Jargondan uzak — anlamsal arama ne demektir?
Anlamsal arama, yazdığınız kelimelerden ziyade ne demek istediğinize odaklanan bir arama yöntemidir.
Eğer hiç arama yapıp da “cevap burada olmalı — neden bulamıyor?” diye düşündüyseniz, anahtar kelime aramanın sınırlarını hissetmişsiniz demektir. Geleneksel arama terimleri eşleştirir. Bu, sorgunuzun ve içeriğin ifadeleri örtüştüğünde işe yarar.
Neden anahtar kelime arama çoğu zaman yetersiz kalır
Anahtar kelime arama şu durumlarda zorlanır:
- Eşanlamlılar ve ifade farkları: bir hesabı “cancel” etmek ile “close” veya “terminate” etmek farklı kelimeler olabilir.
- Niyet: “how do I stop being billed?” aslında aboneliği iptal etmekle ilgilidir.
- Bağlam: “apple charger” (ürün markası) vs “apple tree charger” (anlamsız, ama fikir aynı).
Ayrıca tekrar eden kelimelere fazla ağırlık verip yüzeyde alakalı görünen ama soruyu gerçekten cevaplayan sayfayı kaçırabilir.
Basit bir örnek
Bir yardım merkezi düşünün; makale başlığı “Pause or cancel your subscription.” olsun. Bir kullanıcı arar:
“stop my payments next month”
Anahtar kelime sistemi eğer içerikte “stop” veya “payments” yoksa o makaleyi üst sıralara getirmeyebilir. Anlamsal arama, “stop my payments” ile “cancel subscription” ifadelerinin yakın anlamlı olduğunu anlar ve buna göre makaleyi üst sıralara taşır — çünkü anlam eşleşmiştir.
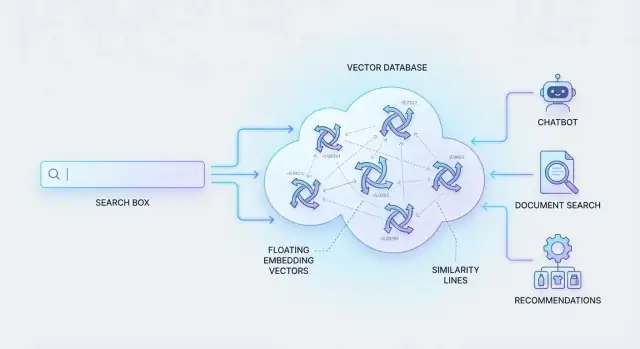
Vektör veritabanları nerede devreye girer
Bunu çalıştırmak için sistemler içeriği ve sorguları “anlam parmak izi”ne (benzerliği yakalayan sayılar) dönüştürür. Sonra bu parmak izleri arasından milyonlarca öğeyi hızlıca aramaları gerekir.
İşte vektör veritabanları bunun için tasarlanmıştır: bu sayısal temsilleri saklamak ve en benzer eşleşmeleri verimli şekilde getirmek, böylece büyük ölçekte anlamsal arama anlık gibi hissedilir.
Gömüler: İçeriği anlamlı vektörlere dönüştürmek
Gömü (embedding), anlamın sayısal temsili demektir. Bir belgeyi anahtar kelimelerle tanımlamak yerine, onun ne hakkında olduğunu yakalayan bir sayı listesi (bir “vektör”) olarak saklarsınız. Benzer anlamlara sahip iki içerik, o sayısal uzayda birbirine yakın vektörler üretir.
Bir gömü gerçekte nasıl görünür
Gömüyü çok yüksek boyutlu bir haritadaki koordinat gibi düşünün. Genelde sayılara doğrudan bakmazsınız—insan dostu olmaları amaçlanmaz. Değerleri, nasıl davrandıklarında yatıyor: “cancel my subscription” ile “how do I stop my plan?” benzer vektörler üretiyorsa, sistem bunları farklı kelimeler kullansalar bile ilişkili sayabilir.
Metin, görsel ve ses de vektöre dönüşebilir
Gömüler sadece metinle sınırlı değildir.
- Metin gömüleri cümleleri, paragrafları, destek taleplerini, ürün açıklamalarını temsil eder.
- Görüntü gömüleri görsel benzerlik ve kavramları temsil eder (ör. “kırmızı koşu ayakkabısı”).
- Ses gömüleri konuşmacıyı, tonu veya konuşmanın anlamını temsil edebilir (konuşma modelleriyle eşleştirildiğinde).
