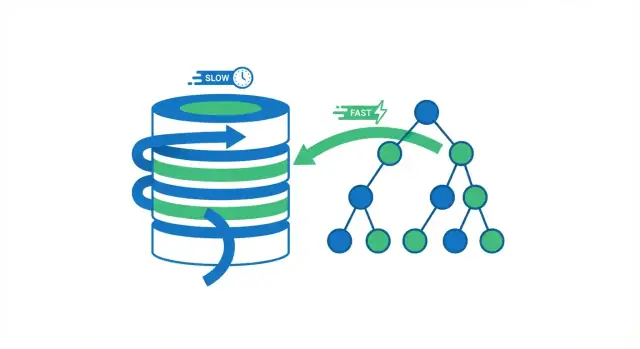
Veritabanı İndekslemesi Gerçekte Ne Yapar
Veritabanı indeksi, veritabanının satırları daha hızlı bulmasına yardımcı olan ayrı bir arama yapısıdır. Tablonuzun ikinci bir kopyası değildir. Bir kitabın dizin sayfalarını düşünün: dizini kullanarak doğru yere yakın atlayıp, ardından ihtiyacınız olan sayfayı (satırı) okuyorsunuz.
İndeks yoksa veritabanının genellikle yalnızca güvenli bir seçeneği vardır: hangi satırların sorgunuza uyduğunu kontrol etmek için birçok satırı okumak. Küçük tablolar için bu sorun olmaz. Tablo milyonlarca satıra ulaştıkça “daha çok satır kontrol etme” daha fazla disk okuması, daha fazla bellek baskısı ve daha fazla CPU işi demektir—aynı sorgu aniden yavaşlamaya başlar.
İndeksin değiştirdiği (ve değiştirmediği) şeyler
İndeksler, veritabanının cevaplamak için incelemek zorunda olduğu veri miktarını azaltır; örneğin “ID 123 olan siparişi bul” veya “bu e-postaya sahip kullanıcıları getir” gibi. Her şeyi taramak yerine veritabanı aramayı hızla daraltan sıkıştırılmış bir yapıya bakar.
Ama indeks her sorunu çözmez. Bazı sorgular yine de çok sayıda satır işlemek zorunda kalır (geniş raporlar, düşük seçicilik filtreleri, ağır agregasyonlar). Ayrıca indekslerin gerçek maliyetleri vardır: ek depolama ve daha yavaş yazmalar; çünkü insert ve update işlemleri indeksi de güncellemek zorundadır.
Bu rehberde ne öğreneceksiniz
Şunları göreceksiniz:
- neden tam tablo taramalarından kaçınmanın büyük bir hız kazancı olduğu
- B-tree gibi yaygın indeks yapıların aramaları nasıl hızlandırdığı
- hangi sorguların en çok faydalandığı ve ne zaman fayda sağlamadığı
- bileşik/kapsayan indeksleri nasıl seçip EXPLAIN plan ile doğrulayacağınız
- performansın sessizce bozulmaması için indeksleri zaman içinde nasıl bakım yapacağınız
Temel Hız Kazancı: Tam Tablo Taramasından Kaçınmak
Veritabanı bir sorgu çalıştırırken iki geniş seçeneğe sahiptir: tabloyu satır satır taramak ya da doğrudan eşleşen satırlara atlamak. Çoğu indeks kazancı gereksiz okumaları önlemekten gelir.
Tam tablo taraması vs. indeks araması
Bir tam tablo taraması (full table scan) tam olarak adının söylediği gibidir: veritabanı her satırı okur, WHERE koşuluna uyup uymadığına bakar ve sonra sonuçları döndürür. Küçük tablolar için kabul edilebilir ama tablo büyüdükçe daha yavaşlar—daha fazla satır, daha fazla iş demektir.
Bir indeks kullanıldığında veritabanı çoğu satırı okumaktan kaçınabilir. Bunun yerine öncelikle arama için oluşturulmuş sıkıştırılmış yapıya bakar, eşleşen satırların nerede olduğunu bulur ve sadece o satırları okur.
