18 May 2025·8 dk
Şema Tasarımı Önce: Erken Sorgu Optimizasyonundan Daha Hızlı Uygulamalar
Erken dönemde performans kazançları genellikle doğru tablo yapısı, anahtarlar ve kısıtlamalardan gelir: iyi bir şema yavaş sorguları ve maliyetli yeniden yazımları önler.
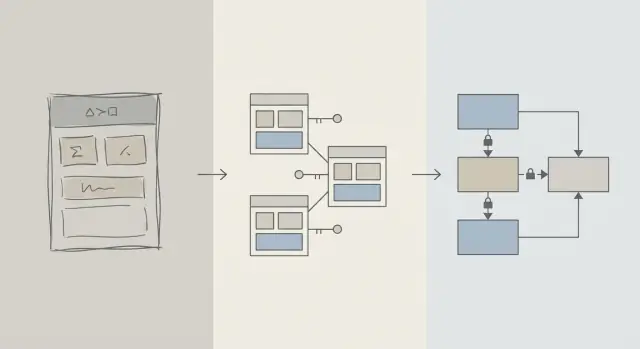
Şema vs Sorgu Optimizasyonu: Ne Anlatıyoruz
Bir uygulama yavaşladığında ilk içgüdü genellikle “SQL’i düzeltmek” olur. Bu mantıklı: tek bir sorgu görünür, ölçülebilir ve suçlanması kolaydır. EXPLAIN çalıştırır, bir indeks eklersiniz, bir JOIN ayarı yaparsınız ve bazen hemen bir kazanım görürsünüz.
Ama ürün yaşam döngüsünün erken döneminde hız problemleri, belirli sorgu metninden ziyade verinin şekli yüzünden de ortaya çıkabilir. Şema veritabanına karşı savaşmanıza zorluyorsa, sorgu optimizasyonu maymun kovalamaca döngüsüne dönüşür.
Şema tasarımı (sade dille)
Şema tasarımı verilerinizi nasıl organize ettiğinizdir: tablolar, sütunlar, ilişkiler ve kurallar. Şu tür kararları kapsar:
- Hangi “şeyler” kendi tablosunu hak eder (kullanıcılar, siparişler, olaylar)
- Tablolar nasıl ilişkilenir (bir-çok, çok-çok)
- Neyin benzersiz veya zorunlu olması gerektiği (kısıtlamalar)
- Durumları ve geçmişi nasıl temsil ettiğiniz (zaman damgaları, durum alanları, denetim kayıtları)
İyi bir şema, soruları doğal yoldan sormayı aynı zamanda hızlı bir yol haline getirir.
Sorgu optimizasyonu (sade dille)
Sorgu optimizasyonu ise veriyi alma veya güncelleme şeklinizi iyileştirmektir: sorguları yeniden yazma, indeks ekleme, gereksiz işi azaltma ve büyük taramalara yol açan kalıplardan kaçınma.
İkisi de önemli—zamanlama daha önemli
Bu yazı “şema iyi, sorgular kötü” demiyor. Söz konusu olan işlem sırası: önce veritabanı şemasının temellerini doğru kurgulayın, sonra gerçekten ihtiyaç duyulan sorguları iyileştirin.
Erken aşamada neden şema kararlarının performansı domine ettiğini, şemanın gerçek darboğaz olduğu durumları nasıl fark edeceğinizi ve uygulama büyüdükçe şemayı güvenli şekilde nasıl evriltileceğini öğreneceksiniz. Yazı, ürün ekipleri, kurucular ve gerçek dünya uygulamaları inşa eden geliştiriciler için; veritabanı uzmanlarına değil.
Neden Şema Tasarımı Erken Performansı Belirler
Erken performans genellikle zekice SQL yazımından değil—veritabanının dokunmak zorunda kaldığı veri miktarından kaynaklanır.
Yapı, ne kadar tarama yapılacağını belirler
Bir sorgu, veri modelinin izin verdiği kadar seçicidir. Eğer “status”, “type” veya “owner” gibi alanları gevşek yapılandırılmış alanlarda saklıyorsanız (veya tutarsız tablolara yaymışsanız), veritabanı eşleşen kayıtları bulmak için çok daha fazla satırı taramak zorunda kalır.
İyi bir şema arama alanını doğal olarak daraltır: açık sütunlar, tutarlı veri tipleri ve iyi sınırlandırılmış tablolar, sorguların daha erken filtrelemesine ve disk/ram’den daha az sayfa okumasına yol açar.
