Transformer, sıraların—sıralamanın ve bağlamın önemli olduğu şeylerin—bilgisayarlar tarafından anlaşılmasına yardımcı olan bir yoldur. Cümleler, kod veya ardışık arama sorguları gibi verilerde; önceki tokenları tek tek okuyup kırılgan bir belleği ileri taşımak yerine, Transformer tüm diziyi gözden geçirir ve her parçayı yorumlarken neye dikkat edeceğine karar verir.
Bu basit kayma büyük bir fark yarattı. Modern büyük dil modellerinin (LLM'ler) bağlamı korumasının, talimatları takip etmesinin, tutarlı paragraflar yazmasının ve önceki fonksiyonlara ve değişkenlere atıfta bulunan kod üretmesinin ana sebeplerinden biridir.
Bir sohbet botu, “bunu özetle” özelliği, semantik arama veya bir kod yardımcısı kullandıysanız, Transformer tabanlı sistemlerle etkileşime geçmişsiniz demektir. Aynı temel şablon şu alanları destekler:
- Daha önce söylediklerinizi takip eden sohbet ve müşteri destek araçları
- Anlamı anahtar kelimelerden ziyade eşleştiren arama ve öneri sistemleri
- Neyi merkeze alıp neyin detay olduğunu tartabilen özetleme
- Tanımları, kullanımları ve niyeti dosyalar arasında bağlayan kod araçları
Bu yazıda neler öğreneceksiniz
Kilit parçaları—self-attention, multi-head attention, positional encoding ve temel Transformer bloğunu—ayrıntılarıyla ele alacağız ve bu tasarımın model büyüdükçe neden iyi ölçeklendiğini açıklayacağız.
Ayrıca aynı temel fikri koruyan fakat hızı, maliyeti veya daha uzun bağlam pencereleri için öne çıkan modern varyantlara da değineceğiz.
Ne beklemelisiniz (ve ne beklememelisiniz)
Bu yazı matematikten kaçınan, düz anlatımlı bir üst düzey turdur. Amaç sezgiyi geliştirmektir: parçalar ne yapar, neden birlikte çalışırlar ve bunun gerçek ürün yeteneklerine nasıl yansıdığı.
Noam Shazeer, 2017 tarihli “Attention Is All You Need” makalesinin eş-yazarlarından biri olarak bilinen bir AI araştırmacısı ve mühendistir. O makale Transformer mimarisini tanıttı ve bu mimari daha sonra birçok modern büyük dil modelinin temelini oluşturdu. Shazeer'in çalışması bir ekip çabasının parçasıdır: Transformer Google'daki bir araştırma grubu tarafından oluşturuldu ve bunu böyle anmak önemlidir.
2017 makalesinin değiştirdikleri
Transformer'dan önce, pek çok NLP sistemi metni adım adım işleyen rekürent modellere dayanıyordu. Transformer önerisi, dizileri rekürens olmadan—attention'ı cümlenin genelinde bilgi birleştirme mekanizması olarak kullanarak—etkili şekilde modelleyebileceğinizi gösterdi.
Bu kayma önemliydi çünkü eğitimin paralelleştirilmesini kolaylaştırdı (birçok tokenı aynı anda işleyebilirsiniz) ve modelleri ile veri kümelerini pratik şekilde ölçeklendirmenin yolunu açtı; bu da hızlıca gerçek ürünlere dönüştürülebilir hale geldi.
Araştırma fikrinden ürün yapı taşına
Shazeer'in katkısı—diğer yazarlarla birlikte—sadece akademik kıyaslamalarla sınırlı kalmadı. Transformer yeniden kullanılabilir bir modül haline geldi: bileşenleri değiştirin, boyutu ayarlayın, görevlere göre ince ayar yapın ve daha sonra ölçekli ön eğitim uygulayın.
Pek çok atılım bu şekilde yayılır: bir makale temiz, genel bir tarif sunar; mühendisler bunu iyileştirir; şirketler operasyonelleştirir; ve sonunda dil özellikleri oluşturmanın varsayılan seçeneği haline gelir.
Krediyi doğru vermek
Shazeer'in Transformer makalesinin kilit katkıda bulunanlarından biri olduğunu söylemek doğru; ancak onu tek mucit olarak göstermek doğru olmaz. Etki kolektif tasarımdan gelir—ve topluluk tarafından yapılan birçok sonradan gelen iyileştirmeden.
