Ölçeklendirme Basitçe
Ölçeklendirme, “daha fazlasını çökmeden karşılamak” demektir. Bu “daha fazla” şunlar olabilir:
- Aynı anda ürünü kullanan daha fazla kullanıcı
- Saniyede daha fazla API isteği
- Saklanan ve sorgulanan daha fazla veri
- Arka planda çalışan daha fazla iş (e-postalar, video işleme, raporlar)
İnsanlar ölçeklendirmeden bahsederken genelde bunlardan bir veya birkaçını iyileştirmeye çalışırlar:
- Kapasite: sistemin ne kadar trafiği veya veriyi işleyebildiği.\n- Hız: yük altındayken ne kadar hızlı yanıt verdiği.\n- Güvenilirlik: bir şey bozulduğunda ne kadar çalışmaya devam ettiği.
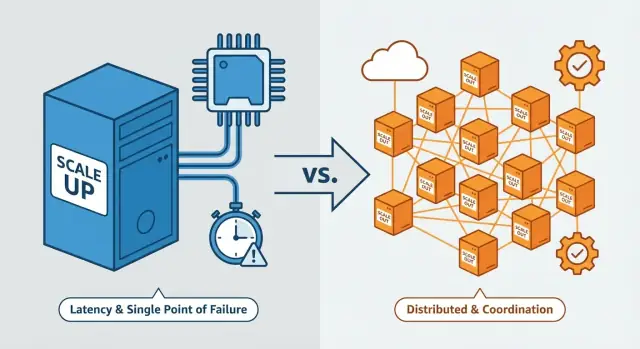
Bunun çoğu tek temaya dayanır: dikey ölçekleme “tek sistem” hissini korur, oysa yatay ölçekleme sisteminizi bağımsız makinelerden oluşan koordineli bir gruba çevirir—ve işte zorluklar koordinasyonda patlar.
Dikey vs. Yatay Ölçekleme (Kısa Tanımlar)
Dikey ölçekleme (scale up)
Dikey ölçekleme, bir makineyi daha güçlü hale getirmek demektir. Temel mimariyi aynı tutarsınız ama sunucuyu (veya VM'i) yükseltirsiniz: daha fazla CPU çekirdeği, daha fazla RAM, daha hızlı diskler, daha yüksek ağ bant genişliği.
Bunu daha büyük bir kamyon almak gibi düşünün: hâlâ tek bir sürücü ve tek bir araç var, sadece daha fazlasını taşıyor.
Yatay ölçekleme (scale out)
Yatay ölçekleme, daha fazla makine veya örnek eklemek ve işi bunlar arasında bölmek demektir—genelde bir yük dengeleyicinin arkasında. Tek bir daha güçlü sunucu yerine, birlikte çalışan birkaç sunucu çalıştırırsınız.
Bu, daha fazla kamyon kullanmak gibidir: genel olarak daha fazla yük taşıyabilirsiniz ama artık zamanlama, rota ve koordinasyonla ilgilenmeniz gerekir.
Soru genellikle ne zaman ortaya çıkar?
Yaygın tetikleyiciler:
- Trafik patlamaları (pazarlama kampanyaları, mevsimsellik, viral büyüme)
- Aylar ya da yıllar süren sürekli ürün büyümesi
- Daha büyük veri setleri (daha fazla müşteri, daha fazla olay, saklanacak daha fazla geçmiş)
Önemli bir nüans: çoğu gerçek sistem her ikisini de kullanır
Takımlar genellikle önce dikey ölçeklemeyi dener çünkü hızlıdır (kutu yükseltilir), sonra tek bir makine limitlere ulaştığında veya daha yüksek kullanılabilirlik gerektiğinde yataya geçerler. Olgun mimariler genelde iki yöntemi de karıştırır: darboğaza bağlı olarak hem daha büyük düğümler hem daha fazla düğüm kullanılır.
Dikey Ölçekleme Neden Daha Basit Hisseder
Dikey ölçekleme caziptir çünkü sistemi tek bir yerde tutar. Tek bir düğümde genelde bellek ve yerel durum için tek bir gerçek kaynak vardır. Bir süreç in-memory cache'e, iş kuyruğuna, oturum deposuna (oturumlar bellekteyse) ve geçici dosyalara sahip olur.
