Bu yazıda neler var (ve neden önemli)
Snowflake, bulut veri ambarcılığında basit ama kapsamlı bir fikri popüler hale getirdi: veri depolama ile sorgu hesaplamasını ayrı tutun. Bu ayrım veri ekiplerinin iki günlük temel sorusunu değiştirir—ambarların nasıl ölçeklendiği ve bunlar için nasıl ödeme yaptığınız.
Ambarı tek bir sabit “kutu” gibi ele almak yerine (daha fazla kullanıcı, daha fazla veri veya daha karmaşık sorguların hepsi aynı kaynaklar için rekabet ettiği yer), Snowflake’in modeli veriyi bir kez depolayıp ihtiyacınız olduğunda doğru miktarda hesaplama çalıştırmanızı sağlar. Sonuç genellikle daha hızlı cevap süreleri, yoğun kullanımda daha az darboğaz ve hangi işlemlerin ne zaman maliyet oluşturduğunu daha net kontrol etme imkanıdır.
Bu yazı, depolama ile hesaplamayı ayırmanın gerçekte ne anlama geldiğini ve bunun şu konuları nasıl etkilediğini sade bir dille açıklar:
- Eşzamanlılık (aynı anda birçok kişinin sorgu çalıştırması)
- Elastik ölçekleme (hesaplamayı yukarı/aşağı çevirmek)
- Maliyet davranışı (sadece çalışırken hesaplamaya ödeme ve devam eden depolama maliyeti)
Ayrıca modelin her şeyi sihirle çözmediği noktaları da göstereceğiz—çünkü bazı maliyet ve performans sürprizleri platformtan değil, iş yüklerinin tasarımından kaynaklanır.
Tema #2: neden ekosistem ham hız kadar önemli olabilir
Hızlı bir platform tek başına yeterli değildir. Pek çok ekip için değere ulaşma süresi, ambarı zaten kullandığınız araçlara ne kadar kolay bağlayabildiğinize bağlıdır—ETL/ELT boru hatları, BI panoları, katalog/yönetişim araçları, güvenlik kontrolleri ve ortak veri kaynakları.
Snowflake’in ekosistemi (veri paylaşım desenleri ve pazar yeri benzeri dağıtım dahil) uygulama sürelerini kısaltabilir ve özel mühendislik ihtiyacını azaltabilir. Bu yazı, “ekosistem derinliği”nin pratikte nasıl göründüğünü ve kuruluşunuz için bunu nasıl değerlendirebileceğinizi ele alır.
Kimler için
Bu rehber veri liderleri, analistler ve uzman olmayan karar vericiler için yazıldı—Snowflake mimarisinin, ölçeklemenin, maliyetin ve entegrasyon seçeneklerinin arkasındaki ödünleşmeleri satıcı jargonuna boğmadan anlaması gereken herkes için.
Ayrılmadan önce: geleneksel ambarlar neden tıkanır
Geleneksel veri ambarları basit bir varsayıma göre kurulmuştu: sabit miktarda donanım satın alırsınız (veya kiralarsınız), sonra her şeyi aynı kutuda veya kümede çalıştırırsınız. Bu, iş yükleri öngörülebilir ve büyüme yavaş olduğunda işe yarıyordu—ancak veri hacimleri ve kullanıcı sayısı hızlandığında yapısal sınırlamalar ortaya çıktı.
Klasik model: sabit kümeler ve dikkatli kapasite planlaması
On-prem sistemler (ve erken bulut “lift-and-shift” dağıtımları) genellikle şöyle görünüyordu:
- Depolama, CPU ve bellek aynı MPP (massively parallel processing) kümesi tarafından birlikte yönetilirdi.
- Yeniden boyutlandırma yavaş, riskli veya kesinti gerektirdiğinden kümeyi zirve ihtiyaçlarına göre boyutlandırırdınız.
- Kapasite planlaması sürekli bir proje haline gelirdi: büyümeyi tahmin et, bütçeyi gerekçelendir, donanım sipariş et, kur, taşı.
Tedarikçiler “düğümler” sunsa bile temel desen aynı kaldı: ölçek genelde tek paylaşılan ortamda daha büyük veya daha fazla düğüm eklemek demekti.
