2025年8月18日·1 分钟
Chris Lattner 的 LLVM:现代工具链背后的静默引擎
了解 Chris Lattner 的 LLVM 如何成为多语言与工具背后的模块化编译平台——推动优化、更好的诊断与快速构建。
用通俗语言理解 LLVM
可以把 LLVM 想象成许多编译器和开发工具共享的“引擎室”。
当你用 C、Swift 或 Rust 等语言编写代码时,必须有人把这些代码翻译成 CPU 能执行的指令。传统编译器通常把这条流水线的每一部分都自己构建。LLVM 采用了不同的思路:它提供了一个高质量、可复用的核心,处理那些难且耗时的部分——优化、分析以及为多种处理器生成机器码。
许多语言共用的基础
LLVM 大多数时候并不是一个你“直接使用”的单一编译器,而是编译器基础设施:语言团队可以把它当作搭建工具链的积木。一个团队可以专注于语法、语义和面向开发者的特性,然后把繁重的工作交给 LLVM。
这种共享基础是现代语言能够快速发布安全、成熟工具链而无需重复几十年编译器工作的重要原因。
即便你不是编译器专家也很重要的理由
LLVM 在日常开发体验中随处可见:
- 速度:它可以把高级代码编译成跨平台的高效机器码。
- 更好的错误与调试信息:围绕 LLVM 的生态使得更丰富的诊断和更好的工具成为可能。
- 不仅仅是“编译”:静态分析、sanitizer、代码覆盖等开发辅助工具常常建立在相同的底层表示与库之上。
本文要做的(和不做的)
这是对 Chris Lattner 启动的思想的导览:LLVM 的结构、为什么中间层重要、以及它如何支持优化与多平台。它不是教科书——我们会把重心放在直觉与真实影响,而不是形式化理论。
Chris Lattner 的最初愿景
Chris Lattner 是一位计算机科学家与工程师,早在 2000 年代初作为研究生时就因为一个实际的挫折开始了 LLVM:编译器技术强大,但重用困难。如果你想做一门新语言、更好的优化或支持新 CPU,通常要在一个紧耦合的“整体”编译器里反复改动——每次修改都会带来副作用。
他想解决的问题
当时,许多编译器像一台单一的大机器:理解语言的部分、负责优化的部分与生成机器码的部分深度交织。这使得它们对原始目标很有效,但难以适配。
Lattner 的目标不是“为一门语言做编译器”,而是打造一个能为多门语言与多类工具提供动力的共享基础——让大家不用一次又一次重写相同的复杂模块。他的赌注是:如果可以把流水线的中间部分标准化,边缘创新就能更快。
为什么“模块化基础设施”是个新鲜主意
关键转变在于将编译视作一组可分离的构建块并划清边界。在模块化世界里:
- 语言团队可以专注于解析和面向开发者的特性,
- 优化团队可以做一次改进并广泛共享,
- 硬件支持可以在不重设计上游所有东西的情况下添加。
现在听起来很明显,但当时它挑战了许多生产编译器的发展路径。
开源、为他人而建
LLVM 在早期就以开源发布,这很重要,因为共享基础设施只有在多个群体能信任、检查并扩展它时才有意义。随着时间推移,大学、公司和独立贡献者通过增加目标、修复边缘情况、提升性能并围绕它构建新工具来塑造该项目。
社区方面不仅仅是善意——也是设计的一部分:让核心尽可能通用,它才值得共同维护。
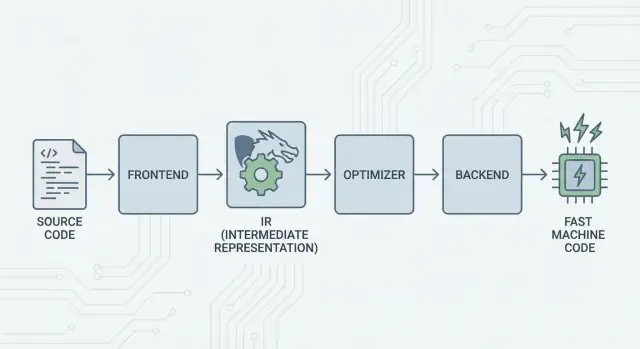
大思路:前端、共享核心与后端
LLVM 的核心思想很直接:把编译器拆成三大部分,让许多语言能共享最难的工作。
1) 前端:"程序员想表达什么?"
