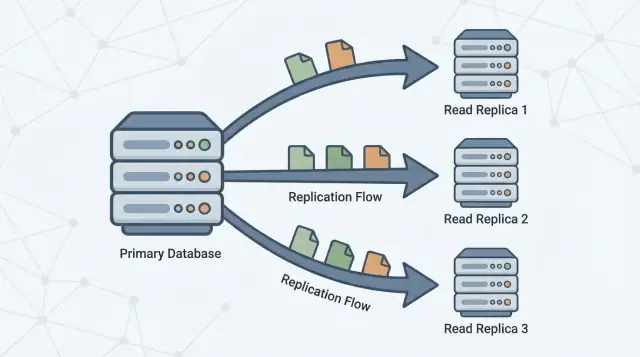
Okuma Replikası Nedir (ve Ne Değildir)
Bir okuma replikası, ana veritabanınızın (genellikle birincil diye anılan) bir kopyasıdır ve ondan gelen değişiklikleri sürekli alarak güncel kalır. Uygulamanız, replikalara sadece okuma sorguları (ör. SELECT) gönderebilir; birincil ise tüm yazmaları (ör. INSERT, UPDATE, DELETE) işlemeye devam eder.
Temel vaat
Vaat basit: birincile ek yük bindirmeden daha fazla okuma kapasitesi.
Uygulamanız çok sayıda “getirme” trafiğine sahipse—ana sayfalar, ürün sayfaları, kullanıcı profilleri, panolar—bu okumalardan bir kısmını bir veya daha fazla replika üzerine taşımak birincilin yazma işine odaklanmasını sağlar. Birçok durumda bu, uygulamada az değişiklikle yapılabilir: bir veritabanını gerçeğin kaynağı olarak tutarsınız ve sorgulanacak ek yerler olarak replikalar eklersiniz.
Okuma replikası ne değildir
Replikalar faydalıdır ama sihirli bir performans düğmesi değildir. Replikalar şunları yapmaz:
- Yazma kapasitesini artırmaz. Tüm yazmalar hâlâ birincile gider.
- Yavaş sorguları düzeltmez. Bir sorgu verimsizse (eksik indeksler, büyük tablo taramaları, kötü join desenleri), replika üzerinde de muhtemelen yavaş çalışır—sadece yük farklı bir yerde olur.
- İyi şema ve veri tasarımının yerini almaz. Replikalar hot-spot’ları, aşırı büyük satırları veya “her şey tablosu” sorununu çözmez.
- İzleme ihtiyacını ortadan kaldırmaz. Replikalar ek hareketli parçalar katar: lag, bağlantı limitleri ve failover davranışı.
Bu rehber için beklentileri ayarlama
Replikaları bir okuma ölçeklendirme aracı olarak düşünün; her çözüm gibi ödünler vardır. Bu makalenin geri kalanı, ne zaman gerçekten yardımcı olduklarını, sıkça nasıl ters tepebileceklerini ve replikasyon gecikmesi ile nihai tutarlılık gibi kavramların bir kopyadan okumaya başladığınızda kullanıcıların ne göreceğini nasıl etkilediğini açıklıyor.
Okuma Replikalarının Var Olma Nedeni
Tek bir birincil veritabanı sunucusu genellikle başlangıçta “yeterince büyük” görünür. Yazmaları (insert, update, delete) işler ve uygulamanız, panolarınız ve iç araçlarınızdan gelen her okuma isteğine (SELECT) cevap verir.
Kullanım arttıkça, okumalar genellikle yazmalardan daha hızlı çoğalır: her sayfa görüntüleme birden çok sorgu tetikleyebilir, arama ekranları birçok arama yapabilir ve analitik tarzı sorgular çok sayıda satırı tarayabilir. Yazma hacminiz ılımlı olsa bile, birincil yine de iki işi aynı anda yapmak zorunda kaldığı için darboğaz olabilir: değişiklikleri güvenli ve hızlı kabul etmek ve artan okuma trafiğini düşük gecikmeyle karşılamak.
