26 Kas 2025·8 dk
Operasyonel Tıkanıklıkları İzleyen Bir Web Uygulaması Nasıl Oluşturulur
İş akışı verisini yakalayan, tıkanıklıkları tespit eden ve ekiplerin gecikmeleri düzeltmesine yardımcı olan bir web uygulamasını planlama, tasarlama ve dağıtma adım adım rehberi.
Sorunu ve Kararları Belirleyerek Başlayın
Bir süreç izleme web uygulaması ancak belirli bir soruyu yanıtlıyorsa işe yarar: “Nerede takılıyoruz ve bununla ilgili ne yapmalıyız?” Ekranları çizmeden veya bir web uygulama mimarisi seçmeden önce, operasyonunuzda “tıkanıklık”ın ne anlama geldiğini tanımlayın.
Tıkanıklık sayılanı tanımlayın
Tıkanıklık bir adım (ör. “QA incelemesi”), bir ekip (ör. “tedarik”), bir sistem (ör. “ödeme geçidi”) veya hatta bir tedarikçi (ör. “taşıyıcı teslimatı”) olabilir. Gerçekte yöneteceğiniz tanımları seçin. Örneğin:
- Bir adım, ortalama kuyruk süresi 24 saati aştığında tıkanıklık sayılır.
- Bir ekip, üzerinde çalışan iş miktarı 3 gün boyunca belirlenen eşiklerin üzerinde kaldığında tıkanıklık olur.
- Bir sistem, arızalar çevrim süresinde kabul edilen aralığın üzerine sıçrama yaptığında tıkanıklık olur.
Uygulamanın hangi kararları desteklemesi gerektiğini listeleyin
Operasyon panonuz sadece raporlamak yerine harekete geçirmeli. Hızlandırmak ve daha emin kararlar almak istediğiniz kararları yazın, örneğin:
- Personel düzenlemesi: “Bu hafta Kişi A'yı Takım A'dan Takım B'ye mi kaydırıyoruz?”
- Önceliklendirme: “Hangi sipariş/bilet SLA'ları korumak için sırayı atlamalı?”
- Otomasyon: “Hangi adım önce otomatikleştirilmek için yeterince kararlı (ve yeterince maliyetli)?”
Birincil kullanıcıları ve ihtiyaçlarını belirleyin
Farklı kullanıcılar farklı görünüm ister:
- Operasyon yöneticileri bugünkü müdahale noktalarını gösteren net bir görünüm ister.
- Takım liderleri bireysel kuyruklara, engellemelere ve teslim noktalarına inebilmelidir.
- Analistler tutarlı tanımlar ve iş akışı analitiği için dışa aktarımlar ister.
Uygulama için başarı metriklerini belirleyin
Uygulamanın işe yarayıp yaramadığını nasıl bileceğinizi karar verin. İyi ölçütler arasında benimseme (haftalık aktif kullanıcılar), raporlama için kazanılan zaman ve daha hızlı çözüm (tıkanıklıkları tespit ve düzeltme süresinin azalması) yer alır. Bu metrikler sizi özelliklerden çok sonuçlara odaklanmaya zorlar.
İş Akışını Seçin ve Basit Bir Süreç Haritası Yazın
Tabloları, panoları veya uyarıları tasarlamadan önce, bir cümlede tanımlayabileceğiniz bir iş akışı seçin. Amaç beklemelerin nerede olduğunu izlemek—bu yüzden küçük başlayın ve bir veya iki süreç seçin; örneğin sipariş karşılama, destek talepleri veya çalışan işe alımı gibi düzenli hacim üreten süreçler.
Sıkı bir kapsam, bitmiş tanımını net tutar ve proje farklı ekiplerin süreçlerin nasıl olması gerektiği konusunda anlaşamaması yüzünden tıkanmasını engeller.
1–2 yüksek sinyalli süreçle başlayın
Aşağıdaki özelliklere sahip iş akışlarını seçin:
- Yeterince sık gerçekleşir (örüntüleri görmek için veri sağlar)
- En az bir teslimat noktası içerir (kuyrukların oluştuğu yerler)
- Açık müşteri etkisi vardır (zaman, maliyet, memnuniyet)
Örneğin, “destek talepleri” çoğunlukla “müşteri başarı”dan daha iyidir çünkü iş birimi ve zaman damgalı eylemleri bellidir.
Adımları ve teslim noktalarını açık, anlaşılır dilde haritalayın
Süreç haritasını ekiplerin zaten kullandığı kelimelerle basit bir adım listesi olarak yazın. Burada politika dokümante etmiyorsunuz—iş öğesinin geçtiği durumları belirliyorsunuz.
