05 Eki 2025·8 dk
Uygulamalarınız İçin RabbitMQ: Desenler, Kurulum ve Operasyon
Uygulamalarınızda RabbitMQ nasıl kullanılır öğrenin: temel kavramlar, yaygın desenler, güvenilirlik ipuçları, ölçekleme, güvenlik ve üretimde izleme.
Uygulamalarınızda RabbitMQ nasıl kullanılır öğrenin: temel kavramlar, yaygın desenler, güvenilirlik ipuçları, ölçekleme, güvenlik ve üretimde izleme.
RabbitMQ bir mesaj aracısıdır: sisteminizin parçalarının arasında durur ve "iş"i (mesajları) üreticilerden tüketicilere güvenilir şekilde taşır. Uygulama ekipleri genellikle doğrudan, senkron çağrılar (servisler arası HTTP, paylaşılan veritabanları, cron işleri) kırılgan bağımlılıklar, dengesiz yükler ve zor debuglanan hata zincirleri yarattığında RabbitMQ'ya yönelir.
Trafik sıçramaları ve dengesiz iş yükleri. Uygulamanız kısa sürede 10× daha fazla kayıt veya sipariş alırsa, her şeyi hemen işlemek downstream servisleri zorlayabilir. RabbitMQ ile üreticiler görevleri hızlıca kuyruğa alır, tüketiciler ise bunları kontrollü bir hızda işler.
Hizmetler arası sıkı bağlılık. Servis A, Servis B'yi çağırıp beklemek zorundaysa, hatalar ve gecikmeler yayılır. Mesajlaşma bunları ayırır: A bir mesaj yayınlar ve devam eder; B uygun olduğunda işler.
Daha güvenli hata yönetimi. Her hata kullanıcıya gösterilecek bir hataya dönüşmemeli. RabbitMQ arka planda yeniden denemeleri, “zehirli” mesajları izole etmeyi ve geçici kesintiler sırasında iş kaybını önlemeyi kolaylaştırır.
Ekipler genellikle daha düzgün iş yükleri (zirveleri tamponlama), ayrışmış servisler (daha az çalışma zamanı bağımlılığı) ve kontrollü yeniden denemeler elde eder. Aynı derecede önemli olarak, işin nerede takıldığını—üreticide mi, bir kuyruğun içinde mi yoksa tüketicide mi—anlamak kolaylaşır.
Bu rehber uygulama ekipleri için pratik RabbitMQ bilgisine odaklanır: temel kavramlar, yaygın desenler (pub/sub, work queue'lar, yeniden denemeler ve dead-letter kuyrukları) ve operasyonel konular (güvenlik, ölçekleme, gözlemlenebilirlik, sorun giderme).
AMQP spesifikasyonunun tamamını veya her RabbitMQ eklentisinin derinlemesine incelemesini amaçlamaz. Amaç, gerçek sistemlerde sürdürülebilir kalan mesaj akışları tasarlamanıza yardımcı olmaktır.
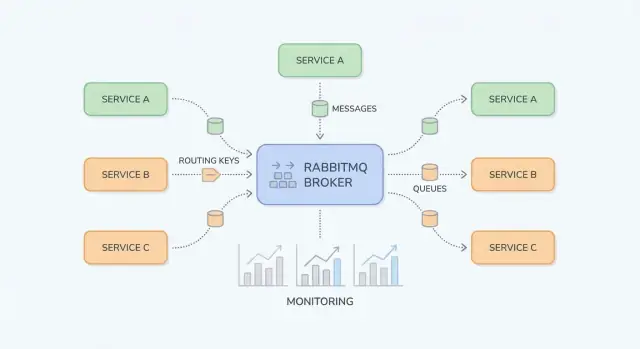
RabbitMQ, sisteminizin parçaları arasında mesajları yönlendiren bir mesaj aracısıdır; böylece üreticiler işi devreder ve tüketiciler hazır olduklarında işler.
Doğrudan bir HTTP çağrısında Servis A, Servis B'ye bir istek gönderir ve genellikle bekler. Servis B yavaşsa veya kapalıysa, Servis A başarısız olur veya bekler; zaman aşımı, yeniden deneme ve backpressure her arayan taraf için ele alınmalıdır.
RabbitMQ ile (çoğunlukla AMQP üzerinden) Servis A broker'a bir mesaj yayınlar. RabbitMQ onu saklar ve doğru kuyruk(lar)a yönlendirir; Servis B asenkron olarak tüketir. Ana fark, iletişiminizi spike'ları tamponlayan ve dengesiz iş yüklerini düzelten kalıcı bir ara katman üzerinden yapmanızdır.
