Sharding Nedir (Ve Neyi Değildir)
Sharding (başka bir deyişle yatay bölümleme), uygulamanıza tek bir veritabanı gibi görünen yapıyı alıp veriyi birden çok makineye, yani shardlara bölmek anlamına gelir. Her shard yalnızca satırların bir alt kümesini tutar; birlikte tam veri kümesini oluştururlar.
Tek mantıksal tablo, birçok fiziksel yer
Yararlı bir zihinsel model, mantıksal yapı ile fiziksel yerleşim arasındaki farktır.
- Mantıksal: hâlâ bir “Users” tablonuz var (aynı sütunlar, aynı anlam).\n- Fiziksel: o tablonun satırları farklı yerlerde depolanır—örneğin 1–1.000.000 arasındaki kullanıcılar shard A'da, sonraki milyon shard B'de olabilir.
Uygulamanın bakış açısından, sorguları tek bir tabloymuş gibi çalıştırmak istersiniz. Alt katta sistem hangi shard(lar)la konuşulacağını belirlemelidir.
Replikasyon değil, “daha büyük bir kutu alma” da değil
Sharding, replikasyondan farklıdır. Replikasyon aynı verinin kopyalarını birden çok düğüme koyar; esas olarak yüksek erişilebilirlik ve okuma ölçeklendirmesi içindir. Sharding ise veriyi böler; her düğüm farklı kayıtları tutar.
Ayrıca dikey ölçeklendirmeden de farklıdır: tek veritabanını daha güçlü bir makineye taşımaktır (daha fazla CPU/RAM/daha hızlı diskler). Dikey ölçeklendirme daha basit olabilir ama pratik sınırları ve maliyetleri vardır.
Sharding'in sihirli bir çözüm olmadığı şeyler
Sharding kapasiteyi artırır, ancak veritabanınızı “kolay” veya her sorguyu otomatik olarak daha hızlı yapmaz.
- Join işlemleri, ilişkili satırlar farklı shard'larda olduğunda pahalılaşabilir.
- İşlemler (transactions) shardlar arasında zordur; tümüyle ya da hiç güncellemeleri koordinasyon gerektirebilir.
- Operasyonel karmaşıklık artar: yönlendirme, yeniden dengeleme, hata ayıklama ve hata işleme sistemin parçası olur.
Bu yüzden sharding depolama ve throughput'u ölçeklendirme yolu olarak en iyi anlaşılmalıdır—her veritabanı davranışını ücretsiz olarak düzeltmez.
Takımlar Neden Shard Yapar: Çözmeye Çalıştığı Sorunlar
Sharding genellikle bir takımın ilk tercihi değildir. Takımlar başarılı bir sistem fiziksel sınırlarına ulaştığında veya operasyonel ağrı dayanılmaz olduğunda sharding'e yönelirler. Motivasyon daha çok "sharding istiyoruz" değil, "tek bir veritabanının tek bir hata noktası ve maliyet olmasını engellemenin bir yolu gerekiyor" şeklindedir.
Takımları shard yapmaya iten ağrı noktaları
Tek bir veritabanı düğümü çeşitli açılardan yer sıkıntısı çekebilir:
- Depolama limitleri: tablolar ve indeksler büyür, disk sıkışır, yedeklemeler yavaşlar ve bakım riskli hâle gelir.
- Yazma throughput limitleri: CPU, WAL/redo veya kilitlenme yazma sayısını sınırlar.
- Okuma throughput limitleri: cache ve replikalar olsa bile bazı iş yükleri primary'i boğar.
- Gürültülü komşular: bir tenant ya da iş yükü modeli kaynakları tekelleştirir ve diğerlerininkini düşürür.
Bu sorunlar düzenli görünüyorsa, genellikle sorun tek bir kötü sorgu değil—bir makinenin çok fazla sorumluluk taşımasıdır.
Amaçlar: ölçeklendirmek, izole etmek ve maliyeti kontrol etmek
Veritabanı sharding'i, veriyi ve trafiği birden çok düğüme yayar; böylece kapasite tek bir makineyi dikey olarak yükseltmek yerine makine ekleyerek büyür. İyi yapılırsa, iş yüklerini izole edebilir (bir tenant'in ani trafiği diğerlerinin gecikmesini bozmaz) ve maliyetleri kontrol altında tutar—çok büyük premium örneklere bağlı kalmadan.