Hafif bir süreç haritası şöyle görünebilir:
- Ticket oluşturuldu → triage edildi → atandı → görevli çalışıyor → müşteri bekleniyor → çözüldü
Bu aşamada teslim noktalarını açıkça işaretleyin (triage → atandı, görevli → uzman vb.). Kuyruk zamanı genellikle teslim noktalarında gizlenir ve bunlar daha sonra ölçmek isteyeceğiniz anlardır.
Her adım için başlangıç/bitiş olaylarını ve “tamam”ı tanımlayın
Her adım için iki şey yazın:
- Başlangıç olayı (adımın başladığını kanıtlayan nedir?)
- Bitiş olayı (adımın bittiğini kanıtlayan nedir?)
Gözlemlenebilir olsun. “Görevli araştırmaya başlıyor” öznel olabilir; “durum In Progress olarak değişti” veya “ilk dahili not eklendi” gibi izlenebilir olaylar tercih edin.
Ayrıca “tamam”ın ne anlama geldiğini tanımlayın ki uygulama kısmi tamamlamayı tamamlama ile karıştırmasın. Örneğin, “çözüldü” demek “çözüm mesajı gönderildi ve ticket Resolved olarak işaretlendi” anlamına gelebilir, sadece dahili işin bitmesi değil.
Daha sonra izleyeceğiniz yaygın istisnaları not edin
Gerçek operasyonlar karışık yollar içerir: yeniden çalışma, eskalasyonlar, eksik bilgiler ve yeniden açılan öğeler. İlk günde her şeyi modellemeye çalışmayın—sadece istisnaları yazın, böylece daha sonra kasıtlı olarak ekleyebilirsiniz.
“Ticket'ların %10–15'i Tier 2'ye yükseltiliyor” gibi basit bir not yeterlidir. Bu notları, istisnaların ayrı adımlar, etiketler veya ayrı akışlar olup olmayacağına karar verirken kullanacaksınız.
Tıkanıklıkları Gerçekten Ortaya Koyan Metrikleri Tanımlayın
Tıkanıklık bir his değil—belirli bir adımda ölçülebilir bir yavaşlamadır. Grafikler inşa etmeden önce, işin nerede biriktiğini ve nedenini kanıtlayacak sayıları belirleyin.
Küçük bir temel ölçüt seti seçin
Çoğu iş akışı için işe yarayan dört metrikle başlayın:
- Cycle time: bir öğenin başlangıçtan tamamlanmaya kadar geçen süresi.
- Wait/queue time: bir öğenin adımlar arasında hareketsiz kaldığı süre.
- Throughput: belirli bir zaman diliminde tamamlanan öğe sayısı.
- WIP (work in progress): sistemde şu anda bulunan öğe sayısı.
Bunlar hızı (cycle), boşta kalma (queue), çıktı (throughput) ve yükü (WIP) kapsar. Çoğu “gizemli gecikme”, belirli bir adımda artan kuyruk süresi ve WIP olarak görünür.
Hesaplamaları (uç durumlar dahil) tanımlayın
Tüm ekip tarafından üzerinde anlaşılabilecek tanımları yazın, sonra tam olarak bunu uygulayın.
- Cycle time =
done_timestamp − start_timestamp.- Uç durumlar: yeniden açılan öğeler (yeni bir döngü sayılacak mı yoksa orijinali mi uzatılacak), hiç başlamamış öğeler (cycle time'dan hariç tut, ama WIP'te say), eksik zaman damgaları (veri kalitesi olarak işaretle).
- Queue time = adımlar arasındaki, durumun “bekliyor” olduğu boşlukların toplamı.
- Uç durumlar: gece/hafta sonu (takvim zamanı vs iş saatleri), engellenmiş durumlar (daha net nedenler için normal beklemeden ayrı sayılabilir).
- Throughput = pencerede
done_timestampolan öğelerin sayısı.- Uç durumlar: iptaller (hariç tut veya ayrı takip et), kısmi tamamlamalar.
- WIP = belirli bir anda terminal durumda olmayan öğelerin sayısı.
- Uç durumlar: beklemeye alınmış öğeler (hala WIP, ama ayrı bir “blocked WIP” isteyebilirsiniz).
Kararları yönlendiren kırılımları seçin
Yöneticilerinizin gerçekten kullandığı dilimlemeleri seçin: ekip, kanal, ürün hattı, bölge ve öncelik. Amaç, “Nerede yavaş, kim için ve hangi koşullarda?” sorusunu yanıtlamaktır.
