14 Eyl 2025·8 dk
Veri Kalitesi Kontrolleri ve Uyarılar İçin Bir Web Uygulaması Nasıl Kurulur
Veri kalite kontrolleri çalıştıran, sonuçları izleyen ve sahiplik, günlükler ve panolarla zamanında uyarılar gönderen bir web uygulamasını nasıl planlayıp inşa edeceğinizi öğrenin.
Veri Kalitesinin Amaç ve Kapsamını Netleştirin
Herhangi bir şeyi inşa etmeden önce ekibinizin “veri kalitesi” derken gerçekte ne kastettiği konusunda uzlaşın. Bir web uygulaması olarak veri kalite izleme yalnızca herkesin korumak istediği çıktılar ve desteklemesi gereken kararlar üzerinde anlaşması halinde faydalı olur.
Kendi bağlamınızda “veri kalitesi”yi tanımlayın
Çoğu ekip birkaç boyutu harmanlar. Önemli olanları seçin, bunları sade bir dille tanımlayın ve bu tanımları ürün gereksinimi gibi ele alın:
- Doğruluk: değerler gerçeği yansıtır (ör. gelir rakamları kaynak sistemlerle tutarlı).\n- Tamlık: gerekli alanlar null değil; beklenen satırlar geldi.\n- Zamanında Olma: veri desteklediği kararlar için yeterince taze.\n- Benzersizlik: istenmeyen çoğaltmalar yok (müşteriler, siparişler, olaylar).
Bu tanımlar veri doğrulama kurallarının temelini oluşturur ve uygulamanızın hangi veri kalite kontrollerini desteklemesi gerektiğine karar vermenize yardımcı olur.
Kötü verinin risklerini gerçek kişilerle eşleyin
Kötü verinin risklerini ve etkilenenleri listeleyin. Örneğin:
- Finans yanlış rakamlarla kapanır → kontrolörler ve liderlik güven kaybeder.\n- Pazarlama yanlış segmente hedefler → bütçe boşa gider ve müşteriler rahatsız olur.\n- Operasyon güncel olmayan envanter verisi kullanır → gönderimler kaçırılır.
Bu, “ilginç” metrikleri takip eden ama işin gerçekten zararını gözardı eden bir araç inşa etmenizi önler. Ayrıca web uygulaması uyarılarının şeklini belirler: doğru mesaj doğru sahibine ulaşmalı.
Toplu vs gerçek zamanlı kontroller konusunda karar verin
Şu seçeneklerden hangisine ihtiyacınız olduğunu netleştirin:
- Toplu kontroller (ETL/ELT için yaygın): günlük/saatlik yüklemelerden sonra çalışır; ETL veri kalitesi geçitleri için ideal.\n- Gerçek zamanlı kontroller: olayları veya API yazımlarını geldikçe doğrular; sorunları hızla yakalamada faydalıdır.\n- Her ikisi: genellikle en pratik olanı—kritik akışlar için gerçek zamanlı, daha geniş kapsam için toplu.
Gecikme beklentilerini (dakikalar vs saatler) açıkça belirleyin. Bu karar zamanlama, depolama ve uyarı aciliyeti üzerinde etki yapar.
Takasları yönlendiren başarı metrikleri belirleyin
Uygulamayı yayına aldıktan sonra “daha iyi”yi nasıl ölçeceğinizi tanımlayın:
- Kötü veri kaynaklı üretim olaylarının azalması\n- Tespit ve çözüm süresinin kısalması\n- Daha düşük yanlış uyarı oranı (daha az gürültü)\n- Daha yüksek sahiplenme: uyarıların onaylanması ve çözülmesi
Bu metrikler veri gözlemlenebilirliği çabalarınızı odaklı tutar ve basit kural tabanlı doğrulama ile anomali tespiti temelleri arasındaki öncelikleri belirlemenize yardımcı olur.
Verilerinizi Envanterleyin ve İzlenecekleri Önceliklendirin
Kontrolleri oluşturmadan önce hangi verilere sahip olduğunuzu, nerede bulunduğunu ve bir şey bozulduğunda kimlerin düzeltebileceğini netleştirin. Hafif bir envanter şimdi haftalarca sürecek kafa karışıklığını önler.
Önce bir kaynak haritası oluşturun (ve gerçek sahipler atayın)
Verinin kaynaklandığı veya dönüştüğü her yeri listeleyin:
- Operasyonel veritabanları (Postgres/MySQL), analitik ambarları (BigQuery/Snowflake), olay akışları\n- Dosyalar ve ekstraktlar (S3/GCS, SFTP düşmeleri, CSV yüklemeleri)\n- Üçüncü taraf API'ler ve SaaS bağlayıcıları
Her kaynak için bir sahip (kişi veya ekip), Slack/e-posta irtibatı ve beklenen yenileme periyodunu kaydedin. Sahiplik belirsizse uyarılar da belirsiz olur.
“Ne neyi bozar” haritası çıkarın
Kritik tablolar/sütunları seçin ve bunlara kimlerin bağımlı olduğunu belgeleyin:
- Alt akış panoları (finans, büyüme, üst yönetim raporlaması)\n- Müşteriye dönük özellikler (öneriler, faturalama, bildirimler)\n- ML modelleri, atıf boru hatları ve ana metrikler
Basit bir bağımlılık notu, örn. orders.status → gelir paneli, başlamanız için yeterlidir.