Eksik anahtarlar maliyetli işler yaratır
Birincil anahtarlar ve yabancı anahtarlar eksik olduğunda (veya uygulanmadığında) ilişkiler tahmine dönüşür. Bu iş yükünü sorgu katmanına iter:
- Join’ler daha büyük olur çünkü güvenilir, indeksli bir join yolu yoktur.
- Filtreler daha karmaşıklaşır çünkü çoğaltmalar, null’lar ve “neredeyse eşleşen” değerlerle telafi etmeye çalışırsınız.
Kısıtlamalar yoksa kötü veri birikir—böylece satır ekledikçe sorgular giderek yavaşlar.
İndeksler şemayı takip eder (her şeyi düzeltemez)
İndeksler, öngörülebilir erişim yollarıyla eşleştiğinde en kullanışlıdır: yabancı anahtarla join, iyi tanımlanmış sütunlarla filtreleme, ortak alanlarla sıralama. Eğer şema kritik öznitelikleri yanlış tabloda saklıyorsa, anlamları bir sütunda karıştırıyorsa veya metin ayrıştırmaya dayanıyorsa, indeksler sizi kurtaramaz—hala çok fazla tarama ve dönüşüm yapılıyor demektir.
Varsayılan olarak hızlı
Temiz ilişkiler, stabil tanımlayıcılar ve mantıklı tablo sınırlarıyla birçok günlük sorgu "varsayılan olarak hızlı" olur çünkü daha az veriye dokunur ve basit, indeks-dostu koşullar kullanır. Sorgu optimizasyonu o zaman sürekli bir yangın söndürme yerine bitirme adımı olur.
Erken Aşama Gerçekliği: Değişim Süreklidir
Erken aşama ürünlerin “stabil gereksinimleri” yoktur—deneyimleri vardır. Özellikler yayınlanır, yeniden yazılır veya kaybolur. Küçük bir ekip yol haritası baskısı, destek ve altyapıyla uğraşırken eski kararları tekrar gözden geçirmek için sınırlı zamana sahiptir.
En sık ne değişir
İlk değişen genellikle SQL metni değildir. Veri anlamı değişir: yeni durumlar, yeni ilişkiler, “ayrıca takip etmemiz gerek” alanları ve lansmanda hayal edilmeyen iş akışları. Bu değişim normaldir—ve tam da bu yüzden şema seçimleri erken dönemde çok önemlidir.
Şemayı sonra düzeltmek sorguyu düzeltmekten neden daha zordur
Bir sorguyu yeniden yazmak genellikle geri alınabilir ve yereldir: bir iyileştirme yayınlayabilir, ölçebilir ve gerekirse geri alabilirsiniz.
Şemayı yeniden yazmak farklıdır. Gerçek müşteri verisini sakladıktan sonra her yapısal değişiklik bir projeye dönüşür:
- Tabloları kilitleyen veya yoğun zamanlarda yazmaları yavaşlatan migrasyonlar
- Yeni sütunları doldurmak veya türetilmiş verileri yeniden oluşturmak için backfill işlemleri
- Geçiş sırasında uygulamayı çalışır tutmak için çift yazma veya gölge tablolar
- Çevrimiçi yapılamayan bir değişiklikse kesinti riski
İyi araçlar olsa bile, şema değişiklikleri koordinasyon maliyetleri getirir: uygulama kodu güncellemeleri, dağıtım sıralaması ve veri doğrulama.
Erken kararlar nasıl katmanlaşır
Veritabanı küçükken, sakar bir şema “idare eder” gibi görünebilir. Satırlar binlerden milyonlara yükseldikçe aynı tasarım daha büyük taramalar, ağır indeksler ve maliyetli join’ler yaratır—sonra her yeni özellik bu temelin üzerine inşa edilir.
Bu yüzden erken aşama hedefi mükemmellik değil. Her yeni ürün öğrenişinde riskli migrasyonlar gerektirmeyecek şekilde değişimi absorbe edebilen bir şema seçmektir.
Yavaş Sorguları Önleyen Tasarım Temelleri
Başlangıçtaki çoğu “yavaş sorgu” problemi SQL numaralarından ziyade veri modelindeki belirsizlikten kaynaklanır. Eğer şema bir kaydın neyi temsil ettiğini veya kayıtların nasıl ilişkilendiğini belirsiz kılıyorsa, her sorgu yazmak, çalıştırmak ve sürdürmek için daha pahalı olur.
