Eskalasyon İş Akışını ve Hedefleri Netleştirin
Ekranlar hazırlamadan veya kod yazmadan önce uygulamanızın ne için olduğunu ve hangi davranışları zorlaması gerektiğini belirleyin. Eskalasyonlar sadece “sinirli müşteriler” değildir—daha hızlı işlem, daha yüksek görünürlük ve sıkı koordinasyon gerektiren biletlerdir.
Eskalasyon sayılan nedir?
Ajansların ve müşterilerin tahmin yürütmesine gerek kalmaması için eskalasyon kriterlerini açık bir dille tanımlayın. Yaygın tetikleyiciler şunlardır:
- Bir kesinti veya ciddi performans düşüşü
- VIP veya sözleşmeli “öncelikli destek” müşterisi
- Yaklaşan bir SLA ihlali (veya tekrarlayan ihlaller)
- Güvenlik, faturalama veya hukuki etkisi olan bir sorun
Ayrıca neyin eskalasyon olmadığını tanımlayın (ör. nasıl yapılır soruları, özellik talepleri, küçük hatalar) ve bu taleplerin nasıl yönlendirileceğini belirtin.
Roller ve sorumluluklar
İş akışınızın ihtiyaç duyduğu rolleri ve her rolün neler yapabileceğini listeleyin:
- Agent: triage yapar ve çözer, bileti günceller, playbook’ları takip eder
- Lead: eskalasyonları gözden geçirir, işi yeniden atar, öncelik değişikliklerini onaylar
- Manager: raporlama, müşteri iletişim standartları ve eskalasyon politikası sahibi
- On-call: acil uyarıları alır ve mesai dışı durumlarda derhal sahiplenir
- Customer admin: bilet gönderir ve takip eder, iç paydaşları ekler
Her adımda kimin bileti sahiplenip sahiplenmediğini (ve devirleri) ve “sahiplik”in ne anlama geldiğini (yanıt gereksinimi, bir sonraki güncelleme zamanı ve eskalasyon yetkisi) yazılı hale getirin.
İlk desteklenecek kanallar
Daha çabuk dağıtım yapmak ve triage’ı tutarlı tutmak için küçük bir giriş kümesiyle başlayın. Birçok ekip önce e-posta + web formu ile başlar, sonra SLA’lar ve yönlendirme stabil olduktan sonra sohbet ekler.
Hedefler ve başarı metrikleri
Uygulamanın geliştirmesi gereken ölçülebilir sonuçları seçin:
- İlk yanıt süresi (genel ve eskalasyonlar için)
- Çözüm süresi veya olaylar için hafifletmeye kadar geçen süre
- Yeniden açılma oranı ve “güncelleme için ping” sayısı
- Kaçırılan SLA oranı ve sahiplenilmemiş geçirilen süre
Bu kararlar, inşa sürecinin geri kalanı için ürün gereksinimleriniz olur.
Biletler, SLA'lar ve Eskalasyonlar için Veri Modelini Tasarlayın
Bir öncelikli destek uygulaması veri modeline bağlıdır. Temelleri doğru kurarsanız yönlendirme, raporlama ve SLA uygulaması daha basit olur—çünkü sistem ihtiyacı olan gerçekleri tutar.
Bilet “temelleri” ile başlayın (ajanların her zaman bilmesi gerekenler)
En azından her bilet şu bilgileri yakalamalıdır: talep eden (bir iletişim), şirket (müşteri hesabı), konu, açıklama ve ekler. Açıklamayı orijinal problem beyanı olarak ele alın; sonraki güncellemeler yorumlarda olmalı ki hikâyenin nasıl geliştiğini görebilesiniz.
Eskalasyona özgü alanlar ekleyin (bunu “öncelikli” yapan nedir)
Eskalasyonlar genel destekten daha fazla yapı gerektirir. Yaygın alanlar: severity (ne kadar kötü), impact (kaç kullanıcı/hangi gelir), ve priority (ne kadar hızlı yanıt verilecek). Triage’ın hızlı yönlendirme yapabilmesi için etkilenen servis alanı ekleyin (örn. Faturalama, API, Mobil Uygulama).
Son tarihler için, sadece “SLA adı” tutmak yerine açık bitiş zamanlarını saklayın (örn. “ilk yanıt süresi dolma zamanı”, “çözüm/sonraki güncelleme süresi”). Sistem bu zaman damgalarını hesaplayabilir, fakat ajanlar kesin saatleri görmelidir.