Basit bir benzetme
Bir kitabı düşünün. “Fotosentez” geçen her sayfayı istiyorsanız kitabı baştan sona okuyabilirsiniz (tam tarama). Ya da kitabın dizinini kullanıp listelenen sayfalara atlayıp sadece o bölümleri okuyabilirsiniz (indeks araması). İkinci yöntem çok daha hızlıdır çünkü neredeyse tüm sayfaları atlamış olursunuz.
Neden daha az okuma genelde daha hızlıdır
Veritabanları özellikle veriler bellekte değilse okumaları beklemekle çok zaman harcar. Okunması gereken satır (ve sayfa) sayısını azaltmak tipik olarak şunları küçültür:
- disk/SSD okumaları
- filtreleri değerlendirmek için harcanan CPU zamanı
- önbelleğe gereksiz veri çekilmesinden kaynaklanan bellek baskısı
Hız kazancının nerede görünür olduğu
İndeksleme en çok veri büyük olduğunda ve sorgu kalıbı seçiciyse görünür (örneğin 10 milyon kayıttan 20 eşleşen satır çekmek gibi). Sorgunuz zaten tablonun çoğunu döndürüyor veya tablo rahatça belleğe sığıyorsa tam tarama aynı hızda ya da daha hızlı olabilir.
İndeks Yapıları Aramaları Nasıl Hızlandırır
İndeksler, veritabanının her satırı kontrol etmek yerine istediğiniz değere yakın bir yere atlamasını sağlar çünkü değerleri düzenlerler.
B-tree indeksleri: varsayılan iş atölyesi
SQL veritabanlarında en yaygın indeks yapısı B-treedir (çoğunlukla "B-tree" veya "B+tree" şeklinde yazılır). Kavramsal olarak:
- değerler sıralı tutulur
- indeks sayfalara (chunks) bölünür; bu sayfalar diğer sayfalara ve nihayetinde eşleşen tablo satırlarına işaret eder
Sıralı olduğu için B-tree hem eşitlik aramaları (WHERE email = ...) hem de aralık sorguları (WHERE created_at >= ... AND created_at < ...) için iyidir. Veritabanı doğru mahalli bulup sonra sırayla ileri tarama yapabilir.
"Logaritmik" ne demek (matematik olmadan)
İnsanlar B-tree aramalarının “logaritmik” olduğunu söyler. Pratikte bunun anlamı şudur: tablonuz binlerden milyona çıktığında, bir değeri bulmak için gereken adım sayısı yavaşça artar, orantılı olarak artmaz.
"Verinin iki katı, işi iki katına çıkarır" yerine, "çok daha fazla veri sadece birkaç ekstra navigasyon adımı ekler" gibi düşünün; çünkü veritabanı ağacın birkaç seviyesinden pointer takip eder.
Hash indeksleri: tam eşleşmeler için hızlı (sınırlamalarla)
Bazı motorlar ayrıca hash indeksleri sunar. Bunlar tam eşleşmeler için çok hızlı olabilir çünkü değer bir hash'e dönüştürülür ve doğrudan giriş bulunur.
Takas: hash indeksleri genellikle aralıklar veya sıralı taramalarda yardımcı olmaz ve kullanılabilirlik/ver davranışı veritabanına göre değişir.
Motor detayları farklıdır, fikir aynıdır
PostgreSQL, MySQL/InnoDB, SQL Server ve diğerleri indeksleri farklı şekilde depolar ve kullanır (sayfa boyutu, clustering, included sütunlar, görünürlük kontrolleri). Ama temel fikir aynıdır: indeksler veritabanının eşleşen satırları bulmasını taramaya kıyasla çok daha az iş ile sağlayan sıkıştırılmış, gezinilebilir bir yapı oluşturur.
