2025年6月08日·1 分钟
ACID 保证如何塑造可靠的事务系统
了解 ACID 保证如何影响数据库设计与应用行为。探索原子性、一致性、隔离性、持久性、权衡以及实际示例。
了解 ACID 保证如何影响数据库设计与应用行为。探索原子性、一致性、隔离性、持久性、权衡以及实际示例。
当你买菜、订机票或在账户间转账时,你期望结果是明确的:要么成功,要么失败。数据库的目标也是提供这种确定性——即使很多人在同时使用系统、服务器崩溃或网络抖动时也能如此。
事务 是数据库当作一个“包裹”处理的单个工作单元。它可能包含多步操作——扣减库存、创建订单记录、扣卡、写收据——但它应当表现为一个连贯的动作。
如果任何一步失败,系统应回退到安全点,而不是留下半完成的混乱状态。
部分更新不仅是技术故障;它们会变成客服工单和财务风险。例如:
这些失败难以调试,因为表面看起来“大多正确”,但数字并不对。
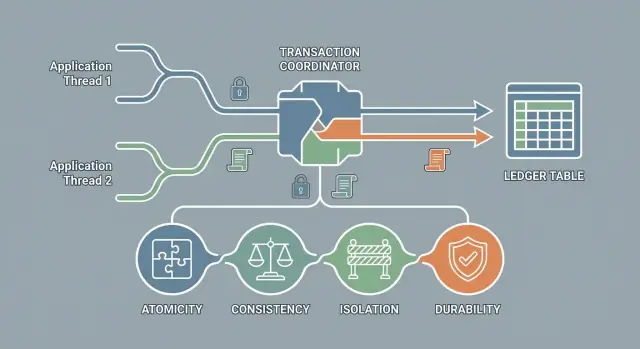
ACID 是对事务许多数据库可以提供的四项保证的简称:
它不是某个具体数据库品牌或一个可切换的单一功能;而是一条关于行为的承诺。
更强的保证通常意味着数据库必须做更多的工作:额外的协调、等待锁、追踪版本和写入日志。在高负载下,这会降低吞吐或增加延迟。目标不是“始终最大化 ACID”,而是选择与真实业务风险相匹配的保证。
原子性意味着事务被视为单个工作单元:要么完全完成,要么完全没有任何影响。你不会在数据库中看到“半个更新”。
想象把 50 美元从 Alice 转给 Bob。底层通常至少涉及两次变更:
在原子性下,这两次变更要么一起成功,要么一起失败。如果系统不能安全地同时完成这两步,它就必须两步都不做。这样可以防止 Alice 被扣款但 Bob 未到账(或 Bob 收到钱但 Alice 未被扣款)的糟糕结果。
数据库给事务两个出口:
一个有用的比喻是“草稿 vs 发布”。在事务运行期间,更改是暂时的。只有提交才把它们发布出去。
原子性重要,因为故障是常态:
如果在提交完成前发生这些情况,原子性确保数据库可以回滚,以防部分工作泄露到真实余额中。
原子性保护数据库状态,但你的应用仍需处理不确定性——尤其是在网络掉线导致不清楚提交是否发生时。
两个实用补充:
将原子事务与幂等重试结合,有助于避免部分更新和意外的重复扣款。
在 ACID 中,一致性并不等于“数据看起来合理”或“所有副本一致”。它的含义是:每个事务必须把数据库从一个有效状态变为另一个有效状态——依据你定义的规则。
数据库只能相对于显式约束、触发器和不变量来保持一致。ACID 不会发明这些规则;它在事务期间强制执行它们。
常见示例包括:
order.customer_id 必须指向一个存在的客户。如果这些规则存在,数据库会拒绝任何将违反它们的事务——因此你不会得到“半合法”的数据。
应用层校验很重要,但单靠它不足以保证安全:
一个典型失败场景是:在应用中先检查“邮箱可用”,然后再插入行。在并发情况下,两个请求可能同时通过检查。数据库中的 唯一约束 才能保证只有一个插入成功。
如果你把“不允许负余额”编码为约束(或在单一事务中可靠地强制它),那么任何会透支的转账必须整体失败。如果你没有在任何地方编码该规则,ACID 无法保护它——因为没有东西可以去强制执行。
一致性最终关乎明确:定义规则,然后让事务确保这些规则永远不被破坏。
隔离性确保事务不会相互踩踏。在一个事务进行期间,其他事务不应看到半成品,也不应意外覆盖它。目标很简单:每个事务应表现得好像独自运行一样,即使许多用户同时活跃。
真实系统非常繁忙:客户下单、支持人员更新资料、后台任务对账——这些动作同时发生。它们在时间上重叠,且经常触及相同的行(账户余额、库存计数或预订时段)。
