2025年9月01日·2 分钟
用一个 AI 辅助的工作流把想法变成上线应用
一篇实用的端到端指南,展示如何用一个 AI 辅助的连续工作流将应用想法推进到部署:步骤、提示与检查项。
一篇实用的端到端指南,展示如何用一个 AI 辅助的连续工作流将应用想法推进到部署:步骤、提示与检查项。
想象一个小而有用的应用想法:一个“排队小助手”,咖啡馆员工点一下按钮就能把顾客加到候位名单,并在座位准备好时自动短信通知他们。成功度量很简单且可测量:在两周内将因等待时间而产生的疑问电话减少 50%,同时保证员工上手不超过 10 分钟。
这就是本文的精神:选一个清晰、有限的想法,定义什么是“好”,然后从概念一路推进到线上部署,而不在工具、文档和心智模型之间频繁切换。
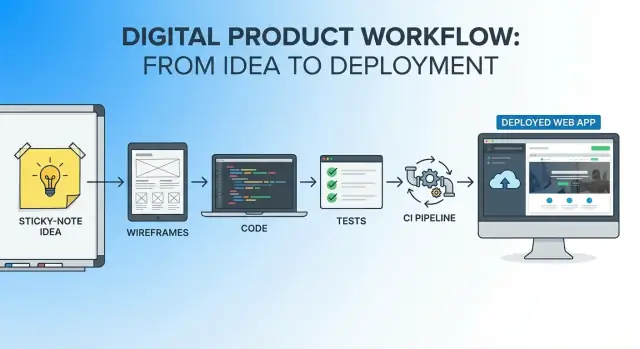
单一工作流是从想法第一句到首个生产发布的一条连续线索:
你仍会使用多种工具(编辑器、仓库、CI、托管),但不会在每个阶段都“重启”项目。相同的叙事和约束会被持续带入。
当 AI 扮演以下角色时最有价值:
但它不承担产品决策。你来做决定。这个工作流的设计是让你始终验证:这个改动能否推动指标?是否可以安全上线?
下面各节会带你逐步完成:
到最后,你应该有一套可复用的方式,把“想法”带到“上线”同时保持范围、质量和学习的紧密连接。
在让 AI 起草界面、API 或数据库表之前,你需要一个清晰的目标。这里的小小清晰能节省后面许多“近乎正确”的输出调整时间。
你要构建一个应用,是因为一类人反复遇到同样的摩擦:他们无法用现有工具快速、可靠或自信地完成一项重要任务。v1 的目标是消除工作流中的一个痛点——不要试图把所有东西自动化——让用户能在几分钟内从“我要做 X”到“X 完成”,并留下清晰的记录。
挑一个主要用户。次要用户可以以后再考虑。
假设是好想法悄然失败的地方——把它们显性化。
v1 应该是一个能交付的小胜利:
一页的轻量需求文档(想想一页纸)是“好主意”到“可构建计划”之间的桥梁。它让你保持专注,给 AI 提供正确上下文,并防止第一版膨胀成数月工程。
保持精炼、易扫读。一个简单模板:
写 5–10 个功能,尽量用结果来表述。然后排序:
这个排序也是你引导 AI 生成计划和代码的方式:“先只实现 must-have”。
为最重要的 3–5 个功能,每项写 2–4 条验收标准。用平实语言和可测试的陈述。
示例:
最后列一个“开放问题”列表——这些问题可以用一次聊天、一次用户通话或一次快速搜索回答。
示例:"用户需要 Google 登录吗?" "我们最少必须存哪些数据?" "需要管理员审批吗?"
