21 Eyl 2025·8 dk
Uygulamalarınızda Anlık Sunucu Tarafı Arama için Meilisearch
Meilisearch'i backend'inize ekleyerek hızlı, yazım hatalarına toleranslı arama sağlayın: kurulum, indeksleme, sıralama, filtreler, güvenlik ve ölçekleme temelleri.
Meilisearch'i backend'inize ekleyerek hızlı, yazım hatalarına toleranslı arama sağlayın: kurulum, indeksleme, sıralama, filtreler, güvenlik ve ölçekleme temelleri.
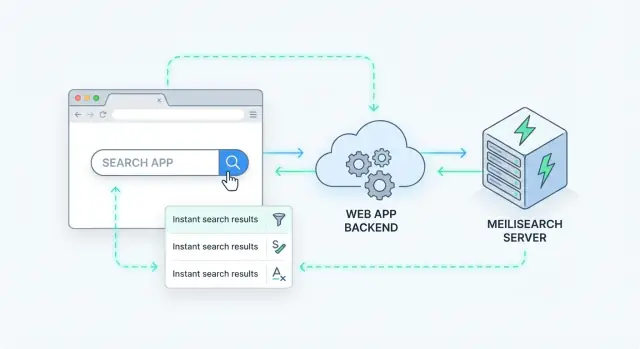
Sunucu tarafı arama, sorgunun tarayıcıda değil sunucunuzda (veya özel bir arama servisinde) işlendiği anlamına gelir. Uygulamanız bir arama isteği gönderir, sunucu bunu bir indeks üzerinde çalıştırır ve sıralanmış sonuçlar döner.
Bu, veri kümeniz istemciye gönderilecek kadar büyük olduğunda, platformlar arasında tutarlı alaka gerektiğinde veya erişim kontrolünün kesin olduğu durumlarda önem kazanır (örneğin, kullanıcıların yalnızca izin verilen kayıtları görmesi gereken dahili araçlar). Ayrıca analiz, kayıt ve öngörülebilir performans istediğinizde varsayılan seçimdir.
İnsanlar arama motorlarını düşünmez—deneyimi değerlendirirler. İyi bir “anlık” arama akışı genellikle şunları ifade eder:
Bunlardan herhangi biri eksikse, kullanıcılar farklı sorgular denemek, daha fazla kaydırmak veya aramayı tamamen bırakmak suretiyle telafi eder.
Bu makale, Meilisearch ile bu deneyimi oluşturmak için pratik adım adım bir yönergedir. Güvenli kurulum, indekslenmiş verinin nasıl yapılandırılacağı ve senkronize edileceği, alaka ve sıralama kurallarının nasıl ayarlanacağı, filtreleme/sıralama/faset eklemenin yolları, güvenlik ve ölçeklendirme düşünceleri gibi konuları ele alacağız ki arama uygulamanız büyüdükçe hızlı kalsın.
Meilisearch özellikle uygundur:
Amacımız: sonuçların anlık, doğru ve güvenilir hissettirmesi—aramayı büyük bir mühendislik projesine dönüştürmeden.
Meilisearch, uygulamanızın yanında çalıştırdığınız bir arama motorudur. Ona belgeler gönderirsiniz (ürünler, makaleler, kullanıcılar veya destek talepleri gibi) ve hızlı aramaya optimize edilmiş bir indeks oluşturur. Backend’iniz (veya frontend) Meilisearch’e basit bir HTTP API ile sorgu gönderir ve milisaniyeler içinde sıralanmış sonuçlar alırsınız.
Meilisearch modern aramadan beklenen özelliklere odaklanır:
Kısa, hafif hatalı veya belirsiz bir sorgu olsa bile duyarlı ve hoşgörülü hissettirecek şekilde tasarlanmıştır.
Meilisearch ana veritabanınızın yerini almaz. Veritabanınız yazmalar, işlemler ve kısıtlamalar için gerçek kaynak olmaya devam eder. Meilisearch, aranabilir, filtrelenebilir veya görüntülenebilir yapmak için seçtiğiniz alanların bir kopyasını saklar.