Okumaları yazmalardan ayırmak
Okuma replikaları bu iş yükünü bölmek için vardır. Birincil yazmaları işlemeye ve “gerçeğin kaynağı” olmaya odaklanırken, bir veya daha fazla replika yalnızca okuma sorgularını işler. Uygulamanız bazı sorguları replikalara yönlendirebildiğinde birincilin CPU, bellek ve I/O baskısını azaltırsınız. Bu genellikle genel yanıt verme süresini iyileştirir ve yazma ani yükleri için daha fazla boşluk bırakır.
Replikasyonu bir cümleyle özetlemek
Replikasyon, replikaların birincilden değişiklikleri kopyalayarak güncel kalmasını sağlayan mekanizmadır. Birincil değişiklikleri kaydeder ve replikalar bu değişiklikleri uygular, böylece neredeyse aynı veriyle sorgulara cevap verebilirler.
Bu desen birçok veritabanı sistemi ve yönetilen hizmette yaygındır (ör. PostgreSQL, MySQL ve bulut varyantları). Uygulama farklılıkları olsa da amaç aynıdır: birincili sonsuza dek dikey ölçeklemeye zorlamadan okuma kapasitesini artırmak.
Replikasyon Nasıl Çalışır (Basit Zihinsel Model)
Birincil veritabanını “gerçeklik kaynağı” olarak düşünün. O her yazmayı kabul eder—sipariş oluşturma, profilleri güncelleme, ödemeleri kaydetme—ve bu değişikliklere kesin bir sıra atar.
Bir veya daha fazla okuma replika daha sonra birincili takip eder, bu değişiklikleri kopyalar ve böylece sorgulara (ör. “sipariş geçmişimi göster”) ek yük bindirmeden cevap verebilirler.
Temel akış
- Birincil yazmaları kabul eder ve bunları kalıcı bir günlükte kaydeder (veritabanına göre isim değişir).
- Replikalar bu günlük girdilerini akışla alır veya getirir.
- Replikalar aynı değişiklikleri aynı sırada tekrarlar, kademeli olarak yakalar.
Okumalar replikalardan sunulabilir, ancak yazmalar hâlâ birincile gider.
Senkron vs asenkron replikasyon (yüksek seviyede)
Replikasyon iki geniş modda olabilir:
- Senkron: Birincil, yazmanın “commit” sayılması için bir replikadan (veya bir çoğunluktan) onay bekler. Bu eski okumaları azaltır ama yazma gecikmesini artırabilir ve replikaya/ağa duyarlılığı yükseltebilir.
- Asenkron: Birincil yazmayı hemen commit eder, replikalar daha sonra yakalar. Bu yazmaları hızlı ve dayanıklı tutar, ama replikalar geçici olarak geride kalabilir.
Replikasyon gecikmesi ve “nihai tutarlılık”
Bu gecikme—replikaların birincilin gerisinde kalması—replikasyon gecikmesi olarak adlandırılır. Bu otomatik olarak bir hata değildir; okumaları ölçeklendirmek için kabul ettiğiniz normal bir ödün olabilir.
Kullanıcılar için gecikme, nihai tutarlılık olarak görülür: bir şeyi değiştirdikten sonra sistem her yerde tutarlı hale gelir, ama hemen olmayabilir.
Örnek: e-posta adresinizi güncellersiniz ve profil sayfanızı yenilersiniz. Sayfa bir replikadan servis ediliyorsa ve replikada birkaç saniye gecikme varsa, kısa süreliğine eski e-posta görünebilir—ta ki replika güncellemeyi uygulayıp “yetişene” kadar.
Okuma Replikaları Ne Zaman Gerçekten Yardımcı Olur
Okuma replikaları, birincil veritabanınız yazmalar için sağlıklı ama okuma trafiğini karşılamakta zorlandığında yardımcı olur. Yazma şeklinizi değiştirmeden anlamlı miktarda SELECT yükünü devredebildiğinizde en etkili olurlar.
