Olay Etkisini Tanımlayın ve Hangi Kararları Etkilemesi Gerektiğine Karar Verin
Hesaplamaları veya panoları inşa etmeden önce, organizasyonunuzda “etki”nin gerçekte ne anlama geldiğine karar verin. Bu adımı atlarsanız, bilimsel görünen ama kimseye yardımcı olmayan bir puanla sonuçlanırsınız.
Neler “etki” sayılır (ve neler sayılmaz)
Etki, bir olayın iş için önemli bir şey üzerindeki ölçülebilir sonucudur. Yaygın boyutlar şunlardır:
- Kullanıcılar: giriş yapamayan kullanıcı sayısı, kritik akışlarda hata oranı sıçramaları, bir bölge için kötüleşmiş gecikme.
- Gelir: ödeme işlemlerinin başarısız olması, abonelik yenilemelerinin engellenmesi, reklam gösterimlerinde düşüş.
- SLA/SLO riski: erişilebilirlik hedefine karşı geçen kesinti dakikaları, hata bütçesi tüketimi.
- İç ekipler: destek talebi hacmi, nöbet yükü, engellenmiş dağıtımlar.
2–4 ana boyut seçin ve bunları açıkça tanımlayın. Örneğin: “Etki = etkilenen ücretli müşteriler + risk altındaki SLA dakikaları,” değil “Etki = grafiklerde kötü görünen her şey.”
Uygulamayı kim kullanır ve ilk 10 dakikada neye ihtiyaçları var
Farklı roller farklı kararlar alır:
- Olay komutanları hızlı, savunulabilir bir özet ister: ne kırıldı, kim etkilendi ve eğilimler ne yönde.
- Destek müşteri odaklı kapsam ister: hangi hesaplar, bölgeler veya planlar etkilendi.
- Mühendislik hata bölgesine dair bir hipotez ister; bu debug ve azaltma için yol gösterir.
- Yöneticiler kısa bir iş bildirimi ister: şiddet, müşteri etkisi ve ETA güveni.
“Etki” çıktıları, her kitlenin metrikleri çevirmeden en önemli sorusunu yanıtlayacak şekilde tasarlayın.
Gerçek zamanlı mı yoksa yakın-gerçek-zamanlı mı: beklentileri erken belirleyin
Hangi gecikmenin kabul edilebilir olduğuna karar verin. “Gerçek zamanlı” pahalıdır ve genellikle gerekli değildir; yakın-gerçek-zamanlı (ör. 1–5 dakika) karar verme için çoğu zaman yeterlidir.
Bunu bir ürün gereksinimi olarak yazın; çünkü alım, önbellekleme ve UI üzerinde etkisi olur.
Uygulamanın bir olay sırasında hangi kararları almasını sağlamalı
MVP'niz doğrudan şu tür eylemleri desteklemelidir:
- Şiddeti ve taşınma seviyesini ilan etmek
- Müşteri iletişimlerini tetiklemek (status page, destek makroları)
- Azaltma çalışmasını önceliklendirmek (hangi servis/ekip önce)
- Geri almalar, özellik bayrakları veya trafik kaydırmaları hakkında karar vermek
- Hangi müşterilere proaktif ulaşılması gerektiğini belirlemek
Bir metrik bir kararı değiştirmiyorsa, muhtemelen “etki” değildir—sadece telemetri.
Gereksinimler Kontrol Listesi: Girdiler, Çıktılar ve Kısıtlar
Ekranları tasarlamadan veya veritabanı seçmeden önce, "etki analizi"nin gerçek bir olay sırasında cevaplaması gerekenleri yazın. Hedef ilk günde kusursuz hassasiyet değil—müdahale edenlerin güveneceği tutarlı, açıklanabilir sonuçlardır.
Gerekli girdiler (minimum ihtiyaç)
Etkiyi hesaplamak için almanız veya referans vermeniz gereken verilerle başlayın:
- Olaylar: ID, başlangıç/bitiş zamanları, durum, sorumlu ekip, özet, olay kanalına/bilete bağlantılar.
- Hizmetler: kanonik hizmet listesi (isim, sahip, seviye/önem, runbook bağlantısı).
- Bağımlılıklar: hangi hizmetlerin hangilerine bağlı olduğu (ilk versiyon kaba olsa bile).
- Telemetri sinyalleri: uyarılar, SLO tüketimi, hata oranı/gecikme, dağıtım olayları—bozulma gösteren her şey.
- Müşteri hesapları: hesap ID'leri, plan/SLA, bölge, ana kişiler, ayrıca hesapların hizmetlere nasıl haritalandığı (doğrudan veya iş yükleri aracılığıyla).
