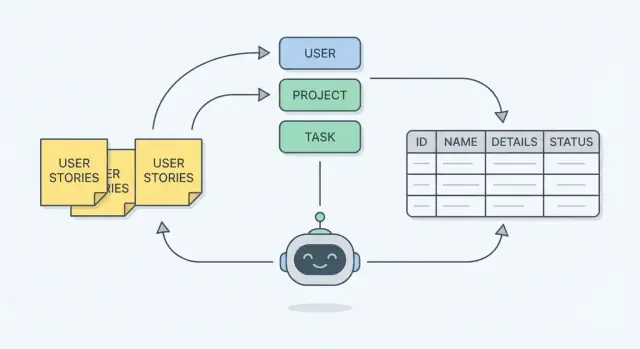
Ne İnşa Ediyorsunuz: Gerçek İşe Uyan Bir Şema
Bir veritabanı şeması, uygulamanızın bilgileri nasıl hatırlayacağını planlayan taslaktır. Pratik anlamda bu şunlardır:
- Tablolar: bilgi “kovalıkları” (Customers, Orders, Tickets)
- Alanlar (sütunlar): her şey hakkında sakladığınız detaylar (customer_name, order_date)
- İlişkiler: kovaların nasıl bağlandığı (bir Order bir Customer’a ait; bir Customer birçok Order’a sahip olabilir)
Şema gerçek işle eşleştiğinde, insanların gerçekten yaptığı işleri yansıtır—oluşturma, inceleme, onaylama, programlama, atama, iptal etme—beyaz tahtada hoş görünen şeyler yerine.
Neden kullanıcı hikayelerinden başlamak?
Kullanıcı hikayeleri ve kabul kriterleri gerçek ihtiyaçları düz bir dille açıklar: kim ne yapıyor ve “tamam” ne demek. Bunları kaynak olarak kullanırsanız, şema kritik ayrıntıları kaçırma olasılığı daha düşüktür (ör. “iadeyi kim onayladı”yı takip etmeliyiz veya “bir rezervasyon birden fazla kez yeniden planlanabilir”).
Hikayelerden başlamak ayrıca kapsam konusunda dürüst olmanızı sağlar. Eğer hikayelerde (veya iş akışında) yoksa, bunu isteğe bağlı olarak değerlendirin; “ya olur diye” karmaşık modeller kurmayın.
AI burada neler yapabilir, neler yapamaz
AI hızlandırmada yardımcı olabilir:
- Hikayelerden aday varlıkları çıkarmak
- Kabul kriterlerinin ima ettiği alanları (zaman damgaları, statüler, referanslar) önermek
- Muhtemel ilişkileri ve boşlukları işaretlemek (“onaylardan bahsediyorsunuz ama onaylayanı saklamıyorsunuz”)
AI güvenilir şekilde yapamaz:
- Yazmadığınız gizli iş kurallarını veya kenar durumlarını bilmek
- Doğru detay seviyesini (basit vs esnek) otomatik olarak seçmek
- Şemanın raporlama, güvenlik veya uyumluluk ihtiyaçlarına uygun olduğunu garanti etmek
AI'ı güçlü bir yardımcı, karar verici değil destekçi olarak görün.
Eğer bu yardımcıyı ilerlemeye dönüştürmek isterseniz, Koder.ai gibi bir vibe-coding platformu şema kararlarından çalışan bir React + Go + PostgreSQL uygulamasına daha hızlı geçmenize yardımcı olabilir—aynı zamanda modeli, kısıtları ve migrationları sizin kontrolünüzde tutar.
Beklentileri ayarlayın: yinelemeli, tek seferlik değil
Şema tasarımı bir döngüdür: taslak → hikayelere karşı test → eksik veriyi bul → iyileştir. Amaç mükemmel ilk çıktı değil; her kullanıcı hikayesine kadar izlenebilen ve “Evet, bu iş akışının ihtiyaç duyduğu her şeyi saklayabiliriz—and her tablonun neden var olduğunu açıklayabiliriz.” diyebileceğiniz bir modeldir.
Girdiler: Kullanıcı Hikayeleri, Kabul Kriterleri ve Gerçek Örnekler
Gereksinimleri tablolara dönüştürmeden önce neyi modelleyeceğiniz konusunda net olun. İyi bir şema nadiren boş bir sayfadan başlar—insanların yaptığı somut işlerden ve sonra ihtiyaç duyacağınız kanıtlardan (ekranlar, çıktılar ve kenar durumlar) başlar.
