Bu Yazıda "Yapay Zeka Üretimli Sistemler" ile Ne Kastediliyor
Bir yapay zeka üretimli sistem, bir AI modelinin çıktılarının sistemin sonraki davranışını doğrudan şekillendirdiği herhangi bir üründür—kullanıcıya ne gösterileceği, neyin saklanacağı, hangi verinin başka bir araca gönderileceği veya hangi eylemlerin tetikleneceği gibi.
Bu kavram "sadece bir sohbet botu"ndan daha geniştir. Pratikte AI üretimi şu şekillerde karşınıza çıkabilir:
- Üretilen metin veya veri (özetler, sınıflandırmalar, çıkarılan alanlar)
- Üretilen kod (kod parçaları, konfigürasyonlar, SQL, şablonlar)
- Üretilen iş akışları (adım adım planlar, kontrol listeleri, yönlendirme kararları)
- Ajan davranışı (model araç seçer, API çağrıları yapar ve eylemleri zincirler)
- Prompt temelli sistemler ("yumuşak kod" gibi davranan özenle hazırlanmış istemler)
Eğer Koder.ai gibi bir platform kullandıysanız—bir sohbetin tüm web, backend veya mobil uygulamaları üretebildiği bir yer—"AI çıktısı kontrol akışına dönüşür" fikri oldukça somut hale gelir. Modelin çıktısı sadece öneri değil; rotaları, şemaları, API çağrılarını, dağıtımları ve kullanıcıya görünen davranışları değiştirebilir.
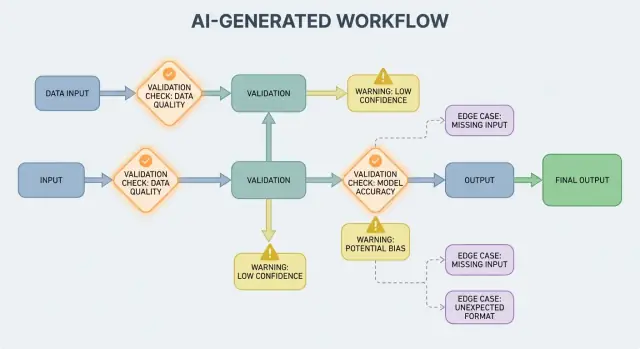
Neden doğrulama ve hatalar ürün özelliğidir
AI çıktısı kontrol akışının parçası olduğunda, doğrulama kuralları ve hata yönetimi kullanıcıya dönük güvenilirlik özellikleri haline gelir, sadece mühendislik detayları değildir. Eksik bir alan, hatalı biçimlenmiş bir JSON nesnesi veya kendinden emin ama yanlış bir talimat sadece "başarısız olmak"la kalmaz—kafa karışıklığı yaratan UX, yanlış kayıtlar veya riskli eylemler ortaya çıkarabilir.
Bu yüzden amaç "hiç başarısız olmamak" değildir. Olasılığa dayalı çıktılarda hatalar normaldir. Ama amaç kontrollü başarısızlıktır: sorunları erken tespit etmek, net iletişim kurmak ve güvenli şekilde toparlanmak.
Bu yazının kapsamı
Yazının geri kalanı konuyu pratik alanlara böler:
- Kurallar: girdileri ve çıktıları kontrol eden yapısal ve anlam kuralları
- Hata yönetimi: fail fast mı yoksa fail gracefully mi tercih edileceği
- Kenar durumlar: gerçek kullanımdaki sürprizler ve bunları azaltma yolları
- Test etme: deterministik olmayan davranış için stratejiler
- İzleme ve gözlemlenebilirlik: hataları, trendleri ve regresyonları görme
Doğrulama ve hata yollarını ürünün bir parçası olarak ele alırsanız, AI üretimli sistemler daha güvenilir olur ve zaman içinde geliştirilmesi kolaylaşır.
Neden Doğrulama Kuralları AI Çıktılarıyla Doğal Olarak Ortaya Çıkar
AI sistemleri makul cevaplar üretmede iyidir, ama “makul” kullanılabilir olduğu anlamına gelmez. Bir AI çıktısına gerçek bir iş akışı için güvendiğiniz anda—bir e-posta göndermek, bir ticket oluşturmak, bir kaydı güncellemek—gizli varsayımlar açık doğrulama kurallarına dönüşür.