Gerçek iş için ilişkileri modelleyin
Pratik bir model genellikle şunları içerir:
- Customers → birçok Contacts
- Customers → birçok Tickets
- Tickets → birçok Comments (dahili + müşteri görünen)
- Tickets → birçok Tasks (kontrol listesi öğeleri, takip işleri)
Bu, işbirliğini temiz tutar: konuşmalar yorumlarda, işlem öğeleri görevlerde ve sahiplik bilet üzerinde tutulur.
Durum (status) durumlarını tanımlayın (ve tutarlı tutun)
Küçük, sabit bir durum seti kullanın: New, Triaged, In Progress, Waiting, Resolved, Closed. “Neredeyse aynı” durumlardan kaçının—her ekstra durum raporlama ve otomasyonu daha az güvenilir yapar.
Denetimler için hangi alanların değişmez olması gerektiğine karar verin
SLA takibi ve hesap verebilirlik için bazı veriler ekleme-yalnız (append-only) olmalıdır: oluşturma/güncelleme zamanları, durum değişikliği geçmişi, SLA başlama/durma olayları, eskalasyon değişiklikleri ve her değişikliği yapan. Ne olduğunu yeniden inşa edebilmek için tercih edilen çözüm bir audit log (veya olay tablosu)dır.
Öncelik Seviyelerini ve SLA Kurallarını Belirleyin
Öncelik ve SLA kuralları uygulamanızın zorladığı “sözleşmedir”: neyin önce ele alınacağı, ne kadar hızlı ve kimin sorumlu olduğu. Şemayı basit tutun, açıkça belgeleyin ve makul bir neden olmadan geçersiz kılmayı zorlaştırın.
Basit bir öncelik şeması (P1–P4)
Hızlı sınıflandırma ve tutarlı raporlama için dört seviye kullanın:
- P1 — Kritik kesinti / ciddi etki: Ürün kapalı, veri kaybı oluyor veya güvenlik olayı şüphesi. Birden fazla kullanıcı veya tüm müşteri hesabı bloke.
- P2 — Büyük bozulma: Temel özellikler kısmen bozuk, geçici çözümler sınırlı ve iş etkisi yüksek ama tamamen değil.
- P3 — Standart sorun: Tek bir kullanıcı veya önemsiz bir özellik etkilenmiş. Bir geçici çözüm var. Birçok bilet burada olmalı.
- P4 — Düşük öncelik / talepler: Nasıl yapılır soruları, küçük hatalar, özellik talepleri, kullanımını engellemeyen faturalama soruları.
UI’de “impact” (kaç kullanıcı/müşteriyi etkilediği) ve “urgency” (zaman açısından ne kadar hassas olduğu) tanımlayın ki yanlış sınıflandırma azalsın.
Plan, müşteri seviyesi ve önceliğe göre SLA tanımlayın
Veri modelinizin SLA’ların müşteri planı/seviyesi (örn. Free/Pro/Enterprise) ve öncelik bazında değişmesine izin vermelidir. Genellikle en az iki zamanlayıcı izlersiniz:
- İlk yanıt SLA’sı (sahiplenme ve yanıt için süre)
- Çözüm SLA’sı veya sonraki güncelleme SLA’sı (çözüm veya anlamlı bir güncelleme için süre)
Örnek: Enterprise + P1 ilk yanıtı 15 dakikada gerektirebilir, Pro + P3 ise 8 iş saati olabilir. Kurallar tablosunu ajanların görebileceği şekilde tutun ve bilet sayfasından bağlayın.
Mesai saatleri, 7/24 ve tatil takvimleri
Destek SLA’ları genellikle planın 7/24 kapsama içerip içermediğine bağlıdır.
- Mesai-saati SLA’ları için çalışma takvimi saklayın (zaman dilimi, hafta içi günleri, başlama/bitiş saatleri).
- 7/24 SLA’lar için saat her zaman akar.
- Gerekirse bölgeye göre bir tatil takvimi ekleyin ki zamanlayıcılar kimsenin çalışması beklenmeyen günlerde “ihlal” olmasın.
Bilet hem “kalan SLA”yı hem de hangi takvimi kullandığını göstermeli ki ajanlar sayaçlara güvenebilsin.
SLA duraklatmaları, “müşteri bekleniyor” ve ihlal yönetimi
Gerçek iş akışları duraklatmalar gerektirir. Yaygın kural: bilet Waiting on customer (veya üçüncü taraf bekleniyor) durumunda SLA duraklatılır ve müşteri yanıtladığında devam eder.
Açık olun:
- Hangi durumların hangi SLA zamanlayıcılarını duraklattığı
- Duraklatmaların yanıt SLA’sına, çözüm SLA’sına veya her ikisine uygulanıp uygulanmadığı
- Bir ihlal olduğunda ne olduğu (örn. otomatik eskalasyon, on-call paging, yöneticiye bildirim, bilete “SLA Breached” etiketi)
Gizli ihlallerden kaçının. İhlal yönetimi bilet geçmişinde görünür bir olay oluşturmalı.
