2025年9月21日·2 分钟
为什么 C 与 C++ 仍驱动操作系统、数据库与游戏引擎
了解 C 与 C++ 如何通过内存控制、速度与低级访问继续构成操作系统、数据库与游戏引擎的核心。
为什么 C 和 C++ 在幕后仍然重要
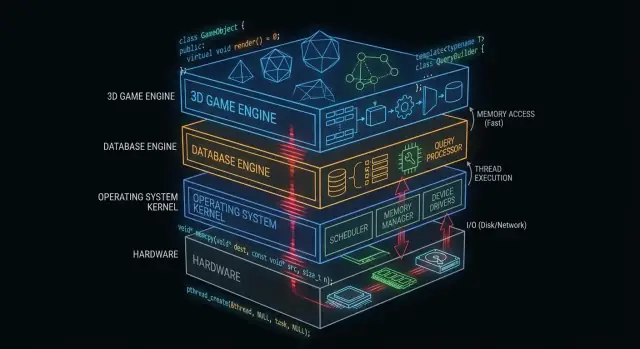
“引擎盖下”的部分是你的应用所依赖但很少直接接触的:操作系统内核、设备驱动、数据库存储引擎、网络栈、运行时和性能关键库。
相比之下,许多应用开发者日常看到的是表层:框架、API、托管运行时、包管理器和云服务。这些层被设计为安全且高产——即便它们有意隐藏了复杂性。
为什么有些层必须贴近硬件
某些软件组件的要求很难在没有直接控制的情况下满足:
- 可预测的性能和延迟(例如:调度 CPU 时间、处理中断、流式加载资源)
- 精确的内存控制(布局、对齐、缓存行为、避免暂停)
- 直接的硬件访问(寄存器、DMA、驱动、文件系统与块设备)
- 小巧、可移植的二进制,能在引导早期或受限环境中运行
C 和 C++ 在这些场景仍然常见,因为它们可以编译成本地代码、运行时开销极小,并且让工程师对内存和系统调用具有细粒度的控制。
C 和 C++ 今天最常见的领域
在高层次上,你会发现 C 和 C++ 驱动着:
- 操作系统内核与低级库
- 驱动程序与嵌入式固件
- 数据库引擎(查询执行、存储、索引)
- 游戏引擎与实时子系统(渲染、物理、音频)
- 编译器、工具链与语言运行时,其他语言依赖这些组件
本文将(和不会)涵盖的内容
本文关注机制层面:这些“幕后”组件做什么、为什么能从本地代码中受益,以及这种能力带来的权衡。
本文不会宣称 C/C++ 适合每个项目,也不会演变成语言之争。目标是务实地理解这些语言为何仍然物有所值——以及现代软件栈为何继续在它们之上构建。
什么使 C 和 C++ 适合系统软件
C 和 C++ 被广泛用于系统软件,因为它们可以实现“贴近金属”的程序:体积小、运行快、与操作系统和硬件紧密集成。
编译为本地代码(通俗说明)
当 C/C++ 代码被编译后,会变成 CPU 可以直接执行的机器指令。运行时不需要在程序运行时翻译指令。
这对于基础设施组件(内核、数据库引擎、游戏引擎)很重要——即便是微小的开销在负载下也会累积。
对核心基础设施的可预测性能
系统软件常常需要一致的时序,而不仅仅是平均性能。例如:
- 操作系统调度器必须在负载下快速响应。
- 数据库必须在大量查询并发时保持延迟稳定。
- 游戏引擎必须满足帧预算(例如 60 FPS 对应约 16 ms)。
C/C++ 提供对 CPU 使用、内存布局和数据结构的控制,帮助工程师实现可预测的性能。
直接的内存和指针访问
指针让你可以直接操作内存地址。这种能力听起来令人畏惧,但它解锁了许多高级语言抽象掉的功能:
- 针对特定工作负载优化的自定义分配器
- 紧凑的内存格式(在数据库和缓存中非常有用)
- 零拷贝 I/O 模式,避免反复复制数据
谨慎使用时,这种控制能带来显著的效率提升。
权衡:安全性、复杂性与开发时间
同样的自由也带来了风险。常见的权衡包括:
- 安全性: 错误可能导致崩溃、数据损坏或安全漏洞。
- 复杂性: 手动内存管理和未定义行为需要高度自律。
- 开发时间: 为了可靠性,测试、代码审查和工具链成了不可谈判的需求。
一种常见做法是把性能关键的核心用 C/C++ 实现,然后用更安全的语言围绕它实现产品功能和用户体验。
C/C++ 在操作系统内核中的角色
操作系统内核是最接近硬件的部分。当你的笔记本唤醒、浏览器打开或程序请求更多内存时,内核在协调这些请求并决定下一步操作。
内核实际做什么
在实际层面,内核处理几个核心任务:
- 调度: 决定哪个程序(或线程)获得 CPU 时间,以及持续多长时间。
- 内存管理: 为进程分配内存、保持隔离并安全回收内存。