Daha az hareketli parça
Tek bir sunucuda çoğu operasyon basittir çünkü düğümler arası koordinasyon azdır veya yoktur:
- Hata ayıklama daha kolaydır çünkü loglar ve metrikler genelde tek bir yerde toplanır.\n- Arızalar daha nettir: ya makine sağlıklıdır ya da değildir.\n- Birçok darboğaz yereldir ve ölçülebilirdir.
Scale up yaptığınızda tanıdık kolları çekersiniz: CPU/RAM eklemek, daha hızlı depolama kullanmak, indeksleri iyileştirmek, sorguları ve yapılandırmaları ayarlamak. Verinin nasıl dağıtılacağını veya birden çok düğümün “sonraki adımda ne yapacağı” konusunda yeniden tasarım yapmanız gerekmez.
Kabul ettiğiniz ödünler
Dikey ölçekleme “bedava” değildir—sadece karmaşıklığı sınırlı tutar.
En nihayetinde sınırlarına ulaşırsınız: kiralayabileceğiniz en büyük örnek, azalan verimlilik veya üst kademede dik bir maliyet eğrisi. Ayrıca tek bir büyük makinenin arızalanması veya bakım gerektirmesi durumunda daha fazla kesinti riski taşır; yedeklilik eklemediyseniz sistemin büyük bir kısmı etkilenir.
Koordinasyon Yükü: Daha Fazla Düğüm, Daha Fazla Kural
Yatay ölçeklediğinizde sadece “daha fazla sunucu” elde etmezsiniz. Her biri bağımsız aktör olan daha fazla düğüm elde edersiniz ve bunların hangi işten kim sorumlu olduğu, ne zaman ve hangi veriyi kullanarak karar verecekleri konusunda anlaşmaları gerekir.
Tek bir makinede koordinasyon genelde örtük olur: tek bir bellek alanı, tek bir süreç, durum için bakılacak tek yer. Çok makinede koordinasyon tasarlamanız gereken bir özellik haline gelir.
Koordinasyon pratikte nasıl görünür
Yaygın araçlar ve desenler:
- Lider seçimi: hangi düğümün karar vereceğini belirlemek (ör. hangi worker'ın bir sonraki işi işleyeceği). Lider ölürse herkesi bir yedek üzerinde anlaşmaya zorlar.\n- Kilitler/lease'ler: yalnızca bir düğümün aynı anda bir görevi yapmasını sağlamak (fatura gönderimi veya migration gibi). Lease'ler süresi dolabilir, saatler kayabilir ve “kilidi kim tuttu” karmaşası doğabilir.\n- Konsensüs sistemleri: kritik durumun (konfigürasyon, üyelik, liderlik) ortak bir görünümünü koruyan küçük düğüm grupları. Güçlü ama işletme maliyeti yüksektir.
Koordinasyon bozulduğunda görülen belirtiler
Koordinasyon hataları nadiren temiz çöküşler gibi görünür. Daha sık gördükleriniz:
- Yarış koşulları: iki düğüm aynı veriye yanlış sırada müdahale eder.\n- Tekrarlı işler: iki worker aynı işi unclaimed zannedip iki kez çalıştırır.\n- Split brain: bir ağ problemi iki “lider” yaratır ve her biri çelişen kararlar alır.
Bu sorunlar genelde gerçek yük altında, dağıtımlarda veya kısmi arızalar olduğunda (bir düğüm yavaş, bir switch paket düşürüyor, bir bölge kısaca erişilemez) ortaya çıkar. Sistem çoğunlukla iyi görünür—ta ki stres altında çökene kadar.
Veri Bölümlendirme ve Sharding Doğru Yapmak Zordur
Yatay ölçeklediğinizde genelde tüm veriyi tek yerde tutamazsınız. Veriyi makineler arasında bölersiniz (shard'lar) ki birden fazla düğüm paralel olarak saklayıp hizmet verebilsin. Bu bölme karmaşıklığın başladığı yerdir: her okuma ve yazma “bu kayıt hangi shard'ta?” sorusuna bağlıdır.
Yaygın stratejiler: range vs hash
Range partitioning veriyi sıralı bir anahtara göre gruplandırır (ör. kullanıcılar A–F shard 1, G–M shard 2). Bu sezgiseldir ve aralık sorgularını iyi destekler (“geçen haftanın siparişleri”). Dezavantajı dengesiz yük: bir aralık popüler olursa o shard darboğaz olur.
