18 Eki 2025·8 dk
Veri İçe Aktarımları, Dışa Aktarımlar ve Doğrulama İçin Web Uygulaması Nasıl Oluşturulur
CSV/Excel/JSON içe/dışa aktarmalarını, net hata doğrulamasını, roller ve denetim kayıtlarını destekleyen güvenilir bir web uygulaması nasıl tasarlanır öğrenin.
Kapsamı ve kullanıcı ihtiyaçlarını tanımlayın
Ekranları tasarlamadan veya bir dosya ayrıştırıcı seçmeden önce, veriyi kimlerin ürününüze taşıdığını ve neden taşıdıklarını netleştirin. İç kullanıcılara yönelik bir veri içe aktarma uygulaması, müşterilerin kullandığı kendi kendine hizmet Excel içe aktarma aracından çok farklı görünecektir.
Kullanıcılar kimler?
İçe/dışa aktarmalara dokunacak rolleri listeleyerek başlayın:
- Yöneticiler: eşlemeleri, kuralları ve izinleri yapılandıranlar
- Operatörler: düzenli içe aktarmaları çalıştıran ve istisnalarla ilgilenenler
- Müşteriler: kendi CSV/Excel dosyalarını yükleyen ve net rehberlik bekleyenler
Her rol için beklenen beceri düzeyini ve karmaşıklık toleransını tanımlayın. Müşteriler genellikle daha az seçenek ve ürün içi daha iyi açıklamalar ister.
Temel kullanım senaryoları (ve “tamamlanmış” ne demek?)
En önemli senaryolarınızı yazın ve önceliklendirin. Yaygın olanlar:
- Başlangıçta toplu yükleme (onboarding sırasında, yüksek hacim, dağınık veri)
- Periyodik senkronizasyon (haftalık/aylık güncellemeler, tutarlılık önemli)
- Tek seferlik dışa aktarma (raporlama, taşıma veya yedekleme için)
Sonra ölçülebilir başarı metriklerini tanımlayın. Örnekler: daha az başarısız içe aktarma, hataların çözüm süresinin kısalması, “dosyam yüklenmiyor” destek taleplerinde azalma. Bu metrikler, daha sonra yapılacak takaslarda (ör. daha net hata raporlama mı yoksa daha fazla dosya formatına yatırım mı) yol gösterir.
Formatlar, limitler ve uyumluluk
Gün 1’de destekleyeceklerinizi açıkça belirtin:
- Dosya formatları: CSV, Excel (XLSX), JSON
- Maksimum dosya boyutu ve satır limitleri (aşıldığında ne olur)
- Kodlama beklentileri (örn. UTF-8) ve tarihler için zaman dilimi kuralları
Son olarak, dosyaların KİB içerip içermediğini, saklama gereksinimlerini (yüklemeleri ne kadar süre saklayacağınız) ve denetim gereksinimlerini erken tespit edin. Bu kararlar depolama, kayıt tutma ve izinleri tüm sistemde etkiler.
Mimari ve teknoloji yığınını seçin
Süslü bir sütun eşleme UI’si veya CSV doğrulama kuralları hakkında düşünmeden önce, ekibinizin teslim edebileceği ve işletmekten çekinmeyeceği bir mimari seçin. İçe/dışa aktarmalar genellikle “sıkıcı” altyapıdır—yenilikten çok yineleme hızı ve hata ayıklama kolaylığı öne çıkar.
Ekibinizin bildiği bir yığınla başlayın
Her ana akım web yığını bir veri içe aktarma uygulamasını çalıştırabilir. Seçiminizi mevcut becerilere ve işe alım gerçeklerine göre yapın:
- React + Node (TypeScript): tek dilli full-stack ve arka plan işleri için güçlü ekosistem istiyorsanız.
- Django: pil içinde admin, olgun ORM ve hızlı teslimat istiyorsanız.
- Rails: konvansiyonlar, hızlı CRUD ve yerleşik arka plan işi desenlerini tercih ediyorsanız.
Önemli olan tutarlılıktır: yığın, yeni içe aktarma türleri, yeni doğrulama kuralları ve yeni dışa aktarma formatları eklemeyi yeniden yazmadan kolaylaştırmalı.
Eğer tek seferlik prototipe bağlı kalmadan hızla iskelet oluşturmak istiyorsanız, Koder.ai gibi sohbet tabanlı bir kod üretme platformu yardımcı olabilir: içe aktarma akışınızı (yükleme → önizleme → eşleme → doğrulama → arka plan işleme → geçmiş) tarif ederek React UI ve Go + PostgreSQL backend üretebilir, planlama modu ve snapshot/rollback ile hızlı yineleme yapabilirsiniz.
Depolama: “ham dosya”yı “normalize kayıtlar”dan ayırın
Yapılandırılmış kayıtlar, upsert'ler ve veri değişiklikleri için ilişkisel veritabanı (Postgres/MySQL) kullanın.
Orijinal yüklemeleri (CSV/Excel) object storage (S3/GCS/Azure Blob) içinde saklayın. Ham dosyaları tutmak destek için paha biçilemezdir: ayrıştırma sorunlarını yeniden üretir, işleri tekrar çalıştırır ve hata işleme kararlarını açıklamanıza yardımcı olur.
İçe aktarmaların nasıl çalışacağına karar verin
Küçük dosyalar senkron (yükleme → doğrula → uygula) olarak çalışabilir ve hızlı bir kullanıcı deneyimi sağlar. Daha büyük dosyalar için işi arka plan işlerine taşıyın:
- upload → iş kuyruğuna ekle → ilerleme/geçmiş göster → tamamlanınca bildirim
Bu, yeniden denemeler ve hız sınırlı yazma için de hazır olmanızı sağlar.