Başlangıçta isteğe bağlı (planlayın, zorunlu kılmayın)
Çoğu ekip ilk günden mükemmel bağımlılık veya müşteri haritalamasına sahip değildir. Uygulamayı yine de kullanışlı kılmak için insanların manuel girmesine izin verilecekleri şeyleri belirleyin:
- Verinin eksik olduğu durumlarda etkilenen hizmet/müşteri seçimi
- Telemetri geciktiğinde tahmini başlangıç zamanı veya kapsam
- Gerekçeli geçersiz kılmalar (örn. “yanlış olumlu uyarı”, “yalnızca dahili etki”)
Bunları ad-hoc notlar yerine açık alanlar olarak tasarlayın ki sonradan sorgulanabilir olsunlar.
Temel çıktılar (uygulamanın üretmesi gerekenler)
İlk sürümünüz güvenilir şekilde şunları üretmelidir:
- Etkilenen hizmetler ve net bir “neden” (sinyaller + bağımlılıklar)
- Müşteri listesi; plan/bölge bazında sayımlar ve “önde gelen hesaplar” görünümü
- Ağırlaşma/etki puanı sade bir dille açıklanabilir
- Zaman çizelgesi: etkinin ne zaman başladığı, zirve yaptığı ve toparlandığı
- Opsiyonel ama değerli: maliyet tahmini (SLA kredileri, destek yükü, gelir riski) ve güven aralıkları
Fonksiyonel olmayan kısıtlar (güvenilir kılan şeyler)
Etki analizi bir karar aracıdır; bu yüzden kısıtlar önemlidir:
- Gecikme: panolar bir olay sırasında saniyeler içinde yüklenmeli
- Erişilebilirlik: dahili kritik araç gibi ele alın; bir kullanılabilirlik hedefi tanımlayın
- Denetlenebilirlik: bir geçersiz kılmayı kim değiştirdi, ne zaman ve önceki değer neydi, kaydedin
- Erişim kontrolü: hassas müşteri verilerini kısıtlayın; okuma vs yazma izinlerini ayırın
Bu gereksinimleri test edilebilir ifadeler olarak yazın. Doğrulayamıyorsanız, kesinti sırasında güvenemezsiniz.
Veri Modeli: Olaylar, Hizmetler, Bağımlılıklar ve Müşteriler
Veri modeliniz, alım, hesaplama ve UI arasındaki sözleşmedir. Doğru kurarsanız, araç kaynaklarını değiştirebilir, puanlamayı iyileştirebilir ve yine de aynı soruları yanıtlayabilirsiniz: “Ne kırıldı?”, “Kim etkilendi?” ve “Ne kadar süre?”
Temel varlıklar (küçük ve ilişkilendirilebilir tutun)
En azından bunları birinci sınıf kayıtlar olarak modelleyin:
- Olay: anlatı kabı (başlık, şiddet, durum, sahip), artı kanıtlara işaretçiler.
- Hizmet: bağımlılıkları eşlediğiniz birim (API, veritabanı, kuyruk, üçüncü taraf sağlayıcı).
- Bağımlılık: yönlendirilmiş bir kenar Hizmet A → Hizmet B metadata ile (tip, kritiklik).
- Sinyal: zaman damgalı bir gözlem (uyarı, SLO tüketimi, hata sıçraması, sentetik kontrol başarısızlığı).
- Müşteri: hizmetleri tüketen bir hesap veya organizasyon.
- Abonelik/SLA: müşterinin hakları (plan, SLA/SLO hedefleri, raporlama kuralları).
ID'leri kaynaklar arasında tutarlı ve sabit tutun. Zaten bir hizmet kataloğunuz varsa, onu doğruluk kaynağı olarak kullanın ve harici araç tanımlayıcılarını buna eşleyin.
Zaman modelleme (etki bir zaman aralığı sorunudur)
Raporlama ve analiz için olaya birden fazla zaman damgası saklayın:
- start_time / end_time: gerçek etki penceresi (sonradan iyileştirilebilir)
- detection_time: ilk fark edilme zamanı
- mitigation_time: düzeltmelerin etkiyi azaltmaya başladığı zaman
Ayrıca etki puanlama için hesaplanan zaman pencereleri (ör. 5 dakikalık kovalar) saklayın. Bu, tekrar oynatmayı ve karşılaştırmaları kolaylaştırır.
“Kim etkilendi?” sorusunu güçlendiren ilişkiler
İki önemli grafiği modelleyin:
- Hizmet-ten hizmete bağımlılıklar (blast radius)
- Müşteri-ten hizmet kullanım (etkilenen kapsam)
Basit bir desen customer_service_usage(customer_id, service_id, weight, last_seen_at) şeklinde olabilir; böylece müşterinin ne kadar dayandığını kullanarak etkiyi sıralayabilirsiniz.