Bir arada bulundurmak istediğiniz tipik girdiler
Kullanıcı hikayeleri başlıktır, ama tek başına yeterli değildir. Şunları toplayın:
- Kullanıcı hikayeleri + roller (kim ne yapıyor ve neden)
- Kabul kriterleri ("mutlaka doğru olması gerekenler")
- Formlar/ekranlar (kullanıcıların yazdığı, seçtiği veya gördüğü alanlar)
- Raporlar/aktarımlar (özetlenmesi, gruplanması, filtrelenmesi gerekenler)
- Gerçek örnekler (örnek siparişler, faturalar, ticketlar, takvimler—temsil niteliğinde olan ne varsa)
AI kullanıyorsanız, bu girdiler modeli ayakları üzerinde tutar. AI hızlıca varlıklar ve alanlar önerebilir, ama ürününüzle örtüşmeyen bir yapı icat etmemesi için gerçek artefaktlara ihtiyacı vardır.
Kabul kriterleri: kısıtların gizli kaynağı
Kabul kriterleri genellikle veritabanı kurallarının en önemli kısmını içerir, veri açıkça belirtilmemiş olsa bile. Şuna dikkat edin:
- “E-posta benzersiz olmalı” (benzersizlik)
- “Status Draft, Submitted, Approved olabilir” (izin verilen değerler)
- “Sadece yöneticiler onaylayabilir” (izinler, muhtemelen audit alanları)
- “Ödemesi olan faturayı silemezsiniz” (referans kuralları)
Erken düzeltilecek yaygın tuzaklar
Belirsiz hikayeler (“Bir kullanıcı olarak projeleri yönetebilirim”) birden fazla varlık ve iş akışını gizleyebilir. Diğer sık eksiklikler iptaller, yeniden denemeler, kısmi iadeler veya yeniden atama gibi kenar durumların unutulmasıdır.
Hızlı hikaye-kalite kontrol listesi (modellemeden önce)
- Aktör/rol açıkça belirtilmiş mi?\n- Nesne spesifik mi (sadece “veri” veya “şeyler” değil)?\n- En az bir gerçek örnek var mı?\n- Kabul kriterleri doğrulamaları ve sınırları içeriyor mu?\n- Hata ve “ya olursa” durumları bahsedilmiş mi (veya açıkça ertelenmiş mi)?
Adım 1 — Hikayelerden Varlıkları Çıkar (İsimler)
Tablolar veya diyagramlardan önce kullanıcı hikayelerini okuyun ve isimleri vurgulayın. Gereksinim yazımında, isimler genellikle sistemin hatırlaması gereken “şeyleri” gösterir—bunlar genellikle şemada varlıklar olur.
Kısa zihinsel model: isimler varlık olur, fiiller eylem veya iş akışları olur. Eğer bir hikaye “Bir yönetici bir teknisyeni bir işe atar” diyorsa, olası varlıklar manager, technician ve job’tır—ve “atanır” daha sonra modele edeceğiniz bir ilişkiye işaret eder.
Bir ismin gerçek varlık olup olmadığını nasıl anlarsınız
Her isim kendi tablosuna layık değildir. Bir isim iyi bir varlık adayıdır when:
- Kendi kimliği var: tek bir örneğe işaret edebilirsiniz (Job #1042, Customer A).\n- Zaman içinde değişir: bir yaşam döngüsü vardır (bir iş scheduled → completed olur).\n- Birden fazla yerde kullanılır: birçok hikaye buna referans veriyor veya birçok iş akışı ona dokunuyor.
Bir isim yalnızca bir kez geçiyorsa veya başka bir şeyi tarif ediyorsa (“kırmızı buton”, “Cuma”), muhtemelen varlık değildir.
Öznitelik vs ayrı varlık ("Address" ve "Tag" testi)
Her detayı tabloya dönüştürmek yaygın bir hatadır. Kural şu:
- Eğer tek bir değerse ve bir şeyi tarif ediyorsa, genellikle bir özelliktir (ör. Customer.phone_number).\n- Eğer tekrarlanabilir, paylaşılan veya yapısal ise, genellikle ayrı bir varlıkdir.