Çok kiracılı mı tek kiracılı mı?
SaaS inşa ediyorsanız, tenant verilerini (satır düzeyinde kapsam, ayrı şemalar veya ayrı veritabanları) nasıl ayıracağınıza erken karar verin. Bu seçim veri dışa aktarma API’nizi, izinleri ve performansı etkiler.
Şimdiden belgeleyin: fonksiyonel olmayan gereksinimler
Çalışma süresi hedefleri, maksimum dosya boyutu, bir içe aktarmadaki beklenen satır sayısı, tamamlanma süresi ve maliyet sınırlarını yazın. Bu sayılar iş kuyruğu seçimini, partileme stratejisini ve indekslemeyi UI’yi cilalamadan çok önce yönlendirir.
İçe aktarma kabul (intake) akışını kurun
Kabul akışı her içe aktarmanın tonunu belirler. Eğer tahmin edilebilir ve affedici hissediyorsa, bir şeyler ters gittiğinde kullanıcılar tekrar deneyecektir—destek talepleri azalır.
Giriş noktaları: UI yükleme ve API
Web UI için sürükle-bırak alanı ve klasik dosya seçimci sunun. Sürükle-bırak güç kullanıcılar için daha hızlıdır; dosya seçimci daha erişilebilir ve tanıdıktır.
Müşterileriniz verilerini başka sistemlerden alıyorsa bir API uç noktası da ekleyin. Bu multipart yüklemeleri (dosya + meta) kabul edebilir veya büyük dosyalar için ön-imzalı URL akışı kullanabilirsiniz.
Güvenli ayrıştırma: başlıklar, kodlamalar ve örnekleme
Yüklemede, veriyi commit etmeden hafif bir ayrıştırma yaparak bir “önizleme” oluşturun:
- Başlıkları algılayın ve bir örnek satır gösterin (örn. ilk 20–100)
- Yaygın kodlamaları (UTF‑8, UTF‑16) ve ayırıcıları (virgül, tab, noktalı virgül) ele alın
- Yeni satırları normalize edin ve bariz biçimleme sorunlarını kırpın
Bu önizleme, sonraki adımlarda sütun eşleme ve doğrulama için temel olur.
Sorunsuz inceleme için orijinal dosyayı saklayın
Orijinal dosyayı güvenli şekilde (object storage tipik) her zaman saklayın. Bunu değiştirilemez tutun, böylece:
- Doğrulama kurallarınız değiştiğinde içe aktarmayı yeniden çalıştırabilirsiniz
- Hataları aynı girdiyi kullanarak araştırabilirsiniz
- İçe aktarma geçmişinden “orijinali indir” seçeneği sunabilirsiniz
Başlangıçtan itibaren meta veriyi yakalayın
Her yüklemeyi ilk sınıf bir kayıt olarak ele alın. Yükleyen, zaman damgası, kaynak sistem, dosya adı ve checksum gibi meta verileri kaydedin (çoğaltmaları tespit etmek ve bütünlük sağlamak için). Bu, denetlenebilirlik ve hata ayıklama için değer taşır.
Kullanıcı zamanı harcamadan önce hızlı kontroller
Hızlı ön kontrolleri hemen çalıştırın ve gerekirse erken başarısız olun:
- Dosya türü ve boyut limitleri
- Temel okunabilirlik (ayrıştırabiliyor muyuz?)
- Gerekli sütunların varlığı (içe aktarma türünüze göre)
Ön kontrol başarısızsa, kullanıcılara net bir mesaj dönün ve neyi düzeltmeleri gerektiğini gösterin. Hedef, gerçekten kötü dosyaları hızlıca durdurmak; daha sonra eşlenebilecek ve temizlenebilecek geçerli ama kusurlu verileri engellememektir.
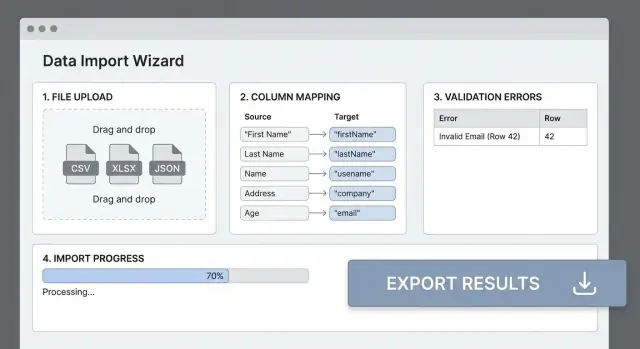
Sütun eşleme ve dönüşümleri ekleyin
Çoğu içe aktarma hatası, dosyanın başlıklarının uygulamanızın alanlarıyla eşleşmemesinden kaynaklanır. Net bir sütun eşleme adımı “dağınık CSV”yi tahmin edilebilir girdiye çevirir ve kullanıcıları deneme-yanılma döngüsünden kurtarır.
İnsanların anlayabileceği bir eşleme UI’sı
Basit bir tablo gösterin: Kaynak sütun → Hedef alan. Olası eşlemeleri otomatik algılayın (büyük/küçük harfe duyarsız başlık eşleştirme, “E-mail” → email gibi eşanlamlılar), ancak kullanıcıların her zaman üzerine yazmasına izin verin.