Ağrı noktaları: yavaş ölçekleme, israf ve kuyruklanma
Bu tasarım birkaç ortak baş ağrısı yaratır:
- Yavaş ölçekleme: Çeyreklik raporlama döneminde ani bir ihtiyaç artışı olursa, her zaman hızlıca ek güç sağlanamayabilir. Ya beklersiniz ya da “olur ya” diye aşırı kapasite alırsınız.
- Boşa harcanan kapasiteler: Zirveler için boyutlandırılan kümeler çoğu zaman kullanılmaz durumda durur—ama yine de maliyeti (donanım, lisans, operasyon zamanı) ödersiniz.
- Yük altında kuyruklanma: Birden çok ekip aynı anda sorgu çalıştırdığında kaynaklar için rekabet olur. Ağır işler etkileşimli panoları engelleyebilir; zaman aşımı, memnuniyetsizlik ve “iş saatlerinde bu sorguyu çalıştırma” gibi kurallar doğar.
Araçlar ve entegrasyonlar: güçlü ama çoğu zaman kırılgan
Bu ambarlar ortama sıkı bağlı olduğundan entegrasyonlar genellikle organik olarak gelişti: özel ETL script’leri, el yapımı konektörler ve tek seferlik boru hatları. Çalışırlardı—ta ki bir şema değişince, üst sistem taşınınca veya yeni bir araç eklenene kadar. Her şeyi çalışır tutmak sürekli bakım gibi hissedilebiliyordu.
Temel fikir: depolama ile hesaplamayı ayırmak
Geleneksel veri ambarları sıklıkla iki farklı görevi birbirine bağlar: depolama (verilerinizin yaşadığı yer) ve hesaplama (o veriyi okuyan, join’leyen, toplayan ve yazan işlem gücü).
Depolama vs. hesaplama (sade ifadeyle)
Depolama uzun vadeli bir kiler gibidir: tablolar, dosyalar ve metadata ucuz, dayanıklı ve her zaman erişilebilir şekilde saklanır.
Hesaplama ise mutfak ekibi gibidir: sorgularınızı 'pişiren' CPU ve bellek setidir—SQL çalıştırır, sıralar, tarar, sonuçları oluşturur ve aynı anda birden çok kullanıcıyı idare eder.
Kilit değişim: bunları bağımsız ölçekleyebilmek
Snowflake bu ikisini ayırır, böylece birini değiştirmek diğerini zorunlu kılmaz.
- Veri hacmi büyürse daha fazla depolama eklersiniz (genellikle artımlıdır ve öngörülebilir).
- Rapor trafiği artarsa daha fazla hesaplama eklersiniz (warehouse yeniden boyutlandırma veya yeni warehouse’lar ekleyerek) ve temel veri taşınmaz veya çoğaltılmaz.
Pratikte bu, günlük operasyonları değiştirir: depolama büyüdüğü için hesaplamayı “aşırı satın almak” zorunda kalmazsınız ve iş yüklerini izole ederek (ör. analistler vs. ETL) birbirlerini yavaşlatmalarını önlersiniz.
Bu ne değildir
Bu ayrım güçlü ama sihirli değildir.
- Bu bedava ölçekleme değildir. Daha fazla veya daha büyük warehouse’lar genelde daha yüksek hesaplama maliyeti demektir.
- Bu her durumda otomatik tasarruf değildir. Kötü yazılmış sorgular, gereksiz yenileme takvimleri veya sürekli açık warehouse’lar maliyetleri yine artırır.
- Bu planlamayı göz ardı etmek için bir bahane değildir. Hala warehouse boyutlarını seçmeli, auto-suspend kuralları belirlemeli ve hesaplamayı iş kullanımıyla hizalamalısınız.
Değer, depolama ve hesaplamayı kendi şartlarında ödemek ve her birini ekiplerinizin gerçek ihtiyaçlarına göre eşleştirmekte yatıyor.
