13 Kas 2025·8 dk
NoSQL Veritabanları Ölçek ve Esnekliği Düzeltmek İçin Nasıl Ortaya Çıktı
NoSQL’in neden ortaya çıktığını öğrenin: web ölçeği, esnek veri ihtiyaçları ve ilişkisel sistemlerin sınırları—artı temel modeller ve ödünler.
NoSQL’in neden ortaya çıktığını öğrenin: web ölçeği, esnek veri ihtiyaçları ve ilişkisel sistemlerin sınırları—artı temel modeller ve ödünler.
NoSQL, birçok ekibin uygulamalarının ihtiyaçları ile geleneksel ilişkisel veritabanlarının (SQL veritabanları) optimize edildiği şeyler arasında bir uyumsuzluk yaşadığı zaman ortaya çıktı. SQL “başarısız” olmadı—ancak web ölçeğinde bazı ekipler farklı hedefleri önceliklendirmeye başladı.
İlk olarak, ölçek. Popüler tüketici uygulamaları trafik sıçramaları, sürekli yazma işlemleri ve kullanıcı tarafından üretilen büyük veri hacimleri görmeye başladı. Bu iş yükleri için “daha büyük bir sunucu al” demek hem pahalı, uygulaması yavaş hem de en fazla işleyebileceğiniz makineyle sınırlıydı.
İkincisi, değişim. Ürün özellikleri hızla evriliyor ve arkalarındaki veri her zaman sabit tablolara düzgün sığmıyordu. Kullanıcı profillerine yeni öznitelikler eklemek, birden fazla olay tipi saklamak veya farklı kaynaklardan gelen yarı yapılandırılmış JSON almak sık sık şema göçleri ve ekipler arası koordinasyon gerektiriyordu.
İlişkisel veritabanları yapıyı zorlamakta ve normalleştirilmiş tablolar arasında karmaşık sorgulara izin vermekte mükemmeldir. Ancak bazı yüksek ölçekli iş yükleri bu güçlü yönlerden tam olarak faydalanmayı zorlaştırdı:
Sonuç: bazı ekipler, belirli garanti ve yeteneklerden feragat ederek daha basit ölçeklenebilirlik ve daha hızlı yineleme sağlayan sistemleri tercih ettiler.
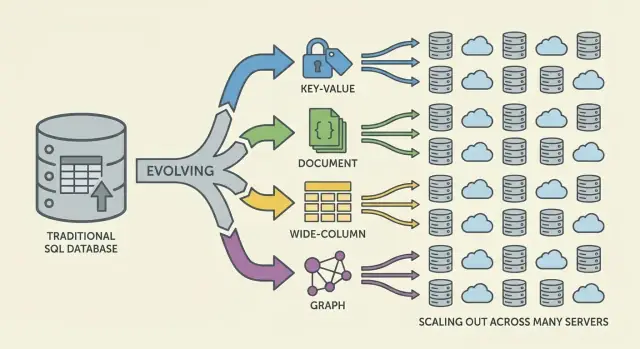
NoSQL tek bir veritabanı ya da tek bir tasarım değildir. Yatay ölçekleme (daha fazla makine ekleme), esnek veri modelleri ve uygulama ihtiyaçlarına göre ayarlanmış erişim desenlerini vurgulayan sistemler için şemsiye bir terimdir.
NoSQL hiçbir zaman SQL için evrensel bir ikame olarak tasarlanmadı. Bu, bir dizi ödünleşmedir: ölçeklenebilirlik veya şema esnekliği kazanabilirsiniz, ama zayıf tutarlılık garantileri, daha az ad-hoc sorgu seçeneği veya uygulama düzeyinde daha fazla veri modelleme sorumluluğu kabul edebilirsiniz.
Yıllarca yavaş bir veritabanına verilen standart cevap basitti: daha büyük bir sunucu satın alın. Daha fazla CPU, daha fazla RAM, daha hızlı disk ekleyin ve aynı şema ve işletme modelini koruyun. Bu “yukarı ölçekleme” yaklaşımı işe yarıyordu—ta ki pratik olmaktan çıkana kadar.
Yüksek uç makineler hızla pahalılaşır ve fiyat/perfomans eğrisi sonunda elverişsiz hale gelir. Yükseltmeler genellikle büyük, seyrek bütçe onayları ve veri taşıma ile kesinti pencereleri gerektirir. Daha büyük donanımı karşılayabilseniz bile, tek bir sunucunun tavanı vardır: tek bir bellek yolu, tek bir depolama alt sistemi ve yazma yükünü emen tek bir birincil düğüm.