Hangi Sorgular İndekslerden En Çok Yararlanır
İndeksler genel olarak "SQL'i hızlandırır" demek yerine belirli erişim kalıplarını hızlandırır. İndeks, sorgunuzun filtreleme, join veya sıralama şekliyle eşleştiğinde veritabanı doğrudan ilgili satırlara atlayabilir.
İndeks dostu sorgu kalıpları
1) WHERE filtreleri (özellikle seçici sütunlarda)
Sorgunuz büyük bir tabloyu küçük bir satır kümesine sık sık daraltıyorsa indeks genellikle ilk bakılacak yerdir. Klasik örnek bir kullanıcıyı tanımlayıcıyla aramaktır.
users.email üzerinde indeks yoksa veritabanı her satırı taramak zorunda kalabilir:
SELECT * FROM users WHERE email = '[email protected]';
email üzerinde indeks olduğunda eşleşen satırı(ları) hızla bulup durabilir.
2) JOIN anahtarları (foreign key ve referanslanan anahtarlar)
Join'ler küçük verimsizliklerin büyük maliyetlere dönüştüğü yerlerdir. orders.user_id ile users.id join'i yaparken join sütunlarını indekslemek (genellikle orders.user_id ve users.id gibi) veritabanının satırları tekrar tekrar taramadan eşleştirmesine yardımcı olur.
3) ORDER BY (sonuçları zaten sıralı istiyorsanız)
Sıralama, veritabanının çok sayıda satırı toplayıp sonra sıralaması gerektiğinde pahalıdır. Sıklıkla çalıştırdığınız:
SELECT * FROM orders WHERE user_id = 42 ORDER BY created_at DESC;
gibi sorgular için user_id ve sıralama sütunu ile uyumlu bir indeks motorun gerekli sırada okumasına izin vererek büyük bir kazanç sağlayabilir.
4) GROUP BY (gruplama indeksle hizalandığında)
Grouplama, veritabanı veriyi gruplanmış sırada okuyabildiğinde fayda sağlar. Kesin garanti yok, ama sıkça grup yapılan bir sütun filtreyle birlikte kullanılıyorsa veya indeks doğal olarak grupla uyumluysa motor daha az iş yapabilir.
Aralık filtreleri: B-tree'nin sık görülen kazancı
B-tree indeksleri aralık koşullarında özellikle iyidir—tarihler, fiyatlar ve "between" sorguları gibi:
SELECT * FROM orders
WHERE created_at >= '2025-01-01' AND created_at < '2025-02-01';
Dashboardlar, raporlar ve "son etkinlik" ekranları için bu desen çok yaygındır ve aralık sütunu üzerinde bir indeks genelde hemen iyileşme getirir.
Tema basit: indeksler arama ve sıralama şeklinizle uyumlu olduğunda en çok yardımcı olur. Sorgularınız bu erişim kalıplarıyla eşleşirse veritabanı geniş taramalar yerine hedeflenmiş okumalar yapabilir.
Seçicilik: Neden Bazı İndeksler Yardımcı Olmaz
İndeksler en fazla, veritabanının kaç satırı işlemesi gerektiğini keskin şekilde azaltıyorsa yardımcı olur. Bu özellik seçicilik olarak adlandırılır.
Seçicilik pratikte ne demek
Seçicilik temelde: belirli bir değer kaç satırla eşleşiyor? Çok sayıda farklı değere sahip olan bir sütun yüksek seçiciliğe sahiptir, böylece her arama az sayıda satır döndürür.
- Yüksek seçicilik:
email, user_id, order_number (genellikle benzersiz veya ona yakın)
- Düşük seçicilik:
is_active, is_deleted, birkaç yaygın değeri olan status
Yüksek seçicilikte indeks bir aramayı küçük bir satır kümesine daraltır. Düşük seçicilikte indeks tabloyun büyük bir kısmına işaret eder—veritabanının yine de çok okuyup filtrelemesi gerekir.