Zaman pencerelerini ve hedefleri belirleyin
Raporlama ritminizi belirleyin (günlük ve haftalık yaygındır) ve örneğin “yüksek öncelikli öğelerin %80'i 2 gün içinde tamamlanır” gibi SLA/SLO eşiklerini tanımlayın. Hedefler panoyu süs yerine eyleme dönüştürür.
Veri Kaynaklarınızı ve Toplama Yöntemini Planlayın
Tıkanıklık izleme uygulamasını en hızlı şekilde tıkayan şey verinin “zaten orada olacağını” varsaymaktır. Tabloları veya grafiklerini tasarlamadan önce her olayın ve zaman damgasının nereden geleceğini—ve bunları zaman içinde nasıl tutarlı tutacağınızı—yazın.
Halihazırda sahip olduğunuz kaynakları envantere alın
Çoğu operasyon ekibi işi birkaç yerde izler. Yaygın başlangıç noktaları:
- Teslim noktaları, günlük kayıtlar veya üretim sayımları için kullanılan elektronik tablolar
- ERP/CRM sistemleri (siparişler, müşteriler, karşılama adımları)
- Ticketing araçları (destek kuyruğu, değişiklik talepleri, bakım görevleri)
- İç veritabanları (depo taramaları, iş planlama tabloları, üretim yürütme verileri)
Her kaynak için ne sağlayabileceğini not edin: kalıcı bir kayıt kimliği, bir durum geçmişi (sadece mevcut durum değil) ve en az iki zaman damgası (adım girildi, adımdan çıkıldı). Bunlar yoksa kuyruk zamanı izleme ve çevrim süresi takibi tahmin olur.
Kaynağa uyan yakalama yöntemini seçin
Genelde üç seçenek vardır ve birçok uygulama karışım kullanır:
- API pull: ERP/CRM/ticketing araçlardan zamanlanmış senkron. Sayfalama, hız sınırları ve artımlı güncellemelerle başa çıkmanız gerekir.
- Webhooks: iş değiştikçe güncellemeleri anında push. Tersine sırada gelen olaylar ve yeniden deneme mekanizmaları için tasarım gerektirir.
- Manuel giriş / CSV yükleme: elektronik tablolardan başlayan ekipler için kullanışlı. Şablonlar, doğrulama ve net hata mesajları ile güvenli hale getirin.
Veri kalitesi için plan yapın (çünkü olacak)
Eksik zaman damgaları, kopyalar ve tutarsız statüler bekleyin (“In Progress” vs “Working”). Kuralları erken kurun:
- Üzerine yazmak yerine değiştirilemez bir olay günlüğünü tercih edin
- Kaynak kimliği + olay zamanı + statü ile çoğaltmaları ortadan kaldırın
- Statüleri uygulamanızın kanonik adımlarına normalize edin
- Güvenilir çevrim süresi hesabı üretemeyen kayıtları işaretleyin
Yenileme sıklığını belirleyin
Her süreç gerçek zaman gerektirmez. Karara göre seçin:
- Gerçek zamanlı: sevkiyat, destek triage, SLA riski
- Saatlik: depo throughput, kuyruk zamanı izleme
- Günlük: haftalık raporlama, sürekli iyileştirme incelemeleri
Bunu şimdi yazın; senkron stratejinizi, maliyetleri ve operasyon panosu beklentilerini belirler.
Zamana Dayalı Analiz İçin Tasarlanmış Bir Veri Modeli Oluşturun
Tıkanıklık izleme uygulaması, “Bu ne kadar sürdü?”, “Nerede bekledi?” ve “Yavaşlamadan hemen önce ne değişti?” gibi zaman sorularını ne kadar iyi cevaplayabildiğiyle var olur veya yok olur. Bu soruları desteklemenin en kolay yolu veriyi baştan olaylar ve zaman damgaları etrafında modellemektir.
Temel varlıklardan başlayın
Modeli küçük ve açık tutun:
- Process: genel iş akışı (ör. “Sipariş Karşılama”).
- Step: süreç içindeki bir aşama (ör. “Toplama”, “Paketleme”, “Gönderim”).
- Work item: adımlar arasında ilerleyen birim (ticket, sipariş, talep).
- Event: durum değişikliğini kaydeden olay (adıma girildi, atandı, engellendi, tamamlandı).
- User/Team ve Assignment: bir işi o anda kimin sahip olduğu.
Bu yapı, özel durumlar icat etmeden adım başına çevrim süresi, adımlar arası kuyruk süresi ve süreç boyunca throughput ölçmenizi sağlar.
