05 Eki 2025·8 dk
SLA İhlallerini İzlemek ve Önlemek için Gerçek Zamanlı Bir Web Uygulaması Oluşturun
SLA zamanlayıcılarını izleyen, ihlalleri anında tespit eden, ekipleri uyaran ve uyumluluğu gerçek zamanlı görselleştiren bir web uygulamasının pratik bir yol haritasını öğrenin.
SLA İzleme Hedefini Tanımlayın
Ekranları tasarlamadan veya tespit mantığını yazmadan önce, uygulamanızın neyi önlemeye çalıştığına net olun. “SLA izleme” günlük rapordan saniye saniye ihlal tahminine kadar her şeyi ifade edebilir—bunlar çok farklı ürünlerdir ve mimari ihtiyaçları da çok farklıdır.
“Gerçek zaman”ın ne anlama geldiğine karar verin (ve neden)
Başlangıç olarak ekibinizin gerçekçi bir şekilde uygulayabileceği tepki penceresinde uzlaşın.
Destek organizasyonunuz 5–10 dakikalık döngülerde çalışıyorsa (triaj kuyrukları, paging rotasyonları), “gerçek zaman” pano güncellemelerinin her dakika ve uyarıların 2 dakika içinde olması anlamına gelebilir. Yüksek şiddetli olaylarla uğraşıyorsanız ve dakikalar kritikse, 10–30 saniyelik tespit ve uyarı döngüsüne ihtiyaç duyabilirsiniz.
Bunu ölçülebilir bir hedef olarak yazın, örneğin: “Potansiyel ihlalleri 60 saniye içinde tespit et ve nöbetçiyi 2 dakika içinde bilgilendir.” Bu, daha sonra mimari ve maliyetle ilgili kararlar için bir kılavuz olur.
Hangi SLA’ları izlemeniz gerektiğini netleştirin
İzlediğiniz özel taahhütleri listeleyin ve her birini sade bir dille tanımlayın:
- İlk yanıt süresi (ör. “1 saat içinde yanıt verin”)
- Çözüm süresi (ör. “24 saat içinde çözün”, genellikle duraklatma kurallarıyla)
- Kullanılabilirlik/uptime (ör. “aylık %99.9”)
Ayrıca bunların kuruluşunuzdaki SLO ve SLA tanımlarıyla nasıl ilişkili olduğunu not edin. İçsel SLO müşteri SLA’sından farklıysa, uygulamanızın her ikisini de izlemesi gerekebilir: operasyonel iyileşme için biri, sözleşmesel risk için diğeri.
Paydaşları ve karar sahiplerini belirleyin
Sistemi kullanacak veya ona güvenecek grupları adlandırın: destek, mühendislik, müşteri başarı, ekip liderleri/yonetici ve olay müdahale/nöbetçi.
Her grup için “bu anda ne karara varmalılar?” sorusunu yakalayın: “Bu ticket risk altında mı?”, “Kimin sorumluluğunda?”, “Eskalasyona ihtiyaç var mı?” Bu, panonuzu, uyarı yönlendirmesini ve izinleri şekillendirecektir.
Uygulamanın tetiklemesi gereken eylemleri tanımlayın
Amacınız sadece görünürlük değil—zamanında harekettir. Risk yükseldiğinde veya bir ihlal olduğunda neler olması gerektiğine karar verin:
- Slack/e-posta/pager ile gerçek zamanlı uyarılar gönderin
- Şiddet, müşteri seviyesi veya mesai saatlerine göre escalate edin
- Otomatik görev (Jira/Linear) oluşturun ve bir sahibi atayın
İyi bir sonuç bildirimi: “Anlaşılmış tepki penceremiz içinde ihlal tespiti ve olay müdahalesini mümkün kılarak SLA ihlallerini azaltmak.”
SLA Kurallarınızı ve Kenar Durumları Haritalayın
Tespit mantığını inşa etmeden önce, servisinize göre “iyi” ve “kötü”nün tam olarak ne olduğunu yazın. Çoğu SLA izleme problemi teknik değil—tanım problemidir.
SLA vs SLO vs KPI (basit dil)
Bir SLA (Service Level Agreement) müşteriye verilen bir vaat olup genellikle sonuçları (kredi, ceza, sözleşme maddeleri) içerir. Bir SLO (Service Level Objective), SLA’nın üstünde güvenle kalmak için hedeflenen içsel bir hedeftir. Bir KPI (Key Performance Indicator) ise izlediğiniz herhangi bir metriktir (faydalı, ama her zaman bir vaadet bağlı değildir).
Örnek: SLA = “1 saat içinde yanıt ver.” SLO = “30 dakika içinde yanıt ver.” KPI = “ortalama ilk yanıt süresi.”
İhlal türlerini net şekilde tanımlayın
Tespit etmeniz gereken her ihlal türünü ve zamanlayıcıyı başlatan olayı listeleyin.
Yaygın ihlal kategorileri:
- Kaçırılmış yanıt süresi: ör. bilet 10:00'de oluşturuldu; ilk temsilci yanıtı 11:00'e kadar olmalı.
- Kaçırılmış çözüm süresi: ör. bilet açıldı; onaylanmış duraklatmalar hariç 24 saat içinde çözüme ulaşmalı.