Bu sayede tek bir vektör veritabanı “bir görselle ara”, “benzer şarkıları bul” veya “bu ürün gibi öner” gibi deneyimleri destekleyebilir.
Modeller tarafından üretilir — elle etiketlenmez
Vektörler elle etiketlenmez. Anlamı sayılara sıkıştırmayı öğrenmiş makine öğrenimi modelleri üretir. İçeriği bir embedding modeline (kendi veya sağlayıcınız tarafından barındırılan) gönderirsiniz, model bir vektör döner. Uygulamanız bu vektörü orijinal içerik ve metadata ile birlikte saklar.
Hangi gömüyü seçtiğiniz kaliteyi ve maliyeti etkiler
Seçtiğiniz embedding modeli sonuçları güçlü şekilde etkiler. Daha büyük veya uzmanlaşmış modeller genellikle daha iyi alaka sunar ama daha pahalı ve yavaş olabilir. Küçük modeller daha ucuz ve hızlıdır ama özellikle alanınıza özgü dil, çok dilli içerik veya kısa sorgular için nüansı kaçırabilir. Birçok ekip, ölçeklemeden önce birkaç modeli test ederek en iyi dengeyi bulur.
Vektör veritabanları veriyi nasıl saklar
Bir vektör veritabanı basit bir fikre dayanır: “anlamı” (vektörü) yanında kimliklendirme, filtreleme ve gösterim için gereken bilgileri sakla.
Temel veri modeli
Çoğu kayıt şöyle görünür:
- ID: sizin kontrolünüzde benzersiz bir tanımlayıcı (ör.
doc_18492 veya bir UUID)
- Vektör (gömü): içeriğin anlamını temsil eden sayı dizisi
- Metadata: title, URL, tags, author, language, created_at veya tenant_id gibi anahtar–değer alanlar
Örneğin bir yardım makalesi şu bilgileri saklayabilir:
- ID:
kb_123
- Vektör: yaygın bir embedding modeli için 768 kayan nokta sayısı
- Metadata:
{ "title": "Reset your password", "url": "/help/reset-password", "tags": ["account", "security"] }
Vektör anlamsal benzerliği sağlar. ID ve metadata ise sonuçları kullanılabilir kılar.
Metadata iki işi yapar:
- Vektör aramadan önce/sonra filtreleme: “Sadece ürün X'ten göster”, “Sadece İngilizce”, “Kullanıcının erişebileceği belgeler” veya “90 günden yeni olanlar” gibi kısıtlamalar. Bu alaka ve erişim kontrolü için elzemdir.
- Gösterim ve eylemler: Kullanıcıya bir vektör değil bir başlık, özet ve link göstermek istersiniz. Metadata UI'nizin ihtiyaç duyduğu ayrıntıları sağlar.
İyi metadata yoksa doğru anlamı geri getirebilirsiniz ama yine de yanlış bağlamı gösterebilirsiniz.
Yaygın vektör boyutları ve depolama etkileri
Embedding boyutu modele göre değişir: 384, 768, 1024 ve 1536 boyutlar yaygındır. Daha fazla boyut nüansı yakalayabilir ama aynı zamanda artırır:
- Depolama (her kayıt daha çok sayı saklar)
- Hızlı arama için bellek baskısı
- İndeks kurma süresi (özellikle ANN indekslemede)
Kabaca bir sezgi: boyutları ikiye katlamak maliyeti ve gecikmeyi artırma eğilimindedir; bunu indeksleme seçimleri veya sıkıştırma ile dengelersiniz.
Güncelleme modelleri: ekleme, değişiklik ve silme
Gerçek veri setleri değişir, bu yüzden vektör veritabanları genellikle şunları destekler:
- Insert: yeni içeriği gömü ve metadata ile ekleme
- Update: metadata'yı değiştirme (ör. etiketler) veya içerik değiştiyse vektörü yenileme
- Delete: güncelliğini yitirmiş veya erişimi kaldırılmış içeriği silme
- Re-embed: embedding modelini değiştirdiğinizde, chunklama yöntemini değiştirdiğinizde veya metni önemli ölçüde düzenlediğinizde vektörleri yeniden hesaplama
Güncellemeler için erken planlama, arama sonuçlarının kullanıcıların gördüğüyle uyuşmaması sorununu önler.
Benzerlik arama: “En yakın anlamı” hızlıca bulmak
Metin, görsel veya ürünler gömülere dönüştürüldükten sonra arama bir geometri problemine dönüşür: “Bu sorgu vektörüne en yakın hangi vektörler?” Buna en yakın komşu arama denir. Anahtar kelime eşleştirmek yerine sistem iki vektörün ne kadar yakın olduğuna bakar.