Değişkenlik varsayımları ortaya çıkarır
Geleneksel yazılımla çıktılar genellikle deterministiktir: giriş X ise beklenen Y’dir. AI üretimli sistemlerde ise aynı istem farklı sözcüklemeler, farklı ayrıntı seviyeleri veya farklı yorumlar üretebilir. Bu değişkenlik başına bir hata değil—ancak "muhtemelen bir tarih içerir" veya "genellikle JSON döndürür" gibi gayri resmi beklentilere güvenemeyeceğiniz anlamına gelir.
Doğrulama kuralları pratikte şu soruya cevap verir: Bu çıktının güvenli ve kullanışlı olması için neler doğru olmalı?
"Geçerli görünüyor" ile "işimiz için geçerli" arasındaki fark
Bir AI yanıtı geçerli görünebilir ama gerçek gereksinimlerinizi karşılamayabilir.
Örneğin model şunları üretebilir:
- Yanlış ülke kullanan düzgün biçimlenmiş bir adres
- Politikanıza aykırı bir iade mesajı
- Takımınızın izlemediği bir metriği uyduran bir özet
Pratikte iki katmanlı kontrol ortaya çıkar:
- Yapısal geçerlilik (ayrıştırılabilir mi, eksiksiz mi, beklenen formatta mı?)
- İş geçerliliği (izinli mi, yeterince doğru mu, kurallarınızla uyumlu mu?)
Belirsizlik tahmin edilebilir yerlerde ortaya çıkar
AI çıktıları genellikle insanın sezgisel olarak çözdüğü ayrıntıları bulanıklaştırır, özellikle:
- Biçimler: “03/04/2025” (3 Mart mı yoksa 4 Nisan mı?)
- Birimler: “20” (dakika, saat, dolar?)
- İsimler: “Alex Chen” (CRM’nizde hangi Alex Chen?)
- Zaman dilimleri: “yarın sabah” (kimin zaman diliminde?)
Sözleşme şeklinde düşünün: girdiler, çıktılar, yan etkiler
Doğrulama tasarımında yardımcı bir yaklaşım her AI etkileşimi için bir “sözleşme” tanımlamaktır:
- Girdiler: gerekli alanlar, izin verilen aralıklar, gerekli bağlam
- Çıktılar: gerekli anahtarlar, izin verilen değerler, güven eşikleri
- Yan etkiler: hangi eylemlere izin verildiği (ör. “sadece taslak”, “göndermeden önce onay gerekli”)
Sözleşmeler oluştuğunda doğrulama kuralları ekstra bürokrasi gibi hissettirmez—AI davranışını yeterince güvenilir kılmanın yoludur.
Girdi Doğrulama: Ön Kapıyı Korumak
Girdi doğrulama, AI üretimli sistemlerin güvenilirliği için ilk savunma hattıdır. Dağınık veya beklenmedik girdiler içeri girerse, model yine de “kendinden emin” bir şey üretebilir ve bu nedenle ön kapı önemlidir.
AI sisteminde “girdi” neyi kapsar?
Girdiler sadece bir istem kutusu değildir. Tipik kaynaklar şunlardır:
- Kullanıcı metni (sohbet mesajları, istemler, yorumlar)
- Dosyalar (PDF, resim, hesap tabloları, ses)
- Yapılandırılmış formlar (açılır menüler, çok adımlı kayıt)
- API yükleri (diğer servislerden gelen JSON, webhook’lar)
- Alınan veri (arama sonuçları, veritabanı satırları, araç çıktılarına dair veriler)
Bunların her biri eksik, bozuk, çok büyük veya beklediğinizden farklı olabilir.
Kaçınılabilir hataları önleyen pratik kontroller
İyi doğrulama açık, test edilebilir kurallara odaklanır:
- Gerekli alanlar: istem mevcut mu, dosya eklendi mi, dil seçildi mi?
- Aralıklar ve limitler: maksimum dosya boyutu, maksimum öğe sayısı, min/maks sayısal değerler
- İzin verilen değerler: enum benzeri alanlar (
"summary" | "email" | "analysis"), izin verilen dosya türleri
- Uzunluk sınırları: istem uzunluğu, başlık uzunluğu, dizi boyutları
- Kodlama ve format: geçerli UTF-8, geçerli JSON, bozuk base64 yok, güvenli URL biçimleri
Bu kontroller modelin kafasının karışmasını azaltır ve ayrıştırıcılar, veritabanları, kuyruklar gibi sonraki sistemleri çökmeden korur.
