“Yapay Zeka Backend'inizi Tasarlıyor” Aslında Ne Anlama Gelir
İnsanlar “yapay zeka backend'imizi tasarladı” dediğinde genellikle modelin temel teknik taslağın ilk versiyonunu ürettiğini kastediyorlar: veritabanı tabloları (veya koleksiyonlar), bu parçaların nasıl ilişkili olduğu ve veriyi okuyan/yazan API'ler. Pratikte bu, “AI her şeyi inşa etti”den çok “AI uygulanıp iyileştirilebilecek bir yapı önerdi”ye daha yakın.
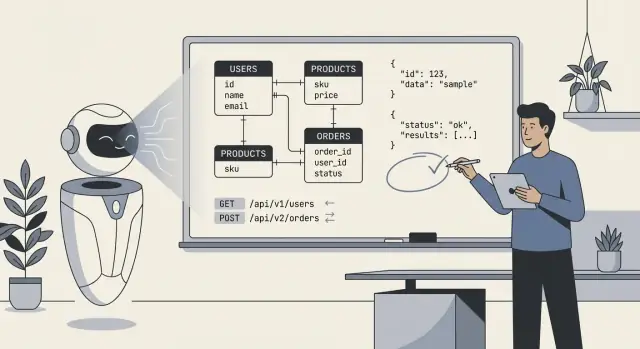
AI tarafından tasarlanan bir backend tipik olarak neleri içerir
En azından AI şunları üretebilir:
- Şemalar ve varlıklar:
users, orders, subscriptions gibi tablolar/koleksiyonlar ile alanlar ve temel tipler.
- İlişkiler: bire-çok ve çok-çok bağlantılar (ör. bir order'ın birçok line item'ı vardır; bir ürün birçok kategoriye ait olabilir).
- Kısıtlar ve doğrulamalar: zorunlu alanlar, benzersiz anahtarlar, temel aralıklar, enum-benzeri durumlar ve basit referans bütünlüğü kuralları.
- API yüzeyi: CRUD uç noktaları, istek/yanıt biçimleri, sayfalama desenleri, hata formatları ve bazen sürümlendirme önerileri.
İş bağlamınız olmadan karar veremeyeceği şeyler
AI “tipik” kalıpları çıkarabilir, ama gereksinimler belirsiz veya alana özgü ise doğru modeli güvenilir şekilde seçemez. Gerçek politikalarınızı bilmez:
- “kullanıcı”nın ne sayıldığı (roller? organizasyonlar? misafir hesaplar?)
- hangi alanların yasal olarak gerekli, hassas veya saklama kurallarına tabi olduğu
- hangi eylemlerin denetlenmesi, geri alınabilmesi veya onay gerektirmesi gerektiği
- durumların gerçek anlamı (ör.
cancelled vs refunded vs voided)
Doğru beklenti: yardımcı pilot, nihai otorite değil
AI çıktısını hızlı, yapılandırılmış bir başlangıç noktası olarak değerlendirin—seçenekleri keşfetmekte ve eksikleri yakalamakta faydalıdır—ama doğrudan gönderilebilecek bir spesifikasyon olarak değil. İşiniz, net kurallar ve uç durumları sağlamak, sonra AI'nın ürettiklerini bir kıdemsiz mühendisin ilk taslağını inceler gibi gözden geçirmek: faydalı, bazen etkileyici, ara sıra ince biçimde hatalı.
AI Çıktısının Kalitesini Belirleyen Girdiler
AI bir şema veya API hızlıca tasarlayabilir, ama backend’in ürününüze “uyması” için gereken eksik gerçekleri icat edemez. En iyi sonuçlar, AI'yı hızlı bir kıdemsiz tasarımcı gibi ele aldığınızda ortaya çıkar: siz net kısıtlar verirsiniz, o seçenekler önerir.
AI'nın gerçekten ihtiyaç duyduğu girdiler
Tablolar, uç noktalar veya modeller istemeden önce şu esasları yazın:
- Temel varlıklar ve tanımlar: Hangi nesneler var (örn. User, Subscription, Order) ve her birinin iş bağlamında ne anlama geldiği.
- Ana iş akışları: Kayıt, ödeme, iade, onaylar gibi ana yolculuklar ve bunların geçtiği durumlar.
- Roller ve izinler: Kim ne yapabilir (admin, çalışan, müşteri, denetçi) ve nelerin kısıtlanması gerektiği.
- Raporlama ve analiz ihtiyaçları: Daha sonra cevaplamanız gereken sorular (aylık gelir, kohort retention, SLA metrikleri) ve “group by” boyutları.
