02 Ara 2025·8 dk
Larry Page'in Google'ın Uzun Vadeli Oyununun Arkasındaki Orijinal Yapay Zeka Vizyonu
Larry Page’in erken yapay zeka fikirlerinin ve bilgi anlayışının Google’ın uzun vadeli stratejisini—aramadan moonshot’lara ve AI-öncelikli bahislere—nasıl şekillendirdiğini keşfedin.
Bu yazıda “Larry Page’in yapay zeka vizyonu” ile ne kastediliyor
Bu, tek bir atılımı abartan bir haber yazısı değil. Uzun vadeli düşünceyle ilgili: bir şirketin bir yönü erken seçip, birden fazla teknoloji değişimi boyunca yatırım yapmaya devam ederek büyük bir fikri yavaşça günlük ürünlere nasıl dönüştürebileceğiyle ilgili.
Bu yazı “Larry Page’in yapay zeka vizyonu” dediğinde, “Google bugünkü sohbet botlarını tahmin etti” demek istemiyor. Daha basit ve daha kalıcı bir şey kastediliyor: deneyimden öğrenen sistemler kurmak.
Düz İngilizce bir tanım
Bu yazıda “yapay zeka vizyonu” birkaç bağlantılı inancı ifade ediyor:
- Bilgisayarlar yalnızca el yazısı kuralları izleyerek değil, veriden öğrenerek performanslarını geliştirmeli.
- En iyi sistemler, gerçek dünya kullanımı geri bildirimleri yarattığı için zamanla daha iyi olur (insanların neye tıkladığı, neyi görmezden geldiği, nasıl yeniden ifade ettikleri).
- Öğrenmeyi pratik hâle getirmek için altyapıya ihtiyaç vardır: hızlı işlem, güvenilir depolama ve büyük ölçekte deneyleri güvenle çalıştırma yolları.
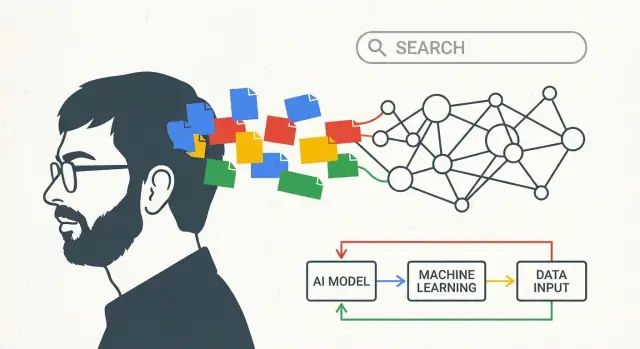
Başka bir deyişle, “vizyon” tek bir modelden çok bir motor hakkındadır: sinyalleri topla, desenleri öğren, iyileştirmeleri gönder, tekrarla.
İzleyeceğimiz yay
Bu fikri somutlaştırmak için yazının geri kalanı basit bir ilerlemeyi izliyor:
- Arama: insanlara iyi cevaplar bulmada yardımcı olacak net bir problemle başla.
- Veri + altyapı: gerçekte neyin “iyi” olduğunu öğrenmek için kullanım verisini kullan ve bunu işlemek için makineleri kur.
- Yapay Zeka-öncelikli ürünler: öğrenen sistemleri varsayılan yaklaşım olarak ele al, böylece ses, görseller ve yeni arayüzler her şeyi baştan yazmadan iyi çalışabilir.
Yazının sonunda “Larry Page’in yapay zeka vizyonu” bir slogan gibi değil, bir strateji gibi hissettirmeli: öğrenme sistemlerine erken yatırım yapın, onları besleyecek boruları kurun ve yıllar içinde bileşik ilerlemeye sabredin.
Google’ın çözmeye çalıştığı erken problem: iyi cevaplar bulmak
Erken web basit ama sonuçları karmaşık bir problem taşıyordu: bir kişi tarafından elden geçirilemeyecek kadar çok bilgi ortaya çıkmıştı ve çoğu arama aracı önemli olanı tahmin ediyordu.
Bir sorgu yazdığınızda, birçok motor sayfadaki bir kelimenin ne sıklıkta geçtiği, başlıkta olup olmadığı veya site sahibinin görünmez metne kelime doldurup doldurmadığı gibi bariz sinyallere dayanıyordu. Bu, sonuçların kolayca manipüle edilmesini ve güvenilmesini zorlaştırıyordu. Web, onu düzenlemeye çalışan araçlardan daha hızlı büyüyordu.