Mesajlaşma uygundur eğer:
Mesajlaşma uygun değildir eğer:
Senkron (HTTP):
Bir checkout servisi, fatura servisini HTTP ile çağırır: "Fatura oluştur." Kullanıcı faturanın oluşturulmasını bekler. Eğer fatura servisi yavaşsa checkout gecikir; eğer kapalıysa checkout başarısız olur.
Asenkron (RabbitMQ):
Checkout invoice.requested(id ile) yayınlar. Kullanıcıya sipariş alındı onayı hemen döner. Fatura servisi mesajı tüketir, faturayı oluşturur ve e-posta/bildirimlerin alması için invoice.created yayınlar. Her adım bağımsız olarak yeniden denenebilir; geçici kesintiler tüm akışı otomatik olarak bozmaz.
RabbitMQ'yu anlamak için "mesajların nerede yayınlandığını" "nerede saklandığını" ayırmak faydalıdır. Üreticiler exchangelere yayın yapar; exchange'ler kuyruklara yönlendirir; tüketiciler kuyruklardan okur.
Bir exchange mesajları saklamaz. Kuralları değerlendirir ve mesajları bir veya daha fazla kuyruğa iletir.
billing veya email).\region=eu VE tier=premium), ama özel durumlar için saklayın çünkü anlaşılması zordur.Bir kuyruk, mesajlar tüketici işlemeye hazır olana kadar beklediği yerdir. Bir kuyruğun bir tüketicisi olabilir veya birden fazla (rekabet eden tüketiciler) ve mesajlar tipik olarak aynı anda tek bir tüketiciye teslim edilir.
Bir binding exchange'i bir kuyruğa bağlayan ve yönlendirme kuralını tanımlayan şeydir. Şöyle düşünün: "Mesaj exchange X'e routing key Y ile gelirse, Q kuyruğuna teslim et." Aynı exchange'e birden fazla kuyruk bağlı olabilir (pub/sub) veya tek bir kuyruğu farklı routing key'ler için birden çok kez bind edebilirsiniz.
Direct exchange'lerde yönlendirme tam eşlemelidir. Topic exchange'lerde routing key, noktayla ayrılmış kelimeler şeklindedir, örneğin:
orders.created\orders.eu.refundedBinding'ler wildcard içerebilir:
* tam olarak bir kelime ile eşleşir (örn. orders.* orders.created ile eşleşir)# sıfır veya daha fazla kelime ile eşleşir (örn. orders.# orders.created ve orders.eu.refunded ile eşleşir)Bu, üreticiyi değiştirmeden yeni tüketiciler eklemenin temiz bir yolunu verir—yeni bir kuyruk oluşturup ihtiyacınız olan desenle bind edin.
RabbitMQ mesaj teslim ettikten sonra tüketici sonucu bildirir:
Requeue ile dikkatli olun: sürekli başarısız olan bir mesaj sonsuza kadar döngüye girip kuyruğu bloke edebilir. Birçok ekip nack ile retry stratejisi ve bir dead-letter kuyruğu (aşağıda) eşleştirir ki hatalar öngörülebilir şekilde ele alınsın.
RabbitMQ, işleri veya bildirimleri sistem parçalarınız arasında bekletmeden taşımak istediğinizde parlıyor. Aşağıda günlük ürünlerde karşılaşılan pratik desenler var.
Bir olaya birden fazla tüketici tepki vermeli ve yayıncı kimin abone olduğunu bilmemeli—bu durumda publish/subscribe temiz bir çözüm.
Örnek: bir kullanıcı profilini güncellediğinde, arama indeksleme, analitik ve CRM senkronizasyonu paralel olarak bilgilendirilebilir. Fanout exchange ile tüm bağlı kuyruklara yayın yaparsınız; topic exchange ile seçici yönlendirme yapabilirsiniz (örn. user.updated, user.deleted). Bu, servisleri sıkı şekilde bağlamayı önler ve ekiplerin üreticiyi değiştirmeden yeni aboneler eklemesine izin verir.
Bir görev zaman alıyorsa, onu kuyruğa atıp işçilerin asenkron işlemesine izin verin:
Bu, web isteklerini hızlı tutar ve işçileri bağımsız ölçeklendirmenizi sağlar. Ayrıca concurrency'yi kontrol etmenin doğal bir yoludur: kuyruk sizin “yapılacaklar listesi”niz olur ve işçi sayısı throughput kontrol düğmeniz olur.
