2025年7月15日·1 分钟
按使用量计费的实现:计量与对账
按使用量计费的实现:应该计量什么、在哪里计算总量,以及在发票发出前捕捉计费错误的对账检查。
使用计费出错的直白说法
使用计费会在发票上的数字与产品实际交付不一致时崩坏。差距一开始可能很小(少量缺失的 API 调用),然后演变成退款、愤怒的工单,以及不再信任仪表盘的财务团队。
原因通常是可预测的。事件丢失可能是因为某个服务在上报使用量前崩溃、队列故障或客户端离线。事件被重复计入是因为发生了重试、worker 重处理了同一条消息,或导入任务被再次运行。时间也会带来问题:服务器间的时钟漂移、时区、夏令时以及迟到的事件可能把使用量推到错误的计费期。
举个简单例子:一个按 AI 生成收费的聊天产品在请求开始时可能发出一条事件,在完成时再发一条。如果你从“开始事件”计费,会对失败收费;如果从“完成事件”计费,则当最终回调未到达时会漏计;如果两者都计费,就会重复收费。
多方都需要信任同一组数字:
- 客户需要发票与他们感受到的使用相符。
- 支持需要一条清晰的线索来快速回答“我为什么被收费?”。
- 财务需要能用来结账的总额,而不是估算值。
- 工程需要在钱受影响之前捕捉到计量错误的信号。
目标不仅仅是准确的总额,还要能解释的发票和快速的争议处理。如果你不能把一行账目追溯到原始使用事件,一次故障就能把你的计费变成猜测,这就是计费错误变成计费事故的时候。
定义可计费的单位与计费规则
先问一个简单问题:你到底在收什么费?如果你不能在一分钟内解释清楚该单位和规则,系统最终会猜测,客户会发现。
每个计量器选择一个主要的可计费单位。常见选择有 API 调用、请求、tokens、计算分钟数、存储 GB、传输 GB 或席位数。除非真的需要,避免混合单位(比如“活跃用户分钟”),它们更难审计和解释。
要明确使用的边界。具体说明何时开始和结束计量:试用是否包含计量超额,还是在某个上限内免费?如果你提供宽限期,宽限期内的使用是以后计费还是免除?计划变更是混乱的高发地。决定是否按比例计费、立即重置配额,还是在下个计费周期生效。
把四舍五入和最小值写下来,不要让它们成为隐含规则。例如:向上取整到最近的秒、分钟或 1,000 tokens;应用每日最低收费;或实施最小可计费增量(例如 1 MB)。这类小规则往往产生大量“我为什么被收费?”的工单。
值得早点敲定的规则:
- 可计费单位及其精确定义。
- 何时开始和停止计数(试用、宽限、取消、计划变更)。
- 四舍五入规则、最低收费和免费层。
- 超额时退款、抵扣和善意调整如何应用。
示例:一个团队在 Pro 套餐,月中升级。如果你在升级时重置配额,他们可能在一个月内实际上得到了两次免费配额。如果不重置,他们可能会觉得升级被惩罚了。任何选择都可以,只要一致、可文档化并且可测试。
要跟踪哪些事件(以及那些你以后会后悔没记录的字段)
决定什么算作可计费事件,并以数据形式写下来。如果你不能仅从事件中重放“发生了什么”的故事,争议时你就会进行猜测。
要记录的事件类型
不仅要记录“发生了使用”。你还需要记录会改变客户应付金额的事件。
- 使用消耗(可计费动作:API 调用、token、分钟、席位-天等)。
- 授予信用(促销信用、补偿信用、推荐信用)。
- 退款或调整(手动或自动修正)。
- 计划变更(升级、降级、试用开始/结束)。
- 取消(以及任何服务结束时间戳)。
以后你会想要但现在容易忽略的字段
大多数计费错误来自缺少上下文。现在就捕获那些无聊但有用的字段,这样支持、财务和工程能在以后回答问题。
- 租户或帐号 ID,加上可选的用户 ID(谁付费、谁触发)。
- 精确的 UTC 时间戳(以及单独的摄取时间戳)。
- 数量和单位(10 次请求、3.2 GB-小时、1 席位-天)。