İki klasik örnek:
- Address: Eğer gönderim ve fatura adreslerini saklıyor, geçmiş tutuyor veya adresleri müşteriler/konumlar arasında yeniden kullanıyorsanız, Address ayrı bir varlık olma eğilimindedir. Sadece tek bir posta adresine ihtiyacınız varsa ve yeniden kullanılmayacaksa, öznitelik olarak kalabilir.\n- Tag: Etiketler çoğunlukla ayrı varlık olmalıdır çünkü tekrarlanabilir ve birçoktan-çoğa ilişkilidir (bir Job birçok Tag’e sahip; bir Tag birçok Job’a uygulanır).
AI’ı aday varlık önermek için kullanmak (dikkatli olarak)
AI, hikayeleri tarayıp temalara göre gruplanmış aday isimler döndürebilir ve böylece varlık keşfini hızlandırabilir. Faydalı bir prompt: “Hikayelerden saklanması gereken isimleri çıkar ve eşanlamlıları/grupları birleştir.”
Çıktıyı başlangıç noktası olarak görün, cevap değil. Sonraki sorular:
- “Bunların hangilerinin bir yaşam döngüsü var veya kendi ID’si gerekir?”\n- “Hangileri aslında statü, kategori veya öznitelik?”\n- “Eşanlamlılar var mı (örn. ‘client’ vs ‘customer’)?”
Adım 1’in hedefi, gerçek hikayelere dayanarak savunabileceğiniz kısa, temiz bir varlık listesi oluşturmaktır.
Adım 2 — Detayları Alanlara Dönüştür (Saklamanız Gereken Hatırlatmalar)
Varlıkları adlandırdıktan sonra (ör. Order, Customer, Ticket), sonraki iş saklamanız gereken detayları yakalamaktır. Veritabanında bu detaylar alanlardır (özellikler)—sistemin unutmaması gereken hatırlatmalardır.
Alanları nasıl seçersiniz (tahmin etmeden)
Kullanıcı hikayesiyle başlayın, sonra kabul kriterlerini kontrol listesi gibi okuyun.\n
Eğer bir gereksinim “Kullanıcılar siparişleri teslim tarihine göre filtreleyebilir” diyorsa, delivery_date bir alandır (veya diğer saklanan verilerden güvenilir şekilde türetilmelidir). “İsteği kim onayladı ve ne zaman gösterilsin” diyorsa muhtemelen approved_by ve approved_at gerekir.
Pratik test: Birisi bunu görüntülemek, aramak, sıralamak, denetlemek veya hesaplamak isteyecek mi? Eğer evet ise, muhtemelen bir alan olmalıdır.
Temiz alanlar için basit kurallar
- Değerleri atomik tutun: “Ad” ve “Soyad” ayrı tutulmalıysa ayrı sütunlarda saklayın. Birden fazla değeri tek alana paketlemeyin (ör. “kırmızı, mavi”).\n- Tutarlı tipler kullanın: tarihler date tipinde, para decimal; boole true/false—karışık formatlardan kaçının (örn. “$10”, “10 USD”, “10”).\n- Yinelenen metinden kaçının: müşterinin adresini her sipariş satırına kopyalamayın. Doğru yerde bir kez saklayıp referans verin.
Kontrollü sözlükler: statüler, tipler ve kategoriler
Birçok hikaye “statü”, “tip” veya “öncelik” gibi kelimeler içerir. Bunları kontrollü sözlükler olarak ele alın—izin verilen değerlerin sınırlı seti.
Set küçük ve sabitse basit bir enum alanı işe yarar. Büyüyorsa, etiketlenmesi veya izin yönetimi gerektirecekse ayrı bir lookup tablosu kullanın (örn. status_codes) ve referans saklayın.
Böylece hikayeler, güvenilir arama, raporlama ve yanlış girişleri zorlaştıran alanlara dönüşür.
Adım 3 — Varlıkları İlişkilerle Bağlayın
Varlıkları (User, Order, Invoice, Comment vb.) ve alanlarını listeledikten sonra, onları bağlama zamanı. İlişkiler, hikayeler tarafından ima edilen “bu şeyler nasıl etkileşir” katmanıdır.