- Kesinti eşiği: ör. servis aylık %99.9’un altına düşerse veya tek bir kesinti 15 dakikayı aşarsa.
“Yanıt”ın ne sayıldığı (kamuya açık yanıt vs iç not) ve “çözüm”ün ne olduğu (resolved vs closed) ile yeniden açmanın zamanlayıcıyı sıfırlayıp sıfırlamadığını açıkça belirtin.
Mesai saatleri, 7/24 ve zaman dilimi kuralları
Birçok SLA sadece mesai saatleri içinde sayılır. Takvimi tanımlayın: çalışma günleri, tatiller, başlangıç/bitiş saatleri ve hesaplama için kullanılacak zaman dilimi (müşterinin, sözleşmenin veya ekibin). İş sınırlarını aşan durumlarda ne olacağına da karar verin (ör. 16:55'te gelen ve 30 dakikalık yanıt SLA'sı olan bir bilet).
Duraklatma koşulları ve istisnalar
SLA saatinin durduğu durumları belgeleyin, örneğin:
- Müşteri bekleniyor (istenen bilgi sağlanmadı)
- Planlı bakım pencereleri
- Üçüncü taraf bağımlılığı bekleme (sözleşme izin veriyorsa)
Bunları uygulamanızın tutarlı şekilde uygulayabileceği kurallar olarak yazın ve zor durum örneklerini daha sonra test için saklayın.
İzlenecek Veri Kaynakları ve Olayları Seçin
SLA monitörünüzü besleyen veriler ne kadar iyi olursa, sonuçlar da o kadar güvenilir olur. Her SLA saatinin “kayıt sistemi” olarak hangi sistemleri kullandığını belirleyin. Birçok ekip için bilet aracı yaşam döngüsü zaman damgalarında tek kaynaktır; izleme ve log araçları ise neden olduğunu açıklar.
Gerçeği tutan sistemleri seçin
Çoğu gerçek zamanlı SLA kurulumu küçük bir çekirdek sistem setinden çekim yapar:
- Biletleme/helpdesk (ör. Zendesk, ServiceNow, Jira Service Management): öncelik, durum, atanan, müşteri, zaman damgaları
- İzleme/olay araçları (ör. Datadog, PagerDuty): olay açıldı/onaylandı/kapandı, nöbetçi işlemleri
- CRM/hesap verisi (ör. Salesforce, HubSpot): müşteri seviyesi, sözleşme SLA'sı, destek planı
- Loglar ve denetim izleri (uygulama logları, workflow logları): inceleme ve itirazlar için detay
Eğer iki sistem uyuşmazsa, hangi alan için hangi sistemin galip geleceğini önceden kararlaştırın (ör. “bilet durumu ServiceNow’dan, müşteri seviyesi CRM’den alınır”).
İzlemeniz gereken olayları listeleyin (ve unutulanları)
En azından SLA zamanlayıcısını başlatan, durduran veya değiştiren olayları izleyin:
- Bilet oluşturuldu (SLA başlar)
- Durum değişti ("müşteri bekleniyor", "beklemede" veya "duraklatıldı" durumları dahil)
- Atandı / yeniden atandı (çoğunlukla eskalasyon kurallarını etkiler)
- Öncelik veya şiddet değişti (SLA hedefini akış içinde değiştirebilir)
- İlk yanıt gönderildi ve çözüldü/kapatıldı (SLA durur)
Ayrıca operasyonel olayları düşünün: mesai takvimi değişiklikleri, müşteri zaman dilimi güncellemeleri ve tatil takvimi değişiklikleri.
Veriyi nasıl çekeceğinize karar verin
Yakın gerçek zamanlı güncellemeler için webhook tercih edin. Webhook yoksa veya güvenilmezse polling kullanın. Uzlaştırma için API dışa aktarımları/backfill saklayın (ör. açık boşlukları dolduran gece işi). Birçok ekip hibrit bir yol kullanır: hız için webhook, güvenlik için periyodik polling.
Veri kalitesi sorunlarına hazırlanın
Gerçek sistemler karmaşıktır. Bekleyin:
- Eksik zaman damgaları ("bilinmiyor" olarak saklayın ve inceleme için işaretleyin)
- Tekrarlanan olaylar (idempotentlik anahtarları ve dedup kuralları kullanın)
- Sıra dışı teslimat ve saat kayması (kaynağın zaman damgası + alım zamanına göre sıralayın ve negatif süreleri tespit edin)
Bunları “kenar durum” değil, ürün gereksinimleri olarak görün—ihlal tespitiniz bunlara bağlıdır.
Basit Yüksek Seviyeli Bir Mimari Tasarlayın
İyi bir SLA izleme uygulaması, mimari açık ve kasıtlı olduğunda inşa etmesi ve bakım yapması daha kolaydır. Yüksek seviyede ham operasyon sinyallerini “SLA durumu”na çeviren, sonra bunu insanları uyarmak ve pano beslemek için kullanan bir boru hattı kuruyorsunuz.
Temel bileşenler
Beş blok olarak düşünün:
- Ingest: biletleme sistemleri, uptime monitörleri, loglar veya dahili uygulamalardan olayları topla.
- Process: veriyi normalize et, müşteri/servise ilişkilendir ve SLA zamanlayıcılarını hesapla.
- Store: hem güncel SLA durumunu (hızlı okuma) hem de tarihçe/denetim kayıtlarını sakla.