İlk 5–10 kırılmaması gereken veri setini seçin
Etkilenme ve olasılığa göre öncelik verin:
- Yanlış olduğunda iş üzerinde büyük etki\n2. Sıklıkla değişen veya kırılmaya yatkın boru hatları\n3. Bozuk olduğunda fark edilmesi zor olanlar
Bunlar ilk izleme kapsamınızı ve ilk başarı metriklerinizi oluşturur.
Bugünün acı noktalarını kaydedin
Zaten hissettiğiniz belirli hataları belgeleyin: sessiz pipeline hataları, yavaş tespit, uyarılarda eksik bağlam ve belirsiz sahiplik. Bunları uyarı yönlendirme, denetim günlükleri ve araştırma görünümleri için somut gereksinimlere dönüştürün. Eğer kısa bir dahili sayfa tutuyorsanız (ör. /docs/data-owners), uygulamadan bu metni gösterin ki müdahale edenler hızlıca hareket edebilsin.
Uygulamanızın Destekleyeceği Kontrolleri Seçin
Ekranları tasarlamadan veya kod yazmadan önce ürününüzün hangi kontrolleri çalıştıracağını belirleyin. Bu seçim kural düzenleyicisini, zamanlamayı, performansı ve uyarılarınızın ne kadar eyleme dönüştürülebilir olacağını belirler.
Küçük, yüksek değerli bir katalogla başlayın
Çoğu ekip aşağıdaki temel kontrol türlerinden hemen değer elde eder:\n\n- Şema kontrolleri: beklenen sütunlar, veri tipleri, izin verilen enum değerleri.\n- Null oranı / tamlık: “email alanında %2'den fazla null olmasın.”\n- Değer aralıkları: “order_total 0 ile 10.000 arasında olmalı.”\n- Referans bütünlüğü: “her order.customer_id customers.id içinde olmalı.”\n- Tazelik: “tablo son 2 saatte güncellendi.”\n- Çoğaltımlar: “user_id günlük bazda benzersiz olmalı.”
İlk katalogu yönlendirici (opinionated) tutun. Niş kontrolleri daha sonra ekleyebilirsiniz, ama UI'ı karmaşık hale getirmeyin.
Kullanıcıların gerçekten yönetebileceği kural formatlarını seçin
Genelde üç seçenek vardır:
- UI tabanlı kurallar (açılır menüler + alanlar): teknik olmayan kullanıcılar için ve tutarlılık için en uygun.\n2. Şablonlar (“sütunda benzersizlik”, “tablo için tazelik”): hızlı kurulum ve kolay versiyonlama.\n3. Kod tabanlı kontroller (SQL veya küçük scriptler): en esnek olan, fakat korumalar gerekir.
Pratik bir yaklaşım “önce UI, kaçış kapağı sonra”dır: %80 için şablonlar ve UI kuralları sağlayın, geri kalan için özel SQL'e izin verin.
Şiddet ve tetik mantığını tanımlayın
Şiddeti anlamlı ve tutarlı kılın:\n\n- Bilgi (Info): alışılmadık ama acil değil (trendleri takip edin).\n- Uyarı (Warn): yakında ilgi gerektirir (ticket veya inceleme).\n- Kritik (Critical): muhtemelen alt akış raporlamasını veya operasyonu bozar (sayfa/paniğe neden olacak uyarı).
Tetikleyiciler konusunda açık olun: tek seferlik başarısızlık mı yoksa “ardışık N başarısızlık” mı, yüzdelere dayalı eşikler, ve isteğe bağlı bastırma pencereleri.
Güvenlik açığı yaratmadan özel kontroller için plan yapın
SQL/script destekliyorsanız, önceden karar verin: izin verilen bağlantılar, zaman aşımı, salt okunur erişim, parametreli sorgular ve sonuçların pass/fail + metriklere nasıl normalize edileceği. Bu, esnekliği korurken verinizi ve platformunuzu korur.
Kullanıcı Deneyimini ve Ana Akışları Tasarlayın
Bir veri kalite uygulaması, birinin üç soruya ne kadar çabuk cevap bulabildiğine bağlı olarak başarılı olur: ne başarısız oldu, neden önemli, ve sahibi kim. Kullanıcılar günlükleri kazmak veya şifreli kural isimleriyle uğraşmak zorunda kalırsa uyarıları görmezden gelir ve araca güvenmeyi bırakır.
Asgari kullanılabilir ekranlar (tamamlanmış hissettiren)
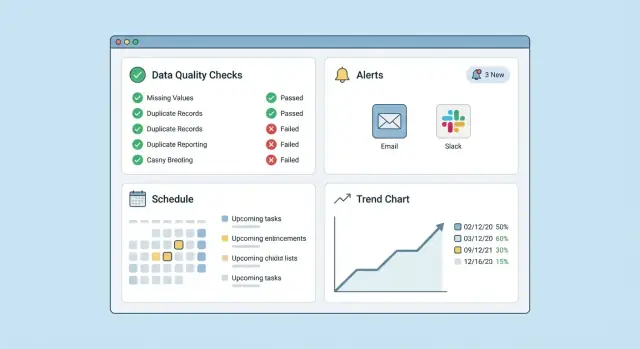
Uçtan uca yaşam döngüsünü destekleyen küçük bir ekran seti ile başlayın:\n\n- Kontroller listesi: veri setine, duruma, sahip ve “şu anda başarısız” filtreleriyle aranabilir/filtrelenebilir.\n- Kontrol düzenleyici: veri doğrulama kurallarını oluşturup düzenleyin; açıklama ve sahip net olsun.\n- Çalıştırma geçmişi: her kontrol için sonuç zaman çizelgesi, “son çalıştırma” özeti ve detaylara linkler.\n- Uyarı ayarları: yönlendirme (email/Slack/vb.), şiddet ve gürültü kontrolleri.\n- Veri seti genel görünümü: bu veri seti için hangi kontroller var, son sağlık durumu ve birincil sahip.