Tavanınıza yaklaştığınızı gösteren erken uyarı işaretleri
Tekrarlayan desenler şunlardır: zirvede p95/p99 gecikmelerinin sürekli artması, replikasyon gecikmesinin uzaması, yedekleme/geri yük süresinin kabul edilebilir pencerenizi aşması ve "küçük" şema değişikliklerinin büyük olaylar haline gelmesi.
Neden sharding genellikle son adım olarak görülür
Karar vermeden önce takımlar genellikle daha basit seçenekleri tüketir: indeksleme ve sorgu düzeltmeleri, cache, read replica'lar, tek veritabanında partition'lama, eski verileri arşivleme ve donanım yükseltmeleri. Sharding ölçek problemini çözebilir ama koordinasyon, operasyonel karmaşıklık ve yeni hata modları getirir—bu yüzden bar yüksek olmalıdır.
Shardlanmış bir veritabanı tek bir şey değildir—işbirliği yapan küçük parçaların bir sistemidir. Sharding'in “anlaşılması zor” hissettirmesinin nedeni, doğruluk ve performansın bu parçaların nasıl etkileştiğine bağlı olmasıdır, sadece veritabanı motoruna değil.
Shardlar: kendi indeksleri olan bağımsız bölümler
Bir shard, verinin bir alt kümesidir ve genellikle kendi sunucusunda veya kümesinde depolanır. Her shard tipik olarak şunlara sahiptir:
- depolama (veri dosyaları)
- indeksler (o shard içinde sorguların hızlı olması için)
- yerel limitler (CPU, bellek, disk, bağlantılar)
Uygulama açısından, shardlanmış bir kurulum genellikle tek bir mantıksal veritabanı gibi görünmeye çalışır. Ama alt katta, tek düğümlü bir veritabanında “bir indeks bakışı” olacak sorgu, bir shard'ı bulma ve ardından aramayı yapma adımına dönüşebilir.
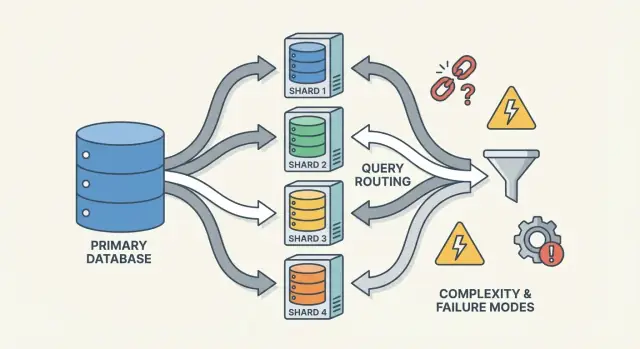
Router/koordinatörler: isteklerin doğru shard'a nasıl ulaştığı
Bir router (bazen koordinatör, sorgu router'ı veya proxy olarak adlandırılır) trafik polisidir. Pratik soru: bu istek verildiğinde, hangi shard bununla ilgilenmeli?
İki yaygın desen vardır:
- İstemci tarafı yönlendirme: uygulama kitaplığı shard haritasını bilir ve doğrudan doğru shard'a bağlanır.
- Proxy yönlendirme: uygulama bir router servisine bağlanır ve router isteği iletir.
Router'lar uygulamadaki karmaşıklığı azaltır, ama dikkatli tasarlanmazsa darboğaz veya yeni bir hata noktası olabilirler.
Sharding metadata'ya dayanır—şunları tanımlayan bir gerçek kaynağı:
- shard haritası (hangi shard hangi aralığı/karma kovasını/ID'yi sahipleniyor)
- sahiplik (özellikle taşımalar sırasında sahiplik geçici olarak çakışabilir)
- sağlık ve üyelik (hangi düğümler up, primary/replica rolleri, draining durumu)
Bu bilgiler genellikle bir konfig servisinde (veya küçük bir kontrol planı veritabanında) tutulur. Metadata eski veya tutarsızsa, tüm shard'lar sağlıklı olsa bile router'lar trafiği yanlış yere gönderebilir.
Arka plan işleri: dengeleme, taşıma ve yedeklemeler
Son olarak, sharding sistemi zaman içinde yaşanabilir tutan arka plan süreçlerine dayanır:
- bir shard diğerlerinden daha hızlı büyüdüğünde yeniden dengeleme
- sahipliği shardlar arasında taşırken yapılan taşımalar
- birçok shard üzerinde çalışan yedekleme/geri yük prosedürleri
Bu işler genellikle başta göz ardı edilir, fakat üretimde birçok sürpriz burada çıkar—çünkü bu işler sistemi trafik hizmet ederken şekillendirir.