- Entegrasyonlar ve harici kimlikler: Ödeme sağlayıcıları, CRM'ler, kimlik sistemleri — ve hangi kimliklerin saklanması gerektiği.
- Ölçek ve performans beklentileri: Kabaca hacim (yüzler vs milyonlarca kayıt) ve gecikme beklentileri.
- Uyumluluk ve saklama: GDPR/CCPA, denetim günlükleri, veri silme kuralları, veri yerleşim gereksinimleri, saklama süreleri.
- Operasyonel gerçekler: Backfill'ler, importlar, manuel üstesinden gelmeler ve “destek ekibi X'i düzenleyebilmeli” senaryoları.
Belirsiz gereksinimlerin neden kırılgan modeller yarattığı
Gereksinimler bulanık olduğunda AI varsayılan olarak “her yerde isteğe bağlı alanlar, genel durum sütunları ve belirsiz sahiplik” gibi tahminler yapar. Bu, görünüşte makul ama gerçek kullanım altında bozan şemalara yol açar—özellikle izinler, raporlama ve uç durumlarda (iadeler, iptaller, kısmi sevkiyatlar, çok adımlı onaylar) sorun yaratır. Bu maliyeti daha sonra migration'lar, geçici çözümler ve kafa karıştırıcı API'lerle ödersiniz.
Kopyalanabilir gereksinimler şablonu
İsteminizde kullanmak için başlangıç noktası olarak bunu yapıştırın:
Product summary (2–3 sentences):
Entities (name → definition):
-
Workflows (steps + states):
-
Roles & permissions:
- Role:
- Can:
- Cannot:
Reporting questions we must answer:
-
Integrations (system → data we store):
-
Constraints:
- Compliance/retention:
- Expected scale:
- Latency/availability:
Non-goals (what we won’t support yet):
-
AI'nın En Çok Yardımcı Olduğu Alanlar: Hız, Tutarlılık, Kapsam
AI'yı hızlı bir taslak makinesi olarak kullandığınızda en verimli olduğu yerler bellidir: mantıklı bir ilk veri modeli ve eşleşen uç noktalar dakikalar içinde çizebilir. Bu hız çalışma biçiminizi değiştirir—çıktı sihirli şekilde “doğru” olduğu için değil, somut bir şey üzerinde hızla yineleyebildiğiniz için.
Hız: boş sayfadan çalışan iskelete
En büyük kazanım soğuk başlangıcı ortadan kaldırmaktır. Kısa bir varlık, ana kullanıcı akışları ve kısıtlama tanımı verin; AI tablolar/koleksiyonlar, ilişkiler ve temel API yüzeyini önerebilir. Bu, demo gerektiğinde veya gereksinimler henüz kararlı değilken özellikle değerlidir.
Hız en çok şu durumlarda işe yarar:
- Gerçek veri akışlarıyla bir konsepti doğrulamanız gereken prototipler
- “Yeterince iyi” yapının mükemmel modellemeden daha önemli olduğu iç araçlar
- Ürünün erken yinelemeleri, ki burada parçaları yeniden yazmayı beklersiniz
Tutarlılık: sıkıcı kararların aynı şekilde yapılması
İnsanlar yorulur ve saparlar. AI bunu yapmaz—bu yüzden tüm backend boyunca konvansiyonları tekrarlamakta iyidir:
- Tutarlı adlandırma desenleri (örn.
createdAt, updatedAt, customerId)
- Tahmin edilebilir uç nokta yapıları (
/resources, /resources/:id) ve yükler
- Standart sayfalama ve filtre parametreleri
Bu tutarlılık backend'inizi belgelemeyi, test etmeyi ve başka bir geliştiriciye devretmeyi kolaylaştırır.
Kapsam: “bir uç nokta unuttuk mu?”
AI genellikle tam kapsam sağlayabilir. Eğer tam CRUD seti ve yaygın işlemleri isterseniz (arama, listeleme, toplu güncellemeler), çoğunlukla aceleyle hazırlanmış insan taslağından daha kapsamlı bir başlangıç yüzeyi üretir.
Hızlı bir kazanım genelde standartlaştırılmış hata yanıttır: tüm uç noktalarda tek tip bir hata zarfı (code, message, details). Başlangıçta tek bir şeklin olması, daha sonra karışık ad-hoc cevapların önüne geçer.
Ana zihniyet: AI'ya ilk %80'i hızlıca ürettirin, sonra zamanınızı karar gerektiren o %20'ye harcayın—iş kuralları, uç durumlar ve modelin arkasındaki “neden” üzerine.