“Mevcut durum” alanları yerine olay günlüğünü tercih edin
Her durum değişikliğini bir değiştirilemez olay kaydı olarak ele alın. current_step üzerine yazıp geçmişi kaybetmek yerine, şu tür bir olay ekleyin:
- work_item_id
- from_step → to_step (veya “entered_step”)
- event_type (assigned, started, blocked, completed)
- event_time
Hız için yine de bir “mevcut durum” anlık görüntüsü saklayabilirsiniz, ama analitikleriniz olay günlüğüne dayanmalı.
Zaman ve izlenebilirliği tartışılmaz yapın
Zaman damgalarını tutarlı şekilde UTC olarak saklayın. Ayrıca her iş öğesi ve olay üzerinde orijinal kaynak tanımlayıcılarını (ör. Jira issue key, ERP sipariş ID) tutun, böylece her grafik gerçek kayıtla izlenebilir.
İstisnaları çok fazla işlem yaratmadan yakalayın
Gecikmeleri açıklayan anları hafif alanlarla planlayın:
- reason_code ("Müşteri bekleniyor" gibi standart seçenekler)
- comment (isteğe bağlı metin)
- blocked_flag veya severity
Bunları isteğe bağlı ve doldurması kolay tutun; böylece öğrenirsiniz ama uygulamayı form doldurma egzersizine çevirmemiş olursunuz.
Ekibinize Uyan Bir Mimariden Seçin
Önce Metrikleri Planlayın
Ekranlar ve tablolar oluşturmadan önce varlıkları, metrikleri ve uç durumları kilitleyin.
“En iyi” mimari, ekibinizin yıllarca inşa edebileceği, anlayıp işletmeye devam edebileceği mimaridir. İşe alım havuzunuza ve mevcut becerilere uyan bir stack seçin—yaygın, iyi desteklenen seçimler arasında React + Node.js, Django veya Rails bulunur. Operasyon panosuna bağımlı bir uygulamayı çalıştırırken tutarlılık yenilikten daha iyidir.
Sistemin düzenli kalması için sorumlulukları ayırın
Bir tıkanıklık izleme uygulaması genellikle aşağıdaki katmanlara ayrıldığında daha iyi çalışır:
- Ingestion: formlar, entegrasyonlar veya içe aktarımlardan olayları alma.
- Storage: güvenilir yazımlar ve denetim geçmişi için ilişkisel veritabanı.
- Analytics queries: çevrim süresi, kuyruk süresi ve throughput hesaplamak için okuma-optimze sorgular veya görünümeler.
- UI/API: panoların hızlı ve öngörülebilir kalmasını sağlayan uç noktalar ve ekranlar.
Bu ayrım, örneğin yeni bir veri kaynağı eklediğinizde her şeyi yeniden yazmak zorunda kalmamanızı sağlar.
Hesaplamaların nerede yapılacağına karar verin
Bazı metrikler veritabanı sorgularında kolayca hesaplanır (ör. “son 7 gün içinde adım başına ortalama kuyruk süresi”). Diğerleri pahalıdır veya ön işlem gerektirir (yüzdelikler, anomali tespiti, haftalık kohortlar). Pratik bir kural:
- Gerçek zamanlı filtreler ve kırılımları veritabanında yapın.
- Ağır agregatları ön hesaplayıp arka plan işleriyle saklayın, panonun hızlı yüklenmesi için.
- Analitik katmanı ekleyin sadece ekibinizin bunu güvenle sürdüreceğinden eminseniz.
Performans için erken plan yapın
Operasyon panoları yavaşladığında başarısız olur. Zaman damgaları, iş akışı adımı ID'leri ve tenant/ekip ID'leri üzerinde indeksleme kullanın. Olay günlükleri için sayfalama ekleyin. Yaygın pano görünümleri (bugün, son 7 gün gibi) için önbellek kurun ve yeni olay geldiğinde geçersiz kılın.
Tartışmaları daha derinleştirmek isterseniz, karar kaydını repo'nuzda kısa tutun ki gelecekteki değişiklikler sürüklenmesin.
Hızlı bir yol: Hızla yayınlamak isteyen takımlar için
Metrik enstrümantasyonunu ve uyarıları tam inşa etmeden doğrulamak istiyorsanız, Koder.ai gibi bir vibe-coding tarzı platform ilk sürümü daha çabuk ayağa kaldırmanıza yardımcı olabilir: iş akışını, varlıkları ve panoları sohbetle tanımlarsınız, sonra üretilen React UI ve Go + PostgreSQL backend üzerinde yineleme yaparsınız.
