2025年10月02日·2 分钟
Brendan Burns 与 Kubernetes:塑造编排的思想
实用梳理 Brendan Burns 在 Kubernetes 时代提出的编排理念——声明式期望状态、控制器与调和、调度与缩放、服务运行与自愈——以及它们为何成为行业标准。
实用梳理 Brendan Burns 在 Kubernetes 时代提出的编排理念——声明式期望状态、控制器与调和、调度与缩放、服务运行与自愈——以及它们为何成为行业标准。
Kubernetes 不只是引入了一个新工具——它改变了在运行几十(或数百)个服务时的“日常运维”长什么样。 在出现编排之前,团队常常把脚本、手动运行手册和部落知识拼接起来,去回答那些反复出现的问题:这个服务应该运行在哪里?我们如何安全地发布变更?当节点在凌晨 2 点宕机时怎么办?
从本质上讲,编排是你意图(“像这样运行这个服务”)与机器会出故障、流量会移动、部署会持续发生这类混乱现实之间的协调层。与其把每台服务器当成独一无二的“雪花”,不如把计算资源视为一个池,把工作负载视为可调度的单元,这些单元可以移动。
Kubernetes 推广了一种模型:团队描述他们想要的内容,系统持续地努力让现实匹配那个描述。这种转变很重要,因为它将运维从个人英雄主义变成可重复的流程。
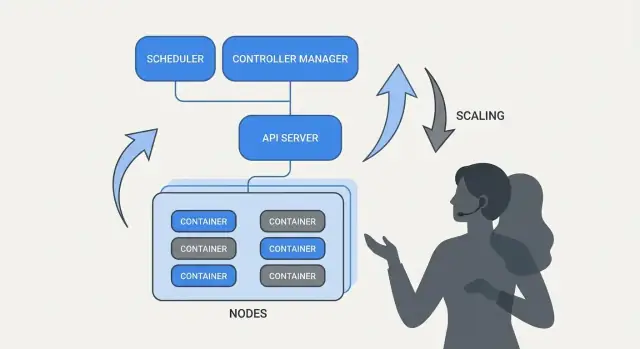
Kubernetes 为大多数服务团队规范化了他们需要的运维结果:
本文聚焦于与 Kubernetes(以及像 Brendan Burns 这样的领导者)相关的思想与模式,而不是个人传记。谈到“它是如何开始的”或“为什么这样设计”,这些说法应以公开来源为依据——会议演讲、设计文档和上游文档——以便于可验证,而非流于传闻。
Brendan Burns 被广泛认为是与 Joe Beda 和 Craig McLuckie 一起的三位 Kubernetes 最初联合创始人之一。在 Google 的早期 Kubernetes 工作中,Burns 帮助塑造了技术方向以及向用户解释项目的方式——尤其是围绕“你如何运维软件”而不是仅仅“如何运行容器”。(来源:Kubernetes: Up & Running,O’Reilly;Kubernetes 项目仓库中的 AUTHORS/maintainers 列表)
Kubernetes 并不是作为一个内部完成的系统被“发布”出来;它是在公众场合与不断增长的贡献者、用例和约束一起构建的。这种开放性推动项目朝着能在不同环境中存活的接口演进:
这种协作压力很关键,因为它影响了 Kubernetes 优化的目标:共享原语和可重复的模式,让许多团队即使在工具选择上存在分歧,也能达成一致。
当人们说 Kubernetes “标准化”了部署和运维,他们通常并不是指它让每个系统都相同。他们的意思是它提供了一个通用词汇和一套可以在团队间重复使用的工作流:
这种共享模型让文档、工具和团队实践更容易从一家公司迁移到另一家。
把 Kubernetes(开源项目) 与 Kubernetes 生态系统 区分开是有用的。
项目本身是实现平台的核心 API 和控制平面组件。生态系统则是围绕它成长起来的所有东西——发行版、托管服务、插件以及相邻的 CNCF 项目。许多现实中人们依赖的“Kubernetes 功能”(可观测性栈、策略引擎、GitOps 工具)存在于生态系统中,而不是核心项目里。
声明式配置是在描述系统时的一个简单转换:你不是列出要采取的步骤,而是陈述你想要的最终结果。
在 Kubernetes 中,你不会告诉平台“启动一个容器,然后打开端口,然后在它崩溃时重启它”。你声明“应该有三个该应用的副本在运行、在这个端口可达、使用这个镜像”。Kubernetes 负责让现实与该声明匹配。
命令式运维更像是运行手册:一系列上次可行的命令,当情况改变时再次执行。
期望状态更像是一份契约。你在配置文件中记录预期结果,系统不断朝这个结果工作。如果发生漂移——实例挂掉、节点消失、有人偷偷做了手动修改——平台会检测到不一致并纠正它。
之前(命令式运行手册思维):
这种方式可行,但很容易产生“雪花”服务器和只有少数人信任的长长检查表。
之后(声明式期望状态):