AI Tarafından Üretilen Şemalardaki Tipik Hata Modları
AI tarafından üretilen şemalar ilk bakışta “temiz” görünebilir: düzenli tablolar, mantıklı isimler ve mutlu yol ile uyumlu ilişkiler. Sorunlar genellikle gerçek veri, gerçek kullanıcılar ve gerçek iş akışları sisteme çarptığında ortaya çıkar.
Normalizasyon: çok fazla veya çok az
AI uçlar arasında gidip gelebilir:
- Aşırı normalizasyon: her şeyi pek çok tabloya bölme (örn. her öznitelik için ayrı tablolar), bu da yaygın sorguları pahalı hale getirir ve join karmaşıklığını artırır.
- Yetersiz normalizasyon: tekrarlanan alanları tek bir tabloya tıkıştırma (örn. birden fazla adres sütunu, denormalize durum bayrakları) ki bu da doğrulamayı ve güncellemeyi zorlaştırır.
Hızlı bir koklama testi: en sık kullanılan sayfalarınız 6+ join gerektiriyorsa muhtemelen aşırı normalizasyon var; güncelleme aynı değeri birçok satırda değiştirmeyi gerektiriyorsa yetersiz normalizasyon olabilir.
Üretimde önemli olan uç durumların eksikliği
AI sıklıkla gerçek backend tasarımını yönlendiren “sıkıcı” gereksinimleri atlar:
- Çok-tenant veri: tablolarda
tenant_id unutmak veya benzersiz kısıtlamalarda tenant kapsamını uygulamamak.
- Soft delete:
deleted_at eklemek ama benzersizlik kurallarını veya sorgu desenlerini silinmiş kayıtları hariç tutacak şekilde güncellememek.
- Denetim:
created_by/updated_by, değişim geçmişi veya değiştirilemez olay kayıtlarının eksik olması.
- Zaman dilimleri: “date” ile “timestamp”i karıştırmak ve UTC depolama vs yerel gösterim konusunda net kural olmaması, gün-of-by-one hatalarına yol açar.
Benzersizlik ve yaşam döngüsü hakkında yanlış varsayımlar
AI şu yanılgılara düşebilir:
- bir alanın küresel olarak benzersiz olduğunu varsaymak oysa bunun tenant başına benzersiz olması gerekir (örn.
invoice_number)
- bir alanın zorunlu olduğunu varsaymak oysa onboarding sırasında isteğe bağlıdır
- tek bir durumun yeterli olduğunu düşünmek oysa yaşam döngüsü durumlarına (taslak → aktif → askıya alınmış → arşivlenmiş) ihtiyaç vardır
Bu hatalar genellikle garip migration'lar ve uygulama tarafı geçici çözümler olarak ortaya çıkar.
Üretilen çoğu şema nasıl sorgulayacağınız gerçeğini yansıtmaz:
- yaygın filtreler için bileşik indekslerin eksikliği (tenant_id + created_at)
- “sıcak yollar” (en yeni öğeler, okunmamış sayıları) için plan yok
- dizinleme stratejisi olmayan JSON alanlarına aşırı güven
Model en sık çalıştırılacak ilk 5 sorguyu tanımlayamıyorsa, bu sorgular için güvenilir bir şema tasarlayamaz.
API Tasarımı: AI'nın Doğru ve Yanlış Yaptıkları
AI sıklıkla “standart görünen” bir API üretmekte şaşırtıcı derecede iyidir. Popüler frameworkler ve açık API'lerden tanıdık kalıpları taklit eder, bu da ciddi zaman kazandırır. Risk, AI'nın ürününüz, veri modeliniz ve gelecekteki değişiklikleriniz için doğru olanı değil, makul görüneni optimize etmesidir.
AI'nın genellikle doğru yaptığı şeyler
Kaynak modelleme temelleri. Net bir domain verildiğinde AI mantıklı isimleri ve URL yapılarını seçer (örn. /customers, /orders/{id}, /orders/{id}/items). Tutarlı adlandırmayı tekrarlamakta da iyidir.
Ortak uç nokta iskeleti. Liste vs detay uç noktaları, create/update/delete işlemleri ve tahmin edilebilir istek/yanıt şekilleri gibi gereklilikleri sıkça içerir.
Temel konvansiyonlar. Açıkça isterseniz sayfalama, filtreleme ve sıralamayı standartlaştırır. Örneğin: ?limit=50&cursor=... (cursor sayfalama) veya ?page=2&pageSize=25 (sayfa tabanlı), ayrıca ?sort=-createdAt ve ?status=active gibi filtreler.
AI'nın sıkça hata yaptığı noktalar
Sızdıran soyutlamalar. Klasik bir hata iç tabloları doğrudan “kaynak” olarak açığa çıkarmaktır; özellikle şema join tabloları, denormalize alanlar veya denetim sütunları içeriyorsa. Sonuç /user_role_assignments gibi uygulama detayını yansıtan uç noktalar olur; bu, API'yi kullanmayı ve değiştirmeyi zorlaştırır.