Bazı kullanılabilirlik dokunuşları ekleyin:
- Zorunlu hedef alanları işaretleyin ve eşlenip eşlenmediğini gösterin
- İlgisiz veriler için “Bu sütunu yoksay” seçeneği verin
- Kullanıcıların hiçbir şeyi kaçırmaması için eşlenmemiş sütunları vurgulayın
Kaydedilmiş eşleme şablonları (müşteri veya veri seti bazında)
Müşteriler aynı formatı her hafta içe aktarıyorsa, tek tıkla bunu sağlayın. Şablonları şu kapsamlarda kaydetmelerine izin verin:
- bir müşteri/hesap
- bir veri seti/türü (örn. Contacts vs. Invoices)
- isteğe bağlı olarak belirli bir entegrasyon veya kaynak sistemi
Yeni bir dosya yüklendiğinde sütun örtüşmesine göre bir şablon önerin. Ayrıca versiyonlamayı destekleyin ki kullanıcılar bir şablonu güncelleyip eski çalışmaları bozmasın.
Dönüşümler: veriyi şemanıza uydurun
Her eşlenen alan için uygulanabilecek hafif dönüşümler ekleyin:
- boşlukları kırpma; boş stringleri null’a çevirme
- tarih ayrıştırma (MM/DD/YYYY vs. DD.MM.YYYY) ve zaman dilimi seçenekleri
- para birimi normalizasyonu (örn. “$1,200.00” → 1200.00 + currency)
- enum’lar (örn. “Active”, “enabled”, “1” → ACTIVE)
- alan bölme/birleştirme (Full Name → First/Last veya tersi)
UI’da dönüşümlerin açıkça gösterilmesini sağlayın (“Uygulandı: Trim → Parse Date”) ki çıktı izah edilebilir olsun.
İşlemeye başlamadan önce önizleme
Tam dosyayı işlemeye başlamadan önce (ör. 20 satır için) eşlenmiş sonuçların önizlemesini gösterin. Orijinal değeri, dönüşmüş değeri ve uyarıları (ör. “Tarih ayrıştırılamadı”) gösterin. Burada kullanıcılar sorunları erken yakalar.
Çoğaltmaları ve anahtar alanları tespit edin
Kullanıcılardan bir anahtar alan (email, external_id, SKU) seçmelerini isteyin ve çoğaltmalarda ne olacağına dair açıklama yapın. Upsert’leri daha sonra işleseniz bile, bu adım beklentileri belirler: çoğalt anahtarları dosyada uyarı verir ve hangi kaydın “kazandığını” (ilk, son veya hata) önerir.
Doğrulama sistemini tasarlayın
Doğrulama, “dosya yükleyici” ile kullanıcının güvenebileceği bir içe aktarma özelliği arasındaki farktır. Amaç, katı olmak için katılaşmak değil—kötü verinin yayılmasını önleyip kullanıcılara net, uygulanabilir geri bildirim vermektir.
Doğrulamayı katmanlara ayırın
Doğrulamayı üç ayrı kontrol olarak ele alın, her biri farklı amaç taşır:
- Şema doğrulaması (tipler & zorunlu alanlar): “
emailbir string mi?”, “amountbir sayı mı?”, “customer_idvar mı?” Bu hızlıdır ve ayrıştırmadan hemen sonra çalıştırılabilir. - İş kuralları: “Tutar pozitif olmalı”, “Durum Active/Paused arasında olmalı”, “Başlangıç tarihi geçmişte olamaz.” Bunlar ürününüzün nasıl çalıştığını yansıtır.
- Alanlar arası ve ilişkisel kurallar: “Eğer
country=USisestatezorunlu”, “end_datestart_date’den sonra olmalı”, “Plan adı bu workspace’te var olmalı.” Bunlar genellikle bağlam (diğer sütunlar veya DB lookupları) gerektirir.
Bu katmanları ayrı tutmak sistemi genişletmeyi ve UI’da açıklamayı kolaylaştırır.
Katı vs esnek mod (ve neden önemli)
Erken karar verin: bir içe aktarma:
- Tüm dosyayı başarısız kılar (katı mod): finansal veriler, izinler veya kısmi güncellemelerin riskli olduğu durumlar için uygundur.
- Geçerli satırları kısmen kabul eder (esnek mod): büyük listelerde kullanıcıların sadece hatalı satırları düzeltmesini beklemeniz durumunda uygundur.
Her ikisini de sunabilirsiniz: varsayılan olarak katı, yöneticiler için “kısmi içe aktarmaya izin ver” seçeneği gibi.
İnsan dostu hatalar (satır/sütun referanslı)
Her hata şu soruyu yanıtlamalı: ne oldu, nerede oldu ve nasıl düzeltilir?
Örnek: “Satır 42, ‘Start Date’ sütunu: YYYY-MM-DD formatında geçerli bir tarih olmalı.”
Ayrımı yapın:
- Hatalar: o satırı (veya katı moddaysa tüm dosyayı) engeller
- Uyarılar: kabul edilir ama vurgulanır (örn. “Bilinmeyen departman; boş bırakılacak”)
“Düzelt ve tekrar yükle” döngülerini kolaylaştırın
Kullanıcılar nadiren her şeyi tek seferde düzeltir. Doğrulama sonuçlarını bir içe aktarma denemesine bağlayarak yeniden yüklemeyi kolaylaştırın. Bu işlemi toplu çözmek için indirilebilir hata raporlarıyla eşleştirin (aşağıda detaylandırılmıştır).
Kurallar motoru: gerektiğinde yapılandırılabilir, çekirdek için kod tabanlı
Pratik bir yaklaşım hibrittir:
- Yapılandırılabilir kurallar tenant’a özgü ihtiyaçlar için (örn. “Çalışan ID bu workspace içinde benzersiz olmalı”).
- Kod tanımlı kurallar çekirdek ürün invariants için (örn. izin sınırları, zorunlu ilişkiler) ki yanlış yapılandırma engellenmiş olsun.
Bu, doğrulamayı esnek tutarken onu hata ayıklaması zor bir “ayarlar labirentine” dönüştürmez.