Bir tıkanıklık izleme uygulaması için pratik avantaj, geribildirim hızıdır: API çekmelerini, webhooks veya CSV içe aktarmayı pilotlayabilir, drilldown ekranları ekleyebilir ve metrik tanımlarını haftalarca sürecek altyapı kurmadan değiştirebilirsiniz. Hazır olduğunuzda Koder.ai ayrıca kaynak kodu dışa aktarma ve dağıtım/barındırma desteği sunar, bu da prototipten bakımı yapılan dahili araca geçişi kolaylaştırır.
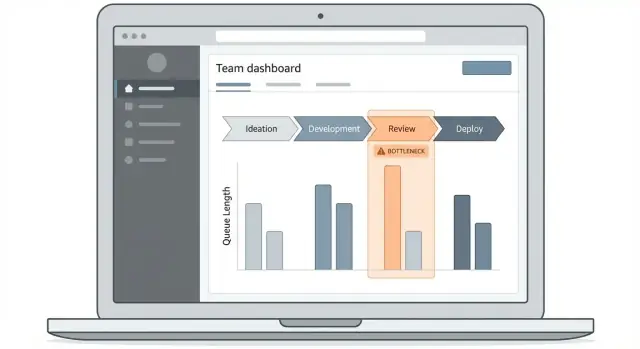
Pano ve Drill-Down Deneyimini Tasarlayın
Bir tıkanıklık izleme uygulaması, insanların “Şu anda iş nerede takılıyor ve buna hangi öğeler sebep oluyor?” sorusunu hızlıca cevaplayıp cevaplayamamasına göre başarılı olur. Panonuz, haftada bir gelen birinin bile yolu açık bulacağı şekilde bu yolu bariz kılmalıdır.
2–3 temel ekranda başlayın
İlk sürümü sıkı tutun:
- Genel bakış panosu: çevrim süresi, kuyruk süresi ve en çok engellenen adımlar için “durum tahtası”.
- İş öğesi listesi: gecikmelerden etkilenen öğelerin aranabilir, filtrelenebilir tablosu.
- Süreç detayı: her aşamada geçirilen süreyi ve teslim noktalarını gösteren adım adım görünüm.
Bu ekranlar, kullanıcıların karmaşık bir arayüz öğrenmesine gerek bırakmadan doğal bir drill-down akışı oluşturur.
Zamanı ve akışı açıklayan görseller kullanın
Operasyon sorularına uyan grafik türlerini seçin:
- Aşama hunisi: hacmin nerede biriktiğini gösterir (kuyrukları fark etmek için iyi).
- Aşamada geçirilen süre çubukları: adımları medyan ve yüzde dilimler üzerinden karşılaştırın, sadece ortalamaya bakmayın.
- Trend çizgileri: “iyileşiyor mu yoksa kötüleşiyor mu?” sorusunu haftalar içinde cevaplar.
- Isı haritaları: “Pazartesileri İnceleme” veya “gece vardiyası teslim noktaları” gibi örüntüleri açığa çıkarır.
Etiketleri sade tutun: “Bekleme süresi” yerine “Kuyruk gecikmesi” gibi açıklayıcı ifadeler kullanın.
Filtreleri tutarlı ve görünür yapın
Ekranlar arasında tek bir paylaşılan filtre çubuğu kullanın (aynı yerleşim, aynı varsayılanlar): tarih aralığı, ekip, öncelik ve adım. Aktif filtreleri chip'ler olarak görünür yapın ki insanlar sayıları yanlış okumamasın.
Net drill-down yolları tasarlayın
Her KPI kutucuğu tıklanabilir olmalı ve işe yarar bir yere götürmeli:
KPI → adım → etkilenen öğe listesi
Örnek: “En uzun kuyruk süresi”ne tıklamak adım detayını açar, ardından tek tıklama ile orada bekleyen tam öğeleri—yaşa, önceliğe ve sahibine göre sıralanmış—gösterir. Bu merakı somut bir yapılacak iş listesine dönüştürür; bu da panonun kullanılmasını sağlar.
Uyarılar ve Erken Uyarı Sinyalleri Ekleyin
Basit Bir Süreç Haritasından İnşa Edin
Süreç haritanızı adımlara, olaylara ve panolara çevirin—haftalar sürsün diye beklemeyin.
Panolar incelemeler için iyidir, ancak tıkanıklıklar genellikle toplantılar arasında daha çok zarar verir. Uyarılar uygulamanızı erken uyarı sistemine çevirir: haftayı kaybetmeden sorunları oluşurken bulursunuz.