Öncesi: RNN'ler, LSTM'ler ve sınırlamaları
Transformer'dan önce, çeviri, konuşma, metin üretimi gibi sıralama problemleri çoğunlukla Recurrent Neural Networks (RNNs) ve daha sonra LSTMs (Long Short-Term Memory ağları) tarafından çözüldü. Büyük fikir basitti: metni her seferinde bir token okuyun, bir "bellek" (gizli durum) tutun ve bir sonraki geldiğinde bunu kullanın.
Nasıl çalıştıklarına kısa bir bakış
Bir RNN cümleyi bir zincir gibi işler. Her adım, mevcut kelime ve önceki gizli durum temelinde gizli durumu günceller. LSTM'ler ise neyi tutup neyi unutacaklarını ve neyi çıktılayacaklarını belirleyen kapılar ekleyerek faydalı sinyalleri daha uzun süre korumayı kolaylaştırdı.
Uzun menzilli bağımlılıklar neden zordu
Pratikte, ardışık bellek bir darbozandır: cümle uzadıkça çok fazla bilgi tek bir durum üzerinde sıkıştırılmak zorunda kalır. LSTM'lerle bile, çok daha önceki kelimelerden gelen sinyaller solabilir veya üzeri yazılabilir.
Bu, doğru isimle bağlama, birçok kelime önceki bir isme dair zamiri doğru eşleştirme ya da birden fazla cümlede bir konuyu takip etme gibi ilişkileri öğrenmeyi zorlaştırdı.
Eğitim ve ölçekleme zorlukları
RNN'ler ve LSTM'ler ayrıca eğitimi yavaşlatan bir yapıya sahiptir çünkü zaman içinde tamamen paralelleştirilemezler. Farklı cümleler arasında batch yapabilirsiniz, ancak tek bir cümlede 50. adım 49. adıma bağlıdır, o da 48. adıma bağımlıdır ve bu böyle devam eder.
Bu adım adım hesaplama, daha büyük modeller, daha fazla veri ve daha hızlı deneme yapmak istediğinizde ciddi bir sınırlama haline gelir.
Daha paralel-dostu bir yaklaşıma ihtiyaç
Araştırmacılar, kelimeleri eğitim sırasında katı şekilde soldan sağa ilerletmeden birbirleriyle ilişkilendirebilen bir tasarıma ihtiyaç duydular—uzak ilişkilere doğrudan bakabilen ve modern donanımı daha iyi kullanabilen bir yol. Bu baskı, Attention Is All You Need'de tanıtılan attention-öncelikli yaklaşım için zemin hazırladı.
Attention, matematiksiz açıklama
Attention modelin şu soruyu sorma yoludur: "Bu kelimeyi anlamak için şu an hangi diğer kelimelere bakmalıyım?"
Bir cümleyi katı şekilde soldan sağa okumak ve belleğin tutacağına güvenmek yerine, attention modelin ihtiyaç duyduğu anda cümlenin en alakalı kısımlarına bakmasını sağlar.
"Arama ve getirme" fikri
Yardımcı bir zihinsel model, cümle içinde küçük bir arama motoru çalışmasıdır.
- Query: mevcut kelimenin aradığı şey (soru)
- Keys: diğer her kelimenin sunduğu şey (potansiyel eşleşmelerin etiketleri)
- Values: eşleşme oluştuğunda alınacak gerçek bilgi (içerik)
Model, mevcut pozisyon için bir query oluşturur, bunu tüm pozisyonların key'leri ile karşılaştırır ve sonra bir değer karışımı alır.
Alaka puanları → attention ağırlıkları
Bu karşılaştırmalar alaka puanları üretir: "ne kadar ilgili?" sinyalleri. Model bunları toplamı 1 olan attention ağırlıklarına çevirir.
Bir kelime çok ilgiliyse, modele daha büyük bir dikkat payı düşer. Birkaç kelime önemliyse, attention bunlara yayılabilir.
Basit bir örnek (zamirler ve dilbilgisi)
Alın: "Maria, Jenna'ya onun daha sonra arayacağını söyledi."
o zamirini yorumlamak için modelin "Maria" ve "Jenna" gibi adaylara bakması gerekir. Attention, bağlama en iyi uyan isme daha yüksek ağırlık verir.