Kullanıcıların kaybetmemesi gereken ana iş akışı
Ana akışı bariz ve tekrar edilebilir yapın:\n\nkontrol oluştur → zamanla/çalıştır → sonucu görüntüle → araştır → çöz → öğren.
“Araştır” birincil eylem olmalı. Başarısız bir çalıştırmadan kullanıcılar veri setine atlayabilmeli, başarısız metriği/değeri görmeli, önceki çalıştırmalarla karşılaştırma yapmalı ve neden üzerine not düşebilmeli. “Öğren” ise iyileştirmeleri teşvik edeceğiniz yerdir: eşik ayarlamayı, yardımcı bir kontrol eklemeyi veya hatayı bilinen bir olaya bağlamayı önerin.
Roller ve izinler (basit ama gerçek)
İlk aşamada rolleri minimal tutun:\n\n- Görüntüleyici (Viewer): kontrolleri ve sonuçları görebilir.\n- Düzenleyici (Editor): atanan veri setleri için kontrolleri ve uyarı ayarlarını oluşturabilir/düzenleyebilir.\n- Yönetici (Admin): kullanıcıları, global entegrasyonları ve izinleri yönetebilir.
Netlik ve sahiplik için tasarım
Her başarısız sonuç sayfası şunu göstermeli:\n\n- Ne başarısız oldu: tam kural, beklenen vs gerçekleşen ve ne zaman başladığı.\n- Neden önemli: kısa etki açıklaması (ör. “finans raporlamasını etkiler”).\n- Sahibi kim: sorumlu ekip/kişi ve uyarının nereye gideceği.
Mimarinin Planlanması: UI, API, İşçiler ve Depolama
Bir veri kalite uygulaması dört kaygıyı ayırdığınızda ölçeklenmesi (ve hata ayıklaması) daha kolay olur: kullanıcıların gördüğü (UI), onların değiştirdiği (API), kontrolleri çalıştıran (işçiler) ve olguların saklandığı yer (dep). Bu, “kontrol düzlemi”ni (konfigürasyonlar ve kararlar) “veri düzleminden” (kontrolleri yürütme ve sonuçları kaydetme) ayrı tutar.
UI: odaklanmış bir gösterge paneli
“Ne kırık ve sahibinin kim olduğu” sorusunu cevaplayan tek bir ekranla başlayın. Basit bir gösterge paneli ve filtreler uzun yol kat eder:\n\n- Veri seti/kaynak\n- Durum (başarılı, uyarı, başarısız)\n- Zaman aralığı (son çalıştırma, 24s, 7g)\n- Sahip/ekip
Her satırdan kullanıcılar çalıştırma detayları sayfasına inebilmeli: kontrol tanımı, örnek hatalar ve son bilinen iyi çalıştırma.
Backend API: stabil kontratlar
API'yı uygulamanızın yönettiği nesneler etrafında tasarlayın:\n\n- Kontroller (oluştur/güncelle/durdur, parametreler, zamanlama)\n- Çalıştırmalar (isteğe bağlı tetikle, çalıştırma geçmişini listele)\n- Sonuçlar (özetleri, hataları, agregaları getir)\n- Uyarılar (onayla, sustur, yönlendirme kuralları)\n- Kullanıcılar/takımlar (sahiplik, izinler)
Yazmaları küçük ve doğrulanmış tutun; UI'ın anlık kalması için ID'ler ve zaman damgaları döndürün.
İşçiler ve zamanlayıcı: güvenilir yürütme
Kontroller web sunucusu dışında çalıştırılmalı. Bir zamanlayıcı işleri kuyruğa almak için kullanılmalı (cron benzeri) ve UI'dan isteğe bağlı tetikleme eklenmeli. İşçiler sonra:\n\n1) kontrol konfigürasyonunu alır, 2) sorguyu/doğrulamayı çalıştırır, 3) sonuçları saklar, 4) uyarı kurallarını değerlendirir.
Bu tasarım veri seti başına eşzamanlılık limitleri ve güvenli yeniden denemeler eklemenize izin verir.
Depolama: farklı ihtiyaçlar için ayrı depolar
Ayrı depolamaları kullanın:\n\n- Konfigürasyon deposu: kontrol tanımları ve uyarı yönlendirmeleri (transactional)\n- Sonuç deposu: çalıştırma özetleri ve trendler için zaman serisi metrikleri\n- Günlük deposu: yürütme günlükleri için hata ayıklama ve denetimler
Bu ayrım panoları hızlı tutar, aynı zamanda bir şey başarısız olduğunda ayrıntılı kanıtı korur.