Birçok iş akışı servis sınırlarını aşar: order → billing → shipping klasik örnektir. Bir servis bir sonraki servisi çağırıp bloke olmak yerine, her adımı tamamlandığında bir olay yayınlayabilir. Downstream servisler olayları tüketip iş akışını sürdürür.
Bu, dayanıklılığı artırır (ör. shipping geçici olarak kapalıyken checkout bozulmaz) ve sahipliği netleştirir: her servis ilgilendiği olaylara tepki verir.
RabbitMQ ayrıca uygulamanız ile yavaş veya hataya açık bağımlılıklar (üçüncü taraf API'ler, eski sistemler, toplu veritabanları) arasında tampon görevi görür. Talepleri hızlıca kuyruğa alırsınız, sonra kontrollü yeniden denemelerle işler sinirli bir şekilde işlenir. Bağımlılık kapalıysa iş güvenle birikir ve daha sonra boşalır—bunun yerine tüm uygulama çapında zaman aşımı ve hatalar oluşmaz.
Kuyrukları kademeli olarak tanıtmayı planlıyorsanız, küçük bir “async outbox” veya tek arka plan iş kuyruğu genellikle iyi bir ilk adım olur (bkz. /blog/next-steps-rollout-plan).
RabbitMQ kurulumu, yönlerin kolay tahmin edilebilir olduğu, isimlerin tutarlı olduğu ve yüklerin eski tüketicileri bozmayacak şekilde evrildiği zaman çalışması keyifli olur. Yeni bir kuyruk eklemeden önce bir mesajın "hikâyesinin" açık olduğundan emin olun: nereden kaynaklandığı, nasıl yönlendirildiği ve bir ekip arkadaşının uçtan uca nasıl debug edebileceği.
Doğru exchange'i baştan seçmek tek seferlik binding'leri ve sürpriz fan-out'ları azaltır:
billing.invoice.created).\billing.*.created, *.invoice.*). Bu, sürdürülebilir olay yönlendirmesi için en yaygın tercihtir.\İyi bir kural: karmaşık yönlendirme mantığını kodda "icat ediyorsanız", muhtemelen bunun yerine topic exchange desenini kullanmalısınız.
Mesaj gövdelerini halka açık API gibi ele alın. Açık sürümlendirme kullanın (ör. üst düzey schema_version: 2) ve geriye dönük uyumluluğa çalışın:
Bu, eski tüketicilerin kendi takvimlerinde yeni sürüme geçmesine izin verir.
Sorun gidermeyi ucuzlatmak için metadata standardize edin:
correlation_id: aynı işsel işlemdeki komutları/olayları birbirine bağlar.\trace_id (veya W3C traceparent): HTTP ve asenkron akışlar arasında izlemeyi bağlar.Her yayıncının bunları tutarlı şekilde ayarlaması, tek bir işlemi birden fazla servis boyunca izlemeyi kolaylaştırır.
Tahmin edilebilir, aranabilir isimler kullanın. Yaygın bir desen:
<domain>.<type> (örn. billing.events)\<domain>.<entity>.<verb> (örn. billing.invoice.created)\<service>.<purpose> (örn. reporting.invoice_created.worker)Tutarlılık zekice olmaktan daha faydalıdır: gelecekteki siz ve on-call ekibiniz minnettar kalacaktır.
Güvenilir mesajlaşma çoğunlukla hatayı planlamaktan ibarettir: tüketiciler çöker, downstream API'ler zaman aşımı verir ve bazı olaylar bozuk olabilir. RabbitMQ size araçları sağlar, ama uygulama kodunuz işbirliği yapmalıdır.
Yaygın bir kurulum en az bir kez teslimattır: bir mesaj birden fazla kez teslim edilebilir, ama sessizce kaybolmamalıdır. Bu genellikle tüketici mesajı alıp işleme başlar, sonra ack göndermeden başarısız olursa olur—RabbitMQ mesajı tekrar kuyruğa koyar ve yeniden teslim eder.
Pratik sonuç: çoğaltmalar normaldir, bu yüzden handler'ınız birden fazla çalıştırılmaya dayanıklı olmalıdır.