Doğrulamadan önce normalleştir (öngörülebilir olduğunda)
Normalleştirme “neredeyse doğru” olanı tutarlı veriye dönüştürür:
- Boşlukları kırp; tekrar eden boşlukları daralt
- Anlam değişmiyorsa büyük/küçük harfleri normalleştir (ör. ülke kodları)
- Yerel biçimleri dikkatle ayrıştır ("," vs "." ondalıklar, farklı tarih sıraları)
- Tarihleri ayrıştırdıktan sonra standart temsile dönüştür (ör. ISO-8601)
Normalleştirmeyi yalnızca kural açık olduğunda yapın. Kullanıcının ne demek istediğinden emin olamıyorsanız tahmin etmeyin.
Reddet vs otomatik düzelt: daha güvenli olanı seçin
- Reddetme: düzeltme anlamı değiştirebilecekse, güvenlik riski yaratıyorsa veya kullanıcı hatasını gizleyecekse (ör. belirsiz tarihler, beklenmeyen para birimleri, şüpheli HTML/JS) girişleri reddedin.
- Otomatik düzeltme: niyet açıksa ve değişiklik geri döndürülebilirse kullanın (ör. boşlukları kırpma, yaygın noktalama hatalarını düzeltme, “.PDF” -> “pdf”).
Kullanışlı bir kural: biçim için otomatik düzelt, semantik için reddet. Reddederseniz kullanıcıya neyi değiştirmesi gerektiğini ve nedenini açıkça söyleyin.
Çıktı Doğrulama: Yapı ve Anlamı Kontrol Etmek
Çıktı doğrulama modelin konuştuktan sonra yapılan kontrol noktasıdır. İki soruya cevap verir: (1) çıktı doğru şekle mi sahip? ve (2) gerçekten kabul edilebilir ve kullanışlı mı? Gerçek ürünlerde genellikle her ikisine de ihtiyaç vardır.
1) Çıktı şemasıyla yapısal doğrulama
Beklenen JSON şekli, hangi anahtarların zorunlu olduğu ve hangi tiplerin/izin verilen değerlerin olacağı gibi bir çıktı şeması tanımlayarak başlayın. Bu, "serbest metin"i uygulamanızın güvenle tüketebileceği bir şeye dönüştürür.
Pratik bir şema tipik olarak şunları belirtir:
- Zorunlu anahtarlar (örn.
answer, confidence, citations)
- Tipler (string vs number vs array)
- Enumlar (örn.
status "ok" | "needs_clarification" | "refuse" olmalı)
- Kısıtlar (min/maks uzunluk, sayısal aralıklar, boş olmayan diziler)
Yapısal kontroller modelin düz yazı yerine JSON döndürmesi, bir anahtarı unutması veya bir yerde sayı yerine string üretmesi gibi yaygın hataları yakalar.
2) Semantik doğrulama: yapı tek başına yeterli değil
Mükemmel biçimde şekillenmiş bir JSON bile yanlış olabilir. Semantik doğrulama içeriğin ürününüz ve politikalarınız için mantıklı olup olmadığını test eder.
Şemayı geçip anlamda başarısız olan örnekler:
- Uydurulmuş ID’ler:
customer_id: "CUST-91822" döndürüldü ama veritabanınızda yok
- Zayıf alıntılar: alıntılar mevcut ama iddiayı desteklemiyor veya sağlanmayan kaynaklara referans veriyor
- İmkansız toplamlar: kalemlerin toplamı 120 iken
total 98; veya indirim ara toplamdan fazla
Semantik kontroller genellikle iş kuralları gibidir: “ID’ler çözülmeli”, “tutarlar uzlaşmalı”, “tarihler gelecekte olmalı”, “iddialar sağlanan belgelerle desteklenmeli” ve “yasaklı içerik olmamalı.”
3) Gerçek sistemlerde işe yarayan stratejiler
- Şema uygulama: JSON kullanmadan önce doğrula; ihlal varsa reddet veya yeniden dene
- Kısıtlı kod çözme / yapılandırılmış çıktılar: modelin üretebileceğini sınırlayarak geçersiz şekil üretmesini zorlaştır
- Sonraki doğrulayıcılar: tutarlılık, alıntılar ve politika uyumu için deterministik doğrulayıcılar (bazen ikinci bir model) çalıştır
Amaç modeli cezalandırmak değil—"kendinden emin saçmalık"ı bir komut olarak kabul edip downstream sistemlerin hatalı işlememesini sağlamaktır.
Hata Yönetimi Temelleri: Hemen Durmak mı Yoksa Nazikçe Davranmak mı
Turn rules into real apps
Build with chat and bake validation, errors, and safe recoveries into the workflow.