apiVersion: apps/v1
kind: Deployment
metadata:
name: checkout
spec:
replicas: 3
selector:
matchLabels:
app: checkout
template:
metadata:
labels:
app: checkout
spec:
containers:
- name: app
image: example/checkout:1.2.3
ports:
- containerPort: 8080
你修改文件(例如更新 image 或 replicas),应用它,Kubernetes 的控制器会努力将正在运行的状态与声明匹配。
声明式的期望状态将“做这 17 个步骤”变成“保持成这样”。它也减少了配置漂移,因为事实上的真相来源是显式且可审查的——通常保存在版本控制中——因此意外更容易被发现、审计并一致地回滚。
Kubernetes 给人“自我管理”的感觉,是因为它围绕一个简单模式构建:你描述想要的,系统持续工作以让现实匹配该描述。这个模式的引擎就是控制器。
控制器是一个循环,它监视集群的当前状态并与你在 YAML(或通过 API 调用)中声明的期望状态比较。当发现差距时,它会采取行动来缩小差距。
这不是一次性脚本,也不是等待人为点击。它会重复运行——观察、决策、动作——因此能随时响应变化。
这种重复的比较与修正行为称为调和(reconciliation)。它是“自愈”这一常见承诺背后的机制。系统并不神奇地阻止故障;它发现漂移并纠正它。
漂移可能由平凡的原因引起:
调和意味着 Kubernetes 将这些事件视为重新检查你意图并恢复它的信号。
控制器带来了熟悉的运维结果:
关键在于你不再被动追逐症状,而是声明目标,控制回路持续做“保持”的工作。
这种方法不限于一种资源类型。Kubernetes 在许多对象上使用相同的控制器与调和思想——Deployments、ReplicaSets、Jobs、Nodes、Endpoints 等。那种一致性是 Kubernetes 成为平台的一个重要原因:一旦你理解了这个模式,就能预测当添加新能力(包括遵循相同循环的自定义资源)时系统会如何表现。
如果 Kubernetes 只是“运行容器”,它仍然会把最难的部分留给团队:决定每个工作负载应该在哪儿运行。调度器是内建的系统,会根据资源需求和你定义的规则自动将 Pods 放到合适的节点。
这很重要,因为放置决定直接影响可用性和成本。卡在拥挤节点上的 web API 可能变慢或崩溃。与延迟敏感服务相邻放置的批处理作业可能产生嘈杂邻居问题。Kubernetes 将其变成可重复的产品能力,而不是电子表格和 SSH 的惯例。
在基本层面,调度器寻找可以满足 Pod 请求的节点。
这个单一习惯——设定现实的 requests——常常能减少“随机”不稳定,因为关键服务不再与所有其它负载争抢资源。
除了资源之外,大多数生产集群依赖一些实用规则:
调度特性帮助团队把运维意图编码进去:
关键的实用结论:把调度规则当作产品需求——记录它们、审查它们并一致地应用——这样可靠性就不会依赖于某人在凌晨 2 点记住“正确节点”的事情。
Kubernetes 最实用的思想之一是:缩放不应该要求改变应用代码或发明新的部署方式。如果应用可以作为一个容器运行,同样的工作负载定义通常可以扩展到数百或数千个副本。
Kubernetes 将缩放分为两个相关但不同的决策:
这种划分很重要:你可以请求 200 个 Pod,但如果集群只有放置 50 个的空间,“扩缩”就会变成一队待调度的挂起任务。
Kubernetes 通常使用三种自动扩缩器,每种关注不同的杠杆:
合并使用时,这把缩放变成策略:例如“保持延迟稳定”或“让 CPU 维持在 X%”,而不是手动唤醒某人去扩容。
缩放的效果取决于输入:
两个错误经常出现:基于错误指标缩放(CPU 很低但请求超时)和缺少资源请求(自动扩缩器无法预测容量,Pod 被过度打包,性能不稳定)。
Kubernetes 推广的一个重大转变是把“部署”视为一个持续的控制问题,而不是你在周五下午 5 点运行的一次性脚本。滚动发布和回滚是一级公民:你声明想要的版本,Kubernetes 会在不断检查变更是否安全的同时把系统推进到那个版本。