Ürünler büyüdükçe veritabanları nadiren aralıklı zirveler yerine sürekli okuma/yazma baskısı ile karşılaştı. Trafik gerçekten 7/24 hale geldi ve bazı özellikler dengesiz erişim desenleri yarattı. Az sayıda yoğun erişilen satır veya partition, sıcak tablolar (veya sıcak anahtarlar) oluşturup her şeyi yavaşlatabiliyordu.
Operasyonel darboğazlar yaygınlaştı:
Birçok uygulama yalnızca bir veri merkezinde hızlı olmak istemiyordu; bölgeler arası erişilebilirlik de gerekliydi. Tek bir “ana” veritabanı uzak kullanıcılar için gecikmeyi artırır ve kesintileri daha yıkıcı hale getirir. Soru "Daha büyük bir kutu nasıl alırız?" değil, "Veritabanını birçok makine ve konumda nasıl çalıştırırız?" oldu.
İlişkisel veritabanları veri şeklinizin sabit olduğu durumlarda parlak. Ancak birçok modern ürün hareketsiz değil. Bir tablo şeması kasıtlı olarak katıdır: her satır aynı sütunlar, tipler ve kısıtlamalara uyar. Bu öngörülebilirlik değerlidir—ta ki sık iterasyon yapan bir ekip için sürtünce yaratana kadar.
Gerçekte sık şema değişiklikleri pahalı olabilir. Küçük görünen bir güncelleme bile göçler, arka doldurmalar, indeks güncellemeleri, koordineli dağıtımlar ve eski kod yollarının kırılmaması için uyumluluk planlaması gerektirebilir. Büyük tablolarda sütun eklemek veya tip değiştirmek bile zaman alıcı operasyonel bir iş olabilir ve gerçek risk taşır.
Bu sürtünce ekipleri değişiklikleri ertelemeye, geçici çözümler biriktirmeye veya metin alanlarına karışık bloblar saklamaya itebilir—hiçbiri hızlı iterasyon için ideal değildir.
Birçok uygulama verisi doğal olarak yarı yapılandırılmıştır: iç içe nesneler, isteğe bağlı alanlar ve zaman içinde gelişen öznitelikler.
Örneğin bir “kullanıcı profili” ad ve e-posta ile başlayıp daha sonra tercihler, bağlı hesaplar, adresler, bildirim ayarları ve deney bayrakları içerebilir. Her kullanıcı her alana sahip değildir ve yeni alanlar kademeli olarak gelir. Doküman tarzı modeller, kayıtları her kaydı aynı katı şablona zorlamadan iç içe ve düzensiz şekillerde saklayabilir.
Esneklik ayrıca bazı veri şekilleri için karmaşık join ihtiyacını azaltır. Tek bir ekranda birleşik bir nesne (ürün, kalem, gönderi ile birlikte öğeler ve durum geçmişi gibi) gerektiğinde ilişkisel tasarımlar birden çok tablo ve join gerektirebilir—ve ORM katmanları bu karmaşıklığı gizlemeye çalışırken genellikle sürtünme ekler.
NoSQL seçenekleri veriyi uygulamanın okuma/yazma şekline daha yakın modellemeyi kolaylaştırdı ve ekiplerin daha hızlı özellik sunmasına yardımcı oldu.
Web uygulamaları sadece büyümedi—şekilleri değişti. İç kullanıcı sayısının öngörülebilir olduğu iş saatleri modelinden, milyonlarca küresel kullanıcıya 7/24 hizmet veren ve lansmanlar, haberler veya sosyal paylaşım nedeniyle aniden patlamalar gören ürünlere geçildi.
Her zaman açık beklentileri çıtayı yükseltti: kesinti bir rahatsızlık değil, haber başlığı oldu. Aynı zamanda ekiplerden daha hızlı özellik sunmaları istendi—çoğu zaman nihai veri modelinin ne olacağı bilinmeden önce.
Ayakta kalmak için tek bir veritabanı sunucusunu büyütmek yeterli olmamaya başladı. Trafiği daha iyi karşıladıkça, kapasiteyi adım adım ekleyebilmek istediler—bir düğüm daha ekle, yükü dağıt, hataları izole et. Bu mimariyi birçok makinenin filosuna doğru itti ve ekiplerin veritabanlarından beklentilerini değiştirdi: sadece doğruluk değil, yüksek eşzamanlılık altında öngörülebilir performans ve sistemin parçaları sağlıksız olduğunda zarif davranış.