Güvenilir işleme ve yeniden denemeler uygulayın
Daha İyi Hata Raporlaması Gönderin
Kullanıcıların filtreleyip düzeltebileceği yapılandırılmış hatalarla bir import geçmişi UI oluşturun.
İçe aktarmalar sık sık sıkıcı nedenlerle başarısız olur: yavaş DB, pik zamanlarda dosya dalgalanmaları veya tek bir “kötü” satır tüm iş akışını bloke edebilir. Güvenilirlik çoğunlukla ağır işi istek/yanıt yolundan çıkarmak ve her adımı tekrar güvenle çalıştırılabilir yapmakla ilgilidir.
Büyük dosyalar için arka plan işleri kullanın
Ayrıştırma, doğrulama ve yazma işlemlerini arka plan işleri (kuyruk/worker) içinde çalıştırın ki uploadlar web zaman aşımına takılmasın. Bu ayrıca müşteriler daha büyük tablolar içe aktarmaya başladığında işçi ölçeklendirmeyi mümkün kılar.
Pratik bir desen: işi parçalara bölün (ör. 1.000 satır/satır grubu). Bir “ebeveyn” import işi parça işlerini planlar, sonuçları toplar ve ilerlemeyi günceller.
Net durumlar ve geçişler takip edin
Import’u bir durum makinesi olarak modelleyin ki UI ve operasyon ekibi her zaman ne olduğunu bilsin:
- queued → running → completed
- queued/running → failed (neden ile)
- queued/running → canceled (kullanıcı veya sistem tarafından)
Her durum geçişi için zaman damgası ve deneme sayısı saklayın ki “ne zaman başladı?” ve “kaç deneme oldu?” gibi sorulara loglarda boğulmadan cevap verilebilsin.
Kullanıcıların güvenebileceği ilerleme gösterimi
İşlenmiş satır sayısı, kalan satırlar ve şu ana kadar bulunan hatalar gibi ölçülebilir ilerleme gösterin. Eğer throughput tahmini verebiliyorsanız kaba bir ETA ekleyin—tam bir geri sayımdan ziyade “~3 dk” gibi yaklaşık değerleri tercih edin.
İşlemeyi idempotent yapın (yeniden denemeye uygun)
Yeniden denemeler asla çoğaltma veya çift uygulama yaratmamalı. Yaygın teknikler:
- import_id + row_number (veya satır hash) gibi kararlı idempotency anahtarları kullanın
- external_id gibi doğal anahtarla upsert yapın, "her zaman insert" yerine
- Parça başına transaction kullanın ki kısmi hatalar durumu bozmasın
Herkesi korumak için hız sınırlama (throttling)
Workspace başına eşzamanlı içe aktarmaları sınırlayın ve veritabanını ezmemek için yazma-ağır adımları (örn. saniyede maksimum N satır) hız sınırlayın.
Hata raporlaması ve import geçmişi
İnsanlar neyin yanlış gittiğini anlayamazsa aynı dosyayı tekrar tekrar denerler. Her içe aktarmayı birinci sınıf “çalıştırma” olarak ele alın ve net bir iz kaydı ile uygulanabilir hatalar sunun.
Bir import run kaydı oluşturun
Dosya gönderildiğinde hemen bir import run varlık kaydı oluşturun. Bu kayıt şunları içermeli:
- Kim başlattı (kullanıcı + organizasyon)
- Ne yüklendi (kaynak dosya adı, boyut, checksum, varlık türü)
- Ne zaman oldu (başlangıç/bitiş zaman damgaları)
- Nasıl yorumlandı (kullanılan eşleme yapılandırması, dönüşüm versiyonu)
- Sonuç (başarılı/başarısız/kısmi, işlenen satır sayısı, reddedilen satırlar)
Bu, import geçmişi ekranınız olur: durum, sayılar ve “detayları görüntüle” linkli basit bir çalıştırma listesi.
Satır düzeyinde hataları saklayın (sadece log değil)
Uygulama logları mühendisler için iyidir; fakat kullanıcıların sorgulayabileceği yapılandırılmış hatalara ihtiyacı vardır. Hataları import run’a bağlı yapısal kayıtlar olarak saklayın, ideal olarak iki seviyede:
- Satır düzeyinde: satır numarası, birincil tanımlayıcı (varsa), ham değerlerin anlık görüntüsü
- Alan düzeyinde: sütun adı, hata kodu (örn. REQUIRED, INVALID_DATE), insan mesajı, önem seviyesi
Bu yapı hızlı filtreleme ve haftalık “En çok görülen 3 hata tipi” gibi özetler üretmenize olanak verir.
Hataları kullanılabilir kılın: UI + indirilebilir rapor
Çalıştırma detayları sayfasında tip, sütun ve önem bazlı filtreler ve bir arama kutusu (örn. “email”) sağlayın. Ardından orijinal satırı ve error_columns, error_message gibi ekstra sütunları içeren indirilebilir CSV hata raporu sunun; “Tarih formatını YYYY-MM-DD olarak düzeltin” gibi açık yönergeler ekleyin.
Bir dry run modu ekleyin
“Dry run” modu, aynı eşleme ve kuralları kullanarak her şeyi doğrular ama veri yazmaz. İlk defa yapılan içe aktarmalar için idealdir ve kullanıcıların commit etmeden önce güvenle yineleme yapmasına izin verir.
Veri modeli, upsert'ler ve denetlenebilirlik
Çalışan Bir Temelden Başlayın
Hemen çalışan bir veri içe aktarma web uygulaması oluşturun, sonra adım adım eşleme ve dönüşümleri iyileştirin.