İhlal öncesi ve sonrası kimler uyarılır
En az iki uyarı eşiği belirleyin:
- Ön-ihlal uyarısı (örn. SLA’nın %50 ve %80’i tükendiğinde): bilet sahibi ve ilgili ekip kanalını bilgilendir
- İhlal bildirimi: on-call (P1/P2 için), ekip lideri ve yüksek seviye hesaplar için müşteri başarısı ekibini bilgilendir
Uyarıları öncelik ve seviyeye göre yönlendirin ki P4 gürültüsü için kimse çağrılmasın.
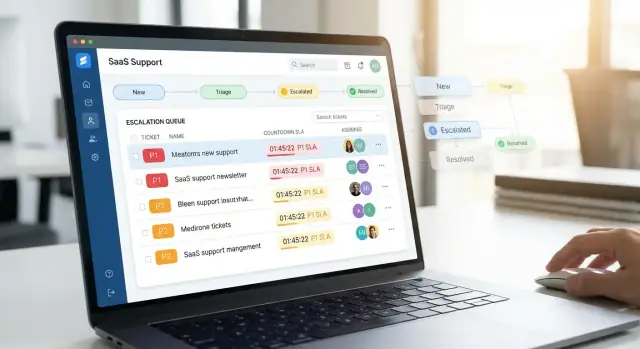
Triage, Yönlendirme ve Sahiplik Mantığını Oluşturun
Triage ve yönlendirme, öncelikli destek uygulamasının zaman kazandırmasını ya da kafa karışıklığı yaratmasını sağlar. Amaç basit: her yeni istek doğru yere hızla düşsün, net bir sahibi ve açık bir sonraki adımı olsun.
Ajanların güvenebileceği bir triage gelen kutusu oluşturun
Atanmamış veya inceleme bekleyen biletler için özel bir triage gelen kutusuyla başlayın. Hızlı ve öngörülebilir olsun:
- Varsayılan sıralama: aciliyet sinyalleri (öncelik, SLA dolma zamanı, müşteri seviyesi)
- Ürün alanı, bölge/zaman dilimi, kanal (e-posta/sohbet/web) ve “VIP” hesaplar için filtreler
- “Sahibi yok / Kategorisi yok” görünümü ile veri kalitesi boşluklarını vurgulama
İyi bir gelen kutusu tıklamaları en aza indirir: ajanlar her bileti açmadan listeden sahiplenebilmeli, yeniden yönlendirebilmeli veya eskalasyon başlatabilmelidir.
Yönlendirme kurallarını tanımlayın (ve okunabilir tutun)
Yönlendirme kural tabanlı olmalı, ancak mühendis olmayanların da okuyabileceği şekilde olmalı. Yaygın girdiler:
- Ürün alanı (kullanıcı tarafından seçilen, formdan algılanan veya etiketlerden çıkarılan)
- Konu/gövde içindeki anahtar kelimeler (örn. “outage”, “invoice”, “SSO”)
- Müşteri seviyesi (standart vs öncelikli)
- Bölge (zaman dilimine uyumlu ekipler)
Her yönlendirme kararının “nedenini” saklayın (örn. “Eşleşen anahtar kelime: SSO → Auth takımı”). Bu, anlaşmazlıkları çözmeyi kolaylaştırır ve eğitim için iyileştirir.
Manuel geçersiz kılma ve eskalasyon yolları
En iyi kuralların bile kaçış kapısı gerekir. Yetkili kullanıcıların yönlendirmeyi geçersiz kılmasına ve şu tür eskalasyon yollarını tetiklemesine izin verin:
Agent → Team lead → On-call
Geçersiz kılmalar kısa bir gerekçe gerektirmeli ve bir denetim girdisi oluşturmalıdır. On-call uyarıları varsa, eskalasyon eylemlerini onlarla bağlayın.
Aynı işi çoğaltmayı engelleme ve ilişkili işleri bağlama
Yinelenen biletler SLA zamanını boşa harcar. Basit araçlar ekleyin:
- Müşteri + benzer konu + zaman penceresine göre olası kopyaları önerin
- Ajanların biletleri bir “parent incident”e bağlamasına izin verin (örn. “related to INC-123”)
Bağlı biletler ana olaydan durum güncellemeleri ve halka açık iletileri miras almalıdır.