PageRank: bir öneri gibi açıklaması
Larry Page ve Sergey Brin’in temel sezgisi, web’in zaten yerleşik bir oy verme sistemine sahip olduğuydu: bağlantılar.
Bir sayfadan diğerine verilen bağlantı, bir makaledeki atıf ya da bir arkadaşın önerisine benzeri bir oy gibidir. Ancak tüm öneriler eşit değildir. Birçokları tarafından değerli kabul edilen bir sayfadan gelen bağlantı, bilinmeyen bir sayfadan gelen bağlantıdan daha fazla sayılmalıdır. PageRank bu fikri matematiğe döktü: sayfaları yalnızca kendi içeriğine göre değil, diğer web sayfalarının bağlantılar yoluyla onlara “ne söylediğine” göre sıraladı.
Bu aynı anda iki önemli şey yaptı:
- Sorguyla tam olarak aynı terimleri tekrarlamayan yetkili sayfaları ortaya çıkarmaya yardımcı oldu.
- Güvenirliği ağa yayılmış şekilde kazanmak gerektiği için sıralamayı manipüle etmeyi zorlaştırdı.
Ölçüm ve yinelemenin ilk günden neden önemli olduğu
Sadece zekice bir sıralama fikriye olmak yetmiyordu. Arama kalitesi hareketli bir hedefti: yeni sayfalar ortaya çıkıyor, spam uyum sağlıyor ve insanların bir sorgudan ne anladığı değişebiliyordu.
Bu yüzden sistem ölçülebilir ve güncellenebilir olmalıydı. Google, değişiklikleri deneme, sonuçların iyileşip iyileşmediğini ölçme ve tekrarlama üzerine yoğunlaştı. Bu yineleme alışkanlığı şirketin uzun vadeli “öğrenen” sistem yaklaşımını şekillendirdi: aramayı tek seferlik bir mühendislik projesi değil, sürekli değerlendirilebilen bir şey olarak görmek.
Veri bir ivme döngüsü: gerçek kullanımdan öğrenmek
Mükemmel arama sadece zekice algoritmalarla ilgili değildir—algoritmaların öğrenebileceği sinyallerin kalite ve niceliğiyle ilgilidir.
Erken Google’un yerleşik bir avantajı vardı: web kendisi neyin önemli olduğuna dair “oylarla” doludur. Sayfalar arasındaki bağlantılar (PageRank’in temeli) atıflar gibi davranır ve bağlantı metni (“buraya tıkla” vs. “en iyi yürüyüş botları”) anlam katar. Bunun üzerine sayfalar arasındaki dil kalıpları eşanlamlıları, yazım çeşitlerini ve aynı sorunun birçok farklı şekilde nasıl sorulduğunu anlamaya yardımcı olur.
Bileşikleyen geri besleme döngüsü
Bir arama motoru ölçekte kullanılmaya başladığında, kullanım ek sinyaller üretir:
- Tıklamalar, belirli bir sorgu için hangi sonuçların gerçek kullanıcılar tarafından alakalı göründüğünü gösterir.
- “Uzun tıklamalar” ile hızlı geri dönüşler memnuniyeti ima edebilir.
- Sorgu yeniden formülasyonları (farklı kelimelerle yeniden arama) niyet ile sonuçlar arasındaki uyumsuzlukları ortaya çıkarabilir.
Bu ivme döngüsüdür: daha iyi sonuçlar daha fazla kullanım çeker; daha fazla kullanım daha zengin sinyaller yaratır; daha zengin sinyaller sıralamayı ve anlayışı geliştirir; ve bu iyileşme daha fazla kullanıcıyı çeker. Zamanla arama, sabit kurallar seti olmaktan çıkar ve insanların gerçekten faydalı bulduklarına uyum sağlayan öğrenen bir sisteme dönüşür.
Veri çeşitliliğinin neden önemli olduğu
Farklı veri türleri birbirini güçlendirir. Bağlantı yapısı yetkiyi ortaya çıkarabilirken, tıklama davranışı güncel tercihleri yansıtır ve dil verisi belirsiz sorguları yorumlamaya yardımcı olur (“jaguar” hayvan mı yoksa araba mı). Birlikte, bunlar sadece “bu kelimeleri içeren sayfalar hangileri” sorusunu değil, “bu niyet için en iyi cevap nedir” sorusunu yanıtlamayı mümkün kılar.