Satırlar veritabanınıza indiğinde iş “tamam” gibi görünür—ama uzun vadeli maliyet genelde dağınık güncellemeler, çoğaltmalar ve belirsiz değişiklik geçmişinde çıkar. Bu bölüm, içe aktarmaların öngörülebilir, geri alınabilir ve açıklanabilir olmasını sağlayacak veri modelini tasarlamaya odaklanır.
Oluşturma mı, güncelleme mi yoksa her ikisi mi?
Her varlık için içe aktarılan bir satırın domain modelinize nasıl eşleneceğini tanımlayın. Her varlık için içe aktarma şu işlemleri yapabilir mi:
- Sadece yeni kayıt oluşturma
- Sadece mevcut kayıtları güncelleme
- Her ikisi (yaygın SaaS durumu)
Bu karar import kurulum UI’sında açıkça gösterilmeli ve davranış iş ile birlikte saklanmalıdır ki tekrar edilebilir olsun.
Upsert anahtarlarını ve çakışma kurallarını seçin
“Create or update” destekliyorsanız stabil upsert anahtarlarına ihtiyacınız var—aynı kaydı her defasında tanımlayan alanlar. Yaygın seçimler:
external_id(başka bir sistemden geliyorsa en iyisi)- Email (kullanıcılar/kişiler için çalışır ama değişebilir)
- Kompozit anahtarlar (örn.
account_id + sku)
Çakışma durumunda ne yapılacağını tanımlayın: iki satır aynı anahtarı paylaşıyorsa veya anahtar birden fazla kayıtla eşleşiyorsa ne olacak? İyi varsayılanlar “satırı açık bir hata ile başarısız kıl” veya “son satır kazanır” şeklindedir; bilinçli seçim yapın.
Dünya çapında kilitlemeden transaction kullanın
Tutarlılığı koruyan yerlerde transaction kullanın (örn. bir ebeveyn ve onun çocuklarını oluştururken). 200k satırlık bir dosya için tek büyük transaction kullanmaktan kaçının; tabloları kilitleyebilir ve yeniden denemeleri zorlaştırır. Bunun yerine parça yazma (ör. 500–2.000 satır) ve idempotent upsert’ler tercih edin.
Referans bütünlüğünü koruyun
Bir satır bir ebeveyn kayda referans veriyorsa (ör. Company), ya onun var olmasını zorunlu kılın ya da kontrollü bir adımda oluşturun. “Eksik ebeveyn” hatalarıyla erken başarısız olmak yarım bağlı veriyi önler.
İçe aktarmaların yaptığı değişiklikleri denetleyin
İçe aktarma kaynaklı değişiklikler için denetim kayıtları ekleyin: kim import’u tetikledi, ne zaman, kaynak dosya, ve her kayıt için özet değişiklik (eski vs yeni). Bu destek işini kolaylaştırır, kullanıcı güveni sağlar ve rollbackleri basitleştirir.
Ölçeklenen dışa aktarmalar inşa edin
Dışa aktarmalar basit görünür ama müşteriler bir teslim tarihinden hemen önce “her şeyi” indirmeye çalışınca sorun ortaya çıkar. Ölçeklenebilir bir dışa aktarma sistemi büyük veri setlerini uygulamanızı yavaşlatmadan veya tutarsız dosyalar üretmeden işlemelidir.
Doğru dışa aktarma türlerini sunun
Üç seçenekle başlayın:
- Tam dışa aktarma: kullanıcının erişebildiği her şey.
- Filtrelenmiş dışa aktarma: UI’daki aynı filtreleri/arama kriterlerini uygular (durum, tarih aralığı, sahibi vb.).
- Artımlı dışa aktarma: “X tarihinden sonra değişiklikler” senaryoları için.
Artımlı dışa aktarmalar entegrasyonlar için özellikle faydalıdır ve tekrar eden tam dökümler yerine daha düşük yük sağlar.
Gerçek kullanım için formatları seçin
- CSV: hesap tabloları ve toplu analiz için varsayılan.
- JSON: veri dışa aktarma API’si ve otomasyon için en uygunu.
- Excel: yalnızca çok sayıda sayfa, zengin biçimlendirme veya teknik olmayan iş akışları gerektiğinde.
Seçiminiz ne olursa olsun, tutarlı başlıklar ve stabil sütun sırası sağlayın ki downstream süreçler bozulmasın.
Bellek sıçramalarını önlemek için akış ve sayfalama kullanın
Büyük dışa aktarmalar tüm satırları belleğe yüklememeli. Satırları alırken yazmak için sayfalama/streaming kullanın. Bu zaman aşımını önler ve web uygulamanızı duyarlı tutar.
Büyük dışa aktarmaları asenkron üretin
Büyük veri setleri için dışa aktarmaları arka plan işinde oluşturun ve hazır olduğunda kullanıcıyı bilgilendirin. Yaygın desen:
- Kullanıcı dışa aktarma talep eder.
- Uygulama bir işi kuyruğa alır.
- İş dosyayı object storage’a yazar.
- UI indirme linkini gösterir ve bunu dışa aktarma geçmişinde tutar.
Bu, hata raporları ve içe aktarmalar için kullandığınız aynı “çalıştırma geçmişi + indirilebilir artefakt” desenleriyle iyi eşleşir.
Tarihler, zaman dilimleri ve biçimlendirmayı doğru yapın
Dışa aktarmalar sık sık denetlenir. Her zaman şunları dahil edin:
- Açık bir zaman dilimi politikası (örn. UTC’de sakla, kullanıcının zaman diliminde dışa aktar)
- Tutarlı tarih biçimlendirmesi (JSON için ISO-8601; CSV/Excel için açık formatlar)
- Bir “oluşturulma zamanı” damgası ve artımlı dışa aktarmalar için kesme zamanı
Bu ayrıntılar kafa karışıklığını azaltır ve güvenilir uzlaştırma sağlar.
