SQL ve NoSQL Veritabanları: Temel Farklar ve Kullanım Durumları
SQL ve NoSQL veritabanları arasındaki gerçek farkları öğrenin: veri modelleri, ölçeklenebilirlik, tutarlılık ve hangi kullanım durumlarında hangisinin daha uygun olduğunu keşfedin.
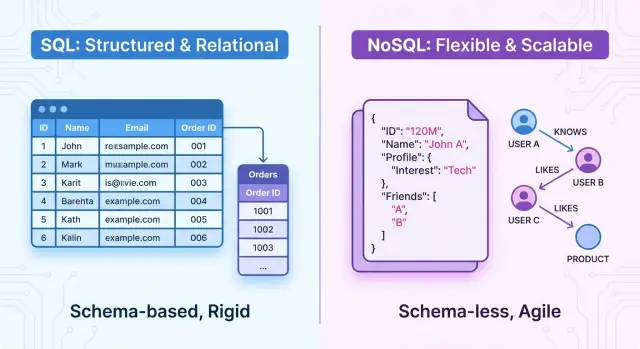
Genel Bakış: SQL ve NoSQL'e hızlı bakış
SQL ile NoSQL arasında seçim yapmak, uygulamanızı tasarlama, inşa etme ve ölçeklendirme biçiminizi belirler. Veri modeli, veri yapıları ve sorgu kalıplarından performans, güvenilirlik ve ürünün hızla evrilme yeteneğine kadar her şeyi etkiler.
Genel olarak, SQL veritabanları ilişkisel sistemlerdir. Veriler sabit şemalı tablolarda, satırlar ve sütunlar halinde düzenlenir. Varlıklar arasındaki ilişkiler açıkça tanımlanır (foreign key ile) ve veriyi sorgulamak için güçlü, deklaratif bir dil olan SQL kullanılır. Bu sistemler ACID işlemleri, güçlü tutarlılık ve iyi tanımlanmış yapı üzerinde durur.
NoSQL veritabanları ise ilişkisiz sistemlerdir. Tek bir katı tablo modelinin yerine, farklı ihtiyaçlara yönelik çeşitli veri modelleri sunarlar, örneğin:
- Anahtar‑değer mağazaları
- Doküman veritabanları
- Geniş‑sütun (wide‑column) mağazalar
- Grafik veritabanları
Yani “NoSQL” tek bir teknoloji değil, esneklik, performans ve veri modellemesi açısından farklı ödünler veren birçok yaklaşımı kapsayan bir şemadır. Birçok NoSQL sistemi, yüksek ölçeklenebilirlik, kullanılabilirlik veya düşük gecikme uğruna katı tutarlılık garantilerini gevşetir.
Bu makale, SQL ve NoSQL arasındaki farklara—veri modelleri, sorgu dilleri, performans, ölçeklenebilirlik ve tutarlılık (ACID vs nihai tutarlılık)—odaklanır. Amacı, belirli projeler için SQL mi NoSQL mi seçilmeli sorusuna yardımcı olmak ve hangi veritabanı türünün ne zaman daha uygun olduğunu göstermektir.
Tek bir seçim yapmak zorunda değilsiniz. Birçok modern mimari, SQL ve NoSQL veritabanlarının poliglot persistans şeklinde aynı sistemde birlikte kullanılmasını tercih eder; her biri güçlü olduğu işleri üstlenir.
SQL (ilişkisel) veritabanı nedir?
Bir SQL (ilişkisel) veritabanı, verileri yapılandırılmış, tabular bir biçimde saklar ve bu veriyi tanımlamak, sorgulamak ve değiştirmek için Structured Query Language (SQL) kullanır. Matematiksel ilişki (relation) kavramı etrafında kuruludur; bunu iyi organize edilmiş tablolar olarak düşünebilirsiniz.
Temel yapı: tablolar, satırlar, sütunlar ve şemalar
Veriler tablolar halinde düzenlenir. Her tablo, customers, orders veya products gibi bir varlık türünü temsil eder.
- Bir satır (kayıt) o varlığın tek bir örneğidir, örneğin bir müşteri.
- Bir sütun (alan) ise
emailveyaorder_dategibi bir özelliktir.
Her tablo sabit bir şema izler: hangi sütunların olduğu, veri tipleri (INTEGER, VARCHAR, DATE gibi) ve kısıtlar (NOT NULL, UNIQUE) önceden tanımlanır.
Şema veritabanı tarafından zorlanır; bu da veriyi tutarlı ve öngörülebilir kılar.
Anahtarlar ve ilişkiler
İlişkisel veritabanları, varlıklar arasındaki bağlantıları modellemede çok iyidir.
- Bir primary key her satırı benzersiz şekilde tanımlar (ör.
customer_id). - Bir foreign key başka bir tablodaki primary key'e referans veren bir sütundur; ilişkili satırları birbirine bağlar.
Bu anahtarlar sayesinde şunları tanımlayabilirsiniz:
- Bir‑çok (one‑to‑many) (bir müşteri, birçok sipariş)
- Çok‑çok (many‑to‑many) (birden fazla siparişte bulunan ürünler, bir siparişte birden fazla ürün)
İşlemler ve ACID özellikleri
İlişkisel veritabanları işlemleri (transactions) destekler—birbirleriyle bağlantılı bir dizi işlemin tek bir birim gibi davranmasını sağlar. İşlemler ACID özellikleri ile tanımlanır:
- Atomiklik (Atomicity): tüm işlemler başarılı olur ya da hiçbiri olmaz.
- Tutarlılık (Consistency): işlemler veritabanını bir geçerli durumdan diğerine taşır.
- İzolasyon (Isolation): eşzamanlı işlemler birbirini etkilemez.
