Hedefleri, Kullanıcıları ve Başarı Metriklerini Netleştirin
Ekran tasarlamadan veya veritabanı seçmeden önce, ekibinizin olay izleme web uygulaması ile ne demek istediği ve “postmortem yönetimi”nin neyi başarması gerektiği konusunda uzlaşın. Ekipler aynı kelimeleri farklı şekillerde kullanır: bir grup için olay her müşteri bildirimi olabilir; bir başkası içinse yalnızca on-call yükseltmesi gerektiren Sev-1 kesintisi olabilir.
Ekibiniz için “olay izleme”yi tanımlayın
Kısa bir tanım yazın ve şu soruları yanıtlayın:
- Hangi durumlar olayı tanımlar (müşteri etkisi, yalnızca dahili etki, güvenlik olayları, kaçırılan SLA'lar)?
- Bir olay ne zaman “başlar” ve ne zaman “biter” (ilk alarm vs. ilk insan onayı; tamamen düzeldi vs. izleniyor)?
- Hangi veriler zorunludur (etkilenen servis, şiddet/severity, sahip, zaman damgaları, durum güncellemeleri)?
Bu tanım, olay müdahale iş akışınızı yönlendirir ve uygulamanın ya çok katı (kimse kullanmaz) ya da çok gevşek (veri tutarsız) olmasını engeller.
“Postmortem yönetimi”ni (ve neden yaptığınızı) tanımlayın
Bir postmortem’in kuruluşunuz için ne olduğunu belirleyin: her olay için hafif bir özet mi, yoksa yalnızca yüksek şiddetli olaylar için tam bir RCA mı? Hedefin öğrenme, uyumluluk, tekrarlayan olayları azaltma veya bunların tümü olup olmadığını açıkça belirtin.
Yararlı bir kural: postmortem’in değişim üretmesini bekliyorsanız, aracınız eylem öğeleri takibini desteklemelidir; sadece belge depolamak yeterli değildir.
Çözdüğünüz problemleri listeleyin
Çoğu ekip bu tür bir uygulamayı tekrar eden birkaç ağrılı noktayı çözmek için kurar:
- Görünürlük: “Şu an ne oluyor?” “Bu servis ne sıklıkla bozuluyor?”
- Koordinasyon: net sahiplik, devirler ve paylaşılan olay zaman çizelgesi
- Öğrenme: tutarlı RCA şablonları ve gerçekten yapılan bir inceleme süreci
- Takip: eylem öğeleri toplantıdan sonra kaybolmaz
Bu listeyi kısa tutun. Eklediğiniz her özellik en az bir probleme karşılık gelmelidir.
Davranışı ölçen başarı metrikleri seçin
Uygulamanızın veri modelinden otomatik olarak ölçebileceğiniz birkaç metrik seçin:
- Tespit, onay, hafifletme ve çözüm süreleri (olay zaman çizelgeniz bunları yakalamalı)
- Şiddete, servise ve kök neden kategorisine göre sıklık
- Eylem öğesi kapanma oranı ve kapanma için medyan süre
- Kalite sinyalleri: N gün içinde postmortem tamamlanma yüzdesi; açık sahip ve durum güncellemeleri olanların yüzdesi
Bunlar ilk sürüm için operasyonel metrikleriniz ve “yapıldı tanımınız” olur.
Kullanıcılarınızı netleştirin (ve her birinin ihtiyaçları)
Aynı uygulama nöbet operasyonları içinde farklı rollerin ihtiyaçlarını karşılar:
- Nöbetçi mühendis: hızlı kayıt, minimum alan, kolay durum güncellemeleri
- Olay komutanı: koordinasyon görünümü, güncel durum, sahipler, kontrol noktaları
- Yöneticiler: trendler, tekrarlayan sorunlar, eylem öğelerinin takibi
- Paydaşlar: dahili gürültü olmadan net durum güncellemeleri
Hepsini aynı anda tasarlarsanız karışık bir UI elde edersiniz. Bunun yerine, v1 için birincil kullanıcıyı seçin—ve diğerlerinin ihtiyaçlarını daha sonra özelleştirilmiş görünümler, panolar ve izinlerle almasını sağlayın.
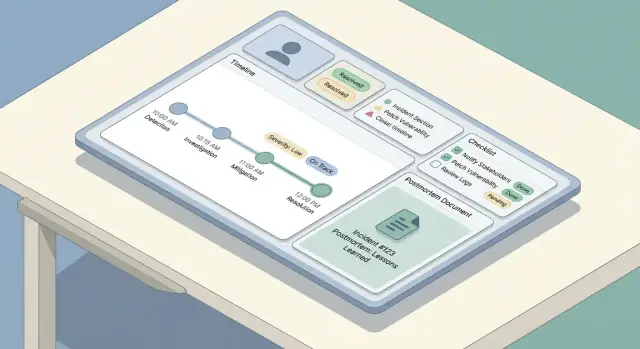
Olay İş Akışını ve Rolleri Tasarlayın
Net bir iş akışı iki yaygın başarısızlık biçimini önler: kimsenin “sonraki adım”ı bilmediği için duraklayan olaylar ve “bitmiş” görünen ama öğrenme üretmeyen olaylar. Yaşam döngünüzü baştan sona haritalayın ve her adıma roller ve izinler atayın.