Boolean (ve benzeri) indekslerin neden hayal kırıklığı yarattığı
10 milyon satırlık bir tabloda is_deleted sütununun %98'i false ise is_deleted üzerinde bir indeks şu sorgu için çok da fayda sağlamaz:
SELECT * FROM orders WHERE is_deleted = false;
Eşleşen küme hâlâ tablonun neredeyse tamamıdır. İndeks kullanmak, motorun indeks girdileri ile tablo sayfaları arasında ekstra atlamalar yapması gerektiği için sıralı taramadan daha yavaş olabilir.
Veritabanının indeksinizi görmezden gelmesinin nedenleri
Sorgu planlayıcı maliyetleri tahmin eder. Eğer indeks işi yeterince azaltmayacaksa—örneğin çok fazla satır eşleniyorsa veya sorgu çoğu sütunu da gerektiriyorsa—planlayıcı tam tablo taramasını seçebilir.
Seçicilik zaman içinde değişir
Veri dağılımı sabit değildir. Bir status sütunu başlangıçta eşit dağılabilir, sonra bir değerin hakim olduğu bir duruma kayabilir. İstatistikler güncel değilse planlayıcı kötü tahminlerde bulunur ve eskiden fayda sağlayan bir indeks artık işe yaramayabilir.
Bileşik ve Kapsayan İndeksler (Ve Sütun Sırası)
Tek sütunlu indeksler iyi bir başlangıçtır, ama birçok gerçek sorgu bir sütuna göre filtreler ve diğerine göre sıralar veya filtreler. İşte bileşik (çok sütunlu) indeksler devreye girer: tek bir indeks sorgunun birden çok parçasına hizmet edebilir.
Sütun sırası: "soldan sağa" kuralı
Çoğu veritabanı (özellikle B-tree ile) bileşik bir indeksi soldan başlayarak verimli kullanabilir. İndeksi önce A'ya, sonra B'ye göre sıralanmış gibi düşünün.
Bu demektir ki:
- (account_id, created_at) indeksi
account_id ile filtreleyip sonra created_at ile sıralayan sorgular için harikadır
- aynı indeks genellikle sadece
created_at ile filtreleyen bir sorgu için yararlı değildir (çünkü created_at soldaki ilk sütun değildir)
Pratik bir desen: hesap başına zaman çizelgeleri
Sık görülen bir iş yükü “bu hesabın en son etkinliklerini göster” tipindedir. Bu sorgu kalıbı:
SELECT id, created_at, type
FROM events
WHERE account_id = ?
ORDER BY created_at DESC
LIMIT 50;
çoğunlukla şu indeksten büyük fayda görür:
CREATE INDEX events_account_created_at
ON events (account_id, created_at);
Veritabanı indeksi kullanarak bir hesabın bölümüne atlayıp zaman sırasıyla satırları okuyabilir; büyük bir küme tarayıp sıralamak zorunda kalmaz.
Kapsayan indeksler: indeks cevabın kendisi olduğunda
Kapsayan indeks, sorgunun ihtiyaç duyduğu tüm sütunları içerir; böylece veritabanı tablo satırlarını okumadan sadece indeksten sonuç döndürebilir (daha az okuma, daha az rastgele I/O).
Dikkat: ek sütunlar indeksin boyutunu büyütür ve masraflı hale getirir.
Geniş bileşikleri “her ihtimale karşı” oluşturmayın
Geniş bileşik indeksler yazmaları yavaşlatır ve çok yer tutar. Sadece belirli, yüksek değerli sorgular için ekleyin ve EXPLAIN plan ile gerçek ölçümlerle doğrulamadan önce geniş indeksler oluşturmayın.
Takaslar: Yazma Yavaşlamaları ve Ek Depolama
İndeksler sıklıkla "bedava hız" olarak tanımlanır, ama bedava değildir. İndeks yapıları, altta yatan tablo her değiştiğinde korunmalı ve gerçek kaynaklar tüketir.