En yakın komşuyu sade dille anlatmak
Her içeriği çok boyutlu dev bir uzaydaki bir nokta olarak hayal edin. Kullanıcı arama yaptığında sorgusu başka bir noktaya dönüştürülür. Benzerlik araması, noktalara en yakın olanları döndürür — bunlar niyet, konu veya bağlam açısından benzeme olasılığı yüksek olan öğelerdir, kelime örtüşmesi olmasa bile.
Yaygın benzerlik metrikleri
Vektör veritabanları genelde bazı standart puanlama yöntemlerini destekler:
- Cosine similarity: vektörler arasındaki açıyı karşılaştırır (yön/anlam önemliyse iyi)
- Dot product: cosinel ile ilişkili, vektör uzunluğundan etkilenebilir; normalize gömülerle sık kullanılır
- Euclidean distance: noktalar arasındaki düz mesafe (bazı modeller ve alanlar için kullanışlı)
Farklı embedding modelleri belirli bir metriğe göre eğitilmiş olabilir; bu yüzden model sağlayıcısının önerdiği metriği kullanmak önemlidir.
Tam arama vs yaklaşık (ANN)
Tam arama her vektörü kontrol ederek gerçek en yakın komşuları bulur. Bu doğru olabilir ama milyonlarca öğeye gelince yavaş ve pahalıdır.
Çoğu sistem yaklaşık en yakın komşu (ANN) araması kullanır. ANN, aramayı en umut verici adaylarla sınırlandıran akıllı indeks yapıları kullanır. Genelde gerçek en iyi eşleşmelere “yeterince yakın” sonuçlar verir — çok daha hızlı.
Gecikme vs recall takası
ANN popülerdir çünkü ihtiyaçlarınıza göre ayarlanabilir:
- Daha düşük gecikme (daha hızlı yanıt) için daha az aday aranır.
- Daha yüksek recall (gerçek en iyi eşleşmeleri daha fazla bulma) için daha çok aday aranır.
Bu ayarlanabilirlik, vektör aramayı gerçek uygulamalarda işe yarar kılar: sonuçları akıcı tutarken hâlâ yüksek alakalı sonuçlar döndürebilirsiniz.
Baştan sona anlamsal arama iş akışı
Anlamsal aramayı basit bir boru hattı olarak düşünmek en kolayıdır: metni anlam haline dönüştür, benzer anlamları ara, sonra en faydalı eşleşmeleri göster.
1) Sorguyu gömüle
Kullanıcı bir soru yazar (ör. “How do I cancel my plan without losing data?”). Sistem bu metni bir embedding modelinden geçirir ve sorgunun kelimelerinden ziyade anlamını temsil eden bir vektör üretir.
2) Vektör veritabanında ara
O sorgu vektörü vektör veritabanına gönderilir; veritabanı saklanan içerikler arasından “en yakın” vektörleri bulmak için benzerlik araması yapar.
Çoğu sistem top-K eşleşmeleri döndürür: en benzer K chunk/doküman.
- K'nin ayarlanabilir olması neden önemli: daha küçük bir K daha hızlıdır ve çoğu kez yeterli olabilir (ör. K=5).
- Daha büyük K recall'u artırır (doğru cevabı kaçırma olasılığı azalır) ama “neredeyse alakalı” sonuçlar da kapsanabilir (ör. K=50).
3) (Opsiyonel) Hassasiyet için yeniden sıralama
Benzerlik araması hız için optimize edildiğinden ilk top-K içinde yanılmalar olabilir. Bir reranker ikinci bir model olarak sorgu ile her aday sonucu birlikte inceler ve yeniden sıralama yapar.
Vektör arama güçlü bir kısa liste verir; yeniden sıralama en iyiyi seçer.
4) Sonuçları döndür veya aşağı akışa ver
Son olarak en iyi eşleşmeleri kullanıcıya döndürürsünüz (arama sonuçları olarak) veya onları bir AI asistanına (ör. RAG sistemi) “dayanak” bağlamı olarak verirsiniz.
Bu tür bir iş akışını bir uygulamaya entegre ediyorsanız, Koder.ai gibi platformlar hızlı prototipleme konusunda yardımcı olabilir: anlamsal arama veya RAG deneyimini sohbet arayüzünde tarif edersiniz, sonra React ön yüzü ve Go/PostgreSQL arka ucunu yineleyerek retrieval boru hattını (embed → vector search → opsiyonel rerank → cevap) ürünün birinci sınıf parçası haline getirirsiniz.