Olay yaşam döngüsünü haritalayın
Çoğu ekip basit bir çizgiyi takip eder: tespit → ön değerlendirme → hafifletme → çözüm → öğrenme. Uygulamanız bunu küçük ve öngörülebilir adımlarla yansıtmalı, sonsuz bir seçenek menüsüyle değil.
Her aşama için “tamam” tanımını yapın. Örneğin, hafifletme müşteri etkisinin durdurulması anlamına gelebilir; kök neden hâlâ bilinmiyor olabilir.
Roller ve sorumlulukları tanımlayın
Rolleri açık tutun ki insanlar toplantıları beklemeden hareket edebilsin:
- Bildiren: olayı oluşturur, ilk bağlamı ekler, bağlantılar/loglar ekler.
- Yanıtlayan: araştırır, güncellemeler ekler, hafifletmeleri uygular.
- Olay Komutanı: koordinasyondan sorumludur, yanıtlayıcıları atar, şiddeti onaylar, paydaş güncellemelerini kontrol eder.
- İnceleyen: olay sonrası incelemeyi yönetir, postmortem kalitesini sağlar.
UI’niz “güncel sahip”i görünür kılmalı ve iş akışı devretmeyi desteklemelidir (yeniden atama, yanıtlayıcı ekleme, komutan döndürme).
Durumlar ve geçişler
Gerekli durumları ve izin verilen geçişleri seçin, örneğin İnceleniyor → Hafifletildi → Çözüldü. Koruyucular ekleyin:
- Triage sonrası geçişler için bir şiddet gerektirin.
- Çözüldü olarak işaretlemeden önce bir çözüm özeti isteyin.
- “Çözüldü → İnceleniyor”a izin vermeden önce yeniden açma nedeni kaydedilmesini zorunlu kılın.
İletişim kanallarını planlayın
Dahili güncellemeler (hızlı, taktiksel, dağınık olabilir) ile paydaşlara yönelik güncellemeler (net, zaman damgalı, seçilmiş) arasında ayrım yapın. Farklı şablonlar, görünürlük ve onay kurallarıyla iki güncelleme akışı oluşturun—çoğu durumda komutan, paydaş güncellemelerinin tek yayımlayıcısıdır.
Veriyi Modelleyin: Varlıklar, İlişkiler ve Geçmiş
İyi bir olay aracı UI'da “basit” hissi verir çünkü altında tutarlı bir veri modeli vardır. Ekranları oluşturmadan önce hangi nesnelerin var olduğunu, nasıl ilişkili olduklarını ve hangi verilerin tarihsel olarak doğru tutulması gerektiğini belirleyin.
Temel varlıklar (sakladığınız nesneler)
Küçük bir ilk sınıf nesne setiyle başlayın:
- Olay (Incident): olup bitenin kapsayıcısı.
- Servis: işlettiğiniz şey (API, veritabanı, mobil uygulama); etki ve raporlama için kullanılır.
- Güncelleme (Update): insan tarafından okunabilir durum güncellemeleri (dahili notlar ve dışa dönük durumlar için).
- Zaman Çizelgesi Olayı (Timeline Event): kesin, zaman damgalı olgular (“alarm tetiklendi”, “geri alma yapıldı”, “hafifletme uygulandı”).
- Eylem Öğesi (Action Item): sahipleri ve teslim tarihleri olan takipler.
- Postmortem: yapılandırılmış yazım (etki, kök neden analizi, dersler, bağlantılar).
İlişkiler ve tanımlayıcılar
Çoğu ilişki bire çoktur:
- Bir Olay → birçok Güncelleme / Zaman Çizelgesi Olayı / Eylem Öğesi
- Bir Olay → bir (veya sıfır) Postmortem
- Bir Olay ↔ birçok Servis (genellikle “affected_services” gibi bir ilişki tablosu üzerinden çoktan çoğa)
Olaylar ve olay içi etkinlikler için kararlı tanımlayıcılar (UUID) kullanın. İnsanların yine de INC-2025-0042 gibi okunabilir bir anahtara ihtiyacı olur; bunu sıra numarasından üretebilirsiniz.