- Dayanıklılık (Durability): commit edildikten sonra veriler güvenle saklanır.
Bu garantiler finansal sistemler, envanter yönetimi ve doğruluğun kritik olduğu her uygulama için çok önemlidir.
Yaygın SQL veritabanları
Popüler ilişkisel veritabanı sistemleri şunlardır:
- MySQL ve MariaDB
- PostgreSQL
- Microsoft SQL Server
- Oracle Database
Bunların hepsi SQL'i uygular ve yönetim, performans ayarı ve güvenlik için kendi uzantılarını ve araçlarını ekler.
NoSQL (ilişkisiz) veritabanı nedir?
NoSQL veritabanları, geleneksel tablo–satır–sütun modelini kullanmayan ilişkisiz veri depolarıdır. Bunun yerine esnek veri modelleri, yatay ölçeklenebilirlik ve yüksek kullanılabilirlik üzerine odaklanır; genellikle katı işlem garantilerinden ödün verirler.
Esnek veri modelleri
Birçok NoSQL veritabanı şemasız veya şema‑esnek olarak tanımlanır. Sert bir şema tanımlamak yerine, aynı koleksiyonda farklı alanlara veya yapılara sahip kayıtlar saklayabilirsiniz.
Bu özellikle şunlar için faydalıdır:
- Hızla değişen uygulama gereksinimleri
- Yarı‑yapılı verinin (loglar, olaylar, kullanıcı profilleri) işlenmesi
- JSON gibi iç içe geçmiş verilerin saklanması
Alanlar kayıt başına eklenip çıkarılabildiği için geliştiriciler her yapısal değişiklikte migration yapmak zorunda kalmazlar.
Başlıca NoSQL türleri
NoSQL, birkaç farklı modeli kapsayan geniş bir terimdir:
- Doküman veritabanları: Veriyi JSON benzeri dokümanlar halinde saklar. Örnek: MongoDB, Couchbase.
- Anahtar–değer mağazaları: Her anahtar bir değere karşılık gelir; caching ve oturum verisi için iyidir. Örnek: Redis, Amazon DynamoDB (anahtar‑değer modu).
- Sütun‑aile (wide‑column) mağazalar: Yüksek yazma verimi ve geniş tablolar için sütun aileleriyle organize eder. Örnek: Apache Cassandra, HBase.
- Graf veritabanları: Düğümler ve ilişkiler üzerinde odaklanır; yüksek bağlı veri için ideal. Örnek: Neo4j, Amazon Neptune.
Tutarlılık modelleri
Birçok NoSQL sistemi kullanılabilirlik ve partition toleransını önceliklendirir; bunun sonucu olarak nihai tutarlılık (eventual consistency) sunar. Bazıları ayarlanabilir tutarlılık seviyeleri veya sınırlı işlem özellikleri (doküman başına, partition başına) sunar; böylece belirli operasyonlar için daha güçlü garantiler seçilebilir.
Veri modelleri: yapı, şemalar ve ilişkiler
Veri modelleme, SQL ve NoSQL arasındaki en belirgin farklılıklardan biridir. Bu, özellikleri nasıl tasarlayacağınızı, veriyi nasıl sorgulayacağınızı ve uygulamanızı nasıl evriltileceğini belirler.
Yapı ve şemalar
SQL veritabanları yapılandırılmış, önceden tanımlanmış şemalar kullanır. Tabloları ve sütunları önceden tasarlarsınız, sıkı tipler ve kısıtlar ile:
CREATE TABLE users (
id INT PRIMARY KEY,
name VARCHAR(100) NOT NULL
);
CREATE TABLE orders (
id INT PRIMARY KEY,
user_id INT NOT NULL,
total DECIMAL(10, 2) NOT NULL,
FOREIGN KEY (user_id) REFERENCES users(id)
);
Her satır şemaya uymak zorundadır. Sonradan değişiklikler genellikle migration (ALTER TABLE, backfill vb.) gerektirir.
NoSQL veritabanları genellikle esnek şemaları destekler. Bir doküman mağazası her dokümanın farklı alanlara sahip olmasına izin verebilir:
{
"_id": 1,
"name": "Alice",
"orders": [
{ "id": 101, "total": 49.99 },
{ "id": 102, "total": 15.50 }
]
}
Alanlar doküman bazında eklenip çıkarılabilir; bazı NoSQL sistemleri opsiyonel veya zorunlu şemalar sunsa da genelde daha gevşektir.
Normalizasyon vs denormalizasyon
İlişkisel modeller normalizasyonu teşvik eder: veriyi çoğaltmamak ve bütünlüğü korumak için tablolara bölme. Bu yazma işlemlerini tutarlı ve depolamayı küçük tutar, ancak karmaşık okumalar birçok join gerektirebilir.
NoSQL modelleri çoğunlukla denormalizasyonu tercih eder: ilgili veriyi okumalardaki performansı iyileştirmek için aynı yerde gömmek. Bu okuma hızını artırır ama yazma işlemleri daha pahalı veya karmaşık olabilir, çünkü aynı bilgi birden fazla yerde tutulur.
İlişkileri modelleme
SQL'de ilişkiler açıktır ve veritabanı tarafından uygulanır:
- Bir‑çok: foreign key (users → orders)
- Çok‑çok: join tabloları (users_roles)
NoSQL'de ilişkiler şu yollarla modellenir:
- Gömme (embedding): sıkı bağlı veriyi aynı dokümanda tutmak (kullanıcı dokümanı içinde orders dizisi).
- Referanslama: order dokümanında user_id gibi referanslar kullanmak; büyük koleksiyonlar veya bağımsız erişim için uygundur.
