2025年8月21日·2 分钟
你必须掌握的6种SQL连接(简单清晰的示例)
学习每位分析师都应掌握的6种 SQL 连接:INNER、LEFT、RIGHT、FULL OUTER、CROSS 和 SELF,附实用示例与常见陷阱。
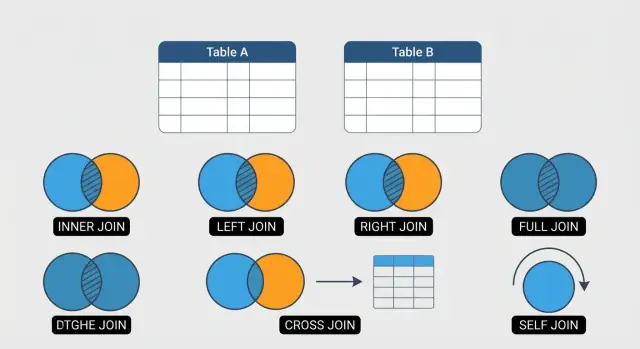
学习每位分析师都应掌握的6种 SQL 连接:INNER、LEFT、RIGHT、FULL OUTER、CROSS 和 SELF,附实用示例与常见陷阱。
SQL JOIN 允许你将两个(或多个)表的行按相关列合并到一个结果中——通常是通过一个 ID 来匹配。
现实中的大多数数据库为了避免重复信息,会将数据拆分到多个表中。例如客户的姓名存储在 customers 表,而他们的购买记录在 orders 表。JOIN 是在需要答案时把这些分散的信息重新连接起来的方式。
这也是为什么 JOIN 在报表和分析中随处可见:
没有 JOIN,你将不得不分别运行多个查询并手动合并结果——既慢又容易出错,也难以复现。
如果你在关系型数据库上构建产品(仪表盘、管理面板、内部工具、客户门户),JOIN 仍然是把“原始表”变成面向用户视图的关键。像 Koder.ai 这类平台(能从聊天生成 React + Go + PostgreSQL 应用)在需要准确的列表页、报表和对账界面时仍然依赖扎实的 JOIN 基础——因为数据库逻辑不会消失,即便开发速度变快了。
本指南聚焦于六种覆盖日常 SQL 工作的大多数场景的 JOIN:
大多数 SQL 数据库(PostgreSQL、MySQL、SQL Server、SQLite)中 JOIN 语法非常相似。存在少数差别——尤其是 FULL OUTER JOIN 的支持和一些边缘行为——但概念和核心模式是可迁移的。
为了让 JOIN 示例简洁,我们使用三个小表来反映常见的现实场景:客户下订单,订单可能有(或没有)付款。
在开始之前小提醒:下面的示例表只展示了部分列,但后文有些查询会引用额外字段(比如 order_date、created_at、status 或 paid_at)来演示常见模式。将这些列视为生产模式中常见的字段。
主键: customer_id
| customer_id | name |
|---|---|
| 1 | Ava |
| 2 | Ben |
| 3 | Chen |
| 4 | Dia |
主键: order_id
外键: customer_id → customers.customer_id
| order_id | customer_id | order_total |
|---|---|---|
| 101 | 1 | 50 |
| 102 | 1 | 120 |
| 103 | 2 | 35 |
| 104 | 5 | 70 |
注意 order_id = 104 引用的是 customer_id = 5,而该客户在 customers 表中不存在。这个“缺失匹配”可以很好地用来观察 LEFT JOIN、RIGHT JOIN 和 FULL OUTER JOIN 的行为。
主键: payment_id
外键: order_id → orders.order_id
| payment_id | order_id | amount |
|---|---|---|
| 9001 | 101 | 50 |
| 9002 | 102 | 60 |
| 9003 | 102 | 60 |
| 9004 | 999 | 25 |
这里有两个重要的教学细节:
order_id = 102 有 两个付款行(分期或拆单付款)。当你将 orders 与 payments 连接时,该订单会出现两次 —— 这正是重复项经常让人感到惊讶的来源。payment_id = 9004 引用 order_id = 999,而该订单在 orders 中不存在。这又是一个“未匹配”的例子。orders 与 payments 连接会因为订单 102 有两条付款而重复该订单。INNER JOIN 只返回在两边表中都有匹配的行。如果一个客户没有订单,他不会出现在结果中。如果一个订单引用了不存在的客户(脏数据),该订单也不会出现。
你选一个“左表”,连接一个“右表”,并在 ON 子句中指定它们如何匹配。
SELECT
c.customer_id,
c.name,
o.order_id,
o.order_date
FROM customers c
INNER JOIN orders o
ON o.customer_id = c.customer_id;
关键在于 ON o.customer_id = c.customer_id:它告诉 SQL 行如何对应。