- 来源(服务名、环境和精确的功能名)。
- 稳定的幂等键(对应真实世界动作的唯一键以防重复)。
支持级的元数据也很值钱:请求 ID 或 trace ID、区域、应用版本,以及应用的定价规则版本。当客户说“我在 14:03 被收费两次”,这些字段能让你证明发生了什么、安全地撤销并防止复发。
在哪里发出事件以便被信任
第一条规则很简单:从真正知道工作已发生的系统发出可计费事件。大多数情况下,这是你的服务器,而不是浏览器或移动端。
客户端计数容易伪造也容易丢失。用户可以拦截请求、重放请求或运行旧代码。即便没有恶意,移动应用也会崩溃、时钟会漂移且会发生重试。如果必须读取客户端信号,把它当作提示而不是发票依据。
一个实用的方法是在后端在达到不可逆点时发出使用事件,例如你持久化了记录、作业完成,或返回了可证明已生成的响应。可信的发出点包括:
- 在主数据库成功写入之后(动作现在是持久的)。
- 在后台作业完成之后(而不是入队时)。
- 在 API 网关或后端端点,在授权后并返回最终状态码时。
- 在实际消耗计算或调用付费第三方 API 的 worker 上。
- 在计费服务自身,当它确认某付费功能被解锁时。
离线移动是主要例外。如果一个 Flutter 应用需要在离线下工作,它可能会本地计数并稍后上传。要加入防护:包括唯一事件 ID、设备 ID 和单调序列号,并让服务器校验能校验的内容(账户状态、计划限制、重复 ID、不可能的时间戳)。当应用重新连接时,服务器应以幂等方式接受事件,这样重试不会重复收费。
事件的时机取决于用户期望看到的内容。实时适用于客户在仪表盘中观察使用量的 API 调用。近实时(每几分钟)通常足够且更便宜。批量适用于高流量信号(如存储扫描),但要清楚延迟并使用相同的事实来源规则以免迟到数据悄然更改过去的发票。
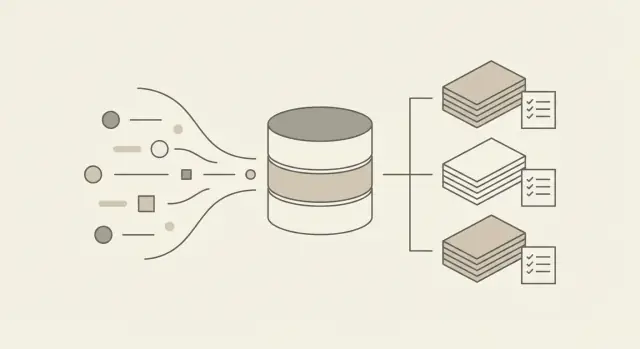
在哪里计算总量:原始事件还是聚合使用
你需要两样看起来重复但能在以后省事的东西:不可变的原始事件(发生了什么)和派生的总量(你要计费的东西)。原始事件是你的事实来源。聚合使用是你快速查询、向客户解释并生成发票的对象。
你可以在两处常见的位置计算总量。把逻辑放在数据库中(SQL 作业、物化表、定时查询)起步更容易,且逻辑靠近数据。一个专门的聚合服务(读取事件并写入汇总的小 worker)更容易版本化、测试和扩展,并能在不同产品间强制一致规则。
为什么应同时保留两层
原始事件保护你免于错误、退款和争议。聚合保护你免于缓慢的发票和昂贵的查询。如果你只保存聚合,一条错误规则可能永久破坏历史。
一个实用的设置:
- 存储 append-only 的原始事件。
- 构建小时和每日的汇总以便快速报告。
- 构建仅用于出具发票的计费周期总量并冻结。
明确聚合窗口。选择一个计费时区(通常是客户的,或对所有人使用 UTC)并坚持它。“日”的边界随时区而变,当使用量在天之间移动时客户会注意到。
迟到和乱序事件是常态(移动离线、重试、队列延迟)。不要因为迟到事件到达就悄悄更改过去的发票。使用“关闭并冻结”规则:一旦计费周期开票,就在下一张发票中以调整的形式写入修正并注明原因。
示例:如果按月计费 API 调用,你可以为仪表盘做小时汇总,为告警做每日汇总,为开票做月度冻结总计。如果 200 次调用延迟两天到达,记录它们,但作为下月的 +200 调整计费,而不是重写上个月的发票。
一个简单的逐步计量管道
让发票可解释
生成内部管理界面,将发票追溯到原始事件。
工作中的使用管道主要是数据流加上严格的防护。把顺序做好,你以后就能在不手工重处理所有数据的情况下更改定价。
第 1 步:在信任事件前先让它们一致化