没有隔离时,时序会成为你的业务逻辑的一部分。“扣库存”的更新可能与另一个结账竞争,或报告在读取中途读到不稳定的数据并显示从未存在过的数字。
完全“像你独自运行”式的隔离可能代价高昂:它会降低吞吐、增加等待(锁)或导致事务重试。与此同时,许多工作流并不需要最严格的保护——例如读取昨天的分析可以容忍轻微的不一致性。
这就是为什么数据库提供可配置的隔离级别:你选择在更好性能和更少冲突之间能容忍多少并发风险。
当隔离对你的工作负载过弱时,你会遇到经典异常:
理解这些失败模式可以帮助你选择与产品承诺相匹配的隔离级别。
隔离决定在你的事务运行时允许你“看到”其他事务的哪些行为。当隔离对某个工作负载过弱时,你会遇到令人惊讶的异常行为。
脏读 是指读取了另一个事务写入但未提交的数据。
场景:Alex 转出 500 美元,余额暂时变为 200 美元,你在 Alex 的转账后来失败并回滚前读到了 200 美元。
用户后果:客户看到错误的低余额,欺诈规则误报,或客服给出错误答复。
不可重复读 指你两次读取同一行却得到不同值,因为另一个事务在此期间提交了更改。
场景:你加载订单总额为 $49.00,稍后刷新看到 $54.00,因为一行折扣被移除。
用户后果:“我在结账时总额变了”,导致信任下降或放弃购物车。
幻读 像不可重复读,但作用于行集合:第二次查询返回了额外或缺失的行,因为另一个事务插入/删除了匹配记录。
场景:酒店搜索显示“3 间可用”,在预订时重新检查却发现没有了,因为新的预订被插入。
用户后果:重复尝试预订、库存显示不一致或超卖。
丢失更新 发生在两个事务读取相同值并分别写回更新,最终较晚的写覆盖了早先的写。
场景:两个管理员编辑同一商品价格。都从 $10 开始:一个保存 $12,另一个最后保存 $11。
用户后果:某人的修改消失,报表与总计出错。
写偏差(write skew) 发生在两个事务各自做出单独看起来合法但合并后违反规则的改变。
场景:规则:“至少要有一名值班医生”。两名医生分别在查看另一人仍值班后各自将自己标记为不值班。
用户后果:最终出现零覆盖率,尽管每个事务单独看都通过了检查。
更强的隔离减少异常,但会增加等待、重试和成本。在很多场景下,团队会为读取密集的分析选择较弱的隔离,而对资金流动、预订等关键正确性流程使用更严格的设置。
隔离关系到在其他事务运行时你的事务被允许“看到”什么。数据库将其暴露为隔离级别:更高的级别减少意外行为,但可能付出吞吐或等待的代价。
团队常把 Read Committed 作为面向用户应用的默认:性能好,且“无脏读”符合多数期望。
当你需要事务内读取结果稳定时使用 Repeatable Read(例如从一组行生成发票),并能容忍一些开销。
当正确性比并发性更重要时使用 Serializable(例如防止超卖库存),或者当你无法在应用层轻易推理竞态条件时。
Read Uncommitted 在 OLTP 系统中很少使用;它有时用于监控或近似报告,在容忍偶发错误读的场合。
名字是标准化的,但具体保证因数据库引擎(有时还与配置相关)而不同。请参考你的数据库文档并测试对业务重要的异常。
持久性意味着一旦事务 提交,其结果应能在崩溃后幸存——比如断电、进程重启或机器重启。如果你的应用告诉客户“支付成功”,持久性就是数据库不会在下一次故障后“忘记”这件事的承诺。
大多数关系型数据库通过 预写日志(WAL) 实现持久性。高层来说,数据库在认为事务已提交之前,会把顺序的“变更收据”写到磁盘上的日志。如果数据库崩溃,启动时可以重放日志以恢复已提交的更改。