"NoSQL" ana akım bir kategori olmadan önce bile birçok ekip web-ölçeği gerçeklerine sistemleri zorlayordu:
Bu teknikler işe yaradı, ama karmaşıklığı uygulama koduna kaydırdı: önbellek geçersiz kılma, çoğaltılmış veriyi tutarlı tutma ve "servise hazır" kayıtlar için boru hatları kurma gibi.
Bu desenler standart hale geldikçe, veritabanları veriyi makineler arasında dağıtmayı, kısmi hatalara dayanmayı, yüksek yazma hacimlerini ve evrilen veriyi temiz şekilde temsil etmeyi desteklemek zorunda kaldı. NoSQL veritabanları kısmen yaygın web-ölçekli stratejileri temel özellik haline getirmek için ortaya çıktı.
Veri tek bir makinede yaşadığında kurallar basit görünür: tek bir hakikat kaynağı vardır ve her okuma veya yazma hemen kontrol edilebilir. Veriyi sunuculara (genellikle bölgelere) yaydığınızda ise yeni bir gerçeklik ortaya çıkar: iletiler gecikebilir, düğümler başarısız olabilir ve sistemin bazı bölümleri geçici olarak iletişim kurmayı durdurabilir.
Bir dağıtık veritabanı koordinasyon sağlanamadığında ne yapacağını seçmelidir. Uygulama "çalışır durumda" kalması için istekleri servis etmeye devam mı etsin (sonuçlar biraz eski olabilir)? Yoksa replikaların anlaştığını doğrulayana kadar bazı işlemleri reddederek kullanılabilirlikten mi feragat etsin?
Bu durumlar yönlendirici hatalarında, aşırı yüklü ağlarda, kısmi dağıtımlarda, güvenlik duvarı hatalarında ve bölge-arası replikasyon gecikmelerinde ortaya çıkar.
CAP teoremi üç özelliğin aynı anda istenebilmesinin kısa yoludur:
Ana nokta "daima iki seç" değil. Asıl olan: bir ağ bölünmesi olduğunda tutarlılık ile kullanılabilirlik arasında seçim yapmanız gerekir. Web-ölçekli sistemlerde bölünmeler kaçınılmaz kabul edilir—özellikle çok bölgeli kurulumlarda.
Uygulamanız iki bölgede çalışıyor olsun. Bir fiber kesmesi veya yönlendirme sorunu eşitlemeyi engelliyor.
Farklı NoSQL sistemleri (ve hatta aynı sistemin farklı yapılandırmaları) hangi şeyin daha önemli olduğuna bağlı olarak farklı ödünler verir: kullanıcı deneyimi, doğruluk garantileri, işletme basitliği veya kurtarma davranışı.
Yatay ölçekleme (scale out), kapasiteyi daha büyük bir sunucu almak yerine daha fazla makine ekleyerek artırmak demektir. Birçok ekip için bu finansal ve operasyonel bir değişimdi: ucuz düğümler kademeli olarak eklenebiliyordu, hatalar bekleniyordu ve büyüme riskli "büyük kasa" geçişleri gerektirmiyordu.
Birçok düğümün işe yaraması için NoSQL sistemleri sharding'e (bölümlendirme) güvendi. Tek bir veritabanı her isteği ele almak yerine veri bölümlere ayrılır ve düğümler arasında dağıtılır.
Basit bir örnek: bir anahtara (ör. user_id) göre partitionlama:
Okumalar ve yazmalar yayılır, sıcak noktalar azalır ve düğüm ekledikçe throughput artar. Partition anahtarı bir tasarım kararıdır: sorgu desenleriyle uyumlu bir anahtar seçin, yoksa trafiğinizi tek bir shard'a yönlendirebilirsiniz.
Replikasyon aynı verinin birden çok kopyasını farklı düğümlerde tutmak demektir. Bu şunları iyileştirir:
Replikasyon, veriyi raflar veya bölgeler arasında yayarak yerel arızalardan kurtulmayı da mümkün kılar.
Sharding ve replikasyon sürekli operasyonel iş getirir. Veri büyüdükçe veya düğümler değiştikçe sistemin yeniden dengeleme yapması gerekir—partitionları taşırken çevrimiçi kalmak. Kötü yapılırsa yeniden dengeleme gecikme sıçramalarına, dengesiz yüke veya geçici kapasite eksikliğine yol açabilir.