Shard Anahtarı Seçmek: İlk Büyük Takas
Bir shard anahtarı, sisteminizin bir satırı/dökümanı hangi shard'a koyacağını belirleyen alandır. Bu tek seçim, sorguların hedeflenip hedeflenmeyeceğini, masrafları ve hangi özelliklerin ileride “kolay” hissedileceğini sessizce belirler—çünkü ortak sorguların tek shard'a mı yoksa birçok shard'a mı gitmesini kontrol eder.
İyi bir shard anahtarını ne yapar
İyi bir anahtar genellikle şunlara sahiptir:
- Yüksek kardinalite: çok sayıda olası değer (ör. ülke yerine
user_id).
- Eşit dağılım: yazma ve okuma yükünü shard'lar arasında yayar.
- Sabit erişim desenleri: bugün ve gelecek çeyrekte nasıl sorgulayacağınızla örtüşür.
Çok kiracılı bir uygulamada tenant_id ile shardlama yaygındır: çoğu okuma ve yazma bir tenant için aynı shard'ta kalır ve tenant'lar yeterince fazla olduğunda yük dağılır.
Kötü bir shard anahtarını ne yapar (ve neden zarar verir)
Bazı anahtarlar neredeyse doğrudan sorun getirir:
- Zamana dayalı monoton anahtarlar (timestamp, auto-increment ID): yeni veriler “en yeni” shard'ta kümelenir, yazma hotspot'ı oluşur.
- Düşük kardinaliteli alanlar (status, plan_tier, country): çok az farklı değer birkaç shard'ın işini üstlenir.
- Değişen tanımlayıcılar (email, değiştirilebilir kullanıcı adları): anahtar değişirse veriyi shardlar arasında taşımak pahalı ve riskli olur.
Düşük kardinaliteli bir anahtar filtreleme için uygun görünse bile, ilgili satırlar her yerde olduğundan rutin sorguları genellikle scatter-gather sorgularına dönüştürür.
Gerçek takas: sorgu kolaylığı vs dağılım kalitesi
Yük dengeleme için en iyi shard anahtarı her zaman ürün sorguları için en iyi anahtar değildir.
- Sık ve gecikme hassas sorgularınızı shard anahtarına göre optimize edin; o zaman bazı “global” sorgular (yönetici raporlaması gibi) daha yavaş veya ayrı boru hatları gerektirebilir.
- Raporlama için bir anahtar seçerseniz (ör.
region), hotspot'lar ve dengesiz kapasite riski alırsınız.
Çoğu takım bu takası göze alır: shard anahtarını en sık ve gecikme açısından kritik işlemler için optimize edin; gerisini indeksler, denormalizasyon, replikalar veya özel analitik tablolarla yönetin.
Yaygın Sharding Stratejileri (Aralık, Hash, Dizin)
Tek bir “en iyi” yol yoktur. Seçtiğiniz strateji sorguların nasıl yönlendirileceğini, verinin ne kadar eşit dağıtılacağını ve hangi erişim desenlerinin problem yaratacağını belirler.
Aralık (range) sharding
Range sharding'de her shard bir anahtar uzayının bitişik bir dilimini sahiplenir—örneğin:
- Shard A: customer_id 1–1.000.000
- Shard B: customer_id 1.000.001–2.000.000
Routing açıktır: anahtara bak ve shard'ı seç.
Ancak hotspot riski vardır. Yeni kullanıcılar hep artan ID alıyorsa, “son” shard yazma darboğazı olur. Aralık sharding ayrıca düzensiz büyümeye duyarlıdır (bir aralık popüler olur, diğeri sessiz kalır). Artı tarafı: aralık sorguları fiziksel olarak gruplanmış veri sayesinde verimli olabilir (ör. "1–31 Ekim arasındaki siparişler").
Hash sharding
Hash sharding anahtarın bir hash fonksiyonundan geçirilip sonuçla shard seçilmesine dayanır. Bu genellikle veriyi daha eşit dağıtır ve en yeni shard'a yığılma sorununu önler.
Takas: aralık sorguları zorlaşır. X ile Y arasındaki ID'leri sorgulamak artık küçük bir shard setine eşlenmeyebilir; birçok shard'ı dokunabilir.