事件到达时,立即校验并标准化。检查必需字段、单位转换(字节换成 GB、秒换成分钟),并把时间戳钳制到清晰的规则(事件时间 vs 接收时间)。如果有问题,把它作为被拒绝事件连同原因存储,而不是悄悄丢弃。
标准化后,保持 append-only 思维,不要就地“修历史”。原始事件是你的事实来源。
第 2-6 步的实践
以下流程适用于大多数产品:
- 存储不可变的原始事件(append-only),包括已标准化的载荷和原始载荷。
- 用幂等键和唯一性规则去重(例如:account_id + event_name + idempotency_key)。
- 按计费周期对每个客户聚合总量(小时或每日汇总通常足够)。
- 将总量定价为可出具发票的行项(阶梯、包含包、最低值、折扣)。
- 生成引用确切聚合版本的发票草稿。
然后冻结该发票版本。“冻结”意味着保留审计轨迹,回答这些问题:哪些原始事件、哪个去重规则、哪个聚合代码版本以及哪个定价规则产生了这些行项。如果你后来改价格或修复 bug,创建一个新的发票修订,而不是悄悄修改。
如何避免重复收费和漏计使用
重复收费和漏计使用通常来自同一个根本问题:你的系统无法判断一个事件是新的、重复的还是丢失的。这与聪明的计费逻辑关系不大,而与事件身份和校验的严格控制关系更大。
幂等键是第一道防线。生成一个对真实世界动作稳定的键,而不是针对 HTTP 请求的键。一个好的键是确定性的并对每个可计费单位唯一,例如:tenant_id + billable_action + source_record_id + time_bucket(只有在单位基于时间时才使用时间桶)。在第一个持久写入点(通常是摄取数据库或事件日志)通过唯一约束强制它,这样重复就不会落地。
重试和超时是正常的,所以为它们设计。客户端在收到 504 后可能再次发送同一事件,即使你已经收到了。你的规则应该是:接受重复,但不重复计数。把接收和计数分开:做幂等的摄取,然后从存储的事件做聚合。
校验能防止“不可能的使用量”破坏总量。既要在摄取时校验,也要在聚合时再校验一次,因为两处都可能出错。
- 除非产品确实支持用负数表示信用或退款,否则拒绝负数量。
- 把单位锁定为单一规范形式(秒 vs 毫秒,tokens vs 字符)。
- 在可行时要求类似货币的精度规则(例如仅整数单位)。
- 只允许已知的计量器和已知的计划映射。
漏计使用最难被发现,所以把摄取错误当作一等公民数据处理。把失败的事件单独存储,字段与成功事件相同(包括幂等键),并附上错误原因和重试计数。
提前捕捉计费错误的对账检查
明确规划计费规则
在编写任何事件模式前,将计量器、规则和对账检查绘制清楚。
对账检查是那些无聊但关键的防护,它们能在客户发现前捕捉“我们多收了”或“我们漏计了”的问题。
先在两处对同一时间窗口进行对账:原始事件与聚合使用。选择一个固定窗口(例如昨天的 UTC),然后比较计数、总和和唯一 ID。小差异会发生(迟到事件、重试),但它们应该能用已知规则解释,而不是神秘的差额。
接着,对账你实际计费的内容与你定价的内容。发票应该能从某个已定价的使用快照重现:确切的使用总量、确切的价格规则、确切的货币和确切的四舍五入。如果当你再次运行计算时发票会改变,那你拿到的不是发票,而是猜测。
每日的健康检查能抓住不是“数学错了”而是“现实奇怪”的问题:
- 对于通常活跃的客户出现零使用(可能是摄取失败)。
- 突然的峰值(可能是重复事件或重试风暴)。
- 部署后立即出现的骤降(可能是计量器重命名或过滤错误)。
- 与客户自身历史相比的异常(可能是时间窗口错误)。
- 与类似客户相比的异常(可能是定价层映射错误)。
当发现问题时,你需要后填流程。后填要有意图并记录。记录修改了什么、哪个窗口、哪些客户、谁触发以及原因。把调整当作会计分录,而不是悄悄修改。