Gizlilik hakkında bir not
Bu döngü bariz gizlilik sorularını gündeme getirir. Kamuya açık, güvenilir raporlar uzun zamandır büyük tüketici ürünlerinin muazzam etkileşim verileri ürettiğini ve şirketlerin kaliteyi geliştirmek için toplulaştırılmış sinyalleri kullandığını belirtiyor. Google’ın zaman içinde gizlilik ve güvenlik kontrollerine yatırım yaptığı da genişçe belgelenmiştir; detaylar ve etkinlikleri ise tartışmalıdır.
Alınacak ders basit: gerçek dünya kullanımından öğrenmek güçlüdür—ve güven, bu öğrenmenin nasıl sorumlu bir şekilde yapıldığına bağlıdır.
“Makineyi” kurmak: yapay zekayı pratik yapan altyapı
Google, dağıtılmış hesaplamaya erken yatırım yaptı çünkü bu trend olduğu için değil—web’in düzensiz ölçeğiyle başa çıkmanın tek yoluydu. Milyarlarca sayfayı taramak, sıralamaları sık sık güncellemek ve sorgulara saniyenin kesirlerinde yanıt vermek istiyorsanız, tek bir büyük bilgisayara güvenemezsiniz. Birçok daha ucuz makinenin birlikte çalışması, yazılımın arızaları normal sayması gerekir.
Dağıtılmış hesaplamanın neden çok erken önemli olduğu
Arama, Google’ı verileri güvenilir şekilde depolayıp işleyebilen sistemler inşa etmeye zorladı. O aynı “birden çok bilgisayar, tek sistem” yaklaşımı, indeksleme, analiz, deneyler ve nihayetinde makine öğrenimi dahil her şeyin temeli oldu.
Temel sezgi şudur: altyapı yapay zekadan ayrı değildir—hangi tür modellerin mümkün olduğunu belirler.
Altyapı nasıl yapay zekayı demodan ürüne çevirir
Uygun bir modeli eğitmek, ona çok sayıda gerçek örnek göstermek demektir. O modeli sunmak, milyonlarca kişi için kesintisiz, anlık şekilde çalıştırmak demektir. Her iki durumda da bunlar “ölçek problemleri”dir:
- Eğitim veriyi tekrar tekrar işlemek için devasa işlem gücü gerektirir.
- Sunum tahminleri hızlı (çoğunlukla milisaniyeler içinde) yapabilmek için düşük gecikmeli sistemler gerektirir; trafik zirvelerinde bile kesinti olmamalıdır.
Bir kez veri depolama, dağıtık hesaplama, performans izlemesi ve güncelleme dağıtımı için boru hatları kurduğunuzda, öğrenme tabanlı sistemler nadir, riskli yeniden yazımlar olarak değil, sürekli gelişebilen sistemler haline gelebilir.
“Altyapı ile güçlendirilmiş yapay zeka”nın günlük örnekleri
Bazı tanıdık özellikler makinenin neden önemli olduğunu gösterir:
- Yazım düzeltme: “restarant” → “restaurant” gibi kalıpları fark etmek birçok arama ve tıklamadan öğrenmeyi, sonra düzeltmeleri anında sorgu zamanında uygulamayı gerektirir.
- Otomatik tamamlama: ne yazmak üzere olduğunuzu tahmin etmek, toplanmış davranışa ve hızlı çıkarıma bağlıdır—aksi takdirde öneriler gecikir ve yanlış hissedilir.
- Çeviri: daha iyi çeviri kalitesi, büyük veri setlerinde eğitim yapmaktan ve kullanıcılar için hızlı çalışabilen modeller göndermekten gelir.
Google’ın uzun vadeli avantajı sadece zekice algoritmalara sahip olmak değil—algoritmaların internet ölçeğinde öğrenmesine, gönderilmesine ve gelişmesine izin veren operasyonel motoru kurmaktı.