Hash partitioning bir anahtarı hash fonksiyonundan geçirir ve sonuçları shard'lara dağıtır. Trafiği daha eşit dağıtır, ama ilişkili kayıtlar dağılır, bu da aralık sorgularını zorlaştırır.
Yeniden dengeleme ücretsiz değildir
Node ekleyip onu kullanmak istediğinizde veri taşınmalıdır. Bir node'u kaldırdığınızda (planlı veya arıza nedeniyle) diğer shard'ların üzerine geçmesi gerekir. Yeniden dengeleme büyük transferler, cache ısınmaları ve geçici performans düşüşleri tetikleyebilir. Taşıma sırasında eski okumalardan ve yanlış yönlendirilmiş yazılardan kaçınmanız gerekir.
Sıcak partition'lar ve eğilim (skew)
Hashleme olsa bile gerçek trafik eşit değildir. Bir ünlü hesap, popüler bir ürün veya zamana bağlı erişim desenleri okumaları/yazmaları bir shard üzerinde yoğunlaştırabilir. Tek bir sıcak shard tüm sistemin verimini sınırlayabilir.
İhmal edilemeyecek operasyonel işler
Sharding sürekli sorumluluklar getirir: yönlendirme kurallarını sürdürme, migration'lar çalıştırma, şema değişikliklerinden sonra backfill yapma ve bölme/birleştirme planları hazırlama—bunların hepsi müşterileri bozmadan yapılmalıdır.
Durum: Oturumlar, Cache'ler ve Arka Plan İşleri
Yatay Ölçeklemeyi Güvenle Keşfedin
Tam bir pipeline kurmadan stateless desenleri ve paylaşılan durum fikirlerini test edin.
Yatay ölçeklediğinizde sadece daha fazla sunucu eklemezsiniz—uygulamanızın kopyalarını eklersiniz. Zor olan kısım durumtur: uygulamanızın istekler arasında veya iş sürerken “hatırladığı” her şey.
Oturumlar: giriş nerede saklanıyor?
Bir kullanıcı Server A'da giriş yapıp sonraki isteği Server B'ye giderse, B kullanıcının kim olduğunu biliyor mu?
- Sticky session: kullanıcıyı aynı sunucuya yönlendirir. Basit ama kırılgan: yeniden başlatmalar ve dengesiz yük kullanıcıya görünür hale gelir.\n- Paylaşılan oturum deposu (
Redis veya bir DB) herhangi bir sunucunun isteği işleyebilmesini sağlar. Daha sağlam ama ek maliyet ve bağımlılık getirir. Oturum deposu yavaşlarsa tüm uygulama yavaş hissedilir.
Cache'ler: hızlı ama anlaşmazlık olana kadar
Cache'ler hız sağlar, ama birden çok sunucu birden çok cache demektir. Şimdi uğraşacağınız konular:
- Invalidation: veri değiştiğinde her cache'in eski değeri sunmasını nasıl engellersiniz?\n- Tutarlılık: düğümler kısa süreler için farklı şeyler düşünebilir.\n- Dengesiz hit oranları: bir sunucu sıcak, diğeri soğuk olabilir; performans tutarsızlığı yaratır.
Arka plan işleri: çift işlemeyi önlemek
Birden çok worker varken, işler tekrarlanabilir. Genelde bir kuyruk, lease/kilit veya idempotent iş mantığı gerekir ki “fatura gönder” veya “kartı çek” iki kez gerçekleşmesin—özellikle retry ve yeniden başlatmalar sırasında.
Tutarlılık ve Eşzamanlılık Problemleri Çarpılır
Tek bir düğümde (veya tek bir primary DB'de) genelde net bir “gerçek kaynak” vardır. Yatay ölçeklendiğinde veri ve istekler makineler arasında yayılır ve herkesin senkron kalması sürekli bir endişe haline gelir.
Güçlü vs sonunda tutarlılık (düz Türkçe)
- Güçlü tutarlılık: bir yazma başarılı olduktan sonra tüm okuyucular hemen en güncel değeri görür.\n- Sonunda tutarlılık: güncellemeler yayılır, bu yüzden kısa bir süre bazı okuyucular eski değeri görebilir.
Sonunda tutarlılık genelde daha hızlı ve daha ucuzdur, ancak beklenmedik kenar durumlar getirir.