Hızlı prototipleme seçeneği: iskeleti üretin
Hızlı bir MVP göndermek istiyorsanız, Koder.ai gibi bir vibe-coding platformu React dashboard, Go API ve PostgreSQL şemasını yazılı bir spesifikasyondan (kontroller, çalıştırmalar, uyarılar, RBAC) sohbet yoluyla başlatmanıza yardımcı olabilir. Kaynak kodu dışa aktarabildiği için ortaya çıkan sistemi yine kendi repozitorinizde sahiplenip sertleştirebilirsiniz.
Veri Modelinizi ve Denetim İzini Tanımlayın
Çalışma Zamanını Hızlandırın
Koder.ai'de işçi ve zamanlama akışları oluşturun; sonra kendi korumalarınızla genişletin.
İyi bir veri kalite uygulaması yüzeyde basit hisseder çünkü altındaki veri modeli disiplinlidir. Amacınız her sonucu açıklanabilir kılmaktır: ne çalıştı, hangi veri seti üzerinde, hangi parametrelerle ve zaman içinde ne değişti.
Temel varlıklar (ve neden varlar)
Küçük bir temel nesne setiyle başlayın:\n\n- Dataset: izlenen varlık (tablo, dosya, API uç noktası). Tanımlayıcılar, bağlantı referansı ve insan tarafından okunabilir isim saklayın.\n- Check: yeniden kullanılabilir kural (ör. “satır sayısı dünü ±%10 içinde olmalı”). Tip, konfig, zamanlama, şiddet ve sahip dahil.\n- CheckRun: belirli bir zaman ve girdi için değiştirilemez yürütme kaydı. Bu denetim omurganızdır.\n- ResultMetric: grafikleme için özetlenmiş çıktılar (sayım, yüzde null, min/max, anomali skoru).\n- AlertRule: sonuçları uyarıya çeviren mantık (eşikler, ardışık hatalar, bakım pencereleri).\n- Notification: her gönderim denemesi (Slack/email/PagerDuty) ile durumu ve sağlayıcı yanıtı.\n- Incident: gruplanmış izlenebilir problem (açıldı/onaylandı/çözüldü) — spamı azaltır.\n- Ownership: veri setleri/kontrollerden takımlara ve yükseltme yollarına eşlemeler.
Ham detayları ve özet metrikleri saklayın
Hata araştırması için ham sonuç detaylarını (ör. başarısız satır örnekleri, ilgili sütunlar, sorgu çıktısı snippet'i) saklayın; ayrıca panolar ve trendler için optimize edilmiş özet metrikler de tutun. Bu ayrım grafiklerin hızlı yüklenmesini sağlar ama hata ayıklamak için gereken kanıtı kaybetmezsiniz.
Geçmişi değiştirilemez yapın (ve sorgulanabilir)
Hiçbir CheckRun'ı üstüne yazmayın. Eklenebilir tarihçe denetimleri mümkün kılar (“Salı günü ne biliyorduk?”) ve hata ayıklamayı kolaylaştırır (“kural mı değişti yoksa veri mi?”). Her çalıştırma yanında kontrol versiyonunu/konfig hash'ini kaydedin.
Filtreleme ve erişim kontrolü için etiketler
Dataset ve Check'lere team, domain ve PII flag gibi etiketler ekleyin. Etiketler gösterge panolarındaki filtreleri güçlendirir ve izin kurallarını destekler (ör. PII etiketli veri setleri için ham satır örneklerini görebilme kısıtlaması).
Kontrol Yürütme Motorunu Kurun
Yürütme motoru, veri kalite izleme uygulamanızın “runtime”ıdır: bir kontrolün ne zaman çalışacağını, nasıl güvenle çalışacağını ve ne kaydedeceğini belirler ki sonuçlar güvenilir ve tekrarlanabilir olsun.
Zamanlayıcı + kuyruk: kontrolleri güvenilir çalıştırın
Kontrolleri bir takvim (cron-benzeri) üzerinde tetikleyen bir zamanlayıcıyla başlayın. Zamanlayıcı ağır işleri kendisi çalıştırmamalı—işleri kuyruğa almak onun görevidir.
Bir kuyruk (DB veya mesaj aracısı tarafından desteklenen) size şunları sağlar:\n\n- aynı anda çok sayıda kontrolün tetiklenmesi halinde trafiği absorbe etme\n- işleri işçilere dağıtma\n- işler kaybolmadan duraklatıp devam ettirme
Veri kaynaklarını zaman aşımı ve limitlerle koruyun
Kontroller genellikle üretim veritabanlarına veya ambarlara sorgu yapar. Yanlış yapılandırılmış bir kontrolün performansı bozmasını önlemek için koruyucu tedbirler koyun:\n\n- Her çalıştırma için zaman aşımı (örn. 60–300 saniye)\n- Geçici hatalar için geri çekilmeli yeniden denemeler (network sorunları, kısa ambar yüklenmesi)\n- Aynı veri kaynağı için eşzamanlılık limitleri (örn. aynı ambar için max 3 paralel sorgu)\n- Güvenli olmayan sorgular için sert hata modları (izinli/engelli desenler)
Ayrıca “devam eden” durumları yakalayın ve işçiler çöktüğünde terk edilmiş işleri güvenle yeniden alabilsin.