İyi bir zihinsel model: veritabanı veri saklar ve günceller, Meilisearch onu hızlıca bulur.
Meilisearch çok hızlı olabilir, ancak sonuçlar birkaç pratik faktöre bağlıdır:
Küçükten orta ölçekli veri kümeleri için genellikle tek bir makinede çalıştırmak yeterlidir. İndeks büyüdükçe, neyi indekslediğinize ve nasıl güncel tuttuğunuza daha dikkatli karar vermeniz gerekir—bunları sonraki bölümlerde ele alacağız.
Hiçbir şey yüklemeden önce, gerçekte neyi arayacağınızı belirleyin. İndeksleriniz ve belgeleriniz insanlar uygulamanızı nasıl gezdiğine uymuyorsa Meilisearch “anlık” hissettirmeyebilir.
Aranabilir varlıklarınızı listeleyerek başlayın—genellikle ürünler, makaleler, kullanıcılar, yardım dokümanları, konumlar vb. Birçok uygulamada en temiz yaklaşım her varlık türü için bir indeks (ör. products, articles) kullanmaktır. Bu, sıralama kurallarını ve filtreleri öngörülebilir tutar.
UX bir kutuda birden fazla türü arıyorsa (“her şeyi ara”), ayrı indeksleri saklayıp sonuçları backend'de birleştirebilir veya daha sonra özel bir “genel” indeks oluşturabilirsiniz. Alanlar gerçekten uyumlu değilse her şeyi tek bir indekse zorlamayın.
Her belgenin sabit bir kimliği (birincil anahtar) olmalıdır. Şu özelliklere sahip bir şey seçin:
id, sku, slug)Belge yapısı için mümkün olduğunda düz alanları tercih edin. Düz yapılar filtreleme ve sıralama için daha kolaydır. İç içe alanlar, sıkı ve değişmeyen bir paketi temsil ediyorsa (ör. bir author nesnesi) uygundur, ancak tüm ilişkisel şemanızı yansıtan derin iç içe yapılardan kaçının—arama belgeleri okumaya optimize edilmiş olmalı, veritabanı şeklinde değil.
Belgeleri tasarlamak için pratik bir yol her alanı bir rol ile etiketlemektir:
Bu, yaygın bir hatayı önler: “olur ya diye” bir alanı indekslemek ve sonra neden sonuçların gürültülü veya filtrelerin yavaş olduğunu merak etmek.
“Dil” verinizde farklı şeyler anlamına gelebilir:
lang: "en" gibi)Erken karar verin: dil başına ayrı indeksler mi kullanacaksınız (basit ve öngörülebilir) yoksa dil alanları içeren tek bir indeks mi (daha az indeks, daha fazla mantık). Doğru cevap, kullanıcıların bir seferde tek bir dilde mi arama yaptığına ve çevirileri nasıl sakladığınıza bağlıdır.
Meilisearch'i çalıştırmak basittir, ancak “varsayılan olarak güvenli” olması için birkaç kasıtlı karar gerekir: nerede dağıtıldığı, verilerin nasıl kalıcı tutulduğu ve master anahtarının nasıl yönetildiği.
Depolama: Meilisearch indeksini diske yazar. Veri dizinini güvenilir, kalıcı depolamaya koyun (geçici konteyner depolamasına değil). Büyüme için kapasite planlayın: geniş metin alanları ve çok sayıda özellik indekslerle hızla büyüyebilir.
Bellek: Yük altında arama için yeterli RAM ayırın. Swap gözlemlerseniz performans düşer.
Yedekler: Meilisearch veri dizinini yedekleyin (veya depolama katmanında anlık görüntüler kullanın). En az bir kez geri yüklemeyi test edin; geri yükleyemediğiniz bir yedek sadece bir dosyadır.
İzleme: CPU, RAM, disk kullanımını ve disk I/O'yu izleyin. Ayrıca süreç sağlığını ve log hatalarını takip edin. En azından hizmet durduğunda veya disk alanı azaldığında uyarı verin.
Geliştirme dışındaki her durumda Meilisearch'i bir master key ile çalıştırın. Bu anahtarı bir gizli yönetici veya şifrelenmiş ortam değişkeni deposunda saklayın (Git'e, açık metin .env dosyasına koymayın).