Gerçek sistemlerde neler ters gidebilir
Yaygın sorunlar:
- Eski okuma: kullanıcı adresini günceller, yeniler ve hâlâ eski adresi görür.\n- Yazma çakışmaları: iki güncelleme neredeyse aynı anda olur ve birbirini üstüne yazar.\n- Kaybolan güncellemeler: “son yazma kazanır” yaklaşımı sessizce bir değişikliği düşürebilir.
Hasarı azaltan desenler
Arızaları ortadan kaldıramazsınız ama bunlara hazırlanabilirsiniz:
- Idempotency anahtarları: “ödeme oluştur” yeniden denendiğinde iki kez ücretlendirme olmaz.\n- Backoff ile retry: 200ms, sonra 400ms, sonra 800ms (jitter ile) gibi; stampeden kaçınır.\n- Deduplikasyon: mesaj iki kez gelirse bir kez işleyin.
Dağıtık transaction'lar neden zordur
Birden fazla servisi kapsayan transaction (sipariş + stok + ödeme) birçok sistemin aynı anda anlaşmasını gerektirir. Bir adım ortasında başarısız olursa telafi edici işlemler ve dikkatli kayıt tutma gerekir. Ağ ve düğüm arızaları bağımsız iken klasik “hepsi ya da hiçbiri” davranışı uygulamak zordur.
Güçlü tutarlılığın en kritik olduğu yerler
Doğruluğun zorunlu olduğu konularda güçlü tutarlılık kullanın: ödeme işlemleri, hesap bakiyeleri, stok sayımları, koltuk rezervasyonları. Daha az kritik veriler (analitik, öneriler) için genelde sonunda tutarlılık kabul edilebilir.
Ağ: Gecikme, Zaman Aşımı ve Retry'ler
Dikey ölçeklemede birçok çağrı aynı süreç içinde fonksiyon çağrısıdır: hızlı ve öngörülebilir. Yatay ölçeklemede aynı etkileşim ağ çağrısına dönüşür—bu da gecikme, jitter ve kodun ele alması gereken yeni hata modları ekler.
Gecikme sadece “biraz daha yavaş” değildir
Ağ çağrılarının sabit maliyeti (serileştirme, kuyruklama, hoplar) ve değişken maliyeti (tıkanma, routing, noisy neighbor) vardır. Ortalama gecikme iyi olsa bile tail latency (en yavaş %1–5) kullanıcı deneyimini domine edebilir çünkü tek bir yavaş bağımlılık tüm isteği yavaşlatır.
Bant genişliği ve paket kaybı da kısıtlayıcı hale gelir: yüksek istek oranlarında “küçük” yükler birikir ve yeniden gönderimler sessizce yükü artırır.
Zaman aşımı, retry ve retry fırtınaları
Zaman aşımı olmazsa yavaş çağrılar birikir ve thread'ler meşgul kalır. Zaman aşımı ve retry ile kurtarabilirsiniz—ta ki retry'ler yükü artırıp problemi büyütene kadar.
Yaygın bir arıza deseni retry fırtınasıdır: bir backend yavaşlar, istemciler zaman aşımı yaşar ve retry yapar, retry'ler yükü artırır, backend daha da yavaşlar.
Daha güvenli retry'ler genelde şunları gerektirir:
- Gerçek gecikme verilerine dayalı muhafazakar zaman aşımı değerleri\n- Sınırlı retry sayısı (genelde 0–1) ile üstel backoff ve jitter\n- Hangi işlemlerin güvenle retry edilebileceğine dair açık kurallar (idempotent işlemler)
Yük dengeleyiciler ve servis keşfi
Birden çok örnekle istemcilerin isteği nereye göndereceğini bilmesi gerekir—yük dengeleyici aracılığıyla veya servis keşfi + istemci tarafı dengeleme ile. Her iki durumda da hareketli parçalar eklenir: sağlık kontrolleri, bağlantı boşaltma (drain), dengesiz trafik dağılımı ve yarım bozuk örneğe yönlendirme riski.
Backpressure ve hız sınırlama
Aşırı yükün yayılmasını önlemek için backpressure gerekir: sınırlı kuyruklar, circuit breaker'lar ve rate limiting. Amaç, küçük bir yavaşlamanın sistem çapında bir olaya dönüşmesini önleyip hızlı ve öngörülebilir şekilde başarısız olmaktır.
Arıza Modları Değişir: Kısmi Arıza Normalleşir
Kod Tabanına Sahip Olun
Kendi iş akışınıza geçtiğinizde tam kaynak kodunu dışa aktararak ilerlemeye devam edin.