Veya: "Anahtarlar dolabın içine sığmıyordu çünkü o çok küçüktü." Attention, "sığmıyordu"nun hangi isme bağlandığını belirlemeye yardımcı olur—yakınlık her zaman doğru gösterge değildir. İşte temel fayda: attention, anlamı uzak mesafelerde dahi gerektiğinde bağlar.
Self-Attention: Temel mekanizma
Self-attention, dizideki her tokenin şu anda neyin önemli olduğunu belirlemek için aynı dizideki diğer tokenlere bakabilmesidir. Eski rekürent modellerin yaptığı gibi kelimeleri tek tek işlemeye gerek kalmaz; Transformer her tokenin girdi içinde her yerden ipuçları toplamasına izin verir.
Tokenların tokenlara dikkat etmesi
Cümleyi hayal edin: "Suyu bardağa doldurdum çünkü o boştu." "o" kelimesinin "bardak" ile bağlantı kurması gerekir, suyla değil. Self-attention ile "o" tokeni anlamını çözmeye yardımcı olacak tokenlere ("bardak", "boş") daha yüksek önem verir, alakasızlara daha düşük verir.
Bağlamın nasıl inşa edildiği
Self-attention sonrası her token artık sadece kendisi değildir. O, bağlam farkındalıklı bir versiyon olur—diğer tokenlerden ağırlıklı bir karışımdır. Her tokenın, o tokenin ihtiyacına göre tüm cümlenin kişiselleştirilmiş bir özetini oluşturduğunu düşünebilirsiniz.
Pratikte bu, "bardak" temsilinin "doldurdu", "su" ve "boş" gibi sinyalleri taşıyabileceği, "boş"un ise tanımladığı şeyle ilgili bilgileri çekebileceği anlamına gelir.
Neden eğitim paralel olabilir
Her token tüm dizi üzerindeki attention'ını aynı anda hesaplayabildiği için eğitim önceki tokenların işlenmesini beklemek zorunda kalmaz. Bu paralel işlem, Transformer'ların büyük veri kümelerinde verimli bir şekilde eğitilmesinin ve devasa modellere ölçeklenmesinin ana nedenlerinden biridir.
Neden uzun menzilli ilişkilerde güçlüdür
Self-attention, metnin uzak kısımlarını bağlamayı kolaylaştırır. Bir token, kendisine uzak bir yerdeki ilgili kelimeye doğrudan odaklanabilir—uzun bir ara zincirden bilgi geçirmek zorunda kalmaz.
Bu doğrudan yol, koreferans, paragraf boyunca konuları takip etme ve önceki ayrıntılara bağlı talimatları işleme gibi görevlerde yardımcı olur.
Multi-Head Attention: Aynı cümlenin birçok bakışı
Geri alma ile daha güvenli iterasyonlar
Sonuçlar gerilediğinde özgürce deney yapın ve anlık görüntülerle geri alın.
Tek bir attention mekanizması güçlüdür, ama sohbeti tek bir kamera açısıyla anlamaya çalışmak gibi olabilir. Cümleler genellikle aynı anda birkaç ilişki içerir: kim ne yaptı, "o"nun neye atıfta bulunduğu, hangi kelimelerin tonu belirlediği ve genel konunun ne olduğu.
Neden tek bir attention görünümü yetmez
"Kupa sığmadı çünkü o çok küçük" cümlesini okurken aynı anda birden fazla ipucu takip etmeniz gerekebilir (dilbilgisi, anlam, gerçek dünya bağlamı). Bir attention "görünümü" en yakın isme odaklanabilir; başka bir başlık fiil öbeğini kullanarak "o"nun neye atıfta bulunduğunu belirleyebilir.
Birden çok başlık ne yapar
Multi-head attention, birkaç attention hesaplamasını paralel çalıştırır. Her "başlık" farklı bir mercekle bakması için teşvik edilir—genelde farklı altuzaylarda. Uygulamada başlıklar şunlarda uzmanlaşabilir:
- Yerel sözdizimi (ör. sıfat → isim)
- Uzun menzilli bağlantılar (ör. özne ↔ fiil bir cümle boyunca)
- Koreferans (ör. zamir → varlık)
- Konu sinyalleri (konuyu veya duyguyu belirleyen kelimeler)
Başlıklar nasıl birleştirilir
Her başlık kendi içgörülerini ürettikten sonra model bunlardan sadece birini seçmez. Başlık çıktıları birleştirilir (yan yana istiflenir) ve sonra öğrenilen lineer bir katmanla modelin ana çalışma alanına projeksiyon yapılır.