Tutarsız hata işleme. AI bazen stilleri karıştırır: bazen hatayı 200 ile döner, bazen 4xx/5xx. İyi bir kontrat şu kuralları içerir:
- Doğru HTTP durum kodları (
400, 401, 403, 404, 409, 422)
- Tutarlı bir hata zarfı (örn.
{ "error": { "code": "...", "message": "...", "details": [...] } })
Sürümleme sonradan düşünülmüş gibi. Birçok AI tasarımı sürümleme stratejisini atlar. Yolun başında yol tabanlı (/v1/...) mı yoksa header tabanlı mı kullanılacağına karar verin ve hangi değişikliğin kırıcı sayılacağını tanımlayın. Kurallar olması tesadüfi kırılmaları önler.
İyi bir kural
Hızı ve tutarlılığı AI'ya bırakın; ama API tasarımını bir ürün arayüzü olarak görün. Bir uç nokta veritabanınızı yansıtıyorsa, AI'nın kolay üretim için optimize ettiği ama uzun vadeli kullanılabilirlik için kötü olduğu sinyalini verir.
Kontrolü Kaybetmeden AI Kullanmak İçin Pratik Bir İş Akışı
Korkmadan yineleyin
Anlık görüntüler ve rollback ile denemeler yapın ve güvenle geri dönün.
AI'yı hızlı bir kıdemsiz tasarımcı gibi değerlendirin: taslaklarda çok iyi, nihai sistemden sorumlu değil. Amaç, hızından yararlanırken mimarinizi kasıtlı, denetlenebilir ve test odaklı tutmaktır.
Koder.ai gibi vibe-coding araçları kullanıyorsanız, sorumluluk ayrımının önemi daha da artar: platform hızlıca bir backend taslağı ve uygulaması oluşturabilir (ör. Go servisleri ile PostgreSQL), ama siz yine de invarianları, yetkilendirme sınırlarını ve kabul edilebilir migration kurallarını tanımlamalısınız.
Tekrar edilebilir döngü: istem → taslak → inceleme → testler → revize
Kısıtları, başarının ne olduğunu ve non-goalları tanımlayan sıkı bir istemle başlayın. Önce bir kavramsal model (varlıklar, ilişkiler, invarianlar) isteyin, tablo yerine.
Sonra sabit bir döngüyle yineleyin:
- İstem: gereksinimler, non-goallar, ölçek varsayımları ve adlandırma konvansiyonlarını belirtin.
- Taslak: AI'dan kavramsal model + ilk seviye şema + API sözleşmeleri üretmesini isteyin.
- İnceleme: alan doğruluğu, uç durumlar ve ürün kararları ile tutarlılığı kontrol edin.
- Testler: kararları (doğrulama kuralları, yetkilendirme, idempotentlik, migration güvenliği) kodlayan testler yazın veya üretin.
- Revize: inceleme bulgularını ve test hatalarını geribildirim olarak verip düzeltilmiş sürüm isteyin.
Bu döngü AI önerilerini ispatlanabilir veya reddedilebilir varlıklara dönüştürdüğü için işe yarar.
Kavramsal modeli fiziksel şema ve API sözleşmelerinden ayırın
Üç katmanı ayrı tutun:
- Kavramsal model: işin önem verdiği şeyler (örn. “Abonelik duraklatılabilir”, “Fatura bir fatura dönemine referans vermeli”).
- Fiziksel şema: nasıl saklanacağı (tablolar/koleksiyonlar, indeksler, kısıtlar, partitioning).
- API sözleşmeleri: istemcilerin nasıl etkileşeceği (kaynaklar, istek/yanıt şekilleri, hata kodları, sürümlendirme stratejisi).
AI'dan bu üç bölümü ayrı sekmeler halinde çıkarmasını isteyin. Bir şey değiştiğinde (ör. yeni bir durum veya kural), önce kavramsal katmanı güncelleyin, sonra şema ve API ile uzlaştırın. Bu, kazara bağlanmayı azaltır ve refactor'ları daha az acı verici kılar.
Kararları izlenebilir tutmak için hafif tasarım notları bırakın
Her yineleme bir iz bırakmalı. Kısa ADR tarzı özetler (bir sayfa veya daha az) kullanın:
- Karar: ne seçildi (örn. “soft delete via
deleted_at”).
- Gerekçe: neden (denetim gereksinimi, geri yükleme akışı).
- Düşünülen alternatifler: ve neden reddedildikleri.