- Alert: ihlal tahmini veya gerçekleşmesi durumunda bildirimler ve eskalasyonlar tetikle.
- Display: “şu an risk altında ne var” için web uygulama panosu ve inceleme için detaylar.
Bu ayrım sorumlulukları temiz tutar: ingest SLA mantığı içermemeli, panolar ağır hesaplamalar yapmamalıdır.
Akış (streaming) vs sık yeniden hesaplama
Gerçekten ne kadar "gerçek zaman"a ihtiyaç duyduğunuza erken karar verin.
- Olay akışı (önerilen, hızlı tepki için): olaylar geldiğinde (olay açıldı, durum değişti, servis düştü) SLA durumunu hemen güncelleyin. Bu düşük gecikmeli ihlal tahmini ve hızlı uyarılar sağlar.
- Sık yeniden hesaplama (başlamak için daha basit): her N dakikada bir iş çalıştırıp son verilerden SLA riskini yeniden hesaplayın. Bu saat düzeyindeki SLA'lar için işe yarar, ama kısa dalgalanmaları kaçırabilir veya yenileme döngüsü etrafında gürültü yaratabilir.
Pragmatik bir yaklaşım: birkaç SLA kuralı için sık yeniden hesaplama ile başlayın, sonra yüksek etkili kuralları akışa taşıyın.
Basit bir dağıtım modeliyle başlayın
İlk etapta çok bölge ve çok ortam karmaşıklığından kaçının. Tek bölge, bir üretim ortamı ve minimal bir staging genellikle veri kalitesi ve uyarı faydasını doğrulayana kadar yeterlidir. “Daha sonra ölçeklendir” bir tasarım kısıtlaması olsun, başlangıç gereksinimi değil.
Eğer panoyu ve iş akışlarını hızla çalışır hale getirmek istiyorsanız, sohbet tabanlı bir spesifikasyondan React tabanlı bir UI ve Go + PostgreSQL backend iskeleti oluşturmanıza yardımcı olabilecek Koder.ai gibi bir platform ilk sürümü hızlandırabilir.
Şimdi belirlemeniz gereken fonksiyonel olmayan gereksinimler
Bunları uygulamadan önce yazın:
- İzleme sisteminin kullanılabilirlik hedefi (ör. %99.9).
- Olaydan panoya/uyarıya uçtan uca gecikme (ör. <60 saniye).
- Geçmiş ve denetimler için saklama süresi (ör. 13 ay).
- Denetlenebilirlik: her SLA durumu değişikliği açıklanabilir olmalı (“bu duruma hangi olay neden oldu?”).
Olay Alma ve Normalizasyonu İnşa Edin
Olay alımı, SLA izleme sisteminizin ya güvenilir ya da gürültülü ve kafa karıştırıcı olmasını belirler. Amaç: birçok araçtan olay kabul etmek, bunları tek bir “gerçek” formata dönüştürmek ve her SLA kararını açıklayabilecek kadar bağlam saklamaktır.
Açık bir olay şeması tanımlayın
“SLA-ilişkili olay”ın nasıl göründüğünü standartlaştırarak başlayın. Pratik bir temel şema şunları içerir:
ticket_id(veya vaka/iş öğesi ID'si)timestamp(değişikliğin olduğu an, alındığı an değil)status(opened, assigned, waiting_on_customer, resolved, vb.)priority(P1–P4 veya eşdeğeri)customer(hesap/tenant tanımlayıcısı)sla_plan(hangi SLA kuralları geçerli)
Şemayı versiyonlayın (ör. schema_version) ki alanları evriltirken eski üreticileri kırmayın.
Hesaplamadan önce normalize edin
Farklı sistemler aynı şeyi farklı isimlendirebilir: “Solved” vs “Resolved”, “Urgent” vs “P1”, zaman dilimi farklılıkları veya eksik öncelikler. Küçük bir normalizasyon katmanı kurun:
- durumları tutarlı bir sete eşleştirir
- zaman damgalarını UTC'ye çevirir
- eksik alanları doldurur (veya işaretler)
- ihlal mantığını basitleştirecek türetilmiş alanlar ekler (
is_customer_wait,is_pausegibi)
İdempotentlik: olayları iki kez saymayın
Entegrasyonlar tekrar dener. Ingest idempotent olmalı. Yöntemler:
- üreticiden
event_idisteyin ve çiftleri reddedin - deterministik bir anahtar üretip (ör.
ticket_id + timestamp + status) upsert yapın
Açıklanabilir bir denetim izi tutun
“Niye uyardık?” sorusuna cevap verebilmek için her kabul edilen ham olayı ve her normalize edileni saklayın, ayrıca kim/ne tarafından değiştirildiğini kaydedin. Bu denetim geçmişi müşteri görüşmeleri ve iç incelemeler için gereklidir.
Hata durumları için dead-letter
Bazı olaylar ayrıştırma veya doğrulamada başarısız olur. Bunları sessizce atmayın. Orijinal yükü, hata nedenini ve yeniden deneme sayısını içeren bir dead-letter kuyruğuna/tablosuna yönlendirin ki eşlemeleri düzeltebilin ve güvenle yeniden oynatabilesiniz.