Çalıştırmaları tam bağlamla tekrarlanabilir kılın
Bağlamsız bir geçiş/başarısızlık güvenilmezdir. Her sonuçla birlikte çalıştırma bağlamını saklayın:\n\n- kontrol tanımı versiyonu (veya hash)\n- sorgu metni (veya referans) ve parametreler\n- ortam (prod/stage), zaman dilimi ve zamanlama penceresi\n- connector detayları (hangi veri kaynağı, şema, rol), sırları saklamadan
Bunlar haftalar sonra “tam olarak ne çalıştı?” sorusunu cevaplamanızı sağlar.
Daha güvenli onboarding: dry run ve bağlantı testi
Bir kontrolü aktifleştirmeden önce sunun:\n\n- Bağlantı testi: kimlik bilgilerini ve izinleri doğrulayın, hafif bir sorgu çalıştırın\n- Kuru çalıştırma (Dry run): kontrolü bir kez çalıştırın, beklenen maliyeti/zamanı gösterin ve uyarı göndermeden sonuç önizlemesini sunun
Bu özellikler sürprizleri azaltır ve uyarıların ilk günden itibaren güvenilir olmasını sağlar.
Eyleme Geçirilebilir (Gürültüsüz) Uyarılar Oluşturun
İlk Ekranları Gönderin
Haftalar süren altyapı işlerinden kurtulup kontrol katalogları, çalıştırma geçmişi ve uyarı ayarlarını prototipleyin.
Uyarı mekanizması veri kalite izleme ile ya güven kazanır ya da görmezden gelinir. Amaç “her şeyin yanlış olduğunu söylemek” değil—ama “sonraki adım ne, ne kadar acil” sorularına cevap verebilen uyarılar göndermektir. Her uyarı üç soruyu yanıtlamalı: ne kırıldı, ne kadar kötü, ve kimin sorumluluğunda.
Net uyarı koşulları tanımlayın
Farklı kontroller farklı tetikleyiciler gerektirir. Çoğu ekip için pratik birkaç desen sağlayın:\n\n- Eşik aşımı (örn. null oranı \u003e %2)\n- Baz karşıtı değişim (örn. bugünkü satır sayısı son 7 gün medyanının %40 altında)\n- Ardışık hatalar (örn. 3 çalıştırmada başarısız olursa uyar)\n- Tazelik ihlalleri (örn. veri seti 6 saatte güncellenmemiş)
Bu koşullar her kontrol için yapılandırılabilir olsun ve bir önizleme gösterin (“geçen ay 5 kez tetiklenecekti”) ki kullanıcılar hassasiyeti ayarlayabilsin.
Gürültüyü azaltmak için dedupe ve soğuma pencereleri ekleyin
Aynı olay için tekrar eden uyarılar insanları sessize aldırır. Ekleyin:\n\n- Deduping: uyarıları kontrol + veri seti + hata sebebine göre gruplayın.\n- Soğuma pencereleri: şiddet artmadıkça aynı uyarıyı belirli bir süre yeniden göndermeyin.
Ayrıca durum geçişlerini izleyin: yeni hatalarda uyarı verin ve isteğe bağlı olarak iyileşme durumunda bilgilendirin.
Uyarıları doğru sahiplere yönlendirin
Yönlendirme veri odaklı olmalı: veri seti sahibi, ekip, şiddet veya etiketler (örn. finance, customer-facing) bazında. Bu yönlendirme mantığı yapılandırmada, kodda değil olmalı.
Email ve Slack ile başlayın, webhook'ları sonra ekleyin
Email ve Slack çoğu iş akışını kapsar ve benimsenmesi kolaydır. Uyarı yükünü ileride webhook'a genişletmeyi kolaylaştıracak biçimde tasarlayın. Derin triage için inceleme görünümüne doğrudan bağlanın (ör. /checks/{id}/runs/{runId}).
Sonuçlar, Trendler ve Araştırma İçin Gösterge Panoları Oluşturun
Gösterge paneli veri kalite izlemenin kullanılabilir olduğu yerdir. Amaç güzel grafikler değil—birinin hızlıca iki soruyu cevaplayabilmesini sağlamak: “Bir şey kırık mı?” ve “Sonraki adım ne?”
Genel durum görünümü
Hızlı yüklenen, kompakt bir “sağlık” görünümüyle başlayın ve dikkat gerektirenleri vurgulayın.
Gösterin:\n\n- Son başarısızlıklar ve etkileri (veri seti, kural, şiddet, zaman)\n- En çok dalgalanan kontroller (yüksek geçiş başarısız/geçiş oranı) ki takımlar gürültülü kuralları düzeltebilsin\n- En taze veri setleri ve son başarılı güncelleme zamanları (tazelik)
Bu ilk ekran operasyon konsolu gibi hissettirmeli: net durum, az tıklama ve tutarlı etiketler.
Eylemi destekleyen derinlemesine inceleme
Herhangi bir başarısız kontrolden detay görünümüne gidildiğinde insanları uygulamadan çıkarmadan araştırmayı destekleyin.
İçerikte şunlar olsun:\n\n- Başarısız kural detayları (ne kontrol edildi, beklenen vs gerçek)\n- Başarısız satırlardan örnekler (hassas sütunlar için güvenli maskeleme ile)\n- Aynı veri setindeki ilgili kontroller (sorun genellikle yukarı akıştadır)\n- Teknik olmayan paydaşlar için kısa “neden önemli” notu
Mümkünse bir tıkla “Araştırma aç” paneli ve runbook ile sorgulara (yalnızca göreli metinler) bağlantılar sağlayın, örn. /runbooks/customer-freshness ve /queries/customer_freshness_debug.