Seçim erişim desenlerinizle belirlenir:
- Eğer her zaman bir kullanıcıyı ve son 10 siparişini birlikte getiriyorsanız, gömme ideal olabilir.
- Siparişler çok büyük, sık güncelleniyor veya bağımsız erişiliyorsa, referanslar ve ayrı sorgular daha iyidir.
Gereksinimlerin evrilmesine etkisi
SQL ile şema değişiklikleri daha planlıdır ama veri kümesi genelinde güçlü garantiler sağlar. Refaktörler açıktır: migrationlar, backfill, kısıtlama güncellemeleri.
NoSQL ile gereksinimlerin evrilmesi kısa vadede genellikle daha kolaydır. Yeni alanları hemen saklayabilir ve eski dokümanları kademeli güncelleyebilirsiniz. Bunun bedeli, uygulama kodunun farklı doküman biçimlerini ve kenar durumları ele almasıdır.
Normalizasyonlu SQL modeller ile denormalize NoSQL modeller arasında seçim "daha iyi" ya da "kötü" meselesi değil; veri yapınızı sorgu desenleri, yazma hacmi ve modelin ne sıklıkla değiştiği ile uyumlu hale getirmektir.
Sorgu dilleri ve erişim desenleri
SQL: deklaratif ve standartlaşmış
SQL veritabanları deklaratif bir dille sorgulanır: ne istediğinizi söylersiniz, nasıl alınacağını değil. SELECT, WHERE, JOIN, GROUP BY, ORDER BY gibi yapı taşlarıyla tek bir ifadede çok tabloya dair karmaşık sorgular yazabilirsiniz.
SQL standardı (ANSI/ISO) sayesinde çoğu ilişkisel sistem ortak bir temel sözdizimine sahiptir. Sağlayıcılar kendi uzantılarını ekler ama yetenekler ve sorgular genelde taşınabilir. Bu standardizasyon, ORM’ler, raporlama araçları, BI panelleri, migration çerçeveleri ve sorgu optimizatörleri gibi zengin bir ekosistem getirir.
NoSQL: API'ler ve desenler
NoSQL sistemleri sorguları daha çeşitli şekillerde sunar:
- Doküman mağazaları (MongoDB, Couchbase) JSON‑benzeri sorgu nesneleri veya kendi sorgu dillerini kullanır.
- Anahtar‑değer mağazaları (Redis, DynamoDB tarzı API) genelde birincil anahtar aramaları ve sınırlı ikinci dereceden indeks sorgularına odaklanır.
- Geniş‑sütun mağazalar (Cassandra, HBase) belirlenmiş birincil anahtar ve clustering‑key desenlerini optimize eder.
- Arama motorları (Elasticsearch, Solr) tam metin ve alaka tabanlı sorgular için DSL'ler sunar.
Bazı NoSQL veritabanları analitik için aggregation pipeline veya MapReduce benzeri mekanizmalar sağlar, ancak koleksiyonlar/aralarında join'ler sınırlıdır. Bunun yerine ilgili veri genelde aynı dokümanda gömülü veya kayıtlar arasında denormalize edilir.
Erişim desenleri ve üretkenlik
İlişkisel sorgular genellikle JOIN‑ağırlıklı desenlere dayanır: veriyi normalize edip okuma zamanında join'lerle birleştirirsiniz. Bu ad‑hoc raporlama ve değişen sorular için güçlüdür ama karmaşık join'ler optimize etmeyi ve anlamayı zorlaştırabilir.
NoSQL erişim desenleri genellikle doküman‑ veya anahtar‑merkezlidir: veriyi uygulamanın en sık kullandığı sorgular etrafında tasarlarsınız. Okumalar hızlı ve basittir—çoğunlukla tek anahtar sorgusu—ancak erişim deseni değişirse veriyi yeniden şekillendirmeniz gerekebilir.
Öğrenme ve üretkenlik açısından:
- SQL’in deklaratif modeli ve bol kaynak sayesinde öğrenilmesi ve sürdürülmesi kolaydır.
- NoSQL sorguları basit, iyi bilinen desenler için kolay olabilir; ancak her sistemin farklı sözdizimi ve sınırlamaları vardır, bu yüzden beceriler daha az taşınabilir olabilir.
İlişkileri yoğun sorgulama ve ad‑hoc analiz gereken takımlar genelde SQL’i tercih eder. Çok yüksek ölçekte, stabil ve öngörülebilir erişim desenleri olan takımlar NoSQL’i daha uygun bulabilir.
Tutarlılık, işlemler ve CAP takası
SQL sistemlerinde ACID: sıkı garantiler
Çoğu SQL veritabanı ACID işlemleri etrafında tasarlanmıştır:
- Atomiklik: bir işlem ya tamamen başarılı olur ya da tamamen başarısız.
- Tutarlılık: commit edilen her işlem veriyi geçerli bir duruma taşır.
- İzolasyon: eşzamanlı işlemler görünür şekilde birbirini etkilemez (READ COMMITTED, REPEATABLE READ, SERIALIZABLE gibi izolasyon seviyeleri yoluyla).
- Dayanıklılık: commit edilen veri çökmelerden sonra korunur (write‑ahead log, replikasyon vb.).
Bu, doğruluğun ham yazma veriminden daha önemli olduğu durumlar için SQL’i uygun kılar.
NoSQL'te BASE ve nihai tutarlılık
Birçok NoSQL veritabanı BASE ilkelerine eğilimlidir:
- Basically Available: sistem cevap vermeye çalışır.
- Soft state: replikalar arasında kısa süreli tutarsızlık olabilir.
- Eventual consistency: eğer yeni güncelleme olmazsa, tüm replikalar zamanla uyum sağlar.
Yazmalar çok hızlı ve dağıtık olabilir; ancak okuma kısa süreli eski veriyi görme riski taşır.