Durum, Geçmiş ve Denetimler için Depolama Seçin
Erişimi Kolaylaştırın
Ekiplerin hızlıca bulabilmesi için dahili SLA panonuzu özel bir alana koyun.
SLA uygulamanızın iki farklı “hafızaya” ihtiyacı vardır: şu anda ne doğru (uyarı tetiklemek için) ve zaman içinde ne oldu (neden uyarı verildiğini açıklamak için).
Hızlı kararlar için güncel durumu saklayın
Güncel durum her iş öğesinin (bilet/olay/sipariş) en son bilinen durumu ve aktif SLA zamanlayıcılarını içerir (başlama zamanı, duraklama süresi, vade zamanı, kalan dakika, mevcut sahip).
ID ile hızlı okuma/yazma ve basit filtreler için optimize edilmiş bir depo seçin. Yaygın seçenekler: ilişkisel veritabanı (Postgres/MySQL) veya anahtar-değer (Redis/DynamoDB). Birçok ekip için Postgres yeterlidir ve raporlamayı basit tutar.
Durum modelini küçük ve sorgu-dostu tutun. “Çok yakında ihlal olacaklar” gibi görünümler için sık okunur.
Geçmişi eklemeye dayalı bir olay günlüğü olarak saklayın
Geçmiş her değişikliği değişmez bir kayıt olarak yakalamalı: oluşturuldu, atandı, öncelik değişti, durum güncellendi, müşteri cevap verdi, on-hold başladı/bitti vb.
Bir ekleme-yalnızca olay tablosu (veya event store) denetimler ve yeniden oynatma için gereklidir. Mantık hatası keşfederseniz, olayları yeniden işleyip durumu yeniden oluşturabilirsiniz.
Pratik desen: başlangıçta aynı veritabanında state table + events table; hacim büyürse analitik depolamaya taşıyın.
Saklama ve arşivleme kararları
Amaçlara göre saklama belirleyin:
- Operasyonel görünümler: yakın durumu ve kısa tarihçe penceresini hızlı tutun (örn. 30–90 gün).
- Denetim/uyumluluk: olayları daha uzun tutun (örn. 1–7 yıl), sonra daha ucuz depolamaya arşivleyin.
Arşiv ve silmeleri öngörülebilir kılmak için bölümlendirme (ay/çeyrek) kullanın.
Ana ekranlarınız için indeksler ve sorgular
Panonuzun en sık soracağı sorulara göre plan yapın:
- “Çok yakında ihlal olacak”:
due_atvestatusüzerinde indeks (ve gerekirsequeue/team). - “Bugün ihlal olanlar”:
breached_atveya hesaplanmış ihlal bayrağı ve tarih üzerinde indeks. - Müşteri/servis bazlı görünümler:
(customer_id, due_at)gibi birleşik indeksler.
Performans burada kazanılır: depolamayı en çok kullanılan 3–5 görünüm etrafında yapılandırın.
Gerçek Zamanlı İhlal Tespit Mantığını Uygulayın
Gerçek zamanlı ihlal tespiti büyük ölçüde şuna dayanır: dağınık, insan süreçlerini (atanma, müşteri beklemesi, yeniden açma, transfer) güvenilir SLA zamanlayıcılarına dönüştürmek.
SLA zamanlayıcıları: başlat, durdur, duraklat, devam ettir
Hangi olayların SLA saatini kontrol ettiğini tanımlayarak başlayın. Yaygın desenler:
- Başlat: bilet oluşturulduğunda veya ilk kez “destek aktif” statüsüne girdiğinde.
- Duraklat: “Müşteri bekleniyor” veya “On hold” durumuna geçtiğinde.
- Devam ettir: müşteri yanıt verdiğinde veya bilet aktif kuyruğa döndüğünde.
- Durdur: resolved/closed olduğunda (veya ilk yanıt SLA’sı sağlandığında).
Bu olaylardan bir vade zamanı hesaplayın. Katı SLA'lar için bu “created_at + 2 saat” olabilir. Mesai saatlerini dikkate alan SLA'lar için “2 iş saati” gerekir; bu da bir takvim gerektirir.
Yeniden kullanılabilir iş takvimi modülü
Her SLA kuralının tutarlı şekilde cevaplayabileceği küçük bir takvim modülü oluşturun:
- “A ile B arasında ne kadar iş süresi geçti?”
- “A’dan sonra N iş dakikası hangi zaman damgasına denk gelir?”
Tüm tatilleri, çalışma saatlerini ve zaman dilimlerini tek bir yerde tutun ki her kural aynı mantığı kullansın.
Kalan süre ve ihlal riski
Bir vade zamanınız olduğunda, kalan süreyi hesaplamak basittir: due_time - now (uygulamaya göre iş dakikasıysa iş dakikası olarak). Sonra “15 dakika içinde vade”, “SLA’nın %10’undan az kaldı” gibi ihlal riski eşikleri tanımlayın. Bu, aciliyet rozeti ve uyarı yönlendirmesini besler.
Sürekli yeniden hesaplama vs zamanlanmış tickler
Şunlardan birini seçebilirsiniz:
- Sürekli yeniden hesaplama (ilgili her olay + her okuma üzerine): kavramsal olarak en basit ama ölçeklendiğinde maliyetli olabilir.
- Zamanlanmış tickler (ör. her dakika): kalan süreyi günceller ve “risk” geçişlerini toplu işler.