Daha yavaş INSERT/UPDATE/DELETE (çünkü her indeks güncellenmeli)
Yeni bir satır INSERT ettiğinizde veritabanı sadece satırı yazmaz—aynı zamanda her indeks için de ilgili girdileri ekler. DELETE ve birçok UPDATE için de durum aynıdır.
Bu yüzden "daha fazla indeks" yazma ağırlıklı iş yüklerinde belirgin şekilde yavaşlama getirebilir. İndeksli bir sütunu değiştiren bir UPDATE özellikle pahalı olabilir: veritabanı eski indeks girdisini kaldırıp yenisini eklemek zorunda kalabilir (ve bazı motorlarda bu ekstra page split veya yeniden dengeleme tetikleyebilir). Eğer uygulamanız çok yazma yapıyorsa—örneğin sipariş olayları, sensör verisi, audit log'lar—her şeye indeks koymak veritabanını yavaş hissettirebilir.
Ek depolama ve bellek baskısı
Her indeks disk alanı kaplar. Büyük tablolarda indeksler tablo boyutuna yakın veya daha büyük olabilir, özellikle birden fazla örtüşen indeks varsa.
Bu aynı zamanda bellek kullanımını etkiler. Veritabanları önbelleğe çok güvenir; çalışma setiniz büyük indeksleri de içeriyorsa önbellek daha fazla sayfa tutmak zorunda kalır. Aksi halde daha fazla disk I/O ve daha az öngörülebilir performans görürsünüz.
Pratik denge
İndeksleme, hangi işleri hızlandıracağını seçmektir. İş yükünüz okuma ağırlıklıysa daha fazla indeks değerli olabilir. Yazma ağırlıklıysa en önemli sorguları destekleyen indekslere öncelik verin ve kopyaları/örtüşmeleri önleyin. Faydalı bir kural: bir indeksi sadece ona fayda sağlayacak sorguyu adlandırabildiğinizde ekleyin—ve okuma kazancının yazma ve bakım maliyetini aşıp aşmadığını doğrulayın.
Bir İndeksin Yardımcı Olduğunu Kanıtlama: EXPLAIN ve Ölçümler
Bir indeks eklemek yardımcı olmalı diye görünebilir—ama bunu doğrulamalısınız. Bunu somut yapan iki araç sorgu planı (EXPLAIN) ve gerçek öncesi/sonrası ölçümlerdir.
Planı okuyun: indeks gerçekten kullanılıyor mu?
Tam olarak ilgilendiğiniz sorguda EXPLAIN (veya EXPLAIN ANALYZE) çalıştırın.
- Tarama türü: Seq Scan / Full Table Scan veritabanının tüm tabloyu okuduğunu gösterir. Index Scan / Index Seek (veya Index Range Scan) ise indeksin eşleşen satırları daraltmak için kullanıldığını gösterir.
- Tahmini vs. gerçek satırlar (
EXPLAIN ANALYZE ile özellikle): Eğer plan 100 satır tahmin etti ama gerçekte 100.000 satır okuduysa optimizer yanlış tahminde bulunmuş demektir—genellikle istatistikler güncel değilse veya filtre beklenenden daha az seçiciyse.
- Sort adımları: Eğer açıklamada açık bir Sort operasyonu görüyorsanız veritabanı sonuçları aldıktan sonra sıralıyor demektir. Yeni bir indeks
ORDER BY ile eşleşirse o sort kaybolabilir ve bu büyük bir kazançtır.
Doğru ölçün: öncesi/sonrası, aynı koşullar
Sorguyu aynı parametrelerle, temsilî veri hacminde benchmark edin ve hem gecikme hem de işlenen satır sayısını kaydedin.
Önbellekleme tuzağına dikkat: ilk çalışma daha yavaş olabilir çünkü veri henüz bellekte değildir; tekrar eden çalışmalarda indeks olmasa bile sonuçlar "hızlanmış" görünebilir. Kendinizi kandırmamak için birden çok çalışma karşılaştırın ve planın değişip değişmediğine (indeks kullanımı, daha az satır okunması) odaklanın, sadece ham zamana bakmayın.
