorsanız faydalıdır.
Kafka'nın parladığı durumlar
Kafka genellikle iyi işler:
- Yüksek hacimli olay akışları (tıklamalar, siparişler, sensör verileri)
- Aynı olaylara ihtiyaç duyan birçok tüketici (analitik, izleme, dolandırıcılık, bildirimler)
- Yeniden oynatma ve uzun süreli geçmiş ihtiyacı
- Ekipleri ve servisleri gevşek bağlı hale getirme gereksinimi
Kafka çok ağır olabilir
Kafka, ihtiyaçlar basitse aşırıya kaçabilir:
- İki servis arasında tek, düşük hacimli bir kuyruk
- Yeniden oynatma değeri olmayan kısa ömürlü işler (background job'lar)
- Dağıtık bir sistemi işletmek ve izlemek için zaman/uzmanlık olmayan ekipler
Bu durumlarda işletme yükü (küme boyutlandırma, yükseltmeler, izleme, on-call) faydaları aşabilir.
Alternatifler ve tamamlayıcılar
- RabbitMQ: klasik iş kuyruğu ve yönlendirme desenleri için iyi.
- NATS: düşük gecikmeli, hafif mesajlaşma.
- Bulut pub/sub hizmetleri: yönetilen altyapı ve daha basit operasyon istiyorsanız uygun.
Kafka ayrıca veritabanlarının (kayıt sistemi), cache'lerin (hızlı okuma) ve batch ETL araçlarının yerini almaz—tamamlayıcıdır.
Hızlı karar kontrol listesi
Sorun:
- Birden çok tüketici ve yeniden oynatma ihtiyacı var mı?
- Throughput önemli ölçüde büyüyecek mi?
- Olay geçmişi/retention bir özellik mi?
- Operasyonel sahipliği destekleyebilir miyiz (veya yönetilen Kafka mı kullanacağız)?
- Olay gönderiyor muyuz, yoksa sadece komut/görev mi?
Bu soruların çoğuna “evet” yanıtı veriyorsanız Kafka genelde mantıklı bir seçimdir.
Başlarken: Basit Bir Benimseme Yolu
Kafka, birçok sistemin gerçek zamanlı olay akışları için ortak bir “gerçeğin kaynağı” olduğu durumlarda en iyi şekilde uyar: birçok üretici olay üretiyor (sipariş oluşturuldu, ödeme yetkilendirildi, envanter değişti) ve birçok tüketici bu olayları boru hatlarını, analitiği ve reaktif özellikleri güçlendirmek için tüketiyor.
Adım 1: Bir somut kullanım durumu seçin
Başlangıçta dar ve yüksek değerli bir akış seçin—örneğin downstream servisler (e-posta, dolandırıcılık, sevkiyat) için "OrderPlaced" olaylarını yayınlamak. İlk günden Kafka'yı genel bir kuyruk haline getirmeyin.
Adım 2: Olaylarınızı ve konularınızı tanımlayın
Şunları yazın:
- Olaylar: ne oldu, iş diliyle
- Konular: bu olayların nereye ait olduğu (genelde her olay türü veya domain için bir topic)
- Tüketiciler: hangi ekipler/servisler bu olaylara ihtiyaç duyuyor ve neden
Erken şemaları basit ve tutarlı tutun (zaman damgası, kimlikler ve net bir olay adı). Şemaları baştan zorunlu kılmak mı yoksa zaman içinde dikkatli evrim mi yapacağınız konusunda karar verin.
Adım 3: Sahiplik ve işletme temellerini belirleyin
Kafka, şu şeylerin bir sahibi olduğunda başarılı olur:
- Topic oluşturma ve adlandırma kuralları
- Retention ve erişim politikaları
- On-call sorumlulukları ve çalışma kitapları
Hemen izleme ekleyin (consumer lag, broker sağlığı, throughput, hata oranları). Eğer henüz bir platform ekibiniz yoksa, yönetilen bir teklif ile başlayın ve net sınırlar belirleyin.
Adım 4: "İnce" bir ilk boru hattı oluşturun
Bir sistemden olay üretin, bir yerde tüketin ve döngüyü uçtan uca kanıtlayın. Ancak sonra daha fazla tüketici, partition ve entegrasyon ekleyin.
Hızla fikirden çalışan bir olay tabanlı servise geçmek istiyorsanız, Koder.ai gibi araçlar çevresindeki uygulamayı (React web UI, Go backend, PostgreSQL) prototiplemenize yardımcı olabilir ve sohbet tabanlı iş akışıyla producer/consumer eklemeyi hızlandırır. Bu araç, dahili panolar ve hafif tüketici servisleri oluşturmak için planlama modu, kaynak kodu dışa aktarma, dağıtım/barındırma ve anlık görüntülerle geri alma gibi özellikler sunar.
Eğer bunu olay tabanlı yaklaşıma haritalıyorsanız, bakınız /blog/event-driven-architecture. Maliyet ve ortam planlaması için bakınız /pricing.