Pratik hibrit: doğruluk için olay odaklı güncellemeler + zaman bazlı eşik geçişlerini yakalamak için dakikalık tick.
Uyarı, Eskalasyon ve Bildirim Kurun
Uygulamayı Sahiplenin
Daha derin özelleştirme için hazır olduğunuzda kaynak kodunu dışa aktararak tam kontrolü elinizde tutun.
Uyarılar SLA izlemeyi operasyonel hale getirir. Amaç “daha fazla bildirim” değil—doğru kişiyi doğru eylemi almaya yönlendirmektir.
Uyarı türlerini tanımlayın (ve ne anlama geldiklerini)
Küçük bir uyarı seti kullanın ve her birinin amacı net olsun:
- Risk uyarısı: SLA hâlâ sağlanabilir ama ihlale doğru gidiyor (örn. “30 dakika içinde ihlal olası”).
- İhlal onayı: SLA resmen ihlal edildi; zaman damgası ve etkilenen kapsam verilir.
- Eskalasyon adımı: sorun kabul edilmezse zamanlı bir takip.
Her türü farklı aciliyet ve teslim kanalına eşleyin (sohbet uyarıları risk için, paging onaylanmış ihlaller için vb.).
Uyarıları ekip, servis, öncelik ve müşteri seviyesine göre yönlendirin
Yönlendirme veri odaklı olmalı, sabit kodlanmış değil. Basit bir kurallar tablosu kullanın: servis → sahip ekip, sonra modifiye edin:
- Öncelik/seviye (P0–P3)
- Müşteri seviyesi (kurumsal vs standart)
- Mesai saatleri vs mesai dışı nöbetçi
Bu, herkesi bilgilendirmek yerine sahipliği görünür kılar.
Uyarı spam'ini önlemek için deduplike ekleyin
Olay müdahalesi sırasında SLA durumu hızlıca değişebilir. Şu anahtarlarla deduplike yapın: (ticket_id, sla_rule_id, alert_type) ve şunları uygulayın:
- kısa bir soğuma penceresi (örn. 5–15 dakika)
- durum tabanlı gönderim (sadece geçişlerde bildirim)
Ayrıca birden fazla uyarıyı periyodik özet halinde paketlemeyi düşünün.
Her uyarıda net bağlam verin
Her bildirim “ne, ne zaman, kim, şimdi ne yapmalı” sorusunu yanıtlamalı:
- Sahip/ekip ve nöbet hedefi
- Vade zamanı ve kalan süre
- Sonraki eylem (onayla, ata, yanıt ver)
- İş öğesine doğrudan bağlantı metni (ör. /tickets/123) ve SLA görünümü referansı (ör. /sla/tickets/123)
Eğer bir kişi bunu okuyup 30 saniye içinde harekete geçemiyorsa, uyarının daha iyi bir bağlama ihtiyacı vardır.
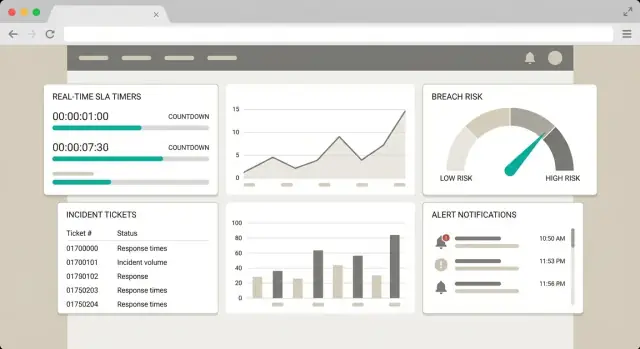
Pano ve Kullanıcı İş Akışlarını Tasarlayın
İyi bir SLA panosu grafiklerden çok bir kişinin bir dakika içinde ne yapması gerektiğine karar vermesine yardımcı olur. UI’yı üç sorunun etrafında tasarlayın: Ne risk altında? Neden? Hangi eylem?
Ekiplerin çalışma şekline uyan temel görünümler
Dört basit görünümle başlayın, her birinin net bir amacı olsun:
- Genel Bakış: iş yükü ve riskin anlık görüntüsü (açık toplam, yakında vade, ihlal olmuş, en çok etkilenen müşteriler).
- Yakında ihlal olacaklar: günlük operasyonel gelen kutusu—en yüksek aciliyete sahip öğeler.
- İhlal olanlar: olay müdahalesi, eskalasyon veya müşteri güncellemesi gerekenler.
- Uyumluluk trendleri: yöneticilerin tekrarlayan sorunları görmesi için haftalık/aylık raporlama.
Varsayılan görünümü yakında ihlal olacaklara odaklı tutun; önleme burada gerçekleşir.
Basit (ama faydalı) filtreler
Kullanıcılara gerçek sahiplik ve triaj kararlarına denk gelen küçük bir filtre seti verin:
- Ekip/kuyruk
- Öncelik
- Müşteri
- SLA planı
- Zaman aralığı (son 24s, 7g, 30g)
Filtreleri kullanıcı başına yapışkan (sticky) tutun ki her ziyaret yeniden yapılandırmasınlar.