为了让恢复时间可控,数据库还会创建检查点(checkpoint)。检查点是数据库确保足够多的近期更改被写入主数据文件的时刻,这样恢复时无需重放无限量的日志历史。
持久性不是开关,而取决于数据库将数据强制写入稳定存储的积极程度:
底层硬件也很关键:SSD、带写缓存的 RAID 控制器、云盘在故障下的表现可能不同。
备份与复制有助于恢复或降低宕机时间,但它们不是持久性的同一保证。一个事务在主库上可以是持久的,即便它还没复制到从库;备份通常是时间点快照,而不是逐提交的保证。
当你 BEGIN 一个事务并随后 COMMIT 时,数据库要协调许多移动部件:谁可以读哪些行、谁可以更新它们,以及当两个人尝试改同一条记录时会发生什么。
处理冲突的关键底层选择是:
许多系统会根据工作负载和隔离级别混合两种思路。
现代数据库常用 MVCC(多版本并发控制):数据库保留行的多个版本而不是只有一个副本。
这就是一些数据库在大量读写并发时能减少阻塞的主要原因——尽管写写冲突仍需解决。
锁会导致死锁:事务 A 等待事务 B 持有的锁,而 B 又等待 A 持有的锁。
数据库通常通过检测循环并中止其中一个事务(作为“死锁受害者”)来解决,返回错误以便应用重试。
如果 ACID 的强制带来了摩擦,你通常会看到:
这些症状通常意味着是时候重新审视事务大小、索引或适合工作负载的隔离/锁策略了。
ACID 保证不仅是数据库理论——它影响你如何设计 API、后台任务,甚至用户界面流程。核心思想很简单:决定哪些步骤必须一起成功,然后只把这些步骤包进事务中。
一个好的事务性 API 通常映射到单一业务动作,即便它触及多张表。例如,一个 /checkout 操作可能:创建订单、预留库存并记录支付意图。这些数据库写入通常应放在一个事务内,以便它们一起提交(或一起回滚)当任何校验失败时。
一个常见模式是:
这既保持了原子性和一致性,又避免了缓慢、脆弱的长事务。
事务边界的放置取决于什么被视为“一次工作单元”:
ACID 有所帮助,但你的应用仍需正确处理失败:
避免 长事务、在事务内调用外部 API 和 在事务内等待用户思考时间(例如“锁定购物车行,等待用户确认”)。这些会增加争用并使隔离冲突更可能发生。
如果你要快速构建事务系统,最大风险往往不是“不懂 ACID”,而是无意中把一个业务动作散落到多个端点、作业或表中而没有清晰的事务边界。
像 Koder.ai 这样的开发平台可以帮助你更快推进,同时仍围绕 ACID 设计:你可以在规划式对话中描述工作流(例如“带库存预留和支付意图的结账”),生成 React UI + Go + PostgreSQL 后端,并通过快照/回滚迭代架构或事务边界。数据库仍在执行保证;这些工具的价值在于把正确设计快速变成可运行的实现。
单个数据库通常能在一个事务边界内提供 ACID 保证。一旦你把工作分散到多个服务(通常也跨多个数据库),保持相同保证就变得更难,且在尝试时成本更高。
严格一致意味着每次读取都能看到“最新提交的真相”。高可用性意味着系统在部分组件慢或不可达时仍能响应。
在多服务架构中,临时网络问题会迫使你做出选择:阻塞或失败请求直到所有参与者达成一致(更一致,但可用性更低),或接受服务短暂不同步(更可用,但一致性更弱)。没有绝对正确的答案——取决于业务可容忍的错误类型。
分布式事务需要跨你不能完全控制的边界进行协调:网络延迟、重试、超时、服务崩溃与部分故障。
即便每个服务都正确,网络也会制造模糊性:支付服务提交了但订单服务没有收到确认?为安全解决该问题,系统会使用协调协议(如两阶段提交),但这会很慢、在故障时降低可用性并增加运维复杂度。
Saga 把工作流拆成多个步骤,每步在本地提交。如果随后步骤失败,靠补偿动作撤销先前步骤(例如退款)。