Güvenlik, izinler ve veri gizliliği
İçe/dışa aktarmalar çok veri taşıyabildiği için güçlü bir güvenlik yüzeyi gerektirir. Bu aynı zamanda sıkça yapılan güvenlik hatalarının olduğu yerdir: fazla geniş rol, sızan dosya URL’si veya log’larda kazara kişisel veriler.
Kimlik doğrulama: ürün kullanım şekline uygun olanı seçin
Uygulamanızdaki genel kimlik doğrulamayı kullanın—içe/dışa aktarmalar için özel bir auth yolu oluşturmayın.
Tarayıcı tabanlı kullanıcılar için oturum tabanlı auth (ve isteğe bağlı SSO/SAML) en uygun olabilir. Otomatikleştirilmiş importlar/entegre job’lar için API anahtarları veya OAuth token’ları, net kapsam ve rotasyon ile düşünülmelidir.
Pratik kural: import UI ve import API aynı izinleri uygulamalı, farklı kitleler tarafından kullanılsalar bile.
Rol tabanlı erişim: kim ne yapabilir belirleyin
İçe/dışa aktarma yeteneklerini açık ayrı ayrı ayrıcalıklar olarak ele alın. Yaygın roller:
- İçe aktarabilir (dosya yükle, import çalıştır)
- Dışa aktarabilir (dışa aktarma oluştur/indir)
- Geçmişi görüntüleyebilir (import run’ları, hatalar, sayılar)
- Dosya indirebilir (orijinal yüklemeler, hata raporları)
“Dosya indirme” iznini ayrı tutun. Birçok hassas sızıntı, biri run’ı görebiliyorken sistemin otomatik olarak indirme yetkisi verdiği varsayıldığı durumlarda olur.
Ayrıca satır/tenant düzey sınırlarını düşünün: bir kullanıcı yalnızca ait olduğu hesap/çalışma alanı için veri içe/dışa aktarmalı.
Hassas veriyi uçtan uca koruyun
Saklanan dosyalar (yüklemeler, oluşturulan hata CSV’leri, dışa aktarma arşivleri) için özel object storage ve kısa ömürlü indirme linkleri kullanın. Uyumluluk gerekiyorsa dinlenme halindeyken şifreleme kullanın ve tutarlı olun: orijinal yükleme, işlenmiş ara dosya ve üretilen raporlar aynı kuralları takip etmelidir.
Log’lara dikkat edin. Hassas alanları (e-postalar, telefon numaraları, kimlikler, adresler) maskeleyin ve ham satırları varsayılan olarak loglamayın. Gerekirse hata ayıklamada “detaylı satır loglamayı” sadece yöneticiler için bir ayar arkasına alın ve süreli temizlenmesini sağlayın.
İşlemeden önce yüklemeleri doğrulayın ve tarayın
Her yüklemeyi doğrulanmamış girdi olarak değerlendirin:
- Dosya türü kontrolleri uygulayın (sadece dosya adlarına güvenmeyin)
- Boyut limitleri koyun (DoS ve kazara devasa yüklemeleri önlemek için)
- Risk/iş sektörünüz gerektiriyorsa kötü amaçlı yazılım taraması düşünün
Ayrıca yapıyı erken doğrulayın: bariz bozuk dosyaları arka plan işlerine ulaşmadan reddedin ve kullanıcıya neyin yanlış olduğunu açıkça bildirin.
Güvenlikle ilgili olaylar için denetim izleri
Soruşturma esnasında gereken olayları kaydedin: kim dosya yükledi, kim import başlattı, kim dışa aktarma indirdi, izin değişiklikleri ve başarısız erişim girişimleri.
Denetim girdileri actor, zaman damgası, workspace/tenant ve etkilenen nesneyi (import run ID, export ID) içermeli, hassas satır verilerini saklamamalıdır. Bu, import geçmiş UI’siyle iyi çalışır ve “kim ne zaman neyi değiştirdi?” sorusuna hızlı cevap verir.
Test, izleme ve işletilebilirlik
İnşa Etmeden Dağıtıma Geçin
Ek araçları birleştirmeden içe/dışa aktarma uygulamanızı dağıtın ve barındırın.
İçe/dışa aktarmalar müşteri verisine dokunuyorsa er ya da geç uç durumlarla karşılaşırsınız: garip kodlamalar, birleştirilmiş hücreler, yarım dolu satırlar, çoğaltmalar ve “dün çalışıyordu” gizemleri. İşletilebilirlik bu sorunların destek kabusuna dönüşmesini engeller.
Gerçek dosyaları andıran testler
En çok hata veren bölümlere odaklanan testlerle başlayın: ayrıştırma, eşleme ve doğrulama.
- Ayrıştırma testleri: farklı ayırıcılar, tarih formatları, boş sütunlar, büyük sayılar, UTF‑8 vs Windows-1252 gibi temsil eden CSV/XLSX fixture’ları kullanın. Satır sayıları ve ana alanların doğru ayrıştığını doğrulayın.
- Eşleme + dönüşüm testleri: verilen bir giriş sütun kümesi için uygulamanın doğru iç alanlara eşlediğini ve dönüşümleri uyguladığını doğrulayın (trim, case normalization, para birimi dönüşümü).
- Doğrulama kural testleri: her kural için “iyi” ve “kötü” satırlar ekleyin ve tam hata kodu/mesajını assert edin.
Sonra en az bir uçtan uca test ekleyin: upload → arka plan işleme → rapor üretimi. Bu testler UI, API ve worker’lar arasındaki sözleşme uyuşmazlıklarını yakalar.