Sahiplik kuralları: bir isim, bir kuyruk
Net sahiplik durumları tanımlayın:
- Tek atanan (single assignee): sorumlu tek kişi
- Ekip kuyruğu: ekip içinde atanmadı; sık el değiştirmeler için kullan
- Handoff: notlarla açık transfer ve gerekirse yeni bir SLA kontrol noktası
Sahipliği her yerde görünür kılın: liste görünümü, bilet başlığı ve etkinlik günlüğü. Birisi “Bunu kim tutuyor?” diye sorduğunda uygulama anında cevap vermeli.
Ajanların Hızla Kullanabileceği Bir Destek Panosu Oluşturun
Bir öncelikli destek uygulamasının başarılı olup olmadığını ajanın içinde geçirdiği ilk 10 saniye belirler. Panoda üç sorunun hemen yanıtı olmalı: şimdi neye dikkat etmeliyim, neden, ve sonraki ne yapabilirim.
Ajanların gerçekten kullandığı ana görünümler
Çok sayıda sekme yerine yüksek fayda sağlayan küçük bir görünüm seti ile başlayın:
- Kuyruk (worklist): öncelik, SLA durumu, kanal, ürün alanı ve atanan kişi için filtrelerle varsayılan görünüm
- Bilet detayı: tek tıkta açılır, üstte bağlam ve eylemler
- Müşteri profili: hesap seviyesi, son eskalasyonlar, aktif olaylar ve kilit kişiler
- SLA panosu: nelerin yakında ihlal olacağını gösteren zaman bazlı görünüm
Bilişsel yükü azaltan görsel ipuçları
Ajanların her satırı “okuması” gerekmesin diye net, tutarlı sinyaller kullanın:
- Öncelik etiketleri (P1–P4) erişilebilir renk + metin ile (asla sadece renk yok)
- SLA geri sayımı (örn. “ilk yanıta 45dk kaldı”) ve “ihlal riski” göstergesi
- Engeller rozeti (Waiting on customer, Waiting on engineering, Needs approval)
Tipografiyi basit tutun: bir ana vurgu rengi ve sıkı bir hiyerarşi (başlık → müşteri → durum/SLA → son güncelleme).
Hızlı eylemler ve triage hızı
Her bilet satırı tam sayfayı açmadan hızlı eylemleri desteklemeli:
- Atama / yeniden atama, escalate, öncelik değiştir, bilgi iste, engelle belirle, dahili not ekle.
Geri log temizliği için toplu işlemler (ata, kapat, etiket uygula, engel koy) ekleyin.
Klavye, erişilebilirlik ve “sürpriz yok”
Güç kullanıcıları için klavye kısayollarını destekleyin: / arama, j/k hareket, e eskalasyon, a atama, g sonra q kuyruka dönüş gibi.
Erişilebilirlik için yeterli kontrast, görünür odak durumları, etiketli kontroller ve ekran okuyucu dostu durum metni (örn. “SLA: 12 dakika kaldı”) sağlayın. Aynı akışın küçük ekranlarda da çalışması için tabloyu duyarlı yapın.
Bildirimler ve On-Call Uyarıları
Offset Your Build Time
Get credits by creating content about building apps with Koder.ai.
Bildirimler, öncelikli destek uygulamasının “sinir sistemi”dir: bilet değişikliklerini zamanında eyleme dönüştürürler. Amaç daha fazla bildirim göndermek değil—doğru kişiyi, doğru kanalda, yanıt verebilecek yeterli bağlamla uyarmaktır.
Bildirim türlerini eşleştirin
Mesaj tetikleyecek olayların net bir setiyle başlayın. Yaygın, yüksek sinyal türleri:
- Atama: bilet bir ajana veya ekibe atandı/yeniden atandı
- Mention: biri dahili notta bir ajanı @etiketledi
- SLA uyarısı: bilet ilk yanıt veya çözüm hedeflerine yaklaşırken
- SLA ihlali: hedef kaçırıldı (biliniyorsa neden ile birlikte)
- Eskalasyon: öncelik arttı, bir yönetici/müşteri eklendi veya bir olay ilan edildi
Her mesaj bilet ID’si, müşteri adı, öncelik, mevcut sahip, SLA zamanlayıcıları ve biletin derin bağlantısını içermelidir.
Kontrolü kaybetmeden kanalları seçin
Günlük işler için uygulama içi bildirimler, dayanıklı güncellemeler ve devirler için e-posta kullanın. Gerçek on-call senaryoları için SMS/push gibi isteğe bağlı kanalları yalnızca acil olaylar (P1 eskalasyonu veya yaklaşan ihlal) için ayırın.