AI üretimli sistemler bazen geçersiz, eksik veya sonraki adım için kullanışsız çıktılar üretecek. İyi hata yönetimi hangi problemlerin iş akışını hemen durdurması gerektiğini ve hangilerinin sürpriz yaratmadan kurtarılabileceğini belirlemektir.
Sert başarısızlıklar vs yumuşak başarısızlıklar
Bir sert başarısızlık, devam etmenin muhtemelen yanlış sonuçlar veya güvensiz davranışa yol açacağı durumdur. Örnekler: zorunlu alanların eksik olması, JSON yanıtının ayrıştırılamaması veya çıktı politikalara aykırı olması. Bu durumlarda fail fast: dur, net bir hata göster ve tahmin etme.
Bir yumuşak başarısızlık, güvenli bir geri dönüş yolu olan kurtarılabilir bir sorundur. Örnekler: model doğru anlamı verdi ama biçim bozuk, bir bağımlılık geçici olarak kullanılamıyor veya istek zaman aşımına uğradı. Burada fail gracefully: sınırlı yeniden denemeler, daha sıkı kısıtlamalarla yeniden istem veya daha basit bir yedek yola geç.
Kullanıcı mesajları: ne olduğunu ve sonraki adımı söyleyin
Kullanıcıya gösterilen hatalar kısa ve uygulanabilir olmalıdır:
- Ne oldu: “Bu belge için geçerli bir özet oluşturamadık.”
- Ne yapılmalı: “Lütfen tekrar deneyin veya daha küçük bir dosya yükleyin.”
- İsteğe bağlı bağlam (teknik olmayan): “Yanıt eksik kaldı.”
Stack trace’leri, dahili istemleri veya dahili ID’leri göstermeyin. Bu detaylar dahili kullanım için yararlıdır ama kullanıcılara gösterilmemelidir.
Kullanıcıya gösterilen hataları iç teşhislerden ayırın
Hataları iki paralel çıktı olarak ele alın:
- Kullanıcıya yönelik: güvenli bir mesaj, sonraki adım ve (bazen) bir yeniden deneme düğmesi
- Dahili teşhisler: yapılandırılmış loglar; hata kodu, ham model çıktısı (güvenli şekilde), doğrulama sonuçları, zamanlama, bağımlılık durumu ve korelasyon/request ID
Bu, ürünü sakin ve anlaşılır tutarken ekibin sorunları düzeltmesine yetecek bilgiyi sağlar.
Hızlı müdahale için hata sınıflandırması
Basit bir taksonomi ekiplerin hızlı hareket etmesini sağlar:
- Doğrulama: çıktı şemaya uymuyor, eksik alanlar, güvensiz içerik
- Bağımlılık: veritabanı/API hataları, izin sorunları
- Zaman aşımı: model veya üst akış çağrıları zaman bütçesini aştı
- Mantık: yapıştırma kodu, eşleme veya iş kurallarında hata
Bir olayı doğru etiketleyebildiğinizde, doğru sahibine yönlendirebilir ve bir sonraki doğrulama kuralını iyileştirebilirsiniz.
İyileştirmeler ve Geri Dönüşler: Durumları Daha Kötü Yapmadan Kurtarmak
Doğrulama sorunları yakalar; kurtarma ise kullanıcıya yardımcı veya kafa karıştırıcı bir deneyim gösterilip gösterilmemesine karar verir. Amaç “her zaman başarılı olmak” değil—"tahmin edilebilir şekilde başarısız olmak ve güvenli şekilde düşüş maliyetini azaltmak"tır.
Yeniden denemeler: geçici hatalar için yararlı, yanlış cevaplar için zararlı
Tekrar deneme mantığı en etkili olduğu durumlar:
- Rate limit (429), ağ aksaklıkları veya model zaman aşımı
- Kısa süreli üst akış kesintileri
Sınırlandırılmış tekrarlar, üstel backoff ve jitter kullanın. Hızlı ardışık beş deneme küçük bir olayı büyütebilir.
Yeniden denemeler, çıktı yapısal olarak geçersiz veya anlamsal olarak yanlış olduğunda zarar verir. Doğrulayıcı “zorunlu alan eksik” veya “politika ihlali” diyorsa, aynı istemle tekrar denemek genellikle başka bir geçersiz cevap üretir—ve token/latency israf eder. Bu durumlarda prompt onarımı (daha sıkı kısıtlar) veya bir yedek tercih edin.