Bunları erken modelleyin ki filtreleme, arama ve raporlama yapabilesiniz:
- Şiddet, durum (açık/hafifletildi/çözüldü), etiketler
- Başlangıç zamanı, bitiş zamanı, tespit zamanı
- Olay komutanı, sahip ekip, nöbet rotasyonu (opsiyonel)
- Etkilenen servisler, müşteri etki özeti
Geçmiş, saklama ve denetlenebilirlik
Olay verileri hassas olabilir ve sonra incelenir. Düzenlemeleri verinin bir parçası olarak ele alın—üst yazma yapmayın:
- Her kayıtta created_at/created_by saklayın.
- Düzenlemeler için bir denetim günlüğü (alan değişiklikleri + aktör + zaman damgası) tutun veya önemli belgeleri (postmortem, güncellemeler) versiyonlayın.
- Saklama süresini baştan belirleyin (ör. olayları sonsuza kadar tut, sohbet dökümlerini N gün sonra sil).
Bu yapı, daha sonra arama, metrikler ve izinler gibi özellikleri yeniden çalışmadan uygulamayı kolaylaştırır.
Olay Kaydı, Güncellemeler ve Zaman Çizelgesini Oluşturun
Bir şey bozulduğunda uygulamanın görevi yazma işini azaltmak ve netliği artırmaktır. Bu bölüm “yazma yolu”nu kapsar: insanların nasıl olay oluşturduğu, güncellediği ve sonra ne olduğunu nasıl yeniden kurduğu.
Olay kaydı: minimum alanlar, akıllı varsayılanlar
Kayıt formunu, sorun giderirken tamamlanabilecek kadar kısa tutun. İyi bir varsayılan zorunlu alan seti şunlardır:
- Başlık (düz dil: “Mobilde ödeme sayfasında hata”)
- Servis/Sistem (yazım çeşitliliğini önlemek için listeden seç)
- Şiddet (Severity) (servise veya zamana göre varsayılan ayarlayın, ama düzenlenebilir olsun)
- Bildirici (Reporter) (giriş yapan kullanıcıdan otomatik doldurma)
Diğer her şey oluşturma sırasında isteğe bağlı olmalı (etki, müşteri talep bağlantıları, şüpheli neden). Akıllı varsayılanlar kullanın: başlangıç zamanını “şimdi”ye, kullanıcının nöbet ekibini ön seçime ayarlayın ve bir dokunuşla “Olay odası oluştur ve aç” eylemi sunun.
Hızlı güncellemeler: durum, etki, sonraki adımlar
Güncelleme UI'nız tekrarlanan küçük düzenlemeler için optimize edilmeli. Kompakt bir güncelleme paneli sağlayın:
- Durum (İnceleniyor / Belirlendi / Hafifletildi / Çözüldü)
- Etkİ özetı (bir veya iki cümle)
- Ana notlar (son güncellemeden bu yana ne değişti)
- Sonraki adımlar (sırada olan, kimin yapacağı)
Güncellemeleri eklemeye uygun yapın: her güncelleme zaman damgalı bir giriş olsun, önceki metnin üstüne yazılmasın.
Zaman çizelgesi: otomatik geçmiş + manuel olaylar
Aşağıdakileri karıştıran bir zaman çizelgesi oluşturun:
- Otomatik yakalanan olaylar: alan değişiklikleri (şiddet, durum), atamalar, eklenen bağlantılar, çözüm zamanı
- Manuel olaylar: “Hotfix deploy edildi”, “Geri alındı”, “DB failover başlatıldı”
Bu, insanların her tıklamayı kaydetmelerini zorlamadan güvenilir bir anlatı oluşturur.
Mobilde hız için tasarım
Bir kesinti sırasında birçok güncelleme telefondan gelir. Hızlı, düşük engelli bir ekran önceliklendirin: büyük dokunmatik hedefler, tek kaydırmalı sayfa, çevrimdışı taslaklar ve “Güncelleme gönder” ve “Olay bağlantısını kopyala” gibi tek dokunuş eylemler.
Şiddet, Kontrol Listeleri ve Destekleyici Bağlam Ekleyin
Şiddet, olay müdahalesinin “hız düğmesi”dir: insanlara ne kadar acil davranacaklarını, ne kadar geniş iletişim yapılacağını ve hangi ödünlerin kabul edilebilir olduğunu söyler.
Şiddet seviyelerini tanımlayın (ve ne anlama geldiklerini)
“yüksek/orta/düşük” gibi belirsiz etiketlerden kaçının. Her şiddet seviyesini açık operasyonel beklentilerle—özellikle yanıt süresi ve iletişim takvimi—eşleştirin.
Örneğin:
- SEV1 (Kritik): kullanıcıyı etkileyen kesinti veya büyük güvenlik riski. Hemen çağır (page), bir olay köprüsü/sohbet aç, paydaşları her 15–30 dakika güncelle ve gerekirse halka açık durum güncellemesi düşün.