- Sonuçlar: migration etkisi, sorgu karmaşıklığı, API davranışı.
Geri bildirimi AI'ya yapıştırırken ilgili karar notlarını kelimesi kelimesine ekleyin. Bu modelin önceki seçimleri “unutmasını” engeller ve ekip ileride backend'i anladığında nedenler elinde olur.
Daha İyi Şemalar ve API'ler Üreten İstemler
AI istemleri spesifik olduğunda daha iyi çalışır: domaini tanımlayın, kısıtları belirtin ve somut çıktılar (DDL, uç nokta tabloları, örnekler) talep edin. Amaç “yaratıcı olmak” değil—"kesin olmak".
Varlıklar ve ilişkiler için (kısıtlarla birlikte) istemler
Bir veri modeli ve onu tutarlı kılacak kurallar isteyin.
- “Kullanıcı, Plan, Subscription, Invoice varlıklarıyla abonelikler için ilişkisel bir şema tasarla. Kardinaliteleri, benzersiz kısıtları ve soft-delete stratejisini ekle. Kurallar: her kullanıcı için bir aktif abonelik; faturalar satın alma anında plan fiyatını immutable olarak referanslamalı; para birimini ISO kodu olarak sakla; zaman damgalarını UTC'de sakla.”
Zaten konvansiyonlarınız varsa söyleyin: adlandırma stili, ID türü (UUID vs bigint), null politika ve indeks beklentileri.
Uç noktalar ve sözleşmeler için istemler (örneklerle)
Sadece rota listesi değil, açık sözleşmeler isteyin:
- “Abonelik yönetimi için REST uç noktaları önerin. Her uç nokta için: method, path, auth, query params, request JSON, response JSON, hata kodları ve idempotency rehberliği. Bir başarı örneği ve iki hata örneği ekleyin.”
İş davranışını ekleyin: sayfalama stili, sıralama alanları ve filtreleme nasıl çalışır.
Migrasyonlar ve geriye uyumluluk için istemler
Modeli sürümler halinde düşünmesini sağlayın.
- “Customer'a
billing_address ekliyoruz. Güvenli bir migration planı ver: ileri migration SQL, backfill adımları, feature-flag rollout ve rollback stratejisi. API 30 gün boyunca geriye uyumlu kalmalı; eski istemciler alanı atlayabilir.”
Kaçınılması gereken anti-desen istemler
Muğlak istemler muğlak sistemler üretir:
- “Bir e-ticaret uygulaması için veritabanı tasarla” (çok geniş)
- “Bunu ölçeklenebilir ve güvenli yap” (ölçülebilir kısıt yok)
- “En iyi şemayı üret” (domain kuralları yok)
- “Her şey için API oluştur” (sınırlar veya öncelik yok)
Daha iyi çıktı istiyorsanız istemi sıkıştırın: kuralları, uç durumları ve teslimat formatını belirtin.
Yayına Almadan Önce İnsan İnceleme Kontrol Listesi
Kullanıcılar için gerçeğe dönüştürün
Paylaşmaya hazır olduğunuzda backend'inizi özel bir alan adının arkasına alın.
AI iyi bir taslak çıkarabilir, ama güvenle göndermek için insan onayı hâlâ gerekli. Bu kontrol listesini bir “yayın kapısı” olarak düşünün: bir maddeyi kendinizden emin şekilde cevaplayamıyorsanız, üretime geçmeden önce durup düzeltin.
Şema kontrol listesi (tablolar, koleksiyonlar, sütunlar)
- Birincil anahtarlar: Her tablonun açık bir PK'si olsun. UUID kullanıyorsanız üretim stratejisini (DB vs uygulama) ve indekslemeyi onaylayın.
- Yabancı anahtarlar & kısıtlar: İlişkiler gerçekse FK kısıtları ekleyin. ON DELETE/ON UPDATE kurallarının (restrict vs cascade vs set null) bilinçli olduğundan emin olun.
- Benzersizlik: E-postalar, harici kimlikler, bileşik kısıtlar (örn.
(tenant_id, slug)) veritabanında zorunlu kılın.
- Nullability: Her nullable alanı gözden geçirin. “Bilinmiyor” ile “boş” farklı ise bunu açıkça modelleyin.
- İndeksler: Sık filtrelenen/sıralanan/join edilen alanlar için indeksler ekleyin. Düşük kardinaliteliğe sahip alanlarda gereksiz indekslerden kaçının.
- Adlandırma tutarlılığı: Tekil vs çoğul,
_id eki, zaman damgaları gibi konvansiyonları seçin ve tutarlı uygulayın.
