18 Ara 2025·6 dk
Postgres şema tasarımı planlama modu: adım adım yaklaşım
Postgres şema tasarımı planlama modu, kod üretmeden önce varlıkları, kısıtları, indeksleri ve migrationları tanımlamanıza yardımcı olur; sonraki yeniden yazmaları azaltır.
Postgres şema tasarımı planlama modu, kod üretmeden önce varlıkları, kısıtları, indeksleri ve migrationları tanımlamanıza yardımcı olur; sonraki yeniden yazmaları azaltır.
Eğer veritabanının şekli net olmadan endpointler ve modeller oluşturursanız, genellikle aynı özellikleri iki kez yeniden yazmak zorunda kalırsınız. Uygulama demo için çalışır, sonra gerçek veri ve kenar durumlar gelince her şey kırılgan hale gelir.
Çoğu yeniden yazma üç öngörülebilir sorundan kaynaklanır:
Her biri kod, testler ve istemci uygulamalarında dalga dalga değişikliklere neden olur.
Postgres şemasını planlamak, önce veri sözleşmesini belirlemek, sonra ona uyan kodu üretmek demektir. Pratikte bu, varlıkları, ilişkileri ve önemli birkaç sorguyu yazmak; sonra herhangi bir araç tablo ve CRUD iskeletini oluşturmadan önce kısıtları, indeksleri ve migration yaklaşımını seçmek anlamına gelir.
Bu, Koder.ai gibi hızlı kod üreten platformları kullandığınızda daha da önem kazanır. Hızlı üretim harikadır, ama şema kararlı olduğunda çok daha güvenilir olur. Üretilen modelleriniz ve endpointlerinizin sonradan daha az düzenleme gerektirmesi için şema oturmuş olmalı.
Planlamayı atladığınızda genellikle şu hatalar çıkar:
İyi bir şema planı basittir: varlıkların düz anlatımı, tablolar ve sütunların taslağı, ana kısıtlar ve indeksler, ve ürün büyüdükçe güvenle değişiklik yapmanızı sağlayan bir migration stratejisi.
Şema planlaması en iyi, uygulamanın neyi hatırlaması gerektiği ve kullanıcıların verilerle ne yapması gerektiğiyle başladığınızda işler. Amacı 2–3 düz cümleyle yazın. Basitçe açıklayamıyorsanız muhtemelen gereksiz tablolar oluşturursunuz.
Sonra veriyi oluşturan veya değiştiren eylemlere odaklanın. Bu eylemler gerçek satır kaynağıdır ve neyin doğrulanması gerektiğini gösterir. İsimler yerine fiiller düşünün.
Örneğin, bir rezervasyon uygulaması rezervasyon oluşturma, yeniden planlama, iptal, iade ve müşteriye mesaj gönderme eylemlerine ihtiyaç duyabilir. Bu fiiller hangi verilerin saklanması gerektiğini (zaman aralıkları, durum değişiklikleri, para miktarları) hızlıca gösterir, tablo isimlendirmesinden önce.
Okuma yollarınızı da yakalayın; çünkü okumalar yapı ve indekslemeyi belirler. İnsanların gerçekten kullanacağı ekranları veya raporları ve veriyi nasıl dilimleyeceklerini listeleyin: tarih sırasına göre sıralanmış ve durumla filtrelenmiş “My bookings”, müşteri adı veya rezervasyon referansına göre admin araması, lokasyona göre günlük gelir, ve kim neyi ne zaman değiştirdiğinin izlendiği audit görünümü.
Son olarak, audit geçmişi, soft delete, çok kiracılı ayrım veya gizlilik kuralları gibi şema seçimlerini etkileyen fonksiyonel olmayan ihtiyaçları not edin.
Eğer sonra kod üretecekseniz, bu notlar güçlü promptlara dönüşür. Nelerin gerekli olduğunu, nelerin değişebileceğini ve nelerin aranabilir olması gerektiğini açıklar. Koder.ai kullanıyorsanız, üretmeden önce bunları yazmak Planning Mode’u çok daha etkili kılar çünkü platform tahminler yerine gerçek gereksinimlerden çalışır.
Tablolarla uğraşmadan önce uygulamanızın neyi sakladığını düz dille yazın. Tekrarladığınız isimleri listeleyerek başlayın: user, project, message, invoice, subscription, file, comment. Her isim bir varlık adayıdır.