- SEV2 (Önemli): kısmi kesinti veya ciddi yavaşlama. Hızlı yanıt ver, sohbette koordine ol, paydaşları her 30–60 dakika güncelle.
- SEV3 (Küçük): sınırlı etki, geçici çözüm mevcut. Uygunsa mesai saatlerinde ele alın, önemli kilometre taşlarında güncelleme yapın.
- SEV4 (Bilgi): anlık etkisi yok; operasyonel bir konu olarak takip edin.
Bu kuralları, şiddetin seçildiği her yerde UI’da görünür yapın ki yanıtlayanlar olağanüstü durum dokümanlarında arama yapmak zorunda kalmasın.
İş akışınıza uyan yanıtlayıcı kontrol listeleri ekleyin
Stres altındayken kontrol listeleri bilişsel yükü azaltır. Kısa, uygulanabilir ve rollere bağlı tutun.
Yararlı bir desen birkaç bölüm içerir:
- Triage: müşteri etkisini doğrula, blast radius’u belirle, şiddeti ayarla, olay liderini atama.
- Hafifletme: rollback/feature flag eylemlerini doğrula, kurtarma sinyallerini doğrula, regresyon izleme.
- İletişim: destek ekibini bilgilendir, dahili güncelleme yap, halka açık / durum güncellemesini kararlaştır, müşteri mesajlaşmasını yakala.
Kontrol listesi maddelerini zaman damgalı ve atfedilebilir yapın ki bunlar olay kaydının bir parçası olsun.
Destekleyici belgeleri bağlayın (bağlam kaybolmasın)
Olaylar nadiren tek bir araçta yaşar. Yanıtlayıcıların bağlayabileceği bağlantılar sunun:
- Panolar ve belirli grafikler
- Log sorguları
- Ticket/issue kayıtları
- Sohbet dizileri veya war-room kanalları
- Runbooklar ve playbooklar
Filtrelenebilir olsun diye “tiplenmiş” bağlantıları tercih edin (ör. Runbook, Ticket).
İlgili olduğunda SLA/SLO etkisini kaydedin
Kuruluşunuz güvenilirlik hedefleri tutuyorsa, SLO etkilendi (evet/hayır), tahmini hata bütçesi tüketimi ve müşteri SLA riski gibi hafif alanlar ekleyin. Bunları isteğe bağlı tutun—ama olay sırasında veya hemen sonra doldurulması kolay olsun.
Postmortem Şablonları ve İnceleme Akışı Oluşturun
Plan Before You Generate
Map roles, states, and templates first, then generate screens and data models.
İyi bir postmortem başlamak için kolay, unutması zor ve ekipler arasında tutarlı olmalıdır. Bunu sağlamanın en basit yolu varsayılan bir şablon sunmak (az zorunlu alanla) ve postmortemi olay kaydından otomatik doldurmaktır, böylece insanlar düşünmeye zaman harcar—tekrar yazmaya değil.
Pratik bir postmortem şablonu (ne eklemeli)
Yerleşik şablonunuz yapı ile esnekliği dengelemeli:
- Özet: düz dilde ne olduğu (2–5 cümle)
- Etkİ: kim/ne etkilendi, ne kadar sürdü, kullanıcıya yansıyan semptomlar ve iş etkisi (geciken siparişler, hata oranı, ihlal edilen SLA'lar)
- Kök neden: birincil teknik/süreç neden. Olgusal tutun, suçlamadan kaçının.
- Katkıda bulunan faktörler: izleme boşlukları, belirsiz sahiplik, riskli değişiklik zamanlaması gibi ikincil sorunlar
- İyi giden / yanlış giden / şanslı olduğumuz yerler: dürüst, uygulanabilir çıkarımlar üreten yönlendiriciler
“Kök neden”i hızlı yayımlama için başta isteğe bağlı yapabilirsiniz; ancak nihai onaydan önce zorunlu kılın.
Postmortemi olay zaman çizelgesine otomatik bağlayın
Postmortem ayrı bir belgede yüzmesin. Bir postmortem oluşturulduğunda otomatik olarak ekleyin:
- Olay zaman çizelgesi (anahtar güncellemeler, durum değişiklikleri, hafifletme adımları)
- Katılımcılar (olay komutanı, yanıtlayanlar, iletişim sorumluları)
- Eserler (ilgili ticket'lar, panolar, log bağlantıları—referans olarak saklanır)
Bunları postmortem bölümlerini ön-doldurmak için kullanın. Örneğin, “Etkİ” bloğu olayın başlama/bitiş zamanları ve mevcut şiddetiyle başlayabilir; “Yaptıklarımız” zaman çizelgesi girdilerinden çekilebilir.