Versiyonlama ve geçmiş (bağımlılıklar değişir)
Bağımlılıklar evrilir ve etki hesaplamaları o an olanı yansıtmalıdır. Kenarlara etkinlik tarihleri ekleyin:
dependency(valid_from, valid_to)
Aynı şeyi müşteri abonelikleri ve kullanım anlık görüntüleri için de yapın. Tarihsel versiyonlarla geçmiş olayları doğru şekilde yeniden çalıştırabilir ve tutarlı SLA raporlaması üretebilirsiniz.
Mevcut Araçlardan Veri Toplama ve Normalleştirme
Etki analiziniz yalnızca besleyen girdiler kadar iyidir. Buradaki hedef basittir: zaten kullandığınız araçlardan sinyalleri çekin, sonra uygulamanızın üzerinde mantık yürütebileceği tutarlı bir olay akışına dönüştürün.
Neleri almalısınız (ve neden)
Olay sırasında “bir şey değişti” diyen güvenilir kaynaklarla başlayın:
- Monitoring uyarıları (PagerDuty, Opsgenie, CloudWatch alarm): semptomların ve şiddetin hızlı göstergeleri
- Loglar ve trace'ler (ELK, Datadog, OpenTelemetry backend'leri): kapsam kanıtı (hangi endpointler, hangi müşteriler)
- Status page güncellemeleri (Statuspage, Cachet): resmî anlatı ve müşteri tarafı zaman damgaları
- Ticket/olay araçları (Jira, ServiceNow): sahiplik, zaman damgaları ve olay sonrası veriler
Her şeyi bir anda almaya çalışmayın. Tespit, yükseltme ve teyit süreçlerini kapsayan kaynakları seçin.
Alım yöntemleri
Farklı araçlar farklı entegrasyon modelleri destekler:
- Webhooklar yakın-gerçek-zamanlı güncellemeler için (uyarılar ve status page için en iyisi)
- Sorgulama (polling) webhook olmayan API'ler için (backoff ve oran sınırlamalarına dikkat edin)
- Toplu içe aktarma geçmiş doldurmalar için (başlangıçta doğrulama için faydalı)
- Manuel giriş son düzeltmeler için (analist eksik servis etiketi ekleyebilir)
Pratik bir yaklaşım: kritik sinyaller için webhooklar ve boşlukları doldurmak için toplu içe aktarma.
Ortak bir şemaya normalleştirme
Gelen her öğeyi kaynak ne ad verirse versin tek bir “olay” şekline normalleştirin. En azından standart hale getirin:
- Zaman damgaları: occurred_at, detected_at, resolved_at (mevcutsa)
- Hizmet tanımlayıcıları: kaynak etiket/isimlerini kanonik hizmet ID'lerine eşleyin
- Şiddet/öncelik: araçlara özgü seviyeleri kendi ölçeğinize dönüştürün
- Kaynak ve ham payload: denetim ve debug için orijinal JSON'u saklayın
Veri hijyeni: çoğaltmalar, sıralama, eksik alanlar
Dağınık veri bekleyin. Çoğaltmayı engellemek için idempotency anahtarları (source + external_id) kullanın, sıralama dışı olayları occurred_at üzerinden sıralayarak tolere edin ve eksik alanlarda güvenli varsayılanlar uygulayın (aynı zamanda bunları incelenmek üzere işaretleyin).
UI'da küçük bir “eşleşmeyen hizmet” kuyruğu sessiz hataları engeller ve etki sonuçlarını güvenilir kılar.
Hizmet Bağımlılıklarını Haritalama ve Doğru Blast Radius
Bir genel görünüm sayfası yayınlayın
Ne kırıldığını, kimlerin etkilendiğini ve nedenini gösteren bir olay genel görünümü oluşturun.
Bağımlılık haritanız yanlışsa, sinyalleriniz ve puanlamanız mükemmel olsa bile blast radius yanlış olur. Amaç, hem bir olay sırasında hem de sonrasında güvenilebilecek bir bağımlılık grafiği oluşturmaktır.
Hizmet kataloğundan başlayın (doğruluk kaynağınız)
Kenarları haritalamadan önce düğümleri tanımlayın. Bir olayda referans verebileceğiniz her sistem için bir hizmet kataloğu girdisi oluşturun: API'ler, arka plan işçileri, veri depoları, üçüncü taraf satıcılar ve diğer kritik paylaşılan bileşenler.