Sonra her varlık için bir cümle ekleyin: nedir ve neden var? Örneğin: “A Project is a workspace a user creates to group work and invite others.” Bu, data, items veya misc gibi belirsiz tablolardan kaçınmanızı sağlar.
Sahiplik bir sonraki büyük karardır ve neredeyse her sorguyu etkiler. Her varlık için karar verin:
Sonra kayıtları nasıl tanımlayacağınızı belirleyin. UUID, kayıtların birçok yerden oluşturulduğu veya tahmin edilemez ID istediğiniz durumlar için iyidir. Bigint ID’ler daha küçük ve hızlıdır. İnsan dostu bir tanımlayıcı gerekiyorsa, bunu birincil anahtar yapmak yerine ayrı tutun (örneğin, hesabın içinde benzersiz kısa bir project_code).
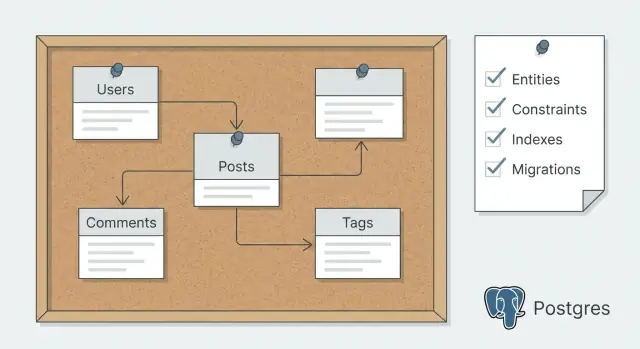
Son olarak ilişkileri diyagramlamadan önce kelimelerle yazın: bir kullanıcı birçok projeye sahip, bir proje birçok mesaja sahip ve kullanıcılar birçok projeye katılabilir. Her bağlantıyı gerekli mi yoksa isteğe bağlı mı olarak işaretleyin: “a message must belong to a project” vs “an invoice may belong to a project.” Bu cümleler daha sonra kod üretimi için tek doğru kaynağınız olur.
Varlıklar düz dille okunur hale gelince, her birini ihtiyaç duyduğunuz gerçek bilgileri saklayan bir tabloya dönüştürün.
Adlar ve tipler için tutarlı kalabileceğiniz kalıplarla başlayın: snake_case sütun isimleri, aynı fikir için aynı tip, ve öngörülebilir birincil anahtarlar. Zaman damgaları için timestamptz tercih edin ki zaman dilimleri sizi şaşırtmasın. Para için numeric(12,2) (veya kuruşları integer olarak saklama) kullanın; float kullanmayın.
Durum alanları için ya Postgres enum ya da izin verilen değerleri kontrol eden bir CHECK kısıtı kullanın.
Gerekli vs isteğe bağlı olanı NOT NULL ile çevirin. Bir değer satırın anlamı için zorunluysa required yapın. Eğer gerçekten bilinmiyorsa veya uygulanamıyorsa null’a izin verin.
Planlamak için pratik varsayılan sütun seti:
id (uuid veya bigint, bir yaklaşım seçin ve tutarlı kalın)created_at ve updated_atdeleted_at sadece gerçekten soft delete gerekiyorsa ve geri yükleme ihtiyacı varsacreated_by kim ne yaptığını izlemek istiyorsanızÇoktan çoğa ilişkiler neredeyse her zaman join tabloları olmalıdır. Örneğin, birden çok kullanıcı bir uygulamada işbirliği yapabiliyorsa, app_members oluşturun ve app_id ile user_id çiftinde benzersizliği uygulayın ki tekrarlar olmasın.
Geçmişi erken düşünün. Versiyonlama gerekeceğini biliyorsanız, her satırın kaydedildiği değiştirilemez bir tablo (app_snapshots) planlayın; her satır app_id ile bağlanır ve created_at ile damgalanır.
Kısıtlar şemanızın korkuluklarıdır. Hangi kuralların hangi servis, script veya admin aracı veritabanına dokunsa da her zaman doğru olması gerektiğine karar verin.
Kimlik ve ilişkilerle başlayın. Her tablonun birincil anahtarı olmalı ve her “belongs to” alanı gerçek bir yabancı anahtar olmalı, sadece uygun olduğunu umduğunuz bir integer değil.
Sonra çoğaltma durumlarını önleyin: aynı e-postaya sahip iki hesap veya aynı (order_id, product_id) ile iki line item gibi durumlar için benzersizlik ekleyin.