- 设备管理: 通过驱动与硬件通信(磁盘、网络、键盘、GPU 等)。
- 安全边界: 强制权限,防止进程读取或破坏其他进程的数据。
因为这些职责位于系统的核心,内核代码既对性能敏感也对正确性敏感。
为什么严格控制更适合 C(有时也用 C++)
内核开发者需要对以下方面有精确控制:
- 内存布局: 固定大小结构、对齐和可预测的分配行为。
- CPU 指令与调用约定: 与中断、上下文切换和低级同步交互。
- 硬件寄存器: 读取/写入特定地址并处理特殊 CPU 模式。
C 仍是常见的“内核语言”,因为它与机器级概念映射良好,同时在可读性和跨架构可移植性之间取得平衡。许多内核也在最底层使用汇编来处理最硬件相关的部分,而由 C 来承担大部分工作。
C++ 也可以出现在内核中,但通常以受限风格使用(限制运行时特性、异常策略谨慎、严格的分配规则)。在能看到它的地方,C++ 多用于在不放弃控制的前提下改善抽象。
与内核相邻的代码通常也用 C/C++ 编写
即使内核本身较为审慎,许多周边组件仍采用 C/C++:
- 设备驱动(尤其是性能关键的)
- 标准库和运行时的一部分(如 libc 的部分、低级线程实现)
- 引导加载程序和早期启动代码
- 需要本地速度的系统服务(例如网络或存储辅助组件)
想了解驱动如何连接软件与硬件,可参见 /blog/device-drivers-and-hardware-access。
设备驱动与硬件访问
设备驱动在操作系统与物理硬件之间翻译通信——网卡、GPU、SSD 控制器、音频设备等。当你点击“播放”、复制文件或连接 Wi‑Fi 时,驱动往往是首先响应的代码。
由于驱动位于 I/O 的热路径上,它们对性能非常敏感。每个包或每次磁盘请求多出的几微秒在繁忙系统中会迅速累积。C 和 C++ 在这里仍然常见,因为它们能直接调用内核 API、精确控制内存布局并以最小开销运行。
中断、DMA 以及低级 API 的重要性
硬件不会“有礼貌地”按顺序等待。设备通过中断向 CPU 发出信号——表示某事发生了(数据包到达、传输完成)。驱动代码必须快速且正确地处理这些事件,常常在严格的时序和线程约束下工作。
为了获得高吞吐量,驱动还依赖 DMA(直接内存访问),设备可以不通过 CPU 复制每个字节而直接读/写系统内存。设置 DMA 通常涉及:
- 以正确的格式和对齐准备缓冲区
- 向设备提供物理地址或映射的描述符
- 在设备与 CPU 之间同步内存的所有权
这些任务需要低级接口:内存映射寄存器、位标志以及谨慎的读/写顺序。C/C++ 能实用地表达这种“贴近金属”的逻辑,同时在编译器与平台间保持可移植性。
稳定性是不可妥协的
不同于普通应用,驱动错误可能导致整个系统崩溃、数据损坏或产生安全漏洞。这一风险塑造了驱动代码的编写与审查方式。
团队通过严格的编码标准、防御性检查和分层审查来降低风险。常见做法包括限制不安全指针的使用、校验来自硬件/固件的输入,以及在 CI 中运行静态分析。
内存管理:力量与陷阱
规划架构
使用规划模式在生成代码前绘制组件、边界与权衡。
内存管理是 C 与 C++ 在操作系统、数据库与游戏引擎等领域仍占主导地位的最大原因之一,同时也是最容易引入微妙错误的地方。
“内存管理”是什么意思
在实践中,内存管理包括:
- 分配内存(获取一段用于存储数据的区域)
- 释放内存(使用结束后归还)
- 处理碎片化(剩余的空洞使未来分配变慢或更困难)
在 C 中这通常是显式的(malloc/free)。在 C++ 中可能是显式的(new/delete)或被更安全的模式封装。
为什么手动控制是优势
在性能关键组件中,手动控制可以是一种特性:
- 可以避免垃圾收集引起的不确定暂停。
- 可以选择在哪里以及如何分配内存(例如池化或 arena 分配器),提高一致性。
- 可以根据真实工作负载定制分配模式(许多小对象 vs 大的连续缓冲区)。