Her hizmet en azından şunları içermeli: sahip/ekip, seviye/kritiklik (ör. müşteri-facing vs dahili), SLA/SLO hedefleri ve runbook/on-call dokümanlarına bağlantılar (ör. /runbooks/payments-timeouts).
Bağımlılık yakalama: statik vs. öğrenilmiş
İki tamamlayıcı kaynağı kullanın:
- Statik (beyan edilen) bağımlılıklar: ekiplerin bağımlı olduğunu söylediği şeyler (IaC, konfigürasyon, hizmet manifestoları, ADR'ler). Kararlı ve denetlenmesi kolay.
- Öğrenilmiş (gözlemlenen) bağımlılıklar: sistemlerin gerçekten kiminle konuştuğu (trace'ler, servis mesh telemetri, API gateway logları, egress proxy'ler, veritabanı audit logları). Bu, unutulmuş downstream çağrılarını yakalar.
Bunları ayrı kenar türleri olarak ele alın ki insanlar güveni anlayabilsin: “ekip tarafından beyan edildi” vs “son 7 günde gözlendi”.
Yön ve kritiklik önemlidir
Bağımlılıklar yönlü olmalıdır: Checkout → Payments ile Payments → Checkout aynı şey değildir. Yön, akıl yürütmeyi yönetir (“Payments bozulursa hangi upstream'ler başarısız olabilir?”).
Ayrıca sert vs yumuşak bağımlılıkları modelleyin:
- Sert: hata temel fonksiyonu engeller (ör. auth servisi giriş için)
- Yumuşak: bozulma kaliteyi düşürür ama geri dönüş vardır (öneriler, isteğe bağlı zenginleştirme)
Bu ayrım etkiyi abartmayı önler ve müdahale edenlerin önceliklendirmesine yardımcı olur.
Oynatma ve olay sonrası analiz için grafiğin anlık görüntüsünü alın
Mimari haftalık değişir. Anlık görüntü saklamazsanız iki ay önceki bir olayı doğru şekilde analiz edemezsiniz.
Bağımlılık grafiği versiyonlarını zaman içinde (günlük, deploy başına veya değişiklikte) saklayın. Blast radius hesaplanırken olay zaman damgasını en yakın graf anlık görüntüsüne çözümleyin; böylece “kim etkilendi” o andaki gerçeği yansıtır—bugünkü mimariyi değil.
Etki Hesaplama: Sinyallerden Puanlara ve Etkilenen Kapsama
Sinyalleri (uyarılar, SLO tüketimi, sentetik kontroller, müşteri biletleri) aldıktan sonra uygulama, dağınık girdileri net bir ifadeye dönüştürmelidir: ne kırıldı, ne kadar kötü ve kim etkilendi?
Bir puanlama yaklaşımı seçin (basit başlayın)
Aşağıdaki desenlerden herhangi biriyle uygulanabilir bir MVP elde edebilirsiniz:
- Kural tabanlı puanlama: “Eğer ödeme hata oranı %5'i 10 dakika aşarsa, etki = Yüksek.” Açık ve debug edilmesi kolay.
- Ağırlıklı formül: Normalleştirilmiş metrikleri tek bir skora (ör. 0–100) birleştirin. Çok sayıda sinyal olduğunda pürüzsüz bir eğri sağlar.
- Seviye tabanlı eşleme: Sistemleri iş katmanlarına eşleyin (Seviye 0–3) ve şiddeti buna göre sınırlayın veya artırın. Bu, sonuçları iş öncelikleriyle hizalar.
Hangi yaklaşımı seçerseniz seçin, ara değerleri (eşik atlaması, ağırlıklar, seviye) saklayın ki insanlar puanın neden ortaya çıktığını anlayabilsin.
Etki boyutlarını tanımlayın
Her şeyi tek bir sayıya erken sıkıştırmaktan kaçının. Önce birkaç boyutu ayrı ayrı takip edin, sonra genel bir şiddet türetin:
- Erişilebilirlik: kesinti, başarısız istekler, ulaşılamayan endpointler
- Gecikme: temel veya SLO'ya göre p95/p99 bozulması
- Hatalar: hata oranı sıçramaları, başarısız işler, zaman aşımı
- Veri doğruluğu: eksik/yanlış kayıtlar, gecikmiş işleme
- Güvenlik riski: şüpheli erişim, veri sızması göstergeleri
Bu, müdahale edenlerin durumu doğru iletişim kurmasını sağlar (örn. “erişilebilir ama yavaş” vs “yanlış sonuçlar”).
Etkilenen kapsama hesaplama (müşteriler/kullanıcılar)
Etki sadece hizmet sağlığı değildir—onu hisseden kişilerdir.