Üç ilişki tipi (düz İngilizce)
Birebir (1:1): “bir şey tam olarak bir diğerine sahip.”\n
- Hikâye ifadesi: “Her kullanıcının bir profili vardır.”\n- Model fikri:
User ↔ Profile (Neden yoksa birleştirilebilir).
Bire-çok (1:N): “bir şey birçok diğer şeye sahip olabilir.” Bu en yaygın olanıdır.\n
- Hikâye ifadesi: “Bir kullanıcı birçok siparişe sahip olabilir.”\n- Model fikri:
User → Order (Order üzerinde user_id saklayın).
Çoktan-çoğa (M:N): “birçok şey birçok şeyle ilişkili olabilir.” Bu ek bir tablo gerektirir.\n
- Hikâye ifadesi: “Bir sipariş birçok ürünü içerebilir ve bir ürün birçok siparişte olabilir.”
Çoktan-çoğa: join tablosu taktiği
Veritabanları Order içinde “ürün ID’leri listesi” gibi yapılarla düzgün çalışmaz. Bunun yerine ilişkinin kendisini temsil eden bir join tablosu oluşturun.
Örnek:
Order\n- Product\n- OrderItem (join tablosu)
OrderItem genellikle şunları içerir:
order_id\n- product_id\n- hikâyeden gelen ekstra detaylar: quantity, unit_price, discount
Dikkat edin: hikâyedeki detaylar (miktar gibi) çoğunlukla ilişkinin kendisine aittir, iki varlıktan hiçbirinin üzerine değil.
Zorunlu vs isteğe bağlı (jargondan uzak)
Hikâyeler ayrıca bir bağlantının zorunlu mu yoksa bazen eksik mi olduğunu söyler.
- “Bir sipariş bir kullanıcıya ait olmak zorunda” → her
Order için user_id gereklidir (boş olmasına izin vermeyin).\n- “Bir kullanıcının telefon numarası olabilir” → phone boş olabilir.\n- “Bir sipariş göndermeye (fiziksel ürünler) sahip olabilir” → shipping_address_id dijital siparişler için boş olabilir.
Hızlı kontrol: hikâye kaydı olmadan yaratamayacağınız şeyleri zorunlu kabul edin; “yapabilir”, “izin verilir” veya istisna varsa isteğe bağlı kabul edin.
Hikâye cümlelerini ilişki cümlelerine dönüştürün
Her hikâyeyi şu şekilde yeniden yazın:
- “Bir kullanıcı birçok yorum bırakabilir” →
User 1:N Comment\n- “Bir yorum bir kullanıcıya ait” → Comment N:1 User
Bunu hikayelerdeki her etkileşim için yapın. Sonunda ER diyagramı aracını açmadan önce işin nasıl yürüdüğünü gösteren bağlı bir model elde edeceksiniz.
Adım 4 — İş Akışlarını Kullanarak Durumları, Olayları ve Boşlukları Bulun
Gerçek bir önizleme paylaşın
Hazır olduğunuzda kendi özel alan adınızla gerçek bir uygulama paylaşın.
Kullanıcı hikayeleri size ne istendiğini söyler. İş akışları işi nasıl ilerlediğini adım adım gösterir. Bir iş akışını veriye çevirme, “bunu saklamayı unuttuk” problemlerini inşa etmeden önce yakalamanın en hızlı yollarından biridir.
Basit bir iş akışıyla başlayın
İş akışını eylemler ve durum değişimleri dizisi olarak yazın. Örneğin:
- Create request → Draft\n- Submit request → Submitted\n- Manager reviews → Approved or Rejected\n- If approved, work is scheduled → In progress\n- Completed → Done
Bu kalın kelimeler genellikle bir status alanı (veya küçük bir “state” tablosu) olur, açıkça izin verilen değerlerle.
İş akışları eksik alanları ortaya çıkarır
Her adımı yürürken sorun: “Sonra ne bilmemiz gerekir?” İş akışları şu alanları sıkça ortaya çıkarır:
- zaman damgaları:
submitted_at, approved_at, completed_at\n- sahiplik: created_by, assigned_to, approved_by\n- sebep/bağlam: rejection_reason, approval_note\n- sıralama: çok adımlı süreçler için sequence
Bekleme, yükseltme veya devredilmeler varsa genellikle en az bir zaman damgası ve şu anda “kimin kullandığı” bilgisini tutan bir alan gerekir.