当数据库需要维持稳定延迟或游戏引擎需要满足帧时间预算时,这些都很重要。
常见失败模式(及其严重性)
相同的自由会产生经典问题:
- 内存泄漏: 忘记释放内存,导致使用量增长直至性能下降或进程崩溃。
- 缓冲区溢出: 写入超出数组边界,破坏数据或引发利用。
- 使用已释放内存(use-after-free): 在释放后仍使用指针,导致难以复现的崩溃。
这些 bug 常常十分隐蔽,因为程序在特定工作负载触发前可能“看起来正常”。
现代实践如何帮助降低风险
现代 C++ 在不放弃控制的同时降低风险:
- RAII(资源获取即初始化)将资源的生命周期绑定到作用域,自动完成清理。
- 智能指针(如
std::unique_ptr和std::shared_ptr)使拥有权显式化,防止许多泄漏。 - Sanitizers(AddressSanitizer、UndefinedBehaviorSanitizer)和静态分析能在早期(通常在 CI 中)捕捉问题。
合理使用这些工具,既能保持 C/C++ 的速度,又能减少内存错误进入生产环境的机会。
并发与多核性能
现代 CPU 单核速度并没有显著攀升——它们的核心数在增加。这把性能问题从“代码有多快”转为“代码能多好地并行运行而不互相干扰”。C 和 C++ 在这里受欢迎,因为它们允许对线程、同步和内存行为做低级控制,且开销极小。
线程、核心与调度
线程是程序用来做工作的单位;CPU 核心是这些工作实际运行的地方。操作系统调度器将可运行的线程映射到可用核心,并不断做出权衡。
调度的细节在性能关键代码中十分重要:在错误时刻暂停线程可能会阻塞流水线、造成队列积压或产生“停停走走”的行为。对于 CPU 绑定工作,让活跃线程数与核心数大致匹配通常能减少抖动。
锁定基础:互斥、原子与争用
- 互斥量(mutex) 易于理解,但大量共享会产生争用——等待时间代替了工作时间。
- 原子操作(atomics) 在小范围的共享状态更新上可能更快,但需要小心设计以避免细微的正确性缺陷。
实际目标不是“永不加锁”,而是:更少地加锁、更聪明地加锁——保持临界区小,避免全局锁,并减少共享可变状态。
延迟尖峰为何重要
数据库和游戏引擎不仅关心平均速度——它们关心最坏情况的暂停。锁队列、页面错误或阻塞的工作线程都能导致可察觉的卡顿或违反 SLA 的慢查询。
常见的 C/C++ 模式
许多高性能系统依赖于:
- 线程池,重用工作线程并保持调度可预测。
- 工作窃取队列,在核心间平衡负载。
- 无锁队列(仅用于部分热点路径),以减少阻塞——但正确性更难证明。
这些模式力求在压力下既保持稳定吞吐又保持一致延迟。
数据库引擎:C/C++ 提供速度的场所
数据库引擎不仅仅是“存储行”。它是在 CPU 与 I/O 间运行的紧密循环,每秒可能执行数百万次操作,小的低效会迅速放大。这就是许多引擎和核心组件仍主要用 C 或 C++ 编写的原因。
引擎的主要任务:解析、规划、执行
当你发送 SQL 时,引擎会:
- 解析(把文本转换成结构化表示)
- 规划(选择高效的查询执行方式)
- 执行(扫描、索引查找、连接、排序、聚合并返回行)
每个阶段都受益于对内存和 CPU 时间的精细控制。C/C++ 支持快速解析器、在规划期间减少分配,以及精简的执行热路径——通常配合为工作负载设计的自定义数据结构。
存储引擎:页、索引、缓冲
在 SQL 层之下,存储引擎处理枯燥但关键的细节:
- 页(pages): 数据按固定大小块读写,而不是逐行处理。
- 索引: B 树、LSM 树及相关结构需要高效更新。
- 缓冲: 缓冲池决定哪些数据留在内存、哪些被淘汰,以及如何批量读写。
C/C++ 很适合这些部分,因为它们依赖于可预测的内存布局和对 I/O 边界的直接控制。
亲缓存的数据结构(为何重要)
现代性能常常更多依赖 CPU 缓存而非纯粹的 CPU 速度。用 C/C++,开发者可以把经常使用的字段紧凑放在一起、把列存为连续数组、减少指针跳转——这些模式能让数据更贴近 CPU、减少停顿。