Idempotency, "aynı mesaj iki kez işlenirse tek kez işleme ile aynı etkiye sahip olması" demektir. Kullanışlı yaklaşımlar:
message_id (veya order_id + event_type + version) dahil edin ve bunu TTL'li bir “işlenmiş” tablo/cache'ine kaydedin.\PENDING ise güncelle gibi koşullu yazmalar veya veritabanı benzersizlik kısıtları kullanın.\Yeniden denemeler tüketicide sıkı döngü olarak değil, ayrı bir akış olarak ele alınmalıdır.
Yaygın desen:
Bu, mesajları unacked bırakmadan backoff sağlar.
Bazı mesajlar asla başarılı olamayacaktır (kötü şema, eksik referans verisi, kod hatası). Bunları şöyle tespit edin:
Bunları bir DLQye gönderin ve DLQ'yu operasyonel bir gelen kutusu gibi ele alın: payloadları inceleyin, temel sorunu düzeltin ve seçili mesajları manuel olarak yeniden oynatın (mümkünse kontrollü bir araç/script ile)—hepsini ana kuyruğa yeniden dökmeyin.
RabbitMQ performansı genellikle bağlantıları nasıl yönettiğiniz, tüketicilerin işi ne kadar hızlı güvenle işleyebildiği ve kuyruğun bir “depolama” olarak kullanılıp kullanılmadığı gibi birkaç pratik faktörle sınırlanır. Amaç, büyüyen bir backlog oluşturmadan istikrarlı throughput elde etmektir.
Her yayıncı veya tüketici için yeni bir TCP bağlantısı açmak yaygın bir hatadır. Bağlantılar düşündüğünüzden daha ağırdır (handshake, heartbeats, TLS), bu yüzden uzun ömürlü tutun ve yeniden kullanın.
Yayın için az sayıda bağlantı ve çok sayıda channel kullanın. Genel kural: az bağlantı, çok kanal. Yine de binlerce kanal oluşturmayın—her kanalın overhead'i vardır ve client kütüphanenizin kendi limitleri olabilir. Her servis için küçük bir kanal havuzu oluşturup kanalları yeniden kullanmayı tercih edin.
Tüketiciler aynı anda çok fazla mesaj çekerse bellek sıçraması, uzun işleme süreleri ve düzensiz gecikme görürsünüz. Her tüketicinin kontrollü sayıda unacked mesaj tutması için prefetch (QoS) ayarlayın.
Pratik rehber:
Büyük mesajlar throughput'u düşürür ve bellek baskısını artırır (yayıncıda, broker'da ve tüketicide). Eğer payload büyükse (dokümanlar, resimler, büyük JSON), bunları başka bir yerde (nesne depolama veya veritabanı) saklayıp RabbitMQ üzerinden sadece bir ID + metadata gönderin.
Kural: mesajları KB aralığında tutun, MB değil.
Kuyruk büyümesi bir strateji değil, belirtidir. Üreticilerin tüketiciler yetişemezken yavaşlamasını sağlayın:
Şüphede kaldığınızda tek bir ayarı değiştirin ve ölçün: publish hızı, ack hızı, kuyruk uzunluğu ve uçtan uca gecikme.
RabbitMQ güvenliği çoğunlukla "kenarları sıkılaştırmak"le ilgilidir: istemciler nasıl bağlanır, kim ne yapabilir ve kimlik bilgilerini yanlış yerde tutmamak.
RabbitMQ izinleri tutarlı kullanıldığında güçlüdür.
Operasyonel sertleştirme (portlar, firewall, denetim) için kısa bir iç runbook tutun ve ekiplerin tek bir standardı takip etmesi için belgenize bağlayın (ör. /docs/security).
RabbitMQ bozulduğunda semptomlar önce uygulamanızda görünür: yavaş uç noktalar, zaman aşımaları, eksik güncellemeler veya "hiç bitmeyen" işler. İyi gözlemlenebilirlik broker'ın sebep olup olmadığını doğrulamanızı, darboğazı (üretici, broker veya tüketici) tespit etmenizi ve kullanıcılar fark etmeden önce müdahale etmenizi sağlar.
Akışın devam edip etmediğini söyleyen küçük bir sinyal seti ile başlayın:
Eşikler yerine trendler üzerine uyarı verin:
Broker logları "RabbitMQ çöktü" ile "istemciler onu yanlış kullanıyor" arasındaki farkı ayırt etmenize yardımcı olur. Kimlik doğrulama hataları, bloklanan bağlantılar (resource alarm'ları) ve sık kanal hatalarını arayın. Uygulama tarafında her işleme denemesi için bir correlation ID, kuyruk adı ve sonuç (acked, rejected, retried) loglandığından emin olun.