Bir hızlı “anahtar kelime vs anlamsal” örneği
Yardım makaleniz “terminate subscription” diyorsa ve kullanıcı “cancel my plan” arıyorsa, anahtar kelime arama bunu kaçırabilir çünkü “cancel” ve “terminate” eşleşmeyebilir.
Anlamsal arama genelde bunu geri getirir çünkü embedding her iki ifadenin de aynı niyeti ifade ettiğini yakalar. Yeniden sıralama eklerseniz, üst sonuçlar genelde sadece “benzer” değil doğrudan kullanıcı için uygulanabilir hale gelir.
Kaynak kodunu alın
Prototiplerin ötesine geçtiğinizde tam sahiplik için kaynak kodunu dışa aktarın.
Saf vektör arama “anlam” konusunda mükemmeldir, ama kullanıcılar her zaman anlamla aramaz. Bazen tam bir eşleşme gerekir: kişinin tam adı, SKU, fatura numarası veya logdan kopyalanmış bir hata kodu. Hibrit arama, anlamsal sinyalleri (vektörler) leksikal sinyallerle (BM25 gibi geleneksel anahtar kelime arama) birleştirir.
Hibrit arama gerçekte ne yapar
Hibrit sorgu genelde iki yolu paralel çalıştırır:
- Vektör arama: ifade farklı olsa bile kavramsal olarak benzer içeriği bulur.
- Anahtar kelime/BM25 arama: tam token eşleşmesi olan içerikleri bulur ve nadir kelimelere ödül verir.
Sonra sistem bu adayları tek bir sıralı listede birleştirir.
Hibrit ne zaman daha iyi varsayılandır
Veri setiniz “zorunlu eşleşme” dizileri içeriyorsa hibrit parıldar:
- Ürün adları ve belirteçleri (ör. “Pro Max”, “Gen 2”)
- ID'ler (sipariş numaraları, ticket ID'leri, parça numaraları)
- Hata kodları (“E0421”, “ORA-00933”) ve komut bayrakları
- Eşanlamlılık riskli olan nadir domain terimleri
Anlamsal arama tek başına geniş ilgili sayfaları getirirken; anahtar kelime arama yalnız başına farklı ifade şekillerindeki doğru cevabı kaçırabilir. Hibrit her iki başarısızlık modunu kapsar.
Metadata filtreleri sıralamadan önce (veya onunla birlikte) retrieval'u kısıtlar, alaka ve hızı artırır. Yaygın filtreler:
- Dil (sadece İngilizce belgeleri döndür)
- Tarih aralığı (en güncel politika, son sürüm notları)
- Kategori veya kaynak (dokümanlar vs. ticket'lar; “billing” vs. “security”)
- Erişim kontrol etiketleri (kullanıcının görebileceği içerikler)
Puanlama nasıl çalışır (yüksek seviyede)
Çoğu sistem pratik bir karışım kullanır: her iki aramayı çalıştır, puanları normalize et ki karşılaştırılabilir olsun, sonra ağırlık uygula (ör. “ID'lerde anahtar kelimelere daha fazla ağırlık ver”). Bazı ürünler birleştirilmiş kısa listeyi hafif bir model veya kurallarla yeniden sıralar; filtreler ise doğru alt küme üzerinde sıralama yaptığınızdan emin olur.
RAG: LLM cevaplarını dayandırmak için vektör veritabanları
Retrieval-Augmented Generation (RAG), LLM'den daha güvenilir cevaplar almak için pratik bir yaklaşımdır: önce ilgili bilgiyi geri getir, sonra o bağlama bağlı bir cevap üret.
RAG fikri tek cümlede
Modelin şirket dokümanlarınızı “hafızasında tutmasını” beklemek yerine, bu dokümanları gömüler halinde vektör veritabanında saklarsınız, soru zamanında en ilgili chunk'ları geri çekersiniz ve bunları LLM'e destekleyici bağlam olarak verirsiniz.
Vektör veritabanı neden halüsinasyonu azaltmaya yardımcı olur
LLM'ler yazmada mükemmeldir ama gerekli gerçekler yoksa kendinden emin biçimde boşluk doldurma eğilimindedir. Vektör veritabanı, bilgi tabanınızdan en yakın anlamlı pasajları almak ve bunları prompt'a eklemek için kolay bir yol sağlar.