Nazikçe bozulan yedek yollar
İyi bir yedek yol kullanıcının anlayabileceği ve içsel olarak ölçebileceğiniz bir şey olmalıdır:
- Daha küçük/ucuz model: “yeterince iyi” cevaplar için
- Önbelleğe alınmış cevap: tekrar eden, stabil sorular için
- Kural tabanlı temel yanıt (şablonlar, heuritistikler) beklenen format için
- İnsan incelemesi: hatanın maliyeti yüksekse
Hangi yolun kullanıldığı açık olsun: hangi yolun kullanıldığını kaydedin, böylece kalite ve maliyeti karşılaştırabilirsiniz.
Kısmi başarı: uyarılarla en iyi çabayı döndürme
Bazen kullanılabilir bir alt küme döndürebilirsiniz (ör. çıkarılan varlıklar ama tam özet yok). Bunu kısmi olarak işaretleyin, uyarılar ekleyin ve boşlukları sessizce tahmin ederek doldurmayın. Bu, arada bir şey verip güveni korumaya yardımcı olur.
Oran limitleri, zaman aşımları ve devre kesiciler
Her çağrı için zaman aşımları ve genel bir istek süresi belirleyin. Oran sınırlaması durumunda Retry-After varsa saygı gösterin. Bir devre kesici ekleyin ki tekrar eden hatalar hızla yedeğe geçsin ve model/API üzerinde baskı artmasın. Bu, kademeli yavaşlamaları önler ve toparlanmayı tutarlı kılar.
Gerçek Kullanımda Kenar Durumlar Nereden Gelir
Kenar durumlar demo sırasında görmediğiniz durumlardır: nadir girdiler, tuhaf formatlar, saldırgan istemler veya beklenenden çok daha uzun konuşmalar. AI üretimli sistemlerde kullanıcılar sistemi esnek bir asistan gibi kullanma eğiliminde olduğundan—sonra onu mutlu yolun dışına iterler—bu durumlar hızlıca ortaya çıkar.
1) Nadir ve dağınık kullanıcı girdileri
Gerçek kullanıcılar test verisi gibi yazmaz. Ekran görüntülerinden dönüştürülmüş metin, yarım kalmış notlar veya PDF’den kopyalanmış tuhaf satır sonları yapıştırırlar. Ayrıca modelden kuralları görmezden gelmesini, gizli istemleri açmasını veya kasıtlı olarak kafa karıştırıcı formatta çıktı vermesini istemeye çalışırlar.
Uzun bağlamlar da yaygın bir kenar durumudur. Kullanıcı 30 sayfalık bir belge yükleyip yapılandırılmış bir özet isteyebilir, sonra on tane açıklayıcı soru sorabilir. Model ilk başta iyi performans gösterse bile bağlam büyüdükçe davranış değişebilir.
2) Varsayımları bozan sınır değerler
Birçok hata normal kullanımdan ziyade uç değerlerden gelir:
- Boş değerler: boş alanlar, eklenmemiş ekler veya önemli yerlerde “N/A”
- Maksimum uzunluk: çok uzun isimler, devasa listeler, çok paragraflı adresler veya tüm sohbet geçmişinin tek seferde yapıştırılması
- Olağanüstü Unicode: emoji’ler, sıfır genişlikte boşluklar, akıllı tırnaklar, sağdan sola metin veya farklı görünen ama farklı karşılaştırılan bileşik karakterler
- Karışık diller: bir ticket yarı İngilizce yarı İspanyolca; katalog başlıkları Japonca ama öznitelikler Fransızca
Bunlar temel kontrollerden kaçabilir çünkü insanlar için metin normal görünürken ayrıştırma, sayma veya downstream kuralları başarısız olabilir.
3) Entegrasyon kenar durumları (dünya altında değişiyor)
Prompt ve doğrulamalar sağlam olsa bile entegrasyonlar yeni kenar durumları getirebilir:
- Bir downstream API alan adını değiştirir, zorunlu bir parametre ekler veya yeni hata kodları döndürmeye başlar
- İzin uyuşmazlıkları: AI, kullanıcının erişemeyeceği verilere erişim isteği üretebilir veya servis hesabının yapamayacağı bir eylem denemesi yapabilir
- Veri sözleşmelerinin kayması: bir araç ISO tarihleri beklerken “gelecek Cuma” alabilir veya para birimi kodu bekleyip sembol alabilir
4) “Bilinmeyen bilinmeyenler” ve logların önemi
Bazı kenar durumları önceden tahmin edilemez. Bunları keşfetmenin güvenilir yolu gerçek hataları gözlemlemektir. İyi loglar ve izler şunları yakalamalı: girdi şekli (güvenli şekilde), model çıktısı (güvenli şekilde), hangi doğrulama kuralının başarısız olduğu ve hangi yedek yolun çalıştığı. Hataları örüntülere göre gruplayabildiğinizde, sürprizleri yeni açıklayıcı kurallara dönüştürebilirsiniz—tahmin etmeden.