Ayrıca ağ kurallarını düşünün: özel bir arayüze bağlayın veya yalnızca backend'inizin erişebildiği şekilde gelen trafiği kısıtlayın.
curl -s http://localhost:7700/version
Meilisearch indeksleme eşzamansızdır: belgeleri gönderirsiniz, Meilisearch bir görev kuyruğuna alır ve o görev başarılı olana kadar belgeler aranabilir hale gelmez. İndekslemeyi bir iş sistemi gibi ele alın, tek bir istek gibi değil.
id).curl -X POST 'http://localhost:7700/indexes/products/documents?primaryKey=id' \\
-H 'Content-Type: application/json' \\
-H 'Authorization: Bearer YOUR_WRITE_KEY' \\
--data-binary @products.json
taskUid içerir. succeeded (veya failed) olana kadar sorgulayın.curl -X GET 'http://localhost:7700/tasks/123' \\
-H 'Authorization: Bearer YOUR_WRITE_KEY'
curl -X GET 'http://localhost:7700/indexes/products/stats' \\
-H 'Authorization: Bearer YOUR_WRITE_KEY'
Sayım eşleşmiyorsa, tahmin yürütmeyin—önce görev hata detaylarını kontrol edin.
Toplu yükleme, görevleri öngörülebilir ve kurtarılabilir tutmakla ilgilidir.
addDocuments bir upsert gibi davranır: aynı birincil anahtara sahip belgeler güncellenir, yenileri eklenir. Normal güncellemeler için bunu kullanın.
Tam yeniden indeksleme gerektiren durumlar:
Kaldırmalar için deleteDocument(s) çağırın; aksi takdirde eski kayıtlar kalabilir.
İndeksleme yeniden denenebilir olmalıdır. Anahtar nokta sabit belge id'leridir.
taskUid'yi parti/iş id'nizle birlikte saklayın ve görev durumuna göre yeniden deneyin.Üretim verisinden önce, gerçek alanlara uyan küçük bir veri kümesi (200–500 öğe) indeksleyin. Örnek: id, name, description, category, brand, price, inStock, createdAt alanlarına sahip bir products seti. Bu, görev akışı, sayımlar ve güncelleme/silme davranışını doğrulamak için yeterlidir—büyük bir içe aktarma beklemeden.
Arama “alakası” basitçe: ne önce gösterilir ve neden. Meilisearch bunu zorlamak zorunda bırakmadan ayarlanabilir hale getirir.
İki ayar Meilisearch'in içeriğinizle ne yapabileceğini şekillendirir:
searchableAttributes: kullanıcının yazdığı sorguda aranacak alanlar (örneğin: title, summary, tags). Sıra önemlidir: ilk alanlar daha önemli sayılır.displayedAttributes: yanıtta döndürülecek alanlar. Bu gizlilik ve yük boyutu için önemlidir—bir alan gösterilmiyorsa gönderilmez.Pratik bir temel: birkaç yüksek sinyal alanını aranabilir yapın (başlık, ana metin) ve görüntülenen alanları UI'nin ihtiyaçlarıyla sınırlayın.
Meilisearch eşleşen belgeleri sıralama kurallarıyla—bağlayıcı tiebreaker'lar hattıyla—sıralar. Kavramsal olarak tercih eder:
İçini ezberlemenize gerek yok; etkili ayarlamak için esas olarak hangi alanların daha önemli olduğunu ve ne zaman özel sıralama uygulayacağınızı seçersiniz.
Amaç: “Başlık eşleşmeleri kazanmalı.” title'ı öne koyun:
{
"searchableAttributes": ["title", "subtitle", "description", "tags"]
}
Amaç: “Daha yeni içerik önce gelsin.” Bir sıralama kuralı ekleyin ve sorgu zamanında sıralayın (veya özel sıralama ayarlayın):
{
"sortableAttributes": ["publishedAt"],
"rankingRules": ["sort", "typo", "words", "proximity", "attribute", "exactness"]
}
Sonra şu şekilde istekte bulunun:
{ "q": "release notes", "sort": ["publishedAt:desc"] }
Amaç: “Popüler öğeleri öne çıkar.” popularity'yi sıralanabilir yapın ve uygun olduğunda buna göre sıralayın.