一个简单的争议工作流能让支持镇静。当客户质疑一笔费用时,你应该能用相同的快照和定价版本从原始事件中重现他们的发票。那会把模糊的抱怨变成可修复的 bug。
常见错误和陷阱(别在生产上学这些教训)
大多数计费火灾不是由复杂的数学造成的,而是由在最糟时刻才暴露的小假设引起:月末、升级后或重试风暴中。小心主要是选定时间、身份和规则的一个真相,然后拒绝弯曲它。
会造成错误发票的陷阱
这些问题在成熟团队中也会反复出现:
- 使用了错误的时间戳:如果你按摄取时间计费而不是事件时间,延迟批次会把真实使用推到下个月。选一个“计费时间”字段并记录它,把摄取时间仅用于调试。
- 同一动作被计了两次:很容易在 API 网关和应用服务两处计量。如果两者都发出可计费事件,就会重复收费。为每个单位决定哪个层是事实来源。
- 计划变更破坏总量:月中升级可以把一个月分成两个规则集。如果你把新价格应用到整个月,客户会注意到。你需要按比例计费规则和明确的“生效时间”。
- 不小心改写历史:如果不对定价规则版本化,重跑和后填会用新价格重算旧发票。为每条发票行存储使用的定价版本。
- 没测试失败场景:重试、部分失败、并发和后填是常态。如果管道不是幂等的,同一事件可能被重复计费或悄悄丢失。
示例:客户在 20 号升级,而你的事件处理器在超时后重试了前一天的数据。没有幂等键和规则版本化,你可能会重复计入 19 号,并用新价格对 1-19 号进行计费。
示例:把真实使用事件变成一张发票
下面是一个简单示例,客户 Acme Co 在三个计量器上计费:API 调用、存储(GB-天)和高级功能运行。
这是应用在一天(1 月 5 日)发出的事件。注意能让故事易于重建的字段:event_id、customer_id、occurred_at、meter、quantity 和幂等键。
{"event_id":"evt_1001","customer_id":"cust_acme","occurred_at":"2026-01-05T09:12:03Z","meter":"api_calls","quantity":1,"idempotency_key":"req_7f2"}
{"event_id":"evt_1002","customer_id":"cust_acme","occurred_at":"2026-01-05T09:12:03Z","meter":"api_calls","quantity":1,"idempotency_key":"req_7f2"}
{"event_id":"evt_1003","customer_id":"cust_acme","occurred_at":"2026-01-05T10:00:00Z","meter":"storage_gb_days","quantity":42.0,"idempotency_key":"daily_storage_2026-01-05"}
{"event_id":"evt_1004","customer_id":"cust_acme","occurred_at":"2026-01-05T15:40:10Z","meter":"premium_runs","quantity":3,"idempotency_key":"run_batch_991"}
在月末,你的聚合作业按 customer_id、meter 和计费周期对原始事件分组。1 月的总量是整月求和:API 调用合计为 1,240,500;存储 GB-天合计为 1,310.0;高级运行合计为 68。