Takımaların sıklıkla hafife aldığı pratik bir detay tutarlı hashing (consistent hashing) kullanmaktır. Doğrudan shard sayısına eşlemek (shard sayısı değişince her şeyi yeniden karıştırır) yerine, birçok sistem hash ring ve “sanal düğümler” kullanır, böylece kapasite eklenince yalnızca bir kısmı taşınır.
Dizin (directory) sharding
Directory sharding, anahtar → shard konumunu açıkça saklayan bir harita/servis kullanır. Bu en esnektir: belirli tenantları özel shardlara koyabilir, bir müşteriyi tek başına taşıyabilir ve düzensiz shard boyutlarını destekleyebilirsiniz.
Dezavantajı ek bir bağımlılıktır. Dizin yavaşsa, eskiyse veya ulaşılmazsa routing zarar görür—shard'lar sağlıklı olsa bile.
Bileşik anahtarlar ve alt-shardlama
Gerçek sistemler genellikle yaklaşımları harmanlar. Bir bileşik shard anahtarı (örn. tenant_id + user_id) tenant'ları izole ederken tenant içinde yükü dağıtır. Alt-shardlama benzer: önce tenant'a göre yönlendir, sonra o tenant'ın shard grubunda hash yaparak tek bir "büyük tenant"ın tek bir shard'ı domine etmesini önle.
Sorgular Nasıl Çalışır: Yönlendirme vs Scatter-Gather
Bir Shard Anahtarı Seçin
Planlama Modunu kullanarak shard anahtarlarını, sorgu yollarını ve taşıma adımlarını kodlamadan önce haritalayın.
Shardlanmış bir veritabanının iki çok farklı “sorgu yolu” vardır. Hangi yolun kullanıldığını anlamak, performanstaki çoğu sürprizi ve neden sharding'in öngörülemez hissettirdiğini açıklar.
Tek-shard sorgular: hızlı yol
İdeal sonuç, sorguyu tam olarak bir shard'a yönlendirmektir. İstek shard anahtarını içeriyorsa veya router bununla eşleyebiliyorsa, sistem doğrudan doğru yere gönderebilir.
Bu yüzden takımlar sık okunanların "shard-key farkında" olmasına takıntılıdır. Tek shard, daha az ağ atlaması, daha basit yürütme, daha az kilit ve çok daha az koordinasyon demektir. Gecikme çoğunlukla veritabanının işi yapmasından gelir, küme üzerinde tartışmadan değil.
Scatter-gather okumalar: fan-out ve kuyruk gecikmesi
Bir sorgu kesin yönlendirilemiyorsa (ör. non-shard-key alanına göre filtreliyorsa), sistem bunu birçok veya tüm shardlara yayınlayabilir. Her shard sorguyu yerel olarak çalıştırır; ardından router (veya koordinatör) sonuçları birleştirir—sıralama, tekrarlardan arındırma, limit uygulama ve kısmi agregatları toplama.
Bu fan-out kuyruk gecikmesini büyütür: 9 shard hızlı cevap verse bile bir yavaş shard tüm isteği rehin alabilir. Ayrıca yükü katlar: bir kullanıcı isteği N shard isteğine dönüşür.
Çapraz-shard join'ler ve agregasyonlar
Shardlar arası join'ler pahalıdır çünkü birlikte olması gereken veriler artık shardlar arasında taşınmak zorundadır (veya bir koordinatöre). Basit agregasyonlar (COUNT, SUM, GROUP BY) bile iki aşamalı plan gerektirebilir: her shard üzerinde kısmi sonuç hesapla, sonra birleştir.
İndeksleme sınırlamaları: lokal vs global
Çoğu sistem varsayılan olarak lokal indeksleri kullanır: her shard yalnızca kendi verisini indeksler. Bunlar bakım açısından ucuzdur ama routing'e yardımcı olmaz—dolayısıyla sorgular yine scatter olabilir.
Global indeksler shard anahtar olmayan alanlarda hedefli yönlendirme sağlayabilir, ama yazma yükünü, ekstra koordinasyonu ve ölçek/tutarlılık zorluklarını artırır.
Yazmalar ve Shardlar Arası İşlemler
Yazmalar, sharding'in "sadece ölçeklendirme" olmaktan çıkıp özelliklerin nasıl tasarlandığını değiştirdiği kısımdır. Tek bir shard'ı dokunan yazma hızlı ve basit olabilir. Mantıksal olarak iki shard'ı etkileyen bir yazma ise yavaş, hata eğilimli ve doğru yapmak açısından şaşırtıcı derecede zor olabilir.