Okuma-bağlı olduğunuzun işaretleri
Aşağıdaki kalıplara bakın:
- Trafik zirvelerinde birincilin CPU’sunun yüksek olması, yazma veriminin olağanüstü yüksek olmaması
SELECT sorgularının INSERT/UPDATE/DELETE’e göre çok yüksek oranı- Okuma sorgularının zirvelerde yavaşlaması, oysa yazmalar stabil kalması
- Ürün sayfaları, akışlar, arama sonuçları gibi okuma-ağırlıklı uç noktaların bağlantı havuzu doygunluğu
Okumaların sorun olduğunu doğrulamak için metrikler
Replikaları eklemeden önce şunlarla doğrulayın:
- CPU vs I/O: Okuma gecikmesi yükseldiğinde birincilin CPU’su doluyor mu? Yoksa disk okuma I/O’su mu dar boğaz?
- Sorgu karışımı: Yavaş sorgu günlükleri/APM’den geçirilen sürenin ne kadarı
SELECT içinde?
- p95/p99 okuma gecikmesi: Okuma uç noktalarını ve veritabanı sorgu gecikmesini ayrı ayrı takip edin.
- Buffer/cache hit oranı: Düşük bir hit oranı okumaların diske gitmesine neden olabilir.
- Top sorgular (toplam süreye göre): Bir pahalı sorgu “okuma yükü”nü domine ediyor olabilir.
Daha ucuz çözümleri atlamayın
Çoğu zaman ilk hamle tuning olmalıdır: doğru indeks eklemek, bir sorguyu yeniden yazmak, N+1 çağrılarını azaltmak veya sıcak okumaları önbelleğe almak. Bu değişiklikler replikalar işletmekten daha hızlı ve daha ucuz olabilir.
Hızlı kontrol listesi: replikalar mı yoksa tuning mi
Replikaları seçin eğer:
- Yükün çoğu okuma trafiğiysa ve okumalar zaten makul düzeyde optimize edilmişse
- Offload ettiğiniz sorgular için ara sıra eski veriyi tolere edebilirsiniz
- Şema/sorgu değişiklikleri yapmadan hızlıca ek kapasiteye ihtiyacınız varsa
Önce tuning seçin eğer:
- Birkaç sorgu toplam okuma süresini domine ediyorsa
- Eksik indeksler veya verimsiz join’ler açıkça ortadaysa
- Düşük trafikte bile okumalar yavaşsa (sorgu tasarım sorunu işareti)
En Uygun Kullanım Senaryoları
Okuma replikaları, birincil veritabanınız yazma işleriyle meşgulken (checkout’lar, kayıtlar, güncellemeler) ama trafiğin büyük bir kısmı okuma-ağırlıklı olduğunda en çok değer katar. Birincil–replica mimarisinde doğru sorguları replikalara yönlendirmek, uygulama özelliklerini değiştirmeden veritabanı performansını iyileştirir.
1) İşlemleri yavaşlatmaması gereken panolar ve analitik
Panolar genellikle uzun sorgular çalıştırır: gruplama, geniş tarih aralıkları üzerinde filtreleme veya çoklu tablo join’leri. Bu sorgular işlem işiyle CPU, bellek ve cache için yarışabilir.
Bir replikayı iyi bir yer olarak kullanabilirsiniz:
- İç raporlama iş yükleri
- Yönetici panoları
- “Günlük/haftalık metrik” görünümleri
Böylece birincil hızlı, öngörülebilir transaction’lara odaklanırken analitik okumalar bağımsız olarak ölçeklenir.
2) Ağır okuma hacmi olan arama ve gezinti sayfaları
Katalog gezintisi, kullanıcı profilleri ve içerik akışları benzer okuma sorgularının yüksek hacimlerini üretebilir. Okuma ölçeklendirme baskısı darboğaz olduğunda replikalar trafiği emebilir ve gecikme zirvelerini azaltabilir.
Bu, özellikle okumaların cache-miss ağırlıklı olduğu (çok sayıda benzersiz sorgu) veya yalnızca uygulama önbelleğine güvenilemediği durumlarda etkilidir.
3) Büyük veri tarayan arka plan işleri
Dışa aktarmalar, backfill’ler, özet yeniden hesaplamalar ve “X ile eşleşen her kaydı bul” işler birincili zorlayabilir. Bu taramaların replikada çalıştırılması genellikle daha güvenlidir.
Ancak job’un nihai tutarlılığı tolere etmesi gerektiğini unutmayın: replikasyon gecikmesi yüzünden en yeni güncellemeleri görmeyebilir.