Öğrenmeyi destekleyen inceleme ve onay akışı
Postmortemlerin takılı kalmaması için hafif bir iş akışı ekleyin:
- Taslak (olay kapanınca otomatik oluşturulabilir veya elle)
- İncelemede (genellikle IC + servis sahibi gibi atanan gözden geçirenler)
- Onaylandı (kilitlenmiş özet + karar notları kaydedilir)
- Yayınlandı (dahili olarak paylaşıldı; isteğe bağlı müşteriyle paylaşım)
Her adımda karar notları kaydedin: ne değişti, neden değişti ve kim onayladı. Bu, “sessiz düzenlemeler”i önler ve gelecekteki denetimler veya öğrenme incelemeleri için kolaylık sağlar.
UI'yi basit tutmak isterseniz, incelemeleri yorumlar gibi ele alın ve açık sonuçlarla (Onayla / Değişiklik iste) saklayın; nihai onayı değiştirilemez bir kayıt olarak tutun.
Dilerseniz “Yayınlandı”yı durum güncellemeleri iş akışınıza bağlayın (ör. /blog/integrations-status-updates) ama içeriği elle kopyalamadan.
Eylem Öğelerini Tamamlanana Kadar İzleyin
Postmortemler sadece takip işleri yapıldığında gelecekteki olayları azaltır. Eylem öğelerini bir belgenin alt paragrafı olarak değil, uygulamanızda birinci sınıf nesneler olarak ele alın.
Eylem öğelerini yapılandırılmış kayıtlar olarak tanımlayın
Her eylem öğesi tutarlı alanlara sahip olmalıdır ki ölçülebilsin:
- Sahip (tek sorumlu kişi, yürütme paylaşılabilir)
- Bitiş tarihi (ve isteğe bağlı “başlama tarihi”)
- Öncelik (P0–P3 veya Yüksek/Orta/Düşük)
- Durum (Açık, Yapılıyor, Engellendi, Tamamlandı, Yapılmayacak)
- Doğrulama kriteri (düzeltmenin nasıl teyit edileceği)
Küçük ama faydalı meta veriler ekleyin: etiketler (örn. “izleme”, “dokümantasyon”), bileşen/servis ve “oluşturulduğu yer” (olay ID ve postmortem ID).
İşleri olaylar arasında bulmayı kolaylaştırın
Eylem öğelerini tek bir postmortem sayfasına hapsetmeyin. Sunun:
- Sahip, servis, etiket ve durum ile küresel arama
- “gecikmiş”, “bu hafta bitiyor”, “engellendi”, “yüksek öncelik” gibi filtreler
- Takım/servise göre sayımlar: tamamlama oranı, ortalama kapanma süresi
Bu, takipleri dağınık notlardan ziyade operasyonel bir kuyruğa dönüştürür.
Tekrarlayan işler ve dış bağlantılar (opsiyonel)
Bazı görevler yinelenir (çeyreklik oyun günleri, runbook incelemeleri). Bir yinelenen şablon destekleyin; bu, programlı olarak yeni öğeler oluşturur ama her örneği bağımsız izlenebilir kılar.
Ekipler başka bir takip aracı kullanıyorsa, bir eylem öğesinin dış referans bağlantısı ve dış ID içermesine izin verin; yine de uygulamanız olay bağlantısı ve doğrulama için kaynak olsun.
Hatırlatmalar ve yükseltme kuralları
Hafif hatırlatmalar ekleyin: bitiş tarihine yaklaşanlarda sahipleri uyarın, gecikmiş öğeleri takım liderine işaretleyin ve kronik gecikmeleri raporlarda gösterin. Kuralları yapılandırılabilir tutun ki ekipler kendi nöbet operasyonlarına ve iş yükü gerçeklerine uyarlayabilsin.
İzinler, Erişim Kontrolü ve Denetlenebilirlik
Use a Proven Tech Base
Get a React frontend with a Go and PostgreSQL backend from one conversation.
Olaylar ve postmortemler genellikle hassas detaylar içerir—müşteri kimlikleri, dahili IP’ler, güvenlik bulguları veya tedarikçi sorunları. Net erişim kuralları aracı işbirliği için yararlı tutar ve veri sızıntılarını engeller.
İzin seviyelerini tanımlayın
Anlaşılır, küçük bir rol setiyle başlayın:
- Sadece görüntüleme (paydaşlar): olay özetlerini, zaman çizelgelerini ve nihai postmortemleri okuyabilir; düzenleyemez. Liderlik, müşteri desteği ve ortak ekipler için ideal.
- Editörler (yanıtlayanlar): olay oluşturabilir, güncelleme ekleyebilir, zaman çizelgesini yönetebilir ve postmortem taslağı oluşturabilir.
- Yöneticiler (sahipler): rolleri yönetebilir, şablonları yapılandırabilir, entegrasyonları bağlayabilir ve erişim anlaşmazlıklarını çözebilir.