Eğer EXPLAIN ANALYZE daha az satır okunduğunu ve daha az pahalı adım (ör. sort) gösteriyorsa indeksi kanıtlamış olursunuz—sadece ummak yerine görgül olarak doğrulamış olursunuz.
İndeks Kazançlarını İptal Eden Yaygın Hatalar
"Doğru" indeksi ekleyip yine de hızlanma görmemenizin nedeni sorgunun indeksi kullanmasını engelleyen yazım biçimleri olabilir. Bu sorunlar genellikle ince detaylardır; sorgu hâlâ doğru sonuç döndürür—sadece daha yavaş bir plan seçilir.
İndeksi engelleyen anti-pattern'ler
1) Önde joker karakter kullanımı
Aşağıdaki gibi yazdığınızda:
WHERE name LIKE '%term'
normal bir B-tree indeksi verimli şekilde kullanılamaz; çünkü sıralı düzende "%term" ifadesinin nerede başladığını bilmek mümkün değildir. Motor genellikle geniş bir taramaya geri döner.
Alternatifler:
- Eğer mümkünse önek araması kullanın:
WHERE name LIKE 'term%'.
- Eğer gerçekten "içerir" araması gerekiyorsa, standart indeks yerine full-text veya trigram gibi özel indeks türlerini düşünün.
2) İndeksli sütunlarda fonksiyon kullanmak
Bu görünüşte zararsızdır:
WHERE LOWER(email) = '[email protected]'
Ama LOWER(email) ifadesi sütunu değiştirir, bu yüzden email üzerindeki indeks doğrudan kullanılamaz.
Alternatifler:
- Normalleştirilmiş veriyi saklayın (ör. küçük harfe alınmış e-postalar) ve
WHERE email = ... ile sorgulayın.
- Veya
LOWER(email) için ifade-tabancı (expression/function-based) bir indeks oluşturun (veritabanına bağlıdır).
İnsanların kaçırdığı gizli indeks engelleyiciler
Dolaylı tip dönüşümleri: Farklı veri tiplerini karşılaştırmak bir tarafın implicit olarak dönüştürülmesine yol açabilir ve bu indeksin kullanılmasını engelleyebilir. Örnek: bir integer sütunu string literal ile karşılaştırmak.
Uygun olmayan collation/encoding: Karşılaştırma indeksi oluşturulduğu collation ile uyuşmuyorsa optimizer indeksi kullanmaktan kaçınabilir.
Hızlı kontrol listesi: "İndeksim neden kullanılmıyor?"
- Koşul bir jokerle mi başlıyor (
LIKE '%x')?
- İndeksli sütuna fonksiyon uygulanıyor mu (
LOWER(col), DATE(col), CAST(col)) ?
- Her iki tarafta tipler aynı mı (implicit cast yok mu)?
- Karşılaştırma için collation/locale tutarlı mı?
- Predikat yeterince seçici mi (tablonun büyük kısmını eşlemiyor mu)?
- Bileşik indeksin sol başlık sütunları ile filtreleme/sıralama uyumlu mu?
- Gerçek planı
EXPLAIN ile kontrol ettiniz mi?
İndeks Bakımı: İstatistikler, Bloat ve Uzun Vadeli Sağlık
İndeksler "kur ve unut" değildir. Zamanla veri değişir, sorgu desenleri kayar ve fiziksel yapı bozulur. İyi seçilmiş bir indeks zamanla etkinliğini kaybedebilir ya da zararlı hale gelebilir eğer bakım yapılmazsa.
İstatistikler: planlayıcının haritası güncelliğini yitirebilir
Çoğu veritabanı sorgu planını seçmek için istatistiklere (değer dağılımları, satır sayıları, data skew özetleri) güvenir.