Küçük bir çekirdek varlık setiyle başlayın
Ürününüzün olmadan çalışamayacağı birkaç şeyi adlandırarak başlayın: kullanıcılar, hesaplar, siparişler, abonelikler, olaylar, faturalar—gerçekte merkezi olanlar. Sonra ilişkileri açıkça tanımlayın: bir-çok, çok-çok (genellikle bir bağlantı tablosuyla) ve sahiplik (kim neyi “içerir”).
Pratik bir kontrol: her tablo için "Bu tablodaki bir satır ___ temsil eder." cümlesini tamamlayabiliyor olmalısınız. Eğer yapamıyorsanız, tablo muhtemelen kavramları karıştırıyor ve ileride karmaşık filtreleme ve join’lere zorlayacaktır.
İsimlendirme ve sahipliği sıkıcı derecede tutarlı yapın
Tutarlılık kazara join’leri ve kafa karıştırıcı API davranışını engeller. Konvansiyonlar seçin (snake_case vs camelCase, *_id, created_at/updated_at) ve bunlara sadık kalın.
Ayrıca bir alanın kime ait olduğunu belirleyin. Örneğin, “billing_address” bir siparişe mi aittir (zaman içindeki anlık görüntü) yoksa bir kullanıcıya mı (geçerli varsayılan)? Her ikisi de geçerli olabilir—ama açık niyet olmadan karıştırmak yavaş, hataya açık sorgulara yol açar.
Gerçeğe uygun veri tipleri seçin
Çalışma zamanı dönüşümlerinden kaçınacak tipler kullanın:
- Anladığınız zaman dilimi kurallarıyla timestamp'ler kullanın.
- Para için decimal kullanın (float değil).
- Bilinen kategoriler için enum/reference tablolar kullanın.
Tipler yanlış olduğunda, veritabanı verileri verimli kıramaz, indeksler daha az faydalı olur ve sorgular genellikle cast gerektirir.
Plan olmadan gerçekleri çoğaltmayın
Aynı gerçeği birden çok yerde saklamak (ör. order_total ve sum(line_items)) sürtüşme yaratır. Türetileşmiş bir değeri cache’liyorsanız, bunu belgeleyin, doğruluk kaynağını tanımlayın ve güncellemeleri tutarlı şekilde uygulayın (genellikle uygulama mantığı artı kısıtlamalar ile).
Anahtarlar ve Kısıtlamalar: Hız Veri Bütünlüğüyle Başlar
Hızlı bir veritabanı genellikle öngörülebilir bir veritabanıdır. Anahtarlar ve kısıtlamalar verilerinizi “imkansız” durumları engelleyerek öngörülebilir kılar—eksik ilişkiler, çoğaltılmış kimlikler veya uygulamanın düşündüğü anlamda olmayan değerler. Bu temizlik performansı doğrudan etkiler çünkü sorgu planlayıcı sorgu planlarken daha iyi varsayımlarda bulunabilir.
Birincil anahtarlar: her tablonun sabit bir kimliği olsun
Her tablonun birincil anahtarı (PK) olmalıdır: bir satırı benzersiz tanımlayan ve değişmeyen bir sütun (veya küçük bir sütun seti). Bu sadece veritabanı kuramı değil—tabloları verimli bir şekilde join etmenizi, güvenli cache yapmanızı ve kayıtlara tahmin olmadan referans vermenizi sağlar.
Sabit bir PK ayrıca pahalı geçici çözümleri önler. Eğer bir tablo gerçek bir tanımlayıcıdan yoksunsa, uygulamalar satırları e-posta, isim, zaman damgası veya bir dizi sütunla “tanımlamaya” başlar—bu da daha geniş indeksler, yavaş join’ler ve bu değerler değiştiğinde kenar durumlarına yol açar.
Yabancı anahtarlar: optimizer için bütünlük
Yabancı anahtarlar (FK) ilişkileri zorunlu kılar: orders.user_id var olan bir users.id'ye işaret etmelidir. FK yoksa geçersiz referanslar birikir (silinmiş kullanıcılara ait siparişler, eksik posta için yorumlar) ve her sorgu savunmacı filtreleme, left-join ve null işleme yapmak zorunda kalır.
FK’lar varken sorgu planlayıcı join’leri daha emin şekilde optimize edebilir çünkü ilişki açık ve garantilidir. Ayrıca zaman içinde tablolarda ve indekslerde şişmeye neden olan yetim satırlardan kaçınırsınız.