Birden fazla takımınız varsa, rolleri servis/ekip bazında kapsamlandırmayı düşünün (ör. “Ödemeler Editörleri”)—genel geniş erişim vermektense.
Hangi alanlar özel, hangileri paylaşılabilir olsun karar verin
İnsanlar alışkanlık kazanmadan önce içeriği sınıflandırın:
- Yalnızca dahili alanlar: müşteri PII, güvenlik soruşturma notları, ham loglar, dahili sohbet dökümleri
- Paylaşılabilir alanlar: yüksek düzey etki, başlama/bitiş zamanları, hafifletmeler, halka açık durum güncellemeleri
Pratik bir desen, bölümleri Dahili veya Paylaşılabilir olarak işaretlemek ve dışa aktarma ile durum sayfalarında bunu zorunlu kılmaktır. Güvenlik olayları daha sıkı varsayılanlara sahip ayrı bir olay tipi gerektirebilir.
Güvenilir denetim günlükleri
Olaylar ve postmortemlerdeki her değişiklik için: kim değiştirdi, ne değişti ve ne zaman kaydedin. Şiddet, zaman damgaları, etki ve “nihai” onaylar gibi düzenlemeleri dahil edin. Denetim günlüklerini aranabilir ve düzenlenemez yapın.
Kimlik doğrulama ve oturum güvenliği
E-posta + MFA veya magic link gibi güçlü kimlik doğrulamayı yerleşik destekleyin ve kullanıcılarınız bekliyorsa SSO (SAML/OIDC) ekleyin. Kısa ömürlü oturumlar, güvenli çerezler, CSRF koruması ve rol değişikliklerinde otomatik oturum iptali kullanın. Rollout ile ilgili daha fazla düşünce için /blog/testing-rollout-continuous-improvement adresine bakabilirsiniz.
UX: Panolar, Arama ve Navigasyon
Bir olay aktifken insanlar tarama yapar—okumaz. UX’iniz güncel durumu saniyeler içinde açık hale getirmeli, aynı zamanda yanıtlayanların detaylara kaybolmadan inmesine izin vermelidir.
İlk tasarlamanız gereken temel ekranlar
Çoğu iş akışını kapsayan üç ekranla başlayın:
- Olay listesi (panel): durum rozeti, şiddet, başlık, etkilenen servis(ler), sahip/olay komutanı, son güncelleme zamanı ve süreyi gösteren tek tablo veya kart listesi.
- Olay detayı: tek bir olay hakkında her şeyin ana merkezi—özet, güncel durum, ana bağlantılar, katılımcılar ve eylem paneli.
- Zaman çizelgesi görünümü: güncellemelerin ve olayların kronolojik akışı (alarm, manuel notlar, durum değişiklikleri) büyük, okunaklı zaman damgalarıyla.
Basit bir kural: olay detay sayfası üstte “Şu an ne oluyor?” sorusunu, altta “Buraya nasıl geldik?” sorusunu yanıtlamalı.
Yanıtlayanların gerçekten kullandığı filtreleme ve arama
Olaylar hızla birikir; keşfi hızlı ve hoşgörülü yapın:
- Hızlı filtreler: servis, şiddet, durum (açık/hafifletiliyor/çözüldü/postmortem gerekli), etiket, tarih aralığı ve sahip.
- Arama: başlık, olay ID, etkilenen bileşenler ve etiketler üzerinde.
Nöbetçi mühendislerin her nöbet için filtreleri yeniden kurmaması için Benim açık olaylarım veya Bu hafta Sev-1 gibi kaydedilmiş görünümler sunun.
Durum rozetleri ve “güncel durum” tutarlılığı
Uygulama genelinde tutarlı, renk açısından güvenli rozetler kullanın (stres altındaki görüş için başarısız olan ince tonlardan kaçının). Aynı durum sözlüğünü liste, detay başlığı ve zaman çizelgesi olaylarında kullanın.
Bir bakışta yanıtlayanlar şunu görmelidir:
- Güncel durum + şiddet
- Son güncelleme zamanı (ve kim paylaştı)
- Sonraki kontrol noktası (ör. “Sonraki güncelleme 8 dk içinde”)
Baskı altındaki okunabilirlik
Tarama kolaylığını önceliklendirin:
- Büyük zaman damgaları ve net bölüm başlıkları
- Kaydırırken yapışkan olay başlığı
- Gürültülü veriler için katlanabilir bölümler (ham alarmlar, uzun loglar)
- Klavye dostu gezinme (/, n/p ile sonraki/önceki olay)
En kötü anı düşünün: birisi uykusuz ve telefondan çağırılıyor; UI hala doğru eyleme hızlıca yönlendirmeli.