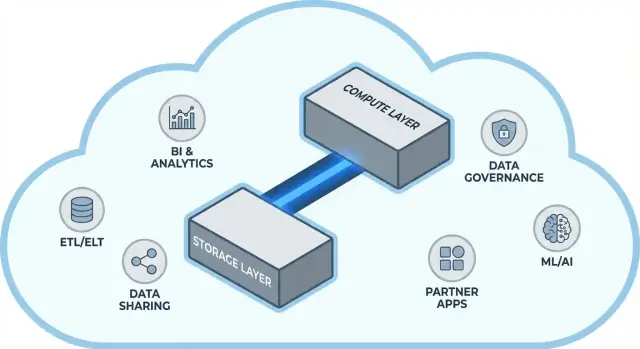
Snowflake mimarisi basitçe
Snowflake, birlikte çalışan ama bağımsız ölçeklenebilen üç katman olarak en kolay anlaşılır.
1) Depolama: bulut nesne depolama
Tablolarınız sonunda bulut sağlayıcınızın nesne depolamasındaki dosyalar olarak yaşar (S3, Azure Blob veya GCS gibi). Snowflake dosya formatlarını, sıkıştırmayı ve organizasyonu sizin için yönetir. Disk eklemezsiniz veya depolama hacmi boyutlandırmazsınız—depolama veri büyüdükçe genişler.
2) Hesaplama: virtual warehouse’lar
Hesaplama virtual warehouse olarak paketlenir: sorguları çalıştıran bağımsız CPU/bellek kümeleri. Aynı veriye karşı aynı anda birden çok warehouse çalıştırabilirsiniz. Bu, ağır iş yüklerinin aynı kaynak havuzu için kavga ettiği eski sistemlerden farkı yaratır.
Ayrı bir servis katmanı sistemin “beynini” yönetir: kimlik doğrulama, sorgu ayrıştırma ve optimizasyon, işlem/metadata yönetimi ve koordinasyon. Bu katman bir sorgunun nasıl verimli çalıştırılacağını hesaplar ve ardından hesaplamaya teslim eder.
Bir sorgunun akışı
SQL gönderdiğinizde, Snowflake’in servis katmanı onu ayrıştırır, yürütme planı oluşturur ve bu planı seçilen virtual warehouse’a verir. Warehouse yalnızca gerekli veri dosyalarını nesne depolamadan okur (ve mümkünse cache’den faydalanır), bunları işler ve sonuçları döndürür—temel veriyi kalıcı olarak taşımadan.
Eşzamanlılık ve izolasyon (jargondan uzak)
Birçok kişi aynı anda sorgu çalıştırıyorsa ya:
- Farklı ekipler/iş yükleri için ayrı warehouse’lar kullanırsınız (iş yükü izolasyonu), ya da
- Talep arttığında Snowflake’in daha fazla compute kümesi ekleyebildiği multi-cluster warehouse’lar etkinleştirirsiniz.
Bu, Snowflake’in performans ve “gürültü yapan komşu” kontrolünün mimari temelidir.
Ölçekleme ve eşzamanlılık: gerçekten ne değişiyor
Snowflake’in büyük pratik farkı, hesaplamayı veriden bağımsız ölçekleyebilmenizdir. “Ambar büyüyor” demek yerine, her iş yükü için kaynakları yukarı/aşağı çevirebilirsiniz—tabloları kopyalamadan, diskleri yeniden bölmeden veya kesinti planlamadan.
Elastiklik: veriyi taşımadan hesaplamayı yeniden boyutlandırma
Snowflake’te virtual warehouse sorguları çalıştıran hesaplama motorudur. Bunu (ör. Small’dan Large’a) saniyeler içinde yeniden boyutlandırabilirsiniz ve veri paylaşılan depolamada kalır. Bu yüzden performans ayarı genelde basit bir soruya dönüşür: “Bu iş yükü şu anda daha fazla güç ister mi?”
Bu aynı zamanda geçici patlamalara izin verir: ay sonu kapanışı için ölçeği yükseltin, sonra zirve geçince tekrar küçültün.
Eşzamanlılık: daha az kuyruklanma
Geleneksel sistemler genelde farklı ekipleri aynı compute havuzunu paylaşmaya zorlar; bu da yoğun saatleri kasada kuyruk beklemeye benzetir.
Snowflake, ekip veya iş yükü başına ayrı warehouse’lar çalıştırmanıza izin verir—örneğin biri analistler, biri dashboard’lar, biri ETL için. Bu warehouse’lar aynı temel veriyi okuduğu için “benim dashboard’ım senin raporunu yavaşlattı” sorununu azaltır ve performansı daha öngörülebilir kılar.