Açık, sade kurallarla başlayın
Ekibin zaten “kötü” diye kabul ettiği küçük bir uyarı seti ile başlayın:
- Eşik aşımı: çevrim süresi veya kuyruk süresi bilinen bir limiti aştığında (örn. “İnceleme adımı > 24 saat”).
- Anormal artışlar: bugünün medyan çevrim süresi geçen haftaya göre %30 artmış.
- Sıkışmış öğeler: N saat/gün boyunca statü değişmemiş öğeler veya maksimum yaş sınırını geçen öğeler.
İlk sürümü basit tutun. Birkaç deterministik kural çoğu sorunu yakalar ve karmaşık modellerden daha güvenilirdir.
Hafif anomali kontrolleri ekleyin
Eşikler oturduktan sonra temel “bu garip mi?” sinyallerini ekleyin:
- Geçen haftaya göre yüzde değişim (aynı haftanın günü karşılaştırması yanlış alarmları azaltır).
- Hareketli ortalama sapması (ör. 7 günlük ortalama sürekli yükseliyorsa).
- Hacim uyumsuzlukları (girdi adımda çıktıdan daha hızlı artıyor).
Anomalileri "uyarı" yerine öneri olarak gösterin: kullanıcılara "Haberdar olun" etiketiyle sunun, kullanıcılar bunların faydalı olduğunu onaylayana kadar acil durum ilan etmeyin.
Uyarıları insanların çalıştığı yerlere gönderin
Ekiplerin neye uygun olduğunu seçebilmesi için birden çok kanal destekleyin:
- Yöneticiler için e-posta ve günlük özetler
- Gerçek zamanlı triage için Slack/Microsoft Teams
- Araç içi bildirimler sahipler için
Her uyarıyı eyleme geçirilebilir yapın
Bir uyarı “ne, nerede ve sonraki adım” sorusunu yanıtlamalı:
- Hangi adım etkilendi ve hangi zaman dilimi
- En büyük sürükleyiciler (ör. ekip, kategori, öncelik)
- İncelemek için doğrudan görünen bir hedef:
/dashboard?step=review&range=7d&filter=stuck
Uyarılar somut bir sonraki adrese götürmezse insanlar bunları susturur—bu yüzden uyarı kalitesini bir ürün özelliği olarak görün.
İzinler, Güvenlik ve Denetlenebilirlik ile İlgilenin
Bir tıkanıklık izleme uygulaması hızla “gerçek bilgi kaynağı” olur. Bu iyi—ta ki yanlış bir kişi tanımı değiştirene, hassas veriyi dışa aktarana veya panoyu ekibi dışına paylaşana kadar. İzinler ve denetim izleri kırmızı bant değildir; sayılara duyulan güveni korurlar.
Roller ve erişim kurallarını tanımlayın
Küçük, net bir rol modeliyle başlayın ve yalnızca gerektiğinde büyütün:
- Viewer: panolara ve raporlara salt-okunur erişim.
- Manager: ekiplere göre filtreleyebilir, kaydedilmiş görünümler oluşturabilir, uyarıları onaylayabilir ve not ekleyebilir (ancak genel ayarları değiştiremez).
- Admin: süreç tanımlarını, KPI formüllerini, entegrasyonları ve kullanıcı erişimini yönetir.
Her rolün ne yapabileceğini açıkça belirtin: ham olayları görüntüleme vs agregat metrikler, veri dışa aktarma, eşikleri düzenleme ve entegrasyon yönetimi.
Verileri ekip veya birim bazında ayırın
Birden fazla ekip uygulamayı kullanıyorsa, ayırmayı sadece UI'de değil veri katmanında uygulayın. Yaygın seçenekler:
- Multi-tenant: her kaydın bir
tenant_idsi olur ve her sorgu buna göre sınırlandırılır. - Partitions/projects: iş birimi başına ayrı “workspace”ler, bağımsız ayarlar ve panolar.
Yöneticilerin diğer ekiplerin verisini görüp göremeyeceğini erken kararlaştırın. Çapraz ekip görünürlüğünü varsayılan değil, kasıtlı bir izin yapın.
Güvenli kimlik doğrulama (SSO veya MFA uyumlu)
Kuruluşunuzda SSO (SAML/OIDC) varsa kullanın; böylece işten ayrılmalar ve erişim kontrolü merkezi yönetilir. Yoksa MFA hazır (TOTP veya passkeys) giriş, güvenli şifre sıfırlama ve oturum zaman aşımı uygulayın.