Kullanım haritalaması (tenant → hizmet, müşteri planı → özellikler, kullanıcı trafiği → endpoint) kullanın ve etkilenen müşterileri olayla hizalı bir zaman penceresi içinde hesaplayın (başlangıç zamanı, azaltma zamanı ve varsa backfill dönemi).
Varsayımları açıkça belirtin: örneklenmiş loglar, tahmini trafik veya kısmi telemetri gibi.
Manuel ayarlamalar—hesap verebilirlikle
Operatörlerin geçersiz kılmaya ihtiyacı olacak: yanlış pozitif uyarı, kısmi dağıtım, bilinen bir müşteri alt kümesi.
Şiddet, boyutlar ve etkilenen müşteriler üzerinde manuel düzenlemelere izin verin, ancak şu bilgiler zorunlu olsun:
- Kim neyi değiştirdi
- Ne zaman
- Neden (kısa sebep + isteğe bağlı bilet/runbook bağlantısı)
Bu denetim izi panodaki güveni korur ve olay sonrası incelemeyi hızlandırır.
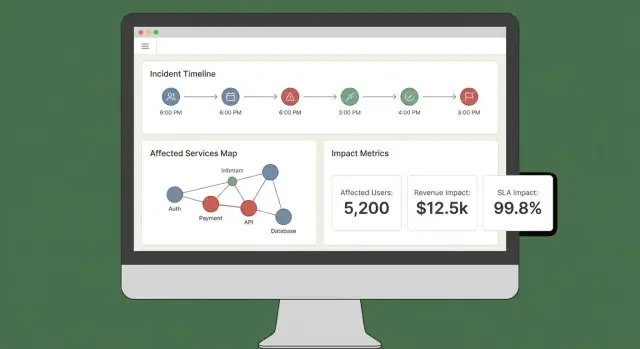
UX ve Panolar: Etkiyi Dakikalar İçinde Anlaşılır Kılın
İyi bir etki panosu üç soruyu hızlıca yanıtlar: Ne etkilendi? Kim etkilendi? Ne kadar eminiz? Kullanıcılar beş farklı sekme açmak zorunda kalırsa, çıktıya güvenmezler veya harekete geçmezler.
MVP'de yayınlanacak temel görünümler
Her zaman orada olacak ve gerçek olay iş akışlarına uyan küçük bir görünüm setiyle başlayın:
- Olay genel görünümü: durum, başlangıç zamanı, geçerli etki puanı, en çok etkilenen hizmetler/müşteriler ve en son kanıtlar.
- Etkilenen hizmetler: şiddet, bölge ve bağımlılık yolu gösteren sıralı liste (mühendislerin nerede müdahale edeceğini görmesi için).
- Etkilenen müşteriler: plan/bölge bazlı sayılar ve biliniyorsa tahmini kullanıcı etkisi.
- Zaman çizelgesi: tespitler, dağıtımlar, uyarılar, azaltmalar ve etki değişikliklerini birleştiren kronolojik akış.
- Eylemler: önerilen sonraki adımlar, sahipler ve playbook/ticket bağlantıları.
“Neden”i görünür kılın
Açıklaması olmayan etki puanları keyfi görünür. Her puan girdilere ve kurallara geri izlenebilir olmalı:
- Hangi sinyallerin katkıda bulunduğunu gösterin (hatalar, gecikme, health check, destek hacmi) ve mevcut değerlerini.
- Kullanılan kuralları ve eşikleri gösterin (örn. “latency p95 > 2s for 10 min = degraded”).
- Hafif bir güven göstergesi ekleyin (örn. “Yüksek güven: 3 kaynaktan doğrulandı”).
Ana görünümü karmaşıklaştırmadan bunu yapacak basit bir “Etkiyi Açıklayın” çekmecesi yeterli olabilir.
Gerçek sorulara uygun filtreler ve detay incelemeleri
Etkiyi hizmete, bölgeye, müşteri kademesine ve zaman aralığına göre dilimlemeyi kolaylaştırın. Kullanıcıların herhangi bir grafik noktasına veya satıra tıklayıp değişikliğe neden olan ham kanıtlara (tam monitörler, loglar veya olaylar) inebilmesini sağlayın.
Paylaşım ve dışa aktarmalar
Aktif bir olay sırasında insanlar taşınabilir güncellemelere ihtiyaç duyar. Şunları ekleyin:
- Paylaşılabilir bağlantılar (izinleri koruyarak)
- CSV dışa aktarımı için servis/müşteri listeleri
- PDF dışa aktarımı durum güncellemeleri ve olay sonrası özetler için
Zaten bir status page'iniz varsa, iletişim ekiplerinin hızlı çapraz referans yapabilmesi için /status gibi göreli bir rota ile bağlantı verin.