Kurallardan öğrenmeye: arama nasıl sessizce daha “yapay zeka benzeri” oldu
Öğrenme döngüsünü hızlıca gönderin
Sohbetten bir web veya backend MVP'si oluşturun, sonra kullanıcıdan öğrenmek için geri bildirim döngüleri ekleyin.
Erken Google zaten “akıllı” görünüyordu, ama bu zekâ büyük ölçüde mühendislikti: bağlantı analizi (PageRank), el ile ayarlanmış sıralama sinyalleri ve spam için birçok kestirimsel kural. Zamanla ağırlık merkezi, insanların ne demek istediği konusunda veriden öğrenen sistemlere kaydı—sadece yazdıkları değil.
ML aramanın hissini nasıl değiştirdi
Makine öğrenimi, günlük kullanıcının fark edeceği üç şeyi kademeli olarak geliştirdi:
- Sıralama kalitesi: sabit formüllerle sinyalleri ağırlamak yerine, modeller hangi sinyal kombinasyonlarının kullanıcıları tatmin etme eğiliminde olduğunu öğrendi (anonimleştirilmiş toplu davranış ve insan kalite değerlendiricisi geri bildirimi ile ölçüldü).
- Niyet anlama: “jaguar hızı” veya “apple destek” gibi sorgular anlamı, bağlamı ve belirsizliği çıkarmayı zorunlu kıldı. Öğrenme tabanlı sistemler, kelimeleri kavramlara ve olası hedeflere eşlemekte daha iyi oldu.
- Spam ve güven: içerik fabrikaları ve manipülatif SEO ölçeklendiğinde, ML doğal olmayan bağlantı kalıplarını, zayıf içeriği ve diğer taktikleri tespit etmeye yardımcı oldu—yüksek kaliteli sonuçlara yönelik daha geniş itici gücü destekledi.
Okuyucu dostu kilometre taşları zaman çizelgesi
- 1998: PageRank ve orijinal Google makalesi, bağlantılar aracılığıyla alaka temeli için zemini attı.
- 2000'lerin başı: istatistiksel yazım düzeltme ve sorgu önerileri “şunu mu demek istediniz” ve yeniden formülasyonları iyileştirdi.
- 2011: Panda düşük kaliteli içeriği hedef aldı; kalite sinyalleri daha sistematik hâle geldi.
- 2012: Penguin bağlantı manipülasyonunu cezalandırdı, anti-spam yaklaşımını manuel kuralların ötesine taşıdı.
- 2015: RankBrain (öğrenme tabanlı bir sıralama bileşeni) tanıdık olmayan veya belirsiz sorgulara yardım etti.
- 2018–2019: neural matching ve BERT daha güçlü dil anlayışı getirdi, özellikle daha uzun sorgular ve edatlar için.
- 2021+: MUM dönemi çok görevli modeller ve “yardımcı içerik” çabaları daha derin niyet ve fayda sinyallerine yöneltti.
Değer katacak kaynaklar
Güvenilirlik için birincil araştırma ve kamuya açık ürün açıklamalarını karışık olarak alıntılayın:
- Araştırma makaleleri: Brin & Page (PageRank, 1998), BERT (Devlin ve diğ., 2018).
- Resmi duyurular: Google Search blog yazıları RankBrain, BERT, MUM, Panda/Penguin güncellemeleri üzerine.
- Konuşmalar/röportajlar/etkinlikler: Amit Singhal ile sıralama evrimi üzerine röportajlar; Sundar Pichai konuşmaları (Google I/O); modern kilometre taşları için “Search On” etkinlikleri.
Araştırma kültürü: uzun vuruşları kullanışlı sistemlere dönüştürmek
Google’ın uzun oyunu sadece büyük fikirlere sahip olmakla ilgili değildi—akademik görünen makaleleri milyonlarca kişinin gerçekten kullandığı şeylere çevirebilen bir araştırma kültürüne dayanıyordu. Bu, merakı ödüllendirmenin yanı sıra bir prototipi güvenilir bir ürüne dönüştürecek yollar inşa etmeyi gerektiriyordu.
“Yayınla”dan “gönder”e
Birçok şirket araştırmayı ayrı bir ada gibi ele alır. Google daha sıkı bir döngü için bastırdı: araştırmacılar iddialı yönleri keşfedebilir, sonuçları yayımlayabilir ve yine de gecikme, güvenilirlik ve kullanıcı güveniyle ilgilenen ürün ekipleriyle işbirliği yapabilir. O döngü çalıştığında, bir makale bitiş noktası değil—daha hızlı, daha iyi bir sistemin başlangıcıdır.