Kullanıcıların yazdığı 5–10 gerçek sorgu seçin. Değişiklikten önce en üst sonuçları kaydedin, sonra sonra karşılaştırın.
Örnek:
"apple" → Apple Watch band, Pineapple slicer, Apple iPhone case"apple" → Apple iPhone case, Apple Watch band, Pineapple slicerEğer “sonra” listesi kullanıcı niyetine daha uygunsa ayarları koruyun. Kenar durumları bozuyorsa, neyin iyileştirdiğini bilmek için bir seferde bir şey değiştirin (önce alan sırası, sonra sıralama kuralları).
İyi bir arama kutusu sadece “kelimeleri yaz, eşleşmeleri al” değildir. İnsanlar sonuçları daraltmak ister (“sadece stoktakiler”) ve sıralamak isterler (“en ucuz ilk”). Meilisearch'te bunu filtreler, sıralama ve fasetler ile yaparsınız.
Bir filtre, sonuç kümesine uyguladığınız kuraldır. Bir faset, kullanıcıların bu kuralları oluşturmasına yardımcı olmak için UI'de gösterdiğiniz (genellikle onay kutuları veya sayımlar olarak) şeydir.
Teknik olmayan örnekler:
Kullanıcı “running” arayıp sonra category = Shoes ve status = in_stock ile filtreleyebilir. Fasetler “Shoes (128)” ve “Jackets (42)” gibi sayımlar göstererek neyin mevcut olduğunu anlamalarına yardımcı olur.
Meilisearch, filtre ve sıralama için kullanacağınız alanları açıkça izinlendirmenizi ister.
category, status, brand, price, created_at (zamanla filtreleme yapıyorsanız), tenant_id (müşterileri izole ediyorsanız).price, rating, created_at, popularity.Bu listeyi sıkı tutun. Her şeyi filtrelenebilir/sıralanabilir yapmak indeks boyutunu artırabilir ve güncellemeleri yavaşlatabilir.
50.000 eşleşmeye sahip olsanız bile kullanıcılar yalnızca ilk sayfayı görür. Küçük sayfalar kullanın (genellikle 20–50 sonuç), mantıklı limit ayarlayın ve offset ile sayfalandırın (veya tercih ederseniz daha yeni sayfalama özelliklerini kullanın). Ayrıca uygulamanızda maksimum sayfa derinliğini sınırlandırın; “sayfa 400” istekleri pahalıdır.
Sunucu tarafı aramayı eklemenin temiz yolu Meilisearch'i API'nizin arkasında uzmanlaşmış bir veri servisi gibi treat etmektir. Uygulamanız bir arama isteği alır, Meilisearch'i çağırır, sonra istemciye düzenlenmiş bir yanıt döner.
Çoğu ekip şu akışla çalışır:
GET /api/search?q=wireless+headphones&limit=20).Bu desen, Meilisearch'i değiştirilebilir tutar ve frontend kodunun indeks iç detaylarına bağlı kalmasını engeller.
Eğer yeni bir uygulama inşa ediyor veya iç aracı yeniden kuruyorsanız ve bu paterni hızla uygulamak istiyorsanız, Koder.ai gibi bir vibe-coding platformu React UI, Go backend ve PostgreSQL ile tam akışı iskeletleyip Meilisearch'i tek bir /api/search uç noktasının arkasına entegre edebilir—istemciyi basit, izinleri ise sunucu tarafında tutar.
Meilisearch istemci tarafı sorgulamayı destekler, ancak backend sorgulama genellikle daha güvenlidir çünkü:
Kamuya açık veriler için kısıtlı anahtarlarla istemci sorgulaması çalışabilir, ancak kullanıcıya özel görünürlük kuralları varsa aramayı sunucunuz üzerinden yönlendirin.