İş akışları eksik tabloları da ortaya çıkarır
Bazı iş akışı adımları sadece alan değildir—ayrı veri yapılarıdır:
- Audit log / history "kim ne zaman statüyü değiştirdi" için\n- Approvals çoklu onaycı veya koşullu onay kuralları için\n- Attachments kullanıcılar adım sırasında dosya yüklediğinde\n- Comments tartışma sürecin bir parçasıysa
AI ile boşluk kontrolü yapmak
AI'a hem (1) kullanıcı hikayelerini ve kabul kriterlerini, hem de (2) iş akışı adımlarını verin. AI'dan her adımı listelemesini ve her biri için gerekli veriyi (durum, aktör, zaman damgası, çıktı) belirtmesini ve mevcut alanlar/tablolar tarafından karşılanmayan gereksinimleri vurgulamasını isteyin.
Koder.ai gibi platformlarda bu “boşluk kontrolü” özellikle pratiktir çünkü hızlıca yineleyebilir, şema varsayımlarını düzeltebilir, iskelet kodu yeniden oluşturabilir ve uzun bir manuel boilerplate yolculuğu yaşamadan ilerleyebilirsiniz.
Anahtarlar, Benzersizlik ve Temel Kısıtlar (Jargonsuz)
Kullanıcı hikayelerinden tablolara geçerken sadece alanları listelemiyorsunuz—aynı zamanda verilerin zaman içinde tanımlanabilir ve tutarlı kalmasını nasıl sağlayacağınızı da belirliyorsunuz.
Birincil anahtarlar: her satır için sabit bir “kimlik kartı”
Bir primary key bir kaydı benzersiz tanımlar—satırın kalıcı kimlik kartı gibidir.
Neden her satırın birine ihtiyacı var: hikayeler güncellemeleri, referansları ve geçmişi ima eder. Örneğin “Destek bir siparişi görüntüleyip iade verebilir” derken, müşteri e-postasını değiştirse bile siparişi işaret edecek sabit bir yol gerekir.
Genellikle bu içsel bir iddir (sayı veya UUID) ve değişmez.
Yabancı anahtarlar: tablolar arası güvenli işaretler
Bir foreign key, bir tablonun diğerine güvenli şekilde işaret etme yoludur. Eğer orders.customer_id customers.id'i işaret ediyorsa, veritabanı her siparişin gerçek bir müşteriye ait olmasını sağlayabilir.
Bu, “Bir kullanıcı faturalarını görebilir” gibi hikayelere karşılık gelir: fatura herhangi bir yerde yüzüyorsa değil, bir müşteriye bağlanmış olmalıdır.
Benzersizlik kuralları: “benzersiz olmalı”yı uygulamaya koymak
Kullanıcı hikayeleri gizli benzersizlik gereksinimleri içerir:\n
- “Kullanıcılar e-posta ile kayıt olur” → unique email (veya multi-tenant ise tenant başına benzersiz)\n- “Finans fatura numarasına göre arar” → unique invoice_number
Bu kurallar ileride kafa karıştıran tekrarları (veri hatalarını) önler.
İndeksleme (yüksek seviyede): sık yapılan aramaları hızlandırın
İndeksler “customer by email bulun” veya “orders by customer listele” gibi sorguları hızlandırır. Önce en sık yapılan sorgular ve benzersizlik kurallarıyla uyumlu indekslerden başlayın.
Ertelenmesi gereken: nadir raporlar veya spekülatif filtreler için yoğun indeksleme. Bu ihtiyaçları hikayelerde yakalayın, önce şemayı doğrulayın, sonra gerçek kullanım ve yavaş sorgu verisiyle optimize edin.
Veriyi Tutarlı Tutun: Pratik Bir Normalizasyon Kontrol Listesi
Kod tabanına sahip olun
Derin özelleştirme gerektiğinde kaynak kodunu dışa aktararak kontrolü elinizde tutun.
Normalizasyonun basit hedefi: çakışan kopyaları önlemek. Aynı gerçek iki yerde saklanabiliyorsa, er ya da geç uyuşmazlık çıkar (iki farklı yazım, iki fiyat, iki “güncel” adres).