İstatistikler eskidiğinde planlayıcının satır tahminleri vahim derecede yanlış olabilir. Bu da yanlış plan seçimlerine yol açar: çok fazla satır döndüren bir indeksi seçmek ya da hızlı bir indeksi atlamak gibi.
Rutinde yapılacak: düzenli istatistik güncellemeleri (genelde "ANALYZE" veya benzeri). Büyük yüklemeler, büyük silmeler veya yoğun churn sonrası istatistikleri daha erken güncelleyin.
Bloat ve parçalanma: yapılar karmaşıklaştığında
Satırlar eklendikçe, güncellendikçe ve silindikçe indeksler bloat (artık işe yaramayan boş sayfalar) ve fragmentasyon biriktirebilir. Sonuç daha büyük indeksler, daha fazla okuma ve daha yavaş taramalar olabilir—özellikle aralık sorguları için.
Rutinde yapılacak: yoğun kullanılan ve orantısız büyümüş indeksleri periyodik olarak yeniden oluşturun veya yeniden düzenleyin. Tam araçlar ve etkiler veritabanına göre değişir; bu yüzden ölçümlere dayalı şekilde, her zaman dikkatle uygulayın.
Zaman içinde izleyin, sadece bir kez değil
Aşağıyı izleyin:
- yavaş sorgular (gecikme, sıklık, en kötü sağlayıcılar)
- indeks kullanımı (hiç kullanılmayanlar vs. sıcak olanlar)
- indeks boyutu büyümesi ve ani plan değişiklikleri
Bu geri besleme döngüsü hangi bakımın gerektiğini ve hangi indeksin ayarlanması veya kaldırılması gerektiğini yakalamanıza yardımcı olur. Daha fazla doğrulama için /blog/how-to-prove-an-index-helps-explain-and-measurements metnine bakabilirsiniz.
Doğru İndeksi Eklemek İçin Pratik Bir İş Akışı
İndeks eklemek kasıtlı bir değişiklik olmalı, tahmin değil. Hafif iş akışı sizi ölçülebilir kazanımlara odaklar ve "indeks yayılması"nı engeller.
1) Gerçek problem sorgusunu belirleyin
Kanıtla başlayın: yavaş sorgu günlükleri, APM izleri veya kullanıcı şikayetleri. Sık ve yavaş olan bir sorgu seçin—nadir 10 saniyelik bir rapor, sık görülen 200 ms'lik bir aramadan daha az önemlidir.
Tam SQL'i ve parametre kalıbını yakalayın (ör. WHERE user_id = ? AND status = ? ORDER BY created_at DESC LIMIT 50). Küçük farklar hangi indeksin yardımcı olacağını değiştirir.
2) Bir temel ölçüm alın
Mevcut p50/p95 gecikmeyi, taranan satır sayısını ve CPU/IO etkisini kaydedin. Karşılaştırmak için mevcut plan çıktısını (EXPLAIN / EXPLAIN ANALYZE) saklayın.
3) En küçük işe yarar indeksi tasarlayın
Sorgunun filtreleme ve sıralama şekline uyan sütunları seçin. Planın büyük aralıkları taramayı bırakmasını sağlayacak minimal indeksi tercih edin.
Üretime benzer veri hacmine sahip bir staging ortamında test edin. İndeksler küçük veri kümelerinde iyi görünebilir ama ölçeklendiğinde hayal kırıklığı yaratabilir.
4) Güvenli şekilde oluşturun
Büyük tablolarda destekleniyorsa online seçenekleri kullanın (ör. PostgreSQL CREATE INDEX CONCURRENTLY). Veri tabanı yazmaları kilitleyecekse değişiklikleri daha düşük trafikli zamanlara planlayın.
5) Öncesi/sonrası kanıtla doğrula
Aynı sorguyu yeniden çalıştırıp karşılaştırın:
- plan şekli (tam taramadan indeks erişimine mi geçti?)