Dikkat etmeniz gereken ödünleşmeler
Elastik hesaplama otomatik başarı getirmez. Yaygın tuzaklar:
- Cold start: askıya alınmış warehouse’ların yeniden başlaması biraz zaman alabilir, bu da seyrek işler için gecikme ekler.
- Doğru boyutlandırma seçimi: aşırı büyük seçmek para israfıdır; çok küçük seçmek sorguları yavaşlatır.
- Koruyucu kurallar gerekli: auto-suspend/auto-resume, resource monitor’lar ve net sahiplik olmalı ki warehouse’lar boş yere çalışmasın veya kontrolsüz çoğalmasın.
Toplamda: ölçekleme ve eşzamanlılık, altyapı projelerinden günlük işletme kararlarına dönüşür.
Maliyet modeli: nerede tasarruf olur (ve nerede olmaz)
Plan your Snowflake pilot
Draft a 2-4 week pilot app plan and implement it step by step in planning mode.
Snowflake faturalaması gerçekte nasıl işler
Snowflake’in “kullandığın kadar öde” modeli temelde paralel koşan iki sayaç gibidir:
- Compute: virtual warehouse’un çalıştığı süre için faturalandırılır (credit). Açık ise sayaç çalışır.
- Storage: depolanan veri miktarı için faturalandırılır (ve Time Travel/Fail-safe gibi ek saklama için ekstra ücretler).
Bu ayrım tasarrufların olabileceği yerdir: çok miktarda veriyi nispeten ucuza saklarken, hesaplamayı yalnızca ihtiyaç duyduğunuzda çalıştırabilirsiniz.
Maliyetlerin nerede arttığı
Çoğu “beklenmeyen” harcama hesaplama davranışlarından gelir, ham depolamadan değil. Yaygın nedenler:
- Aşırı büyük warehouse’lar (iş yükünün ihtiyacından daha büyük boyut seçmek)
- Sürekli çalışan işler (gece veya hafta sonu açık kalan warehouse’lar)
- Verimsiz sorgular (filtrelenmemiş taramalar, gereksiz join’ler, tekrar eden ağır dönüşümler)
- Yüksek eşzamanlılık desenleri (çok sayıda küçük dashboard’ın sürekli yenilenmesi)
Depolama ve hesaplamayı ayırmak sorguları otomatik olarak verimli yapmaz—kötü SQL hâlâ hızla credit yaktırabilir.
Gerçek dünyada işe yarayan pratik kontroller
Bunları yönetmek için bir finans ekibine gerek yok—sadece birkaç kural:
- Auto-suspend / auto-resume ile boşta ödemeyi durdurun
- Resource monitor ile ekip/warehouse başına uyarı veya kota koyun
- Zamanlama (batch işleri belirli pencerelerde çalıştırın; dev/test ortamlarını çalışma saatleri dışında durdurun)
- Doğru boyutlandırma ve önce daha küçük boyutları test etme
Doğru kullanıldığında model disiplin ödüllendirir: kısa süreli, doğru boyutlandırılmış hesaplama ve öngörülebilir depolama büyümesi.
Veri paylaşımı ve iş birliği birinci sınıf özellik olarak
Snowflake paylaşımı platforma sonradan eklenen bir özellik değil, platformun içine tasarlanmış bir yetenektir.
Kopyalamadan paylaşım (çoğu durumda)
Veri çıkarıp göndermek yerine Snowflake, başka bir account’un aynı temel veriyi güvenli bir “share” aracılığıyla sorgulamasına izin verebilir. Pek çok senaryoda veri ikinci bir warehouse’a kopyalanmak zorunda değildir veya indirme için nesne depolamaya itilmeye gerek yoktur. Tüketici paylaşılan database/tabloyu yerelmiş gibi görürken sağlayıcı neyin açığa çıkarıldığını kontrol etmeye devam eder.
Bu “ayrıştırılmış” yaklaşım veri yayılımını azaltır, erişimi hızlandırır ve oluşturmanız gereken pipeline sayısını düşürür.
Yaygın iş birliği desenleri
Ortak ve müşteri paylaşımı: Bir satıcı, müşterilere düzenlenmiş veri setleri (ör. kullanım analitiği veya referans verileri) yayınlayabilir; yalnızca izin verilen şemalar, tablolar veya view’lar paylaşılır.