这个文档不是繁文缛节,而是你会在构建过程中持续更新的共同事实来源。
在让 AI 生成界面或代码前,把产品的“故事”理清:用户要做什么,“成功”什么样,哪里可能出错。快速的旅程草图能确保所有人对目标一致理解。
从愉快路径开始:最简单的一系列步骤能交付主要价值。
示例流程(通用):
然后加入几种可能发生且代价高的边缘情况:
你不需要大图。编号列表加注释足以指导原型和代码生成。
为每个页面写一段“要完成的工作”,用结果导向而非 UI 细节。
如果你使用 AI,这个列表就是很好的提示素材:"生成一个支持 X、Y、Z 的仪表盘,并包含空态/加载/错误状态。"
保持在“餐巾纸模式”的模式级别——足以支撑界面和流程。
说明关系(User → Projects → Tasks)以及影响权限的字段。
指出那些错误会破坏信任的地方:
这不是过度工程,而是防止“可用演示”在上线后变成客服噩梦的常见失误。
v1 的架构应该只做一件事——让你能交付最小可用产品且不把自己逼进死角。一个好的规则是“一个仓库、一个可部署后端、一个可部署前端、一个数据库”——只有在有明确需求时才增加额外组件。
如果你在做常见的 web 应用,一个合理默认是:
保持服务数量低。对 v1 来说,“模块化单体”(组织良好的代码库,但只有一个后端服务)通常比微服务更容易。
如果你偏好 AI 优先的环境,能把架构、任务和生成代码紧密关联的平台(例如 Koder.ai)会很合适:你可以在聊天中描述 v1 范围、以“规划模式”迭代,然后生成 React 前端与 Go + PostgreSQL 后端——同时保持审查与控制权在你手中。
在生成代码前,写一个小的 API 表格以保证你和 AI 的目标一致。示例形态:
GET /api/projects → { items: Project[] }POST /api/projects → { project: Project }GET /api/projects/:id → { project: Project, tasks: Task[] }POST /api/projects/:id/tasks → { task: Task }补充状态码说明、错误格式(例如 { error: { code, message } })以及分页规则(如有)。
如果 v1 可以是公开或单用户的,跳过认证可以更快上线。如果需要账号,使用托管提供方(邮箱魔法链接或 OAuth),并保持权限简单:“用户拥有自己的记录”。在真正有使用需求前,避免复杂角色设计。
记录一些实用约束:
这些说明能指导 AI 生成更接近可部署而非仅可运行的代码。
拖死势头最快的方式是争论工具一周仍无可运行代码。你的目标是:得到一个“hello app”能在本地启动、显示界面并能接受请求——同时保持代码小到每次修改都容易审查。
给 AI 一个紧凑提示:选择的框架、基本页面、一个桩 API,以及你期望的文件结构。你要的是可预测的约定,而非巧思。
一个合理的第一版结构是:
/README.md
/.env.example
/apps/web/
/apps/api/
/package.json
如果使用单仓库,请求 AI 生成基本路由(如 / 和 /settings)以及一个 API 端点(例如 GET /health 或 GET /api/status)。这足以验证 plumbing 是否正常。
如果你使用 Koder.ai,这里也是自然的起点:请求一个“web + api + database-ready”的最小骨架,在你对结构和约定满意时导出源码。
把 UI 做得故意无聊:一个页面、一个按钮、一次调用。
示例行为:
这给你即时反馈:如果 UI 加载但调用失败,就能精确定位问题(CORS、端口、路由、网络)。抵制加入认证、数据库或复杂状态的诱惑——在骨架稳定后再做这些。
第一天就做 .env.example。它防止“只在我电脑上能跑”的问题,并让上手变得轻松。
示例:
WEB_PORT=3000
API_PORT=4000
API_URL=http://localhost:4000
然后把 README 写成一分钟内可运行:
.env.example 为 .env把这个阶段当作铺设干净基础线。每次小胜利就提交:"init repo"、"add web shell"、"add api health endpoint"、"wire web to api"。小提交让 AI 辅助的迭代更安全:如果生成的改动出问题,你可以无损回退。