Uyarı yorgunluğunu önleyin
Uyarı yorgunluğu yanıt süresini öldürür. Gruplama, sessiz saatler ve çoğaltma önleme gibi kontroller ekleyin:
- Tekrarlayan SLA uyarılarını tek bir başlıkta grupla
- Kısa penceredeki “atama değişti” patlamalarını çoğaltma
- Kritik olaylar için geçersiz kılma ile sessiz saatlere saygı göster
Şablonlar + teslim geçmişi
Hem müşteri-facing güncellemeler hem de dahili notlar için şablonlar sağlayın ki ton ve eksiklik tutarlı kalsın. Teslim durumunu (gönderildi, teslim edildi, başarısız) takip edin ve denetim ve takibi kolaylaştırmak için bilet başına bir bildirim zaman çizelgesi tutun. Bilet detay sayfasında basit bir “Notifications” sekmesi bunu gözden geçirmeyi kolaylaştırır.
Bilet Detay Sayfası: İşbirliği ve İletişim
Bilet detay sayfası eskalasyon işinin fiilen yapıldığı yerdir. Ajanlara birkaç saniyede bağlamı anlamada, ekip arkadaşlarıyla koordine olmada ve müşteriyle hata yapmadan iletişim kurmada yardımcı olmalıdır.
Müşterinin gördüğü ile dahili olanı ayırın
Yazıcıyı açıkça Müşteri Yanıtı veya Dahili Not seçmeye zorlayın; farklı stil ve net bir önizleme gösterin. Dahili notlar hızlı formatlama, runbook bağlantıları ve özel etiketleri (örn. “needs engineering”) desteklemeli. Müşteri yanıtlama alıcıları dost canlısı bir şablonla varsayılan gelsin ve tam olarak gönderilecek içerik önizlensin.
Konuşma dizisi + güvenli ekler
E-postalar, sohbet dökümleri ve sistem olaylarını kronolojik bir dizide gösterin. Ekler için güvenlik öncelikli olsun:
- Virüs taraması ve dosya türü izin listeleri
- Boyut limitleri ve süresi dolan indirme bağlantıları
- Hassas veri (token, şifre) için redaksiyon uyarıları
Müşteri tarafından yüklenen dosyaları gösteriyorsanız, kim tarafından ve ne zaman yüklendiğini açıkça gösterin.
Makrolar, hızlı cevaplar ve kayıtlı adımlar
Onaylı cevapları ve sorun giderme kontrol listelerini (örn. “log topla”, “yeniden başlatma adımları”, “status page metni”) ekleyen makrolar ekleyin. Ekiplerin paylaşılan bir makro kütüphanesini sürüm geçmişi ile yönetmesine izin verin ki eskalasyonlar tutarlı ve uyumlu olsun.
Önemli olayların zaman çizelgesi
Mesajların yanında kompakt bir olay zaman çizelgesi gösterin: durum değişiklikleri, öncelik güncellemeleri, SLA duraklatma/devam etme, atanmış kişi transferleri ve eskalasyon seviye değişimleri. Bu, “ne değişti?” tartışmalarını önler ve olay sonrası incelemelere yardımcı olur.
Gürültü yaratmayan işbirliği araçları
@bahsetmeler, takipçiler ve bağlantılı görevler (mühendislik bileti, olay dokümanı) etkinleştirin. Bahsetmeler sadece ilgili kişileri uyarmalı ve takipçiler bilet maddi olarak değiştiğinde özetler almalı—her tuş vuruşunda bildirim almamalı.
Güvenlik, Gizlilik ve İzinler
Iterate Without Fear
Use snapshots and rollback while tuning routing rules and notification thresholds.
Eskalasyonlar genellikle müşteri e-postaları, ekran görüntüleri, loglar ve dahili notlar içerir; bu yüzden güvenliği erken kurun ki ajanlar hızlı hareket ederken veri paylaşımını abartmasın veya güven kaybetmesin.
Gerçek destek işiyle uyumlu rol tabanlı erişim kontrolü (RBAC)
Her bir rolü bir cümlede açıklanabilecek küçük bir setle başlayın (örn. Agent, Team Lead, On-Call Engineer, Admin). Sonra her rolün neleri görebileceğini, düzenleyebileceğini, yorumlayabileceğini, yeniden atayabileceğini ve dışa aktarabileceğini tanımlayın.
Pratik bir yaklaşım “varsayılan reddet” izinleridir:
- Eskalasyon görünürlüğü: ekip, kuyruk ve müşteri hesabı bazlı kısıtla (örn. sadece Enterprise kuyruğu ajanları Enterprise eskalasyonlarını açabilir)
- Düzenleme hakları: ajanlara durum güncelleme ve not ekleme izni ver, SLA değişiklikleri, öncelik geçersiz kılmaları ve eskalasyon iptallerini lead/admin ile sınırlı tut
- Hassas alanlar: müşteri PII (e-posta, telefon), güvenlik logları ve ekler ayrı izinler gerektirsin
Gizlilik temelli tasarım: en az ayrıcalık varsayımı
Sadece iş akışınızın ihtiyaç duyduğu verileri toplayın. Tam mesaj gövdelerine veya tam IP adreslerine ihtiyaç yoksa bunları saklamayın. Müşteri verisini saklarken hangi alanların gerekli vs. isteğe bağlı olduğunu net yapın ve diğer sistemlerden veri kopyalarken gerekçe isteyin.
