OLTP vs OLAP: Jargondan Uzak Ne Anlama Geliyorlar
İnsanlar “OLTP” ve “OLAP” dediğinde, veritabanının iki çok farklı kullanım biçiminden bahsediyorlar.
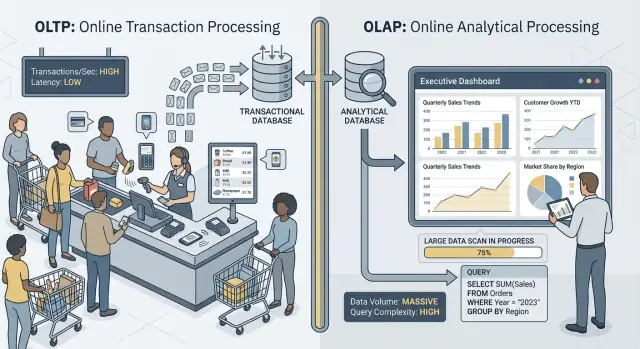
OLTP: işi yürüten veritabanı
OLTP (Online Transaction Processing), her seferinde hızlı ve doğru olması gereken günlük işlemlerin arkasındaki işyüküdür. Düşünün: “bu değişikliği hemen kaydet.”
Tipik OLTP işleri arasında sipariş oluşturma, stok güncelleme, ödeme kaydı veya müşteri adresi değişikliği yer alır. Bu işlemler genellikle küçük (birkaç satır), sık ve milisaniyeler içinde cevap vermelidir çünkü bir kişi ya da başka bir sistem bekliyordur.
OLAP: işi açıklayan veritabanı
OLAP (Online Analytical Processing), ne olduğunu ve neden olduğunu anlamak için kullanılır. Düşünün: “çok veri tara ve özetle.”
Tipik OLAP görevleri panolar, trend raporları, kohort analizleri, tahminler ve şu gibi “dilimle ve parçala” sorularıdır: “Gelir son 18 ayda bölge ve ürün kategorisine göre nasıl değişti?” Bu sorgular genellikle çok sayıda satır okur, ağır agregasyonlar yapar ve saniyeler (veya dakikalar) sürebilir—ve bunun yanlış olduğu anlamına gelmez.
Aynı veri, farklı hedefler—ve farklı ihtiyaçlar
Ana fikir basit: OLTP hızlı, tutarlı yazmaları ve küçük okumaları optimize eder, oysa OLAP büyük okumaları ve karmaşık hesaplamaları optimize eder. Hedefler farklı olduğundan, en iyi veritabanı ayarları, indeksler, depolama düzeni ve ölçeklendirme yaklaşımları da genellikle farklı olur.
Ayrıca sözcük seçimine dikkat: nadiren, hiç değil. Bazı küçük ekipler, özellikle veri hacmi mütevazıysa ve sorgu disiplini sıkıysa bir süre tek veritabanı kullanabilir. Sonraki bölümler ilk bozulan şeyleri, yaygın ayrım desenlerini ve raporlamayı üretimden güvenli şekilde nasıl taşıyacağınızı anlatır.
Hızlı örnekler
- Ödeme (OLTP): bir müşteri “Öde”ye tıklar ve uygulamanız bir sipariş, ödeme durumu ve stok güncellemesi yazar.
- Rapor paneli (OLAP): bir yönetici binlerce (veya milyonlarca) siparişi toplayıp dönüşüm oranı, ortalama sipariş değeri ve haftalık eğilimleri göstermek için bir pano açar.
Farklı Hedefler, Farklı Başarı Ölçütleri
OLTP ve OLAP her ikisi de “SQL kullanır” ama farklı işlere göre optimize edilir ve bu, her birinin neyi başarı saydığına yansır.
OLTP: hız, eşzamanlılık ve doğruluk
OLTP (işlemsel) sistemler günlük operasyonları çalıştırır: ödeme akışları, hesap güncellemeleri, rezervasyonlar, destek araçları. Öncelikler açıktır:
- Küçük okuma/yazmalar için hızlı yanıt süreleri (milisaniyeler düşünülebilir)
- Yavaşlamadan çok sayıda eşzamanlı kullanıcı
- Doğruluk ve tutarlılık, çünkü yanlış bir bakiye veya çift sipariş gerçek bir iş problemi olur
Başarı genellikle p95/p99 istek süreleri, hata oranı ve sistemin pik eşzamanlılık altındaki davranışıyla ölçülür.