使用 Deployment,发布是旧 Pod 向新 Pod 的逐步替换。Kubernetes 可以分阶段进行更新——在新版本证明能处理真实流量的同时保持可用容量。
如果新版本开始失败,回滚不是紧急程序,而是正常操作:你可以回退到前一个 ReplicaSet(上一个已知良好版本),让控制器恢复旧状态。
健康检查使得发布从“靠运气”变为可度量:
合理使用探针可以减少“看起来正常但实际请求失败”的错误成功例。
Kubernetes 内建支持 滚动更新,但团队常在其上加层策略:
安全部署依赖于信号:错误率、延迟、饱和度和用户影响。许多团队将发布决策与 SLO 与误差预算 关联——如果金丝雀消耗过多预算,则停止推广。
目标是基于真实指标触发自动回滚(失败的 readiness、上升的 5xx、延迟尖峰),使“回滚”成为可预测的系统响应,而不是熬夜的英雄式操作。
只有在系统的其他部分仍能在你的应用移动后找到它时,容器平台才感觉“自动化”。在真实的生产集群中,Pods 会不断创建、删除、重新调度和扩缩。如果每次变化都要在配置中更新 IP 地址,运维就会变成持续忙碌的工作——停机会频繁发生。
服务发现是为客户端提供可达一组不断变化后端的可靠方式。在 Kubernetes 中,关键转变是你不再指向单个实例(“调用 10.2.3.4”),而是指向一个命名的 Service(“调用 checkout”)。平台处理哪个 Pod 当前为该名称提供服务。
一个 Service 是一组 Pod 的稳定前门。它在集群内有一个一致的名称和虚拟地址,即便底层 Pod 在变化。
Selector 决定 Kubernetes 哪些 Pod 在该前门后面。通常通过标签匹配,如 app=checkout。
Endpoints(或 EndpointSlices)是当前匹配 selector 的实际 Pod IP 的实时列表。当 Pods 扩缩、发布或被重新调度时,这个列表会自动更新——客户端继续使用同一个 Service 名称。
在运维上,这提供了:
对于入站流量(从集群外部),Kubernetes 通常使用 Ingress 或更新的 Gateway 方式。两者都提供受控的入口点,可按主机名或路径路由请求,并常常集中处理 TLS 终止。重要的思想不变:在后端变化时保持外部访问的稳定。
Kubernetes 的“自愈”不是魔法,而是一组对故障的自动反应:重启、重新调度和替换。平台会监视你声明的期望状态,并不断推动现实向其靠拢。
如果进程退出或容器变得不健康,Kubernetes 可以在同一节点上重启它。这通常由:
常见生产模式:单个容器崩溃 → Kubernetes 重启它 → Service 仅将流量路由到健康的 Pod。
如果整个节点宕机(硬件问题、内核崩溃、网络丢失),Kubernetes 会将该节点标记为不可用并把工作负载迁移到别处。总体流程:
这是集群层面的“自愈”:系统替换容量,而不是等待人为 SSH 进入修复。
自愈之所以重要,前提是你能验证它。团队通常监控:
即便使用 Kubernetes,如果护栏配置错误,“自愈”也会失败:
当自愈设置得好,故障变得更小、更短,并且更重要的是,更易于衡量。
Kubernetes 赢得广泛采用并不仅因为它能运行容器,而是它为最常见的运维需求提供了标准 API——部署、缩放、网络和观察。当团队在对象形状上(如 Deployment、Service、Job)达成一致时,工具可以在组织间共享,培训更简单,开发与运维的交接也不再依赖部落知识。
一致的 API 意味着你的部署管道无需了解每个应用的特性。它可以使用相同的操作——创建、更新、回滚、检查健康——应用相同的 Kubernetes 概念。
它也改善了对齐:安全团队可以把护栏表达为策略;SRE 可以围绕常见健康信号标准化运行手册;开发者可以用共同的词汇来推理发布。
当你使用 Custom Resource Definitions (CRDs) 时,“平台”这一转变变得显而易见。CRD 让你向集群添加新的对象类型(例如 Database、Cache 或 Queue),并以与内建资源相同的 API 模式进行管理。