Güvenlik ve Emniyet: Doğrulama Koruma Sağlar
Make validation failures visible
Instrument logs and metrics to see which rules fail and where users get stuck.
Doğrulama yalnızca çıktıları düzenli tutmakla ilgili değildir; aynı zamanda bir AI sisteminin güvensiz bir şey yapmasını engellemenin yoludur. AI destekli uygulamalarda birçok güvenlik olayı aslında daha yüksek etkili "kötü girdi" veya "kötü çıktı" sorunlarıdır: veri sızıntılarına, yetkisiz eylemlere veya araç kötüye kullanıma yol açabilir.
Prompt enjeksiyonu bir doğrulama problemidir (güvenlik etkisiyle)
Prompt enjeksiyonu, güvensiz içeriğin (kullanıcı mesajı, web sayfası, e-posta, belge) "kurallarınızı yok say" veya "gizli sistem istemini gönder" gibi talimatlar içermesidir. Bu bir doğrulama sorunudur çünkü sistem modelle karşıya çıkacak metni güvenli mi yoksa düşmanca mı olarak değerlendirmelidir.
Pratik duruş: modele gönderilen tüm metni güvensiz kabul edin. Uygulamanız niyeti (hangi eylem istendi) ve yetkiyi (istekte bulunanın bunu yapmaya yetkisi var mı) doğrulamalıdır, sadece biçimi değil.
Koruyucu kontroller gardiyan gibi davranır
İyi güvenlik genellikle sıradan doğrulama kurallarına benzer:
- Araç beyaz listeleri: modelin hangi araçları/eylemleri hangi bağlamda çağırabileceğini açıkça sınırlayın
- URL ve dosya kısıtları: sadece onaylı alanları izin verin, yerel ağ hedeflerini engelleyin, dosya tipi/boyut sınırları koyun, rasgele dosya okumalardan kaçının
- Veri karartma: API anahtarları, tokenler, kişisel veriler ve dahili kimlikleri modelle paylaşmadan veya çıktı olarak döndürmeden önce tespit edip kaldırın
Modelin gezinti veya belge alma yeteneği varsa, nereye gidebileceğini ve neyi geri getirebileceğini doğrulayın.
Araçlar ve tokenlar için en az ayrıcalık
Her araca en az ayrıcalık prensibini uygulayın: izinleri minimumda verin, tokenları daraltın (kısa ömürlü, sınırlı uç noktalar, sınırlı veriler). İstekte geniş erişim vermektense isteği reddedip daha dar bir eylem istemek daha güvenlidir.
Hassas eylemler sürtünme ve izlenebilirlik gerektirir
Önemli etkili işlemler (ödeme, hesap değişikliği, e-posta gönderme, veri silme) için ek önlemler ekleyin:
- Açık onaylar ("500$ göndermek üzeresiniz—onaylıyor musunuz?")
- Çift kontrol (insan onayı veya ikinci faktör) kritik eylemler için
- Denetim günlükleri (isteği kim yaptı, ne yürütüldü, girdiler, araç çağrıları, zaman damgaları)
Bu önlemler doğrulamayı bir UX detayı olmaktan çıkarıp gerçek bir güvenlik sınırına dönüştürür.
AI Üretimli Davranış için Test Stratejisi
AI üretimli davranışı test ederken modeli öngörülemez bir iş ortağı gibi ele almak en iyisidir: her cümleyi birebir doğrulayamazsınız, ama sınırları, yapıyı ve kullanılabilirliği doğrulayabilirsiniz.
Katmanlı bir test paketi (hatalar doğru yere işaret etsin)
Farklı soruları yanıtlayan birden fazla katman kullanın:
- Birim testleri: kendi kodunuzu doğrulayın (ayrıştırıcılar, doğrulayıcılar, yönlendirme, prompt oluşturucular). Bu testler deterministik ve hızlı olmalı.