4) Düşük gecikme için çok bölgeli okumalar (eskime riskiyle)
Küresel kullanıcı kitleniz varsa, replikaları onlara yakın bölgelere koymak round-trip süresini azaltır. Takas, lag veya ağ sorunları sırasında eski okumaya daha fazla maruz kalmaktır, bu yüzden yalnızca “neredeyse güncel” olmasının kabul edilebilir olduğu sayfalar (gezinti, öneriler, herkese açık içerik) için uygundur.
Replikaların Ters Tepmesi (Backfire Olması)
Go ve Postgres ile Başlayın
Go + PostgreSQL tabanlı bir backend üretin ve okuma/yazma yollarını erkenden şekillendirin.
Replikalar “yeterince yakın” iyi olduğunda harikadır. Ürününüz her okumanın en güncel yazmayı yansıttığını varsayıyorsa replikalar ters tepebilir.
Klasik belirti: “Az önce güncelledim, neden değişmedi?”
Kullanıcı profilini düzenler, bir form gönderir veya hesap ayarlarını değiştirir—ve bir sonraki sayfa yüklemesi replikadan geliyorsa birkaç saniye eski veri görebilir. Güncelleme başarılı olmuştur ama kullanıcı eski veriyi görür, yeniden dener, çift gönderim yapar veya güvenini kaybeder.
Bu, e-posta adresi değiştirme, tercihi açma/kapama, belge yükleme veya yorum gönderip geri yönlendirme gibi anında onay beklenen akışlarda özellikle can sıkıcıdır.
“Güncel olmalı” ekranları (burada kumar oynamayın)
Bazı okumalar kısa süre bile olsa eski olmayı tolere edemez:
- Sepetler ve ödeme toplamları
- Cüzdan bakiyeleri, sadakat puanları, stok sayımı
- “Ödemem geçti mi?” durum ekranları
Bir replika gerideyse yanlış sepet toplamı gösterebilir, stok fazlası satılmasına neden olabilir veya yanlış bakiye gösterebilir. Sistem daha sonra kendini düzeltebilse bile kullanıcı deneyimi (ve destek hacmi) zarar görür.
Yönetici ve operasyon araçları en güncel gerçeği gerektirir
İç panolar genellikle gerçek kararlar alır: fraud incelemesi, müşteri desteği, sipariş karşılama, moderasyon ve olay müdahalesi. Bir yönetici aracı replikalardan okuma yapıyorsa, tamamlanmamış verilere göre hareket etme riski vardır—ör. zaten iade edilmiş bir siparişi geri ödeyebilir veya son durumu kaçırabilirsiniz.
Pratik düzeltme: “yazdığını kendin oku” için birincile yönlendirme
Yaygın bir desen şartlı yönlendirmedir:
- Kullanıcı yazma yaptıktan sonra, sonraki “onay” okumalarını kısa bir pencere için birincile yönlendirin (saniyeler–dakikalar).
- Arka plan, anonim veya kritik olmayan okumalar replikalarda kalsın.
Bu, replikaların faydalarını korurken tutarlılığı tahmin oyununa çevirmeyi önler.
Replikasyon Gecikmesini ve Eski Okumaları Anlamak
Replikasyon gecikmesi, bir yazmanın birincilde commit edilmesi ile aynı değişikliğin replikada görünmesi arasındaki gecikmedir. Uygulamanız bu süre boyunca replikadan okuma yaparsa “eski” sonuçlar dönebilir—kısa süre önce doğru olan ama artık geçerli olmayan veriler.
Neden gecikme olur
Lag normaldir ve genellikle stres altında büyür. Yaygın nedenler:
- Birincildeki yük patlamaları: çok fazla yazma daha fazla değişiklik gönderilmesi ve uygulanması demek.
- Replika yetersiz veya meşgul: replika gelen değişiklikleri uygulayacak kadar hızlı değildir (CPU, disk I/O).
- Ağ gecikmesi veya değişkenlik: replikasyon akışının taşınmasında gecikme.
- Büyük işlemler / toplu güncellemeler: tek bir büyük değişiklik seri hale getirme, transfer ve replay gerektirir.