Arama trafiği genellikle tekrarlar içerir (“iphone case”, “return policy”). API katmanında önbellekleme ekleyin:
Aramayı herkese açık bir endpoint gibi muamele edin:
limit ve maksimum sorgu uzunluğu belirleyin.Meilisearch genellikle uygulamanızın “arka” tarafında konumlandırılır çünkü hassas iş verilerini hızla döndürebilir. Bir veritabanı gibi davranın: kilitleyin ve sadece her çağıranın görmesi gerekeni açığa çıkarın.
Meilisearch'in tüm işlemleri yapabilen bir master key'i vardır: indeks oluşturma/silme, ayar güncelleme ve belge okuma/yazma. Bu anahtarı sadece sunucuda tutun.
Uygulamalar için sınırlı eylemler ve sınırlı indekslerle API anahtarları oluşturun. Yaygın bir desen:
En az ayrıcalık, sızan bir anahtarın veri silme veya alakasız indeksleri okuma yeteneğini kısıtlar.
Çoklu müşteriye hizmet veriyorsanız iki ana seçenek vardır:
1) Kiracı başına bir indeks.
Çapraz-kiracı erişim riskini azaltır ve mantığı basit tutar. Dezavantaj: daha fazla indeks yönetimi gerekir.
2) Paylaşılan indeks + tenant filter.
Her belgeye tenantId alanı koyun ve tüm aramalarda tenantId = "t_123" gibi bir filtre zorunlu kılın. Bu iyi ölçeklenebilir, ancak her isteğin filtreyi uyguladığından emin olmalısınız (en iyisi, çağıranların bunu kaldıramayacağı şekilde scoped key kullanmak).
Arama doğru olsa bile sonuçlar istemeden gizli alanları sızdırabilir (e-posta, dahili notlar, maliyet fiyatları). Döndürülebilecekleri yapılandırın:
Kötü senaryo testi yapın: yaygın bir terim aratın ve özel alanların görünmediğini doğrulayın.
Anahtarın istemci tarafında olup olmaması konusunda emin değilseniz, varsayılan olarak “hayır” kabul edin ve aramayı sunucu tarafında tutun.
Meilisearch iki işi ayırt eder: indeksleme (yazma) ve arama sorguları (okuma). Çoğu “bilinmeyen yavaşlık”, bu iki işin CPU, RAM veya disk için rekabet etmesinden kaynaklanır.
İndeksleme yükü büyük toplu içe aktarmalar, sık güncellemeler veya çok sayıda aranabilir alan eklendiğinde artar. İndeksleme arka planda olsa da CPU ve disk bant genişliği kullanır. Görev kuyruğu büyürse, sorgu trafiği değişmese bile aramalar yavaşlayabilir.
Sorgu yükü trafikle artar; ancak filtreler, fasetler, daha büyük sonuç setleri ve yazım toleransı da istekte yapılan işi artırır.
Disk I/O sessiz suçludur. Yavaş diskler (veya paylaşılan hacimde gürültülü komşular) “anlık”ı “nihayetinde” haline getirebilir. Üretim için NVMe/SSD tipik tabandır.
Başlangıç olarak Meilisearch'e indeksleri sıcak tutacak kadar RAM ve tepe QPS'i karşılayacak kadar CPU verin. Sonra kaygıları ayırın:
Küçük bir sinyal setini izleyin:
Yedeklemeler rutin olmalı. Meilisearch'in snapshot özelliğini düzenli kullanın, snapshot'ları kutu dışına saklayın ve ara sıra geri yüklemeyi test edin. Yükseltmelerde sürüm notlarını okuyun, yükseltmeyi non-prod ortamda aşamalayın ve bir sürüm değişikliği indeks davranışını etkiliyorsa yeniden indeksleme zamanını planlayın.
Eğer platformunuz (örneğin Koder.ai) ortam snapshot'ları ve rollback kullanıyorsa, arama dağıtımınızı aynı disipline göre yapın: değişiklik öncesi snapshot, sağlık kontrollerini doğrulama ve hızlı geri dönüş yolu tutun.