SSS
Apache Kafka nedir basitçe?
Kafka, olayları kalıcı, ekleme-yalnızca (append-only) günlüklerde saklayan dağıtık bir olay akışı platformudur.
Üreticiler (producers) olayları konulara (topics) yazar; tüketiciler (consumers) bunları bağımsız olarak okur (çoğunlukla gerçek zamanlı ama istenirse daha sonra da).
Bir ekip ne zaman doğrudan servisler arası çağrılardan ziyade Kafka'yı tercih etmeli?
Birden çok sistemin aynı olay akışına ihtiyacı olduğunda, gevşek bağlılık ve geçmişi yeniden oynatma (replay) gerektirdiğinde Kafka kullanın.
Özellikle faydalıdır:
- Olay tabanlı mikroservisler (olayları yayınla, asenkron tepki ver)
- Gerçek zamanlı analitik/warehouselara veri boru hatları
- Patlamalı trafik gösteren etkinlik izleme, denetim kayıtları, telemetri
Topic ile partition arasındaki fark nedir?
Bir topic, orders veya payments gibi olayların adlandırılmış kategorisidir.
Bir partition ise bir topic'in dilimidir ve şunları sağlar:
- Daha yüksek verim (yazma/okuma yükü broker'lara dağıtılır)
- Paralel tüketim (bir gruptaki birden çok tüketici)
Kafka sadece tek bir partition içinde sıralamayı garanti eder.
Anahtarlar (keys) sıralamayı ve ölçeklenmeyi nasıl etkiler?
Kafka, kayıt anahtarı (örneğin order_id) ile ilişkili olayları aynı partition'a yönlendirir.
Pratik kural: bir varlık için (sipariş/müşteri) sıralama gerekiyorsa, o varlığı temsil eden bir anahtar kullanın ki olaylar aynı partition'a düşsün.
Consumer group nedir ve neden önemlidir?
Bir consumer group, bir topic için işi paylaşan tüketici örnekleri kümesidir.
Bir grup içinde:
- Her partition aynı anda en fazla bir örnek tarafından işlenir
- Örnek sayısını arttırmak paralelliği artırır partition sayısına kadar
İki farklı uygulamanın her olayı alması gerekiyorsa, farklı consumer group'lar kullanmalıdırlar.
Kafka veriyi ne kadar süre saklar ve retention ne işe yarar?
Kafka, konulara göre disk üzerinde olayları saklar, böylece tüketiciler kesinti sonrası yakalayabilir veya geçmişi yeniden işleyebilir.
Yaygın saklama türleri:
- Zaman bazlı (N gün sakla)
- Boyut bazlı (günlük N GB'a ulaşana kadar sakla)
Saklama konu başına ayarlanır; audit amaçlı konular ile yüksek hacimli telemetri farklı tutulabilir.
Log kompaksiyon (compaction) nedir ve normal retention'dan ne zaman daha iyidir?
Log kompaksiyonu, her anahtar için en azından en güncel kaydı tutar ve zamanla eskilerini kaldırır.
Bu, her değişikliğin tamamını değil, her anahtarın güncel durumunu korumak istediğiniz "mevcut durum" akışları için uygundur.
Kafka olayları tam olarak bir kez (exactly once) teslim eder mi?
En yaygın uçtan uca desen "at-least-once" şeklindedir: olaylar kaybolmaz ama çoğaltmalar olabilir.
Güvenli uygulamalar için:
- Tüketicileri idempotent yapın (aynı olayı tekrar uygulamak güvenli olsun)
- Gerekirse benzersiz olay kimlikleri ile deduplama yapın
- İş tamamlandıktan sonra offset commit edin ki kayıp riski azalsın
Tüketici offsetleri nedir, retry ve dead-letter konuları (DLQ) nasıl çalışır?
Offsetler, her partition için tüketicinin son işlenen konumudur.
Erken commit ederseniz çökme durumunda iş kaybolur; geç commit ederseniz yeniden işleme ve çoğaltma olur.
Yaygın operasyonel desen: arızalar için sınırlı yeniden deneme, ardından başarısız kaydı bir dead-letter topic'e gönderme—böylece tek bir kötü kayıt tüm grup işini engellemez.
Kafka Connect ve Kafka Streams nedir, hangisini ne zaman kullanmalıyım?
Kafka Connect, veri kaynaklarını (source) Kafka'ya ve Kafka'dan hedeflere (sink) taşımak için konektörler çalıştıran entegrasyon çerçevesidir. Tek seferlik boru hattı kodları yazmak yerine Connect yapılandırılır.
Kafka Streams ise uygulamalarınıza eklediğiniz bir kütüphanedir; konulardan okur, filtreler, zenginleştirir, join'ler ve toplar, sonra sonuçları konulara yazar.
Kısaca: Connect entegrasyon içindir; Streams hesaplama/işleme içindir.