Eski okumalar ürün davranışında nasıl görünür
Lag sadece tazelikten etkilemez—kullanıcı açısından doğruluk da etkilenir:
- Kullanıcı profilini günceller, sonra yeniler ve eski değeri görür.
- “Okunmamış mesajlar” veya bildirim sayaçları biraz eski verilere dayanarak sapma gösterir.
- Yönetici/raporlama ekranları en son siparişleri, iadeleri veya durum değişikliklerini kaçırır.
Pratik yaklaşımlar
Özelliğinizin ne kadar esnek olduğunu kararlaştırın:
- Tolerans penceresi ekleyin: “Veriler 30 saniyeye kadar eski olabilir” birçok pano için kabul edilebilir.
- Okuma sonrası-yazma’yı (read-after-write) birincile yönlendirin: bir kullanıcı bir şeyi değiştirdikten sonra, o varlığı kısa süreliğine birincilden okuyun.
- UI mesajları: beklentiyi ayarlayın (“Güncelleniyor…”, “Görünmesi birkaç saniye alabilir”).
- Tekrar deneme mantığı: kritik bir okuma yeni yazılmış kaydı kaçırıyorsa primary’e karşı yeniden deneyin veya kısa bir gecikme sonrası tekrar deneyin.
Neleri izlemeli ve uyarı vermeli
Replika lag’ını (saniye/byte), replika apply oranını, replikasyon hatalarını ve replika CPU/disk I/O’sunu izleyin. Lag kabul edilebilir eşiğinizi aştığında (ör. 5s, 30s, 2m) ve lag zaman içinde artmaya devam ediyorsa (replikanın yakalanamayacağının işareti) uyarı verin.
Okuma Ölçeklendirme vs Yazma Ölçeklendirme (Temel Ödünler)
Değişiklikleri Güvenle Yapın
Replikasyon takaslarını çalışırken test ederken migrasyonları ve geri alımları güvenle test edin.
Okuma replikaları, okuma ölçeklendirme aracıdır: SELECT sorgularını sunmak için daha fazla yer ekler. Yazma ölçeklendirme aracı değildir: sisteminizin kaç INSERT/UPDATE/DELETE kabul edebileceğini artırmazlar.
Okumaları ölçeklendirme: replikaların iyi olduğu noktalar
Replikalar eklendiğinde, okuma kapasitesi eklersiniz. Uygulamanız okuma-ağırlıklı uç noktalarda (ürün sayfaları, beslemeler, lookuplar) darboğazdaysa bu sorguları birden çok makineye yayabilirsiniz.
Bu genellikle şunları iyileştirir:
- Yük altındaki sorgu gecikmesi (birincil üzerindeki rekabet azalır)
- Okumalar için throughput (SELECT’ler için daha fazla CPU/bellek/I/O)
- Raporlama gibi ağır okumaların izole edilmesi, böylece transaction trafiğine müdahale etmemesi
Yazmaları ölçeklendirme: replikaların yapmadıkları
Yaygın yanlış anlaşılma: “daha fazla replikalar = daha fazla yazma throughput’u.” Tipik primary-replica kurulumunda tüm yazmalar hâlâ primary’e gider. Hatta daha fazla replika birincil için biraz daha iş yaratabilir, çünkü birincilin her replika için replikasyon verisi üretip göndermesi gerekir.
Eğer sorununuz yazma throughput’uysa, replikalar bunu çözmez. Genellikle farklı yaklaşımlar gerekir (sorgu/indeks tuning, batching, partitioning/sharding veya veri modelini değiştirme).
Bağlantı limitleri ve havuzlama: gizli darboğaz
Replikalar size daha fazla okuma CPU’su sağlasa bile, hâlâ bağlantı limitlerine takılabilirsiniz. Her veritabanı düğümünün eşzamanlı bağlantı sınırı vardır ve replikalar eklemek uygulamanızın bağlanabileceği yer sayısını çoğaltır—toplam talebi azaltmadan.
Pratik kural: bağlantı havuzu veya bir pooler kullanın ve servis başına bağlantı sayılarınızı kasıtlı tutun. Aksi halde replikalar sadece “yüklenebilecek daha fazla veritabanı” haline gelebilir.