Veri bütünlüğü kararları (sonradan değiştirmesi pahalı olanlar)
Sistemin kurallarını yazılı hale getirin:
- Referans bütünlüğü: Hangi ilişkiler asla kopmamalı? Hangileri best-effort olmalı?
- Cascading kuralları: Bir ebeveyn silindiğinde çocuklar silinmeli mi, yetim kalmalı mı, yoksa engellenmeli mi?
- Soft delete stratejisi: Soft delete kullanılıyorsa sorguların silinmiş kayıtları “diriltmemesini” sağlayın. Benzersizlik kısıtlarının soft-deleted satırları yok sayıp saymayacağını kararlaştırın.
API kontrol listesi (davranış ve güvenlik)
- Auth & authorization: Her uç noktayı kimler çağırabilir ve neleri görebilir belirleyin (özellikle çok-tenant veride).
- Doğrulama: Tipleri, aralıkları, formatları ve çapraz sütun kurallarını doğrulayın. Veritabanı hatalarına doğrulama gibi güvenmeyin.
- Rate limit & kötüye kullanım kontrolü: Uygun yerlerde makul varsayılanlar ekleyin (kullanıcı/jeton/IP bazlı).
- Idempotency: Oluşturma/ödeme-benzeri işlemler için idempotency anahtarları veya deterministik istek ID'leri destekleyin.
- Tutarlı hatalar: Hata yapıları ve HTTP kodlarını standartlaştırın. Hata mesajlarının gizli bilgileri sızdırmadığından emin olun.
Birleştirmeden önce hızlı bir “mutlu yol + en kötü yol” incelemesi yapın: normal bir istek, geçersiz bir istek, yetkisiz bir istek, yüksek hacimli bir senaryo. API davranışı sizi şaşırtıyorsa, kullanıcılarınızı da şaşırtacaktır.
AI Tasarımlı Backendler İçin Test Stratejisi
AI makul bir şema ve API yüzeyi hızla üretebilir, ama bu çıktıların gerçek trafik, gerçek veri ve gelecekteki değişiklikler altında doğru davrandığını kanıtlayamaz. AI çıktısını taslak olarak kabul edin ve davranışı testlerle sabitleyin.
API için sözleşme testleri
İstekleri, yanıtları ve hata semantiklerini doğrulayan sözleşme testleriyle başlayın—sadece “mutlu yollar” değil. Gerçek bir servis örneği (veya container) üzerinde çalıştırılabilecek küçük bir test paketi oluşturun.
Odaklanılacaklar:
- Durum kodları ve hata gövdeleri (ör. 400 vs 404 vs 409)
- Doğrulama uç durumları (boş dizeler, aşırı büyük yükler, beklenmeyen alanlar)
- Sayfalama ve sıralama kararlılığı (tutarlı sıralama, cursor doğruluğu)
- Oluşturma/güncelleme uç noktalarında idempotency (güvenli tekrarlar, idempotency anahtarları)
OpenAPI yayımlıyorsanız, ondan test üretin—ama yetkilendirme kuralları ve iş kısıtları gibi spesifik karmaşaları el ile yazılmış testlerle destekleyin.
Migration testleri ve rollback planları
AI'nın ürettiği şemalar genellikle operasyonel detayları atlar: güvenli varsayılanlar, backfill'ler ve geri döndürülebilirlik. Migration testleri ekleyin:
- Boş bir DB'ye ve “kirli” eski bir snapshot'a migration uygulama
- Backfill sonrası kısıtların (unique, FK) beklenen şekilde çalıştığını doğrulama
- Her migration için rollback (veya en azından ileri-düzeltme) planını test etme
Üretim için betiklenmiş rollback planınız olsun: bir migration yavaşlarsa, tabloları kilitliyorsa veya uyumluluğu bozuyorsa ne yapılacağı.
Gerçek sorgu örüntülerine bağlı yük/perf testleri
Genel uç noktaları benchmark etmeyin. Temsilci sorgu örüntülerini (en çok kullanılan liste görünümleri, arama, join, aggregation) yakalayın ve bunları yük testine tabi tutun.
Ölçülecekler:
- uç nokta başına p95/p99 gecikme
- DB sorgu sayıları ve yavaş sorgular
- indeks kullanımı (ve eksik indeksler)
AI tasarımları genellikle burada başarısız olur: “makul” görünen tablolar yük altında pahalı join'ler üretebilir.
Güvenlik testlerinin temelleri
Otomatik kontroller ekleyin:
- Yetkilendirme kuralları (kullanıcı A, kullanıcı B'nin kaynaklarına erişemez)
- Enjeksiyon türleri (SQL/NoSQL, path traversal, JSON enjeksiyonu)
- Hassas veri işleme (günlüklere gizli veri yazılmaması, alanların doğru şekilde maskelenmesi, gerektiğinde şifreleme)
Basit güvenlik testleri bile AI hatalarının en maliyetli sınıfını önler: çalışan ama çok fazla açığa veren uç noktalar.