İç domain paylaşımı: Merkezi ekipler, sertifikalı veri setlerini ürün, finans ve operasyon ekiplerine çoğaltma gereği duymadan sunabilir—bu, “tek doğru sayı” kültürünü desteklerken takımların kendi hesaplamalarını yapmasına izin verir.
Yönetişimli iş birlikleri: Ajans, tedarikçi veya bağlı şirket gibi ortak projeler paylaşılan bir veri seti üzerinden çalışabilir; hassas sütunlar maskeleyebilir ve erişimler log’lanabilir.
Planlamanız gereken sınırlamalar
Paylaşım “ayarla unut” demek değildir. Hâlâ ihtiyacınız var:
- Yönetişim: açık sahiplik, erişim incelemeleri ve PII/ düzenlenen veriler için politikalar
- Sözleşmeler ve beklentiler: kim hesaplama ücretini öder, SLA’lar, saklama ve tanımlar değiştiğinde ne olacağı
- Bulunabilirlik: katalog ve iyi isimlendirme olmadan insanlar doğru paylaşılan veriyi bulmaz veya güvenmez. Paylaşımları dokümantasyon ve veri kataloğunuzla hizalayın.
Hızlı bir ambar değerli ama hız tek başına genelde bir projenin zamanında teslim edilip edilmeyeceğini belirlemez. Farkı yaratan genelde platformun etrafındaki ekosistemdir: hazır bağlantılar, araçlar ve uzmanlık, özel iş geliştirmeyi azaltır.
Pratikte bir ekosistem şunları içerir:
- Kaynak ve hedef bağlantıları (SaaS uygulamaları, veritabanları, streaming araçları)
- Ortak araçlar: ingest, dönüşüm, BI, veri kalitesi ve izlenebilirlik için
- Veri yakınında çalışan uygulamalar ve yerel entegrasyonlar
- Şablonlar ve referans mimariler (yaygın modeller, desenler, dağıtım rehberleri)
- Topluluk bilgisi: örnekler, forumlar, meetup’lar ve işe alım erişilebilirliği
Ekosistem neden teslim süresinde kıyaslamaları yener
Kıyaslamalar kontrollü koşullarda dar bir performans kesitini ölçer. Gerçek projeler çoğunlukla şu işlere zaman harcar:
- Veriyi güvenilir ve artımlı olarak almak
- Veri modelleme, test ve dokümantasyon
- Operasyonel görevler (izleme, uyarı, maliyet kontrol)
- Güvenlik incelemeleri, erişim kontrolleri ve denetimler
Platformunuz bu adımlar için olgun entegrasyonlara sahipse, köprü kodu yazmaktan kaçınırsınız. Bu genelde uygulama sürelerini kısaltır, güvenilirliği artırır ve ekip/tedarikçi değişse bile her şeyi yeniden yazma ihtiyacını azaltır.
Basit bir değerlendirme merceği: kapsama, kalite, sürdürülebilirlik
Ekosistemi değerlendirirken bakın:
- Kapsama: kilit kaynaklarınızı, BI araçlarınızı, orkestrasyon ve yönetişim ihtiyaçlarınızı destekliyor mu?
- Kalite: konektörler aktif olarak mı güncelleniyor, iyi dokümante edilmiş ve ölçeğinizde kanıtlanmış mı?
- Sürdürülebilirlik: sürekli bakım, kırılma değişiklikleri, hata ayıklama ve destek ne kadar emek gerektiriyor?
Performans size yetenek verir; ekosistem genellikle bu yeteneği iş sonuçlarına dönüştürme hızını belirler.
Entegrasyon ekosistemi: veriyi içeri, dışarı ve kullanılabilir hale getirmek
Own your source code
Create a working web app and export the source code when you are ready to own it.
Snowflake hızlı sorgular çalıştırabilir, ama değer veri yığınınızın yığıldığı yerden günlük kullanılan araçlara güvenilir şekilde akınca ortaya çıkar. “Son mil” genelde platformun zahmetsiz veya sürekli kırılgan hissettirmesini belirler.