Değişiklikleri denetlenebilir yapın
Sonuçları değiştirebilecek veya veriyi açığa çıkarabilecek eylemleri kaydedin: dışa aktarımlar, eşik değişiklikleri, süreç düzenlemeleri, izin güncellemeleri ve entegrasyon ayarları. Kim yaptı, ne zaman yaptı, ne değişti (önce/sonra) ve nerede (workspace/tenant) kaydedin. Sorunlar hızlıca araştırılabilsin diye bir “Denetim Günlüğü” görünümü sağlayın.
İçgörüleri Eyleme ve Süreç İyileştirmelerine Dönüştürün
Bir tıkanıklık panosu ancak insanların ne yapacaklarını değiştirdiğinde önem taşır. Bu bölümün amacı “ilginç grafikler”i tekrar edilebilir bir işletme ritmine dönüştürmektir: karar ver, uygula, ölç ve işe yarayanı devam ettir.
Hafif bir tıkanıklık inceleme ritmi oluşturun
Basit bir haftalık ritim belirleyin (30–45 dakika) ve net sahipler atayın. Etkiye göre en büyük 1–3 tıkanıklıkla başlayın (ör. en yüksek kuyruk süresi veya en büyük throughput düşüşü), sonra her tıkanıklık için bir eylem kararlaştırın.
İş akışını küçük tutun:
- Sahip: her eylem için hesap verebilir bir kişi
- Bitiş tarihi: varsayılan olarak bir sonraki inceleme
- Tamamlanma tanımı: ölçülebilir bir değişiklik ("daha fazla araştır" değil)
Kararları doğrudan uygulama içinde yakalayın ki pano ve eylem günlüğü bağlı kalsın.
İyileştirmeleri birer deney olarak takip edin
Düzeltmeleri hızlı öğrenmek ve rastgele optimizasyonlardan kaçınmak için deney gibi ele alın. Her değişiklik için kaydedin:
- Hipotez (neyin yavaşlattığı ve neden)
- Değişiklik (ne yapacağınız)
- Beklenen etki (hangi metrik hareket etmeli ve ne kadar)
- Sonuç (gerçekte ne oldu)
Zamanla bu, çevrim süresini azaltan, yeniden çalışmayı düşüren ve işe yaramayanları ortaya çıkaran bir oyun kitabı olur.
Açıklama (annotation) ile bağlam ekleyin
Grafikler bağlam olmadan yanıltıcı olabilir. Zaman çizelgelerine (ör. yeni işe alınan, sistem kesintisi, politika güncellemesi) basit notlar ekleyin ki izleyiciler kuyruk süresi veya throughput'taki değişimleri doğru yorumlayabilsin.
Paylaşımı kolaylaştırın
Analiz ve raporlama için dışa aktarma seçenekleri sağlayın—CSV indirmeler ve zamanlanmış raporlar—böylece ekipler sonuçları operasyon güncellemelerine ve liderlik incelemelerine dahil edebilir. Zaten bir raporlama sayfanız varsa, panodan oraya bağlantı verin (ör. /reports).
Dağıtın, İzleyin ve Veriyi Taze Tutun
Bütçenizi Genişletin
Yaptıklarınızı paylaşarak veya ekip arkadaşlarını Koder.ai'ya davet ederek kredi kazanın.
Tıkanıklık izleme uygulaması ancak sürekli erişilebilir ve sayılar güvenilir kaldığı sürece kullanışlıdır. Dağıtımı ve veri tazeliğini ürünün bir parçası olarak görün, sonradan hatırlanacak şeyler değil.
Ayrı ortamlar ve tekrar edilebilir dağıtımlar kullanın
dev / staging / prod yapısını erken kurun. Staging prod'u yansıtmalı (aynı veritabanı motoru, benzer veri hacmi, aynı arka plan işleri) ki yavaş sorguları ve kırılan migrationları kullanıcılar görmeden yakalayabilesiniz.
Dağıtımları otomatikleştiren tek bir pipeline kurun: testleri çalıştırın, migrationları uygulayın, dağıtın, sonra hızlı bir smoke check yapın (giriş yap, panoyu yükle, alma işleminin çalıştığını doğrula). Dağıtımları küçük ve sık tutun; risk azalır ve rollback gerçekçi olur.
Uygulamayı ve pipeline'ı izleyin
İki açıdan izleme istersiniz:
- Uygulama sağlığı: hata oranları, gecikme, yavaş uç noktalar ve yavaş sorgular.
- Veri sağlığı: alma hataları, backlog boyutu ve "son olay alındığından beri geçen süre".
Kullanıcıların hissettiği belirtiler (panoların zaman aşımına uğraması) ve erken sinyaller (30 dakika boyunca artan bir kuyruk) için uyarı koyun. Ayrıca metrik hesaplama hatalarını izleyin—eksik çevrim süreleri iyileşme gibi görünebilir.