Bu dayanak, modeli “cevap uydurmaktan” “bu kaynakları özetle ve açıkla” moduna kaydırır. Ayrıca hangi chunk'ların alındığını takip edip isteğe bağlı olarak atıf göstermenizi kolaylaştırır.
Chunklama temelleri (geri getirme gerçekten çalışsın diye)
RAG kalitesi çoğunlukla modelden çok chunklamaya bağlıdır.
- Chunk boyutu: Tam bir düşünce içeren chunk'lar hedefleyin (genellikle kısa bir bölüm). Çok küçük anlam kaybına, çok büyük gürültüye yol açar.
- Örtüşme: Önemli detayların sınırda bölünmemesi için küçük bir örtüşme ekleyin.
- Bağlamı koruyun: Başlıkları, başlıkçıkları ve tanımlayıcıları (doküman adı, bölüm, tarih) metadata olarak saklayın ki sonuçlar anlaşılır ve filtrelenebilir olsun.
Basit RAG boru hattı (tanım)
Akışı şöyle hayal edin:
Kullanıcı sorusu → Sorguyu gömüle → Vector DB top-k chunk'ları getir (+ opsiyonel metadata filtreleri) → Getirilen chunk'larla prompt oluştur → LLM cevap üretir → Cevabı ve kaynakları döndür.
Vektör veritabanı burada her isteğe en ilgili kanıtı sağlayan “hızlı hafıza” görevi görür.
Vektör veritabanlarının desteklediği yaygın AI kullanım durumları
Kredilerinizi uzatın
Koder.ai hakkında içerik oluşturun veya ekip arkadaşlarınızı yönlendirin, böylece geliştirme sürenizi uzatın.
Vektör veritabanları sadece aramayı “daha akıllı” yapmaz — kullanıcıların doğal dilde ne istediklerini ifade ederek hâlâ alakalı sonuçlar alabilecekleri ürün deneyimlerini mümkün kılar. Aşağıda sık rastlanan bazı kullanım durumları var.
Müşteri desteği: anahtar kelimelerin ötesinde cevap bulun
Destek ekiplerinin genelde bir bilgi tabanı, eski ticket'lar, sohbet transkriptleri ve sürüm notları olur — ama anahtar kelime araması eşanlamlılar, farklı ifade şekilleri ve belirsiz sorun tanımlarıyla zorlanır.
Anlamsal arama sayesinde bir temsilci (veya chatbot) farklı ifadeler kullanan geçmiş ticket'ları alıp ilişkilendirerek çözümü hızlandırabilir, tekrar eden işleri azaltabilir ve yeni temsilcilerin işe alışmasını kolaylaştırır. Vektör aramayı metadata filtreleri (ürün hattı, dil, sorun türü, tarih aralığı) ile eşleştirmek sonuçları odaklı tutar.
Ürün keşfi: insanların konuştuğu şekilde katalogda arama
Alıcılar nadiren tam ürün adını bilir. “Laptop sığan, profesyonel görünen küçük sırt çantası” gibi niyetler ararlar. Gömüler bu tercihleri—stil, işlev, kısıtlar—yakaladığı için sonuçlar insan bir satış görevlisine daha yakın hissedilir.
Bu yaklaşım perakende katalogları, seyahat listeleri, emlak, iş ilanları ve pazar yerleri için uygundur. Ayrıca anlamsal alaka ile fiyat, boyut, stok veya konum gibi yapısal kısıtları harmanlayabilirsiniz.
Öneriler: “buna benzer” ve içerik keşfi
Klasik bir vektör veritabanı özelliği “buna benzer öğeleri bul”dur. Kullanıcı bir öğeye bakıyorsa, okuduğu bir makaleye veya izlediği bir videoya benzer diğer içerikleri geri getirebilirsiniz — kategoriler tam uyuşmasa bile.
Bu, şunlar için kullanışlıdır:
- “Buna benzer” modülleri
- İlgili makaleler ve bilgi tabanı önerileri
- İçerik çoğaltma veya neredeyse eşdeş tespit (moderasyon veya temizlik için)
İzinlerle dahili arama: politika, doküman, toplantı notları
Şirket içinde bilgi dokümanlar, wiki'ler, PDF'ler ve toplantı notları arasında dağılmıştır. Anlamsal arama çalışanların doğal dil sorular sormalarını ve doğru kaynağı bulmalarını sağlar (ör. “Konferans harcamaları için geri ödeme politikamız nedir?”).