Temiz, hızlı veri için kısıtlamalar
Kısıtlamalar bürokrasi değil—koruyucu korkuluklardır:
- UNIQUE tekrarları engeller; uygulamanın ekstra arama ve temizlik yapmasını önler. Örnek: tek bir
users.email. - NOT NULL üç durumlu mantığı ve sorgularda sürpriz null dallarını önler.
- CHECK değerleri bilinen bir küme içinde tutar (ör.
status IN ('pending','paid','canceled')).
Daha temiz veri, daha basit sorgular, daha az yedek koşul ve daha az “ne olur acaba” join demektir.
Yaygın anti-paternler
- Yabancı anahtar yok: ileride yetim kayıt temizleme işleri ve karmaşık sorgu mantığı ödersiniz.
- Çoğaltılmış “email” alanları (
users.emailvecustomers.emailgibi): çakışan kimlikler ve çift indeksler oluşur. - Serbest biçimli durum (status) dizeleri:
Cancelledvscanceledgibi yazım farkları gizli segmentler yaratır ve filtreleri ve raporlamayı bozar.
Erken dönemde hız istiyorsanız, kötü veri depolamayı zorlaştırın. Veritabanı size daha basit planlar, daha küçük indeksler ve daha az performans sürprizi ile ödüllendirir.
Normalizasyon vs Denormalizasyon: Pratik Bir Denge
Design your schema in chat
Turn entities, keys, and constraints into a PostgreSQL schema while you build.
Normalizasyon basit bir fikirdir: her “gerçek” bir yerde saklanmalı, böylece veritabanına veriler her yere kopyalanmaz. Aynı değer birden çok tabloya kopyalandığında güncellemeler riskli hale gelir—bir kopya değişir, diğeri değişmez ve uygulama çelişkili cevaplar göstermeye başlar.
Normalizasyon (varsayılan): bir gerçek, bir yer
Pratikte normalizasyon, güncellemelerin temiz ve öngörülebilir olması için varlıkları ayırmayı ifade eder. Örneğin, bir ürünün adı ve fiyatı products tablosunda olmalı, her sipariş satırında tekrar edilmemelidir. Bir kategori adı categories içinde olmalı ve ID ile referanslanmalıdır.
Bu şunları azaltır:
- tekrar eden veri (daha az depolama, daha az tutarsızlık)
- güncelleme hataları (bir kez değiştir, her yerde yansısın)
- “hangi değer doğru?” hatalarını
Aşırı normalizasyon zarar verebilir
Veriyi çok fazla parçalara ayırmak, günlük ekranlar için sık sık join gerektirdiğinde zarar verebilir. Veritabanı doğru sonuçları döndürebilir, ama yaygın okumalar daha yavaş ve daha karmaşık olur çünkü her istek çoklu join gerektirir.
Erken aşamada tipik bir belirti: basit bir sayfa (ör. sipariş geçmişi listesi) 6–10 tabloyu join etmek zorunda kalır ve performans trafik ile cache durumuna göre değişir.
Pratik yaklaşım: çekirdek gerçekleri normalize et, en sıcak okumaları denormalize et
Mantıklı denge:
- Çekirdek gerçekleri ve sahipliği normalize et (gerçeğin kaynağı). Ürün özniteliklerini
productsiçinde tutun, kategori adlarınıcategoriesiçinde ve ilişkileri yabancı anahtarlarla yapın. - En çok okunan yollar için dikkatli denormalizasyon—faydayı açıklayabildiğiniz ve doğruluğu nasıl korunacağını planlayabildiğiniz durumlarda.
Denormalizasyon, sık sorguyu daha ucuz yapmak için küçük bir veri parçasını kasıtlı olarak çoğaltmak demektir (daha az join, daha hızlı listeler). Anahtar kelime dikkatli: her çoğaltılmış alanın güncel tutulması için bir planı olmalı.
Örnek: ürünler, kategoriler ve sipariş kalemleri
Normalize bir yapı şöyle olabilir:
products(id, name, price, category_id)categories(id, name)orders(id, customer_id, created_at)order_items(id, order_id, product_id, quantity, unit_price_at_purchase)
Dikkat edilmesi gereken ince nokta: order_items içinde unit_price_at_purchase tutulması (bir tür denormalizasyon) tarihsellik için gereklidir çünkü ürün fiyatı daha sonra değişse bile geçmiş doğruluğa ihtiyaç vardır. Bu çoğaltma kasıtlı ve stabildir.