Bunu pratik olarak görmek, model fikirlerinin “küçük” özelliklerde nasıl ortaya çıktığını gözlemlemektir: daha iyi yazım düzeltme, daha akıllı sıralama, geliştirilmiş öneriler veya daha doğal çeviri. Her adım küçük görünebilir, ancak birlikte aramanın hissini değiştirirler.
Ritmi belirleyen çalıştaylar
Birkaç çaba, makaleden ürüne boru hattının simgesi oldu. Google Brain, yeterli veri ve işlem gücünüz olduğunda derin öğrenmeyi şirket içine iterek eski yaklaşımları geçebileceğini kanıtladı. Daha sonra TensorFlow, ekiplerin modelleri tutarlı şekilde eğitip dağıtmasını kolaylaştırdı—ölçekli makine öğrenimi için önemsiz görünen ama kritik bir bileşen.
Sinirsel makine çevirisi, konuşma tanıma ve görsel sistemler üzerindeki araştırma çalışmaları da laboratuvar sonuçlarından günlük deneyimlere geçti; genellikle kaliteyi artıran ve maliyeti düşüren çoklu yinelemeler sonrasında.
Sabır neden önemli
Getiri eğrisi nadiren hemen gelir. Erken sürümler pahalı, hatalı veya entegrasyonu zor olabilir. Avantaj, altyapı kurmak, geri bildirim toplamak ve modeli güvenilir olana kadar rafine etmek için fikirle yeterince uzun süre kalmaktan gelir.
Bu sabır—uzun atışlara fon sağlama, sapmalara izin verme ve yıllarca yineleme—iddialı yapay zeka kavramlarını Google ölçeğinde insanların güvenebileceği kullanışlı sistemlere dönüştürmeye yardımcı oldu.
Yeni girdiler: ses, resimler ve video daha akıllı modelleri zorladı
Metin arama zeki sıralama numaralarını ödüllendiriyordu. Ancak Google ses, fotoğraf ve videoyu almaya başladığında eski yaklaşım tıkanmaya başladı. Bu girdiler dağınıktır: aksanlar, arka plan gürültüsü, bulanık resimler, sallantılı çekimler, argo ve yazılı olarak hiçbir yerde bulunmayan bağlam. Bunları kullanışlı hâle getirmek için Google, elle yazılmış kurallara dayanmaktan ziyade veriden desen öğrenen sistemlere ihtiyaç duydu.
Ses: sesi niyete dönüştürmek
Sesli arama ve Android dikte ile hedef sadece “kelimeleri yazıya dökmek” değildi. Hızlıca, cihaz üzerinde veya zayıf bağlantılarda bile birinin ne demek istediğini anlamaktı.
Konuşma tanıma, Google’ı büyük ölçekli makine öğrenimine itti çünkü performans, modellerin geniş ve çeşitli ses veri setleri üzerinde eğitildiğinde en çok iyileşti. Bu ürün baskısı, eğitim için ciddi işlem gücü, özel araçlar (veri boru hatları, değerlendirme setleri, dağıtım sistemleri) ve modelleri yaşayan ürünler olarak yineleyebilecek insanları işe alma yatırımını haklı çıkardı.
Fotoğraflar: meta veriden ziyade anlam
Fotoğrafların anahtar kelimeleri yoktur. Kullanıcılar Google Photos’un “köpekleri”, “plajı” veya “Paris seyahatimi” bulmasını bekler; etiketlemedikleri halde.
Bu beklenti, nesne tespiti, yüz gruplama ve benzerlik araması gibi daha güçlü görüntü anlayışını zorladı. Yine, kurallar gerçek hayatın çeşitliliğini kapsayamazdı; bu yüzden öğrenen sistemler pratik yoldu. Doğruluğu artırmak daha fazla etiketlenmiş veri, daha iyi eğitim altyapısı ve daha hızlı deney döngüleri gerektirdi.
Video ve öneriler: ölçek zayıf noktaları açığa çıkarıyor
Video çift zorluk getirdi: zaman içinde görüntüler ve ses. YouTube’da kullanıcılara yardımcı olmak—arama, altyazılar, “Sıradaki” ve güvenlik filtreleri—konular ve diller arasında genelleme yapabilen modeller gerektirdi.