Bu temel bir ödün: daha ucuz ölçek için daha fazla düğüm kullanmak, daha karmaşık dağıtım, izleme ve hata yönetimi gerektirir.
Veri dağıtıldığında, bir güncelleme eşzamanlı gerçekleştiğinde, ağ yavaşladığında veya düğümler iletişim kuramadığında "doğru"nun ne anlama geldiğini tanımlamak gerekir.
Strong tutarlılıkta, bir yazma onaylandıktan sonra her okuyucu hemen onu görmelidir. Bu birçok kişinin ilişkisel veritabanlarıyla ilişkilendirdiği "tek hakikat kaynağı" deneyimine uyar.
Zorluk koordinasyondur: düğümler arasında sıkı garanti sağlamak için çoklu mesajlaşma, yeterli yanıt bekleme ve uçta meydana gelen hatalarla başa çıkma gerekir. Düğümler ne kadar uzaktaysa veya o kadar meşgulse, her yazmada daha fazla gecikme girebilir.
Nihai tutarlılık bu garantiyi gevşetir: bir yazmadan sonra farklı düğümler kısa süre farklı cevaplar verebilir, ama sistem zamanla uyumlu hale gelir.
Örnekler:
Çoğu kullanıcı deneyimi için bu geçici uyuşmazlık kabul edilebilir—eğer sistem hızlı ve erişilebilir kalıyorsa.
İki replika neredeyse aynı anda güncelleme kabul ederse veritabanının bir birleştirme kuralı gerekir.
Yaygın yaklaşımlar:
Güçlü tutarlılık para transferleri, stok limitleri, benzersiz kullanıcı adları, izinler gibi bir an için iki gerçeklik olması gerçekten zararlı olabilecek işlemler için genellikle değerdir.
NoSQL, ölçek, gecikme ve veri şekli arasında farklı ödünler veren modellere sahip bir ailedir. "Aileyi" anlamak neyin hızlı, neyin acılı olacağını ve nedenini tahmin etmenize yardımcı olur.
Anahtar-değer veritabanları bir değeri benzersiz bir anahtarın arkasında saklar, dev bir dağıtık hashmap gibi. Erişim deseni genellikle "anahtara göre al"/"anahtara göre ayarla" olduğundan son derece hızlı ve yatay olarak ölçeklenebilir olurlar.
Özellikle lookup anahtarını bildiğiniz durumlar için iyidir (oturumlar, önbellekleme, özellik bayrakları), ama birden fazla alan üzerinde ad-hoc filtreleme genellikle amaç değildir.
Doküman veritabanları JSON-benzeri dokümanları (genellikle koleksiyonlar içinde) saklar. Her doküman biraz farklı yapıda olabilir; bu da ürünler evrildikçe şema esnekliği sağlar.
Bütün dokümanları okuma/yazma ve içindeki alanlara göre sorgulamaya optimize olurlar—katı tablolara zorlamadan. Ödün: ilişkileri modellemek karmaşıklaşabilir ve join desteği ilişkisel sistemler kadar zengin olmayabilir.
Bigtable'dan ilham alan geniş-sütun veritabanları, satır anahtarlarına göre organize olur ve her satır için değişken sayıda sütun tutabilir. Yüksek yazma oranlarında ve dağıtık depolamada güçlüdürler; zaman serileri, olaylar ve log iş yükleri için uygunlardır.
Erişim desenlerine göre dikkatli tasarımı ödüllendirirler: verimli sorgulama genellikle birincil anahtar ve kümeleme kurallarına dayanır, rastgele filtrelere değil.
Graf veritabanları ilişkileri birinci sınıf veri olarak ele alır. Tekrarlı joinler yerine düğümler arasındaki kenarları gezerek "bu şeyler nasıl bağlı?" sorgularını doğal ve hızlı yaparlar (dolandırıcılık ağları, öneriler, bağımlılık grafikleri).
İlişkisel veritabanları normalizasyonu teşvik eder: veriyi birden çok tabloya böl ve sorguda join ile birleştir. Birçok NoSQL sistemi ise veriyi en önemli erişim desenlerine göre tasarlamanızı söyler—bazen çoğaltma pahasına—böylece gecikme düğümler arasında öngörülebilir kalır.