CAP teoremi uygulamada
CAP der ki, ağ bölünmesi (partition) durumunda bir dağıtık sistem tutarlılık (C) ile kullanılabilirlik (A) arasında seçim yapmak zorundadır.
Genel eğilimler:
- Birçok SQL dağıtımı güçlü tutarlılığı tercih eder: ödemeler, stok, hesap bakiyeleri, rezervasyonlar gibi senaryolarda önemlidir.
- Birçok NoSQL kurulumunda kullanılabilirlik ve nihai tutarlılık ön plandadır: analiz, sosyal akışlar, ürün katalogları, loglama gibi küçük ve geçici tutarsızlıkların kabul edildiği durumlar için uygundur.
Modern sistemler genelde modlar karışımı kullanır (örn. işlem başına ayarlanabilir tutarlılık) böylece uygulamanın farklı parçaları ihtiyaç duyduğu garantiyi seçebilir.
Ölçeklenebilirlik ve performans farkları
SQL veritabanları genelde nasıl ölçeklenir
Geleneksel SQL veritabanları güçlü tek bir düğüm üzerine tasarlanmıştır.
Genelde dikey ölçekleme ile başlanır: daha fazla CPU, RAM ve hızlı disk eklenir. Birçok motor ayrıca okuma replikaları sunar: yazmalar tek bir primary node'a giderken okumalar çoğaltılmış düğümlerden alınır. Bu model aşağıdakiler için uygundur:
- Orta düzey yazma hacmi
- Ağır analitik veya raporlama sorguları
- Güçlü tutarlılığın kritik olduğu iş yükleri
Ancak dikey ölçek donanım ve maliyet sınırlarına ulaşır; read replica'lar okuma için replikasyon gecikmesi getirebilir.
NoSQL ve yatay ölçekleme
NoSQL sistemleri genellikle yatay ölçeklenme için tasarlanmıştır: veriyi sharding veya partition ile birçok düğüme yayarlar. Her shard verinin bir alt kümesini tutar, böylece hem okuma hem yazma dağıtılabilir ve throughput artar.
Bu yaklaşım şunlar için uygundur:
- Çok yüksek yazma hacmi
- Tek makinenin depolama sınırlarını aşan büyük veri setleri
- Kullanıcılara yakın veri tutarak global uygulamalar
Trade‑off: shard anahtarının seçimi, yeniden dengeleme ve çapraz‑shard sorgularla başa çıkma gibi operasyonel karmaşıklık artar.
Performans desenleri ve indeksleme
Karmaşık join'ler ve birleşik raporlamalar gerektiren okuma‑ağırlıklı iş yüklerinde, iyi tasarlanmış indekslerle bir SQL veritabanı çok hızlı olabilir; optimizer istatistikler ve sorgu planları kullanır.
Birçok NoSQL sistemi basit, anahtar‑tabanlı erişim desenlerini tercih eder. Öngörülebilir sorgular etrafında modellenmiş veride düşük gecikmeli aramalar ve yüksek throughput sağlarlar.
NoSQL kümelerinde gecikme çok düşük olabilir; ancak çapraz‑partition sorgular, ikincil indeksler ve çok dokümanlı işlemler daha yavaş veya sınırlı olabilir. Operasyonel olarak, NoSQL ölçeklendirmesi genelde daha fazla küme yönetimi gerektirirken, SQL ölçeklendirmesi daha fazla donanım ve dikkatli indeksleme gerektirebilir.
SQL veritabanının genelde daha iyi olduğu durumlar
İşlem‑yoğun, iş açısından kritik iş yükleri
İlişkisel veritabanları, güvenilir yüksek hacimli OLTP (online transaction processing) için mükemmeldir:
- Finansal sistemler (ödeme, muhasebe, ticaret)
- Sipariş yönetimi ve envanter
- ERP, CRM ve faturalama platformları
Bu sistemler ACID işlemlere, güçlü tutarlılığa ve net rollback davranışına ihtiyaç duyar. Bir transferin asla çift ücretlendirmemesi gerekiyorsa, SQL genelde daha güvenlidir.
Yapısı belli ve karmaşık ilişkiler
Veri modeliniz iyi anlaşılmış ve stabildiyse, ilişkisel veritabanı doğal bir uyum sağlar. Örnekler:
- Müşteri, sipariş, fatura, ürün ve sevkiyat verileri
- Hastane kayıtları: hastalar, ziyaretler, reçeteler, laboratuvar sonuçları
SQL’in normalizasyonu, foreign key’leri ve join yetenekleri veri bütünlüğünü korumayı ve karmaşık ilişkileri veri çoğaltmadan sorgulamayı kolaylaştırır.
İyi tanımlanmış şemalar üzerinde analitik
Net yapılı veriler (star/snowflake şemaları, veri martları) için SQL ve SQL uyumlu veri ambarları genellikle tercih edilir. Analitik ekipleri SQL bilir ve mevcut araçlar doğrudan ilişkisel sistemlere bağlanır.
Olgunluk, yetkinlik ve uyumluluk gereksinimleri
İlişkisel ve ilişkisiz tartışmaları sıklıkla operasyonel olgunluk gölgede bırakır. SQL veritabanları sunar:
- Uzun süreli güvenilirlik ve olgun araçlar
- SQL konusunda geniş bir mühendis, DBA ve analist havuzu
- Denetim, erişim kontrolü, şifreleme ve yedekleme gibi düzenleyici ihtiyaçları karşılayan özellikler
Denetimler, sertifikasyonlar veya yasal yükümlülükler söz konusuysa SQL genelde daha doğrudan ve savunulabilir bir seçenektir.