Güvenlik, İzinler ve Denetim Günlükleme
Tam yığını üretin
Olay iş akışınıza dayalı bir React UI, Go API ve PostgreSQL şeması başlatın.
Etki analizi ancak insanlara güven verirse kullanışlı olur—bu da kimlerin neyi görebileceğini kontrol etmeyi ve değişikliklerin açık kaydını tutmayı gerektirir.
Roller ve izinler (basit başlayın)
Olayların gerçek hayatındaki akışa uyan küçük bir rol seti tanımlayın:
- İzleyici: olay özetleri ve yüksek seviyeli etkiye sadece okunur erişim.
- Yanıtlayıcı: not ekleyebilir, etkilenen hizmetleri onaylayabilir ve operasyonel alanları güncelleyebilir.
- Olay komutanı: etki geçersiz kılmalarını onaylayabilir, müşteri-facing statüyü ayarlayabilir ve olayları kapatabilir.
- Yönetici: entegrasyonları, rol atamalarını ve veri saklama ayarlarını yönetir.
İzinleri iş unvanlarına değil eylemlere göre hizalayın. Örneğin, “müşteri etki raporunu dışa aktarabilir” gibi bir izin komutanlara ve sınırlı bir yönetici grubuna verilebilir.
Hassas müşteri verilerini koruyun
Etki analizi genellikle müşteri kimliklerini, sözleşme kademelerini ve bazen iletişim detaylarını içerir. Varsayılan olarak en az ayrıcalık uygulayın:
- Hassas alanları maskeleyin (örn. hesap ID'sinin son 4 hanesini göster) gerekliyse kullanıcı açıkça erişime sahip olmadıkça.
- “Kim etkilendi”yi “ne kırıldı”dan ayırın. Birçok kullanıcı sadece hizmet düzeyinde etkiye ihtiyaç duyar, müşteri listesine değil.
- Güvenli dışa aktarma: PDF/CSV'leri filigranlayın, talep eden kullanıcıyı ekleyin ve dışa aktarımları onaylı rollere sınırlayın. Kısa ömürlü, imzalı indirme linklerini tercih edin.
“Kim neyi değiştirdi?” sorusuna cevap veren denetim günlükleri
İncelemeleri destekleyecek yeterli bağlamla ana eylemleri kaydedin:
- etki girdilerinde yapılan manuel düzenlemeler (etkilenen hizmetler/müşteriler)
- etki puanı geçersiz kılmaları (eski değer, yeni değer, neden)
- onaylamalar ve durum geçişleri
- rapor üretimi ve dışa aktarmalar
Denetim günlüklerini eklemeli olarak saklayın, zaman damgası ve aktör kimliği ile. Olay başına aranabilir hale getirerek olay sonrası incelemelerde kullanışlı olmalarını sağlayın.
Uyumluluk ihtiyaçları için plan yapın (aşırı söz vermeden)
Şu anda neleri destekleyebileceğinizi belgeleyin—saklama süresi, erişim kontrolleri, şifreleme ve denetim kapsamı—ve yol haritasında nelerin olduğu. Uygulamada kısa bir “Güvenlik & Denetim” sayfası (örn. /security) beklentileri belirler ve kritik olaylar sırasında rastgele soruları azaltır.
Aktif Bir Olay Sırasında İş Akışları ve Bildirimler
Etki analizi yalnızca bir olay sırasında bir sonraki eylemi yönlendiriyorsa önemlidir. Uygulamanız olay kanalının “yol arkadaşı” gibi davranmalı: gelen sinyalleri net güncellemelere çevirir ve etki anlamlı şekilde değiştiğinde insanları dürter.
Sohbet ve olay kanallarına bağlanın
Yanıtlayanların zaten çalıştığı yere (çoğunlukla Slack, Microsoft Teams veya adanmış bir olay aracı) entegrasyonla başlayın. Amaç kanalı değiştirmek değil—bağlam odaklı güncellemeler göndermek ve ortak bir kayıt tutmaktır.
Pratik bir desen olay kanalını hem giriş hem çıkış olarak kullanmaktır:
- Girdi: müdahale edenler uygulamayı etiketler (örn. “/impact summarize”, “/impact add affected customer Acme”) kapsamı düzeltmek veya zenginleştirmek için.
- Çıktı: uygulama kısa, tutarlı güncellemeler gönderir (mevcut etki puanı, etkilenen hizmetler/müşteriler, önceki güncellemeye göre eğilim).