Erken planlanması gereken yüksek değerli kısıtlar:
PRIMARY KEY: Tutarlı bir stil seçin (UUID veya bigint) ki joinler öngörülebilir olsun.FOREIGN KEY: İlişkiyi açık yapın ve yetim satırları önleyin.UNIQUE: İş kimlikleri için (email, username) ve “bunlardan yalnızca biri” kuralları için kullanın.CHECK: amount >= 0, status IN ('draft','paid','canceled') veya rating BETWEEN 1 AND 5 gibi ucuz kurallar.NOT NULL: Gerçekte zorunlu alanlar için.Cascade davranışı, planlamanın sizi ileride kurtardığı yerdir. İnsanların beklentisi nedir diye sorun. Bir müşteri silindiğinde siparişleri genellikle kaybolmamalıdır. Bu durum, silmeleri kısıtlamayı ve geçmişi korumayı işaret eder. Order → line items gibi bağımlı veriler için cascade mantıklı olabilir çünkü öğelerin ebeveyn olmadan anlamı yoktur.
Daha sonra modelleri ve endpointleri ürettiğinizde, bu kısıtlar hangi hataların işleneceğini, hangi alanların zorunlu olduğunu ve hangi kenar durumların tasarım gereği imkansız olduğunu netleştirir.
İndeksler tek bir soruya cevap vermeli: Gerçek kullanıcılar için ne hızlı olmalı?
İlk olarak yayınlamayı planladığınız ekranlar ve API çağrılarıyla başlayın. Duruma göre filtrelenen ve en yeniye göre sıralanan bir liste sayfası, ilişkili kayıtları yükleyen bir detay sayfasından farklı ihtiyaçlara sahiptir.
Herhangi bir indeks seçmeden önce 5–10 sorgu deseni düz dille yazın. Örneğin: “Son 30 gündeki faturalarımı göster, paid/unpaid ile filtrele, created_at ile sırala” veya “Bir projeyi aç ve görevleri due_date'e göre listele.” Bu, indeks seçimlerini gerçek kullanımla ilişkilendirir.
İyi bir ilk indeks seti genellikle joinlerde kullanılan yabancı anahtar sütunları, durum, user_id, created_at gibi yaygın filtre sütunları ve her zaman tenant_id ile filtrelediğiniz durumlar için bileşik indeksler içerir (ör. (account_id, created_at)).
Bileşik indeks sırası önemlidir. En çok filtrelediğiniz ve en seçici olan sütunu öne koyun. Her istekte tenant_id ile filtreliyorsanız, çoğu indeksin başına genellikle tenant_id gelmelidir.
Her şeyi “olur ya” diye indekslemeyin. Her indeks INSERT ve UPDATE sırasında iş yükü ekler; nadir bir sorgunun biraz yavaş olması, gereksiz indekslerin verdiği zarardan genelde daha az kötüdür.
Metin aramayı ayrı planlayın. Sadece basit “içerir” eşleşmesi gerekiyorsa, ilk etapta ILIKE yeterli olabilir. Arama çekirdekse, daha sonra yeniden tasarlamamak için erken tsvector ile full-text aramayı planlayın.
Bir şema ilk tablolar oluşturulduğunda “bitti” sayılmaz. Özellik ekledikçe, bir hata düzelttikçe veya veriler hakkında daha fazla öğrendikçe değişir. Migration stratejinizi önceden belirlerseniz, kod üretiminden sonra acı verici yeniden yazmalardan kaçınırsınız.
Basit bir kuralı unutmayın: Veritabanını küçük adımlarla, bir özellikte değiştirin. Her migration kolayca incelenebilir ve her ortamda güvenle çalıştırılabilir olmalı.
Çoğu kırılma sütunların yeniden adlandırılması, kaldırılması veya tip değiştirmesinden gelir. Her şeyi tek seferde yapmak yerine güvenli bir yol planlayın:
Bu, daha fazla adım gerektirir ama kesinti ve acil düzeltmeleri azalttığı için gerçek hayatta daha hızlıdır.
Seed verileri de migrationların parçasıdır. Hangi referans tabloların “her zaman orada” olması gerektiğine karar verin (roller, statüler, ülkeler, plan tipleri) ve bunları öngörülebilir yapın. Bu tablolar için insert ve update işlemlerini özel migrationlara koyun ki her geliştirici ve her deploy aynı sonuçları alsın.