Eğer en yaygın ekranınız “ürün özetli siparişler” ise order_items içine product_name denormalize etmeyi düşünebilirsiniz—ancak bunu senkronize tutmaya veya satınalma zamanının bir anlık görüntüsü olduğunu kabul etmeye hazırlıklı olun.
İndeks Stratejisi Şemayı Takip Eder, Tam Tersine Değil
İndeksler genellikle sihirli bir "hız düğmesi" gibi görülür, ama onlar yalnızca temel tablo yapısı anlamlı olduğunda iyi çalışır. Hâlâ sütunları yeniden adlandırıyorsanız, tabloları bölüyorsanız veya kayıtların birbirleriyle nasıl ilişkili olduğunu değiştiriyorsanız, indeks setiniz de sürekli değişir. İndeksler, sütunlar (ve uygulamanın bu sütunlarda nasıl filtrelediği/sıraladığı) yeterince stabil olduğunda en iyi sonucu verir.
Uygulamanızın en çok sorduğu sorularla başlayın
Mükemmel tahmin gerekmez, ama en çok önem taşıyan sorguların kısa bir listesini bilmelisiniz:
- “Bir kullanıcıyı e-posta ile bul.”
- “Bir müşterinin yeni siparişlerini göster.”
- “Faturalari duruma göre, en yeniden başlayarak listele.”
Bu ifadeler doğrudan hangi sütunların indekslenmesi gerektiğini söyler. Bunları açıkça söyleyemiyorsanız, genellikle sorun şema netliğiyle ilgilidir—indeksleme değil.
Bileşik indeksler, sade dille
Bileşik indeks birden fazla sütunu kapsar. Sütun sırası önemlidir çünkü veritabanı indeksi soldan sağa verimli kullanır.
Örneğin, sık sık customer_id ile filtreleyip sonra created_at ile sıralıyorsanız, (customer_id, created_at) indeksi genellikle faydalıdır. Tersinin (created_at, customer_id) aynı sorguya o kadar yardımcı olmayabilir.
Her şeyi indekslemeyin
Her ek indeksin bir maliyeti vardır:
- Yazma işlemleri yavaşlar: insert/update işlemleri her endeksi güncellemek zorundadır.
- Daha fazla depolama: indeksler veritabanı boyutunun büyük bir kısmını oluşturabilir.
- Daha fazla karmaşıklık: ekstra indeksler bakım ve optimizasyonu zorlaştırır.
Temiz, tutarlı bir şema, doğru indeksleri gerçek erişim kalıplarına uyan küçük bir sete daraltır—sürekli yazma ve depolama vergisi ödemeden.
Yazma Performansı: Dağınık Bir Şemanın Gizli Maliyeti
Plan migrations before shipping
Use planning mode to map migration steps before you change production data.
Yavaş uygulamalar her zaman okumalardan kaynaklanmaz. Birçok erken performans sorunu ekleme ve güncelleme sırasında—kullanıcı kayıtları, ödeme işlemleri, arka plan işleri—görünür çünkü dağınık bir şema her yazmayı ekstra işe dönüştürür.
Neden yazmalar pahalılaşır
Bazı şema seçimleri her değişikliğin maliyetini sessizce katlar:
- Geniş satırlar: bir tabloda onlarca (veya yüzlerce) sütun doldurmak genellikle daha büyük satırlar, daha fazla I/O ve daha fazla cache değişimine yol açar—çoğu sütun nadiren kullanılsa bile.
- Çok fazla indeks: indeksler okumaları hızlandırır, ama her insert/update bunların her birini güncellemelidir.
- Trigger’lar ve cascade’ler: trigger’lar basit bir
INSERTarkasında gizli işleri saklayabilir. Cascade yapan yabancı anahtarlar doğru ve yardımcı olabilir ama ilişkili veriler büyüdükçe yazma zamanında ek iş yükü getirir.
Okuma-ağırlıklı vs yazma-ağırlıklı: acıyı bilinçli seçin
Yükünüz okuma-ağırlıklı ise (feed’ler, arama sayfaları) daha fazla indekslemeyi ve seçici denormalizasyonu tolere edebilirsiniz. Eğer yazma-ağırlıklı ise (olay alımı, telemetri, yüksek hacimli siparişler), yazmaları basit ve öngörülebilir tutan bir şema önceliğiniz olmalı; sonra yalnızca ihtiyaç duyulan yerde okuma optimizasyonları ekleyin.