高级语言仍然出现的地方
即便在以 C/C++ 为主的数据库中,高级语言通常用于管理工具、备份、监控、迁移和编排。性能关键的核心仍然是本地代码;外围生态优先迭代速度和可用性。
数据库中的存储、缓存与 I/O
从聊天构建
通过与 Koder.ai 的简单对话构建 React、Go 或 Flutter 应用。
数据库之所以感觉即时,是因为它们努力避免磁盘访问。即便是快速的 SSD,从存储读取的速度也比内存慢几个数量级。用 C 或 C++ 编写的引擎可以控制等待的每一步——并且常常可以避免等待。
缓冲池与页面缓存的通俗比喻
把磁盘上的数据想象成仓库里的箱子。取箱子(磁盘读)需要时间,所以把最常用的物品放在桌上(内存)。
- 缓冲池: 数据库自己的“桌面”,存放最近使用的页面(表与索引的固定大小块)。
- 页面缓存: 操作系统的“桌面”,缓存最近读过的文件数据。
许多数据库管理自己的缓冲池以预测哪些数据应保持在热存中,从而避免与操作系统在内存使用上的竞争。
为什么磁盘很慢以及缓存如何隐藏它
存储不仅慢,而且不稳定。延迟峰值、排队与随机访问都会增加延时。缓存通过以下方式缓解:
- 大多数读取由内存直接响应
- 把写入合并为更少、更大的 I/O 操作
- 预取可能接下来需要的页面(例如索引扫描时)
需要底层控制的设计选择
C/C++ 使数据库引擎可以调优对高吞吐至关重要的细节:对齐读取、直接 I/O 与缓冲 I/O 的选择、自定义淘汰策略,以及精心构造的内存布局用于索引和日志缓冲区。这些选择可以减少拷贝、避免争用并保持 CPU 缓存供应有用数据。
压缩与校验有时受限于 CPU
缓存减少了 I/O,却增加了 CPU 工作。解压页面、计算校验和、加密日志与验证记录都可能成为瓶颈。由于 C 与 C++ 提供对内存访问模式和 SIMD 友好循环的控制,它们常被用来在每个核心上挤出更多性能。
游戏引擎:实时约束
游戏引擎在严格的实时期望下运行:玩家转动镜头、按下按键,世界必须立即响应。这以帧时间而非平均吞吐衡量。
帧预算:为何毫秒很关键
在 60 FPS 下,你大约有 16.7 ms 来生成一帧:仿真、动画、物理、音频混合、遮挡剔除、渲染提交,通常还要流式加载资源。若为 120 FPS,则预算降为 8.3 ms。超时会被玩家感知为卡顿、输入延迟或节奏不一致。
这就是为什么 C 语言 与 C++ 在引擎核心仍然常见:可预测的性能、低开销以及对内存和 CPU 使用的精细控制。
常用 C/C++ 编写的核心子系统
大多数引擎在关键环节使用本地代码:
- 渲染(场景遍历、绘制调用构建、GPU 资源管理)
- 物理(碰撞检测、约束、刚体)
- 动画(骨骼混合、IK、姿态评估)
- 音频(实时混音、空间化)
这些系统每帧都运行,因此小的低效会迅速放大。
紧密循环与数据布局
大量游戏性能来自紧密循环:遍历实体、更新变换、测试碰撞、顶点蒙皮。C/C++ 更容易将内存结构为缓存高效的形式(连续数组、更少分配、更少虚拟间接),数据布局有时与算法选择同等重要。
脚本的角色(何时适合,何时不适合)
许多工作室用脚本语言实现玩法逻辑——任务、UI 规则、触发器——因为迭代速度重要。引擎核心通常保持本地,脚本通过绑定调用 C/C++ 系统。常见模式是:脚本负责编排;C/C++ 执行昂贵部分。
编译器、工具链与互操作
获取更多构建额度
通过创建有关 Koder.ai 的内容或使用你的邀请链接邀请他人来赚取积分。
C 与 C++ 不只是“运行”——它们被构建为与特定 CPU 与操作系统匹配的本地二进制。这个构建管道是这些语言在操作系统、数据库与游戏引擎中仍占核心地位的一个重要原因。
构建过程中实际发生了什么
典型构建包含几个阶段:
- 编译器: 将 C/C++ 源码转为特定机器的目标文件(object files)。