NoSQL veritabanının genelde daha iyi olduğu durumlar
NoSQL veritabanları ölçek, esneklik ve her zaman erişilebilirlik ön planda olduğunda, karmaşık joinler ve katı işlem garantilerinden ödün verilebileceği durumlarda daha uygundur.
Yüksek trafikli ve büyük ölçekli sistemler
Büyük yazma hacmi, ani trafik sıçramaları veya terabaytları aşan veri setleri bekliyorsanız, NoSQL (anahtar‑değer veya geniş‑sütun gibi) yatay ölçeklemeyi kolaylaştırır. Sharding ve replikasyon genelde yerleşik olup, kapasite eklemek yeni düğümler ekleyerek yapılır.
Bu desen tipik olarak şunlarda görülür:
- Yüksek trafikli web ve mobil uygulamalar
- Oyun sunucuları ve gerçek zamanlı sıralama tabloları
- Reklam teknolojisi, öneri motorları ve kişiselleştirme servisleri
Hızlı ürün iterasyonu için esnek veri
Veri modeliniz sık değişiyorsa, şema‑esnek bir tasarım faydalıdır. Doküman veritabanları yeni alanları migration gerektirmeden kabul etmenizi sağlar.
Uygun örnekler:
- İçerik yönetimi ve ürün katalogları
- Kullanıcı profilleri ve tercihleri
- Yeni etkinlik tiplerinin sıkça ortaya çıktığı etkinlik/log tabanlı sistemler
IoT, önbellekleme ve zaman‑serisi verileri
NoSQL mağazaları ekleme‑ağırlıklı ve zaman sıralı iş yükleri için güçlüdür:
- IoT telemetri ve sensör verileri
- Metrics, logging ve monitoring
- Sık erişilen veriler için önbellek (session, token, feature flag)
Özellikle anahtar‑değer ve zaman‑serisi veritabanları çok hızlı yazmalar ve basit okumalar için optimize edilmiştir.
Küresel dağıtım ve sürekli erişim deneyimleri
Birçok NoSQL platformu geo‑replikasyon ve çoklu bölge yazmalarını önceliklendirir; böylece dünya çapındaki kullanıcılar düşük gecikmeyle okuyup yazabilir. Bu, bölgesel kesintiler sırasında uygulamanın erişilebilir kalması gerektiğinde faydalıdır.
Trade‑off, genelde bölgeler arasında katı ACID semantiği yerine nihai tutarlılık kabul etmektir.
Ödünler ve sınırlamalar
NoSQL seçimi genelde bazı özelliklerden vazgeçmeyi gerektirir:
- Daha zayıf veya ayarlanabilir tutarlılık; her okuma en son yazmayı görmeyebilir
- Sınırlı ad‑hoc sorgulama ve join; sorgular genelde önceden bilinen erişim desenleri etrafında tasarlanır
- Bazı veri bütünlüğü kurallarını uygulama katmanında yönetme sorumluluğu
Bu ödünler kabul edilebiliyorsa, NoSQL geleneksel ilişkisel veritabanlarına kıyasla daha iyi ölçeklenebilirlik, esneklik ve global erişim sağlayabilir.
Hibrit desenler ve poliglot persistans
Poliglot persistans, her işi zorla tek bir depoya sokmak yerine sistem içinde birden fazla veritabanı teknolojisini bilinçli şekilde kullanmaktır.
Tipik hibrit kurulum
Yaygın bir desen:
- SQL: çekirdek veriler (siparişler, ödemeler, kullanıcı profilleri, konfigürasyon) için; burada güçlü tutarlılık, işlemler ve zengin sorgulama gerekir.
- NoSQL: oturumlar ve önbellek için anahtar‑değer mağazası; kullanıcı tercihleri veya etkinlik beslemeleri için doküman mağazası.
Bu, "kayıt sistemi"ni ilişkisel veritabanında tutarken, değişken veya okuma‑ağrılı iş yüklerini NoSQL'e aktarır.
Farklı NoSQL türlerini karıştırmak
Ayrıca NoSQL sistemlerini birlikte kullanabilirsiniz:
- Anahtar‑değer: caching ve oturum verisi
- Doküman: esnek şemalı kullanıcı içeriği
- Geniş‑sütun veya zaman‑serisi: metrikler ve event loglar
- Arama motoru: tam metin arama ve analitik sorgular
Amaç, her veri deposunu belirli bir erişim desenine hizalamaktır.
Entegrasyon ve operasyonel maliyet
Hibrit mimariler entegrasyon noktalarına dayanır:
- Mağazalar arasında veri senkronizasyonu için ETL veya streaming.
- Değişiklikleri yaymak için event streaming (ör. SQL'den cache'e).
- Hangi verinin nerede olduğunu servislerin bilmesine gerek kalmaması için API soyutlamaları.
Trade‑off, operasyonel yük: öğrenilecek, izlenecek, güvenli hale getirilecek, yedeklenecek ve sorun giderilecek daha fazla teknoloji anlamına gelir. Poliglot persistans, her ekstra datastore gerçekten ölçülebilir bir problemi çözdüğünde en iyi sonucu verir.
Bir proje için SQL mi NoSQL mi seçmeli: adım adım
Seçim, verinizi ve erişim desenlerinizi doğru araçla eşleştirmekle ilgilidir; moda takip etmekle değil.
1. Veriniz ve ilişkilerle başlayın
Sorular:
- Verim doğal olarak tabular mı, açık varlıklar (kullanıcılar, siparişler, faturalar) mı var?
- Çok sayıda join ve zengin ilişki var mı (1‑to‑many, many‑to‑many)?
Eğer evet ise ilişkisel SQL genelde varsayılan tercihtir. Veri doküman‑benzeri, iç içe veya kayıtlar arasında çok farklı yapılar gösteriyorsa, doküman ya da başka bir NoSQL modeli daha uygun olabilir.