Tek-shard yazmalar: mutlu yol
Her istek tam olarak bir shard'a yönlendirilebiliyorsa (genellikle shard anahtar ile), veritabanı normal transaction mekanizmasını kullanabilir. O shard içinde atomiklik ve izolasyon elde edersiniz; operasyonel problemler tanıdık tek-düğüm sorunlarına benzer.
Çok-shard yazmalar: karmaşıklığın arttığı yer
Mantıksal bir eylem iki shard'ı güncellemesi gerektiğinde (örn. para transferi, siparişi bir müşteriden diğerine taşıma, başka yerde saklanan bir agregatı güncelleme) dağıtık işlem alanına girersiniz.
Dağıtık işlemler zordur çünkü koordinasyon gerektirir: makineler yavaş olabilir, ağ bölünebilir veya yeniden başlatılabilir. İki fazlı commit benzeri protokoller ekstra tur-trip ekler, zaman aşımında bloklanabilir ve hataları belirsizleştirir: koordinatör ölmeden önce shard B değişikliği uyguladı mı? İstemci yeniden denediğinde yazmayı iki kere mi uygularsınız? Yeniden deneme yapılmazsa veri kaybı mı olur?
Çapraz-shard yazmalardan kaçınma desenleri
Sık kullanılan taktikler:
- Veri lokalitesi: ilişkili kayıtları aynı shard'ta tutun (örn. bir müşteriye ait her şey).
- İstek yönlendirme: bir işlemi tek bir shard'ın sahibi olacak şekilde tasarlayın ve diğerlerini salt-okunur kabul edin.
- Denormalizasyon: küçük veri parçalarını çoğaltarak güncellemaların fan-out yapmasını engelleyin.
Idempotency ve yeniden deneme güvenliği
Shardlanmış sistemlerde yeniden denemeler kaçınılmazdır. Yazmaları idempotent yapmak için stabil operasyon ID'leri (örn. idempotency anahtarı) kullanın ve veritabanında "zaten uygulandı" işaretleri saklayın. Böylece zaman aşımı olursa istemci yeniden denediğinde ikinci deneme no-op olur; çift uygulama, yinelenen sipariş veya tutarsız sayaç önlenir.
Tutarlılık ve Replikasyon: Veriyi Doğru Tutmak
Sharding'i Güvenle Prototipleyin
Chat üzerinden shard farkındalığı olan bir servis prototipi oluşturun, ardından anlık görüntüler ve geri alma ile güvenle yineleyin.
Sharding verinizi makineler arasında böler, ama yedeklilik ihtiyacını ortadan kaldırmaz. Replikasyon bir shard'ın bir düğümü öldüğünde onu kullanılabilir tutar—aynı zamanda "şu an ne doğru?" sorusunu daha zor hale getirir.
Her shard içinde replikasyon
Çoğu sistem her shard içinde replikasyon yapar: bir primary (leader) yazmaları kabul eder ve bir veya daha fazla replica bu değişiklikleri kopyalar. Primary düşerse sistem bir replicayı terfi ettirir (failover). Replikalar ayrıca okumaları karşılayarak yükü azaltabilir.
Takas zamanlamadır. Bir read replica milisaniyeler veya saniyeler geride olabilir. Bu boşluk normaldir, ama kullanıcı "az önce güncelledim, şimdi göreceğim" beklentisi olduğunda fark eder.
Tutarlılık modelleri basitçe
- Güçlü tutarlılık: bir yazma başarılı olduktan sonra okuma bunu yansıtır (sistem vaad ettiği perspektiften). Bu genellikle leader'dan okumayı veya replikaların onayını beklemeyi gerektirir.
- Nihai (eventual) tutarlılık: sistem sonunda tutarlı hale gelir, ama bir okuma geçici olarak eski veri dönebilir.
Shard kurulumlarında genellikle bir shard içinde güçlü tutarlılık ve shard'lar arasında daha zayıf garantiler ile karşılaşırsınız, özellikle çok-shard işlemler söz konusu olduğunda.