Planlamanız gereken ana entegrasyon kategorileri
Çoğu ekip şu karışımı ihtiyaç duyar:
- ELT/ETL: veritabanları, SaaS uygulamaları, dosyalar ve nesne depolamadan alma
- BI ve analitik: panolar, self-serve keşif ve semantik katmanlar
- Reverse ETL: işlenmiş veriyi CRM, pazarlama ve destek sistemlerine geri itme
- Orkestrasyon: zamanlama, bağımlılıklar, backfill’ler ve ortam promosyonu
- Streaming: near‑real‑time olaylar ve change data capture için
- ML araçları: feature pipeline’ları, eğitim iş akışları ve model izleme için
Konektör seçmeden önce sorulacak sorular
Her “Snowflake-uyumlu” araç aynı davranmaz. Değerlendirme sırasında pratik detaylara odaklanın:
- Konektör sertifikalı/desteklenen mi (ve kim tarafından)? Eskalasyon yolu nedir?
- Artımlı yüklemeleri düzgün idare edebiliyor mu (CDC, timestamp, high‑water mark)?
- Şema sürüklenmesi—yeni sütunlar, tip değişiklikleri, silinmiş alanlarla nasıl başa çıkıyor?
- Retry, deduplication ve exactly-once vs at-least-once garantileri nasıl?
Operasyonları ihmal etmeyin
Entegrasyonlar ayrıca day‑2 hazırlığı gerektirir: izleme ve uyarı, lineage/katalog bağlantıları ve olay yanıt iş akışları (ticketing, on‑call, runbook’lar). Güçlü bir ekosistem daha fazla logo demek değildir—2’de sabaha pipelines arızalandığında daha az sürpriz demektir.
Yönetişim, güvenlik ve ölçekte güven
Ekipler büyüdükçe analitiğin en zor kısmı genellikle hız değil—doğru kişilerin doğru verilere doğru amaç için erişebilmesini sağlamak ve kontrollerin çalıştığına dair kanıt sunmaktır. Snowflake’in yönetişim özellikleri bu gerçeğe göre tasarlandı: çok sayıda kullanıcı, çok sayıda veri ürünü ve sık paylaşım.
İşe yarayan yönetişim temelleri
Açık roller ve en az ayrıcalık (least‑privilege) yaklaşımıyla başlayın. Bireylere doğrudan erişim vermek yerine ANALYST_FINANCE veya ETL_MARKETING gibi roller tanımlayın, sonra bu rollere belirli database, schema, tablo ve gerektiğinde view erişimi verin.
Hassas alanlar (PII, finansal tanımlayıcılar) için masking policy kullanarak insanlar veri setlerini ham değerleri görmeden sorgulayabilir; sadece rolleri izin veriyorsa ham değerlere erişir. Bunu auditing ile eşleştirin: kim neyi ne zaman sorguladı takip edin, böylece güvenlik ve uyum ekipleri sorulara tahmin yürütmeden yanıt verebilir.
Yönetişim paylaşımı ve self‑service’i nasıl değiştirir
İyi yönetişim paylaşımı daha güvenli ve ölçeklenebilir kılar. Paylaşım modeli roller, politikalar ve denetlenmiş erişime dayanıyorsa, self‑service’i (daha fazla kullanıcının veri keşfetmesi) güvenle açabilirsiniz. Bu aynı zamanda uyum çabalarını da kolaylaştırır: politikalar tekrarlanabilir kontroller haline gelir, tek seferlik istisnalar değil.
Gelecekte sorun çıkarmayan pratik ipuçları
- İsimlendirme konvansiyonları: database/schema isimlerini amaç ve hassasiyeti gösterir şekilde standartlaştırın (ör.
PROD_FINANCE, DEV_MARKETING, SHARED_PARTNER_X). Tutarlılık incelemeleri hızlandırır ve hataları azaltır.
- Ortam ayrımı: DEV/TEST/PROD mantıksal olarak ayrılmış olmalı ve PROD’da daha sıkı kontroller bulunmalı. Üretim verisini istisna olarak ele alın.
- Erişim incelemeleri: bir rutin belirleyin (yüksek riskli veriler için aylık, diğerleri için çeyreklik). Rol üyeliklerini, eski kullanıcıları ve ayrıcalıklı rolleri gözden geçirin.
Ölçekte güven, tek bir “mükemmel” kontrolden ziyade erişimi kasıtlı ve açıklanabilir tutan küçük, güvenilir alışkanlıklar sistemidir.