Herhangi bir taslak şemada çalıştırabileceğiniz hızlı kontrol listesi
1) Tekrarlayan gruplara dikkat edin\n
“Phone1, Phone2, Phone3” veya “ItemA, ItemB, ItemC” gibi kalıplar görürseniz, bu ayrı bir tablo sinyalidir (örn. CustomerPhones, OrderItems). Tekrarlayan gruplar aramayı, doğrulamayı ve ölçeklemeyi zorlaştırır.
2) Aynı ismi birden fazla tabloda çoğaltmayın\n
Eğer CustomerName Orders, Invoices ve Shipments içinde görünüyorsa, birden fazla gerçek kaynağı yarattınız. Müşteri detaylarını Customers içinde tutun ve başka yerde sadece customer_id saklayın.
3) Aynı şey için birden fazla sütun kullanmaktan kaçının\n
billing_address, shipping_address, home_address gibi sütunlar gerçekten farklı kavramlarsa uygundur. Ancak eğer aslında “farklı tiplerde birçok adres” modelliyorsanız, Addresses tablosu ve type alanı kullanın.
4) Lookupları serbest metinden ayırın\n
Kullanıcılar bilinen bir setten seçiyorsa (status, category, role), bunu ya sınırlı bir enum ya da lookup tablosuyla tutarlı biçimde modelleyin. Bu “Pending” vs “pending” vs “PENDING” sorunlarını önler.
5) Her ID olmayan alanın doğru şeye bağlı olduğunu kontrol edin\n
Bir sezgi kontrolü: bir tabloda bir sütun tablonun ana varlığını değilse, muhtemelen başka yerde olmalı. Örnek: Orders tablosunda product_price yalnızca “sipariş zamanındaki fiyat” anlamına geliyorsa (tarihsel snapshot), orada olabilir.
Denormalize etmek kabul edilebilir olduğunda (sonradan yapılacak bir seçim)
Bazen kasten çoğaltma yapılır:\n
- Raporlama/performance: ön-agregasyon veya özet tablolar\n- Önbellekleme: hesaplanan bir değeri tekrar hesaplamamak için saklama\n- Audit/geçmiş: satın alma zamanındaki “isim” gibi gerçeği korumak için kopyalama
Önemli olan kasıtlı olmasıdır: hangi alanın gerçek kaynak olduğu ve kopyaların nasıl güncellendiği belgelenmelidir.
AI nın yardımı ve insan kararları
AI kuşkulu çoğaltmaları (tekrarlayan sütunlar, benzer alan adları, tutarsız “status” alanları) işaretleyebilir ve tablo ayırma önerileri sunabilir. İnsanlar yine de basitlik vs esneklik vs performans arasında ürün kullanımı doğrultusunda karar verir.
Saklanan vs Hesaplanan: Veritabanında Ne Olmalı
Kullanışlı kural: daha sonra güvenilir şekilde yeniden oluşturamayacağınız gerçekleri saklayın; diğer her şeyi hesaplayın.
Saklanan vs hesaplanan (türev) veriler
Saklanan veri gerçek kaynaktır: tekil satır öğeleri, zaman damgaları, durum değişiklikleri, kim ne yaptı. Hesaplanan (türev) veri bu gerçeklerden üretilir: toplamlar, sayaçlar, “gecikmiş mi” gibi bayraklar ve rollup’lar.
Aynı girdilerden türetilebilecek iki değerin her ikisini de saklarsanız, uyumsuzluk riski doğar.
Türev değer saklamanın neden uyuşmazlıklara yol açtığı
Türetilmiş değerler girdiler değiştikçe değişir. Hem girdileri hem sonucu saklarsanız, her iş akışı ve kenar durumunda bunları senkronize etmek zorunda kalırsınız (düzenlemeler, iadeler, kısmi gönderimler, tarih gerilemesi). Bir güncelleme kaçarsa veritabanı çelişkili bilgiler verir.
Örnek: order_total saklarken order_items de saklıyorsanız; biri güncellendiğinde toplam güncellenmezse finans ile sepet farklı rakam görür.
Hangi durumlarda geçmiş/snapshot saklanmalı
İş akışları geçmiş gerçeğe ihtiyaç duyduğunda, sadece “güncel” bilgi değil, o andaki değerler saklanmalıdır.