OLAP: tarama, toplama ve esneklik
OLAP (analitik) sistemler “Bu çeyrekte ne değişti?” veya “Yeni fiyatlandırmadan sonra hangi segment ayrıldı?” gibi soruları yanıtlar. Bu sorgular genellikle:
- Büyük veri taramaları yapar
- Agregasyonlar (SUM, COUNT, yüzdelikler) ve join'ler gerçekleştirir
- Analistler keşfettikçe ve soruları rafine ettikçe sıkça değişir
Başarı burada daha çok sorgu throughput'u, içgörüye ulaşma süresi ve karmaşık sorguları her rapor için tek tek el ayarı yapmadan çalıştırabilme yeteneği ile ölçülür.
“Her şey için tek bir sistem” neden ödünlere yol açar
Her iki işyükünü tek veritabanına zorladığınızda, aynı anda küçük, yüksek hacimli işlemlerde ve büyük, keşifsel taramalarda mükemmel olmasını beklersiniz. Sonuç genellikle uzlaşmadır: OLTP tahmin edilemez gecikmeler yaşar, OLAP üretimi korumak için kısıtlanır ve ekipler kimin sorgularına “izin verildiği” konusunda tartışır. Ayrı hedefler, ayrı başarı ölçütleri ve genellikle ayrı sistemler hak eder.
Kaynak Rekabeti: Analitik İşlemler İşlemleri Çaldığında
OLTP (uygulamanızın günlük işlemleri) ve OLAP (raporlama ve analiz) aynı veritabanında çalıştığında, aynı sınırlı kaynaklar için kavga ederler. Sonuç sadece “raporlar yavaş” değildir. Genellikle daha yavaş ödeme akışları, takılan girişler ve tahmin edilemez uygulama arızaları olur.
CPU ve bellek: uzun sorgular vs kısa sorgular
Analitik sorgular genellikle uzun süren ve ağırdır: büyük tablolar arasında join'ler, agregasyonlar, sıralama ve gruplama. CPU çekirdeklerini ve hash join’ler ile sıralama için bellek tamponlarını tekeline alabilirler.
Oysa işlemsel sorgular genellikle küçüktür ama gecikmeye duyarlıdır. CPU doygunluğu veya bellek baskısı sık sık tahliye gerektirirse, bu küçük sorgular büyük sorguların arkasında beklemeye başlar—her işlem sadece birkaç milisaniye iş gerektirse bile.
Disk I/O: büyük taramalar vs çok küçük okuma/yazmalar
Analitik genellikle büyük tablo taramaları tetikler ve çok sayıda sayfa ardışık olarak okur. OLTP işyükü bunun tersini yapar: birçok küçük, rastgele okuma ve sürekli indeks/log yazımı.
Birlikte koyduğunuzda veritabanı depolama alt sistemi uyumsuz erişim desenleriyle uğraşmak zorunda kalır. OLTP'ye yardımcı olan önbellekler analitik taramalarla “yıkanabilir” ve disk raporlar için veri akışı yaptığı sırada yazma gecikmesi zirve yapabilir.
Bağlantı havuzu baskısı ve kuyruklanma
Birkaç analist geniş sorgular çalıştırdığında bağlantıları dakikalarca meşgul edebilir. Uygulamanız sabit boyutlu bir havuz kullanıyorsa, istekler boş bir bağlantı bekleyerek kuyruğa girer. Bu kuyruklanma etkisi sağlıklı bir sistemi bozukmuş gibi hissettirebilir: ortalama gecikme kabul edilebilir görünse bile kuyruk uçları (p95/p99) acı verici hale gelir.
Kullanıcıların gerçekten fark ettiği şeyler
Dışarıdan bu durum time-out'lar, yavaş ödeme akışları, gecikmiş arama sonuçları ve genel olarak kararsız davranış olarak görünür—çoğunlukla “sadece raporlama sırasında” veya “sadece ay sonu” olur. Uygulama ekibi hatalar görür; analitik ekip yavaş sorgular görür; gerçek sorun altında yatan ortak kaynak rekabetidir.