Erişim desenleri için “destek ajanları sorunu çözmek için gereken minimumu görmeli” varsayın. Karmaşık kurallar eklemeden önce hesap ve kuyruk bazlı kapsamlamayı tercih edin.
Temelleri koruyun: kimlik doğrulama, oturumlar ve CSRF
Mümkünse SSO/OIDC gibi kanıtlanmış kimlik doğrulama kullanın, parola kullanılıyorsa güçlü parolalar zorunlu kılın ve yükseltilmiş roller için çok faktörlü doğrulama destekleyin.
Oturumları sertleştirin:
- Secure, HttpOnly çerezler; admin eylemleri için kısa oturum süreleri
- Giriş ve ayrıcalık değişimlerinde oturum döndürme
- Durum değiştirici istekler için CSRF koruması
Gizli veriler, denetim günlükleri ve hassas erişim
Gizli verileri kaynak koduna koymayın, yönetilen bir gizli depo kullanın. Hassas verilere erişimi (kim bir eskalasyonu görüntüledi, eki kim indirdi, bileti kim dışa aktardı) loglayın ve denetim günlüklerini kırılamaz ve aranabilir tutun.
Saklama ve dışa aktarma (abartmadan)
Biletler, ekler ve denetim günlükleri için saklama kuralları tanımlayın (örn. ekleri N gün sonra sil, denetim günlüklerini daha uzun sakla). Müşteriler veya dahili raporlama için dışa aktarımlar sağlayın ama belirli uyumluluk sertifikalarını iddia etmeyin; bunu doğrulayabiliyorsanız açıklayın. Basit bir “veri dışa aktar” akışı ve admin-only “silme isteği” iş akışı iyi bir başlangıçtır.
Teknoloji Yığını ve Mimari Seçimi
Eskalasyon uygulamanız değiştirilebilir olmalı. Kurallar, SLA’lar ve entegrasyonlar sürekli evrilir; bu yüzden ekibinizin sürdürebileceği ve işe alım yapabileceğiniz bir yığın tercih edin.
Ekibinize uyan bir yığın seçin
“Mükemmel”den ziyade tanıdık araçları seçin. Yaygın, kanıtlanmış kombinasyonlar:
- React + Node.js (Express/NestJS): yüksek interaktif pano ve gerçek zamanlı UI için iyi
- Django (Python): güçlü admin araçları, hızlı CRUD geliştirme, iş akışı ağırlıklı uygulamalar için uygundur
- Rails (Ruby): bilet tarzı ürünleri hızla kurmak için iyi konvansiyonlar
Zaten bir monolitiniz varsa, o ekosistemi eşlemek işe alımı ve operasyonel karmaşıklığı azaltır.
İlk etapta büyük mühendislik yatırımı yapmak istemiyorsanız, React tabanlı ajan panosu, Go/PostgreSQL arka ucu ve job-driven SLA/bildirim mantığı gibi standart parçaları prototiplemek için Koder.ai gibi vibe-coding platformunda prototip yapabilirsiniz.
Veri depolama: önce ilişkisel, arama gerektiğinde ekleyin
Çekirdek kayıtlar—biletler, müşteriler, SLA’lar, eskalasyon olayları, atamalar—için ilişkisel veritabanı kullanın (Postgres yaygın bir varsayılan). İşlemler, kısıtlar ve raporlama için uygundur.
Başlık satırı, konuşma metni ve müşteri adlarında hızlı arama gerekiyorsa bir arama dizini (Elasticsearch/OpenSearch) eklemeyi düşünün. İlk etapta Postgres full-text arama ile başlayın, sonra gerekirse yükseltin.
Arka plan işleri zorunludur
Eskalasyon uygulamaları zaman bazlı ve entegrasyon işleri gerektirir; bunlar web isteği içinde koşmamalı:
- SLA zamanlayıcıları ve ihlal kontrolleri
- Bildirimler (e-posta/SMS/push)
- On-call paging
- E-posta/sohbet/CRM’den mesaj senkronizasyonu
Bir iş kuyruğu (örn. Celery, Sidekiq, BullMQ) kullanın ve işlerin idempotent olmasını sağlayın ki yeniden denemeler çoğaltılmış uyarı oluşturmasın.