当骨架端到端能运行后,克制“把所有事做完”的冲动。以一个触及数据库、API 与 UI 的窄垂直切片开始,然后重复。薄切片让审查快、 bug 小,AI 助力也更容易验证。
选出应用不可或缺的模型——通常是用户创建或管理的“东西”。明确定义字段、必填与可选、默认值,然后添加迁移(如果使用关系型数据库)。保持首版朴素:避免巧妙的规范化与过早的灵活性。
如果用 AI 起草模型,要求它为每个字段与默认值给出一两句理由。任何它不能在一句话内解释清楚的字段大概率不属于 v1。
只创建支持第一用户旅程的端点:通常是创建、读取和最小更新。在边界处做校验(请求 DTO/模式),并把规则写清楚:
校验是功能的一部分,不是润色——它防止脏数据在后面拖慢你。
把错误消息当作调试和支持的 UX。返回清晰、可操作的消息(哪个失败、如何修复),同时不在客户端返回敏感细节。服务端日志记录技术上下文并包含请求 ID,便于追溯而无需猜测。
让 AI 提出增量且可 PR 的改动:一次迁移 + 一个端点 + 一个测试。像审查同事的代码那样审查 diff:检查命名、边缘情况、安全假设,以及改动是否真的支持用户的小胜利。如果它加了多余功能,删掉并继续前进。
v1 不需要企业级安全,但需要避免那些会把有希望的应用变成客服噩梦的可预测失误。目标是“足够安全”:防止错误输入、默认拒绝访问、并在出错时留下一条有用的证据链。
把每个边界视为不受信任来源:表单字段、API 载荷、查询参数,甚至内部 webhook。校验类型、长度、允许值,并在存储前归一化数据(去空格、规范大小写)。
一些实用默认:
如果用 AI 生成处理器,要求它显式包含校验规则(例如“最大 140 字”或“必须为下列之一:…”),而不是模糊地写“校验输入”。
一个简单的权限模型通常够 v1 使用:
把所有权检查做成可复用的中间件 / 策略函数,避免在代码库到处写 if userId == …。
好的日志回答:发生了什么、对谁发生、在哪里发生?至少包含:
update_project, project_id)记录事件,不记录秘密:永远不要把密码、令牌或完整支付信息写进日志。
在把应用标为“足够安全”前,检查:
测试不是追求完美覆盖率,而是防止会伤害用户、破坏信任或引发昂贵事故的失败。在 AI 辅助的工作流中,测试也作为“契约”,确保生成的代码与真实意图一致。
在增加大量覆盖前,先识别出出错代价高的地方。典型的高风险区域包括:金钱/积分、权限、数据转换与边缘校验。先为这些写单元测试。保持测试小且具体:给定输入 X,期望输出 Y(或抛出错误)。如果一个函数分支太多难以测试,那说明它需要被简化。
单元测试捕捉逻辑 bug;集成测试捕捉“连接”类 bug——路由、数据库调用、认证检查与 UI 流是否能协同工作。
挑核心旅程(愉快路径)并做端到端自动化:
一两个扎实的集成测试,常常比几十个微小测试更能防止事故。
AI 擅长生成测试脚手架并列出你可能遗漏的边界情况。让它帮你:
然后审查每个断言。测试应该验证行为,而不是实现细节。如果一个 bug 出现了测试仍然通过,那测试没起作用。
选一个适中的目标(例如核心模块 60–70%)并把它当作护栏而非奖杯。关注稳定、可重复、在 CI 中运行快速的测试。闪烁不定的测试会破坏信心——一旦团队不再信任测试套件,它就不再保护你。
自动化是 AI 辅助工作流从“在我机器上能跑”变成“可以放心发布”的关键所在。目标不是炫酷工具,而是可重复性。
挑一个在本地和 CI 都能得到相同结果的命令。如果用 Node,可能是 npm run build;Python 可用 make build;移动端则是具体的 Gradle/Xcode 步骤。
并尽早分离开发和生产配置。简单规则:开发默认方便;生产默认安全。
{
"scripts": {
"lint": "eslint .",
"format": "prettier -w .",
"test": "vitest run",
"build": "vite build"
}
}
Linter 能捕捉风险模式(未使用变量、不安全的 async 调用),格式化避免“风格争论”成为审查噪声。v1 的规则保持克制,但要一致执行。
一个实用的门控顺序:
第一个 CI 流程可以很小:安装依赖、跑门控、快速失败。这样就能防止损坏的代码悄悄合入主分支。
name: ci
on: [push, pull_request]
jobs:
test:
runs-on: ubuntu-latest
steps:
- uses: actions/checkout@v4
- uses: actions/setup-node@v4