如果你只想要那些确实下过单的客户(以及订单详情),INNER JOIN 是自然的选择:
SELECT
c.name,
o.order_id,
o.total_amount
FROM customers c
INNER JOIN orders o
ON o.customer_id = c.customer_id
ORDER BY o.order_id;
这类查询适合“发送订单跟进邮件”或“按客户计算收入”(当你只关心有购买的客户时)。
如果写连接时忘记了 ON 条件(或在错误的列上连接),可能会意外生成笛卡尔积(每个客户与每个订单配对)或产生细微错误的匹配。
坏的示例(不要这样写):
SELECT c.name, o.order_id
FROM customers c
JOIN orders o;
一定要在 ON(或在适用的情况下使用 USING)中明确写出连接条件。
LEFT JOIN 会返回左表的所有行,并在存在匹配时填充右表数据。如果没有匹配,右表对应列为 NULL。
当你需要从主表获得完整列表,同时附加可选相关数据时使用 LEFT JOIN。
示例:“显示所有客户,并在他们有订单时包含订单信息。”
SELECT
c.customer_id,
c.name,
o.order_id,
o.order_date
FROM customers c
LEFT JOIN orders o
ON o.customer_id = c.customer_id
ORDER BY c.customer_id;
o.order_id(以及其他订单列)为 NULL。一个常见的用途是查找没有相关记录的项目。
示例:"哪些客户从未下过订单?"
SELECT
c.customer_id,
c.name
FROM customers c
LEFT JOIN orders o
ON o.customer_id = c.customer_id
WHERE o.order_id IS NULL;
这里的 WHERE ... IS NULL 保留的是连接未找到匹配的左表行。
当右表有多条匹配时,LEFT JOIN 会“复制”左表行。例如一个客户有 3 个订单,则该客户会出现 3 次——这在想统计客户数量时会让人惊讶。
例如,这个查询是在统计订单数(而不是客户数):
SELECT COUNT(*)
FROM customers c
LEFT JOIN orders o
ON o.customer_id = c.customer_id;
如果目标是统计客户,通常会改为按客户键计数(例如 COUNT(DISTINCT c.customer_id)),取决于你要衡量的内容。
RIGHT JOIN 会保留右表的所有行,并且只包含左表中能匹配的行。当没有匹配时,左表列为 NULL。它本质上是 LEFT JOIN 的镜像。
假设你想列出所有付款,即便某些付款无法关联到订单(也许订单被删除或付款数据有问题)。
SELECT
o.order_id,
o.customer_id,
p.payment_id,
p.amount,
p.paid_at
FROM orders o
RIGHT JOIN payments p
ON o.order_id = p.order_id;
结果:
payments 在右侧)。o.order_id 和 o.customer_id 为 NULL。大多数情况下,你可以通过调换表的顺序把 RIGHT JOIN 改写成 LEFT JOIN:
SELECT
o.order_id,
o.customer_id,
p.payment_id,
p.amount,
p.paid_at
FROM payments p
LEFT JOIN orders o
ON o.order_id = p.order_id;
这产生相同结果,但很多人觉得更容易阅读:从你关心的“主”表(这里是 payments)开始,然后选择性地拉入相关数据。
许多 SQL 风格指南不推荐 RIGHT JOIN,因为它强迫阅读者在脑中反转常见模式:
当可选关系都用 LEFT JOIN 写时,查询更容易扫描和理解。
当你在编辑一个已有查询并发现“必须保留”的表当前在右侧时,RIGHT JOIN 可能很方便。与其重写整个长查询(包含多个 join),改成 RIGHT JOIN 可以是一个快速且低风险的变更。
FULL OUTER JOIN 返回两个表的所有行:
INNER JOIN)。NULL。NULL。经典的业务场景是对账订单与付款:
示例:
SELECT
o.order_id,
o.customer_id,
p.payment_id,
p.amount
FROM orders o
FULL OUTER JOIN payments p