Bunu, birkaç kısmi notun birleşip bir sonraki katmanın kullanacağı temiz bir özet oluşturmasına benzetin. Sonuç, birçok ilişkiyi aynı anda yakalayabilen bir temsildir—Transformer'ların ölçeklendikçe iyi çalışmasının nedenlerinden biridir.
Positional Encoding: Modele kelime sırasını öğretmek
Self-attention ilişkiyi tespit etmekte mükemmeldir—ama tek başına "kim önceydi" bilgisini vermez. Kelimeleri karıştırırsanız, sıradan bir self-attention katmanı karıştırılmış versiyona eşit davranabilir çünkü tokenleri karşılaştırırken pozisyon bilgisi yoktur.
Positional encoding, token temsilcilerine "ben dizide nerede duruyorum?" bilgisini enjekte ederek bunu çözer. Pozisyon eklendiğinde attention, "not"tan hemen sonra gelenin önemini veya "özne genelde fiilden önce gelir" gibi örüntüleri öğrenebilir.
Pozisyon kodlarının sıra eklemesi nasıl çalışır
Temel fikir basittir: her token embedding'i, Transformer bloğuna girmeden önce bir pozisyon sinyali ile birleştirilir. Bu pozisyon sinyali, bir tokenı girdide 1., 2., 3. … olarak etiketleyen ekstra özellikler seti gibi düşünülebilir.
Yaygın yaklaşımlar:
- Mutlak (sabit) pozisyonlar: Klasik Transformer'lar deterministik, sinüzoidal desenler kullandı. Yeni parametre eklemez ve eğitim sırasında görülenden daha uzun dizilere bir noktaya kadar genellenebilir.
- Öğrenilmiş mutlak pozisyonlar: Model "pozisyon 1" için, "pozisyon 2" için vektör öğrenir. Bu çok iyi çalışabilir, fakat genellikle modeli eğitildiği maksimum bağlam penceresine bağlayabilir.
- Relatif pozisyonlar: "Bu token 57. sırada" demek yerine model "bu token diğerinden 3 adım önce" gibi mesafeye odaklanır. Rotary tarzı yöntemler de genelde bu aileye girer.
Uzun-bağlam görevleri için neden önemli
Pozisyon seçimleri uzun-bağlam modellemesini etkileyebilir—uzun bir raporu özetlemek, birçok paragrafta varlıkları takip etmek veya binlerce token önce bahsedilmiş bir detayı geri bulmak gibi.
Uzun girdilerde model sadece dili öğrenmez; nereye bakacağını da öğrenir. Relatif ve rotary tarzı şemalar, uzak tokenları karşılaştırmayı ve bağlam arttıkça örüntüleri korumayı kolaylaştırma eğilimindedir; bazı mutlak şemalar ise eğitim penceresinin ötesine itildiğinde daha çabuk bozulabilir.
Pratikte positional encoding, bir LLM'in 2.000 token'da keskin ve tutarlı hissedip 100.000 token'da da tutarlı kalıp kalmayacağını belirleyebilecek sessiz bir tasarım kararından biridir.
Tam yığını gönderin
Basit bir istemden React UI, Go backend ve PostgreSQL şeması oluşturun.
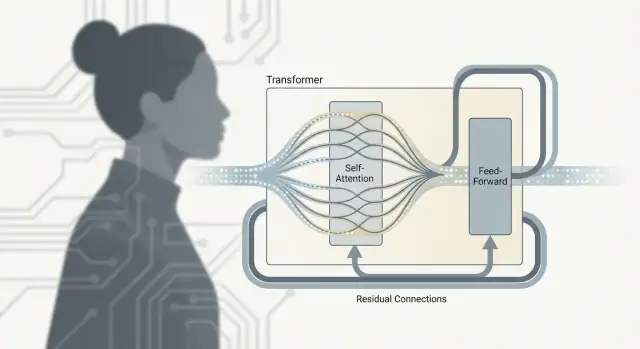
Transformer sadece "attention" değildir. Gerçek iş, bilgiyi tokenlar arasında karıştıran ve sonra bunu rafine eden tekrar eden bir birimin içinde—genelde Transformer bloğu denilen—gerçekleşir. Birçok bloğu üst üste koyduğunuzda, büyük dil modellerini bu kadar yetenekli yapan derinliği elde edersiniz.