Maliyet ödünleri: kapasite ücretsiz değil
Replikalar gerçek maliyetler ekler:
- Daha fazla düğüm (compute maliyeti)
- Daha fazla depolama (her replika genellikle tam bir kopya saklar)
- Daha fazla operasyonel iş (lag izleme, yedek/geri yük stratejisi, şema değişiklikleri, olay müdahalesi)
Ödün basit: replikalar size okuma başlığı ve izolasyon alabilir ama karmaşıklık katar ve yazma sınırını yukarı çekmez.
Yüksek Erişilebilirlik ve Failover: Replikalar Ne Yapabilir
Read replikalar okuma erişilebilirliğini iyileştirebilir: birincil aşırı yüklendiğinde veya kısa süre erişilemez olduğunda, bazı okuma trafiğini replikalardan sunmaya devam edebilirsiniz. Bu, müşteri tarafı sayfalarını (hafifçe eski verinin kabul edilebilir olduğu içerik için) yanıtlı tutar ve birincil olaylarının etki alanını küçültür.
Ancak replikalar tek başına tam bir yüksek erişilebilirlik planı sağlamaz. Bir replika genellikle otomatik olarak yazmaya hazır değildir ve “okunabilir bir kopya var” demek, “sistem güvenli ve hızlı şekilde yazmayı yeniden kabul edebilir” demekle aynı değildir.
Failover genellikle şu adımları içerir: birincil başarısızlığı tespit et → bir replika seç → onu yeni birincil olarak terfi ettir → yazmaları (ve genellikle okumaları) yeni düğüme yönlendir.
Bazı yönetilen veritabanları bu sürecin çoğunu otomatikleştirir, ama temel fikir değişmez: kim yazma kabul edebilecek değişir.
Planlanması gereken ana riskler
- Eski replika verisi: replika geride olabilir. Terfi ederseniz, henüz replike edilmemiş en son yazmaları kaybedebilirsiniz.
- Split-brain önleme: aynı anda iki düğümün yazma kabul etmesini engellemelisiniz. Bu nedenle terfiler genellikle tek bir yetki (yönetilen kontrol paneli, çoğunluk sistemi veya sıkı operasyon prosedürleri) tarafından yönetilir.
- Yönlendirme ve cache’ler: uygulamanızın hedef değiştirmesi için güvenilir bir yolu olmalı—bağlantı dizeleri, DNS, proxy’ler veya bir veritabanı yönlendiricisi. Yazma trafiğinin yanlışlıkla eski birincile gitmediğinden emin olun.
Bunu bir özellik gibi test edin
Failover’ı uygulamalı olarak çalıştırın. Staging’de (ve üretimde düşük riskli pencerelerde dikkatli) game-day testleri yapın: birincil kaybını simüle edin, kurtarma süresini ölçün, yönlendirmeyi doğrulayın ve uygulamanızın salt-okuma dönemlerini ve yeniden bağlanmaları düzgün yönettiğinden emin olun.
Pratik Yönlendirme Desenleri (Okuma/Yazma Ayırma)
Read replikalar ancak trafiğiniz gerçekten onlara ulaştığında yardımcı olur. “Okuma/yazma ayırma”, yazmaları birincile ve uygun okumaları replikalara gönderme kurallarını kapsar—doğruluğu bozmadan.
Desen 1: Uygulama içinde bölme
En basit yaklaşım veri erişim katmanında açık yönlendirmedir:
- Tüm yazmalar (
INSERT/UPDATE/DELETE, şema değişiklikleri) birincile gider.
- Yalnızca seçilmiş okumalar replika kullanabilir.
Bu, gerekçelendirmesi kolay ve geri alması basittir. Ayrıca “checkout sonrası, bir süre sipariş durumunu birincilden oku” gibi iş kurallarını buraya kodlayabilirsiniz.
Desen 2: Proxy veya sürücü aracılığıyla bölme
Bazı ekipler, birincil vs replika uç noktalarını anlayan ve sorgu tipine veya bağlantı ayarlarına göre yönlendiren bir veritabanı proxy’sı veya akıllı sürücü tercih eder. Bu, uygulama kodunda değişiklik gerektirmez ama dikkat: proxy’ler ürün açısından hangi okumaların “güvenli” olduğunu her zaman bilemez.