Öneriler, makine öğrenimine olan ihtiyacı daha da belirginleştirdi. Milyarlarca kullanıcı tıkladıkça, izledikçe, atladıkça ve geri döndükçe sistemin sürekli adapte olması gerekiyordu. Bu tür bir geri besleme döngüsü, modellerin kırılmadan gelişmesini sağlamak için ölçekli eğitim, metrikler ve yetenek yatırımlarını ödüllendirdi.
Yapay Zeka-öncelikli dönüş: AI’yı özellik değil varsayılan yapmak
AI fikirlerini mobile taşıyın
Sohbetten bir Flutter mobil uygulaması oluşturun ve gerçek dünya geri bildirimlerine göre yineleyin.
“Yapay Zeka-öncelikli” bir ürün kararı olarak en kolay şu şekilde anlaşılır: AI’yı yan bir araç olarak eklemek yerine, insanların zaten kullandığı her şeyin içinde motorun bir parçası olarak ele alırsınız.
Google bu yönelimi 2016–2017 civarında kamuoyuna açıkladı; bunu “mobile-first”ten “AI-first”e bir kayma olarak çerçevelediler. Fikir, her özelliğin aniden “akıllı” olması değildi; ürünlerin iyileşme biçiminin giderek öğrenen sistemler—sıralama, öneriler, konuşma tanıma, çeviri ve spam tespiti—olacağıydı, el ile ayarlanmış kurallar değil.
Çekirdek döngüye AI yerleştirmek
Pratik olarak, AI-öncelikli yaklaşım bir ürünün “çekirdek döngüsü”nün sessizce değiştiği zaman ortaya çıkar:
- Arama sonuçları, bir ekip binlerce yeni if-then kuralı kodlamak yerine sistemin sorgulardaki ve tıklamalardaki kalıpları öğrenmesi sayesinde daha iyi olur.
- Fotoğraflar, yalnızca dosya adları ve klasörlere göre değil içlerindeki nesnelere göre düzenlenir.
- Gmail, sürekli evrilen davranışları öğrenerek istenmeyen iletileri daha iyi yakalar; sadece bilinen anahtar kelimelere uymakla kalmaz.
Kullanıcı hiçbir zaman “AI” yazan bir düğme görmeyebilir. Sadece daha az yanlış sonuç, daha az sürtüşme ve daha hızlı cevaplar fark eder.
Asistanlar doğal dili standart haline getirdi
Sesli asistanlar ve konuşma arayüzleri beklentileri yeniden şekillendirdi. İnsanlar “Eve vardığımda annemi aramamı hatırlat” dediğinde yazılımın niyeti, bağlamı ve günlük dili anlamasını beklemeye başlarlar.
Bu, ürünleri doğal dil anlamayı temel yetenek olarak benimsemeye itti—ses, yazma ve hatta kamerayla bir şeye işaret edip ne olduğunu sorma gibi girişlerde. Bu dönüşüm, yeni kullanıcı alışkanlıklarını karşılamayla araştırma hedefleri arasında bir yönelimdi.
Önemli olarak, “Yapay Zeka-öncelikli” terimini bir yön olarak okumak en iyisidir—AI’nin her yaklaşımı anında tüm diğer yaklaşımların yerini aldığı iddiası değil.
Alphabet ve uzun oyun: aramanın ötesinde bahisler için alan yaratmak
Alphabet’in 2015’te kurulması bir yeniden markalandırma değil, operasyonel bir karardı: olgun, gelir getiren çekirdeği (Google) riskli, uzun vadeli girişimlerden ayırmak. Bu yapı, Larry Page’in AI vizyonunu on yıllara yayılmış bir proje olarak düşünüyorsanız önemlidir.
Neden “çekirdek” ile “bahisleri” ayırdılar
Google Search, Ads, YouTube ve Android sürekli dikkat gerektiren işlerdi: güvenilirlik, maliyet kontrolü ve istikrarlı yineleme. Cesur hedefler—sürüşsüz arabalar, yaşam bilimleri, bağlantı projeleri—farklı bir şeye ihtiyaç duyuyordu: belirsizliğe tolerans, pahalı deneyler için alan ve yanlış olmaya izin verme izni.