Temiz bir entegrasyon olsa bile arama sorunları birkaç tekrarlayan kategoride toplanır. İyi haber: Meilisearch size yeterli görünürlük sağlar (görevler, loglar, deterministik ayarlar) — sistematik yaklaşırsanız hızlıca hata ayıklayabilirsiniz.
filterableAttributes'a eklenmemiş veya belgeler beklenmeyen bir şekilde depolanmış (string vs dizi vs iç içe nesne).sortableAttributes/rankingRules ayarı yanlış öğeleri öne çıkarıyor.Önce Meilisearch'in son değişikliğinizi başarılı uygulayıp uygulamadığını kontrol edin.
filter, sonra sort, sonra facets.Açıklayamadığınız bir sonuç varsa, geçici olarak yapılandırmanızı indirgedin: eşanlamlıları kaldırın, sıralama kanca ayarlarını azaltın ve küçük bir veri kümesiyle test edin. Karmaşık alaka sorunları 50 belge üzerinde 5 milyon üzerinde olmaktan çok daha kolay görülür.
your_index_v2 gibi paralel bir indeks kurun, ayarları uygulayın ve üretim sorgularından örnekleri tekrar oynatın.filterableAttributes ve sortableAttributes'ın UI gereksinimlerinizle eşleştiğini doğrulayın.Related guides: /blog (search reliability, indexing patterns, and production rollout tips).
Sunucu tarafı arama, sorgunun tarayıcıda değil backend'inizde (veya özel bir arama hizmetinde) çalıştırılması demektir. Doğru tercihler şunlar olduğunda sunucu tarafı arama kullanılmalıdır:
Kullanıcılar dört şeyi hemen fark eder:
Bu unsurlardan biri eksikse, insanlar sorguları yeniden yazar, fazla kaydırır veya aramayı terk eder.
Bunu bir arama indeksi olarak görün; kaynak veri deposunun yerini almaz. Veritabanınız yazma, işlemler ve kısıtlamalar için temel kaynak olmaya devam eder; Meilisearch ise hızlı erişim için seçtiğiniz alanların bir kopyasını tutar.
Yararlı bir zihinsel model:
Genellikle varsayılan: her varlık türü için bir indeks (ör. products, articles). Bu yaklaşımla:
“Her şeyi ara” ihtiyacı varsa, birden fazla indeksi sorgulayıp sonuçları backend'de birleştirebilir veya daha sonra özel bir global indeks ekleyebilirsiniz.
Aşağıdaki özelliklerde bir birincil anahtar seçin:
id, sku, slug)Sabit ID'ler indekslemeyi idempotent yapar: yeniden denerseniz çoğaltma oluşturmaz, çünkü güncellemeler güvenli upsert olur.
Her alanı amacına göre sınıflandırın, böylece gereksiz indekslemeyi önlersiniz:
Bu roller belirgin olunca gereksiz gürültü ve şişkin indeksleme azalır.
İndeksleme eşzamansızdır: belge yüklemeleri bir görev oluşturur ve belgeler ancak bu görev başarılı olduktan sonra aranabilir hale gelir.
Güvenilir bir akış:
succeeded veya failed olana kadar sorgulayınVeriler eski görünüyorsa, hata ayıklamadan önce görev durumunu kontrol edin.
Tek büyük yüke göre çok sayıda küçük parti tercih edin. Pratik başlangıç noktaları:
Küçük partiler yeniden denemeyi, hatalı kayıtları bulmayı ve zaman aşımı riskini azaltır.
İki yüksek etkili ayar:
searchableAttributes: hangi alanların arandığı ve hangi öncelikle sıralandığıpublishedAt, price veya popularity gibi alanlarla sıralamaya izin verip vermeyeceğinizPratik yol: 5–10 gerçek sorgu alın, önceki sonuçları kaydedin, bir ayar değişikliği yapın ve sonra karşılaştırın.
Çoğu filtre/sıralama sorunu eksik yapılandırmadan kaynaklanır:
filterableAttributes içinde olması gerekirsortableAttributes içinde olması gerekirAyrıca belgelerdeki alan şekillerini doğrulayın (string vs dizi vs iç içe nesne). Bir filtre başarısızsa, son ayarlar/görev durumunu kontrol edin ve indekslenmiş belgelerin beklenen alan değerlerine sahip olduğunu doğrulayın.