Veri Düzeni ve İndeksleme İhtiyaçları Zıt Yönlere Çeker
OLTP ve OLAP sadece veritabanını farklı kullanmaz—fiziksel tasarım açısından karşıt ödüller verirler. İkisini tek bir yerde tatmin etmeye çalıştığınızda genellikle pahalı ve hâlâ yetersiz bir uzlaşma ortaya çıkar.
OLTP: hızlı, seçici aramalar için optimize edilmiş
İşlemsel işyükü kısa sorguların hakimiyetindedir: bir siparişi getir, bir stok satırını güncelle, tek bir kullanıcının son 20 olayını listele.
Bu, OLTP şemalarını satır-odaklı depolamaya ve nokta aramalarını ve küçük aralık taramalarını destekleyen indekslere (genellikle birincil anahtarlar, yabancı anahtarlar ve birkaç yüksek değerli ikincil indeks) iter. Amaç yazmalar için öngörülebilir düşük gecikmedir.
OLAP: tarama, gruplayıp özetleme için optimize edilmiş
Analitik genellikle çok sayıda satırı ve birkaç sütunu okur: “bölgeye göre haftalık gelir”, “kampanyaya göre dönüşüm oranı”, “marjına göre en iyi ürünler”.
OLAP sistemleri yalnızca gereken sütunları okumak için kolonel depolama, hızlı filtreleme için partitioning ve raporların aynı toplamları tekrar hesaplamasını önlemek için ön-agregasyon (materialized views, rollups, summary tables) gibi özelliklerden faydalanır.
“Her şey için indeks” geri teper
Yaygın bir tepki, her pano hızlı olsun diye indeks eklemektir. Ancak her ekstra indeks yazma maliyetini artırır, depolamayı büyütür ve bakım işlerini yavaşlatır. Sonuç olarak raporları hızlandırmak için genelde OLAP-odaklı çözümler daha verimlidir.
Sorgu planlayıcıları ve istatistiklerin kayması (basitçe)
Veritabanları sorgu planlarını istatistiklere göre seçer—filtrelerin kaç satır döndüreceği, bir indeksin ne kadar seçici olduğu ve verinin dağılımı gibi tahminler. OLTP veriyi sürekli değiştirir. Dağılımlar kaydıkça istatistikler eskir ve planlayıcı dünün verisi için harika olan bir planı bugün seçebilir.
Ağır OLAP sorguları karışınca, “en iyi plan” tahmin edilemez hale gelir ve bir işyükü için yapılan ayarlar genellikle diğerini kötüleştirir.
Kilitleme, MVCC ve Bakımın Yan Etkileri
Veritabanınız “eşzamanlılığı desteklese” bile, ağır raporlama ile canlı işlemleri karıştırmak tahmin edilemez yavaşlamalara yol açar—ve bunları müşteriye açıklamak zordur.
Uzun sorgular yine kilit sorunları yaratır
OLAP tarzı sorgular genellikle çok sayıda satırı tarar, birden fazla tabloyu join eder ve saniyelerce veya dakikalarca çalışır. Bu süre boyunca şema nesneleri üzerinde kilitler tutabilirler (örneğin geçici yapılara sıralama/agregasyon için) ve sıkça dolaylı olarak kilit rekabetini artırırlar çünkü birçok satırı “oyunda” tutarlar.
MVCC olsa bile, veritabanı okuyucular ve yazıcıların birbirini bloklamaması için birden çok satır versiyonunu takip etmek zorundadır. Bu yardımcı olur ama özellikle güncellenen sıcak tablolar söz konusu olduğunda rekabeti ortadan kaldırmaz.
MVCC'nin gizli maliyeti: temizleme zorlaşır
MVCC, eski satır versiyonlarının veritabanı güvenle kaldırana kadar kalmasına neden olur. Uzun süre açık kalan bir rapor eski bir snapshot tutarsa, temizleme alanı geri alamaz.
Bunun etkilediği şeyler:
- Vacuum/çöp toplama: "Ölü" tuple/versiyonlar hızla kaldırılamaz.
- Bloat/fragmentation: depolama büyür, indeksler daha az verimli olur, önbellekler daha az işe yarar.
- Sıkıştırma baskısı: bazı motorlar daha ağır arka plan işleri yapar; bu da OLTP'den I/O ve CPU çalar.