Ne bozuldu sorusunu yanıtlayan izleme
Kullanıcı etkisini yansıtan sinyalleri izleyin:
- İş hataları (sayı ve oran)
- İşleme süresi (p50/p95)
- Doğrulama hata oranı (ani sıçramalar genelde bir şablon değişikliğine işaret eder)
- Kuyruk derinliği ve worker throughput
Uyarıları semptomlara (artmış hata oranı, büyüyen kuyruk) bağlayın; her exception için alarm kurmak yerine gerçek kullanıcı etkisini hedefleyin.
Yönetici araçları ve kullanıcı yardımı
İç ekiplerin işleri yeniden çalıştırması, takılı içe aktarmaları iptal etmesi ve hataları incelemesi için küçük bir admin yüzeyi sağlayın (giriş dosyası meta verisi, kullanılan eşleme, hata özeti ve log/trace bağlantıları).
Kullanıcılar için önlenebilir hataları azaltmak adına inline ipuçları, indirilebilir örnek şablonlar ve hata ekranlarında net sonraki adımlar sağlayın. İçe aktarma UI’sından merkezi bir yardım sayfasına (örn. /docs) link verin.
Dağıtım, açılış ve gelecekteki geliştirmeler
İçe/dışa aktarma sistemi "prod'a gönder" ile bitmez. Bunu güvenli varsayılanlar, net kurtarma yolları ve gelişmeye alan bırakan bir ürün özelliği olarak ele alın.
Ortamlar: dev, staging, prod
Geliştirme/staging/üretim için ayrı ortamlar kurun ve yüklenen dosyalar ile oluşturulan dışa aktarmalar için ayrı object storage bucket’ları (veya prefix’leri) kullanın. Her ortam için farklı şifreleme anahtarları ve kimlik bilgileri kullanın ve arka plan işçilerinin doğru kuyruğa işaret ettiğinden emin olun.
Staging, production ile aynısını yansıtmalı: aynı iş eşzamanlılığı, zaman aşımı ve dosya boyutu limitleri. Performans ve izinleri gerçek müşteri verisi riski olmadan burada doğrulayın.
Migrasyonlar ve versiyonlanmış şablonlar
İçe aktarmalar "sonsuz" yaşama eğilimindedir çünkü müşteriler eski spreadsheet’leri tutar. DB migrasyonlarını olağan şekilde kullanın, ancak import şablonlarını versiyonlayın ki bir şema değişikliği geçen çeyreğin CSV’sini bozmasın.
Pratik yaklaşım: her import run ile template_version saklayın ve eski sürümler için uyumluluk kodunu, deprecate edene kadar koruyun.
Özellik bayrakları ile güvenli açılış
Değişiklikleri güvenle göndermek için feature flag kullanın:
- Yeni doğrulama kuralları (önce uyarı modu, sonra hata)
- Yeni dışa aktarma formatları (örn. CSV yanına JSON eklemek)
- Yeni eşleme seçenekleri (örn. “Full name” sütununu bölme)
Bayraklar, değişiklikleri önce dahili kullanıcılarda veya küçük müşteri gruplarında test etmenizi sağlar.
Destek iş akışları ve teşhis
Destek ekibinin hataları nasıl inceleyeceğini belgeleyin: import geçmişi, iş ID’leri ve log’lar kullanılarak bir kontrol listesi: şablon versiyonunu doğrula, ilk hatalı satırı incele, storage erişimini kontrol et, sonra worker log’larına bak. Bu kontrol listesini dahili runbook’unuza ve uygun yerlerde admin UI’ye bağlayın (örn. /admin/imports).
İleri adımlar: entegrasyonlar
Çekirdek akış kararlı hale geldikten sonra onu yüklemelerin ötesine genişletin:
- Otomatik pipeline’lar için API tabanlı içe aktarmalar
- “İçe aktarma tamamlandı” veya “dışa aktarma hazır” olayları için webhook’lar
- Google Sheets, S3, Snowflake gibi yaygın araçlar için konektörler
Bu gelişmeler manuel işi azaltır ve veri içe aktarma web uygulamanızın müşterilerin mevcut süreçlerinde doğal hissetmesini sağlar.
Eğer bunu bir ürün özelliği olarak inşa ediyorsanız ve “ilk kullanılabilir sürüm” zamanını kısaltmak istiyorsanız, Koder.ai kullanarak import sihirbazı, iş durum sayfaları ve çalıştırma geçmişi ekranlarını uçtan uca prototiplemeyi, sonra kaynak kodunu geleneksel mühendislik iş akışına aktarmayı düşünebilirsiniz. Bu yaklaşım, ilk günün mükemmel UI tasarımından çok güvenilirlik ve yineleme hızını önemsediğiniz durumlarda özellikle pratiktir.
SSS
Bir içe/dışa aktarma özelliği inşa etmeden önce neyi tanımlamalıyım?
Öncelikle kimi içe/dışa aktarım yapacağını (yöneticiler, operatörler, müşteriler) ve başlıca kullanım durumlarını (onboarding sırasında toplu yükleme, periyodik senkronizasyon, tek seferlik dışa aktarma) netleştirin.
Gün 1 kısıtlarını yazın:
- Desteklenen formatlar (CSV/XLSX/JSON)
- Dosya boyutu + satır limitleri
- Kodlama/zaman dilimi kuralları
- Uyum gereksinimleri (KİB, saklama, denetim)
Bu kararlar mimariyi, UI karmaşıklığını ve destek yükünü şekillendirir.
İçe aktarımlar ne zaman senkronize, ne zaman arka planda çalıştırılmalı?