Burada vazgeçilmez olan erişim kontrolüdür. Sonuçlar takım, doküman sahibi, gizlilik seviyesi veya ACL listesine göre filtrelenmeli ki kullanıcı sadece erişimine izin verilenleri görebilsin.
Ayrıca bu retrieval katmanı, RAG ile desteklenmiş Soru&Cevap sistemlerinin temelini oluşturur (RAG bölümünde bahsedildi).
Veri boru hatları: alım, chunklama ve güncellemeler
Bir anlamsal arama sistemi, ona veri sağlayan boru hattı kadar iyidir. Belgeler tutarsız geliyorsa, kötü chunk'lanmışsa veya düzenlendikten sonra yeniden gömülenmiyorsa sonuçlar kullanıcı beklentilerinden uzaklaşır.
İşleyen basit bir alım akışı
Çoğu ekip tekrarlanabilir bir sıra izler:
- Veri topla (dokümanlar, PDF'ler, ticket'lar, sohbet logları, wiki sayfaları, ürün verisi)
- Temizle (boilerplate'leri çıkar, kodlamayı düzelt, boşlukları normalleştir, ana metni çıkar)
- Chunk'la (geri çağırılabilecek parçalara böl)
- Gömüle (seçtiğin embedding modeli ile vektör üret)
- Upsert (vektör + metadata'yı vektör veritabanına yaz; gerekirse değiştir)
“Chunk” adımı birçok boru hattının kazanmasını veya kaybetmesini belirler. Çok büyük chunk'lar anlamı seyreltir; çok küçük chunk'lar bağlamı kaybettirir. Pratik bir yaklaşım, chunk'lamayı doğal yapıya (başlıklar, paragraflar, Soru&Cevap çiftleri) göre yapmak ve süreklilik için küçük örtüşme tutmaktır.
Gömüleri güncel tutmak
İçerik sürekli değişir — politikalar güncellenir, fiyatlar değişir, makaleler yeniden yazılır. Gömüleri türetilmiş veri olarak ele alın; yeniden oluşturulmaları gerekir.
Yaygın taktikler:
- Bir kaynak doküman ID'si, chunk ID ve bir içerik hash'i saklayın. Hash değişirse o chunk'ı yeniden gömün.
- Soft delete kullanın (eski chunk'ları pasif olarak işaretleyin) ki hayalet sonuçlar olmasın.
- Her şeyi yeniden gömmek yerine seçerek yeniden oluşturun.
Toplu vs akış halinde güncellemeler
- Toplu: büyük backfill'ler, gece senkronları, belgeler gibi öngörülebilir içerikler için uygundur.
- Akış: destek ticket'ları, kullanıcı içeriği, stok gibi hızlı değişen kaynaklar için uygundur. Daha az eskime sağlar ama izleme ve maliyet kontrolü gerektirir.
Birden çok dil ve birden çok model
Birden çok dil sunuyorsanız ya çokdilli embedding modeli kullanabilirsiniz (daha basit) ya da dil başına modeller (bazen daha yüksek kalite). Model deneyleri yapıyorsanız gömülerinizi versiyonlayın (örn. embedding_model=v3) ki A/B testleri ve geri alma yapabilesiniz.
Anlamsal arama demo aşamasında iyi görünebilir ama üretimde başarısız olabilir. Fark ölçümde: net alaka metrikleri ve hız hedefleri gerekir; bunları gerçek kullanıcı davranışına benzeyen sorgularla değerlendirin.
Kullanıcı memnuniyetini yansıtan alaka metrikleri
Önce küçük bir metrik setiyle başlayın ve sürdürün:
- Precision / Recall: Dönen sonuçların kaçının gerçekten alakalı olduğunu ve toplam alakalı öğelerin kaçını geri getirebildiğinizi gösterir.
- MRR (Mean Reciprocal Rank): Kullanıcının bir “en iyi” cevabı beklediği durumlarda iyidir; doğru dokümanı üst sıralara koymayı ödüllendirir.
- nDCG: Birden çok sonucun farklı düzeylerde alakalı olabileceği durumlarda kullanışlıdır.
- Gecikme (p50/p95): Ortalama ve kuyruk gecikmesini takip edin. Hızlı bir p50 ama yavaş bir p95 kullanıcı için hâlâ yavaş hissettirir.