Yavaş gerilemeleri ortaya çıkaran trendler
Hatalar barizdir; yavaş bozulma değildir. Her veri seti ve kontrol için trend sekmesi ekleyin:\n\n- Zaman içinde null oranı\n- Zaman içinde tazelik (dakika/saat gecikme)\n- Haftalık bazda geçme oranı (veya dağıtıma göre)
Bu grafikler anomali tespiti temellerini pratik kılar: bunun tek seferlik mi yoksa bir desen mi olduğunu görebilirsiniz.
Sonuçları açıklanabilir ve izlenebilir yapın
Her grafik ve tablo altında kaynağa (çalıştırma geçmişi ve denetim günlükleri) bağlantılar olsun. Her nokta için “Çalıştırmayı görüntüle” linki verin ki ekipler girdileri, eşikleri ve uyarı yönlendirme kararlarını karşılaştırabilsin. Bu izlenebilirlik gösterge paneline güven inşa eder.
Güvenlik, İzinler ve Hassas Verilerin Güvenli İşlenmesi
Erken yapılan güvenlik kararları uygulamanızı ya işletmesi kolay veya sürekli yeniden çalışmayı gerektiren bir hale getirebilir. Veri kalite aracı üretim sistemlerine, kimlik bilgilerine ve bazen düzenlemeye tabi verilere dokunduğu için ilk günden iç yönetici ürünü gibi davranın.
Kimlik doğrulama: basit başlayın, SSO planlayın
Kuruluşunuz SSO kullanıyorsa OAuth/SAML'i mümkün olan en kısa sürede destekleyin. O zamana kadar e-posta/parola MVP kabul edilebilir, ama temel gereksinimleri karşılayın: tuzlanmış parola hashleme, hız sınırlama, hesap kilitleme ve MFA desteği.
SSO olsa bile kesinti durumları için güvenli bir “break-glass” yönetici hesabı saklayın. Süreci belgeleyin ve kullanımını kısıtlayın.
Kontroller ve uyarılar için rol tabanlı izinler (RBAC)
“Sonuçları görme” ile “davranışı değiştirme”yi ayırın. Yaygın bir rol seti:\n\n- Viewer: panoları ve çalıştırmaları görebilir\n- Editor: kontroller oluşturup düzenleyebilir\n- Operator: uyarı rotalarını ve zamanlamaları yönetebilir\n- Admin: workspace, kullanıcılar ve sırları yönetir
İzinleri yalnızca UI'da değil API üzerinde de zorlayın. Ayrıca takımların diğer takımların kontrollerini kazara düzenleyememesi için workspace/proje sınırlandırması düşünün.
Hassas verileri varsayılan olarak güvenli şekilde ele alın
PII içerebilecek ham satır örneklerini saklamaktan kaçının. Bunun yerine özetler ve metrikler saklayın (sayım, null oranı, min/max, histogram bucket'ları, başarısız satır sayısı). Örnek saklamanız gerekiyorsa bu açıkça isteğe bağlı olsun: kısa saklama süresi, maskeleme/redaksiyon ve sıkı erişim kontrolleriyle.
Giriş, kontrol düzenleme, uyarı rota değişiklikleri ve gizli güncellemeler için denetim günlükleri tutun. Denetim izi bir şey değiştiğinde karışıklığı azaltır ve uyumluluk için yardımcı olur.
Sırlar yönetimi: kimlik bilgileri kritik üründür
Veritabanı kimlik bilgileri ve API anahtarları asla açık metin olarak veritabanında yaşamamalı. Bir vault veya ortam tabanlı gizli enjeksiyon kullanın ve döndürmeyi destekleyecek şekilde tasarlayın (birden fazla aktif sürüm, son döndürülme zaman damgası ve bağlantı testi akışı). Gizli görünürlüğünü yalnızca yöneticilerle sınırlayın ve erişimi günlükleyin; gizli değerleri günlüklemeyin.
Sistemi Test Edin ve Monitörü İzleyin
Korkmadan İterasyon Yapın
Deneyler ters gittiğinde gürültülü uyarıları anında ayarlayıp hızlı geri alımla güvenle iterasyon yapın.
Uygulamanıza güvenmeden önce hataları güvenilir şekilde tespit edebildiğini, yanlış alarmlardan kaçındığını ve temiz bir şekilde toparlanabildiğini kanıtlayın. Testi bir ürün özelliği gibi ele alın: kullanıcıları gürültülü uyarılardan korur ve sizi sessiz boşluklardan kurtarır.
Her kontrol türü için “altın” test veri setleri oluşturun
Desteklediğiniz her kontrol türü (tazelik, satır sayısı, şema, null oranları, özel SQL vb.) için örnek veri setleri ve altın test vakaları oluşturun: geçmesi gereken bir vaka ve belirli şekillerde başarısız olması gereken birkaç vaka. Bunlar küçük, versiyon kontrollü ve tekrarlanabilir olmalıdır.
İyi bir altın test şunu cevaplar: Beklenen sonuç nedir? UI hangi kanıtı göstermeli? Denetim günlüğüne ne yazılmalı?