2. Tutarlılık ve işlem ihtiyaçlarını netleştirin
- Çok satırlı veya çok tablolı ACID işlemleri gerekli mi (örn. ödemeler, envanter)?
- Bazı okumaların hafifçe eski veri döndürmesi kabul edilebilir mi?
Katı tutarlılık ve karmaşık işlemler genelde SQL’i işaret eder; gevşek tutarlılık ve yüksek yazma hızları NoSQL’i işaret edebilir.
3. Ölçek ve performansı anlayın
- Şu anki ve 2–3 yıl içindeki beklenen okuma/yazma hacmi nedir?
- Birden çok bölgede düşük gecikme gerekiyor mu?
Çoğu proje iyi indeksleme ve donanımla SQL ile uzun süre ölçeklenebilir. Çok büyük ölçek ve basit erişim desenleri bekleniyorsa NoSQL daha ekonomik olabilir.
4. Sorgu desenleri ve raporlama
- Ad‑hoc analitik, join ve raporlama yapılacak mı?
- Veriyi kim sorgulayacak: sadece mühendisler mi, yoksa analistler ve iş kullanıcıları da mı?
SQL, karmaşık sorgular ve BI araçları için idealdir. NoSQL genelde önceden belirlenmiş erişim yolları için optimize olur.
5. Ekip becerileri, araçlar ve barındırma
- Ekip daha çok hangi teknolojilere hakim: SQL, şema tasarımı veya belirli NoSQL sistemleri?
- Hosting ortamında hangi yönetilen servisler mevcut (managed PostgreSQL/MySQL, managed MongoDB, DynamoDB vb.)?
Üretimde güvenle işletilebilecek teknolojileri tercih edin.
6. Maliyet ve operasyonel karmaşıklık
- Dağıtık NoSQL kümelerini yönetebilecek kaynağımız var mı yoksa managed bir SQL örneği yeterli mi?
- Beklenen iş yükü için depolama ve okuma/yazma maliyetleri nasıl karşılaştırılıyor?
Genellikle tek bir managed SQL veritabanı, açıkça aşıldığı belli olana kadar daha ucuz ve basittir.
7. Gerçekçi iş yükleriyle test edin
Karar vermeden önce:
- Verinizin temsilci bir alt kümesini hem SQL şeması hem de aday NoSQL modeliyle modelleyin.
- Kritik birkaç sorgu ve yazmayı uygulayın.
- Gerçekçi veri hacimleri ve trafik desenleriyle yük testleri yapın.
- Gecikme, throughput, hata oranları ve operasyonel çabayı ölçün.
Ölçümlerle karar verin. Birçok proje SQL ile başlamak için güvenli bir yoldur; NoSQL bileşenleri gerektiğinde sonradan eklenebilir.
SQL ve NoSQL hakkında yaygın mitler
Mit 1: NoSQL, SQL'i ortadan kaldıracak
NoSQL, ilişkisel veritabanlarını yok etmek için gelmedi; onları tamamlamak için geldi. Kayıt sistemleri (finans, İK, ERP, envanter) hâlâ ilişkisel veritabanlarıyla yürütülür. NoSQL esneklik, büyük yazma hacimleri ve global okuma gibi alanlarda öne çıkar.
Çoğu organizasyon her iki yaklaşımı da kullanır; iş yüküne göre doğru aracı seçer.
Mit 2: SQL veritabanları yatay ölçeklenemez
Geçmişte ilişkisel veritabanları büyümek için dikey ölçeklenmeye dayanıyordu, ancak modern motorlar:
- Read replica'lar
- Sharding/partitioning desteği
- Dağıtık SQL (NewSQL) çözümleri
sunuyor. Doğru tasarım ve araçlarla yatay ölçeklenme mümkündür.
Mit 3: NoSQL'in şeması yoktur
“Şemasız” demek aslında “şema veritabanı değil, uygulama tarafından yönetilir” anlamına gelir. Doküman, anahtar‑değer ve geniş‑sütun mağazalarının hepsi bir yapıya sahiptir; sadece bu yapı daha esnek veya uygulama doğrulaması ile sağlanır.
Mit 4: Bir tür her zaman daha hızlıdır
Performans, büyük ölçüde veri modellemesi, indeksleme ve iş yüküne bağlıdır. Kötü indekslenmiş bir NoSQL koleksiyonu, iyi yapılandırılmış bir ilişkisel tabloya kıyasla daha yavaş olabilir ve tersi de geçerlidir.
Mit 5: SQL her zaman daha güvenli ve güvenilirdir
Birçok NoSQL veritabanı dayanıklılık, şifreleme, denetim ve erişim kontrolü sağlar. Öte yandan yanlış yapılandırılmış bir ilişkisel veritabanı da güvensiz olabilir. Güvenlik ve güvenilirlik, spesifik ürünün ve dağıtımın konfigürasyonu ile operasyonel olgunluğu ile ilgilidir.
Göç ve birlikte çalışma stratejileri
Takımlar genelde ölçek ve esneklik nedeniyle SQL ile NoSQL arasında geçiş yapar. Yüksek trafik bir ürün, kayıt verisini ilişkisel olarak tutup okumaları ölçeklemek veya esnek şema ihtiyaçları için NoSQL ekleyebilir.
Göç desenleri
Büyük bir geçiş risklidir. Daha güvenli yollar:
- Kademeli göç: tek bir bounded context'i (ürün kataloğu gibi) ayırıp sadece o parçayı NoSQL'e taşıyın.
- Dual writes: bir süre hizmetler hem SQL'e hem NoSQL'e yazsın; yeni depo üretimde doğrulanınca eski yol emekliye ayrılır.