Migrationlar, Refactor'lar ve Uzun Vadeli Bakım
AI iyi bir “versiyon 0” şeması tasarlayabilir, ama backend versiyon 50 üzerinden geçer. İyi yaşlanan bir backend ile çöküp giden bir backend arasındaki farkı belirleyen şey: nasıl evrildiğidir—migration'lar, kontrollü refactor'lar ve niyetin açık belgelenmesi.
AI üretimli şemaları güvenle evrimleştirme
Her şema değişikliğini migration olarak ele alın, AI "tabloyu değiştir" dediğinde bile açık, geri alınabilir adımlar kullanın: önce yeni sütunları ekleyin, backfill yapın, sonra kısıtları sıkılaştırın. Yıkıcı değişikliklerden (yeniden adlandırma/silme) kaçının, bağımlılıkların olmadığını kanıtlayana kadar ekleyici değişiklikleri tercih edin.
AI'dan şema güncellemesi istediğinizde, mevcut şemayı ve izlediğiniz migration kurallarını ekleyin (örn. “kolon silme yok; expand/contract politikası kullan”). Bu, teoride doğru ama üretimde riskli bir öneri yapılmasını azaltır.
Kırıcı değişiklikleri düzensizlik olmadan ele alma
Kırıcı değişiklikler nadiren tek bir an olur; çoğunlukla bir geçiştir.
- Deprecated etme: eski alan/endpoint'leri kullanım kaydını loglarken çalışır tutun.
- Çift yazma: geçiş penceresi boyunca hem eski hem yeni sütunlara yazın.
- Backfill: yeni yapıların doldurulması için tek seferlik veya artımlı işler çalıştırın.
AI adım adım plan (SQL snippet'leri ve rollout sırası dahil) üretebilir ama runtime etkisini doğrulamalısınız: kilitlenmeler, uzun süren transaction'lar ve backfill'in yeniden başlatılabilir olup olmadığı gibi.
Her şeyi yeniden yazmadan veri modellerini refactor etme
Refactor'lar değişikliği izole etmeyi hedeflemeli. Normalizasyon gerekiyorsa, tabloyu bölüyorsanız veya olay kaydı ekliyorsanız uyumluluk katmanları kullanın: view'lar, çeviri kodu veya gölge tablolar. AI'dan mevcut API sözleşmelerini koruyan bir refactor önerisi isteyin ve sorgular, indeksler ve kısıtlar açısından nelerin değişmesi gerektiğini listelemesini talep edin.
Gelecek istemlerin tutarlı kalması için varsayımları belgeleyin
Uzun vadeli sürüklenmenin çoğu, sonraki istemin ilk niyeti unutmasıyla olur. Kısa bir “veri modeli kontratı” belgesi tutun: adlandırma kuralları, ID stratejisi, zaman damgası semantiği, soft-delete politikası ve invariantlar (“sipariş toplamı türetilir, saklanmaz”). Bunu iç dokümanlarınıza (/docs/data-model gibi) koyun ve sonraki AI istemlerinde kullanın ki tasarım aynı sınırlar içinde kalsın.
Güvenlik ve Gizlilik Hususları
Bir sonraki modelinizi başlatın
Gereksinimler şablonunuzu getirip Koder.ai'ın inceleyebileceğiniz bir ilk taslak üretmesine izin verin.
AI tabloları ve uç noktaları hızla tasarlayabilir, ama riskin sahibi sizsiniz. Güvenlik ve gizliliği isteme başından itibaren birinci sınıf gereksinimler olarak ekleyin ve sonra incelemeyle doğrulayın—özellikle hassas veriler etrafında.
Veri sınıflandırmasıyla başlayın
Her şemayı kabul etmeden önce alanları hassasiyetlerine göre etiketleyin (public, internal, confidential, regulated). Bu sınıflandırma hangi alanların şifrelenmesi, maskelenmesi veya azaltılması gerektiğini belirlemelidir.
Örneğin: parolalar asla saklanmamalıdır (yalnızca salted hash), token'lar kısa ömürlü ve diskte şifreli olmalı, PII (e-posta/telefon) admin görünümlerinde ve dışa aktarmalarda maskelenmelidir. Bir alan ürün için gerekli değilse saklamayın—AI genellikle “iyi olur” alanlar ekler ve bu yüzey riskini artırır.