with:
node-version: 20
- run: npm ci
- run: npm run format -- --check
- run: npm run lint
- run: npm test
- run: npm run build
决定秘密放在哪里:CI 的 secret 存储、密码管理器或部署平台的环境设置。切勿把它们提交到 git——把 .env 加入 .gitignore,并用 .env.example 提供安全占位符。
如果你想要清晰的下一步,把这些门控与部署流程连接起来,让“CI 通过”成为通向生产的唯一路径。
发布不是一次按钮点击,而是一套可重复的例行操作。v1 的目标很简单:选一个与栈匹配的部署目标、小步部署,并始终有回退方案。
根据应用运行方式选择平台:
优先考虑“易于重新部署”通常比“极致控制”更适合此阶段。
如果你优先减少工具切换,考虑那些把构建 + 托管 + 回滚合二为一的平台。例如 Koder.ai 支持部署与托管并提供快照与回滚,把发布当成可逆步骤而非单向门。
写好并复用部署清单。把它做短,让人真的去执行:
把它放在仓库(例如 /docs/deploy.md)能让它与代码自然接近。
提供轻量端点回答:“应用是否可用且能访问依赖?”常见模式:
GET /health:供负载均衡器和可用性监测使用GET /status:返回应用版本 + 依赖检查响应要快、无缓存且安全(不暴露秘密或内部细节)。
回滚计划应明确:
当部署可逆时,发布就变成例行操作,你能更频繁、更少压力地交付新版本。
上线是最有价值阶段的开始:观察真实用户如何使用、哪里出问题、哪些小改动能推动成功指标。目标是继续使用你构建时的 AI 辅助工作流——现在以证据为导向而非假设。
从最小的监控栈开始,回答三个问题:是否在线?是否出错?是否变慢?
可用性检测可以很简单(周期性访问健康端点)。错误追踪应捕获堆栈和请求上下文(不收集敏感数据)。性能监控可从关键端点的响应时间和前端页面加载指标开始。
让 AI 帮忙生成:
别追踪所有事——只跟踪能证明产品在起作用的指标。定义一个主要成功指标(例如:“完成结账”、“创建第一个项目”或“邀请到队友”),然后埋点一个小型漏斗:进入 → 关键动作 → 成功。
请 AI 建议事件名和属性,然后审查其隐私与清晰度。保持事件稳定;每周修改名称会使趋势分析失去意义。
建立简单的反馈入口:内置应用反馈按钮、一个简短的邮箱别名和一个轻量的 bug 模板。每周进行分类:把反馈归纳为主题,把主题与分析数据关联,决定接下来的 1–2 项改进。
把监控告警、分析下滑和反馈主题当作新的“需求”。把它们投入同一流程:更新文档、生成小的变更提案、以薄切片实现、增加针对性测试,并通过相同的可回滚发布流程上线。对于团队来说,维护一个“学习日志”页面(放在 /blog 或内部文档)能让决策可见且可复用。
一个“单一工作流”是从想法到生产环境的一条连续线索,其中:
你仍然可以使用多个工具,但避免在每个阶段都“重启”项目。
把 AI 用来生成选项和草案,然后你来选择并验证:
保持决策规则明确:这项变更是否能推动指标?是否安全发布?
定义可衡量的成功指标和紧凑的 v1 “完成定义”。例如:
不支持这些结果的功能应列为非目标,避免范围蔓延。
保持为一页可快速浏览的轻量 PRD,包含:
然后列出 5–10 个核心功能并按 Must/Should/Nice 排序。用这个排序约束 AI 生成的计划和代码。
为前 3–5 个重要功能添加每项 2–4 条可测试的验收标准。好的验收标准:
示例模式:校验规则、预期跳转、错误信息和权限行为(例如“未授权用户看到明确错误且无数据泄露”)。
从编号的“愉快路径”开始,然后列出一些高概率、高代价的失败情况:
一个简单的列表就够了;目标是指引 UI 状态、API 响应和测试。
对大多数 web 应用,v1 的合理默认是“模块化单体”架构:
只有在真正被需求驱动时才增加服务。这能降低协调成本,让 AI 辅助的迭代更容易审查和回滚。
在生成代码前先写一个小的“API 合约”表:
{ error: { code, message } })这能防止前端与后端不匹配,并为测试提供稳定目标。
快速验证 plumbing 的“hello app”即可:
/health).env.example 和可在一分钟内运行的 README尽早提交小的里程碑,这样生成的变更出问题时可以安全回退。
优先用测试阻止代价高的失败:
在 CI 中按固定顺序强制执行门控:
保持测试稳定且快速;不可靠的测试套件会失去保护作用。