Dikey ölçekleme genelde tek bir büyük makinenin çökmesiyle sonuçlanır: etki nettir. Yatay ölçekleme matematiği değiştirir. Birçok düğüm olduğunda bazı makinelerin sağlıksız olması normaldir; sistem “çalışıyor” ama kullanıcılar yine de hatalar, yavaş sayfalar veya tutarsız davranışlar görür. Buna kısmi arıza denir ve ölçek için tasarlanması gereken varsayılan durum haline gelir.
Kısmi arızalar nasıl zincirleme arızalara dönüşür
Yatay kurulumda servisler diğer servislere bağımlıdır: veritabanları, cache'ler, kuyruklar, downstream API'lar. Küçük bir sorun şu şekilde yayılabilir:
- Bir düğüm veritabanına ulaşamaz → agresif retry yapar\n- Retry'ler DB yükünü artırır → herkes için gecikme artar\n- Artan gecikme daha fazla zaman aşımına yol açar → daha fazla retry → daha fazla yük
Kuyruklar dolar, cache'ler ıskalar ve downstream API'lar ezilir.
Yedeklilik yardımcı olur, ama kurallar ekler
Kısmi arızalardan kurtulmak için sistemler yedeklilik ekler:
- Replikasyon: verinin/servisin birden çok kopyası\n- Quorum'lar: "M replikadan N başarılıysa" gibi kararlar\n- Çok-bölge konuşlandırma: bir bölge çöktüğünde her şeyi kaybetmemek için dağıtım
Bu kullanılabilirliği artırır ama split-brain, eski kopyalar ve quorum ulaşılamadığında ne yapılacağı gibi kenar durumlar yaratır.
Gerekli dayanıklılık araçları
Yaygın desenler:
- Circuit breaker ile başarısız bağımlılığı çağırmayı durdurma\n- Bulkhead ile arızaları izole etme\n- Kademeli bozulma (graceful degradation) ile sert hatalar yerine daha basit deneyimler sunma
Çoklu Makinede Gözlemlenebilirlik ve Hata Ayıklama
Tek bir makinede “sistem hikâyesi” tek yerde yaşar: tek bir log seti, tek bir CPU grafiği, incelenecek tek bir süreç. Yatay ölçeklemede hikâye dağılır.
Daha fazla makine, daha fazla eksik bağlam
Her ek düğüm bir log, metric ve trace akışı daha ekler. Zor olan veri toplamak değil—bunları ilişkilendirmektir. Bir checkout hatası bir web düğümünde başlayabilir, iki servisi çağırabilir, bir cache'e takılabilir ve belirli bir shard'dan okuma yaparken farklı yerlerde ve zaman çizelgelerinde iz bırakır.
Sorunlar seçici hale gelir: bir düğüm yanlış konfigüre, bir shard sıcak, bir bölge daha yüksek gecikmeye sahip olabilir. Hata ayıklama rastgelemiş gibi gelebilir çünkü çoğunlukla her şey normal görünür.
Tracing ve correlation ID'ler (düz Türkçe)
Dağıtık izleme, bir isteğe takip numarası takmak gibidir. Correlation ID o takip numarasıdır. Bunu servisler arasında geçirip loglara dahil edersiniz, böylece bir ID alıp isteğin uçtan uca yolculuğunu görebilirsiniz.
Bunaltmayan alarmlar
Daha fazla bileşen genelde daha fazla alarm demektir. Ayarlama yapılmazsa ekipler alarm yorgunluğu yaşar. Eyleme dönüştürülebilir alarmlar hedefleyin:
- Neyin bozuk olduğunu\n- Kimlerin etkilendiğini\n- Önce neye bakılması gerektiğini
Sadece hatalara değil doygunluğa bakın
Kapasite sorunları genelde arızalardan önce görünür. CPU, bellek, kuyruk derinliği ve bağlantı havuzu kullanımı gibi doygunluk sinyallerini izleyin. Doygunluk yalnızca bazı düğümlerde görünüyorsa, dengeleme, sharding veya konfigürasyon sürüklenmesi şüphelenin.
Dağıtımlar, Yükseltmeler ve Geri Alımlar Daha Riskli Hale Gelir
Yatay ölçeklemede deploy artık “bir kutuyu değiştir” değildir. Birçok makinede değişiklikleri koordine etmek ve hizmeti erişilebilir tutmak gerekir.