Sadece kontrol sonuçlarını değil uyarı davranışını da doğrulayın
Uyarı hataları genellikle kontrol hatalarından daha zararlıdır. Eşik, soğuma ve yönlendirme kuralları için uyarı mantığını test edin:\n\n- Eşik kenar durumları (tam sınırda, biraz üstünde, biraz altında)\n- Soğuma ve deduplikasyon (devam eden olay sırasında tekrarlanan bildirimlerden kaçının)\n- Yönlendirme değişiklikleri (takım A vs takım B, ortama göre yönlendirme)\n- Kurtarma davranışı (çözüldüğünde temiz bildirimler, yeni incident değil)
Kendi uygulamanızı üretim gibi izleyin
Monitörün kendisi başarısız olduğunda fark edebilmek için aşağıyı izleyin:\n\n- İş başarı oranı ve ortalama çalışma süresi\n- Kuyruk derinliği ve işçi verimi\n- API hata oranları, zaman aşımı ve yeniden denemeler\n- Bildirim sağlayıcı hataları (email/SMS/Slack)
Bir sorun giderme sayfası yayınlayın
Yapışmış işler, eksik kimlik bilgileri, gecikmeli zamanlamalar, bastırılmış uyarılar gibi yaygın hataları kapsayan açık bir sorun giderme sayfası yazın ve dahili olarak bağlayın, ör. /docs/troubleshooting. “İlk önce ne kontrol edilmeli” adımları ve günlüklerin, çalıştırma ID'lerinin ve son olayların nerede bulunacağı gibi bilgiler verin.
Yayınlayın, İterasyon Yapın ve Zamanla Genişletin
Bir veri kalite uygulaması göndermek “büyük lansman”dan ziyade küçük, istikrarlı adımlarla güven inşa etmektir. İlk sürüm döngüsünü kanıtlamalı: kontroller çalışsın, sonuçları göstersin, uyarı göndersin ve birinin gerçek bir sorunu düzeltmesine yardımcı olsun.
Kullanılan bir MVP ile başlayın
Dar, güvenilir bir yetenek setiyle başlayın:\n\n- Birkaç yüksek değerli kontrol türü (ör. tazelik, satır sayısı, null/benzersizlik eşikleri)\n- Tek bir zamanlayıcı (basit cron tarzı zamanlamalar yeterli)\n- Bir uyarı kanalı (ekibin zaten izlediği email veya Slack)\n- “Ne başarısız oldu, ne zaman ve neden?” sorusunu yanıtlayan bir gösterge paneli
Bu MVP esneklikten çok açıklığa odaklansın. Kullanıcılar bir kontrolün neden başarısız olduğunu anlayamazsa uyarıya tepki vermezler. UX'i hızlı doğrulamak istiyorsanız, CRUD ağırlıklı parçaları (kontrol kataloğu, çalıştırma geçmişi, uyarı ayarları, RBAC) Koder.ai ile prototipleyip planlama modunda iterasyon yapabilirsiniz.
Güvenli dağıtım yapın ve değişiklikleri geri alınabilir tutun
İzleme uygulamanızı üretim altyapısı gibi ele alın:\n\n- Ayrı ortamlar (dev/stage/prod) ile yeni kontrolleri gerçek insanları meşgul etmeden test edin\n- Veri tabanı migrasyonları ve versiyonlu sürümler kullanın\n- Yedekler ve geri yükleme prosedürlerini belgeleyin\n- Gürültülü bir kontrolü hızlıca devre dışı bırakacak bir geri alma planı olsun
Tek bir kontrol veya tüm bir entegrasyon için basit bir “kill switch” erken benimsemede saatler kazandırabilir.
Şablonlar ve hızlı başlangıç ile ekipleri dahil edin
İlk 30 dakikanın başarılı olmasını sağlayın. “Günlük pipeline tazeliği” veya “birincil anahtar için benzersizlik” gibi şablonlar ve kısa bir kurulum kılavuzu /docs/quickstart sağlayın.
Ayrıca hafif bir sahiplik modeli tanımlayın: kim uyarıları alır, kim kontrolleri düzenleyebilir ve bir hatadan sonra “tamamlandı” ne demektir (örn. onayla → düzelt → yeniden çalıştır → kapat).
Sonraki adımları planlayın (fazla inşa etmeden)
MVP kararlı hale gelince gerçek olaylara göre genişletin:\n\n- Olay iş akışı: onaylar, atamalar ve durum (açık/devam/çözüldü)\n- Entegrasyonlar: Jira, PagerDuty/Opsgenie, Teams ve veri katalogu bağlantıları\n- Daha iyi baziller: hareketli ortalamalar, mevsimsellik-dikkatli eşikler ve anomali tespiti temelleri\n- Daha akıllı yönlendirme: yalnızca sahibi takımı uyarın, bağlam ve önerilen sonraki adımlarla
İterasyonunuzu ise tespit süresini kısaltmak ve uyarı gürültüsünü azaltmak üzerine kurun. Kullanıcılar uygulamanın kendilerine gerçekten zaman kazandırdığını hissettiğinde benimseme kendiliğinden artar.
SSS
Veri kalite izleme web uygulaması inşa etmeden önce neyi tanımlamalıyız?
Önce ekibiniz için “veri kalitesi”nin ne anlama geldiğini yazın—genellikle doğruluk, eksiklik, zamanında olma ve benzersizlik. Ardından her bir boyutu somut sonuçlara çevirin (ör. “siparişler sabah 06:00'a kadar yüklenmeli”, “email boş oranı \u003c %2”) ve daha az olay, daha hızlı tespit ve daha düşük yanlış uyarı oranı gibi başarı metrikleri seçin.