- Senkronizasyon boru hatları: bir veritabanını birincil tutup CDC, mesajlaşma veya ETL ile diğerine veri akışı sağlayın.
Şema ve model tuzakları
SQL'den NoSQL'e geçerken tabloları birebir doküman olarak kopyalamak cazip gelebilir; bu genelde şu sorunlara yol açar:
- Aşırı normalize edilmiş NoSQL verisi ve uygulama tarafında çok fazla join ihtiyacı
- Kontrolsüz büyüyen dokümanlar
Yeni erişim desenlerini planlayın, sonra NoSQL şemasını bu sorgulara göre tasarlayın.
Birlikte çalışma ve güvenlik ağları
Yaygın bir desen: SQL yetkili veri (faturalama, kullanıcı hesapları), NoSQL okuma‑ağrılı görünümler (beslemeler, arama, önbellek). Hangi karışımı kullanırsanız kullanın, şunlara yatırım yapın:
- Tekrarlanabilir backfill ve rollback süreçleri
- Mağazalar arası veri doğrulaması
- Gerçekçi sorgu desenlerini yansıtan yük testleri
Böylece SQL ve NoSQL göçleri kontrol altında ve geri alınabilir olur.
Özet ve pratik öneriler
SQL ile NoSQL arasındaki temel farklar dört alanda yoğunlaşır:
- Veri modeli – SQL tablolar, satırlar ve belirgin şemalar kullanır; NoSQL doküman, anahtar‑değer, geniş sütun veya grafik gibi daha esnek yapılar sunar.
- Sorgular – SQL tek, ifade edici bir sorgu dili sunar; NoSQL genelde veritabanına özgü API veya sorgu sözdizimleri kullanır.
- Tutarlılık & işlemler – SQL ACID ve güçlü tutarlılık etrafında şekillenir; birçok NoSQL sistemi ölçek ve kullanılabilirlik için bazı garantileri gevşetir.
- Ölçeklenme – SQL geleneksel olarak dikey ölçeklenir (ve giderek kümeleşme destekler); NoSQL baştan itibaren shard ve replikasyonla yatay ölçek için tasarlanır.
Hiçbir kategori evrensel olarak daha iyi değildir. "Doğru" seçim, gerçekten ihtiyacınız olanlara bağlıdır, trendlere değil.
Uygulamada nasıl seçilir
-
İhtiyaçlarınızı yazın:
- Veri yapısı ve ilişkiler
- Sorgu ve raporlama gereksinimleri
- Tutarlılık vs kullanılabilirlik öncelikleri
- Tepe trafik, veri hacmi ve gecikme hedefleri
- Ekip becerileri ve mevcut araçlar
-
Mantıklı bir varsayılan belirleyin:
- İşlemsel sistemler, analiz ve yapılandırılmış iş verisi için SQL tercih edin.
- Yüksek yazma hacmi, büyük ölçek veya çok değişken veri için NoSQL düşünün.
-
Küçük başlayın ve ölçün:
- İnce bir dikey kesit veya PoC oluşturun.
- Ölçümler toplayın: gecikme, throughput, hata oranları, operasyonel çaba.
- Gerçek kullanım verilerine göre şema, indeks ve partition ayarlayın.
-
Hibrit olmaya açık olun:
- Farklı parçalar çok farklı ihtiyaçlara sahipse birden fazla veritabanı kullanın.
- Kararları, trade‑off'ları ve desenleri iç dokümantasyona (örneğin
/docs/architecture/datastores) kaydedin.
Daha derin okumalar veya göç kontrol listeleri için mühendislik el kitabınızı veya blogunuzu genişletebilirsiniz.
SSS
SQL ve NoSQL veritabanları arasındaki temel fark nedir?
SQL (ilişkisel) veritabanları:
- Tablolar, satırlar ve sütunlar kullanır.
- Sabit bir şemayı uygular (tanımlı sütunlar, tipler, kısıtlar).
- Standart hale gelmiş SQL sorgu diline dayanır.
- ACID işlem ve güçlü tutarlılığı vurgular.
NoSQL (ilişkisiz) veritabanları:
- Esnek modeller kullanır (doküman, anahtar‑değer, geniş sütun, grafik).
- Genellikle şema‑esnek veya şemasız veri saklamaya izin verir.
- Veritabanına özel API'ler veya DSL'ler kullanır.
- Ölçeklenebilirlik ve kullanılabilirlik için bazı tutarlılık garantilerinden vazgeçebilir.
Ne zaman SQL veritabanı genellikle daha iyi bir seçimdir?
Aşağıdaki durumlarda SQL veritabanı tercih edin:
- Veri iyi tanımlanmış ve ilişkisel (kullanıcılar, siparişler, faturalar).
- Çok satırlı veya çok tablolı ACID işlemlerine ihtiyaç var.
- Doğruluk ve tutarlılık ham işlem hacminden daha önemli.
- Çok sayıda ad‑hoc sorgu, join ve raporlama bekleniyor.
- Uyumluluk, denetim ve uzun vadeli sürdürülebilirlik kritik.
Çoğu yeni iş uygulaması için SQL makul bir varsayılan seçimdir.
Ne zaman NoSQL veritabanı genellikle daha iyi bir seçimdir?
NoSQL en iyi şu durumlarda uygundur:
- Yazma ve depolamayı yatay olarak ölçeklendirmeniz gerekiyor.
- Veri yarı‑yapılı, iç içe veya sıkça şekil değiştiriyor.
- Erişim desenleri iyi biliniyor ve anahtar/doküman aramaları etrafında modellenebilir.
- Geçici tutarsızlıklar kabul edilebilir (ör. beslemeler, loglar, analiz görünümleri).