Hızlı prototipleme yapıyorsanız, önce uçtan uca iş akışını kurmayı (olay görünümü → özetle → bildir) düşünün; puanlamayı mükemmelleştirmeye sonra odaklanın. Koder.ai gibi platformlar burada kullanışlı olabilir: React panosu, Go/PostgreSQL arka ucu ile sohbet odaklı yineleme imkanı sağlar ve ekip UX gerçeği yansıdığında kaynak kodunu dışa aktarabilirsiniz.
Eşik tabanlı bildirimler (gürültü değil)
Bildirim spam'inden kaçınmak için yalnızca etki belirli eşikleri aştığında bildirim tetikleyin. Yaygın tetikleyiciler:
- Kapsam: etkilenen müşteri sayısı ani artış (örn. 10 → 100)
- Seviye: Tier 1 bir hizmetin etkilenmesi
- Gelir / SLA riski: öngörülen SLA ihlali veya yüksek kontrat değeri
- Blast radius genişlemesi: etkilenen setine yeni bağımlı hizmetlerin katılması
Bir eşik aşıldığında, neden (ne değişti), kimin harekete geçmesi gerektiği ve ne yapılacağı açıklayan bir mesaj gönderin.
Runbook ve iş akışlarına bağlantı verin
Her bildirim “sonraki adım” bağlantıları içermeli ki müdahale edenler hızla ilerleyebilsin:
- Runbooklar: /blog/incident-runbook-template
- Yükseltme politikası: /pricing
- Hizmet sahiplik sayfası: /services/payments
Bu bağlantıları göreli ve sabit tutun ki ortamlar arasında çalışsınlar.
Paydaş güncellemeleri: dahili ve müşteri tarafı
Aynı veriden iki özet formatı oluşturun:
- Dahili güncelleme: teknik detay, şüphelenilen neden, azaltma ilerlemesi, ETA güveni
- Müşteri odaklı güncelleme: sade dil, mevcut kullanıcı etkisi, geçici çözümler, bir sonraki güncelleme zamanı
Zamanlanmış özetleri destekleyin (örn. her 15–30 dakika) ve harici gönderimden önce onay adımı olan “güncelleme oluştur” eylemlerini sağlayın.
Doğrulama: Test, Tekrar Oynatma ve Doğruluk Kontrolleri
Etkı puanlama fikirlerini test edin
Tam bir yapıya geçmeden önce olay veri modelinizi ve puanlama kurallarınızı prototipleyin.
Etki analizi ancak insanlar hem olay sırasında hem olay sonrasında ona güvendiklerinde kullanışlıdır. Doğrulama iki şeyi kanıtlamalı: (1) sistem tutarlı, açıklanabilir sonuçlar üretiyor ve (2) bu sonuçlar organizasyonun sonradan vardığı bulgularla uyuşuyor.
Test stratejisi: kurallar ve boru hatları
İki en hataya açık alanı kapsayan otomatik testlerle başlayın: puanlama mantığı ve veri alımı.
- Puanlama kuralları için birim testleri: Her kuralı bir sözleşme olarak ele alın. Belirli sinyaller verildiğinde (hata oranı, gecikme, sentetik kontroller, bilet hacmi) beklenen etki puanı ve etkilenen kapsam doğrulanmalı. Sınır testlerini (eşiklerin hemen altı/üstü) dahil edin ki metrik oynaklığı beklenmedik sonuçlara yol açmasın.
- Alım için entegrasyon testleri: webhook/olay girdisinden normalleştirilmiş kayıtlara ve hesaplanmış etkiye kadar tam yolu doğrulayın. Observability ve olay araçlarından alınmış kaydedilmiş payload'ları kullanarak şema kaymasını erken yakalayın.
Test verilerini okunabilir tutun: biri bir kuralı değiştirdiğinde, neden puanın değiştiğini anlamalı.
Geçmiş olayları tekrar oynatın
Oynatma modu güven inşa etmenin hızlı yoludur. Tarihsel olayları uygulamadan geçirip sistemin “o anda” ne göstereceğini ile müdahale edenlerin sonradan vardığı sonuçları karşılaştırın.
Pratik ipuçları:
- Gerçekliği yansıtmak için olay zaman damgalarını (ingestion time değil) kullanarak zaman çizelgelerini yeniden oluşturun.
- Hizmet kataloğu değiştiyse, olay tarihine ait graf anlık görüntüsünü dondurun.
- Oynatma sonuçlarını saklayın, böylece kural değişikliklerinden sonra karşılaştırma yapabilirsiniz.