- 链接器: 将目标文件与库拼接生成可执行文件或共享库。
- 二进制产物: 最终由操作系统直接加载的可执行文件(通常带有单独的调试符号)。
链接步骤常常暴露真实世界的问题:缺失符号、不匹配的库版本或不兼容的构建设置。
为什么工具链与平台支持很重要
“工具链”指完整集合:编译器、链接器、标准库和构建工具。对于系统软件,平台覆盖往往是决定性因素:
- 主机与移动平台 SDK 可能要求特定的编译器与链接器。
- 数据库与后端软件需要在不同 Linux 发行版和 CPU 类型上稳定构建。
- 操作系统与驱动工作可能需要交叉编译器、严格的编译标志与 ABI 纪律。
团队常选用 C/C++ 的部分原因是工具链成熟并覆盖广泛环境——从嵌入式设备到服务器均可用。
与其他语言的接口(FFI)
C 常被视为“通用适配器”。许多语言可以通过 FFI 调用 C 函数,因此团队通常把性能关键逻辑放在 C/C++ 库中,并向更高级语言暴露小型 API。这就是为什么 Python、Rust、Java 等语言常包装现有的 C/C++ 组件而不是重写它们。
调试与分析:团队关心的指标
C/C++ 团队通常测量:
- CPU 时间(热点函数、调用栈)
- 内存使用(分配、泄漏、碎片化)
- 延迟(游戏帧时间、数据库查询时间)
- I/O 行为(缓存未命中、磁盘读取、系统调用)
工作流是一致的:定位瓶颈、通过数据验证、然后优化最小且最有影响的部分。
今天选择 C/C++:实用决策指南
C 和 C++ 在以下场景仍是出色工具——当你构建的组件确实对几毫秒、几个字节或特定 CPU 指令敏感时。它们并非每个功能或团队的默认最佳选择。
何时选择 C/C++
当组件性能关键、需要严格的内存控制或必须紧密集成操作系统或硬件时,选用 C/C++:
- 延迟可见的热点路径(解析、压缩、渲染、查询执行)
- 必须可预测的低级模块(分配器、调度器、网络原语)
- 本地代码即为产品的跨平台库(SDK、引擎、嵌入式)
- 在编译器/工具链之间的可移植性是硬性要求的场景
何时优先选择其他语言
当优先项是安全性、迭代速度或大规模可维护性时,选择更高级语言:
通常在以下情况更适合用 Rust、Go、Java、C#、Python 或 TypeScript:
- 团队规模大且人员流动频繁(减少“脚枪”很重要)
- 功能频繁变化且正确性比极限性能更重要
- 需要强内存安全保证
- 开发者生产力与招聘池比原始速度更受限制
在实践中,大多数产品是混合的:性能关键路径用本地库实现,其他服务与 UI 用更高级语言实现。
给应用团队的实用说明(Koder.ai 的契合点)
如果你主要构建 Web、后端或移动功能,通常不需要亲自编写 C/C++ 就能受益于它——你是通过操作系统、数据库、运行时和依赖来消费它。像 Koder.ai 这样的平台顺应这种分工:你可以通过聊天驱动的工作流快速产出 React Web 应用、Go + PostgreSQL 后端或 Flutter 移动应用,同时在需要时集成本地组件(例如通过 FFI 调用现有的 C/C++ 库)。这让大部分产品表面保留在易迭代的代码中,同时不忽视本地代码作为正确工具时的作用。
实用检查清单(按组件)
在做出决定前问自己这些问题:
- 这是关键路径吗? 先度量;别猜。
- 失败模式是什么? 在 C/C++ 中内存破坏可能是灾难性的。
- 接口边界是什么? 能否把本地代码隔离在小 API 后面?
- 你有相关经验吗? 代码审查、测试与性能分析技能不可或缺。
- 部署目标是什么? 主机、嵌入式、内核与驱动常偏好 C/C++。
- 如何测试与分析? 从第一天起就规划工具链与 CI。
建议的后续阅读
- /blog/performance-profiling-basics
- /blog/memory-leaks-and-how-to-find-them
- /pricing