Bir sipariş için saklayabilecekleriniz:
- Satır öğeleri ve fiyatlar (gözlemler)\n- Checkout sırasında yakalanmış
order_total (snapshot), çünkü vergiler, indirimler ve fiyatlama kuralları sonra değişebilir
Envanter için “stok seviyesi” genellikle hareketlerden hesaplanır. Ancak denetim izi istiyorsanız hareketleri saklayın ve raporlama hızı için periyodik snapshot’lar da tutabilirsiniz.
Giriş izleme için last_login_at gibi bir olay zaman damgası tutun. “Son 30 günde aktif mi?” sorgusu hesaplanmış kalır.
Çalışılmış Örnek: 5 Kullanıcı Hikayesinden ER Modeline
Bir destek ticket uygulaması üzerinden gidelim. Beş kullanıcı hikayesinden basit bir ER modele (varlıklar + alanlar + ilişkiler) geçelim, sonra bir iş akışı ile kontrol edelim.
5 kullanıcı hikayesi → isimler → varlıklar
- Bir müşteri konu, açıklama ve kategori ile bir destek ticketı oluşturabilir.\n2. Bir agent ticketı kendisine veya başka bir agente atayabilir.\n3. Bir agent ticketa dahili notlar ve herkese açık cevaplar ekleyebilir.\n4. Bir müşteri ticket güncellendiğinde ve kapandığında bunu görebilir.\n5. Bir yönetici ticketların ne kadar açık kaldığını ve kim tarafından kapatıldığını takip edebilir.
Bu isimlerden temel varlıkları çıkarıyoruz:
- User (customers, agents, managers)\n- Ticket\n- Message (public replies + internal notes)\n- Category\n- TicketEvent (audit/history)
Alanlar ve ilişkiler (kısa ER modeli)
- User: id, name, email, role\n- Category: id, name\n- Ticket: id, subject, description, status, created_at, updated_at, closed_at\n - ilişkiler: Ticket.category_id → Category.id\n - ilişkiler: Ticket.requester_id → User.id (customer)\n - ilişkiler: Ticket.assignee_id → User.id (agent, nullable)\n- Message: id, ticket_id, author_id, body, is_internal, created_at\n - ilişkiler: Message.ticket_id → Ticket.id\n - ilişkiler: Message.author_id → User.id\n- TicketEvent: id, ticket_id, actor_id, type, from_status, to_status, created_at
İş akışı eşlemesi: oluştur → güncelle → kapat
- Create: Ticket insert (status = “open”, created_at), TicketEvent insert(type = “created”).\n- Update (assign, reply): Message insert veya Ticket.assignee_id güncellemesi ve TicketEvent insert(type = “assigned”/“replied”, updated_at).\n- Close: Ticket.status = “closed” update, closed_at set, TicketEvent insert(type = “closed”, actor_id = closer).
“Öncesi ve sonrası”: AI eksik kısıtı yakalar
Önce (yaygın eksik): Ticket assignee_id içerir, ama sadece agent rolündeki kullanıcıların atama alabileceğini sağlamıyoruz.\n
Sonra: AI bunu işaretler ve pratik bir kural eklersiniz: assignee, role = “agent” olan bir User olmalıdır (uygulama doğrulaması veya veritabanı kısıtı/policy ile uygulanır). Bu, “müşteriye atandı” gibi raporları bozan veriyi önler.
Şemayı Doğrulayın: Her Hikayeye Geri İzleyin
Yap ve kredi kazan
Koder.ai hakkında içerik oluşturarak veya ekip arkadaşlarını davet ederek kredi kazanın.
Bir şema her kullanıcı hikayesinin güvenilir şekilde yanıtlanabileceği zaman “tamamlanmış” sayılır. En basit doğrulama adımı her hikayeyi alıp: "Bu soruyu veritabanından, her durum için güvenilir şekilde cevaplayabilir miyiz?" diye sormaktır. Cevap “belki” ise modelde bir eksik var demektir.
Her hikayeyi veritabanı sorusuna çevirin
Her kullanıcı hikayesini rapor, ekran veya API'nin soracağı net sorulara dönüştürün. Örnekler:
- Raporlar: “Son 30 günde müşteri bazında açık tüm siparişleri toplamlarla göster.”\n- İzinler: “Bu mağaza için iadeleri kim onaylayabilir?”\n- Kenar durumlar: “Bir sipariş kargo adresi olmadan var olabilir mi? Dijital ürünler ne olur?”\n- Silinmeler: “Bir müşteriyi silersek, siparişlere, faturalara ve notlara ne olur?”