İş yükleri ve iyi uygulama desenleri
Track warehouse spend
Build a lightweight cost and usage hub that helps teams see compute spend drivers.
Snowflake, birçok kişinin ve aracın aynı veriyi farklı amaçlarla sorgulaması gereken durumlarda iyi performans gösterir. Hesaplamanın bağımsız warehouse’lara paketlenmiş olması sayesinde her iş yükünü uygun şekil ve zamanlamaya eşleyebilirsiniz.
Yaygın iş yükü eşleştirmesi
Analitik & dashboard’lar: BI araçlarını tahmin edilebilir, sabit sorgu hacmi için ayrılmış bir warehouse’a koyun. Bu, dashboard yenilemelerinin ad hoc keşiflerle yavaşlatılmasını önler.
Ad hoc analiz: Analistler için ayrı bir warehouse verin (genellikle daha küçük) ve auto‑suspend etkin. Hızlı yineleme alırken boşta ödeme yapmazsınız.
Veri bilimi & deney: Daha ağır taramalar ve ara sıra patlamalar için boyutlandırılmış bir warehouse kullanın. Deneyler patlasa bile bu warehouse’ı geçici olarak büyüterek BI kullanıcılarını etkilemezsiniz.
Veri uygulamaları & gömülü analitik: Uygulama trafiğini üretim servisi gibi ele alın—ayrı warehouse, muhafazakar timeout’lar ve sürpriz harcamaları önlemek için resource monitor’lar.
Eğer hafif iç uygulamalar (ör. Snowflake sorgulayıp KPI’ları gösteren bir ops portalı) oluşturuyorsanız, hızlı bir yol React + API iskeleti üretip paydaşlarla iterasyona girmektir. Koder.ai gibi platformlar sohbetten Snowflake destekli bu tür uygulamaları hızla prototipleyip kaynak kodu dışa aktarmanıza yardımcı olabilir.
İşe yarayan iyi uygulama desenleri
Basit bir kural: audience ve amaç bazında warehouse’ları ayırın (BI, ELT, ad hoc, ML, uygulama). Bunu iyi sorgu alışkanlıklarıyla eşleştirin—geniş SELECT * kullanımından kaçının, erken filtre uygulayın ve verimsiz join’lere dikkat edin. Modelleme tarafında, insanların nasıl sorguladığına uyan yapıları önceliklendirin (genellikle temiz bir semantik katman veya iyi tanımlanmış mart’lar), fiziksel yerleşimlerde aşırı optimizasyondan kaçının.
Ne zaman alternatif veya tamamlayıcıları düşünmeli
Snowflake her şeyi değiştirmez. Yüksek verimli, düşük gecikmeli işlem (typical OLTP) iş yükleri için genelde uzmanlaşmış bir veritabanı daha uygundur; Snowflake ise analitik, raporlama, paylaşım ve türev veri ürünleri için kullanılır. Hibrit kurulumlar yaygındır ve çoğu zaman en pratik çözümdür.
Geçiş dikkate alınması gerekenler: taşımadan önce planlanacaklar
Snowflake’e geçiş genelde “lift and shift” değildir. Depolama/hesaplama ayrımı iş yüklerini nasıl boyutlandıracağınızı, iyileştireceğinizi ve ödeyeceğinizi değiştirir—bu nedenle önceden planlama sürprizleri önler.
Pratik bir geçiş sırası
Bir envanter ile başlayın: hangi veri kaynakları ambarı besliyor, hangi pipeline’lar dönüştürüyor, hangi dashboard’lar buna bağlı ve her parçanın sahibi kim? Sonra önceliklendirin (ör. kritik finans raporlaması önce, deneysel sandbox’lar sonra).
Sonra SQL ve ETL mantığını dönüştürün. Standart SQL’lerin çoğu taşınır, ama fonksiyonlar, tarih işlemleri, prosedürel kod ve temp‑table desenleri gibi detaylar genellikle yeniden yazılmayı gerektirir. Sonuçları erken doğrulayın: paralel çıktılar çalıştırın, satır sayıları ve agregatları karşılaştırın ve kenar durumları (null’lar, zaman dilimleri, deduplama mantığı) doğrulayın. Kesme (cutover) planlayın: bir dondurma penceresi, rollback yolu ve her veri seti/rapor için net bir "yapıldı tanımı".