Entegrasyonlar: Alarmlar, Sohbet, Ticket ve Durum Güncellemeleri
Entegrasyonlar, bir olay izleyiciyi “not almak için bir yer”den ekibin gerçekten olayları yönettiği sisteme dönüştürür. Bağlanmanız gereken sistemleri listeleyerek başlayın: izleme/observability (PagerDuty/Opsgenie, Datadog, CloudWatch), sohbet (Slack/Teams), e-posta, ticketing (Jira/ServiceNow) ve bir durum sayfası.
Entegrasyon stilini seçin
Çoğu ekip karışık bir yaklaşım kullanır:
- Inbound webhooklar (alarmlar ve sohbet komutları için) — hızlı, gerçek zamanlı, düşük işletim maliyeti.
- Polling (bir araç olayları push edemiyorsa); aralıkları konservatif tutun ve sonuçları önbelleğe alın.
- Manuel bağlama (alarm URL'sini yapıştırma, ticket anahtarını ekleme) bir yedek olarak kalmalı (API'ler bozulduğunda yardımcı olur).
Yinelenen olayları önleyin (idempotency)
Alarmlar gürültülüdür, tekrar edilir ve sırası karışabilir. Sağlayıcı olay başına kararlı bir idempotency key tanımlayın (örn: provider + alert_id + occurrence_id) ve bunu benzersiz kısıtlama ile saklayın. Tekilleştirme için kurallar belirleyin: “aynı servis + aynı imza 15 dakika içinde” yeni olay oluşturmak yerine mevcut olaya eklenmelidir.
Sınırlar ve hata modlarını tanımlayın
Uygulamanızın neyi sahiplenip neyi kaynak araçta bırakacağı konusunda açık olun:
- Uygulamanız olay kaydını, zaman çizelgesini, rolleri ve postmortemleri sahiplenebilir.
- Ticket sistemi iş yürütme ve onayları sahiplenebilir.
Bir entegrasyon başarısız olduğunda, kibarca düşüşe geçin: yeniden deneme için kuyruklayın, olay üzerinde bir uyarı gösterin (“Slack gönderimi gecikti”) ve operatörlerin manuel devam etmesine her zaman izin verin.
Fazladan iş olmadan durum güncellemeleri
Durum güncellemelerini birinci sınıf çıktı olarak ele alın: UI’daki yapılandırılmış bir “Güncelleme” eylemi sohbete yayınlayabilmeli, olay zaman çizelgesine ekleyebilmeli ve isteğe bağlı olarak durum sayfasına senkronize edebilmelidir—yanıtlayandan aynı mesajı üç kez yazmasını istemeden.
Mimari ve Teknoloji Yığını Seçimleri
Make It Easy to Access
Launch an internal tool with a custom domain your team will remember.
Olay aracınız "kesinti sırasında" çalışacak bir sistemdir; bu yüzden yenilikten çok sadelik ve güvenilirlik tercih edin. En iyi yığın genellikle ekibinizin inşa edip gece 2'de hata ayıklayıp işletmeye alabileceği yığındır.
Ekibinizin sahiplenebileceği bir yığın seçin
Mühendislerinizin zaten üretimde gönderdiği şeyi seçin. Yaygın bir web framework (Rails, Django, Laravel, Spring, Express/Nest, ASP.NET) genellikle tek bir kişinin bildiği yeni bir frameworkten daha güvenli bir tercihtir.
Veri depolama için ilişkisel bir veritabanı (PostgreSQL/MySQL) olay kayıtları için uygundur: olaylar, güncellemeler, katılımcılar, eylem öğeleri ve postmortemler tümü işlemler ve net ilişkilerden faydalanır. Redis yalnızca gerçekten cache, kuyruk veya geçici kilitlere ihtiyaç varsa ekleyin.
Barındırma, yönetilen bir platform (Render/Fly/Heroku-benzeri) veya mevcut bulutunuz (AWS/GCP/Azure) olabilir. Mümkünse yönetilen veritabanları ve yedeklemeleri tercih edin.
Gerçek zaman: websocket mi yoksa periyodik yenileme mi
Aktif olaylar gerçek zamanlı güncellemelerle daha iyi hissedilir, ancak ilk gün websocket zorunlu değildir.
- Periyodik yenileme (polling) uygulaması daha kolaydır ve işletimi daha basittir. Birçok ekip için zaman çizelgesini 10–30 saniyede bir güncellemek “yeterince iyi”dir.
- Websockets/SSE aynı anda çok sayıda izleyici olduğunda, hızlı hareket eden güncellemeler olduğunda veya sohbet benzeri iş birliği istediğinizde değer kazanır.
Pratik bir yaklaşım: API/olay tasarımınızı polling ile başlamak ve daha sonra websocket'e yükseltmek üzere hazırlayın.