Erken aşamada yazmaları kötüleştiren yaygın desenler
- Denetim günlükleri (audit logs): uyumluluk için iyidir, ama her güncellemede büyük snapshot’lar kaydetmekten kaçının.
- Olay tabloları: sadece ekleme yapılan tablolar iyi ölçeklenir, ama gereksiz yükleri saklarsanız şişebilirler.
- Soft delete: kullanışlıdır, ama indeks boyutunu artırır ve dikkatli planlanmazsa güncellemeleri/ sorguları yavaşlatır.
Geçmişi korurken yazmaları basit tutun
Pratik bir yaklaşım:
- “Mevcut durum”u bir tabloda, geçmişi ayrı bir append-only tabloda saklayın.
- Geçmiş satırlarını dar tutun (gerçekten ihtiyaç duyduğunuz: kim/ne zaman/ne değişti).
- Geçmiş için indeksleri gerçek erişim kalıplarına göre ekleyin (genelde
entity_id,created_at). - Denetim için başlangıçta trigger’lardan kaçının; maliyeti görünür ve test edilebilir kılmak için uygulama tarafında açık yazma tercih edin.
Temiz yazma yolları size baş boşluğu verir—ve sonraki sorgu optimizasyonlarını çok daha kolay yapar.
ORM’ler ve API’ler Şema Kararlarını Nasıl Büyütür
ORM’ler veritabanı işini zahmetsiz hissettirir: modelleri tanımlarsınız, metotları çağırırsınız ve veriler gelir. Ama tuzak şu ki, ORM pahalı SQL kalıplarını saklayabilir ta ki zarar verene kadar.
ORM’ler: kolaylık ama yavaş kalıpları gizleyebilir
İki yaygın tuzak:
- Verimsiz join’ler: basit görünen bir
.include()veya iç içe serializer geniş join’lere, tekrar eden satırlara veya büyük sıralamalara dönüşebilir—özellikle ilişkiler net tanımlı değilse. - N+1 sorgu: 50 kayıt çekersiniz, sonra ORM ilişkilileri yüklemek için sessizce 50 tane daha sorgu çalıştırır. Geliştirmede çalışır, gerçek trafikte çöker.
İyi tasarlanmış bir şema bu kalıpların ortaya çıkma şansını azaltır ve çıktıklarında tespit etmeyi kolaylaştırır.
Açık ilişkiler ORM kullanımını daha güvenli kılar
Tablolar belirgin yabancı anahtarlar, benzersiz kısıtlar ve not-null kuralları içerdiğinde ORM daha güvenli sorgular üretebilir ve kodunuz tutarlı varsayımlara dayanabilir.
Örneğin, orders.user_id’nin var olmasını (FK) ve users.email’in benzersiz olmasını zorunlu kılmak, uygulama düzeyinde ekstra kontrollera ve ek sorgu işine yol açan birçok hata sınıfını önler.
API’ler şema seçimlerini ürün davranışına dönüştürür
API tasarımınız şemanın bir çıktısıdır:
- Stabil IDler (ve tutarlı anahtar tipleri) URL’leri, cache’i ve istemci durumunu basitleştirir.
- Sayfalandırma genellikle indeksli, monotonik bir sütuna göre sıralandığında en iyi çalışır (çoğunlukla
created_at+id). - Filtreleme sütunlar gerçek öznitelikleri temsil ettiğinde (aşırı yüklenmiş stringler veya JSON blob’ları değil) ve kısıtlamalar değerleri temiz tuttuğunda öngörülebilir olur.
Kurtarma operasyonu değil, iş akışı yapın
Şema kararlarını birinci sınıf mühendislik işi olarak ele alın:
- Her değişiklik için migrasyon kullanın, kod gibi gözden geçirin.
- Yeni endpoint’ler için hafif “şema incelemeleri” yapın: hangi tablolar, hangi anahtarlar, hangi kısıtlamalar, sorgu şekli ne olacak.
- Aşamada ORM sorgularını loglayın ve üretime geçmeden önce N+1 kalıplarını işaretleyin.
Hızlı inşa ediyorsanız ve sohbet temelli bir geliştirme akışı kullanıyorsanız (örneğin, tek konuşmada bir React uygulaması ve Go/PostgreSQL backend üretiyorsanız Koder.ai), “şema incelemesi”ni erken konuşmaya dahil etmek faydalıdır. Hızla yineleyebilirsiniz, ama trafik gelmeden önce kısıtlamalar, anahtarlar ve migrasyon planının kasıtlı olması önemlidir.