Outbox/Inbox 模式使事件发布与消费变得可靠。服务在同一个本地事务中写入业务数据和一条“待发布事件”记录(outbox)。消费者记录处理过的消息 ID(inbox),以便在重试时不造成重复效果。
最终一致性 接受服务间短暂的数据差异,并有明确的对账计划。
当你能容忍短暂不一致时放松保证:
控制风险的方法包括定义不变量(什么绝对不能被破坏)、设计幂等操作、使用带退避的超时与重试,并监控漂移(卡住的 saga、反复补偿、不断增长的 outbox 表)。对真正关键的不变量(例如“账户绝对不能超支”),尽量将它们保留在单个服务与单个数据库事务内。
一个事务在单元测试中可能是“正确的”,但在真实流量、重启与并发下仍会失败。使用下面的清单把 ACID 保证与生产行为对齐。
先写下必须始终为真(你的数据不变量)。示例:“账户余额永远不为负”、“订单总额等于行项之和”、“库存不能低于零”、“一笔支付只对应一个订单”。把这些当作产品规则,而不是数据库琐事。
然后决定哪些步骤必须在一个事务内,哪些可以延后:
保持事务小:触及更少行,做更少工作(不在事务内调用外部 API),并尽快提交。
把并发作为首要测试维度。
如果你支持重试,加入显式幂等键并测试“在成功后重复请求”。
监控那些表明你的保证变得昂贵或脆弱的指标:
对趋势设警报,而不是只对突发事件;并把指标关联回导致问题的端点或作业。
使用能保护你不变量的最弱隔离;不要默认把隔离“开到最大”。当你需要对小而关键的片段(资金移动、库存减量)严格正确时,把事务范围缩小到仅包含该片段,其他都放在外面。
ACID 是一组事务性保证,帮助数据库在故障和并发情况下表现可预测:
事务是数据库视为一个整体的“工作单元”。即便它执行多条 SQL 语句(例如:创建订单、扣减库存、记录支付意图),事务只有两种结局:
部分更新会导致现实世界的矛盾,事后修复成本高,例如:
ACID(尤其是原子性和一致性)能防止这些“半完成”状态成为真实的数据。
原子性确保数据库不会暴露“半完成”的事务。如果在提交前出现任何故障(应用崩溃、网络断开、数据库重启),事务会被回滚,从而防止早期步骤泄露到持久状态。
在实践中,原子性让涉及多步更新(比如同时更新两笔余额的转账)变得安全。
当客户端在提交后丢失响应(例如网络超时恰好发生在提交之后),你不能总是确定提交是否发生。将 ACID 与以下做法结合使用:
这样既避免了部分更新,也能防止重复扣款或重复写入。
在 ACID 中,“一致性”意味着数据库必须把系统从一个有效状态带到另一个有效状态,依据的是你定义的规则(约束、外键、唯一性、检查条件等)。
如果你没有在任何地方编码某条规则(例如“余额不能为负”),ACID 无法自动保护它。数据库需要明确的不变量来保障一致性。
应用层校验能提升用户体验(早期反馈、友好错误),但在并发场景下不足以作为唯一护栏(例如两个请求同时通过“邮箱可用”检查)。
数据库约束才是最终守门人:
最佳实践:在应用中先校验,数据库中再强制。
隔离控制事务在其他事务运行时能看到什么。弱隔离可能导致以下异常:
隔离级别让你在性能和对这些异常的防护之间做权衡。
一个常见的实际基线是将 Read Committed 设为默认:它防止脏读且性能良好。当你需要更稳定的读取时:
不同数据库的具体行为会有差异,务必基于引擎文档与实际测试来确认。
持久性意味着一旦数据库确认 提交,该更改应能在崩溃后存活。常见实现是 预写日志(WAL):数据库在确认提交前先把变更的顺序日志写到磁盘,崩溃后通过重放日志恢复已提交的更改。
持久性受到配置影响:
备份与复制有利于恢复和可用性,但它们不是持久性的同一概念。