Dağıtık izleme kullanıyorsanız trace header'larını mesaj özellikleri aracılığıyla taşıyın ki "API isteği → yayınlanan mesaj → tüketici işi" zincirini bağlayabilesiniz.
Her kritik akış için bir pano oluşturun: publish hızı, ack hızı, derinlik, unacked, requeues ve tüketici sayısı. Panoya iç runbook'unuzun ve "ilk bakışta kontrol edilecekler" kontrol listesinin bağlantılarını ekleyin (ör. /docs/monitoring).
Bir şey "ilerlemeyi kestiğinde", önce yeniden başlatma dürtüsüne direnin. Çoğu sorun (1) binding ve yönlendirmeler, (2) tüketici sağlığı ve (3) kaynak alarm'larına baktığınızda barizleşir.
Eğer üreticiler "başarıyla gönderildi" diyor ama kuyruklar boş kalıyorsa (veya yanlış kuyruk doluyorsa), önce yönlendirmeyi kontrol edin.
Management UI'da başlayın:
topic exchange'lerde).\Kuyrukta mesaj var ama kimse tüketmiyorsa doğrulayın:
Çoğaltmalar genellikle yeniden denemelerden (tüketici ack göndermeden çöktüğünde), ağ kesilmelerinden veya manuel requeue işlemlerinden gelir. Handler'ları idempotent yaparak (örn. veritabanında mesaj ID'sine göre dedupe) hafifletin.
Sıra kayması, birden fazla tüketici veya requeue olunca beklenen bir durumdur. Sıra önemliyse o kuyruk için tek bir tüketici kullanın veya anahtara göre partition ederek birden çok kuyruk oluşturun.
Alarm, RabbitMQ'nin kendini korumasıdır.
Yeniden oynamadan önce kök nedeni düzeltin ve "zehirli mesaj" döngüsünü önleyin. Mesajları küçük partiler halinde yeniden kuyruğa verin, yeniden deneme sınırı ekleyin ve yeniden oynatılan mesajları ayrı bir kuyruğa göndererek aynı hatanın tekrar etmesi durumunda hızlıca durdurma şansı bırakın.
Mesajlaşma aracını seçmek "en iyi"den çok trafik modelinize, hata toleransınıza ve operasyonel konforunuza bağlıdır.
RabbitMQ, güvenilir mesaj teslimi ve esnek yönlendirme gerektiğinde parlıyor. Komutlar, arka plan işleri, fan-out bildirimleri ve request/response desenleri için güçlü bir seçimdir, özellikle:
Eğer amacınız olayları uzun süre saklamak değil de işi taşımaksa, RabbitMQ genellikle rahat bir varsayılandır.
Kafka ve benzerleri yüksek throughput streaming ve uzun süreli event log için tasarlanmıştır. Kafka-benzeri bir sistem seçin eğer:
Takas: Kafka türü sistemler daha yüksek operasyonel yük getirebilir ve sizi throughput odaklı tasarıma (batching, partition stratejisi) itebilir. RabbitMQ genellikle düşük-orta throughput, düşük uçtan uca gecikme ve karmaşık yönlendirme için daha kolaydır.
Eğer tek bir uygulama iş üretiyor ve tek bir worker havuzu tüketiyorsa—ve daha basit semantiklerle yetinebiliyorsanız—Redis tabanlı kuyruk veya yönetilen görev servisi yeterli olabilir. Ekipler genellikle teslim garantileri, dead-lettering, birden fazla yönlendirme deseni veya üreticiler/tüketiciler arasında daha net ayrım gerektiğinde bu noktadan çıkar.
Mesaj sözleşmelerinizi ileride taşıyabileceğinizi varsayarak tasarlayın:
Daha sonra replay edilebilir stream'lere ihtiyaç duyarsanız, RabbitMQ olaylarını bir log-temelli sisteme köprüleyebilirsiniz; operasyonel iş akışları için RabbitMQ'yu koruyabilirsiniz. Pratik bir rollout planı için bkz. /blog/rabbitmq-rollout-plan-and-checklist.
RabbitMQ'yu devreye almak onu bir ürün gibi ele almakla en iyi sonuç verir: küçük başlayın, sahipliği tanımlayın ve daha fazla servise yaymadan önce güvenilirliği kanıtlayın.