Şemanın Darboğaz Olduğuna Dair Erken Uyarı İşaretleri
Bazı performans problemleri “kötü SQL”den ziyade veritabanının verinin şekliyle savaşıyor olmasındandır. Birçok endpoint ve raporda aynı sorunları görüyorsanız, genellikle bu bir şema sinyalidir, sorgu-tuning fırsatı değil.
İzlenecek yaygın belirtiler
Basit filtrelerin yavaş olması klasik bir işarettir. Eğer “müşteri ile siparişleri bul” veya “oluşturulma tarihine göre filtrele” gibi basit koşullar sürekli yavaşsa, sorun eksik ilişkiler, uyumsuz tipler veya indekslenemeyen sütunlar olabilir.
Başka bir kırmızı bayrak artan join sayısıdır: temel olarak 2–3 tablo join’lemesi gereken bir sorgu temel bir soruyu cevaplamak için 6–10 tablo zincirine dönüyorsa (çoğunlukla aşırı normalize edilmiş lookuplar, polimorfik kalıplar veya "her şey tek tabloda" tasarımları yüzünden) şema sorguya yük bindiriyor demektir.
Ayrıca enum gibi davranan sütunlardaki tutarsız değerlere dikkat edin—özellikle durum alanlarında (“active”, “ACTIVE”, “enabled”, “on”). Tutarsızlık savunmacı sorgulara (LOWER(), COALESCE(), OR zincirleri) yol açar ve bu sorgular ne kadar optimize edilirse edilsin yavaş kalır.
Şema kontrol listesi (hızlı doğrulama)
- Yabancı anahtarlar üzerinde eksik indeksler (join’ler büyüdükçe tam taramalar olur).
- Yanlış veri tipleri (örn. ID’ler string olarak saklanmış, tarihler metin, para float).
- EAV tabloları (Entity–Attribute–Value) çekirdek veri için kullanılmış: başlangıçta esnek ama filtreleme/sıralama çok sayıda join ve zor indekslenebilir predikatlara döner.
Basit, araç bağımsız teşhisler
Gerçeklik kontrolleriyle başlayın: tablo başına satır sayıları ve ana sütunlar için kardinalite (kaç farklı değer). Eğer bir “status” sütunu için 4 beklenen değer varken 40 değer görüyorsanız, şema zaten karmaşıklık sızdırıyor demektir.
Sonra yavaş endpoint’lerin sorgu planlarına bakın. Join sütunlarında tekrar eden sequantial scan’ler veya büyük ara sonuç setleri görüyorsanız, şema ve indeksleme muhtemel kök sebeptir.
Son olarak, yavaş sorgu loglarını etkinleştirip inceleyin. Birçok farklı sorgu benzer şekilde yavaşsa (aynı tablolar, aynı predikatlar), bu genellikle model düzeyinde düzeltmeye değer yapısal bir sorundur.
Büyürken Şemayı Güvenle Evriltme
Build React and Go fast
Create a React app with a Go and PostgreSQL backend from one conversation.
Erken şema seçimleri nadiren gerçek kullanıcıyla ilk temasta değişmeden kalır. Hedef mükemmel olmak değil—üretimi bozmadan, veri kaybetmeden ya da ekibi bir hafta boyunca kilitlemeden değişebilmektir.
Hafif, tekrarlanabilir değişiklik süreci
Tek kişilik bir uygulamadan daha büyük bir ekibe kadar ölçeklenen pratik iş akışı:
- Modelle: Yeni şekli yazın (tablolar/sütunlar, ilişkiler ve gerçeğin nerede saklanacağı). Örnek kayıtlar ve kenar durumları ekleyin.
- Migrate: Geriye dönük uyumlu şekilde yeni yapıları ekleyin (önce yeni sütunlar/tablolar; hemen silme veya yeniden adlandırmadan kaçının).
- Backfill: Mevcut veriden yeni alanları partiler halinde doldurun. İşin ilerlemesini takip edin ki kaldığınız yerden devam edebilin.
- Validate: Veriler temizlendikten sonra kısıtlamaları ekleyin (örn. NOT NULL, yabancı anahtarlar). Eski ve yeni çıktıları karşılaştıran kontroller çalıştırın.
Feature flag ve çift yazma (seyrek kullanın)
Çoğu şema değişikliği karmaşık rollout desenleri gerektirmez. “Genişlet-ve-daralt” yaklaşımını tercih edin: kod hem eskiyi hem yeniyi okuyabilsin, sonra yazmaları bir kerede değiştirin.