Veri parçaları bölündüğünde “tek doğru kaynak”
Sharding ile “tek doğru kaynak” genellikle şunu ifade eder: her veri parçası için yazılacak tek bir yetkili yer vardır (genellikle shard'ın leader'ı). Ancak küresel olarak her şeyin en son durumunu anında onaylayabilecek tek bir makine yoktur. Birçok yerel gerçek vardır ve bunlar replikasyon yoluyla senkron tutulmalıdır.
Küresel kısıtlamalar: benzersizlik, yabancı anahtarlar, sayaçlar
Kısıtlamalar farklı shard'larda bulunan verilerle kontrol edilmesi gerektiğinde zordur:
- Benzersizlik (örn. kullanıcı adı): "her yerde tekrar yok"u sağlamak merkezi bir indeks, özel bir "kısıtlama shard'ı" veya uygulama düzeyinde rezervasyon iş akışı gerektirebilir.
- Yabancı anahtarlar: ebeveyn ve çocuk farklı shard'larda ise referans bütünlüğünü kolayca zorlayamazsınız.
- Sayaçlar (küresel toplamlar, ardışık ID'ler): saf yaklaşımlar darboğaz oluşturur. Yaygın çözümler shard başına aralıklar, batch'leme veya yaklaşık sayımları kabul etmektir.
Bu seçimler sadece uygulama detayları değildir—ürününüz için "doğru"nün ne demek olduğunu tanımlar.
Yeniden Dengeleme ve Resharding (Kesinti Olmadan)
Yeniden dengeleme, gerçeklik değiştikçe shardlanmış veritabanını kullanılabilir tutan şeydir. Veri dengesiz büyür, başlangıçta dengeli görünen shard anahtarı çarpıklığa kayar, yeni düğümler eklenir veya donanım emekliye ayrılmalıdır. Bunların her biri bir shard'ı darboğaz haline getirebilir—ilk tasarım mükemmel görünse bile.
Neden zor
Tek bir veritabanının aksine, sharding verinin konumunu routing mantığına yerleştirir. Veri taşırken yalnızca byte kopyalamıyorsunuz—sorguların nereye gitmesi gerektiğini değiştiriyorsunuz. Bu yüzden yeniden dengeleme metadata ve istemciler kadar depolama ile ilgilidir.
Çevrimiçi taşıma deseni (kopyala → örtüşme → kesme)
Çoğu takım canlı bir iş akışı hedefler:
- Kopya: Hedef shard(lar)ı kaynak shard'tan backfill edin, sistem çalışırken.
- Çift yazma (bazı durumlarda çift okuma): Geçiş sırasında yeni değişiklikleri hem eski hem yeni konuma yazın. Okumalar her iki kaynağı da kontrol edebilir (veya "yeni kazanır" kuralı uygulanabilir).
- Cutover: Shard haritasını güncelleyin, böylece router/istemciler yeni konuma trafik gönderir.
- Temizlik: Çift yazmayı durdurun, eski kopyayı kaldırın ve alanı geri kazanın.
Shard haritaları ve istemci davranışı
Bir shard haritası değişikliği, istemciler routing kararını cache'liyorsa kırıcı bir olay olabilir. İyi sistemler routing metadata'sını konfigürasyon gibi ele alır: versiyonlayın, sık yenileyin ve bir istemci taşınmış bir anahtarla karşılaştığında ne olacağını açıkça tanımlayın (yönlendir, yeniden dene veya proxy).
Planlama gereken operasyonel riskler
Yeniden dengeleme genellikle geçici performans düşüşlerine neden olur (ekstra yazmalar, cache çalkantısı, arka plan kopya yükü). Kısmi taşımalar yaygındır—bazı aralıklar önce taşınır—bu yüzden gözlemlenebilirlik ve geri alma planı (ör. haritayı geri çevirme ve çift yazmayı boşaltma) olmadan cutover'a başlamayın.
Sıcak Noktalar ve Çarpıklık: “Eşit Böl” İşe Yaramayınca
Sharding işin yayılacağını varsayar. Sürpriz şu ki, küme kağıt üzerinde "eşit" görünürken üretimde aşırı düzensiz davranabilir.
Sıcak partition'lar (hot keys)
Bir anahtar alanının küçük bir dilimi trafiğin çoğunu çektiğinde hotspot oluşur—örneğin ünlü bir hesap, popüler bir ürün, ağır batch işi yapan bir tenant veya "bugün"ün tüm yazmaları çektiği zaman bazlı anahtar. Bu anahtarlar tek bir shard'a eşlendiğinde o shard darboğaz olur, diğerleri boştadır.