Bir biletin neden riskte olduğunu açıklayın
“Yakında ihlal olacaklar” listesindeki her satır kısa, sade bir açıklama içermeli, örneğin:
- SLA saati: kalan 2s 10d (hedef 4s)
- Duraklatma süresi: hariç tutulan 1s 30d (müşteri bekleniyor)
- Uygulanan kural: “P1 Mesai Saatleri (Pzt–Cum)”
- Sonraki vade: yerel saatle 15:40
Bir “Detaylar” çekmecesi ekleyin; SLA durum değişikliklerinin zaman çizelgesini (başladı, duraklatıldı, devam etti, ihlal) göstererek kullanıcının hesaplamaya güvenmesini sağlayın.
İş akışı ve eylem butonları
Varsayılan iş akışını şu şekilde tasarlayın: incele → aç → işlem yap → onayla.
Her öğe, kaynağa atlayan eylem butonlarına sahip olmalı:
- Bileti aç: /tickets/{id}
- Müşteriyi görüntüle: /customers/{id}
- Eskalasyon politikası: /oncall/{team}
Hızlı eylemler (ata, öncelik değiştir, not ekle) sunacaksanız, bunları yalnızca tutarlı şekilde uygulayabileceğiniz yerlerde gösterin ve değişiklikleri denetleyin.
Güvenlik, İzinler ve Veri Yönetimini Ekleyin
Gerçek zamanlı bir SLA izleme uygulaması hızla performans, olaylar ve müşteri etkisi için bir kayıt sistemi haline gelir. İlk günden üretim sınıfı yazılım gibi davranın: kim ne yapabilir sınırlandırın, müşteri verilerini koruyun ve verinin nasıl saklandığını/silindiğini belgelendirin.
Roller ve izinleri tanımlayın
Küçük, net bir izin modeliyle başlayın ve gerektiğinde genişletin. Yaygın bir kurulum:
- Viewer: panolara ve raporlara salt okunur erişim.
- Operator: uyarıları onaylayabilir, not ekleyebilir, olay oluşturabilir ve eskalasyon tetikleyebilir.
- Admin: SLA tanımlarını, entegrasyonları, yönlendirme kurallarını, kullanıcıları ve veri politikalarını yönetir.
İzinleri iş akışlarıyla hizalayın. Örneğin, bir operator olay durumunu güncelleyebilir, ama sadece admin SLA zamanlayıcılarını veya eskalasyon kurallarını değiştirebilir.
Hassas alanları koruyun ve erişimi denetleyin
SLA izleme genellikle müşteri tanımlayıcıları, sözleşme seviyeleri ve bilet içeriği içerir. Maruziyeti azaltın:
- Varsayılan olarak müşteri detaylarını maskeleyin veya kırpın (tam değerleri yalnızca yetkili roller görsün).
- Görüntüleme adı ile benzersiz ID'yi ayırın ki panolar özel veriler göstermeden de faydalı olsun.
- Hassas görünümlere ve dışa aktarımlara erişimi kim, ne zaman, nereden kaydedin.
Entegrasyonları uçtan uca güvenli hale getirin
Entegrasyonlar sıkça zayıf nokta olur:
- En az ayrıcalık ilkesi uygulayın: yalnızca olay okumak veya bildirim göndermek için gereken izinleri verin.
- Jetonları secrets manager içinde saklayın (kodda veya pano ayarlarında değil).
- Personel değişikliklerinde veya şüpheli sızıntıda jetonları hemen değiştirin.
- Mümkünse webhooks için imza doğrulama veya kısa ömürlü kimlik bilgileri tercih edin.
Veri işleme politikalarını erken belirleyin
Ay başında çok tarih birikmeden önce kuralları koyun:
- Saklama: ham olayları, hesaplanmış SLA durumlarını ve denetim günlüklerini ne kadar süre tutacaksınız?
- Silme: müşteri verisi talebi üzerine nasıl silinecek (ve uyumluluk için nelerin silinemeyeceği)?
- Dışa aktarımlar: kim operasyonel raporları hangi formatta dışa aktarabilir ve hangi kırpmalar uygulanır?
Bu kuralları yazılı hale getirin ve UI’da yansıtın ki ekip sistemin neyi tuttuğunu ve ne kadar süre tuttuğunu bilsin.
Sistemi Test Edin, Doğrulayın ve İzleyin
SLA Kurallarını Erken Kilitleyin
Uygulamaya koymadan önce zamanlayıcıları, duraklatmaları ve kenar durumlarını planlama modunda yazın.
SLA izleme uygulamasını test etmek “UI yükleniyor mu”dan çok “zamanlayıcılar, duraklamalar ve eşikler sözleşmenizin beklediği gibi her seferinde tam olarak hesaplanıyor mu” sorusudur. Küçük bir hata (zaman dilimleri, mesai saatleri, eksik olaylar) gürültülü uyarılara veya daha kötüsü kaçırılmış ihlallere yol açabilir.
Kuralları gerçekçi senaryolarla doğrulayın
SLA kurallarınızı uçtan uca simüle edilebilecek somut senaryolara çevirin. Normal akışların yanında rahatsız edici kenar durumlarını da dahil edin:
- Mesai bitiminden hemen önce oluşturulan biletler
- Olay sırasında öncelik değişiklikleri (saat sıfırlanır mı?)