Erken beklentileri belirleyin:
Rollback her zaman mükemmel bir “down migration” olmayabilir. Bazen en iyi rollback bir yedekten geri yüklemektir. Koder.ai kullanıyorsanız, riskli değişiklikler öncesi snapshotlara güvenmeyi ve hızlı kurtarma için bunları kullanmayı da karar verin.
Küçük bir SaaS uygulaması hayal edin: insanlar takımlara katılır, projeler oluşturur ve görevleri takip eder.
İlk gün ihtiyaç duyduğunuz sadece alanları listeleyin:
İlişkiler basittir: bir takımın birçok projesi vardır, bir projenin birçok görevi vardır ve kullanıcılar team_members aracılığıyla takımlara katılır. Görevler bir projeye aittir ve bir kullanıcıya atanabilir.
Şimdi tipik olarak çok geç fark edilen bazı hataları önleyecek birkaç kısıt ekleyin:
İndeksler gerçek ekranlarla eşleşmeli. Örneğin, görev listesi proje ve state ile filtrelenip en yeniye göre sıralanıyorsa, tasks (project_id, state, created_at DESC) gibi bir indeks planlayın. “Benim görevlerim” önemli bir görünümse, tasks (assignee_user_id, state, due_date) gibi bir indeks yardımcı olur.
Migrationlar için ilk set güvenli ve sade olsun: tabloları oluşturun, birincil anahtarları, yabancı anahtarları ve temel benzersiz kısıtları ekleyin. Kullanımdan sonra ekleyeceğiniz şeyler (ör. soft delete için deleted_at) gibi değişiklikleri daha sonra yapın.
Çoğu yeniden yazma, ilk şemanın kurallar ve gerçek kullanım detaylarından yoksun olmasından kaynaklanır. İyi bir planlama geçişi mükemmel diyagramlarla değil, tuzakları erken görmeyle ilgilidir.
Sık yapılan bir hata, önemli kuralları sadece uygulama kodunda tutmaktır. Bir değer benzersiz veya zorunluysa, veritabanı da bunu zorlamalı. Aksi halde bir arka plan işi, yeni bir endpoint veya manuel bir import mantığınızı atlayabilir.
Bir diğer sık kaçırılan nokta indeksleri sonradan ele almak. Lansmandan sonra indeks eklemek çoğunlukla tahmin işine dönüşür ve gerçek yavaş sorgu join veya durum alanındaki filtre olabilir.
Çoktan-çoğa tablolar sessiz hataların kaynağıdır. Join tablonuz tekrarları engellemiyorsa aynı ilişki iki kez kaydedilebilir ve “neden bu kullanıcının iki rolü var?” gibi saatler sürecek hatalarla uğraşırsınız.
Ayrıca tabloları ilk oluşturup sonra audit log, soft delete veya event history gerektiğini fark etmek kolaydır. Bu eklemeler endpointleri ve raporları etkiler.
Son olarak JSON sütunları esneklik cazibesi taşır ama doğrulamaları kaldırır ve indekslemeyi zorlaştırır. JSON, gerçekten değişken yükler için uygundur; temel iş alanları için değil.
Kod üretmeden önce bu hızlı düzeltme listesini çalıştırın:
Burada durun ve planın, sürpriz peşinde koşmadan kod üretecek kadar tamamlanmış olduğundan emin olun. Amaç mükemmellik değil; sonraki yeniden yazmalara neden olacak boşlukları yakalamaktır: eksik ilişkiler, belirsiz kurallar ve uygulama ile uyumlu olmayan indeksler.
Hızlı pre-flight kontrolü:
amount >= 0 veya izin verilen statüler gibi).Kısa bir akıl testi: bir ekip arkadaşı yarın gelse, ilk endpointleri saatlerce “bu null olabilir mi?” veya “silince ne oluyor?” diye sormadan inşa edebilir mi?
Plan netleşip ana akışlar kağıt üzerinde mantıklı hale geldiğinde, bunu yürütülebilir hale getirin: gerçek bir şema ve migrationlar.
İlk migration ile tabloları, tipleri (enum kullanıyorsanız) ve gerekli kısıtları oluşturun. İlk geçiş küçük ama doğru olsun. Biraz seed verisi yükleyin ve uygulamanızın gerçekten ihtiyaç duyacağı sorguları çalıştırın. Eğer bir akış zor geliyorsa, migration geçmişi kısa iken şemayı düzeltin.