- yürütme süresi ve taranan satır sayısı
- yazmalar üzerindeki etkisi (insert/update gecikmesi)
6) Geri alma planınız olsun
İndeks yazma maliyetini veya bellek/dep olasılığını artırırsa temizce kaldırın (örn. DROP INDEX CONCURRENTLY kullanılabiliyorsa). Migration'ı tersine çevrilebilir tutun.
7) "Neden"i belgeleyin
Migration veya şema notlarında indeksi hangi sorgunun amaçladığını ve hangi metriğin iyileştiğini yazın. Gelecekte neden var olduğunu ve ne zaman silinebileceğini bilmek faydalıdır.
Bu iş akışında Koder.ai'nın rolü
Yeni bir servis inşa ediyorsanız ve erken dönemde "indeks yayılmasını" önlemek istiyorsanız, Koder.ai tam döngüde hızlı iterasyon yapmanıza yardımcı olabilir: sohbetten React + Go + PostgreSQL uygulaması üretin, şema/indeks migration'larını gereksinimler değiştikçe ayarlayın ve sonra kaynak kodu dışa aktarın. Pratikte bu, “bu endpoint yavaş”tan “işte EXPLAIN planı, minimal indeks ve geri alınabilir migration”a daha hızlı geçmenizi sağlar.
İndeks Yeterli Olmadığında (Sonra Ne Yapmalı)
İndeksler büyük bir kaldıraçtır ama sihirli bir "her şeyi hızlandır" düğmesi değildir. Bazen sorgunun yavaş kısmı veritabanı doğru satırları bulduktan sonra olur—veya sorgu kalıbı indekslemeyi ilk adım olarak yanlış kılar.
İndeksin en iyi çözüm olmadığı durumlar
Eğer sorgu iyi bir indeksi kullanmasına rağmen hâlâ yavaşsa şu nedenlere bakın:
- Eksik veya hatalı sayfalama:
OFFSET 999000 gibi büyük ofsetlerle sayfa çekmek indeks olsa bile yavaş olabilir. Anahtarset (keyset) sayfalamayı tercih edin (ör. son görülen id/timestamp sonrası satırlar).
- Çok fazla veri döndürmek:
SELECT * veya on binlerce kayıt döndürmek ağ, JSON serileştirme veya uygulama tarafı işleme üzerinde darboğaz yaratabilir.
- Şema uyuşmazlıkları: Aşırı normalize join'ler, aranabilir değerlerin JSON/metin blob'larında saklanması veya yanlış veri tipleri indekslerin maskelenemeyecek pahalı işlemlere zorlaması.
Sıkça daha önemli olan tamamlayıcı optimizasyonlar
- Sorguyu yeniden yazın: Gereksiz join'leri kaldırın, indexed sütunlarda fonksiyon kullanmaktan kaçının ve OR ağır predikatları sadeleştirin.
- Sütunları ve satırları sınırlayın: Sadece ihtiyacınız olanı seçin, mantıklı LIMIT ekleyin ve sonuçları kasıtlı olarak sayfalandırın.
- Önbellekleme: Sık okunan verileri uygulama katmanında cache'leyin veya pahalı, tekrarlayan sorgular için read-through cache kullanın.
- Partitioning: Eğer sorgular çoğunlukla "güncel verilere" erişiyorsa zamanla (veya başka doğal sınırlar) partition yaparak arama alanını küçültün.
Daha derin bir darboğaz teşhisi istiyorsanız, bunu /blog/how-to-prove-an-index-helps ile eşleştirerek ölçümlü bir yaklaşım uygulayın.
Öncelik: en büyük darboğazı ilk düzeltin
Tahmin etmeyin. Zamanın nerede harcandığını ölçün (veritabanı yürütmesi vs. döndürülen satırlar vs. uygulama kodu). Eğer veritabanı hızlıysa ama API yavaşsa daha fazla indeks işe yaramayacaktır.
Hızlı kontrol listesi