Hangi sorguların güvenle replikalara gidebileceğini seçmek
İyi adaylar:
- Analitik, raporlama iş yükleri, panolar
- Biraz eski veri kabul edilebilen arama/gezinti sayfaları
- Yeniden deneyebilen ve en yeni değere ihtiyaç duymayan arka plan işleri
Kullanıcının hemen ardından gelen okumaları (ör. “profili güncelle → profili tekrar yükle”) replikalara yönlendirmekten kaçının; eğer bir tutarlılık stratejisi yoksa.
Transaction’lar ve oturum tutarlılığı
Bir transaction içinde, tüm okumaları birincilde tutun.
Transaction dışındaysa, “okuduğunu yazdığını görme” oturumlarını düşünün: yazmadan sonra kullanıcı/oturum kısa bir TTL için birincile sabitlenebilir veya belirli takip sorguları birincile yönlendirilebilir.
Küçük başlayın ve ölçün
Bir replika ekleyin, sınırlı sayıda uç nokta/sorgu yönlendirin ve karşılaştırın:
- Birincil CPU ve okuma IOPS
- Replika kullanımı
- Hata oranı ve gecikme yüzdelikleri
- Eski okumalardan kaynaklanan olaylar
Etkisi net ve güvenliyse yönlendirmeyi genişletin.
İzleme ve Operasyon Temelleri
Hızla Dağıtın ve Yineleyin
Uygulamanızı barındırma ve dağıtımla yayınlayın, trafiğiniz arttıkça yineleyin.
Read replikalar “kur ve unut” değildir. Onlar kendi performans limitleri, başarısızlık modları ve operasyonel görevleri olan ek veritabanı sunucularıdır. Biraz izleme disiplinı genellikle “replikalar işe yaradı” ile “replikalar karışıklık kattı” arasındaki farktır.
İzlemeniz gerekenler (önemli birkaç metrik)
Kullanıcı tarafı semptomlarını açıklayan göstergeye odaklanın:
- Replika gecikmesi: bir replikanın birincilin ne kadar gerisinde olduğu (saniye, byte veya WAL/LSN pozisyonu). Bu, eski okumalar için erken uyarıdır.
- Replikasyon hataları: bağlantı kopmaları, yetki hataları, disk dolu veya replication slot sorunları. Bunları gürültü değil olay olarak ele alın.
- Sorgu gecikmesi (p50/p95) replika vs birincil: replikalar birincil iyi olsa bile yavaş olabilir (farklı cache durumu, farklı donanım, uzun raporlar).
- Cache hit oranı: yeniden başlatma veya trafik kayması sonrası replika sürekli miss yapıyorsa gecikme artabilir.
Kapasite planlama: kaç replika gerekir?
Hedefiniz okuma offload’uysa bir replika ile başlayın. Bir constraint olduğunda daha fazlasını ekleyin:
- Okuma throughput’u: bir replika zirai QPS veya ağır analitik sorgularla baş edemez.
- İzolasyon: raporlama işleri için bir replika ayırın ki panolar kullanıcı trafiğini çalmasın.
- Coğrafya: her bölge için bir replika okuma gecikmesini azaltır ama operasyonel yükü artırır.
Pratik kural: replikaları sadece okumaların darboğaz olduğunu doğruladıktan sonra ölçeklendirin (indeksler, yavaş sorgular veya uygulama önbelleklemesi değilse).
Yaygın operasyon görevleri
- Yedekler: yedeklerin nerede alınacağına karar verin. Replikadan yedek almak birincilin yükünü azaltabilir, ama tutarlılık gereksinimlerini ve replikanın sağlıklı olduğunu doğrulayın.
- Şema değişiklikleri: replikasyonu göz önünde bulundurarak migrasyonları test edin (uzun süren DDL lag artırabilir). Uygulama ve şema değişikliklerinin propagasyon sırasında uyumlu olmasını koordine edin.
- Bakım pencereleri: replikaları yamalamak veya yeniden başlatmak geçici olarak okuma kapasitesini azaltır. Rotasyon planlayın ki gereken okuma başlığı altına düşmeyin.