Sonuç: raporlama veritabanını daha çok çalıştırır ve zamanla sistemi yavaşlatır.
İzolasyon seviyeleri gecikme değişkenliğini artırır
Raporlama araçları genellikle daha güçlü izolasyon talep eder (veya kazara uzun bir işlem içinde çalışır). Daha yüksek izolasyon kilit beklemelerini ve motorun yönetmesi gereken versiyon sayısını artırır. OLTP tarafında bu, çoğu yazma hızlı giderken bazılarının aniden takılmasına neden olur.
Pratik örnek: ay sonu raporu siparişleri yavaşlatır
Ay sonunda finans, tüm ayın siparişlerini ve satırlarını tarayan bir "ürüne göre gelir" sorgusu çalıştırır. Bu sorgu çalışırken yeni sipariş yazmaları kabul edilir ama vacuum eski versiyonları geri alamaz ve indeksler karmaşa yaşar. Sipariş API'si ara sıra time-out'lar görür—sistem "down" olmadığı halde rekabet ve temizlik yükü gecikmeleri limitlerinizi aşar.
İş Yükü Dalgalanması ve Tahmin Edilemez Gecikme
Recover quickly from schema changes
Use snapshots and rollback when a migration or query change causes surprises.
OLTP sistemleri tahmin edilebilirliğe dayanır. Bir ödeme, destek bileti veya bakiye güncellemesi “çoğunlukla iyi” ise hızlı olması yeterli değildir—kullanıcılar yavaş anları fark eder. OLAP ise genellikle patlamalıdır: birkaç ağır sorgu saatlerce sessiz kalıp sonra aniden çok CPU, bellek ve I/O tüketebilir.
Dalgalar normal iş sebepleriyle olur
Analitik trafik genellikle belirli rutinlerin etrafında toplanır:
- Sabah "standup panoları"nda birçok kişinin aynı grafikleri yenilemesi
- Saat başında tetiklenen planlı raporlar
- Ay sonu kapanışı ve çeyrek değerlendirmeleri gibi uzun tarama ve join'leri tetikleyen olaylar
OLTP trafiği daha istikrarlı olabilir. Her iki işyükü aynı veritabanını paylaştığında, analitik sıçramaları işlemler için tahmin edilemez gecikmeye dönüşür—time-out'lar, yavaş sayfa yüklemeleri ve artan retry'ler.
Limitler ve zamanlama yardımcı olur—ama uyumsuzluğu düzeltmez
Raporları gece çalıştırmak, eşzamanlılığı sınırlamak, statement timeout koymak veya sorgu maliyet cap'leri gibi taktiklerle zararı azaltabilirsiniz. Bunlar üretimde raporlama için değerli kısıtlayıcılardır.
Ancak temel gerilim kalkmaz: OLAP sorguları büyük soruları cevaplamak için çok kaynak kullanmayı amaçlar, OLTP ise gün boyu küçük, hızlı kaynak dilimlerine ihtiyaç duyar. Beklenmedik bir pano yenilemesi, ad-hoc sorgu veya backfill içeri girince paylaşılan veritabanı tekrar açığa çıkar.
Gürültülü komşu problemi
Paylaşılan altyapıda bir "gürültülü" analitik kullanıcı veya iş doğru bir şey yapıyor olsa bile önbelleği tekeline alabilir, diski doyurabilir veya CPU planlamasını baskılayabilir. OLTP işyükü yan hasar haline gelir ve en zor olan, hataların rastgele görünmesidir: net tekrar eden hatalar yerine gecikme zirveleri yaşanır.
Operasyonel Karmaşıklık: Yedekleme, Güvenlik ve Kapasite Planlama
OLTP ve OLAP'ı karıştırmak sadece performans baş ağrılarına yol açmaz—günlük operasyonlar da zorlaşır. Veritabanı her şeyin tek kutusu olur ve her operasyonel görev her iki işyükünün risklerini devralır.
Yedeklemeler, geri yüklemeler ve felaket kurtarma yavaşlar
Analitik tablolar genellikle geniş ve hızlı büyür (daha fazla geçmiş, daha fazla sütun, daha fazla agregat). Bu ekstra hacim kurtarma hikâyenizi değiştirir.