API’leri erken tanımlayın ve tutarlı tutun
REST veya GraphQL seçin, kaynak sınırlarını baştan tanımlayın: tickets, comments, events, customers ve users. Tutarlı API stili entegrasyonları ve UI gelişimini hızlandırır. Ayrıca webhook uç noktalarını baştan planlayın (imza gizli anahtarları, yeniden denemeler ve hız sınırları).
Barındırma ve ortamlar
En az dev/staging/prod ortamları çalıştırın. Staging prod ayarlarını (e-posta sağlayıcıları, kuyruklar, webhooks) yansıtmalı ve güvenli test kimlik bilgileri kullanılmalı. Dağıtım ve geri alma adımlarını belgeleyin; yapılandırmayı kod içinde tutmayın, çevre değişkenlerinde tutun.
Entegrasyonlar: E-posta, Sohbet, CRM ve Webhook'lar
Entegrasyonlar uygulamanızı “başka bir kontrol edilmesi gereken yer” olmaktan çıkarıp ekibin gerçekten kullandığı sisteme dönüştürür. Müşterilerin zaten kullandığı kanallarla başlayın, sonra eskalasyon olaylarına diğer araçların tepki verebilmesi için otomasyon kancaları ekleyin.
E-posta: gelen ayrıştırma, giden gönderim, threading
E-posta genellikle en yüksek etkiyi sağlar. Gelen yönlendirmeyi destekleyin (örn. support@) ve ayrıştırın:
- From/To/Cc, konu, gövde (düz metin yedeği tercih edilir) ve ekler
- Message-ID ve In-Reply-To ile threading
- Müşteri domaini ve imza ipuçları ile iletişim bulma
Giden için, bilet üzerinden yanıt gönderin ve threading başlıklarını koruyun ki cevaplar aynı bilette toplanmaya devam etsin. Konuşma zaman çizelgesinde müşterinin ne gördüğünü değil, dahili notları ayrı tutun.
Sohbet araçları (isteğe bağlı): mesajları bilete dönüştürün
Sohbet için (Slack/Teams/intercom widget), basit tutun: konuşmayı net bir döküm ve katılımcılarla bir bilet haline dönüştürün. Varsayılan olarak her mesajı senkronize etmeyin—ajanların gürültüyü kontrol etmesi için “son 20 mesajı ekle” düğümü sunun.
CRM/müşteri dizini senkronizasyonu: seviye ve kişiler
CRM senkronizasyonu “öncelikli destek”i otomatik hale getirir. Şirket, plan/seviye, hesap sahibi ve kilit kişileri çekin. CRM hesaplarını tenant’larınıza eşleyin ki yeni biletler öncelik kurallarını miras alsın.
Önemli olaylar için webhooks
ticket.escalated, ticket.resolved, sla.breached gibi olaylar için webhooks sağlayın. İstikrarlı bir payload (ticket ID, zaman damgaları, severity, customer ID) ve imzalı istekler sunun ki alıcılar kimliği doğrulayabilsin.
Kurulumu belgeleyin ve basitleştirin
“Test e-postası gönder”, “Webhook doğrula” gibi test düğmeleri olan küçük bir admin akışı ekleyin. Entegre dokümantasyonu tek yerde toplayın (örn. /docs/integrations) ve yaygın sorun giderme adımlarını gösterin: SPF/DKIM sorunları, eksik threading başlıkları, CRM alan eşleştirme.
Test, İzleme ve Güvenilirlik
Make It Team Ready
Use a custom domain when you are ready to share the tool beyond the pilot team.
Bir öncelikli destek uygulaması stresli anlarda “gerçeklik kaynağı” olur. SLA zamanlayıcıları saparsa, yönlendirme hatalıysa veya izinler veri sızdırıyorsa güven hızla erir. Güvenilirliği bir özellik olarak ele alın: önemli olanı test edin, olan biteni ölçün ve hata için plan yapın.
Aciliyeti belirleyen kuralları test edin
Otomatik testleri sonucu değiştiren mantık üzerinde yoğunlaştırın:
- SLA hesaplamaları: başlama/durma koşulları, mesai saatleri, duraklatmalar, ihlal eşikleri ve “bir sonraki tarih” zaman damgaları
- Yönlendirme ve sahiplik: triage kuralları, round-robin/skill-based atama ve eskalasyon tetikleyicileri
- İzinler: kuyruklar, bilet detayları, dahili notlar ve müşteri görünen mesajlar için RBAC
Bir avuç uçtan uca testi (bilet oluştur → triage → eskalasyon → çözüm) ekleyin ki UI ile backend arasındaki varsayılan hataları yakalayın.