- Müşteri yanıtı zamanlayıcıyı duraklatır ve doğru şekilde devam ettirir
- Çift olaylar, sıra dışı teslimat ve eksik “resolved” olayları
Hesaplama mantığınızın gerçek operasyonel karmaşıklık altında stabil olduğunu kanıtlayın.
Yeniden oynatılabilir olay fişekleri kullanın
Yeniden oynatılabilir olay fişekleri oluşturun: mantık değiştiğinde ingest ve hesaplama üzerinden yeniden çalıştırılabilen küçük bir “olay zaman çizelgeleri” kitaplığı. Bu, hesaplamayı zaman içinde doğrulamaya ve regresyonları önlemeye yardımcı olur.
Fişekleri Git’te versiyonlayın ve beklenen çıktıları (kalan süre, ihlal anı, duraklama pencereleri, uyarı tetiklemeleri) dahil edin.
İzleme uygulamasını da izleyin
SLA monitörünü diğer üretim sistemleri gibi ele alın ve kendi sağlık sinyallerini ekleyin:
- Alım gecikmesi (gerçek zamandan ne kadar geri kaldığınız)
- Başarısız olay işleme / dead-letter sayıları
- Zamanlayıcı hesaplama hataları (SLA türüne göre)
- Uyarı teslim başarı oranı ve teslim süresi
Panonuz “yeşil” gösterirken olaylar takılı kalıyorsa güven hızla gider.
Takılı boru hatları ve yeniden hesaplama için runbook’lar
Yinelenen hata modları için kısa, net bir runbook yazın: takılı tüketiciler, şema değişiklikleri, üst sistem kesintileri ve backfill. Olayları güvenle yeniden oynatma ve zamanlayıcıları yeniden hesaplama adımlarını (hangi dönem, hangi tenantlar, çift uyarı riskini nasıl önlersiniz) ekleyin. Bunu dahili doküman hub'ınıza veya /runbooks/sla-monitoring benzeri basit bir sayfaya bağlayın.
Kademeli Olarak Yayınlayın ve İterasyonları Planlayın
Bir SLA izleme uygulamasını teslim etmek, onu bir ürün gibi ele aldığınızda en kolaydır. Minimum uygun sürüm (MVP) ile başlayın: ingest → değerlendirme → uyarı → birinin gerçekten harekete geçtiğini doğrulama döngüsünü kanıtlayın.
Minimum uygulanabilir sürümle başlayın
Bir veri kaynağı, bir SLA türü ve temel uyarılar seçin. Örneğin, tek bir biletleme sisteminden “ilk yanıt süresi”ni izleyin ve saat dolmadan önce uyarı gönderin. Bu, kapsamı dar tutar ve zaman damgaları, zaman pencereleri ve sahiplik gibi zor kısımları doğrular.
MVP stabil olduğunda küçük adımlarla genişleyin: önce ikinci bir SLA türü ekleyin (çözüm süresi), sonra ikinci veri kaynağı, sonra daha zengin iş akışları.
Ortamları ve güvenli roll-outları planlayın
Erken dev, staging ve production ortamlarını kurun. Staging, prod konfigürasyonlarını (entegrasyonlar, planlar, eskalasyon yolları) gerçekçi şekilde yansıtmalı ama gerçek yanıtlayıcıları bildirmemeli.
Feature flag kullanın:
- Yeni ihlal kurallarını önce pilot ekibe açın
- Yeni entegrasyonları “sadece gözlemle” modunda ekleyin (tespitleri logla, uyarı gönderme)
- UI değişikliklerini bir toggle arkasına koyun ki hızlıca geri alınabilsin
Koder.ai gibi bir platformla hızlı inşa ediyorsanız, snapshot ve rollback özellikleri pilot aşamasında faydalı olur.
Ekiplerin benimsemesi için onboarding dokümantasyonu yazın
Kısa, pratik kurulum dökümanları yazın: “Veri kaynağını bağla”, “Bir SLA oluştur”, “Bir uyarıyı test et”, “Bildirim aldığınızda ne yapmalı?”. Bu dokümanları ürünün yanında, ör. /docs/sla-monitoring benzeri bir yerde bulun.
İterasyon backlog’u oluşturun
İlk benimsemeden sonra güveni artıran ve gürültüyü azaltan iyileştirmeleri önceliklendirin:
- Olağandışı hacim veya anormal SLA riski sıçramaları için basit anomali tespiti
- Önemli servisler için müşteri tarafı durum sayfaları (opsiyonel)
- Planlı operasyonel raporlar (haftalık SLA özeti, en çok ihlal nedeni, trend çizgileri)
İterasyonları gerçek olaylara göre yapın: her uyarı size otomatikleştirecek, netleştirecek veya kaldıracak bir şey öğretmeli.
SSS
SLA izleme hedefi nedir ve nasıl tanımlanır?
Bir SLA izleme hedefi şuna benzer ölçülebilir bir ifadedir:
- Ne önlenmek isteniyor (ör. ilk yanıt ihlalleri, çözüm süreleri, kullanılabilirlik düşüşleri)
- Riskin ne kadar sürede tespit edilmesi gerektiği (ör. 60 saniye içinde)
- Harekete geçebilecek birine ne kadar sürede bildirim yapılması gerektiği (ör. 2 dakika içinde)
Bunu test edilebilir bir hedef olarak yazın: “Potansiyel ihlalleri X saniye içinde tespit et ve nöbetçi Y dakika içinde bilgilendir.”