Tam bir yedek daha uzun sürer, daha fazla depolama kullanır ve yedek penceresini kaçırma olasılığını artırır. Geri yüklemeler daha da kötüdür: acilen kurtarmanız gerektiğinde sadece uygulamanın çalışması için gereken işlemsel verileri değil, aynı zamanda iş için gerekli olmayan büyük analitik veri setlerini de geri yüklersiniz. Felaket kurtarma testleri daha uzun sürer ve bu yüzden daha seyrek yapılır—bu da tam tersi bir etki yaratır.
Kapasite planlama tahmin oyunu olur
İşlemsel büyüme genellikle öngörülebilirdir: daha fazla kullanıcı, daha fazla sipariş, daha fazla satır. Analitik büyüme çoğunlukla dalgalıdır: yeni bir pano, yeni bir saklama politikası veya bir ekibin “bir yıl daha ham eventi saklayalım” demesi.
İkisi birlikteyken kolayca şu sorulara cevap veremezsiniz:
- Büyüyoruz çünkü ürün başarılı mı yoksa raporlar daha mı fazla tarih saklıyor?
- İşlemler için daha hızlı depolama mı, yoksa analitik için daha ucuz depolama mı gerekli?
Bu belirsizlik aşırı sağlama (gereksiz maliyet) veya yetersiz sağlama (sürpriz kesintiler) ile sonuçlanır.
Koruyucular adil şekilde uygulaması zor
Paylaşılan veritabanında masum bir sorgu olaya dönüşebilir. Sonunda sorgu zaman aşımı, işyükü kotası, zamanlanmış raporlama pencereleri veya işyükü yönetim kuralları gibi koruyucular eklersiniz. Bunlar yardımcı olur ama kırılgandır: uygulama ve analistler aynı limitler için yarışır ve bir grup için yapılan politika değişikliği diğerini bozabilir.
Güvenlik ve erişim kontrolü karışıklaşır
Uygulamalar genellikle dar, amaç odaklı izinlere ihtiyaç duyar. Analistler keşfetme ve doğrulama için genellikle geniş okuma erişimine ihtiyaç duyar. İkisini aynı veritabanında toplamak, raporun çalışması için daha geniş ayrıcalık verme baskısını artırır; bu da hataların etki alanını büyütür ve daha fazla insanın hassas operasyonel veriyi görmesini sağlar.
Ölçekleme ve Maliyet: Çoğunlukla İki Kere (veya Daha Fazla) Ödersiniz
Evolve to CDC when ready
Start simple, then export code as you add ELT models and analytics services.
OLTP ve OLAP'ı aynı veritabanında çalıştırmaya çalışmak ilk bakışta daha ucuz görünebilir—ta ki ölçeklemeye başlayana kadar. Sorun sadece performans değil. Her bir işyükünü ölçeklendirmenin “doğru” yolu farklı altyapıya iter ve birleştirildiğinde pahalı ödünler yapmak zorunda kalırsınız.
OLTP ölçeklemesi yazma odaklıdır (ve genellikle zordur)
İşlemsel sistemler yazmalarla sınırlıdır: birçok küçük güncelleme, sıkı gecikme hedefleri ve hemen emilmesi gereken ani yükler. OLTP'yi ölçeklendirmek genellikle dikey ölçeklendirme (daha fazla CPU, daha hızlı diskler, daha fazla bellek) anlamına gelir çünkü yazma-ağır işyükleri kolayca dağıtılamaz.
Dikey sınırlar dolunca shard'lama veya diğer yazma-ölçekleme desenlerine bakarsınız. Bu ek mühendislik yükü ve uygulamada dikkatli değişiklikler gerektirir.
OLAP ölçeklemesi compute-odaklıdır (ve sıklıkla elastiktir)
Analitik işyükleri farklı ölçeklenir: uzun taramalar, ağır agregasyonlar ve yüksek okuma throughput'u. OLAP sistemleri genellikle dağıtık compute ekleyerek ölçeklenir ve birçok modern düzenlemede compute ile storage ayrıdır—böylece sorgu gücünü veri taşımadan bağımsız ölçekleyebilirsiniz.