Çarpıklık: veri boyutu vs trafik
"Çarpıklık" tek bir şey değildir:
- Veri çarpıklığı: bir shard daha fazla byte/satır tutar (depolama baskısı, daha uzun yedeklemeler, daha yavaş taramalar).
- Trafik çarpıklığı: bir shard daha fazla QPS veya daha ağır sorgularla uğraşır (CPU doygunluğu, kuyruklanma, gecikme sıçramaları).
Her zaman örtüşmezler: daha az veriye sahip bir shard, en çok istenen anahtarlara sahipse en sıcak olabilir.
Hızlı tespit yöntemleri
Çarpıklığı tespit etmek için gelişmiş izleme gerekmez. Shard başına panolarla başlayın:
- Shard başına p95 gecikme (tek bir shard'ın p95'i diğerlerinden ayrılıyorsa kırmızı bayraktır)
- Shard başına QPS (ve yazma QPS'si)
- Shard başına kullanılan depolama / tablo boyutu
Bir shard'ın gecikmesi QPS ile yükselip diğerleri sabit kalıyorsa, muhtemelen bir hotspot var demektir.
Hafifletmeler
Çözümler genellikle basitlikten ödün verip dengeyi iyileştirir:
- Kayıtları değil trafik dağıtan bir shard anahtarı seçin.
- Sıcak anahtarlar için bucketing/salting uygulayın (tek mantıksal anahtarı birden çok fiziksel kovaya bölün).
- Okuma ağırlıklı sıcak öğeleri cacheleyin.
- Küme koruması için oran sınırlamaları veya tenant başına kota uygulayın.
- Bir shard soğumuyorsa sıcak shard'ı bölün veya sıcak aralıkları taşıyın.
Hata Modları ve Sharded Sistemde Hata Ayıklama
Çapraz Shard Yazmalarını Test Edin
Küçük bir servis içinde idempotency anahtarlarını ve yeniden deneme güvenli yazmaları deneyin.
Sharding yalnızca daha fazla sunucu eklemez—aynı zamanda işlerin ters gitmesi için daha fazla yol ve sorun olduğunda bakılacak daha fazla yer ekler. Birçok olay "veritabanı kapandı" değil, "bir shard kapandı" veya "sistem verinin nerede olduğunu bilemiyor" şeklindedir.
Yaygın hata modları
Tekrar eden desenler şunlardır:
- Bir shard erişilemez (çökme, disk dolması, uzun GC duraklamaları), kısmi kesintilere neden olur: bazı müşteriler çalışır, bazıları başarısız olur.
- Router yanlış yönlendirir, genellikle bir konfig değişiminden veya kötü bir deploy'dan sonra. Yanlış shard'a gönderilen okumalar sessizce boş sonuç döndürebilir.
- Eski veya tutarsız metadata (örn. shard haritası, dizin tablosu). Taşımalar veya bölünmeler sırasında farklı bileşenler aynı anahtarı farklı yönlendiriyor olabilir.
- Kısmi ağ problemleri: router ile bazı shardlar arasındaki zaman aşımı "rastgele" hatalar gibi görünür ve yeniden denemeler yükü arttırır.
Hata ayıklama nasıl değişir
Tek düğümlü bir veritabanında bir logu takip edip bir metrik setine bakarsınız. Sharded bir sistemde, bir isteği shardlar arasında takip eden gözlemlenebilirlik gerekir.
Her istekte correlation ID'leri kullanın ve bunları API katmanından router'lara ve her shard'a kadar taşıyın. Bunu dağıtık izleme (distributed tracing) ile eşleştirerek bir scatter-gather sorguda hangi shard'ın yavaş veya başarısız olduğunu görebilirsiniz. Metrikler shard bazında kırılmalıdır (gecikme, kuyruk derinliği, hata oranı), aksi takdirde sıcak bir shard filo ortalamalarında gizlenir.
Veri doğruluğu olayları
Sharding hataları genellikle doğruluk hataları olarak görünür:
- Yeniden denemeler veya idempotent olmayan yazmalar sonrası kopyalar
- Taşıma veriyi taşıdıktan sonra routing hala eski konuma işaret ettiğinde kaybolan satırlar
- İki metadata görünümü aynı anahtar aralığı için yazmaları kabul ettiğinde split-brain yazmalar
Yedekleme, geri yükleme ve felaket kurtarma
"Veritabanını geri yükle" demek artık "doğru sırada birçok parçayı geri yükle" demektir. Önce metadatayı, sonra her shard'ı geri yüklemeniz ve shard sınırlarının ve routing kurallarının geri yüklenen noktayla eşleştiğini doğrulamanız gerekebilir. DR planları, tutarlı bir küme oluşturabileceğinizi kanıtlayan prova çalışmaları içermelidir—sadece bireysel makineleri kurtarmak yeterli değildir.