Uygulamamız toplu kontroller mi, gerçek zamanlı kontroller mi yoksa her ikisini de mi çalıştırmalı?
Her ikisi genellikle en iyi sonucu verir:
- Toplu (batch) kontroller ETL/ELT yüklemelerinden sonra geniş kapsama ve geçit kontrolleri için.
- Gerçek zamanlı kontroller kritik olay/API akışları için hızlı tespit sağlar.
Gecikme beklentilerini (dakikalar vs saatler) açıkça belirleyin; bu zamanlama, depolama ve uyarı aciliyeti üzerinde etkili olur.
Hangi veri setlerini önce izlemeliyiz?
İlk 5–10 kırılmaması gereken veri setini şu kriterlere göre önceliklendirin:
- Yanlış olduğunda iş üzerinde yüksek etki
- Sıklıkla değişen veya kırılmaya elverişli boru hatları
- İzleme olmadan hataların fark edilmesinin zor olması
Her veri seti için bir sahip ve beklenen yenileme sıklığını kaydedin ki uyarılar harekete geçebilecek birine yönlendirilebilsin.
MVP'de hangi veri kalite kontrollerini desteklemeliyiz?
Başlangıç için pratik bir katalog şunları içerir:
- Şema kontrolleri (sütunlar/tipler/enumerasyonlar)
- Tamlık/null-oranı eşik kontrolleri
- Değer aralığı kontrolleri
- Referential bütünlük (ilişkisel tutarlılık)
- Tazelik kontrolleri
- Çoğaltım/benzersizlik kontrolleri
Bunlar, gün birinci gün karmaşık anomalileri zorlamadan çoğu yüksek etkili hatayı kapsar.
Kuralları kullanıcıların nasıl tanımlamasına izin vermeliyiz—UI, şablonlar yoksa SQL mi?
“Önce UI, ikinci kaçış kapağı” yaklaşımını kullanın:
- Sık kullanılan kontroller için UI kuralları/şablonlar (tutarlı ve kolay yönetilir)
- Köşe durumlar için isteğe bağlı özel SQL/scriptler
Özel SQL izin veriyorsanız; salt okunur bağlantılar, zaman aşımı, parametrelendirme ve normalize edilmiş başarılı/başarısız çıktı gibi korumalar uygulayın.
Veri kalite uygulaması için minimum gerekli UI ekranları nelerdir?
İlk sürüm küçük ama tamamlayıcı olsun:
- Kontroller listesi (dataset, durum, sahip; arama/filtreleme)
- Kontrol düzenleyici (kural + açıklama + sahip)
- Çalıştırma geçmişi (zaman çizelgesi ve son çalıştırma özeti)
- Uyarı ayarları (yönlendirme, şiddet, gürültü kontrolleri)
- Veri seti genel görünümü (sağlık + kontroller + sahip)
Her hata görünümü açıkça , ve göstermeli.
Ölçeklenebilir bir veri kalite kontrolleri uygulaması için hangi mimari en uygundur?
Sistemi dört parçaya ayırın:
- UI: gösterge paneli ve inceleme akışları
- API: kontroller, çalıştırmalar, sonuçlar, uyarılar, kullanıcılar/takımlar gibi kararlı nesneler
- İşçiler + zamanlayıcı: kontrolleri web sunucusu dışında çalıştırır
- Depolama: yapılandırma, sonuç/zaman serisi ve günlükler için ayrı depolamalar
Bu ayrım kontrol düzlemini istikrarlı tutarken yürütme motorunun ölçeklenmesini sağlar.
Hangi veri modeli ve denetim izi uygulanmalı?
Eklenecek tek yönlü (append-only) bir model kullanın:
- Dataset, Check, (değiştirilemez çalıştırma kaydı)
İnsanların görmezden gelmeyeceği uyarıları nasıl oluştururuz?
Eyleme geçirilebilirlik ve gürültü azaltmaya odaklanın:
- Tetikleyiciler: eşik ihlalleri, baz vs değişim, ardışık hatalar, tazelik ihlalleri
- Aynı kontrol + veri seti + hata nedeni bazında dedupe
- Tek bir olay süresince yinelenen uyarıları önlemek için soğuma pencereleri
- Yönlendirme: sahip/takım/şiddet/etiketlere göre yapılandırılmalı
Uyarı yükü azaltıldığında ekipler uygulamaya güvenmeye başlar. Sorgu/patika örneğinde inceleme görünümüne (ör. /checks/{id}/runs/{runId}) doğrudan bağlanın ve kurtarma bildirimlerini de isteğe bağlı yapın.
Güvenlik, izinler ve hassas verileri güvenli şekilde nasıl ele alırız?
İç yönetici ürünü gibi davranın:
- API üzerinde uygulanmış RBAC (viewer/editor/operator/admin)
- Mümkünse SSO; parola tabanlı başlangıç için temel güvenlik önlemleri
- Gizli bilgileri vault'ta saklayın ve döndürmeyi destekleyin
- Öntanımlı olarak ham satır örnekleri yerine özetler saklayın; örnek gerekiyorsa opsiyonel, maskeleme ve kısa saklama ile yapın
- Girişler, kontrol düzenlemeleri, uyarı rota değişiklikleri ve gizli güncellemeler için denetim günlükleri tutun