ON p.order_id = o.order_id;
FULL OUTER JOIN 在 PostgreSQL、SQL Server 和 Oracle 中受支持。
它在 MySQL 和 SQLite 中不可用(需要变通方法)。
如果你的数据库不支持 FULL OUTER JOIN,可以通过组合以下两部分来模拟:
orders 的所有行(并在可用时匹配 payments),和payments 侧且未匹配的那些行。一个常见模式:
SELECT o.order_id, o.customer_id, p.payment_id, p.amount
FROM orders o
LEFT JOIN payments p
ON p.order_id = o.order_id
UNION
SELECT o.order_id, o.customer_id, p.payment_id, p.amount
FROM orders o
RIGHT JOIN payments p
ON p.order_id = o.order_id;
提示:当你在一侧看到 NULL 时,那就是该行在另一表中“缺失”的信号——这正是审计和对账所需要的信息。
CROSS JOIN 返回两个表之间每一种可能的配对。如果表 A 有 3 行,表 B 有 4 行,结果将有 3 × 4 = 12 行。这也称为笛卡尔积。
这听起来吓人——确实如此——但当你确实需要生成组合时,它非常有用。
假设你把产品选项分别保存在表中:
sizes: S, M, Lcolors: Red, BlueCROSS JOIN 可生成所有变体(用于创建 SKU、预建目录或测试):
SELECT
s.size,
c.color
FROM sizes AS s
CROSS JOIN colors AS c;
结果(3 × 2 = 6 行):
因为行数会相乘,CROSS JOIN 很容易让结果集膨胀:
这会拖慢查询、占用大量内存,并产生几乎没用的输出。如果需要组合,请保持输入表很小并考虑添加限制或过滤。
SELF JOIN 就是将表自身连接。用于表内一行与另一行有关联的场景——最常见的是父子关系,如员工/经理。
因为你在同一查询中使用同一个表两次,必须给每个“副本”不同的别名。别名让查询更易读,并告诉 SQL 你指的是哪一侧。
常见习惯:
e 表示员工(employee)m 表示经理(manager)假设 employees 表有:
idnamemanager_id(指向另一名员工的 id)要列出每位员工及其经理的姓名:
SELECT
e.id,
e.name AS employee_name,
m.name AS manager_name
FROM employees e
LEFT JOIN employees m
ON e.manager_id = m.id;
注意上面使用了 LEFT JOIN,而不是 INNER JOIN。这点很重要,因为有些员工可能没有经理(例如 CEO),此时 manager_id 通常为 NULL。LEFT JOIN 会保留员工记录,同时将 manager_name 显示为 NULL。
如果使用 INNER JOIN,这些顶层员工会因为没有匹配的经理行而从结果中消失。
JOIN 不会“自动”知道两个表如何关联——你必须告诉它。关联逻辑写在连接条件里,并应紧跟在 JOIN 后面,因为它说明的是如何匹配表,而不是如何过滤最终结果。
ON:最灵活且最常用当你需要完全控制匹配逻辑(列名不同、多列匹配或额外规则)时,使用 ON。
SELECT
c.customer_id,
c.name,
o.order_id,
o.created_at
FROM customers AS c
INNER JOIN orders AS o
ON o.customer_id = c.customer_id;
ON 也适合定义更复杂的匹配(例如基于两列匹配),不会让查询变得难以理解。
USING:简洁,但仅限同名列一些数据库(例如 PostgreSQL 和 MySQL)支持 USING,当两表有同名列且你想按该列连接时,它是简洁的写法。
SELECT
customer_id,
name,
order_id
FROM customers
JOIN orders
USING (customer_id);
一个好处是:USING 通常只在输出中返回一个 customer_id 列(而不是两列)。
连接后列名经常重叠(如 id、created_at、status)。如果写了 SELECT id,数据库可能抛出“列名歧义”错误——或者更糟,你可能读到错误的 id。
推荐使用表前缀(或别名)来保证清晰:
SELECT c.customer_id, o.order_id