现在在 2 月 2 日来了一条迟到事件,但它属于 1 月 31 日(某移动客户端离线)。因为你按 occurred_at(而不是摄取时间)聚合,1 月总量会变化。你要么(a)在下张发票上生成一行调整,要么(b)如果政策允许就重发 1 月的发票。
对账在这里能捕捉到一个 bug:evt_1001 和 evt_1002 共享相同的 idempotency_key(req_7f2)。你的检查会标记“同一次请求有两个计费事件”,并在开票前把一条标记为重复并去除。
支持可以这样解释:“由于重试,我们看到了同一 API 请求的重复上报。我们移除了重复使用事件,因此你只被收费一次。发票中包含反映已修正总量的调整。”
上线使用计费前的快速检查表
从原型到部署
当你准备好与团队共享时,部署并托管你的内部计费工具。
在启用计费前,把你的使用系统当成一个小型财务账本对待。如果你不能重放相同的原始数据并得到相同的总额,你会花很多夜晚来追踪“不可思议”的费用。
把这个检查表作为最后的门槛:
- 每个事件完整且可追溯。 每条记录包含客户 ID、时间戳(含时区)、单位名、数量、来源(服务/作业名)和幂等键,避免重试造成的额外使用。
- 原始事件是 append-only。 不要编辑或删除历史。如果需要更正,则写入新的调整事件。聚合应从原始事件派生并能从头重现。
- 三个地方的总额一致。 对于抽样的客户和日期,原始事件总和应与聚合使用表一致,且两者应与计费时存储的“发票快照”一致。
- 计划变更和钱的变动是显式事件。 升级、降级、中期按比例计费、退款和抵扣应建模为事件(或账本条目),而不是隐藏在某个计费脚本里的逻辑。
- 建立安全告警。 当应该有事件但无摄取时触发警报、对峰值或骤降报警、负总额报警和重复幂等键报警。包含一个日报对账作业,上报差异而不仅仅是通过/失败。
一个实用的测试:选一个客户,把最近 7 天的原始事件重放到一个干净的数据库,然后生成使用量和发票。如果结果与生产不同,那你面对的是决定性问题,而不是数学问题。
下一步:安全上线并在不出乎意料下迭代
把首次发布当成试点。先选一个可计费单位(例如“API 调用”或“GB 存储”)和一个对账报告,用来比较你预期计费的内容与实际计费的内容。一旦该项在一个完整周期内保持稳定,再加入下一个单位。
上线第一天就让支持和财务成功,给他们一个简单的内部页面,展示两边:原始事件和最终进入发票的计算总量。当客户问“我为什么被收费?”时,你希望有一个单一屏幕能在几分钟内回答。
在向真实货币收费前,重放现实。使用暂存数据模拟整个月的使用,运行聚合,生成发票,并将结果与手动计数的小样本对比。挑选一些使用模式不同的客户(低量、脉冲型、稳定型),验证他们的总量在原始事件、每日汇总和发票行项之间保持一致。
如果你在构建计量服务本身,一个像 Koder.ai(koder.ai)这样的 vibe-coding 平台可以快速原型化一个内部管理界面和一个 Go + PostgreSQL 后端,然后在逻辑稳定后导出源码。
当计费规则改变时,通过发布流程减少风险:
- 在变更前快照当前规则和聚合逻辑。
- 在暂存环境用新规则运行整月重放。
- 对比同一时期下新旧发票的差异。
- 如果总额漂移或对账失败,快速回滚。
- 只有在一个干净的计费周期后再扩展到新单位。
常见问题
What does it mean when “usage billing breaks”?
按使用计费会在发票总额与产品实际交付不一致时出现故障。
常见原因包括:
- 丢失事件(服务崩溃、队列中断、客户端离线)
- 重复事件(重试、重复处理、导入重跑)
- 时间问题(时钟漂移、时区、延迟事件落入错误的计费周期)
解决办法不是更复杂的数学,而是让事件可信、可去重并且端到端可解释。
How do I choose the right billable unit and rules?