Sorun giderme kontrol listesi: “replikalar yavaş”
- Replika gecikmesini kontrol edin: yüksekse kullanıcılar yeniden deneyebilir veya eski veri görebilir.
- Replika vs birincil yavaş sorgu günlüklerini karşılaştırın: raporlama sorguları genellikle burada görünür.
- Replika hostunda CPU, bellek, disk I/O ve ağ durumunu doğrulayın.
- Replication’ı geciktiren birincilde kilit contention veya uzun transaction’lar var mı bakın.
- Okuma yönlendirmenizin tek bir replikayı aşırı yüklemediğini kontrol edin (düzgün yük dengeleme).
- Replikalarda indekslerin var olduğunu ve istatistiklerin güncel olduğunu doğrulayın (replikalar birincili yansıtmalıdır).
Alternatifler ve Basit Karar Çerçevesi
Read replikalar okuma ölçeklendirme için bir araçtır, fakat genellikle çekilecek ilk kaldıraç değildir. Operasyonel karmaşıklık eklemeden önce daha basit bir düzeltme aynı sonucu veriyor mu kontrol edin.
İlk denenecek alternatifler
Önbellekleme veritabanından tüm okumaları kaldırabilir. “Çoğunlukla okunan” sayfalar (ürün detayları, herkese açık profiller, konfigürasyon) için uygulama önbelleği veya CDN trafiği dramatik şekilde azaltabilir—replikasyon gecikmesi getirmez.
İndeksler ve sorgu optimizasyonu çoğu durumda replikalara göre daha büyük kazanım sağlar: birkaç pahalı sorgunun CPU yakması söz konusuysa doğru indeksi eklemek, SELECT sütunlarını azaltmak, N+1 sorunlarını çözmek ve kötü join’leri düzeltmek çoğu problemi çözer.
Materialized view / ön-aynılaştırma iş yükü doğası gereği ağırsa (analitik, panolar) yardımcı olur. Karmaşık sorguları yeniden çalıştırmak yerine hesaplanmış sonuçları saklayıp belirli aralıklarla yenileyebilirsiniz.
Sharding/partitioning’i ne zaman düşünmeli
Eğer yazmalar darboğaz yapıyorsa (hot-row’lar, kilit contention, yazma IOPS limitleri), replikalar pek yardımcı olmaz. Bu durumda tabloları zamana/tenant’a göre partition’lamak veya müşteri ID’sine göre sharding yapmak yazma yükünü yayar. Bu daha büyük bir mimari adımdır ama gerçek sınırlamayı çözer.
Basit karar çerçevesi
Dört soru sorun:
- Hedef ne? Okuma gecikmesini azaltmak, raporlama iş yüklerini offload etmek veya yüksek erişilebilirlik mi?
- Okumalar ne kadar taze olmalı? Eski okumayı tolere edemiyorsanız replikalar kullanıcıya görünür sorunlar çıkarabilir.
- Bütçeniz ne kadar? Replikalar altyapı maliyeti ve sürekli izleme/operasyon gideri getirir.
- Ne kadar karmaşıklık kaldırabilirsiniz? Okuma/yazma ayırma, nihai tutarlılıkla başa çıkma ve failover testi zahmetlidir.
Yeni bir ürün prototipleiyorsanız veya bir servisi hızlı başlatıyorsanız, bu kısıtları baştan mimariye dahil etmek yardımcı olur. Örneğin Koder.ai üzerinde geliştiren ekipler genellikle basitlik için tek bir birincil ile başlar, sonra panolar, akışlar veya dahili raporlama işlem trafiği transaction trafiğiyle yarışmaya başlayınca replikalara geçerler. Plan odaklı bir iş akışı hangi uç noktaların nihai tutarlılık gerektirip hangilerinin birincile “okuma-yazma”ya ihtiyaç duyduğunu önceden belirlemeyi kolaylaştırır.
Eğer hangi yolu seçeceğiniz konusunda yardıma ihtiyacınız varsa, seçenekler için /pricing sayfasına bakın veya ilgili rehberleri /blog üzerinde göz atın.