SLA izleme için “gerçek zaman” ne anlama gelmeli ve bunu nasıl karar vermeliyim?
“Gerçek zaman” tanımını teknikten çok ekibinizin yanıt verebilme kapasitesine göre yapın.
- Eğer 5–10 dakikalık triaj döngüleriyle çalışıyorsanız, dakika düzeyinde güncellemeler ve yaklaşık 2 dakikada uyarılar hedefleyin.
- Eğer dakikaların kritik olduğu yüksek şiddetli durumlarla uğraşıyorsanız, 10–30 saniyelik tespit ve bildirim döngüsüne ihtiyaç duyabilirsiniz.
Anahtar nokta: bir (event → hesaplama → uyarı/pano) belirleyin ve tasarımı buna göre yapın.
Öncelikle hangi SLA türlerini izlemeliyim?
Öncelikle müşteriyle sözleşme gereği gerçekten ihlal edilebilecek taahhütleri izleyin (ve gerekirse kredi/ceza riski olanları):
- İlk yanıt süresi (yanıtın ne sayıldığı açık olmalı)
- Çözüm süresi (duraklatma kuralları dahil)
- Kullanılabilirlik/uptime (aylık yüzde veya tek seferlik kesinti eşikleri)
Birçok ekip ayrıca SLA'dan daha sıkı bir iç izler. Hem operasyonel erken uyarı hem de sözleşmesel raporlama için her ikisini de saklayıp gösterin.
Inşa etmeden önce hangi SLA kenar durumlarını belgelemeliyim?
SLA hatalarının çoğu tanım hatalarından gelir. Açıkça belirleyin:
- Başlatma olayı (bilet oluşturuluyor mu, mı yoksa “aktif” statüye mi giriyor?)
- Durdurma olayı (ilk halka açık yanıt mı? resolved vs closed?)
- Duraklatma koşulları (müşteri bekleniyor, beklemede, bakım)
- Sıfırlama davranışı (tekrar açma zamanlayıcıyı sıfırlar mı?)
Bu kuralları deterministik şekilde kodlayın ve test etmek için örnek zaman çizelgeleri koleksiyonu tutun.
SLA hesaplamalarında çalışma saatleri ve zaman dilimleri nasıl ele alınmalı?
Tutarlı bir takvim kural seti belirleyin:
- Çalışma günleri, başlangıç/bitiş saatleri, tatiller
- Hesaplama için kullanılacak zaman dilimi (müşteri, sözleşme veya ekip)
- Sınır davranışı (ör. kapanıştan 5 dakika önce gelen bir bilet)
Tek bir takvim modülü uygulayın ve şu soruları cevaplayabilsin:
- “A ile B arasında kaç iş saati geçti?”
Hangi veri kaynaklarını entegre etmeliyim ve hangi kaynak gerçek kayıt olmalı?
Alan adı olarak her alan için bir “kayıt sistemi” seçin ve sistemler çeliştiğinde hangisinin galip geleceğini belgeleyin.
Tipik kaynaklar:
- Bilet/ticketing: durum, atanan, zaman damgaları
- İzleme/incident araçları: olay yaşam döngüsü, nöbetçi işlemleri
- CRM: müşteri seviyesi, SLA planı
- Loglar/audit trail: inceleme için detay
Gerçek zamanlı için tercih edin; eksik olayları telafi için kullanın.
SLA zamanlayıcılarını doğru hesaplamak için hangi olayları izlemeliyim?
En azından SLA saatini başlatan, durduran veya değiştiren olayları yakalayın:
- Oluşturuldu
- Durum değişiklikleri (bekleme/duraklatma durumları dahil)
- Atama/yeniden atama
- Öncelik/seviyede değişiklikler
- İlk yanıt gönderildi
- Çözüldü/kapatıldı
Ayrıca iş takvimindeki değişiklikler, zaman dilimi güncellemeleri ve tatil takvimi gibi “insanların unutabileceği” olayları da planlayın—bunlar herhangi bir aktivite olmadan vade zamanını değiştirebilir.
Gerçek zamanlı bir SLA izleme web uygulaması için pratik bir mimari nedir?
Basit beş bloklu bir boru hattı kullanın:
- Ingest olayları topla
- Process normalizasyon + SLA hesaplama
- Store güncel durum + değişmez geçmiş
- Alert risk/ihlal geçişlerinde tetikle
- Display triaj ve inceleme için panolar
SLA durumunu streaming olaylarla mı yoksa zamanlanmış yeniden hesaplamayla mı hesaplamalıyım?
Aciliyete göre her ikisini birden kullanın:
- Olay odaklı (streaming): olay geldiğinde anında güncelleme; düşük gecikmeli uyarılar için en iyi.
- Zamanlanmış yeniden hesaplama (ticks): periyodik olarak yeniden hesaplama yapar; daha basit ama kısa pencereleri kaçırabilir.
Güçlü bir hibrit: doğruluk için olay tabanlı güncellemeler + eşik geçişlerini yakalamak için dakikada bir tick.
Uyarı spam'ini nasıl önleyip yine de SLA riskini erken yakalayabilirim?
Uyarıları bir iş akışı olarak yönetin, yayın değil:
- Birkaç uyarı türü tanımlayın: risk uyarısı, onaylanmış ihlal, .