Dağıtık veritabanında bir join, birden çok partition veya makineden veri çekmeyi gerektirebilir. Bu ağ atlamaları, koordinasyon ve öngörülemez gecikme ekler. Denormalizasyon (ilgili veriyi birlikte saklama) round-trip sayısını azaltır ve okumayı genellikle "yerel" tutar.
Pratik sonuç: orders kaydının içinde aynı müşteri adını saklayabilirsiniz; çünkü "son 20 siparişi göster" ana sorgudur ve tek hızlı okuma gerekir.
Birçok NoSQL veritabanı sınırlı join desteği sunar (veya hiç sunmaz), bu yüzden uygulama daha fazla sorumluluk alır:
Bu nedenle NoSQL modelleme genellikle "Hangi ekranları yüklemeliyiz?" ve "Hangi üst sorguların hızlı olması gerekiyor?" sorularıyla başlar.
İkincil indeksler yeni sorguları mümkün kılar ("e-postaya göre kullanıcı bul"), ama bedelsiz değildir. Dağıtık sistemlerde her yazma birden çok indeks yapısını güncelleyebilir; bu da:
NoSQL her açıdan "daha iyi" olduğu için benimsenmedi. Web-ölçeği baskısı altında ekipler ilişkisel veritabanlarının bazı kolaylıklarından feragat etmeye razı oldukları için NoSQL benimsendi: hız, ölçek ve esneklik karşılığında.
Tasarım gereği yatay ölçek. Birçok NoSQL sistemi, makineler eklemeyi pratik hale getirdi; sharding ve replikasyon temel yeteneklerdi.
Esnek şemalar. Doküman ve anahtar-değer sistemleri alan değişikliklerini katı tablo tanımlarından geçirmeden uygulamaların evrilmesine izin verdi.
Yüksek kullanılabilirlik desenleri. Düğümler ve bölgeler arası replikasyon hizmetleri donanım bakımı veya arızalar sırasında çalışır halde tutmayı kolaylaştırdı.
Veri çoğaltma ve denormalizasyon. Joinlerden kaçınmak genellikle veri çoğaltılması anlamına gelir; okuma performansını iyileştirir ama depolama maliyetini ve "her yerde güncelle" karmaşıklığını artırır.
Tutarlılık sürprizleri. Nihai tutarlılık çoğu zaman kabul edilebilir—ta ki kabul edilemez hale gelene kadar. Kullanıcılar güncel olmayan veriler görebilir; uygulama bu durumları tolere edecek veya çözümleyecek şekilde tasarlanmalıdır.
Analitiklerin zorlaşması (bazen). Bazı NoSQL depoları operasyonel okuma/yazma için mükemmeldir ama ad-hoc sorgular, raporlamalar veya karmaşık agregasyonlar SQL öncelikli sistemlere göre daha zahmetli olabilir.
Erken NoSQL benimsemeleri genellikle veritabanı özelliklerinden mühendislik disiplini yönüne kayma anlamına geldi: çoğaltmayı izleme, partition yönetimi, kompaksiyon çalıştırma, yedekleme/geri yükleme planlama ve hata senaryolarını yük testine tabi tutma. Yüksek operasyonel olgunluğa sahip ekipler en çok faydayı gördü.
Seçimi iş yükü gerçeklerine göre yapın: beklenen gecikme, zirve throughput, baskın sorgu desenleri, eski okumalara tolerans ve kurtarma gereksinimleri (RPO/RTO). "Doğru" NoSQL seçimi genellikle uygulamanızın nasıl hata yapacağını, nasıl ölçekleneceğini ve nasıl sorgulanması gerektiğini iyi eşleyen seçimdir—en etkileyici özellik listesine sahip olan değil.
NoSQL seçimi veritabanı markalarından veya heyecandan başlamamalı—uygulamanızın ne yapması gerektiği, nasıl büyüyeceği ve kullanıcılar için "doğru"nun ne anlama geldiği ile başlamalıdır.
Bir veri deposu seçmeden önce şunları yazın:
Erişim desenlerinizi net tarif edemiyorsanız, NoSQL ile modelleme genellikle erişim desenleri etrafında şekillendiği için herhangi bir seçim tahmine dayanacaktır.
Kısa bir filtre:
Pratik bir gösterge: eğer "temel doğruluk" (siparişler, ödemeler, envanter) her an doğru olmak zorundaysa, bunu SQL veya başka güçlü tutarlılık sağlayan bir depoda tutun. Yüksek hacimli içerik, oturumlar, önbellek, etkinlik akışları veya esnek kullanıcı verileri için NoSQL uygun olabilir.