OLAP, OLTP veritabanını paylaşıyorsa analitiği bağımsız ölçekleyemezsiniz. Tüm veritabanını ölçeklendirirsiniz—işlemler iyi olsa bile.
Gizli fatura: analitik için OLTP-dereceli kaynaklar ödemek
Raporlar çalışırken işlemlerin hızlı kalması için ekipler üretim veritabanını aşırı boyutlandırır: ekstra CPU rezervi, yüksek performanslı depolama ve daha büyük instance'lar. Bu, analitiği çalıştırmak için OLTP fiyatları ödemeniz demektir.
Ayrım, her sistemi işine göre boyutlandırmanıza izin verdiği için genelde maliyeti düşürür: OLTP düşük gecikmeli yazmalar için, OLAP patlamalı büyük okumalar için. Sonuç çoğunlukla iki sistem olmasına rağmen toplamda daha ucuz olur çünkü raporlama için premium transactional kapasiteyi satın almayı bırakırsınız.
OLTP ve OLAP'ı Ayıran Yaygın Mimariler
Çoğu ekip işlemsel işyükü (OLTP) ile analitik işyükü (OLAP) arasına ikinci bir “okuma-odaklı” sistem ekleyerek ayırır.
Desen 1: Raporlama için read replica
İlk adım olarak sıkça kullanılan read replica (veya follower) ile OLTP veritabanının bir kopyasında BI araçları sorguları çalıştırılır.
Artıları: uygulamada az değişiklik, tanıdık SQL, hızlı kurulum.
Eksileri: aynı motor ve şema olduğundan ağır raporlar replica CPU/I/O'yu doyurabilir; bazı raporlar replikalarda bulunmayan özellikler isteyebilir; ve replikasyon gecikmesi sayıları dakikalarla geride bırakabilir. Gecikme ayrıca olaylar sırasında “neden üretimle eşleşmiyor?” tartışmalarına yol açar.
En iyi uyum: küçük ekipler, mütevazı veri hacmi, “neredeyse gerçek zaman” hoş ama kritik değil ve raporlama sorguları kontrollü.
Desen 2: Adanmış veri ambarı / analitik veritabanı
Burada OLTP yazmalar ve nokta okumalar için optimize kalır, analitik ise tarama, sıkıştırma ve büyük agregasyonlar için tasarlanmış bir veri ambarına gider.
Artıları: öngörülebilir OLTP performansı, daha hızlı panolar, analistler için daha iyi eşzamanlılık ve maliyet/performans tuning'in net ayrımı.
Eksileri: başka bir sistemi işletirsiniz ve analitik için uygun bir veri modeli (çoğunlukla star şeması) oluşturmanız gerekir.
En iyi uyum: artan veri, çok sayıda paydaş, karmaşık raporlama veya katı OLTP gecikme gereksinimleri.
Desen 3: CDC tabanlı pipeline ile analitiğe akış
Periyodik ETL yerine OLTP logundan değişiklikleri CDC ile veri ambarına akıtırsınız (genellikle ELT ile birlikte).
Artıları: OLTP'ye daha az yük bindirerek daha taze veri, daha kolay incremental işlem ve daha iyi denetlenebilirlik sağlar.
Eksileri: daha fazla hareketli parça ve şema değişikliklerinin dikkatli yönetimi gerekir.
En iyi uyum: daha büyük hacimler, yüksek tazelik ihtiyacı ve veri pipeline'larına hazır ekipler.
OLTP'den OLAP'a Veriyi Güvenli Taşımak
İşlemsel veritabanından analitik sisteme veri taşımak "tablo kopyalamaktan" çok güvenilir, düşük etki yaratan bir pipeline kurmaktır. Amaç basit: analitik ihtiyacı olanı alsın, üretim trafiğine zarar vermesin.
ETL vs ELT (düz İngilizce)
ETL (Extract, Transform, Load) veriyi ambara yüklemeden önce temizler ve yeniden şekillendirir. Ambar içinde hesaplama pahalıysa veya sadece küratörlü çıktıyı saklamak istiyorsanız uygundur.
ELT (Extract, Load, Transform) önce nispeten ham veriyi yükler, sonra ambar içinde dönüştürür. Kurulumu genellikle daha hızlıdır ve evrilmesi daha kolaydır: kaynak tarihçesini saklayabilir ve dönüşümleri ihtiyaç değiştikçe güncelleyebilirsiniz.