Kendi aracınız için gözlemlenebilirlik
Bu uygulama bir olay sırasında başarısız olursa, olayın bir parçası haline gelir. Şunları ekleyin:
- Yapılandırılmış loglar (kimin neyi değiştirdiği ve istek bağlamı)
- Metrikler (gecikme, hata oranı, kuyruk derinliği, websocket bağlantıları)
- Hata izleme (yakalanmamış istisnalar, frontend çökme raporlaması)
Yedeklemeler, göçler ve felaket kurtarma
Bunu üretim sistemi gibi ele alın:
- Otomatik günlük yedeklemeler (ve düzenli geri yükleme testleri)
- Güvenli şema göçleri (genişlet/ daralt desenleri, göç CI kontrolleri)
- Minimal bir DR planı: yeni bir bölgede/hesapta nasıl ayağa kaldırılır, ana ortam kapalıyken verilere nasıl erişilir
Yanlış tasarıma bağlı kalmadan hızlı prototipleme
İş akışını ve ekranları doğrulamak için tam bir yapıya yatırım yapmadan önce bir prototip isterseniz, vibe-coding yaklaşımı işe yarayabilir: Koder.ai gibi bir araçla detaylı bir sohbet spesifikasyonundan çalışan bir prototip üretin ve ardından gerçek olay tatbikatlarıyla yineleyin. Koder.ai, gerçek React ön yüzleri ile Go + PostgreSQL arka uç üretebildiği ve kaynak kodu dışa aktarabildiği için erken sürümleri “atılacak prototip” veya sertleştirilebilecek bir başlangıç olarak ele alabilirsiniz—gerçek tatbikatlardan elde ettiğiniz öğrenmeleri kaybetmeden.
Test, Yayınlama ve Sürekli İyileştirme
Bir olay takip uygulamasını prova etmeden yayınlamak kumarlıktır. En iyi ekipler aracı diğer operasyonel sistemler gibi ele alır: kritik yolları test edin, gerçekçi tatbikatlar yapın, kademeli yayımlar yapın ve gerçek kullanım verisine göre ayarlayın.
Kritik yolları uçtan uca test edin
İnsanların stres altındayken güveneceği akışlara odaklanın:
- Olay oluştur, şiddet ata ve yanıtlayanları bildir
- Güncelleme gönder (durum değişiklikleri dahil), zaman çizelgesindeki sıralamayı doğrula ve düzenlemelerin net işaretlendiğinden emin ol
- Olayı çöz ve kapat, sonra son durumdan postmortem oluştur
- Bağlantıların ve referansların (servisler, sahipler, ticketlar, sohbet dizileri) korunduğunu doğrula
Zaman damgaları, saat dilimleri ve olay sıralaması gibi kırılmaması gerekenleri doğrulayan regresyon testleri ekleyin. Olaylar bir anlatıdır—zaman çizelgesi yanlışsa güven kaybolur.
İzinleri ve denetlenebilirliği doğrulayın
İzin hataları operasyonel ve güvenlik riski taşır. Şunları kanıtlayan testler yazın:
- Sadece yetkili roller şiddeti değiştirebilir, kritik alanları düzenleyebilir veya olayı kapatabilir
- Sadece görüntüleme kullanıcıları kısıtlı olaylara erişemez
- Her hassas eylem bir denetim izi bırakır (kim, ne, ne zaman) ve denetim günlüğü düzenlenemez
Erişim kaybı veya ekip yeniden yapılanması gibi “yakın kaçış” durumlarını da test edin.
Gerçek yanıtlayanlarla masaüstü tatbikatları yapın
Geniş yayımdan önce uygulamayı birincil kaynak olarak kullanarak masaüstü tatbikatları düzenleyin. Kuruluşunuzun tanıdığı senaryoları seçin (ör. kısmi kesinti, veri gecikmesi, üçüncü taraf arızası). Sürtünce noktalarını gözlemleyin: kafa karıştırıcı alanlar, eksik bağlam, çok fazla tıklama, belirsiz sahiplik.
Geri bildirimi hemen yakalayın ve küçük, hızlı iyileştirmelere dönüştürün.
Pilot ile yayınlayın ve geri bildirim döngüsü kurun
Bir pilot ekip ve birkaç ön yapılandırılmış şablonla (olay tipleri, kontrol listeleri, postmortem formatları) başlayın. Kısa eğitim verin ve uygulamadan bağlantılı kısa bir “bu şekilde olay yönetiriz” kılavuzu sağlayın (ör. /docs/incident-process).
Benimsenme metriklerini izleyin ve sürtünce noktalarını yineleyin: oluşturma süresi, % güncellemeye sahip olaylar, postmortem tamamlama oranı ve eylem öğesi kapatma süresi. Bunları uyum değil, ürün metrikleri gibi ele alın ve her sürümde iyileştirin.