Birçok ekip birden fazla mağazayla başarılı olur: örneğin işlemler için SQL, profiller/içerik için bir doküman veritabanı ve oturumlar için anahtar-değer deposu. Amaç karmaşıklık değil—her iş yükünü temizce ele alan aracı seçmektir.
Bu aynı zamanda geliştirici iş akışının önem kazandığı yerdir. Mimaride deney yapıyorsanız (SQL vs NoSQL vs hibrit), çalışan bir prototip (API, veri modeli ve UI) hızlıca ayağa kaldırabilmek karar riskini azaltabilir. Platformlar gibi Koder.ai ekiplerin bunu yapmasına yardımcı olur: sohbetten tam yığın uygulamalar üreterek genellikle bir React frontend ve Go + PostgreSQL backend sağlar, sonra kaynak kodunu dışa aktarmanıza izin verir. Daha sonra belirli iş yükleri için NoSQL ekleseniz bile, güçlü bir SQL “kayıt sistemi” ve hızlı prototipleme, anlık görüntüler ve rollback'ler deneyleri daha güvenli ve hızlı yapabilir.
Ne seçerseniz seçin, bunu doğrulayın:
Eğer bu senaryoları test edemiyorsanız, veritabanı kararınız teorik kalır—ve prodüksiyon sizin için testi yapar.
NoSQL iki yaygın baskıya yanıt verdi:
Bu, SQL’in “kötü” olduğu anlamına gelmiyordu; farklı iş yüklerinin farklı ödünler önceliklendirmesiydi.
Geleneksel “dikey ölçek”in sınırları vardır:
NoSQL sistemleri, kutuyu sürekli büyütmek yerine yatay ölçeklemeyi (düğüm ekleyerek) benimsedi.
İlişkisel şemalar kasıtlı olarak katıdır; bu stabilite için iyidir ama hızlı iterasyonlarda can sıkıcı olabilir. Büyük tablolarda “basit” bir değişiklik bile:
gibi maliyetler gerektirebilir. Doküman tarzı modeller, isteğe bağlı ve evrilen alanlara izin vererek bu sürtünmeyi azaltır.
Her zaman değil. Birçok SQL veritabanı yatay ölçeklenebilir, ama bu genellikle operasyonel olarak karmaşıktır (sharding stratejileri, shardlar arası joinler, dağıtık işlemler).
NoSQL sistemleri veri dağıtımını (parçalama + replikasyon) ilk sınıf hale getirerek belirli, öngörülebilir erişim desenleri için optimize eder.
Denormalizasyon, veriyi okunduğu şekle yakın tutup partitionlar arası pahalı joinlerden kaçınmak için veri tekrarını kabul eder.
Örnek: “son 20 sipariş” sorgusunu tek bir hızlı okuma yapmak için orders kaydının içinde müşteri adını saklamak.
Bunun bedeli ise güncelleme karmaşıklığıdır: çoğaltılan veriyi tutarlı halde tutmak uygulama mantığı veya boru hatları gerektirir.
Bölüntü (partition) sırasında veritabanı ne yapacağını seçmelidir:
CAP, bir bölünme olduğunda hem tam tutarlılık hem de tam kullanılabilirlik garanti edilemeyeceğini hatırlatır.
Güçlü tutarlılık: bir yazma onaylandıktan sonra tüm okuyucular hemen bunu görür; genellikle düğümler arası koordinasyon gerektirir.
Nihai (eventual) tutarlılık: yazmadan sonra replikalar kısa süre farklı cevaplar döndürebilir, ama zamanla veri uyumlu hale gelir. Bu, yüksek kullanılabilirlik ve hız için kabul edilebilir bir ödün olabilir—eğer uygulama kısa süreli eskiliği tolere edebiliyorsa.
Çatırtı, farklı replikaların eşzamanlı güncellemeleri kabul ettiği durumlarda olur. Yaygın stratejiler:
Seçim, ara güncellemelerin kaybolmasının kabul edilebilir olup olmadığına bağlıdır.
Kısa bir uyum rehberi:
Dominant erişim deseninize göre seçin, popülerliğe göre değil.
Öncelikle gereksinimlerle başlayın ve bunları testlerle doğrulayın:
Birçok gerçek sistem hibrittir: işlemler için SQL, yüksek hacimli içerik ve profiller için NoSQL gibi karışık yaklaşımlar başarılı olur.