Pratik kural: iş mantığı sık değişiyorsa ELT işi azaltır; yönetişim sıkıysa ETL daha uygun olabilir.
CDC temelleri: ağır sorgular olmadan değişimi yakalamak
Change Data Capture (CDC), OLTP logundan yapılan insert/update/delete değişikliklerini analytics'e taşır. Büyük tabloları tekrar tekrar taramak yerine sadece değişeni taşırsınız.
Sunduğu olanaklar:
- Yakın-gerçek-zamanlı raporlama üretimde büyük okumalar yapmadan
- Replays ve backfill gerektiğinde analytics tablolarını yeniden oluşturma
- Değişim olaylarını saklarsanız geçmiş izleme (kim ne zaman değiştirdi)
Veri tazeliği: gerçek-zaman mı, yakın-gerçek-zaman mı, günlük mü
Tazelik bir iş kararıdır ve teknik maliyeti vardır.
- Gerçek-zaman (saniyeler): operasyonel panolar için en iyisi ama en zor olanıdır; küçük pipeline aksaklıkları hemen görünür.
- Yakın-gerçek-zaman (dakikalar): yaygın bir tatlı nokta—hızlı karar almayı sağlar ama aşırı karmaşık değildir.
- Günlük toplu: en basit ve en ucuz; finans tarzı raporlar için "dün" yeterliyse idealdir.
Net bir SLA (örneğin: "veri en fazla 15 dakika geride") belirleyin ki paydaşlar tazelikten ne anladıklarını bilsin.
Sessiz başarısızlıkları önleyen veri kalitesi kontrolleri
Pipeline'lar genelde sessizce bozulur—ta ki biri sayıları fark edene kadar. Hafif ama etkili kontroller ekleyin:
- Şema değişiklikleri: yeni sütunlar, yeniden adlandırmalar veya tip değişiklikleri veriyi null yapabilir.
- Gecikmeli gelen olaylar: saatler sonra gelen siparişler veya ödemeler; "lookback window" ile ele alın.
- Deduplication: retry'ler ve replay'lar çift sayım yapabilir; stabil ID'ler ve idempotent yüklemeler kullanın.
Bu güvenlikler OLAP'ın güvenilir kalmasını sağlarken OLTP'yi korur.
Tek Veritabanı Paylaşmanın Kabul Edilebilir Olduğu Durumlar
Protect production from dashboards
Set a clear reporting boundary so dashboards do not slow checkouts.
OLTP ve OLAP'ı birlikte tutmak otomatik olarak yanlış değildir. Uygulama küçük, raporlama ihtiyaçları dar ve analitiğin müşteri deneyimini yavaşlatmayacağından emin olmak için sert sınırlar koyabiliyorsanız makul bir geçici tercih olabilir.
İşleyen durumlar
Hafif analitiğe ve sıkı sorgu limitlerine sahip küçük uygulamalar genellikle tek veritabanı ile iyi gidebilir—özellikle erken aşamada. "Hafif"in ne demek olduğunu dürüstçe tanımlamak önemlidir: birkaç pano, mütevazı satır sayıları ve sorgu çalışma süresi ve eşzamanlılığı için net bir tavan.
Dar kapsamlı, tekrarlayan raporlar için materialized views veya summary tablolar analitik maliyeti azaltabilir. Ham işlemleri taramak yerine günlük toplamları, üst kategorileri veya müşteri düzeyindeki rollup'ları önceden hesaplamak çoğu sorguyu kısa ve öngörülebilir tutar.
İş kullanıcıları gecikmiş rakamlara razıysa off-peak raporlama pencereleri yardımcı olur. Ağır işleri gece veya düşük trafikte çalıştırın ve raporlama için daha sıkı izinlere ve kaynak sınırlamalarına sahip ayrı bir rol düşünün.
Eklemeniz gereken koruyucular
- Statement timeout'ları ayarlayın ve kaçan sorguları iptal edin.
- Rapor kullanıcıları için eşzamanlılık sınırı koyun.
- Çekirdek işlemler için p95/p99 gecikmeyi raporlama sürelerinden ayrı izleyin.