- IoT telemetri, zaman‑serisi veriler, önbellekleme veya büyük ölçekli kullanıcı içeriği gibi senaryolar.
SQL ve NoSQL arasında şemalar ve veri modelleme nasıl farklılaşır?
SQL veritabanları:
- Önceden tanımlanmış şemalar kullanır; her satır tablo tanımına uymalıdır.
- Tekrarı azaltmak ve bütünlüğü korumak için normalizasyonu teşvik eder.
- İlişkileri yönetmek için foreign key ve kısıtlar kullanır.
NoSQL veritabanları:
- Aynı koleksiyonda farklı alanlara sahip dokümanlara izin verebilir.
- Genellikle denormalizasyonu ve ilişkili veriyi gömülü tutmayı teşvik eder.
- Veri kurallarının uygulanması daha çok uygulama tarafına kayar.
Bu, şema kontrolünün SQL'de veritabanında, NoSQL'de ise genellikle uygulamada olduğunu gösterir.
SQL ve NoSQL tutarlılık ve işlemler açısından nasıl farklıdır?
SQL veritabanları:
- ACID işlemler ve güçlü tutarlık etrafında şekillenir.
- Her okuma güncel ve geçerli bir durumu görmelidir diye ideal durumlarda kullanılır.
Birçok NoSQL sistemi:
- Kullanılabilirlik ve bölünme toleransını önceliklendirir.
- BASE yaklaşımı ve nihai tutarlılık kullanır: replika süreyle uyum sağlar.
- Operasyona veya anahtar/partition düzeyine göre ayarlanabilir tutarlılık sunabilir.
Eğer eski okumalardan kaynaklı riskler varsa SQL; küçük gecikmeli tutarsızlıklar kabul edilebilirse NoSQL tercih edilebilir.
SQL ve NoSQL veritabanları genelde nasıl ölçeklenir?
SQL veritabanları genellikle:
- Dikey ölçekle başlar (daha güçlü tek sunucu).
- Okumaları ölçeklendirmek için read replica’lar ekler.
- Ölçek‑dışı durum için sharding veya dağıtık SQL çözümleri kullanabilir.
NoSQL veritabanları genellikle:
- Başından itibaren yatay ölçek için tasarlanmıştır.
- Veriyi shard/partition ile birçok node'a yayar.
- Kapasiteyi commodity sunucular ekleyerek artırmayı kolaylaştırır.
Trade‑off: NoSQL kümeleri operasyonel olarak daha karmaşıktır; SQL ise tek düğüm sınırlarına daha çabuk ulaşabilir.
Aynı sistemde hem SQL hem de NoSQL kullanabilir miyim?
Evet. Polyglot persistence yaygındır:
- SQL'i yetkili veri kaynağı (ödeme, hesaplar, temel varlıklar) için kullanın.
- NoSQL'i oturumlar, önbellekler, beslemeler, loglar veya arama için ekleyin.
Entegrasyon örnekleri:
- SQL'den NoSQL'e Change Data Capture veya olay akışları.
- Okumaya yönelik görünüm oluşturmak için periyodik ETL işleri.
- Hizmetler üzerinden veri mağazalarını soyutlayan API'ler.
Her yeni veri depolama teknolojisini yalnızca gerçek bir problemi çözdüğünde ekleyin.
SQL ve NoSQL arasında geçiş yaparken nasıl yaklaşmalıyım?
Kademeli ve güvenli ilerlemek için:
- Taşınacak bounded context'i (ör. ürün kataloğu) belirleyin.
- Yeni erişim desenleri etrafında veriyi modelleyin; tablo‑tablolu birebir çeviri yapmayın.
- Geçici olarak dual write veya CDC kullanarak iki depoyu eşit tutun.
- Depolar arasında veri doğrulaması yapın ve tekrarlanabilir backfill planları oluşturun.
- Trafiği kademeli olarak kaydırın ve rollback planları hazırlayın.
Büyük‑patlama (big‑bang) göçlerden kaçının; izlenen, küçük adımlar tercih edin.
SQL ve NoSQL arasında seçim yaparken hangi faktörleri değerlendirmeliyim?
Değerlendirilecekler:
- Veri yapısı: tabular ve ilişkisel mi yoksa esnek doküman/event tabanlı mı?
- Tutarlılık ihtiyacı: katı ACID mi yoksa kabul edilebilir eski okuma mı?
- Ölçek ve gecikme hedefleri: beklenen yazma hacmi, veri büyüklüğü, global kullanıcılar.
- Sorgu desenleri: ad‑hoc joinler/analitik mi yoksa öngörülebilir anahtar/doküman aramaları mı?
- Ekip becerileri ve araçlar: hangi teknolojilerle rahat çalışabilirsiniz?
- Maliyet ve operasyon: yönetilen seçenekler mi, dağıtık kümeler mi?
Kritik akışlar için her iki seçeneği de prototipleyip gecikme, throughput ve karmaşıklığı ölçün.
SQL ve NoSQL hakkında bazı yaygın mitler nelerdir?
Yaygın yanlış inanışlar:
- "NoSQL SQL'i ortadan kaldıracak" – gerçekte birbirlerini tamamlarlar.
- "SQL yatay ölçeklenemez" – modern ilişkisel sistemler replikalar, sharding ve dağıtık SQL destekler.
- "NoSQL'in şeması yoktur" – şema vardır; sadece uygulama ya da opsiyonel doğrulama ile uygulanır.
- "Tek tip her zaman daha hızlıdır" – performans büyük ölçüde modelleme, indeksleme ve iş yüküne bağlıdır.
Kategori bazlı mitlere değil, spesifik ürün ve mimarilere bakın.