Dosyalar küçükse ve doğrulama + yazma işlemleri web isteği zaman aşımı içinde güvenli şekilde tamamlanıyorsa senkron işleme kullanın.
Arka plan işleri kullanın when:
- Dosyalar büyük veya dalgalıysa
- Yeniden deneme, hız sınırlama veya parçalı yazma gerekiyorsa
- İlerleme takibi ve bildirim istiyorsanız
Yaygın desen: upload → kuyruğa al → çalıştırma durumu/ilerleme göster → tamamlandığında bildirim gönder.
Ham yüklenen dosyaları normalize edilmiş veritabanı kayıtlarından neden ayırmalıyım?
Her iki şeyi de saklayın, farklı amaçlar için:
- Ham dosya (object storage): yeniden üretilebilirlik, destek için hata incelemesi, işleri yeniden çalıştırma, “orijinali indir” seçeneği.
- Normalize edilmiş kayıtlar (relational DB): upsert, kısıtlar, sorgulama, denetim kayıtları.
Ham yüklemeyi değiştirilemez tutun ve bir import run kaydıyla ilişkilendirin.
Güvenli ve kullanıcı dostu bir içe aktarma giriş akışı nasıl tasarlanmalı?
Herhangi bir şeyi kalıcı hale getirmeden önce başlıkları algılayan ve küçük bir örneği (ör. 20–100 satır) parse eden bir önizleme adımı oluşturun.
Yaygın değişkenlikleri ele alın:
- Kodlamalar (UTF-8/UTF-16)
- Ayırıcılar (virgül/tab/noktalı virgül)
- Yeni satırlar ve gereksiz boşluklar
Gerçek engelleyicilerde hızlıca başarısız olun (okunamayan dosya, eksik zorunlu sütunlar), ancak daha sonra eşlenebilecek veya dönüştürülebilecek verileri reddetmeyin.
CSV/Excel içe aktarımları için iyi bir sütun eşleme UI'sı nasıl olmalı?
Basit bir eşleme tablosu kullanın: Kaynak sütun → Hedef alan.
En iyi uygulamalar:
- Otomatik öneriler (büyük/küçük harfe duyarsız + eşanlamlılar), ama kullanıcıların üzerine yazmasına izin verin
- Zorunlu alanları işaretleyin ve eksik eşlemeleri vurgulayın
- “Bu sütunu yoksay” desteği verin
- Hesap/ veri türü başına eşleme şablonları sağlayın ve versiyonlayın
Her zaman tam dosyayı işlemeye başlamadan önce eşlenmiş bir önizleme gösterin.
Hangi veri dönüşümleri erken dönemde desteklenmeli?
Dönüşümleri hafif tutun ve kullanıcıya ne yapıldığını açıkça gösterin:
- Boşlukları kırpma / büyük-küçük harf normalizasyonu
- Boş string → null
- Tarih ayrıştırma, açık format + zaman dilimi politikası
- Enum normalizasyonu (ör. “enabled/1/Active” →
ACTIVE) - Alanları bölme/birleştirme (Full Name ↔ First/Last)
Önizlemede “orijinal → dönüşmüş” gösterin ve dönüşüm uygulanamazsa uyarıları belirginleştirin.
İçe aktarma doğrulaması nasıl yapılandırılmalı?
Doğrulamayı katmanlara ayırın:
- Şema: zorunlu alanlar, tipler
- İş kuralları: alanlara özgü kısıtlar (pozitif tutar, izin verilen durumlar)
- İlişkisel/alanlar arası: bağımlılıklar, lookup’lar, yabancı anahtarlar
UI’da satır/sütun referanslı, düzeltilebilir mesajlar sağlayın (ör. “Satır 42, Start Date: YYYY-MM-DD olmalı”).
İçe aktarımların (tüm dosya başarısız olur) mı yoksa (geçerli satırlar kabul edilir) mi olacağını belirleyin; yöneticiler için her ikisini de sunmayı düşünün.
İçe aktarımları nasıl güvenilir, yeniden denenebilir ve idempotent yaparım?
İşlemleri yeniden denemeye uygun hale getirin:
- Kararlı bir idempotent anahtar kullanın (ör.
import_id + row_numberveya satır hash'i) - Doğal anahtarla upsert tercih edin (örn.
external_id) ve hep "insert" yapmayın
Hata raporlama ve import geçmişi için en iyi yaklaşım nedir?
Bir dosya sunulduğunda hemen bir import run kaydı oluşturun ve yapılandırılmış, sorgulanabilir hatalar saklayın—sadece uygulama logları değil.
Kullanışlı hata özellikleri:
- Satır düzeyinde + alan düzeyinde hatalar (kodlar, mesajlar, önem seviyesi)
- Sütun/tip/önem bazlı filtreler ve arama (örn. e-posta)
- Orijinal satırı ve hata kolonlarını içeren indirilebilen CSV hata raporu
- Yazmadan doğrulama yapan dry run modu
İçe/dışa aktarma sistemleri hangi güvenlik ve gizlilik kontrollerine ihtiyaç duyar?
İçe/dışa aktarma güçlü olduğu kadar risklidir—yanlış izin, sızmış dosya URL’si veya log’larda hassas veriler gibi.
Gerekli kontroller:
- UI ve API’de aynı izinleri uygulayın
- “Run görüntüleme” ile “dosya indirme” izinlerini ayrı tutun
- Özel object storage ve kısa ömürlü indirme linkleri kullanın
- Ham satırları loglamayın; hassas alanları maskeleyin
- Yükleyen, import başlatan, dışa aktarma indiren gibi güvenlikle ilgili olayları denetim kaydı olarak saklayın
KİB varsa, saklama ve silme kurallarını erken belirleyin.