Attention sonrası: FFN/MLP ne yapar
Self-attention iletişim adımıdır: her token diğer tokenlerden bağlam toplar.
Feed-forward ağı (FFN) veya MLP ise düşünme adımıdır: her tokenın güncellenmiş temsilini alır ve aynı küçük sinir ağını her bir token üzerinde bağımsız olarak çalıştırır.
Basitçe söylemek gerekirse, FFN her tokenın artık bildiklerini dönüştürür ve biçimlendirir; böylece model, bağlam topladıktan sonra sözdizimi örüntüleri, gerçekler veya üslup ipuçları gibi daha zengin özellikler inşa edebilir.
Neden bloklar attention ve FFN arasında dönüşümlüdür
Bu dönüşüm önemli çünkü iki parça farklı işler yapar:
- Attention bilgi tokenlar arasında taşır (kim kimi etkilemeli)
- FFN bilgi her token içinde işler (o bağlamı nasıl kullanmalı)
Bu deseni tekrarlamak modelin kademeli olarak daha yüksek seviyeli anlamlar inşa etmesini sağlar: iletişim kur, hesapla, tekrar iletişim kur, tekrar hesapla.
Residual bağlantılar: "atlama şeritleri"
Her alt-katman (attention veya FFN) residual bağlantıyla sarılıdır: giriş çıktıya geri eklenir. Bu, derin modellerin eğitilmesine yardımcı olur çünkü gradyanlar, belirli bir katman hâlâ öğreniyor olsa bile "atlama şeridi"nden akabilir. Ayrıca bir katmanın her şeyi yeniden öğrenmek zorunda kalmadan küçük düzeltmeler yapmasını sağlar.
Layer normalization: sinyalleri sabit tutmak
Layer normalization, aktivasyonların çok büyük veya çok küçük hale gelmesini engelleyen bir dengeleyicidir; bu sayede ileriki katmanlar sinyalle ezilmez veya sinyalden yoksun kalmaz—bu da özellikle LLM ölçeğinde eğitimi daha pürüzsüz ve güvenilir kılar.
Encoder–Decoder vs Decoder-Only: Hangi LLM'leri Besliyor?
Orijinal Transformer Attention Is All You Need içinde çeviri için tasarlanmıştı; bir diziyi (Fransızca) alıp başka bir diziyi (İngilizce) üretmek. Bu görev doğal olarak iki rolü ayırır: girişi iyi okumak ve çıktıyı akıcı biçimde yazmak.
Encoder–Decoder: "Oku, sonra Yaz"
Encoder–decoder Transformer'da, encoder tüm girdi cümlesini aynı anda işler ve zengin bir temsil seti üretir. Decoder ise çıktıyı token token üretir.
Önemli olarak, decoder yalnızca kendi geçmiş tokenlarına güvenmez; aynı zamanda encoder'ın çıktısına bakmak için cross-attention kullanır, bu da çıktıyı kaynak metne sıkı şekilde dayandırır.
Bu düzen, çeviri, özetleme veya belirli bir pasajla sıkı şekilde koşullandırmanız gereken soru-cevap gibi işler için hâlâ mükemmeldir.
Decoder-Only: Sürekli Tahmin Yapan Tek Model
Modern büyük dil modellerinin çoğu decoder-onlydir. Basit, güçlü bir görev için eğitilirler: bir sonraki tokeni tahmin et.
Bunu yapmak için masked self-attention (causal attention) kullanırlar. Her pozisyon yalnızca önceki tokenlara bakabilir, geleceğe bakamaz; böylece üretim soldan sağa olur ve model diziyi sürekli uzatır.
Bu, devasa metin kütleleri üzerinde eğitimi basit hale getirir, üretim kullanım durumuna doğrudan uyar ve veri ile hesap açısından verimli ölçeklenir.
Encoder-only modellerin yeri
Encoder-only Transformer'lar (BERT tarzı modeller) metin üretmez; girdiyi iki yönlü okurlar. Sınıflandırma, arama ve embedding üretimi gibi, bir metni anlamanın uzun bir devam üretmekten daha önemli olduğu işler için mükemmeldirler.
Transformer'lar sıradışı şekilde ölçek dostu çıktı: onlara daha fazla metin, daha fazla hesap ve daha büyük modeller verirseniz, genellikle öngörülebilir biçimde iyileşirler.