Rolling update'ler, canary'ler ve blue/green
Yatay dağıtımlar genelde rolling update (düğümleri kademeli değiştirme), canary (trafğin küçük bir yüzdesini yeni versiyona yönlendirme) veya blue/green (iki tam ortam arasında geçiş) kullanır. Bunlar blast radius'u azaltır ama gereksinimler ekler: trafik kaydırma, sağlık kontrolleri, bağlantı boşaltma ve “ilerleme için yeterince iyi” tanımı.
Versiyon uyumsuzluğu varsayılan olur
Her kademeli deploy sırasında eski ve yeni sürümler yan yana çalışır. Bu versiyon karışımı şu gereksinimleri doğurur:
- Yeni düğümler eski düğümleri çağırabilir (ve tersi)\n- Eski istemciler yeni sunuculara istek atabilir\n- Farklı cache formatları veya iş yükü biçimleri dolaşımda olabilir
Uyumluluk bir gereksinim haline gelir
API'lar geriye ve ileriye uyumlu olmalı, sadece doğru olmak yetmez. Veritabanı şema değişiklikleri mümkün olduğunca ekleyici olmalı (önce nullable kolon ekleyip sonra required yapmak gibi). Mesaj formatları versiyonlanmalı ki tüketiciler hem eski hem yeni etkinlikleri okuyabilsin.
Veri migration'ları ile geri alma zorlaşır
Kodu geri almak kolaydır; veriyi geri almak zor. Bir migration alanları düşürür veya yeniden yazar ise eski kod çöker veya kayıtları yanlış işler. “Genişlet/sözleş” migration'ları yardımcı olur: önce her iki şemayı destekleyen kod deploy edilir, veri migrate edilir, sonra eski yollar kaldırılır.
Konfig ve secrets tutarlılığı gerekir
Birçok düğümde konfigürasyon yönetimi deploy'un parçası haline gelir. Eski konfigürasyon, yanlış feature flag veya süresi dolmuş kimlik bilgileri tek bir düğümü bozabilir ve tekrarlanması zor hatalar yaratabilir.
Maliyet ve Ekip Karmaşıklığı Genelde Yatayla Artar
Sağlam Bir Çekirdekle Başlayın
Trafik ve veri büyüdükçe geliştirmesi daha kolay bir Go backend oluşturun.
Yatay ölçekleme kağıt üzerinde daha ucuz görünebilir: birçok küçük örnek, her biri düşük saatlik fiyat. Ama toplam maliyet sadece hesaplama değildir. Düğümler eklemek daha fazla ağ, daha fazla izleme, daha fazla koordinasyon ve makineleri tutarlı tutmak için daha fazla zaman demektir.
Az sayıda büyük kutu vs çok sayıda küçük örnek
Dikey ölçekleme maliyeti birkaç makinede yoğunlaşır—genelde yamalar için daha az host, çalıştırılacak daha az ajan, gönderilecek daha az log, çekilecek daha az metrik olur.
Yatayda birim başına fiyat daha düşük olabilir ama sıklıkla ödersiniz:
- Yük dengeleyiciler, servis keşfi ve ekstra bant genişliği\n- Performans ve kullanılabilirlik hedefleri için daha fazla replika\n- Her yerde boşluk (slack) olması gerektiği için daha yüksek temel kapasite
Kullanım oranı ve aşırı-provizyonlama
Patlamaları güvenle karşılamak için dağıtık sistemler sıklıkla düşük dolulukla çalışır. Web, worker, DB, cache gibi katmanlarda baş boşluk tutarsınız; bu da onlarca ya da yüzlerce örnekte boşa ödenen kapasite anlamına gelebilir.
Operasyonel maliyet: gizli çarpan
Yatay ölçek ekip üzerindeki nöbet yükünü artırır ve olgun araçlar gerektirir: alarm ayarı, runbook'lar, tatbikatlar ve eğitim. Takımlar ayrıca sahiplik sınırları (hangi servisi kim sahiplenir?) ve olay koordinasyonu için zaman harcar.
Sonuç: “birim başına daha ucuz” olsa bile insanlar zamanı, operasyonel risk ve birçok makineyi tek bir sistem gibi davranır hale getirme işi dahil edildiğinde toplamda daha pahalı olabilir.