Ne Zaman Shard Yapmamalı: Pratik Alternatifler ve Karar Kontrol Listesi
Sharding genellikle “ölçeklendirme düğmesi” olarak görülür, ama aynı zamanda sistem karmaşıklığında kalıcı bir artıştır. Verileri düğümler arası bölmeden performans ve güvenilirlik hedeflerinize ulaşabiliyorsanız, genellikle daha basit bir mimari, daha kolay hata ayıklama ve daha az operasyonel uç durum elde edersiniz.
Tek düğüm mantığını koruyan pratik alternatifler
Sharding'e başlamadan önce tek mantıksal veritabanını koruyan seçenekleri deneyin:
- Daha iyi indeksleme + sorgu optimizasyonu: yavaş yolları önce düzeltin—eksik indeksler, sınırsız sorgular, pahalı join'ler ve N+1 desenleri.
- Cache: Okuma ağırlıklı, stabil yanıtları cache'in arkasına koyun (uygulama seviyesi cache, halka açık içerik için CDN veya sıcak anahtarlar için bellek içi cache).
- Read replica'lar: Yazma yolunu değiştirmeden okuma trafiğini hafifletin (replika gecikmesini kabul ederek).
- Tek düğümde partition'lama: Birçok veritabanı tablo partition'lamayı destekler; bu bakım ve sorgu performansını iyileştirir ama cross-node routing getirmez.
Araçların yardımcı olduğu yerler: shard farkındalıklı servisleri prototipleme
Sharding riskini azaltmanın pratik yollarından biri altyapıyı (routing sınırları, idempotency, taşıma iş akışları ve gözlemlenebilirlik) üretime bağlamadan önce prototiplemektir.
Örneğin, Koder.ai ile chat üzerinden küçük, gerçekçi bir servis hızla kurabilir—genellikle bir React yönetici UI'si artı Go arka ucu ve PostgreSQL—ve shard-anahtar farkındalıklı API'leri, idempotency anahtarlarını ve "cutover" davranışlarını güvenli bir sandbox'ta deneyebilirsiniz. Koder.ai planlama modu, anlık görüntüler/geri alma ve kaynak kodu dışa aktarma desteklediği için shard ile ilgili tasarım kararlarını yineleyip, kodu ve çalışma kitaplarını ana yığınıza geçirene dek test edebilirsiniz.
Sharding'in uygun olduğu ve olmadığı durumlar
Sharding, veri setiniz veya yazma throughput'unuz açıkça tek düğüm sınırlarını aştığında ve sorgu desenlerinizin çoğu shard anahtarıyla güvenle yönlendirilebildiğinde daha uygundur (az çapraz-shard join, minimal scatter-gather sorgu).
Sık ad-hoc sorgular, sık çok-varlıklı işlemler, küresel benzersizlik kısıtları veya takımın operasyonel işi (yeniden dengeleme, resharding, olay müdahalesi) destekleyememesi durumunda sharding kötü bir uyumdur.
Hızlı karar kontrol listesi
Sor:
- İş yükü: Darboğaz CPU, I/O, bellek mi yoksa kilitlenme mi—bunlar sharding olmadan düzeltilebilir mi?
- Sorgu desenleri: Kritik sorguların %90+'ı shard anahtarıyla yönlendirilebilir mi?
- Takım kapasitesi: Shard haritasını, on-call runbook'ları ve çapraz-shard işlem davranışını kim yönetecek?
- SLO'lar: Bir shard'in düşmesi ve kuyruk gecikmelerinin uzaması gibi kısmi bozulmalara toleransınız var mı?
Büyüme için plan yapın, sadece bir diyagram değil
Sharding'i erteleseniz bile, bir taşıma yolu tasarlayın: ileride engel olmayacak kimlikler seçin, tek-düğüm varsayımlarını kodlamaktan kaçının ve veriyi minimum kesintiyle nasıl taşıyacağınızı prova edin. En iyi zaman resharding'i planlamak, ihtiyacınız olmadan önce olandır.