Güvenilir bir test seti oluşturun
Değerlendirme setinizi şuradan oluşturun:
- Gerçek sorgular (anonimleştirilmiş) arama loglarından veya destek ticket'larından
- Beklenen dokümanlar (altın etiketler) alan uzmanları tarafından kabul edilmiş
- Köşe durumları: kısa sorgular (“refund”), uzun sorular, belirsiz terimler, nadir ürün isimleri ve doğru davranışın “bulunamadı” olduğu sorgular
Test setini versiyonlayın ki sürümler arası karşılaştırma yapabilesiniz.
A/B testleri ve geri bildirim döngüleri
Offline metrikler her şeyi yakalamaz. A/B testleri çalıştırın ve hafif sinyaller toplayın:
- Sonuçlar için başparmak yukarı/aşağı
- Tıklama oranı ve sayfada kalma süresi
- “Aramayı daralt” olayları
Bu geri bildirimleri alaka yargılarını güncellemek ve hata kalıplarını tespit etmek için kullanın.
Zaman içinde sürüklenmeyi (drift) izleme
Performans şu durumlarda değişebilir:
- Embedding modellerini değiştirdiğinizde veya chunklama yöntemini güncellediğinizde
- Korpusunuz kaydığında (yeni ürünler, politika değişiklikleri, mevsimsel terimler)
Her değişiklikten sonra test setinizi yeniden çalıştırın, metrik eğilimlerini haftalık izleyin ve MRR/nDCG düşüşleri ya da p95 gecikme artışları için alarmlar kurun.
Güvenlik, gizlilik ve erişim kontrolü
Bir RAG prototipi test edin
Basit bir RAG uygulaması kurun ve gömüler, chunklama ve geri getirme üzerinde yinelemeler yapın.
Vektör arama veriyi nasıl geri getirdiğini değiştirir ama kimin görmeye yetkisi olduğunu değiştirmemelidir. Anlamsal arama veya RAG sistemi doğru chunk'ı bulabilirse, yanlışlıkla kullanıcının görmemesi gereken bir chunk'ı da döndürebilir — bunu önlemek için erişim ve gizliliği retrieval adımına dahil edin.
Erişim kontrolü: retrieval sırasında zorunlu uygulama
En güvenli kural basittir: bir kullanıcı yalnızca okumaya izinli olduğu içeriği geri alabilmelidir. Vektör veritabanı sonuç döndürmeden uygulamanın onları gizlemesine güvenmeyin — çünkü o noktada içerik zaten veri sınırını terk etmiş olur.
Pratik yaklaşımlar:
- Belge/ chunk başına ACL'ler: her vektörün yanında izin alanlarını saklayın ki her sorguda bunlar denetlenebilsin.
- Tenant izolasyonu: çok kiracılı uygulamalarda veriyi tenant bazında ayırın (mantıksal bölümler, namespace'ler veya ayrı indeksler) ki kiracılar arası sızıntı olmasın.
Çoğu vektör veritabanı metadata tabanlı filtreleri (örn. tenant_id, department, project_id, visibility) benzerlik araması ile birlikte çalıştırır. Doğru kullanıldığında bu, retrieval sırasında izin uygulamanın temiz bir yoludur.
Bir ayrıntı: filtrenin zorunlu ve sunucu tarafı olduğundan emin olun; istemci mantığına bırakmayın. İzin modeli karmaşıksa, “etkin erişim grupları” önceden hesaplanmış veya sorgu zamanında filtre belirteci veren bir yetkilendirme servisi kullanmayı düşünün.
KİŞİSEL VERİ ve hassas içerik: asla gömülmemesi gerekenler
Gömüler orijinal metnin anlamını kodlayabilir. Bu ham PII'yi (kişisel tanımlayıcı bilgileri) otomatik olarak açığa çıkarmaz ama riski artırabilir (ör. hassas gerçeklerin daha kolay geri çağırılabilir hale gelmesi).
İyi uygulamalar:
- Çok hassas alanları gömülemeye çalışmayın (SSN, ödeme detayları, tıbbi kimlikler) mümkünse.
- Gömülemeden önce redaksiyon yapın (tam değerleri yer tutucularla değiştirin) eğer metin aranabilir olmalıysa.
- Orijinalleri ayrı saklayın ve yalnızca izin kontrollerinden sonra geri çağırın.
Operasyonel ihtiyaçlar: yedekler, saklama, denetim
Vektör indeksinizi üretim verisi gibi ele alın:
- Yedekler ve kurtarma: indeksleri yeniden oluşturmak maliyetli olabilir; snapshot planı veya kaynak veriden yeniden oluşturma yolu planlayın.
- Saklama politikaları: kaynak belgeler silindiğinde veya kullanıcı isteminde vektörleri silin.