Doğru Yolu Seçmek: Ne Zaman Dikey, Ne Zaman Yatay
Dikey mi yoksa yatay mı ölçekleyeceğinize karar vermek sadece fiyata bağlı değildir. İş yükünün şekline ve ekibinizin hangi operasyonel karmaşıklığı kaldırabileceğine bağlıdır.
Önemli karar kriterleri
İş yükü ile başlayın:
- İş yükü tipi: CPU-bağımlı işler genelde dikeyden, istek-yoğun web trafiği genelde yük dengeleyicinin arkasında yataydan faydalanır.\n- Durumsallık: istekler yerel duruma bağlıysa (oturumlar, cache'ler, devam eden işler), yatay ölçekleme durumun nerede tutulacağını yeniden tasarlamanızı gerektirir.\n- Tutarlılık ihtiyaçları: doğruluk kritikse (ödeme, stok) yatay ölçekleme eşzamanlılık ve tutarlılık konusunda daha zorlu ödünler getirir.\n- Büyüme hızı ve patlamalar: öngörülebilir büyüme dikey adımlarla yönetilebilir; öngörülemeyen patlamalar yatay kapasiteye itebilir.
Zaman kazandıran pratik bir yol (ve zaman kazandırır)
Yaygın mantıklı yol:
- Optimize edin (yavaş sorgular, eksik indeksler, verimsiz endpoint'ler).\n2) Önce dikey ölçekleme yapın (daha büyük VM/DB), çünkü daha az varsayımı değiştirir.\n3) Tek bir düğüm gerçekten sınırlayıcı hale geldiğinde veya tek bir düğümün sağlayamayacağı kullanılabilirlik gerektiğinde yataya geçin.
Hibrit desenler normaldir
Birçok ekip veritabanını dikey (veya hafifçe kümeleşmiş) tutarken stateless uygulama katmanını yatay ölçeklendirir. Bu, sharding acısını sınırlarken web kapasitesini hızlıca artırmanızı sağlar.
Yatay ölçeklemeye hazır olma sinyalleri
Sağlam izleme ve alarmlarınız, test edilmiş failover, yük testleri ve güvenli geri alımlarla tekrarlanabilir dağıtımlarınız varsa yataya geçmeye yakınsınız.
Taahhüt etmeden önce sorulması gereken sorular
- Önümüzdeki 6–12 ay için hedeflere optimizasyon veya dikey ölçekleme ile ulaşabilir miyiz?\n- Oturumlar, cache'ler ve arka plan işleri nerede yaşayacak?\n- Güçlü tutarlılığa ihtiyacımız var mı ve hangi arızalar kabul edilebilir?\n- Veri parçalama (sharding) ve yeniden dengeleme için planımız ne?\n- Birden çok düğümde sorunları debug etmek için aracımız var mı?
Koder.ai Nerede Yardımcı Olur (Her Şeyi Yeniden İnşa Etmeden Pratik Destek)
Çok ölçeklenmenin acısı sadece “mimari” değildir—operasyon döngüsüdür: güvenli iterasyon, güvenilir dağıtım ve plan işe yaramadığında hızlı geri alma.
Web, backend veya mobil sistemler inşa ediyorsanız ve kontrolü kaybetmeden hızlı hareket etmek istiyorsanız, Koder.ai size bu kararları verirken prototip oluşturup daha hızlı gönderme konusunda yardımcı olabilir. Koder.ai, altında ajan tabanlı bir mimariyle sohbet üzerinden uygulama inşa ettiğiniz bir vibe-coding platformudur. Pratikte bu şunları yapmanızı sağlar:
- Bir React web uygulaması, bir Go + PostgreSQL backend ya da bir Flutter mobil uygulamayı hızlıca ayağa kaldırıp darboğazları keşfettikçe yineleyin.\n- Uygulamaya geçmeden önce “scale up vs. scale out” değişikliklerini düşünmek için planning mode kullanın.\n- Düğümler eklendikçe versiyon uyumsuzluğu normalleşirken snapshots ve rollback ile dağıtım riskini azaltın.\n- Hazır olduğunuzda kaynak kodu dışa aktarın ve kendi pipeline'ınıza taşıyın; özel domainlerle deploy/barındırma yapın.
Koder.ai AWS üzerinde küresel olarak çalıştığı için, çok-bölgeli veya bölge bazlı dağıtımlar gerektiğinde gecikme ve veri aktarım kısıtlarını karşılayacak konuşlandırmaları da destekleyebilir.