Seed verisi ve gerçekçi senaryolar
Demo ötesinde yararlı seed verileri oluşturun: birkaç müşteri, farklı seviyeler (standart vs öncelikli), değişik öncelikler ve farklı durumlarda biletler. Yeniden açılmış biletler, “waiting on customer” ve birden fazla atanan gibi zorlayıcı durumları dahil edin.
Gözlemlenebilirlik: müşteriler söylemeden önce bilin
Uygulamayı şu soruları cevaplayacak şekilde enstrümante edin: “Ne bozuldu, kimin için ve neden?”
- SLA/routing işlerindeki istisnalar için hata takibi
- Bilet ID’leri, kural ID’leri ve korelasyon ID’leri ile yapılandırılmış loglar
- Kritik sayfalar ve arka plan işçileri için performans izleme
Yük testi ve güvenli kurtarma
Kuyruklar, arama ve panolar gibi yüksek trafikli görünümlerde yük testleri çalıştırın—özellikle vardiya değişimleri sırasında.
Son olarak, bir olay oyun planınız olsun: yeni kurallar için feature flag’ler, veritabanı migration geri alma adımları ve otomasyonları devre dışı bırakırken ajanların çalışmaya devam etmesini sağlayan prosedürler.
Lansman Planı, Raporlama ve İterasyon
Bir öncelikli destek web uygulaması ancak ajanlar baskı altında güvenince “tamamlanmış” sayılır. En iyi yol küçük başlamak, gerçekte ne olduğunu ölçmek ve sık döngülerle ilerlemektir.
İş akışını doğrulayan bir MVP ile başlayın
Her özelliği yayımlama dürtüsüne direnin. İlk sürümünüz “yeni eskalasyondan” “hesap verebilirlikle çözülene” kadar en kısa yolu kapsamalı:
- Öncelik, SLA dolma zamanı ve müşteri seviyesi ile net sıralama yapan bir triage kuyruğu
- Hızlı güncelleme ve dahili notları destekleyen bilet detay sayfası
- Görünür SLA zamanlayıcıları (ilk yanıt ve çözüm/sonraki güncelleme)
- Yaklaşan ihlaller ve durum değişiklikleri için temel uyarılar
Eğer Koder.ai kullanıyorsanız, bu MVP şekli onun varsayılanlarına (React UI, Go servisleri, PostgreSQL) uygundur ve SLA matematiği, yönlendirme kuralları ve izinleri ayarlarken snapshot/rollback özelliği faydalı olabilir.
Küçük bir ekip ile pilot ve haftalık gözden geçirme
Pilot gruba dağıtın (bir bölge, bir ürün hattı veya bir on-call rotasyonu) ve haftalık geri bildirim toplantıları yapın. Yapıyı şu sorular etrafında tutun: ajanları yavaşlatan neydi, hangi veri eksikti, hangi uyarılar gürültülüydü ve eskalasyon yönetimi nerede çöktü (devirler, belirsiz sahiplik veya yanlış yönlendirme).
Pratik bir taktik: uygulama içinde hafif bir değişiklik günlüğü tutun ki ajanlar iyileştirmeleri görsün ve kendilerini duyulmuş hissetsinler.
Eyleme yönlendiren raporlar ekleyin, gösteriş için değil
Tutarlı kullanım başladıktan sonra operasyonel sorulara cevap veren raporlar ekleyin:
- SLA uyumu: öncelik, müşteri seviyesi ve kanal bazında ihlal oranları
- Eskalasyon hacmi: zaman içindeki eğilimler ve sürümler sonrası artışlar
- En çok etkileyen nedenler: etiketler/nedenler ile korelasyon
- Ajan yükü: ajan başına açık bilet sayısı ve ilk dokunuşa geçen zaman
Bu raporlar kolay dışa aktarılmalı ve teknik olmayan paydaşlara kolayca açıklanabilmeli.
Kuralları ve makroları gerçek çıktılara göre iteratif iyileştirin
Yönlendirme ve triage kuralları ilk başta yanlış olacaktır—bu normaldir. Yanlış yönlendirmelere, çözüm sürelerine ve on-call geri bildirimine göre triage kurallarını ayarlayın. Makrolar için de aynı: süreyİ azaltmayanları kaldırın, iletişim ve netliği artıranları iyileştirin.
Basit bir yol haritası ve yardım kaynakları yayınlayın
Ürünün içinde kısa, görünür bir yol haritası tutun (“İlk 30 gün”). Yardım içeriklerine ve SSS’lere bağlantılar verin ki eğitim kabile bilgiseliğine dönüşmesin. Eğer halka açık bilgi tutuyorsanız, dahili bağlantılar (örn. /pricing veya /blog) ile erişilebilir yapın ki ekipler kendi kendine öğrenebilsin.