- Denetlenebilirlik: kim ne sorguladı (en azından sorgu bağlamı ve döndürülen doküman ID'leri) gibi kayıtlar tutun ki soruşturmalar ve uyumluluk desteklensin.
İyi uygulamalarla, anlamsal arama kullanıcılar için sihirli hale gelir — ama sonra güvenlik sürprizi olmamalıdır.
Tuzaklar, maliyetler ve pratik seçim kontrol listesi
Vektör veritabanları "takıp çalıştır" gibi görünebilir, ama çoğu hayal kırıklığı çevresel seçimlerden gelir: chunklama nasıl yapıldı, hangi gömü modeli seçildi ve her şeyin güncel tutulması nasıl sağlandı.
Yaygın başarısızlık nedenleri (ve tespit yöntemleri)
Kötü chunklama en başta yatar. Çok büyük chunk'lar anlamı seyreltir; çok küçük chunk'lar bağlamı kaybettirir. Kullanıcılar sıklıkla “doğru dokümanı buldu ama yanlış pasajı” diyorsa chunklama stratejiniz muhtemelen sorunludur.
Yanlış gömü modeli tutarlı anlamsal uyumsuzluk olarak görünür — sonuçlar akıcı ama konu dışı. Bu, modelin alanınıza (hukuk, tıp, destek ticket'ları) veya içerik tipinize (tablolar, kod, çokdilli metin) uygun olmamasıyla olur.
Eski veri güven sorunları yaratarak hızla güveni sarsar: kullanıcı en güncel politikayı arar, geçen çeyreğin versiyonunu alır. Kaynak veri değişiyorsa gömüler ve metadata da güncellenmelidir (ve silinmeler gerçek olarak silinmelidir).
Soğuk başlangıç ve boş-sonuç yönetimi
Erken aşamada içerik az olabilir, sorgu sayısı yetersiz olabilir veya yeterli geri bildirim olmayabilir. Hazırlıklı olun:
- Yedekler: anlamsal sonuçlar zayıfsa anahtar kelime arama veya kürate edilmiş “en iyi cevaplar” olarak geri dönüş
- Boş-sonuç UX: ilgili kategoriler gösterme, açıklayıcı bir soru sorma veya filtreleri genişletme
- Isıtma sorguları: lansmandan önce temsilci sorgularla test edin
Tahmin edilecek maliyet unsurları
Maliyetler genelde dört yerden gelir:
- Gömü hesaplama (ilk backfill + sürekli güncellemeler)
- Depolama (vektörler, metadata, indeksler)
- Sorgu hacmi (okumalar, ağ çıkışı, eşzamanlılık)
- Yeniden sıralama (opsiyonel ama güçlü; sorgu başına model maliyeti ekleyebilir)
Tedarikçileri karşılaştırırken beklenen doküman sayınız, ortalama chunk boyutu ve tepe QPS'inizi kullanarak aylık basit bir tahmin isteyin. Çoğu sürpriz indeksleme sonrası veya trafik zirvelerinde çıkar.
Pratik seçim kontrol listesi
İhtiyaçlarınıza uygun bir vektör veritabanı seçerken kısa kontrol listesi:
- Arama kalitesi: hibrit arama (anahtar kelime + vektör) ve metadata filtrelerini destekliyor mu? Yeniden sıralama ekleyebiliyor musunuz?
- Performans: ANN indeksleme seçenekleri, tepe trafikte öngörülebilir gecikme ve kolay ölçeklenebilirlik
- Veri operasyonları: upsert, delete, yeniden indeksleme, versiyonlama ve backfill'ler kesinti olmadan yapılabiliyor mu?
- Gözlemlenebilirlik: sorgu logları, recall/gecikme metrikleri ve “bu sonuç neden geldi”i debug etmeye yarayan araçlar
- Güvenlik: şifreleme, tenant izolasyonu, rol tabanlı erişim ve izinlerle filtreleme patternleri
- Entegrasyon: SDK'lar, desteklenen diller ve depolama konektörleri (S3, veritabanları, doküman kaynakları)
- Toplam maliyet: depolama, yazma, okuma ve yönetilen hesaplama için şeffaf fiyatlandırma
Doğru seçim, en yeni indeks tipini kovalamaktan ziyade güvenilirlik hakkındadır: verileri güncel tutabiliyor musunuz, erişimi kontrol edebiliyor musunuz ve içerik ile trafik büyüdükçe kaliteyi koruyabiliyor musunuz?