Tablolar, anahtarlar ve isimlendirme yeterince stabil olduğunda modelleri ve endpointleri üretmek daha hızlıdır; ertesi gün her şeyi yeniden adlandırmak zorunda kalmazsınız.
Yeniden yazmaları düşük tutan pratik döngü:
Hangi doğrulamayı veritabanında, hangisini API katmanında yapacağınıza erkenden karar verin. Kalıcı kuralları veritabanına koyun (foreign key, unique, check). Geçici / yumuşak kuralları API katmanında tutun (feature flag'ler, geçici limitler ve sık değişen karmaşık çapraz tablo mantıkları).
Koder.ai kullanıyorsanız, mantıklı bir yaklaşım Planning Mode’da varlıklar ve migrationlar üzerinde anlaşmak, sonra Go + PostgreSQL backend üretmektir. Değişiklik ters giderse, snapshotlar ve rollback sizi bilinen iyi bir versiyona hızlıca döndürürken şema planınızı ayarlamanıza olanak verir.
Planı önce yapın. Bu, üretilen modellerin ve endpointlerin sürekli yeniden adlandırma ve yeniden yazma gerektirmemesini sağlayan sabit bir veri sözleşmesi (tablolar, anahtarlar, kısıtlar) belirler.
Pratikte: varlıklarınızı, ilişkilerinizi ve en önemli sorguları yazın, sonra kod üretmeden önce kısıtları, indeksleri ve migration stratejisini kesinleştirin.
Uygulamanın ne saklaması gerektiğini ve kullanıcıların ne yapabilmesi gerektiğini 2–3 cümleyle yazın.
Sonra şunları listeleyin:
Bu, tabloları aşırı tasarlamadan tasarım yapmak için yeterli netlik verir.
Sürekli tekrar ettiğiniz isimleri (user, project, invoice, task gibi) listeleyerek başlayın. Her biri için bir cümleyle: nedir ve neden var?\n\nAçıklayamıyorsanız, muhtemelen items veya misc gibi belirsiz tablolarla karşılaşırsınız.
Şema genelinde tek bir kimlik stratejisi seçin.
İnsan dostu bir tanımlayıcı gerekiyorsa, onu birincil anahtar yapmak yerine ayrı, benzersiz bir sütun (project_code gibi) ekleyin.
İlişkiye göre karar verin; kullanıcı beklentisi ve korunması gereken veriye bakın.
Yaygın varsayımlar:
RESTRICT/NO ACTION kullanın.CASCADE mantıklı olabilir (ör. order → line items).Bu karar API davranışını ve kenar durumları etkilediği için erken verilmeli.
Veritabanına kalıcı kurallar koyun ki her yazıcı (API, script, import, admin araçları) uyum sağlasın.
Öncelik verin:
Tahmin yerine gerçek sorgu desenlerinden başlayın.
5–10 düz İngilizce sorgu yazın (filtre + sıralama) ve onlara göre indeks seçin:
status, user_id, created_at gibi yaygın filtrelerJoin tablosu oluşturun: iki yabancı anahtar ve bileşik UNIQUE kısıtı.
Örnek desen:
team_members(team_id, user_id, role, joined_at)UNIQUE (team_id, user_id) ekleyin ki tekrarlar oluşmasınBu, aynı ilişkinin iki kez kaydedilmesi gibi sessiz hataları önler ve sorguları temiz tutar.
Varsayılan olarak:
timestamptz (zaman dilimi sürprizlerini azaltır)numeric(12,2) veya kuruş olarak integer (float kullanmayın)CHECK kısıtlarıAynı kavram için tablolar arasında tipleri tutarlı tutun ki join ve doğrulamalar öngörülebilir olsun.
Küçük, gözden geçirilebilir migration'lar kullanın ve tek adımda kırıcı değişikliklerden kaçının.
Güvenli yol:
Ayrıca seed/reference verilerini nasıl yöneteceğinizi baştan belirleyin ki ortamlar tutarlı olsun.
PRIMARY KEYFOREIGN KEYUNIQUE (e-posta, join tablolarındaki çiftler gibi)CHECK (negatif olmayan tutarlar, izin verilen statüler)NOT NULL(account_id, created_at))Her şeyi indekslemeyin; her indeks INSERT/UPDATE'i yavaşlatır.