Dikkat edilmesi gereken tipik riskler
Gizli bağımlılıklar en yaygın olanıdır: bir spreadsheet çıkarımı, sert kodlanmış bağlantı dizesi, kimsenin hatırlamadığı bir downstream job. Performans sürprizleri eski tuning varsayımları geçerli olmadığında ortaya çıkabilir (ör. çok küçük warehouse’ların aşırı kullanımı veya çok sayıda küçük sorgunun eşzamanlılığı düşünmeden çalıştırılması). Maliyet sıçramaları genelde warehouse’ların açık bırakılmasından, kontrolsüz tekrar denemelerden veya çoğaltılmış dev/test iş yüklerinden gelir. İzin boşlukları, kaba rollerden daha ince yönetişime geçerken görünür hale gelir—testler “least privilege” kullanıcı koşularını içermeli.
Değişim yönetimi (atlamayın)
Bir sahiplik modeli belirleyin (veri, pipeline ve maliyet kimin sorumluluğunda), analistler ve mühendisler için role‑bazlı eğitim verin ve cutover sonrası ilk haftalar için destek planı tanımlayın (on‑call rotası, incident runbook ve sorun bildirme yeri).
Modern bir veri platformu seçmek sadece zirve benchmark hızından ibaret değildir. Platformun gerçek iş yüklerinize, ekibinizin çalışma şekline ve zaten güvendiğiniz araçlara uyup uymadığı önemlidir.
Pratik değerlendirme kontrol listesi
Bu soruları kısa listeniz ve tedarikçi konuşmalarınız için kullanın:
- İş yükleri: Genelde zamanlanan dashboard’lar mı, ad‑hoc analiz mi, veri bilimi mi, ELT/ETL mi yoksa müşteri‑yönlü uygulamalar mı çalıştırıyorsunuz? Öngörülebilir batch pencerelerine mi yoksa elastik patlama kapasitesine mi ihtiyacınız var?
- Eşzamanlılık ihtiyaçları: Aynı anda kaç kişi/uygulama sorgu çalıştıracak ve kullanım saatleri ne kadar “patlamalı”?
- Veri paylaşımı gereksinimleri: Ortaklarla, iş birimleriyle veya müşterilerle canlı veri paylaşmanız gerekiyor mu? Üçüncü taraf veri setleri tüketecek misiniz?
- Araç uyumu: BI araçlarınız, orkestrasyon, katalog ve CI/CD iş akışlarınız nasıl entegre olur? Taşındığınızda ne kırılır?
- Yönetişim ve güvenlik: İnce taneli erişim kontrolü, audit trail, masking, saklama politikaları ve görev ayrımı gerekiyor mu?
- Maliyet kısıtları: Hangi maliyetler en çok önemli—sabit durum giderleri, zirve saat giderleri yoksa hesaplamayı kapatma yeteneği mi? “Sürekli açık” israfını nasıl önlersiniz?
Kısa bir pilot planı (2–4 hafta)
2–3 temsilî veri kümesi seçin (oyuncak örnekler değil): büyük bir fact tablosu, karışık yarı‑yapılı kaynak ve iş açısından kritik bir domain.
Sonra gerçek kullanıcı sorguları çalıştırın: sabah pikindeki dashboard’lar, analist keşifleri, zamanlanan yüklemeler ve birkaç en kötü durum join. İzleyecekleriniz: sorgu süresi, eşzamanlılık davranışı, alma süresi, operasyonel çaba ve iş yükü başına maliyet.
Değerlendirmeniz “insanların gerçekten kullandığı bir şeyi ne kadar hızlı hayata geçirebiliriz” ise, pilota küçük bir teslimat ekleyin—ör. iç metrik uygulaması veya yönetilen veri‑istek iş akışı. Bu ince katman, entegrasyon ve güvenlik gerçeklerini benchmark’lardan daha hızlı açığa çıkarır; Koder.ai gibi araçlar sohbetle uygulama yapıp kodu dışa aktarmayı hızlandırabilir.
Önerilen sonraki adımlar
Harcamayı tahmin etme ve seçenekleri karşılaştırma konusunda yardım isterseniz, /pricing ile başlayın.
Geçiş ve yönetişim rehberliği için ilgili makalelere /blog üzerinden göz atın.