2025年7月23日·1 分钟
AI 如何读取布局与意图,将设计转换为 UI 代码
了解 AI 如何从设计中推断布局、层级与用户意图,然后生成 UI 代码——以及其局限、最佳实践与审查要点。
了解 AI 如何从设计中推断布局、层级与用户意图,然后生成 UI 代码——以及其局限、最佳实践与审查要点。
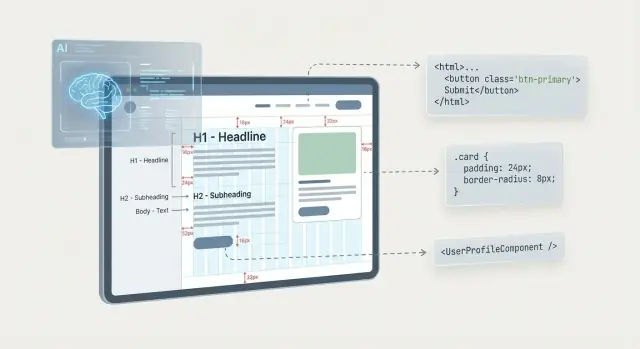
“设计到代码”AI 将一个视觉设计想法——通常是 Figma 的画框或一张截图——翻译成可运行的 UI 代码。目的不是“完美代码”;而是一个可用的初稿,捕捉结构、样式和基本行为,供人工进一步打磨。
系统的核心在于把它能观察到的东西映射到UI 通常如何构建上。
AI 能推断常见模式:一排图标很可能是工具栏;标签+输入的堆栈很可能是表单字段;一致的样式提示可复用组件。它也可能基于约束和间距猜测响应式行为。
但你通常必须指定像素无法保证的信息:真实的组件名称、设计 tokens(颜色/字号尺度)、状态(hover/disabled/error)、断点、数据规则和实际交互(校验、导航目标、分析埋点)。
将输出当作起点。预期需要审查结构、用 tokens 替换临时样式、与你的组件库对齐并迭代。“设计到代码”是加速器——不是能替代设计与工程判断的自动化工具。
AI 无法从“好看的一张界面”里推断产品规则。它依赖你提供的证据——有些输入描述像素,有些描述结构。这一区别常决定你得到的是干净的 UI 代码还是脆弱的绝对定位。
截图是最薄的输入:包含颜色和形状,但没有关于哪个是按钮、哪个是标签、哪些可复用、或布局如何适配的显式事实。
仅凭像素,AI 必须猜测边界(一个元素何处结束另一个开始)、文本样式、间距规则,甚至一个“卡片”是单个组件还是若干独立部分。它也无法推断约束——因此响应式行为多为臆测。
当 AI 可以访问设计文件(或保留结构的导出)时,它获得了关键元数据:画框、组、图层名、Auto Layout 设置、约束和文本/样式定义。
这时布局就不仅仅是几何。例如,带有 Auto Layout 的 Figma 画框可以传达像“垂直堆叠这些项目,间隔 16px”之类的意图,比任何截图都清晰得多。统一的图层命名也有助于把元素映射为 UI 角色(例如“Button/Primary”、“Nav Item”、“Input/Error”)。
连接好的设计系统能减少猜测。tokens(颜色、间距、排版)让 AI 生成引用共享真实来源的代码,而不是硬编码值。已发布的组件(按钮、字段、模态框)提供现成的构建块和更清晰的复用边界。
即便是小的约定——比如命名变体(Button/Primary, Button/Secondary)和使用语义 tokens(text/primary 而不是 #111111)——也能改善组件映射。
规范补充了 UI 背后的“为什么”:hover 行为、加载与空状态、校验规则、键盘行为和错误消息。
没有这些,AI 倾向生成静态快照。有了这些,输出可以包含交互钩子、状态处理和更现实的组件 API——更接近团队可以发布和维护的产物。
设计到代码的工具不会像人一样“看”屏幕;它们试图把每一层解释为布局规则:行、列、容器和间距。那些规则越清晰,输出就越少依赖脆弱的定位。
大多数模型会先寻找重复的对齐和等间距。如果多个元素共享相同的左对齐线、基线或中心线,AI 常把它们当作一列或网格轨道。一致的间距(例如 8/16/24px 模式)暗示布局可以用 stack gaps、grid gutter 或 token 化间距来表达。
当间距略有差异(这里 15px,那里 17px)时,AI 可能判定布局是“手工”的,从而退回到绝对坐标以保留像素精确距离。
AI 也会搜索视觉“封闭”:背景、边框、阴影和类似内边距的空隙,提示这是一个容器。带背景和内部内边距的卡片是父元素包含子元素的明显信号。
随后它通常会把结构映射为原语,比如:
设计文件中的清晰分组有助于区分父元素和兄弟元素。
如果设计包含约束(pin、hug、fill),AI 会用它们来决定什么会拉伸、什么保持固定。“Fill” 元素通常变成可伸缩宽度(例如 flex: 1),而 “hug” 映射为内容尺寸的元素。
当模型无法自信地用流式布局表达关系时(通常由于不一致的间距、重叠图层或错位元素),就会出现绝对定位。它在一种屏幕尺寸下看起来正确,但会破坏响应性和文字缩放。
使用小而统一的间距尺度并对齐到清晰的网格,会大大提高 AI 生成干净 flex/grid 代码而非坐标的概率。一致性不仅关乎美学——它是机器可读的模式。
AI 不是真正“理解”层级;它从通常表明层级的重要性模式中推断出优先级。设计越明确传达这些信号,生成的 UI 就越可能符合你的意图。
排版是最强的线索之一。更大的字号、更粗的字重、更高的对比度和更充裕的行高通常表示更高的优先级。