Operator 将这些自定义对象与控制器配对,持续把现实调和到期望状态——自动化以往手动的任务,如备份、故障切换或版本升级。关键好处不是魔法自动化,而是重用 Kubernetes 对一切资源都采用的相同控制循环方法。
因为 Kubernetes 是 API 驱动的,它能很好地与现代工作流集成:
如果你想阅读更多基于这些思想的实际部署与运维指南,请浏览 /blog。
最大的 Kubernetes 思想——许多与 Brendan Burns 早期表述相关——即使你在运行虚拟机、serverless 或较小的容器集群也同样适用。
把“期望状态”写下来并让自动化来执行。 无论使用 Terraform、Ansible 还是 CI 管道,都要把配置当作可信来源。结果是更少的手动部署步骤和更少的“我机器上能跑”的惊喜。
使用调和而不是一次性脚本。 与其运行只做一次的脚本并寄希望于结果,不如构建持续验证关键属性(版本、配置、实例数量、健康)的循环。这就是获得可重复运维和故障后可预测恢复的方法。
把调度和缩放当作产品特性。 定义何时以及为何增加容量(CPU、队列深度、延迟 SLO)。即便没有 Kubernetes 的自动扩缩,团队也可以标准化扩缩规则,使增长不需要重写应用或叫醒某人。
标准化发布。 滚动更新、健康检查和快速回滚过程能降低变更风险。可以用负载均衡器、功能开关和在真实信号上门控发布的部署管道来实现这些。
这些模式不会修复 糟糕的应用设计、不安全的数据迁移 或 成本控制。你仍然需要版本化 API、迁移方案、预算/配额,以及将部署与客户影响关联的可观测性。
选择一个面向客户的服务并端到端实现上面的清单,然后扩展到更多服务。
如果你正在构建新服务并想更快达到“可部署”的状态,Koder.ai 可以帮你通过聊天驱动的规范生成完整的 Web/后端/移动应用——通常是前端 React、后端 Go + PostgreSQL、移动端 Flutter——然后导出源码,以便你应用本文讨论的相同 Kubernetes 模式(声明式配置、可重复的发布与友好的回滚操作)。对于评估成本与治理的团队,你也可以查看 /pricing。
Orchestration 将你的意图(应该运行什么)与现实世界的频繁变化(节点故障、滚动部署、扩缩容事件)协调起来。与其管理单个服务器,不如管理工作负载,并让平台自动放置、重启和替换它们。
在实践中,它减少了:
声明式配置指出你想要的最终结果(例如:“这个镜像的 3 个副本,暴露到这个端口”),而不是一步步的操作流程。
你可以立即获得的好处包括:
控制器是持续运行的控制循环,会比较当前状态与期望状态并采取行动以缩小差距。
这就是为什么 Kubernetes 能“自我管理”常见结果的原因:
调度器根据约束和可用容量决定每个 Pod 应该运行在哪里。如果不加引导,可能出现“嘈杂邻居”、热点或副本集中在同一节点等问题。
常见的用于表达运维意图的规则有:
Requests 告诉调度器 Pod 需要 的资源;limits 限制 Pod 能使用 的资源。没有现实的 requests,放置就变成了猜测,稳定性往往会受影响。
一个实用的起点:
Deployment 的滚动更新会逐步替换旧 Pod,同时尽力保持可用性。
保持部署安全的做法:
Kubernetes 默认提供滚动更新,但很多团队会叠加更高级的模式:
根据风险承受度、流量形态以及检测回归的速度(错误率/延迟/SLO 消耗)来选择。
一个 Service 为不断变化的一组 Pods 提供稳定的前门。通过 labels/selectors 决定哪些 Pod 在服务后面,而 EndpointSlices 跟踪当前匹配该选择器的实际 Pod IP。
在运维上,这意味着:
service-name,而不是追逐 Pod IP自动扩缩容在每一层都有明确信号时效果最好:
常见问题:
CRD(Custom Resource Definition)让你定义新的 API 对象(例如 Database、Cache),从而用相同的 Kubernetes API 模型管理更高层次的系统。
Operator 将 CRD 与控制器结合起来,对期望状态与实际状态进行调和,常见自动化包括:
将它们视为生产软件:在依赖前评估成熟度、可观测性和故障模式。