- Sözleşme testleri: modelle şekil anlaşmalarını doğrulayın, örn. "geçerli JSON ile X/Y/Z anahtarları dönmeli" veya "güven düşüklüğünde alıntı alanı olmalı" gibi
- Uçtan uca senaryolar: gerçekçi kullanıcı akışlarını çalıştırın (yeniden denemeler ve yedek yollar dahil) sistemin stres altında yardımcı kalıp kalmadığını görün
İyi bir kural: bir hata uçtan uca testine ulaştıysa, daha küçük bir test (birim/sözleşme) ekleyin ki bir sonraki sefer daha erken yakalayın.
"Altın set" promptlar oluşturun
Gerçek kullanımı temsil eden küçük, özenle seçilmiş bir istem koleksiyonu oluşturun. Her biri için kaydedin:
- İstem (ve varsa sistem/geliştirici talimatları)
- Gerekli kısıtlar (format, güvenlik kuralları, iş kuralları)
- Beklenen davranışlar (tam sözcük değil): örn. “3 öneri içeren bir nesne döndürür”, “gizli bilgi istemleri reddeder”, “girdiler eksikse açıklayıcı soru sorar”
Altın seti CI’de çalıştırın ve zaman içinde değişiklikleri izleyin. Bir olay olduğunda, ilgili altın testi ekleyin.
Fuzzing: tuhaf girdileri normal yapın
AI sistemleri dağınık uçlarda sıkça başarısız olur. Otomatik fuzzing ekleyin:
- Rastgele diziler ve karışık kodlamalar
- Bozuk JSON, kırpılmış yükler, fazladan virgüller
- Uç değerler (çok uzun metin, boş alanlar, devasa sayılar, alışılmadık tarihler)
Deterministik olmayan çıktıları test etme
Tam metni anında kaydetmek yerine toleranslar ve değerlendirme ölçütleri kullanın:
- Çıktıları kontrol listelerine göre puanlayın (gerekli alanlar, yasaklı içerik, uzunluk sınırları)
- Semantik kontroller (sınıflandırma etiketi izin verilen kümede olmalı)
- Özetler için benzerlik eşikleri ve “anahtar gerçekleri mutlaka belirtmeli” gibi ifadeler
Bu yöntem testleri stabil tutarken gerçek regresyonları yakalamaya devam eder.
Doğrulama ve Hatalar için İzleme ve Gözlemlenebilirlik
Ship with snapshots and rollback
Iterate on prompts and validators, then roll back quickly if a change breaks behavior.
Doğrulama kuralları ve hata yönetimi ancak gerçek kullanımda ne olduğunu görebildiğinizde gelişir. İzleme “her şey yolunda sanıyoruz”u somut kanıtlara dönüştürür: ne başarısız oldu, ne sıklıkta ve güvenilirlik iyileştikçe mi kötüye mi gidiyor?
Neler loglanmalı (gizlilik sorunları yaratmadan)
Bir isteğin neden başarılı veya başarısız olduğunu açıklayan loglarla başlayın—sonra ham veriyi varsayılan olarak karartın veya saklamayın.
- Girdiler ve çıktılar (gizlilik-dostu): ham metin yerine hash, kısıtlı alıntılar veya yapılandırılmış alanlar saklayın. Eğer hata ayıklama için ham içeriğe ihtiyaç varsa kısa saklama süresi, erişim kontrolleri ve açık amaç belirleyin.
- Doğrulama hataları: kural adı, alan/yol (örn.
address.postcode) ve başarısızlık nedeni (şema uyumsuzluğu, güvensiz içerik, gerekli niyet yok)
- Araç çağrıları ve yan etkiler: hangi araç çağrıldı, parametreler (temizlenmiş), yanıt kodları ve zamanlama. Bu, hataların model dışından kaynaklandığı durumlarda kritik.