Eğer bir hikayeyi net bir soruya çeviremiyorsanız, hikaye belirsizdir. Eğer soruya çevirebiliyorsanız ama şema ile cevap veremiyorsanız, eksik bir alan, ilişki, statü/olay veya kısıt var demektir.
Örnek veri ile hızlı sağlık kontrolü
Küçük bir veri seti (ana tablolar için 5–20 satır) oluşturun; normal ve garip durumları (çoğaltmalar, eksik değerler, iptaller) dahil edin. Sonra hikayeleri bu veriyi kullanarak “oynayın”. Hızla şu tür sorunları fark edersiniz: “hangi adresin satın alma zamanında kullanıldığını söyleyecek yerimiz yok” veya “değişikliği kim onayladı saklanmıyor”.
AI ile ele alınmamış durumları bulun
AI'dan her hikaye için doğrulama soruları (kenar durumlar ve silme senaryoları dahil) üretmesini ve bu soruları cevaplamak için hangi veriye ihtiyaç duyulduğunu listelemesini isteyin. Bu listeyi şemanızla karşılaştırın: herhangi bir uyuşmazlık somut bir aksiyon maddesidir.
AI'ı Güvenli Kullanma ve Şemayı Sürdürülebilir Tutma
AI veri modellemeyi hızlandırsa da hassas bilgi sızma riskini veya kötü varsayımlar sabitleme riskini artırır. Onu çok hızlı bir yardımcı olarak görün: faydalı, ama gözetim gerektirir.
AI ile ne paylaşılmalı (ne paylaşılmamalı)
Modellemeye yeterli ama güvenli girdiler paylaşın:
- Sanitize edilmiş kullanıcı hikayeleri (müşterileri/ürünleri/konumları yeniden adlandırın)\n- Kabul kriterleri ve kenar durumlar\n- Sahte veri örnekleri (ör.
invoice_total: 129.50, status: "paid")\n- Mevcut CSV başlıkları / var olan tabloların yapısı (yapı genellikle güvenlidir; içerik genellikle değil)
Kaçının:
- Gerçek isimler, e-postalar, telefonlar, adresler\n- Gerçek sipariş geçmişleri, destek kayıtları, iç notlar\n- API anahtarları, veritabanı kimlik bilgileri, özel veriler içeren ekran görüntüleri
Gerçekçilik gerekiyorsa, üretim satırlarını asla kopyalamayın—formatlara ve aralıklara uyan sentetik örnekler üretin.
Varsayımları şema yanında tutun
Şemalar genellikle “herkes varsaydığı” şeyler yüzünden başarısız olur. ER modelinin yanında kısa bir karar kaydı tutun:
- Tanımlar (“Aktif hesap ne demek?”)\n- Kısıtlar (“Bir kullanıcı birden fazla organizasyona ait olabilir”)\n- Tradeoff’lar (“Her faturada para birimi kodu saklanır, denetim için”)
Bu, AI çıktılarını ekibin bilgisine dönüştürür.
Değişime hazırlık: versiyonlama ve migrationlar
Şemanız hikayelerle evrilecek. Güvende tutmak için:
- Şema değişikliklerini versiyonlayın (migration dosyaları Git’de)\n- Mümkünse geri alınabilir migrationlar yazın\n- Seed ve örnek sorguları güncelleyin böylece değişiklikler test edilebilir olsun\n- AI tarafından üretilen migrationları normal kod gibi inceleyin
Koder.ai gibi platformlar kullanıyorsanız, yineleme sırasında snapshot ve rollback gibi koruyuculardan faydalanın ve gerektiğinde kaynak kodu dışa aktarın.
Basit, tekrar edilebilir bir iş akışı
- Hikayeleri sanitize edin + 5–10 sentetik örnek oluşturun.\n2. AI’dan varlıklar, alanlar, ilişkiler ve kısıtlar önerisini isteyin.\n3. Takım ile gözden geçirin; varsayımları kaydedin.\n4. Migrationları uygulayın; küçük bir “hikaye izleme” testi çalıştırın (her hikaye modele göre cevaplanabiliyor mu).\n5. Hikayeler değiştikçe tekrarlayın; şema ve notları güncel tutun.