Bunun büyük bir nedeni yapısal sadeliktir. Transformer, tekrarlanan bloklardan (self-attention + küçük bir feed-forward ağı + normalizasyon) oluşur ve bu bloklar bir milyon kelimeyle mi yoksa trilyonla mı eğitiliyor benzer davranırlar.
Paralel eğitim gizli süper gücü
Erken sıralama modelleri (RNN'ler gibi) tokenları tek tek işlemek zorundaydı; bu paralel iş yapılmasını sınırlar. Transformer'lar ise eğitim sırasında tüm tokenları paralel işleyebilir.
Bu onları GPU/TPU ve büyük dağıtık kurulumlara çok uygun kılar—modern LLM'lerin eğitimi için tam da ihtiyaç duyduğunuz şey.
"Bağlam penceresi" ve neden önemli olduğu
Bağlam penceresi, modelin bir kerede "görebildiği" metin parçasıdır—isteminiz artı son konuşma veya belge metni. Daha büyük pencere modelin daha fazla cümle veya sayfa arasında bağlantı kurmasını, kısıtları takip etmesini ve önceki detaylara bağlı soruları yanıtlamasını sağlar.
Ama bağlam ücretsiz değildir.
Temel sınırlama: attention maliyeti uzunlukla artar
Self-attention tokenları birbirleriyle karşılaştırır. Dizi uzadıkça karşılaştırma sayısı hızla artar (yaklaşık dizi uzunluğunun karesiyle).
Bu yüzden çok uzun bağlam pencereleri bellek ve hesap açısından pahalı olabilir; birçok modern çaba attention'ı daha verimli hale getirmeye odaklanır.
Ölçekleme genel amaçlı davranışı açığa çıkarır
Transformer'lar ölçeklendiğinde sadece tek bir dar görevde daha iyi olmazlar. Öğe, çeviri, yazı, kod üretme ve muhakeme gibi geniş, esnek yetenekler sergilemeye başlar—çünkü aynı genel öğrenme mekanizması çok çeşitli büyük veri üzerinde uygulanır.
Aynı Mimarinin Üzerine Kurulan Modern Varyantlar
Prototipin ötesine ölçekleyin
Hızlı bir deneyden ekip hazır bir yapıya geçiş için üst seviye planlara yükseltin.
Orijinal Transformer tasarımı hâlâ referans noktasıdır, ancak üretim LLM'lerinin çoğu "Transformer artı": çekirdeği (attention + MLP) koruyan fakat hızı, kararlılığı veya bağlam uzunluğunu iyileştiren küçük, pratik düzenlemeler içerir.
Sık gördüğünüz iyileştirmeler
Pek çok yükseltme modelin ne olduğunu değiştirmekten çok eğitilmesini ve çalıştırılmasını iyileştirmeye yöneliktir:
- Daha iyi pozisyon yöntemleri: Klasik sinüzoid yerine rotary veya relatif tarzı yaklaşımlar uzun-mesafe işleme konusunda daha yumuşak davranabilir.
- Attention optimizasyonları: Bellek kullanımını azaltan ve verimi artıran uygulamalar (ör. fused kernel'lar veya daha verimli attention hesaplamaları).
- Normalizasyon ayarları: Normalizasyonun nerede ve nasıl uygulandığındaki küçük değişiklikler eğitim kararlılığını iyileştirebilir ve hiperparametrelere duyarlılığı azaltabilir.
Bu değişiklikler genelde modelin "Transformer olmasını" değiştirmez—sadece onu rafine eder.
Uzun-bağlam yaklaşımları (üst düzey)
Bağlamı birkaç bin token'dan on binlerce veya yüz binlere uzatmak genellikle seyrek attention (sadece seçilmiş tokenlara dikkat) veya verimli attention varyantları (hesabı yaklaşıklaştırmak veya yeniden yapılandırmak) kullanır.
Takas genelde doğruluk, bellek ve mühendislik karmaşıklığı arasındadır.
Mixture-of-Experts (MoE): doğrusal maliyet olmadan daha fazla kapasite
MoE modelleri birden çok "uzman" alt-ağ ekler ve her tokenı yalnızca bir altkümeye yönlendirir. Kavramsal olarak: daha büyük bir beyin elde edersiniz, ancak her seferinde hepsini aktive etmezsiniz.