Asenkron işlemden fayda sağlayan tek bir iş akışı seçin (ör. e-posta gönderme, rapor oluşturma, üçüncü taraf API ile senkronizasyon).
Referans şablonlarına ihtiyacınız varsa, adlandırma, retry katmanları ve temel politikalar için merkezi bir /docs tutun.
Birçok ekip uygulamayı hayata geçirirken altyapı ve şablonları standartlaştırmayı düşünür. Örneğin Koder.ai kullanan ekipler genellikle sohbet isteminden küçük bir üretici/tüketici iskeleti üretir (adlandırma, retry/DLQ bağlantıları ve trace/correlation header'ları dahil), sonra kaynak kodunu dışa aktarır ve rollout öncesi planlama aşamasında gözden geçirir.
RabbitMQ, "birinin kuyruğu sahiplenmesi" ile başarılı olur. Bunu üretime almadan önce kararlaştırın:
Yönetilen hosting veya resmi destek planlıyorsanız, beklentileri baştan hizalayın (bkz. /pricing) ve onboarding/destek için bir temas yolu belirleyin (bkz. /contact).
Güveni artırmak için küçük, zaman kutulu egzersizler yapın:
Bir servis birkaç hafta stabil kaldığında, aynı desenleri diğer servislere çoğaltın—ekip başına yeniden icat etmeyin.
RabbitMQ'yu, servisleri birbirinden ayırmak, trafik dalgalanmalarını absorbe etmek veya yavaş işleri istek akışından uzaklaştırmak istediğinizde kullanın.
Arka plan işleri (e-postalar, PDF oluşturma), birden fazla aboneyi bilgilendiren bildirimler ve geçici downstream kesintilerinin iş akışını bozmasını istemediğiniz durumlar iyi birer örnektir.
Gerçekten anlık bir cevap gerektiğinde (basit okuma/doğrulama) veya sürümleme, yeniden deneme ve izleme için taahhütte bulunamıyorsanız mesajlaşmadan kaçının—bunlar üretimde opsiyonel değildir.
Bir exchangee yayın yapın ve mesajları kuyruklara yönlendirin:
orders.* veya orders.# gibi esnek desenler istiyorsanız topic exchange kullanın.Çoğu ekip, sürdürülebilir olay tarzı yönlendirme için varsayılan olarak topic exchangee yönelir.
Bir kuyruk mesajları saklar; bir binding exchange ile kuyruk arasındaki bağlantı kuralını tanımlar.
Yönlendirme sorunlarını debug etmek için:
Bu üç kontrol, "gönderildi ama tüketilmedi" vakaların çoğunu açıklar.
Bir iş birimini her seferinde bir işçi işlemeli diyorsanız work queue kullanın.
Pratik kurulum ipuçları:
At-least-once teslimat, bir mesajın birden çok kez teslim edilebileceği anlamına gelir (ör. tüketici iş yaptıktan sonra ack göndermeden çökebilir).
Tüketicileri güvenli hale getirmek için:
message_id (veya iş anahtarı) kullanıp işlenmiş ID'leri TTL ile saklayın.PENDING ise güncelleme) veya benzersizlik kısıtları kullanın.Sıkı requeue döngülerinden kaçının. Yaygın bir yöntem "retry kuyrukları" + DLQ'dur:
DLQ'den yeniden oynatma yapmadan önce kök nedeni düzeltin ve küçük partiler halinde yeniden oynatın.
Açık ve tahmin edilebilir isimler kullanın ve mesajları halka açık API gibi düşünün:
schema_version ekleyin.Ek metadata standardize edin:
İşin akıp gitmesini gösteren birkaç sinyale odaklanın:
Eşikler yerine trendleri uyarın (ör. "backlog 10 dakika boyunca artıyor"). Loglarda kuyruk adı, correlation_id ve işleme sonucu (acked/retried/rejected) olsun.
Temel uygulamalar:
Kısa bir iç runbook hazırlayın ki ekipler tek bir standardı takip etsin.
Akışın nerede durduğunu bulun:
Çoğu durumda yeniden başlatma ilk ve en iyi hamle değildir.
Yineleme ve çoğaltmaların normal olduğunu varsayın.
correlation_id ile aynı işleme ait komutları/olayları bağlayın.\trace_id (veya W3C traceparent) ile HTTP ve asenkron akışlar arasında izlemeyi bağlayın.Bu, yeni gelenlerin ve on-call ekibin işini kolaylaştırır.