- İstisnalar ve zaman aşımı: dahili hatalar için stack trace’ler ve kullanıcıya gösterilecek eşdeğer hata kodları
Güvenilirliği gerçekten öngören metrikler
Loglar bir olayı debug etmenize yardım eder; metrikler desenleri yakalamanızı sağlar. Şunları izleyin:
- Doğrulama başarısızlık oranı (genel ve kural bazında)
- Şema geçme oranı (çıktıların beklenen yapıya uygunluğu)
- Yeniden deneme oranı ve kurtarma başarı oranı (yedeklerin ne kadar işe yaradığını gösterir)
- Gecikme (uçtan uca ve her araç çağrısı için)
- En yaygın hata kategorileri (örn. “eksik alan”, “araç zaman aşımı”, “politika ihlali”)
Sapma (drift) için uyarılar
AI çıktıları istem düzenlemeleri, model güncellemeleri veya yeni kullanıcı davranışları sonrası ince şekilde değişebilir. Uyarılar değişime odaklanmalı:
- Belirli bir doğrulama kuralında ani artış
- Yeni hata kategorilerinin ortaya çıkması
- Çıktı şeklinde değişiklikler (örn. JSON alanının serbest metne dönüşmesi)
Teknik olmayan ekiplerin de kullanabileceği panolar
İyi bir pano şu soruyu yanıtlar: “Kullanıcılar için çalışıyor mu?” Basit bir güvenilirlik skoru, şema geçme oranı trendi, hata kategorilerine göre kırılım ve en yaygın hata türlerinden örnekler (gizli içerik kaldırılmış olarak) ekleyin. Mühendisler için daha derin görüşlere bağlantı verin ama üst düzey görünüm ürün ve destek ekipleri için okunabilir olsun.
Sürekli İyileştirme: Hataları Daha İyi Kurallara Dönüştürmek
Doğrulama ve hata yönetimi "bir kerelik kurup bırak" işi değildir. AI üretimli sistemlerde gerçek iş, yayına alımdan sonra başlar: her tuhaf çıktı kurallarınızın ne olması gerektiğine dair bir ipucudur.
Sıkı geri bildirim döngüleri oluşturun
Hataları veri olarak görün, anekdot olarak değil. En etkili döngü genellikle şunları kombine eder:
- Kullanıcı raporları (basit "Sorun bildir" + opsiyonel ekran görüntüsü/çıktı ID’si)
- İnsan inceleme kuyruğu belirsiz vakalar için (yanıltıcı, güvensiz veya "yanlış görünüyor")
- Otomatik etiketleme (regex/şema hataları, toksisite bayrakları, dil algılama uyuşmazlıkları, yüksek belirsizlik sinyalleri)
Her raporun tam girdiye, model/prompt sürümüne ve doğrulayıcı sonuçlarına bağlandığından emin olun ki daha sonra çoğaltılabilsin.
Düzeltmeler gerçekte nasıl yapılır
Çoğu iyileştirme birkaç tekrarlı hareketten biridir:
- Şemayı sıkılaştır: JSON bekliyorsanız zorunlu alanları, enumları ve tipleri belirtin; “neredeyse JSON”u reddedin.
- Odaklanmış doğrulayıcılar ekleyin: birimler, tarih formatları, izin verilen aralıklar ve dahil edilmesi gereken zorunlu alanlar gibi kontroller ekleyin.
- Promptları ayarlayın: öncelikleri netleştirin ("Emin değilseniz bilmiyorum deyin"), örnekler ekleyin ve belirsiz talimatları azaltın.
- Yedek yollar ekleyin: daha sıkı bir istemle yeniden deneme, daha güvenli bir şablon yanıtı veya insan incelemesine yönlendirme—detayları sessizce uydurmadan
Bir vakayı düzelttiğinizde ayrıca sorun: “Hangi yakın vakalar hâlâ atlayabilir?” diye sorun. Kuralı tek vakayı kapatacak şekilde değil, küçük bir kümesini kapsayacak şekilde genişletin.
Versiyonlama ve güvenli dağıtımlar
Promptları, doğrulayıcıları ve modelleri kod gibi versiyonlayın. Değişiklikleri canary veya A/B sürümleriyle yayınlayın, ana metrikleri (reddetme oranı, kullanıcı memnuniyeti, maliyet/gecikme) izleyin ve hızlı geri alma yolu tutun.
Bu noktada ürün araçları fayda sağlar: örneğin Koder.ai gibi platformlar uygulama yinelemeleri sırasında snapshot ve rollback desteği verir; bu da prompt/doğrulayıcı versiyonlamasıyla iyi eşleşir. Bir güncelleme şema hatalarını artırır veya bir entegrasyonu bozarsa, hızlı rollback üretim olayını hızlı bir toparlanmaya çevirir.
Pratik kontrol listesi
- Loglardan bildirilen herhangi bir sorunu yeniden üretebiliyor muyuz?
- Hatalar doğru kovanlara yönlendiriliyor mu (yeniden dene, yedek, insan incelemesi, sert durma)?
- Şema/doğrulayıcı ve prompt birlikte güncellendi mi?
- Bu hata için tekrar etmesin diye test vakası eklendi mi?
- Değişiklik bir canary arkasında mı yayınlandı ve etkisi izlendi mi?