例如,32px 粗体标题在 16px 常规段落之上,是一个清晰的“标题 + 正文”模式。难点在于样式模糊时——比如两段文本仅差 1–2px 或使用相同字重但不同颜色——在这些情况下,AI 可能把两者都标注为普通文本或选择错误的标题级别。
层级还通过空间关系推断。更靠近、对齐并被空白与其他内容分隔的元素被视为一组。
常见的背景(卡片、面板、着色区段)像视觉括号:AI 往往把它们解释为 section、aside 或组件 wrapper。如果内边距不均或间距不一致,可能导致误把按钮附着到错误的卡片上。
重复模式——相同的卡片、列表项、行或表单字段——是可复用组件的强证据。哪怕有细微差别(图标大小、圆角、文本样式),也可能导致 AI 生成多个一次性的版本,而不是生成带变体的单一组件。
按钮通过大小、填充、对比度和位置传达意图。带填充且对比强的按钮通常被视为主要操作;轮廓或文本按钮则为次要。如果两个操作看起来同等突出,AI 可能猜错哪个是“主要”。
最后,AI 会尝试把层级映射到语义:标题(h1–h6)、分组区域(section)和有意义的簇(如“产品详情” vs “购买操作”)。清晰的排版步骤与一致的分组能使这种转换更可靠。
模型通过把所见与从大量 UI 学到的模式匹配来预测意图:常见形状、标签、图标语义和位置惯例。
某些布局强烈提示特定组件。顶部的横幅左侧有 logo、右侧有文本项,很可能是导航条。等宽项的一排且某项被高亮通常映射为标签页。带图片、标题和短文的重复箱子被读作卡片。带齐头对齐的密集网格通常变成表格。
这些判断很重要,因为它们影响结构:一个“标签页”暗含选中状态与键盘导航,而“一排按钮”可能没有这些替代行为。
AI 寻找通常表示交互的线索:
然后它会分配行为:点击、打开菜单、导航、提交、展开/收起。设计越能区分可交互与静态元素,输出就越准确。
如果设计展示了多个变体——hover、active/selected、disabled、error、loading——AI 可以把它们映射为有状态组件(例如 disabled 按钮、校验消息、占位加载器)。如果状态不明确,AI 可能会省略它们。
模糊是常见的:卡片是可点击还是信息型?箭头是装饰还是展开控制?遇到这些情况,请通过命名、注释或展示单独画框来澄清交互。
当 AI 对布局有了合理的读法后,下一步是把“看起来像什么”翻译为“它是什么”:语义 HTML、可复用组件和一致的样式。
大多数工具把设计图层和分组映射为 DOM 树:画框变成容器、文本图层变成标题/段落、重复项变成列表或网格。
当意图清晰时,AI 可能附加更好的语义——例如顶部栏变成 \u003cheader\u003e,logo 与链接变成 \u003cnav\u003e,可点击卡片变成 \u003ca\u003e 或 \u003cbutton\u003e。ARIA 角色有时可以被推断(比如对话框会是 role=\"dialog\"),但只有在模式不含糊时才会这样;否则更安全的输出是普通 HTML 加上待办的可访问性审查提示。
这是一种将视觉 UI(Figma 画框、设计导出或截图)翻译为可运行 UI 代码的 AI 辅助流程。目标是产生一个可靠的初稿——包含布局、样式节奏和基本结构——以便开发者能将其重构为使用 tokens、组件和生产级语义的代码。
它通常能翻译:
像素并不能编码所有信息。通常你需要提供或指定:
截图是最薄的信息:只有颜色和几何,没有显式结构(图层、约束、组件)。因此会有更多猜测、更多绝对定位,以及更少的可复用代码。
拥有结构化导出的 Figma/Sketch 文件 则包含画框、图层名、Auto Layout、约束和样式——这些信号能生成更干净的 flex/grid 布局和更准确的组件边界。
AI 会寻找重复的对齐方式和一致的间距,以把 UI 表达为 flex/grid 规则。如果发现清晰的间距节奏(如 8/16/24),通常能生成稳定的堆叠与网格。
如果间距不一致或元素略微错位,模型常会退回到绝对坐标以保留像素级外观——代价是响应性变差。
它会寻找视觉“封闭”信号:
在设计工具中干净的分组与一致结构(画框、Auto Layout)使得父子关系更容易在代码中重建。
当关系不明确时(重叠、不一致间距、手动微调或分组不清),绝对定位会出现。它可能在某一屏幕尺寸下看起来正确,但在:
容易出问题。如果希望输出更灵活,请通过 Auto Layout 与约束让设计表现得像 flex/grid。
AI 从视觉线索推断层级:
当样式仅差 1–2px 或层级步骤不清时,它可能选择错误的标题级别或把标题当作普通文本。
AI 根据界面约定猜测交互性:
如果一个“卡片”既可能是可点击也可能只是信息展示,请注释或展示变体;否则模型可能接错交互或直接忽略。
做一个快速、有结构的审核:
把输出当作脚手架,然后记录假设,避免后续被错误覆盖。