Veriyi taze tutun: geciken olaylar, düzeltmeler ve backfill'ler
Operasyon verileri geç, sıra dışı veya düzeltmeyle gelebilir. Aşağıları planlayın:
- Idempotent alma (aynı olayı yeniden işlemek iki kat saymaz).
- Backfill: bir kaynağın kapalı olduğu tarih aralıklarını doldurma.
- Yeniden hesaplama: referans verisi değiştiğinde (örn. vardiya takvimi güncellendi).
“Canlı”nın ne anlama geldiğini tanımlayın (örn. olayların %95'i 5 dakika içinde gelmeli) ve tazeliği UI'de gösterin.
Adım adım runbooklar yazın
Nasıl bir senkronu yeniden başlatacağınızı, dünkü KPI'ları nasıl doğrulayacağınızı ve bir backfill'in geçmiş rakamları beklenmedik şekilde değiştirmediğini doğrulamayı adım adım belgeleyin. Proje ile birlikte saklayın ve /docsten linkleyin ki ekip hızlıca müdahale edebilsin.
Kullanıcılarla İterasyon Yapın ve Kapsamı Genişletin
Bir tıkanıklık izleme uygulaması, insanlar ona güvenip gerçekten kullandığında başarılı olur. Bu ancak gerçek kullanıcıların gerçek soruları cevaplamaya çalışmasını izleyip ürünü o iş akışlarına göre sıkılaştırdığınızda olur.
Pilot ile başlayın ve nelerin kırıldığını öğrenin
Bir pilot ekiple ve az sayıda süreçle başlayın. Kapsamı dar tutun ki kullanımı gözlemleyip hızlı cevap verebilesiniz.
İlk hafta veya iki haftada, neyin kafa karıştırdığına veya eksik olduğuna odaklanın:
- Hangi grafikleri kullanıcılar yanlış okuyor?
- Drilldown yaparken nerede takılıyorlar?
- Hangi veriyi görmek bekliyorlar ama bulamıyorlar?
- Hangi operasyonel tıkanıklık onlar için “açık” ama uygulamada görünmüyor?
Geri bildirimi doğrudan araç içinde yakalayın (ana ekranlarda basit bir “Bu faydalı mı?” isteği iyi çalışır) ki toplantı hafızasına bağlı kalmayın.
Metrikleri doğrulayın, “pano tartışmalarını” önleyin
Daha fazla ekibe açmadan önce, hesap verme sorumluluğu olan kişilerle tanımları kilitleyin. Birçok yayılma, ekiplerin bir metriğin ne anlama geldiği konusunda anlaşamaması nedeniyle başarısız olur.
Her KPI (cycle time, queue time, yeniden çalışma oranı, SLA ihlalleri) için belgeleyin:
- Kesin başlangıç ve bitiş olayları
- Duraklamaların, hafta sonlarının ve eksik zaman damgalarının nasıl ele alındığı
- İstisnaların nasıl sayıldığı (iptaller, eskalasyonlar, yeniden açılmalar)
Sonra bu tanımları kullanıcılarla gözden geçirin ve UI'de kısa ipuçları ekleyin. Bir tanımı değiştiriyorsanız, sayılar neden hareket ettiğini anlamaları için açık bir değişiklik kaydı gösterin.
Uygulamayı karışıklığa çevirmeden kapsamı genişletin
Pilot ekibin iş akışı analitiği kararlı olduğunda özellikleri dikkatli ekleyin. Yaygın genişlemeler: özel adımlar (farklı ekipler aşamaları farklı adlandırır), ek kaynaklar (ticket + CRM + tablolar) ve gelişmiş segmentasyon (ürün hattı, bölge, öncelik, müşteri düzeyi).
Kullanışlı bir kural: aynı anda bir yeni boyut ekleyin ve bunun sadece raporlama mı yoksa kararları iyileştirme mi getirdiğini doğrulayın.
Onboarding'i kolay ve tekrarlanabilir yapın
Daha fazla ekibe açıldıkça tutarlılık gerekir. Kısa bir onboarding rehberi oluşturun: veriyi nasıl bağlayacakları, operasyon panosunu nasıl yorumlayacakları ve tıkanıklık uyarılarıyla nasıl hareket edecekleri.
Ürünün içindeki ilgili sayfalara ve içeriğe bağlantılar verin (ör. /pricing ve /blog), böylece yeni kullanıcılar eğitim beklemek yerine kendi başlarına cevap bulabilirler.