FROM customers AS c
JOIN orders AS o
ON o.customer_id = c.customer_id;
SELECT *在带有连接的查询中,SELECT * 会很快变得混乱:你会拉入不必要的列、遇到重复列名,并使结果难以理解。
改为精确选择所需列。结果更干净、更易维护,且在表宽(列多)时通常也更高效。
在连接中,WHERE 和 ON 都会“筛选”,但发生的时机不同:
这个时序差异是人们不小心把 LEFT JOIN 变成 INNER JOIN 的常见原因。
假设你需要所有客户,即便他们没有最近的已付订单:
SELECT c.customer_id, c.name, o.order_id, o.status, o.order_date
FROM customers c
LEFT JOIN orders o
ON o.customer_id = c.customer_id
WHERE o.status = 'PAID'
AND o.order_date \u003e= DATE '2025-01-01';
问题在于:对于没有匹配订单的客户,o.status 和 o.order_date 为 NULL。WHERE 子句会把这些行排除掉——未匹配的客户消失了,LEFT JOIN 的效果被破坏,变成了 INNER JOIN。
SELECT c.customer_id, c.name, o.order_id, o.status, o.order_date
FROM customers c
LEFT JOIN orders o
ON o.customer_id = c.customer_id
AND o.status = 'PAID'
AND o.order_date \u003e= DATE '2025-01-01';
现在没有符合条件订单的客户仍会出现(订单列为 NULL),这通常正是使用 LEFT JOIN 的初衷。
WHERE o.order_id IS NOT NULL)。JOIN 不只是“增加列”——它还会倍增行数。这通常是正确的行为,但当总额突然翻倍(或更糟)时,会让人困惑。
连接会为每一对匹配行返回一条输出行:
customers 到 orders 时,每个客户会根据订单数出现多次。orders 连到 payments(每个订单有多个付款),同时又连到另一个“多”表(如 order_items),你可能会得到 payments × items 的乘法效应。如果目标是“每客户一行”或“每订单一行”,先对“多”端汇总,再连接。
-- 从 payments 汇总为每订单一行
WITH payment_totals AS (
SELECT
order_id,
SUM(amount) AS total_paid,
COUNT(*) AS payment_count
FROM payments
GROUP BY order_id
)
SELECT
o.order_id,
o.customer_id,
COALESCE(pt.total_paid, 0) AS total_paid,
COALESCE(pt.payment_count, 0) AS payment_count
FROM orders o
LEFT JOIN payment_totals pt
ON pt.order_id = o.order_id;
这样可以让连接后的“形状”可预测:一条订单仍然是一条订单。
SELECT DISTINCT 可能看起来能修复重复,但它可能掩盖真正的问题:
只有在确认重复是纯属意外并且理解其来源时才使用。
在信任结果之前,比较行数:
人们常把“查询慢”归咎于 JOIN,但真正的原因通常是你要求数据库合并的数据量以及数据库查找匹配行的难易程度。
把索引想象成书的目录。没有它,数据库可能需要扫描大量行才能找到 JOIN 条件匹配的行。有索引(例如在 customers.customer_id 和 orders.customer_id 上),数据库可以更快地跳到相关行。
不需要掌握内部实现:如果某列经常被用于匹配(ON a.id = b.a_id),它通常就是适合建索引的候选列。
尽可能在稳定的唯一标识符上连接:
customers.customer_id = orders.customer_idcustomers.email = orders.email 或 customers.name = orders.name姓名会变化且可能重复,邮箱可能会变更或格式不同。ID 专为一致匹配而设计,且通常被索引。
两个习惯会显著提升 JOIN 查询速度:
SELECT *——额外列会增加内存和网络开销。示例:先限制 orders,再连接:
SELECT c.customer_id, c.name, o.order_id, o.created_at
FROM customers c
JOIN (
SELECT order_id, customer_id, created_at
FROM orders
WHERE created_at \u003e= DATE '2025-01-01'
) o
ON o.customer_id = c.customer_id;
如果你在应用中为报表页面编写这些查询(例如用 PostgreSQL 支持的报告页),像 Koder.ai 这样的工具可以加速脚手架搭建——模式、端点、UI——同时你仍然掌控决定正确性的 JOIN 逻辑。
NULL)NULL)NULLSQL JOIN 将两个(或多个)表的行按相关列匹配并合并到同一结果集中——通常是主键对外键匹配(例如 customers.customer_id = orders.customer_id)。这是在需要报表、审计或分析时“重新连接”已规范化的表的方式。
当你只想要在两个表中都存在关系的行时,使用 INNER JOIN。
它适合“已确认关系”的场景,例如只列出实际下过单的客户。
当你需要主表(左表)的所有行,并且只在有匹配时包含右表数据时,使用 LEFT JOIN。
要查找“没有匹配”的行的常见模式是:先做 LEFT JOIN,然后筛选右表主键为 NULL:
c.customer_id, c.name
customers c
orders o o.customer_id c.customer_id
o.order_id ;
RIGHT JOIN 保留右表的所有行,当左表没有匹配时左表列为 NULL。很多团队避免使用它,因为可读性“倒过来”。
在大多数情况下,你可以通过互换表的顺序并使用 LEFT JOIN 来替代:
FROM payments p
LEFT JOIN orders o ON o.order_id = p.order_id
FULL OUTER JOIN 适用于对账:你希望同时看到匹配行、仅左侧存在的行和仅右侧存在的行。
它非常适合审计,例如“有订单但无付款”和“有付款但无订单”的情况,因为未匹配的一侧会显示为 NULL。
某些数据库(尤其是 MySQL 和 SQLite)不支持 FULL OUTER JOIN。常见的替代办法是组合两次查询:
orders LEFT JOIN payments(包含左侧所有行)RIGHT JOIN 或反向的 LEFT JOIN 并用 WHERE 过滤),通常用 (或在确认不会重复时用 )来获得两侧的记录。
CROSS JOIN 返回两个表之间的所有组合(笛卡尔积)。它适用于生成场景组合(比如 sizes × colors)或构造日历网格等。
注意:行数会成倍增长,因此输入表必须很小且受控,否则输出会爆炸并拖慢查询。
自连接(SELF JOIN)是将表与其自身连接,用来关联表内的不同行(常见于层级关系,如员工 → 经理)。
必须使用别名来区分两份“副本”:
FROM employees e
LEFT JOIN employees m
ON e.manager_id = m.id
ON 定义在连接时哪些行可以匹配;WHERE 在连接完成后对最终结果进行过滤。对于 LEFT JOIN,若你把右表的过滤条件放在 WHERE 中,可能会把那些 NULL(即未匹配)的左表行删掉,从而把 LEFT JOIN 变成有效的 INNER JOIN。
如果想保留所有左表行但限制右表可匹配的行,应把右表的条件放在 中。
当关系是一对多或多对多时,连接会使行数倍增。例如一个订单有两个付款,orders JOIN payments 会让该订单在结果中出现两次。
为了避免双重计数,请先对“多”端进行聚合(例如按 order_id 做 SUM(amount)),然后再连接:
UNIONUNION ALLONWITH payment_totals AS (
SELECT
order_id,
SUM(amount) AS total_paid,
COUNT(*) AS payment_count
FROM payments
GROUP BY order_id
)
SELECT
o.order_id,
o.customer_id,
COALESCE(pt.total_paid, 0) AS total_paid,
COALESCE(pt.payment_count, 0) AS payment_count
FROM orders o
LEFT JOIN payment_totals pt
ON pt.order_id = o.order_id;
仅在明确知道重复是意外且不会破坏聚合结果时才考虑 DISTINCT。