Erişim kontrolü: RBAC vs ABAC
AI-üretimli API'ler genellikle basit “rol kontrolleri” ile başlar. Role-based access control (RBAC) anlaşılırdır ama sahiplik kuralları (“kullanıcılar yalnızca kendi faturalarını görebilir”) veya bağlam kuralları (“destek sadece aktif ticket sırasında veriyi görebilir”) ile zorlaşır. Attribute-based access control (ABAC) bu durumları daha iyi yönetir ama açık politikalar gerektirir.
Hangi deseni kullandığınızı netleştirin ve her uç noktanın bunu tutarlı şekilde uyguladığından emin olun—özellikle liste/arama uç noktaları sızıntı için yaygın noktalardır.
Hassas alanların kazara loglanmasını önleyin
Üretilen kod tüm istek gövdelerini, header'ları veya DB satırlarını hata esnasında loglayabilir. Bu, parolalar, kimlik jetonları ve PII'nin loglara veya APM araçlarına sızmasına neden olabilir.
Varsayılanlar olarak şunları ayarlayın: yapılandırılmış loglar, loglanacak alanların allowlist'i, gizli başlıkların (Authorization, cookie, reset token) maskelenmesi ve doğrulama hatalarında ham payload'ı loglamaktan kaçınma.
Gizlilik, saklama ve silinme
İlk günden silme için tasarlayın: kullanıcı kaynaklı silme, hesap kapatma ve “unutulma hakkı” iş akışları. Veri sınıfına göre saklama pencereleri tanımlayın (ör. denetim olayları vs pazarlama olayları) ve neyin ne zaman silindiğini kanıtlayabilme yeteneği sağlayın.
Denetim günlükleri tutuluyorsa minimal tanımlayıcılar saklayın, bunları daha sıkı erişimle koruyun ve gerektiğinde veriyi dışa aktarma veya silme prosedürlerini belgeleyin.
AI'yı Ne Zaman Kullanmalı (Ne Zaman Kullanmamalı)
AI'yı en iyi kullandığınız yer, onu hızlı bir kıdemsiz mimar olarak görmek: ilk taslakta harika, alan-kararlarında zayıf. Doğru soru “AI backendimi tasarlayabilir mi?” değil, "AI hangi parçaları güvenle taslaklayabilir ve hangi parçalar uzman sahipliği gerektirir?" olmalı.
Uygun kullanım: taslaklar, prototipler ve iyi anlaşılan kalıplar
AI gerçek zaman kazancı sağlar:
- Küçük prototipler, iç araçlar ve hızlı öğrenme amaçlı MVP'ler
- Tanıdık varlıklara sahip CRUD-ağırlıklı sistemler
- Boş sayfa anlarında ilk şema, API yüzeyi ve adlandırma konvansiyonlarını oluşturmak
Burada AI hız, tutarlılık ve kapsam için değerlidir—özellikle sistemin nasıl davranmasını istediğinizi biliyorsanız ve hataları fark edebilecek durumdaysanız.
Uygun olmayan kullanım: düzenlemeli, yüksek riskli veya alan-ağır sistemler
AI üretimini sadece ilham olarak kullanın veya insan onayı şart koşun:
- Finans: defter kayıtları, mutabakat, denetlendiğinde birebir doğruluk gerektiren kurallar
- Sağlık: hasta verisi, onay modelleri, saklama ve birlikte çalışabilirlik kısıtları
- Emniyet kritik sistemler: “makul bir varsayım” maliyetli bir olaya yol açabilir
Bu alanlarda alan uzmanlığı hızın önünde gelir. Hukuki, klinik, muhasebe veya operasyonel gereksinimler istemde bulunmuyor olabilir ve AI bu boşlukları kendinden emin biçimde doldurur.
Karar rehberi: taslaklar için AI kullanın, insan onayı zorunlu kılın
Pratik bir kural: AI seçenekler önersin, ama veri modeli invarianları, yetkilendirme sınırları ve migration stratejisi için son onay insanlardan gelsin. Şemadan ve API sözleşmelerinden kimin sorumlu olduğunu söyleyemiyorsanız, AI taslağını üretime göndermeyin.
Sonraki adımlar
İş akışları ve koruyucular hakkında değerlendiriyorsanız iç rehberlere bakın: /blog. Bu uygulamaları ekibinize nasıl uygulayacağınız konusunda yardım isterseniz /pricing sayfasına göz atın.
Sohbet üzerinden yineleme yapabileceğiniz, çalışan bir uygulama üretebileceğiniz ve kaynak kodu ihracı ile rollback dostu anlık görüntülerle kontrolü elinizde tutabileceğiniz uçtan uca bir iş akışı tercih ediyorsanız, Koder.ai bu tarz build-and-review döngüsü için tasarlanmıştır.