Alphabet altında, çekirdek net performans beklentileriyle yönetilirken; bahisler öğrenme kilometre taşlarına göre değerlendirilebilirdi: “Temel teknik varsayımı kanıtladık mı?” “Model gerçek dünyada yeterince gelişti mi?” “Problem kabul edilebilir güvenlik seviyelerinde çözülebilir mi?”
Büyük hedef mantığı: deney yapmayı strateji haline getirmek
Bu “uzun oyun” zihniyeti her projenin başarıya ulaşacağını varsaymaz. Sürdürülen deneylerin ileride neyin önemli olacağını keşfetmenin yolu olduğunu varsayar.
X gibi bir büyük hedef fabrikası iyi bir örnektir: ekipler cesur hipotezleri dener, sonuçları ölçer ve kanıt zayıfsa fikirleri hızlıca sonlandırır. Bu disiplin yapay zeka için özellikle önemlidir; çünkü ilerleme genellikle tek bir atılımdan ziyade yinelemeden—daha iyi veri, daha iyi eğitim düzenleri, daha iyi değerlendirme—kaynaklanır.
Ne alınmalı (söz vermeden)
Alphabet gelecekteki başarıların garantisi değildi. Yapılan şey iki farklı çalışma ritmini korumanın bir yoluydu:
- Çekirdek işi odaklı ve hesap verebilir tutun.
- Yüksek değişkenlikli araştırma ve ürün bahisleri için açık bir alan yaratın.
Takımlar için ders yapısaldır: uzun vadeli yapay zeka sonuçları istiyorsanız, onlar için tasarlayın. Kısa vadeli teslimatı keşif işinden ayırın, deneyleri öğrenme araçları olarak fonlayın ve ilerlemeyi sadece manşetlerle değil doğrulanmış içgörülerle ölçün.
Zor kısımlar: ölçekte kalite, güvenlik ve güven
İlk iterasyonu oluşturun
AI stratejinizi haftalık ölçüp geliştirebileceğiniz çalışan bir uygulamaya dönüştürün.
Yapay zeka sistemleri milyarlarca sorguya hizmet ettiğinde, küçük hata oranları günlük manşetlere dönüşür. Bir model “çoğunlukla doğru” olsa bile milyonları yanıltabilir—özellikle sağlık, finans, seçimler veya son dakika haberleri gibi konularda. Google ölçeğinde kalite bir isteğe bağlı özellik değil; bileşik bir sorumluluktur.
Temel takaslar
Önyargı ve temsil. Modeller veriden örüntüler öğrenir; buna sosyal ve tarihsel önyargılar da dahildir. “Tarafsız” sıralamalar hâlâ baskın görüşleri güçlendirebilir veya azınlık dillerini ve bölgeleri yeterince hizmet vermeyebilir.
Hatalar ve aşırı güven. Yapay zeka genellikle ikna edici duyulabilecek şekilde başarısız olur. En zararlı hatalar belirgin hatalar değil; kullanıcıların güvendiği inandırıcı sesli yanlışlardır.
Güvenlik vs. fayda. Sert filtreler zararı azaltır ama meşru sorguları da engelleyebilir. Zayıf filtreler kapsama alanını artırır ama dolandırıcılık, öz-kendine zarar veya yanlış bilgi riskini yükseltir.
Hesap verebilirlik. Sistemler daha otomatik hale geldikçe, temel soruları cevaplamak zorlaşır: Bu davranışı kim onayladı? Nasıl test edildi? Kullanıcılar nasıl itiraz eder veya düzeltme yapar?
Ölçeklemenin neden kılavuzlara ihtiyaç duyurduğu
Ölçek yeteneği artırırken aynı zamanda:
- Kenar durumların (diller, kültürler, hassas bağlamlar) sayısını genişletir
- Kötüye kullanım için teşvikleri artırır (spam, prompt enjeksiyonu, adversarial SEO)
- Ürünler çapında entegre edildiğinde hataların geri alınmasını zorlaştırır
Bu yüzden kılavuzlarla birlikte ölçeklenmelidir: değerlendirme setleri, red-teaming, politika uygulama, kaynakların izlenmesi ve belirsizliği gösterecek kullanıcı arayüzleri.