Bu, belirli bir parametre sayısı için token başına hesaplamayı azaltabilir; fakat yönlendirme, uzman dengeleme ve servis etme gibi sistem karmaşıklığını artırır.
Varyant iddialarını nasıl değerlendirmelisiniz
Bir model yeni bir Transformer varyantını öne sürdüğünde, şunları isteyin:
- Görevlerinize uygun benchmark'lar (sadece başlık skorları değil)
- Gecikme (ilk token süresi ve token/sn)
- Maliyet (eğitim ve çıkarım), bellek ve donanım ihtiyaçları dahil
Çoğu iyileştirme gerçektir—ama nadiren bedava gelir.
LLM'lerle Üreten Ekipler İçin Anlamı
Self-attention ve ölçekleme gibi Transformer fikirleri ilginçtir—ama ürün ekipleri bunları genelde şu takaslar olarak hisseder: ne kadar metin koyabilirsiniz, cevabı ne kadar hızlı alırsınız ve istek başına maliyet nedir.
Bir model veya sağlayıcı seçerken dört takası
Bağlam uzunluğu: Daha uzun bağlam daha fazla belge, sohbet geçmişi ve talimat eklemenize izin verir. Aynı zamanda token harcamasını ve yanıt gecikmesini artırır. Özelliğiniz "bu 30 sayfayı oku ve cevap ver"e dayanıyorsa, bağlam uzunluğunu önceliklendirin.
Gecikme: Kullanıcıya yönelik sohbet ve yardımcı deneyimler yanıt süresine bağlıdır. Akışlı çıktı yardımcıdır, ancak model seçimi, bölge ve batch'leme de önemlidir.
Maliyet: Fiyatlama genelde token başına (girdi + çıktı). %10 daha "iyi" bir model bazen 2–5× maliyet getirebilir. Hangi kalite seviyesinin ödemeye değeceğine fiyatlandırma karşılaştırmalarıyla karar verin.
Kalite: Sizin kullanım durumunuz için tanımlayın: doğruluk, talimat takip etme, ton, araç kullanımı veya kod. Değerlendirmeyi alana özgü gerçek örneklerle yapın, genel benchmark'lar yerine.
Embedding'ler üretimi ne zaman yener
Eğer esas ihtiyacınız arama, deduplama, kümeleme, öneriler veya "benzerini bulma" ise, embedding'ler (genellikle encoder tarzı modeller) genelde daha ucuz, daha hızlı ve daha stabil olur. Sadece son adımda (özetler, açıklamalar, taslak) generasyonu kullanın.
Daha ayrıntılı bir döküm için ekibinizi /blog/embeddings-vs-generation gibi teknik bir açıklamaya yönlendirin.
Gerçek ürün iş akışlarında bu nasıl görünür
Transformer yeteneklerini bir ürüne dönüştürdüğünüzde zor kısım genelde mimariden ziyade etrafındaki iş akışıdır: istem yinelemesi, grounding, değerlendirme ve güvenli dağıtım.
Pratik bir yol, Koder.ai gibi bir vibe-coding platformu kullanmaktır: web uygulamanızı, backend uç noktalarını ve veri modelini sohbet içinde tarif ederek prototip oluşturabilir, planlama modunda yineleyebilir ve sonra kaynak kodu dışa aktarabilir veya barındırma, özel alanlar ve anlık görüntülerle dağıtabilirsiniz. Bu, retrieval, embeddings veya araç çağırma döngüleriyle deneme yaparken aynı iskeleti yeniden kurmadan hızlı deneme döngüleri sağlar.
Uygulamalı benimseme kontrol listesi
- Bir sayfa spesifika yazın: kullanıcı hedefi, başarısızlık modları ve "iyi"nin nasıl göründüğü.
- Hangi bilgilerin verilerinizle sabitleneceğine karar verin (RAG, atıflar veya araç çağrıları).
- Token, gecikme ve aylık harcama bütçeleri belirleyin; bunları staging'de ölçün.
- Güvenlik önlemleri ekleyin: reddetmeler, sansürleme ve "bilmiyorum" davranışı.
- Değerlendirmeyi erken kurun: golden prompt'lar, regresyon testleri ve insan incelemesi.
- Model değişiklikleri için plan yapın: prompt ve yönlendirmeyi yapılandırılabilir tutun.