Bölünmenin zamanı geldiğinin net işaretleri
Eğer işlem gecikmesinde artış, rapor çalıştırırken tekrarlayan olaylar, bağlantı havuzu tükenmesi veya "bir sorgu production'ı düşürdü" hikayeleri görüyorsanız, güvenli bölgeyi aştınız demektir. Bu noktada veritabanlarını ayırmak (en azından read replica kullanmak) optimizasyondan ziyade temel operasyonel hijyen olur.
Pratik Geçiş Kontrol Listesi: Paylaşılan'dan Ayrılmışa
Analitiği üretim veritabanından taşımak büyük bir yeniden yazımdan çok, işi görünür kılmak, hedefler belirlemek ve kontrollü adımlarla göç etmektir.
1) Bugün gerçekten ne olduğunu envanterle
Varsayımlar yerine kanıtla başlayın. Şunu listleyin:
- Sıklığa ve p95/p99 gecikmeye göre en üst OLTP uç noktaları/sorguları (checkout, login, create order vb.)
- Çalışma süresine, tarama hacmine ve iş önceliğine göre en üst OLAP raporları/panoları
BI araçlarından gelen ad-hoc SQL, planlı ihracatlar ve CSV indirmeleri gibi "gizli" analizleri dahil edin.
2) Hedefleri tanımlayın: OLTP SLO'ları ve analitik tazeliği
Optimizasyon yapacağınız hedefleri yazın:
- OLTP SLO'ları: p95/p99 gecikme, hata oranı ve sürdürülecek pik throughput
- Analitik tazeliği: kabul edilebilir ne kadar eski (5 dakika, 1 saat, ertesi gün) ve pipeline bozulursa yeniden inşa süresi
Bu, "yavaş" vs "kabul edilebilir" tartışmalarını önler ve doğru mimariyi seçmenize yardımcı olur.
3) Bir ayrılma yolu seçin
Hedefleri karşılayan en basit seçeneği seçin:
- Read replica: okuma-ağır raporlama için en hızlı benimseme, ama replikalar yine de yüklenebilir ve gecikme olur
- Warehouse: büyük taramalar, çoklu join'ler ve uzun geçmiş için en iyi yer; genelde BI için doğru yerdir
- CDC pipeline (ETL/ELT): üretime yük bindirmeden yakın-gerçek-zamanlı analitik istiyorsanız en uygunudur
4) Güvenli bir şekilde devreye alın (önce paralel çalıştırın)
- Tanımları (zaman dilimleri, iadeler, "aktif kullanıcı" vb.) doğrulayın ki sayılar eşleşsin.
- Eski ve yeni panoları tam bir iş döngüsü boyunca paralel çalıştırın.
- En ağrılı sorgularla başlayarak rapor-rapor geçiş yapın.
- Paydaşlar yeni kaynağa güvenince "üretimde doğrudan raporlama" erişimini kilitleyin.
5) Geri dönüşü önleyecek koruyucular ekleyin
Replica gecikmesi/pipeline gecikmelerini, pano çalışma sürelerini ve ambar harcamasını izleyin. Sorgu bütçeleri (timeout, concurrency limitleri) ekleyin ve bir olay oyun kitabı hazırlayın: tazelik düştüğünde, yükler arttığında veya temel metrikler sapma gösterdiğinde ne yapılacak.
Eğer uygulamayı kendiniz inşa ediyorsanız pratik not
Ürününüz erken aşamadaysa ve hızlı ilerliyorsanız, en büyük risk analitiği doğrudan çekirdek işlem yoluna kazara dahil etmektir (örneğin, pano sorgularının sessizce “production-kritik” hale gelmesi). Bunu önlemenin yolu ayrımı baştan tasarlamaktır—hatta mütevazı bir read replica ile başlasanız bile—ve bunu mimari kontrol listesine dahil etmektir.
Platformlar gibi Koder.ai burada yardımcı olabilir; çünkü OLTP tarafını (React uygulama + Go servisler + PostgreSQL) prototiplemenize ve raporlama/warehouse sınırını planlama modunda çizebilmenize izin verir. Ürün büyüdükçe kaynak kodunu dışa aktarabilir, şemayı evriltip CDC/ELT bileşenleri ekleyebilirsiniz—böylece "üretimde raporlama" kalıcı bir alışkanlığa dönüşmez.