Feature flag veya çift yazmayı yalnızca gerçekten kademeli geçiş gerektiğinde kullanın (yüksek trafik, uzun backfill’ler veya çoklu servisler). Çift yazma yapıyorsanız sürüklenmeyi tespit edecek monitoring ekleyin ve çakışmada hangi tarafın kazanacağını belirleyin.
Geri alma ve migrasyon testleri gerçeği yansıtmalı
Güvenli geri alma, geri alınabilir migrasyonlarla başlar. “Geri alma” yolunu pratik edin: yeni bir sütunu drop etmek kolaydır; üzerine yazılmış veriyi kurtarmak değildir.
Migrasyonları gerçekçi veri hacimleriyle test edin. Bir laptopta 2 saniyede biten bir migrasyon üretimde dakikalarca tablo kilitleyebilir. Üretime benzer satır sayıları ve indekslerle çalışın ve süreyi ölçün.
Platform araçları bu riski azaltabilir: güvenilir dağıtımlar, snapshot/rollback yetenekleri ve gerektiğinde kodu export etme imkanı, şema ve uygulama mantığını birlikte yinelemeyi daha güvenli kılar. Eğer Koder.ai kullanıyorsanız, migrations gerektirebilecek değişiklikler yapmadan önce snapshot’lara ve planlama moduna güvenin.
Gelecek kişi için kararları belgeleyin
Kısa bir şema günlüğü tutun: ne değişti, neden ve hangi ödünler kabul edildi. Bunu /docs veya repo README’sinden linkleyin. "Bu sütun kasıtlı denormalize edildi" veya "yabancı anahtar backfill sonrası 2025-01-10'da eklendi" gibi notlar ekleyin ki gelecekteki değişiklikler aynı hataları tekrarlamasın.
Sorguları Ne Zaman Optimize Etmeli (Mantıklı İşlem Sırası)
Sorgu optimizasyonu önemlidir—ama şema sizinle savaşırken en iyi getiriyi vermez. Eğer tablolar net anahtarlara sahip değilse, ilişkiler tutarsızsa veya “her şey bir satır” ihlal ediliyorsa, gelecek hafta yeniden yazılacak sorgulara saatler harcayabilirsiniz.
Pratik öncelik sırası
-
Önce şema engellerini düzeltin. Eksik birincil anahtarlar, tutarsız yabancı anahtarlar, birden fazla anlamı taşıyan sütunlar, çift kaynaklı doğruluk veya gerçeğe uymayan tipler gibi doğru sorgulamayı zorlaştıran her şeyi ele alın.
-
Erişim kalıplarını stabilize edin. Veri modeli uygulamanın nasıl davrandığını (ve önümüzdeki birkaç sprintte muhtemelen nasıl davranacağını) yansıttığında, sorgu iyileştirmeleri kalıcı olur.
-
En önemli sorguları optimize edin—tüm sorguları değil. Loglar/APM ile en yavaş ve en sık kullanılan sorguları belirleyin. Günde 10.000 kez çağrılan bir endpoint nadir bir admin raporundan daha önemlidir.
Erken dönemdeki 80/20’si
Erken kazanımlar şu küçük hamlelerden gelir:
- Doğru indeksi ekleyin: en yaygın filtreleriniz ve join’leriniz için (ve gerçekten kullanıldığını doğrulayın).
- Daha az sütun döndürün (
SELECT *’tan kaçının, özellikle geniş tablolarda). - Gereksiz join’lerden kaçının—bazen bir join sadece şema sizi zorladığı için vardır.
Beklentileri belirleyin: bu devam eden bir iş ama temeller önce gelir
Performans işi hiç bitmez, ama hedefi öngörülebilir kılmaktır. Temiz bir şema ile her yeni özellik kademeli yük ekler; dağınık bir şema ile her özellik bileşik kafa karışıklığı ekler.
Bu haftanın kontrol listesi
- En yavaş 5 ve en sık kullanılan 5 sorguyu listeleyin.
- Her biri için doğrulayın: birincil anahtar var mı, join’ler anahtar-anahtar mı ve tipler doğru mu.
- Baskın filtre/sıralamaya uyan bir indeks ekleyin.
- Bir sıcak yolda
SELECT *kullanımını değiştirin. - Ölçün ve bir sonraki sprint için basit bir “önce/sonra” notu tutun.