Naif puanlamayı bozan uç durumları ele alın
Gerçek olaylar nadiren temiz kesintilere benzer. Doğrulama paketiniz şu senaryoları içermelidir:
- Kısmi kesintiler (sadece bazı endpointler veya müşteri segmentleri başarısız)
- Bozulmuş performans (çalışıyor ama yavaş), iş etkisi hâlâ yüksek olabilir
- Çok bölgeli arızalar; aynı hizmetin bölgelere göre farklı sağlığı olabilir
Her durumda sadece puanı değil, puanı getiren açıklamayı da doğrulayın: hangi sinyaller ve hangi bağımlılıklar/müşteriler sonucu tetikledi.
Olay sonrası bulgularla doğruluğu ölçme
Doğruluğu operasyonel terimlerle tanımlayın ve izleyin.
Hesaplanan etkiyi olay sonrası inceleme sonuçlarıyla karşılaştırın: etkilenen hizmetler, süre, müşteri sayısı, SLA ihlali ve şiddet. Tutarsızlıkları bir doğrulama sorunu olarak kategorize edin (eksik veri, yanlış bağımlılık, hatalı eşik, gecikmiş sinyal).
Zamanla hedef mükemmellik değil—olaylarda daha az sürpriz ve daha hızlı uzlaşıdır.
MVP'den Sonra Dağıtım, Ölçeklendirme ve İyileştirme
Olay etki analizi için bir MVP göndermek çoğunlukla güvenilirlik ve geri bildirim döngüleriyle ilgilidir. İlk dağıtım tercihi değiştirme hızını optimize etmeli, teorik gelecekteki ölçeği değil.
Evrilebileceğiniz bir dağıtım tarzı seçin
Eğer güçlü bir platform ekibiniz ve net servis sınırlarınız yoksa modüler monolit ile başlayın. Tek dağıtılabilir birim migration, debug ve uçtan uca testleri basitleştirir.
Servisleri yalnızca gerçek bir acı noktası oluştuğunda ayırın:
- alım hattı bağımsız ölçekleme gerektiriyorsa
- birden fazla ekip bağımsız deploy etmek zorundaysa
- tek bir uygulamada hata alanları anlaması zor hale geliyorsa
Pratik orta yol: bir uygulama + arka plan worker'lar (kuyruklar) + gerekirse ayrı bir ingestion edge.
Hızlı ilerlemek ama büyük bir özel platforma erken bağlanmamak isterseniz, Koder.ai MVP hızlandırmada yardımcı olabilir: sohbet tabanlı “vibe-coding” ile React UI, Go API ve PostgreSQL veri modeli oluşturma, kural ve iş akışı yinelemeleri sırasında snapshot/rollback imkanı sunar.
Erişim desenlerine göre depolama seçimi
Temel varlıklar (olaylar, hizmetler, müşteriler, sahiplik ve hesaplanmış etki anlık görüntüleri) için ilişkisel depolama (Postgres/MySQL) kullanın. Sorgulanması, denetlenmesi ve evrilmesi kolaydır.
Yüksek hacimli sinyaller (metrikler, log türetilmiş olaylar) için ham sinyal saklama ve rollup'lar SQL'de pahalı hale geldiğinde bir zaman serisi veya sütunlu mağaza ekleyin.
Bağımlılık sorguları darboğaz olduğunda veya model çok dinamik hale geldiğinde graf veritabanı düşünün. Birçok ekip, bitişik tablolar + önbellekleme ile uzun süre idare edebilir.
Uygamanın kendisi için gözlemlenebilirlik ekleyin
Etki analiz uygulamanız olay zincirinin bir parçası haline gelir; onu prod gibi instrument edin:
- hata oranı ve yavaş uç noktalar (özellikle “etkiyi yeniden hesapla”)
- worker kuyruk derinliği/lag ve retry oranları
- kaynaktan kaynak başarısızlık sayıları ve alım throughput'u
- veri tazeliği (son başarılı çekme/gönderme süresi)
- hesaplama süresi ve cache hit oranı
UI'da bir “sağlık + tazelik” görünümü sunun ki müdahale edenler sayılara güvensin veya sorgulasın.
İyileştirme ve refaktörleri planlı yapın
MVP kapsamını sıkı tutun: birkaç aracı alım, net bir etki puanı ve “kim etkilendi, ne kadar” sorusunu yanıtlayan bir pano. Sonra yineleyin:
- Sonraki özellikler: daha iyi bağımlılık doğruluğu, müşteri-özel ağırlıklandırma, SLA raporlama dışa aktarımları, geçmiş olaylar için oynatma
- Refactor tetikleyicileri: haftalık özel durum eklemeye başlamanız, yeniden hesaplama çok yavaşlaması veya veri modeli gerçekliği ifade etmek için hile yapmaya başlaması
Modeli bir ürün gibi yönetin: sürümleyin, güvenli şekilde migrate edin ve değişiklikleri olay sonrası incelemeler için belgelendirin.