Yapay zeka iddialarını değerlendirmek için pratik kontrol listesi
Herhangi bir “yapay zeka destekli” özelliği—Google’dan ya da başkasından—değerlendirmek için bunu kullanın:
- Hata modu nedir? Sadece demolar değil, nerede kırıldığını gösteriyorlar mı?
- Nasıl ölçülüyor? Belirsiz “iyileştirmeler” yerine gerçek metrikler (doğruluk, toksisite oranı, uydurma oranı) arayın.
- Hangi verilerle eğitildi? En azından: geniş kategoriler, güncellik ve hariç tutma politikaları.
- Kılavuzlar neler? Güvenlik kuralları, insan inceleme yolları ve kötüye kullanım izleme.
- Kullanıcılar doğrulayabiliyor mu? İddiaları kontrol etmenizi sağlayacak atıflar, kaynaklar veya açıklamalar.
- Düzeltmeler nasıl ele alınıyor? Net bildirim yolları, hızlı güncellemeler ve denetlenebilirlik.
Güven, tek bir atılım modelinden değil, tekrarlanabilir süreçlerden kazanılır.
Takımlar için dersler: yapay zekayı uzun vadeli düşünmenin yolu
Google’ın uzun yayı arkasındaki en aktarılabilir desen basit: net hedef → veri → altyapı → yineleme. Bu döngüyü kullanmak için Google’ın ölçeğine ihtiyacınız yok—optimize ettiğiniz şey konusunda disiplin ve gerçek kullanımdan öğrenmenin yollarına ihtiyacınız var.
Kopyalayabileceğiniz temel desen
Bir ölçülebilir kullanıcı vaadiyle başlayın (hız, daha az hata, daha iyi eşleşmeler). Bunun sonuçlarını gözlemleyebilmeniz için enstrümante edin. Size veri toplama, etiketleme ve iyileştirmeleri güvenle göndermenizi sağlayan minimum “makineyi” kurun. Sonra küçük, sık adımlarla yineleyin—her sürümü bir öğrenme fırsatı olarak görün.
Eğer darboğazınız “fikirden enstrümante ürüne” yeterince hızlı geçememekse, modern yapım iş akışları yardımcı olabilir. Örneğin, Koder.ai, ekiplerin sohbet arayüzünden web, backend veya mobil uygulamalar oluşturabileceği bir vibe-coding platformudur—feedback döngüleri (başparmak yukarı/aşağı, sorun bildir, kısa anketler) içeren bir MVP hızla kurmak için kullanışlıdır; tam bir özel boru hattı için haftalar beklemeye gerek kalmaz. Planlama modu ile anlık görüntüler/geri alma gibi özellikler de “güvenle dene, ölç, yinele” ilkesine iyi uyar.
Liderlerin uygulayabileceği 6 çıkarım (Google olmadan)
- Kullanıcı odaklı bir kuzey yıldızı seçin. “Arama deneyimini geliştirmek” gibi bir hedef “AI benimsemek”ten daha nettir. Başarıyı insanların hissedeceği terimlerle tanımlayın.
- Ürününüzü öğrenme verisi yaratacak şekilde tasarlayın. Niçin-sonuç yakalayan geri bildirim döngüleri ekleyin (başparmak, düzeltmeler, "yardımcı oldu mu?")—sadece tıklamalar değil.
- Sadece modellere değil, borulara erken yatırım yapın. Veri kalite kontrolleri, değerlendirme panoları ve dağıtım iş akışları tek seferlik prototiplerden iyidir.
- Değerlendirmeyi bir ürün özelliği gibi ele alın. Tekrarlanabilir bir puan kartı (kalite, gecikme, maliyet, güvenlik) oluşturun ki yineleme tahmine dönüşmesin.
- Dilimler hâlinde gönderin. Dar senaryolarla başlayın, küçük bir kitlenin önünde yayınlayın, ölçün, sonra genişletin. Momentum, tek seferlik büyük lansmanlardan iyidir.
- Uzun bahisleri yaşatılabilir kılın. Deneyler için küçük bir kapasite ayırın, ama onları dürüst tutmak için net öğrenme kilometre taşları isteyin.
İlgili okumalar
- /blog/ai-strategy-basics
- /blog/data-flywheels-for-product-teams
- /blog/evaluating-ml-models-without-a-phd
- /blog/ai-governance-lightweight