为每个计量器选择一个清晰的单位并能一句话定义它(例如:“一次成功的 API 请求”或“一次完整的 AI 生成”)。
然后写下客户会争论的规则:
- 何时开始/停止计数(试用、宽限、取消)
- 计划变更时如何处理(按比例计费 vs 重置 vs 下个周期生效)
- 四舍五入和最小增量
如果你不能快速解释单位和规则,以后核查和支持时会很难。
Which event types should I track for usage billing?
跟踪使用量本身,同时也要跟踪会改变客户账单的“金钱相关”事件。
至少要包含:
- 使用消耗(可计费行为)
- 授予的信用(促销、补偿、推荐信用)
- 退款/调整(手动或自动)
- 计划变更(升级/降级、试用开始/结束)
- 取消(以及服务终止时间)
这样在计划变化或修正发生时,发票能被重现。
What fields should every usage event include?
捕获你需要用于回答“我为什么被收费?”的上下文,避免以后猜测:
- 帐号/租户 ID(可选用户 ID)
occurred_at的 UTC 精确时间戳,并另外保留摄取时间- 数量 + 单位(保持单一规范单位)
- 计量器/功能名 + 来源服务/作业名
- 稳定的幂等键(对应真实世界动作唯一)
支持级的额外字段(请求/跟踪 ID、区域、应用版本、定价规则版本)能让争议快速解决。
Where should usage events be emitted from so they’re trustworthy?
应从真正知道工作已完成的系统发出计费事件——通常是你的后端,而不是浏览器或移动端。
好的发出点是“不可逆”的时刻,例如:
- 在主数据库成功写入之后(动作已持久化)
- 在后台作业完成之后(而不是入队时)
- 在授权后并返回最终状态码的 API 网关或后端端点
- 实际消耗计算或调用付费第三方 API 的 worker
客户端信号容易丢失或伪造,除非能强校验,否则把它们当做提示而非账单依据。
Should I bill from raw events or from aggregated totals?
两者都要用:
- 原始事件(append-only):作为审计、争议和回填的事实来源
- 聚合使用量:用于快速查询、仪表盘和出具发票
仅保存聚合的话,一条错误规则可能永久破坏历史;仅保存原始事件则会让发票和仪表盘变慢且昂贵。
How do I prevent double charging when retries happen?
通过设计让重复计费变得不可能:
- 生成代表“真实世界行为”的幂等键,而不是 HTTP 尝试的随机键
- 在第一个持久写入处强制唯一性(例如唯一约束)
- 安全地接受重试:保证摄取是幂等的,然后从存储的事件做聚合
这样超时重试就不会导致重复收费。
What should I do with late or out-of-order events?
选择明确的策略并自动化处理:
实用默认是:
- 按
occurred_at(事件时间)聚合,而不是按摄取时间 - 对已开票周期采用“关闭并冻结”规则,这样延迟到达不会改写历史发票
- 将延迟使用作为下次发票的调整记录并注明原因
这能保持账务清晰,避免过去的发票被悄然修改。
What reconciliation checks catch billing bugs before customers do?
每天运行一些小而无聊的检查——它们能在客户发现问题前捕捉到昂贵的错误。
有用的对账项:
- 同一时间窗口内原始事件与聚合结果的对比(计数、总和、唯一 ID)
- 计价后的总额与发票行项的对比(使用相同规则版本应可重现)
- 异常检测(突增/骤降、活跃客户为零等)
差异应该能用已知规则(延迟事件、去重)解释,而不是莫名其妙的差额。
How can support answer “why was I charged?” quickly?
让发票有一致的“纸链”:
- 存储支持该费用的原始事件
- 存储生成聚合时使用的聚合版本和定价规则版本
- 保留可重现的发票快照
当有工单时,支持应该能回答:是哪几条事件产生该行项、是否删除了重复项(及原因)、是否施加了调整或抵扣。这把争议变成可查的事情,而不是人工调查。