前端 负责理解某种具体编程语言。它读取源代码、检查规则(语法与类型),并将其转换成结构化表示。
关键点:前端不需要了解每个 CPU 的细节。它的工作是把语言概念——函数、循环、变量——翻译成更通用的东西。
2) 共享中间层:替代 N×M 的重复工作
传统上,构建编译器意味着不断重复相同的工作:
- 对于 N 门语言 和 M 种芯片目标,你会得到 N×M 个组合需要支持。
LLVM 把它简化为:
- N 个前端 把语言翻译为共享形式,
- M 个后端 把该共享形式翻译为机器码。
这个“共享形式”就是 LLVM 的中心:优化与分析运行在同一条流水线上。中间层的改进(比如更好的优化或更好的调试信息)可以同时惠及多种语言,而不是在每个编译器里重复实现。
3) 后端:"如何在某个 CPU 上高效运行?"
后端 把共享表示转换为机器特定的输出:x86、ARM 等指令集。在这里寄存器、调用约定和指令选择等细节很关键。
对流水线的直观比喻
把编译看作一段旅行路线:
- 源代码 起始于某个语言特有的国家(前端)。
- 它越过边界进入一个共享、标准化的“中间语言”(LLVM 的核心表示与 passes)。
- 然后搭当地的列车到达目的地城市(针对目标机器的后端)。
结果是一个模块化的工具链:语言可以专注于清晰地表达思想,而 LLVM 的共享核心专注于让这些思想在多平台上高效运行。
LLVM IR:实现复用的中间层
LLVM IR(中间表示)是位于编程语言与 CPU 机器码之间的“通用语言”。
编译器前端(例如 Clang 对 C/C++)把你的源代码翻译成这种共享形式。然后 LLVM 的优化器和代码生成器在 IR 上工作,而不是原始语言。最后,后端把 IR 转换成特定目标(x86、ARM 等)的指令。
工具与 CPU 之间的通用语言
把 LLVM IR 想象成一座精心设计的桥梁:
- 上层:许多源语言可以接入(C、C++、Rust、Swift、Julia 等)。
- 下层:许多 CPU 可以被定位。
- 中间:相同的分析与优化工具可以被重复使用。
这就是为什么人们常把 LLVM 描述为“编译器基础设施”而不是“一个编译器”。IR 是使这种基础设施可复用的共享契约。
为什么 IR 能实现复用(并节省大量工作)
一旦代码进入 LLVM IR,大部分优化 pass 不需要知道它最初是由 C++ 模板、Rust 迭代器还是 Swift 泛型产生的。它们主要关心一些普遍的概念,例如:
- “这个值是常量。”
- “这个计算被重复了;我们能否复用结果?”
- “这个内存加载可以安全地移动或移除。”
因此语言团队不必构建(和维护)自己的完整优化栈。他们可以把精力放在前端——解析、类型检查、语言特定规则——然后把繁重工作交给 LLVM。
概念上“看起来像什么”
LLVM IR 足够底层以便能映射到机器码,但仍然有结构以便分析。概念上它由简单指令(加法、比较、加载/存储)、显式控制流(分支)和强类型值构成——更像为编译器设计的整洁汇编语言,而不是人们通常手写的东西。
优化如何工作(不涉及复杂数学)
当人们听到“编译器优化”时,常会联想到神秘技巧。在 LLVM 中,大多数优化更像是安全的、机械的程序重写——保留程序语义的前提下让程序跑得更快(或更小)。
把它想成编辑而不是发明
LLVM 把你的代码(以 LLVM IR 表示)反复进行小幅改进,就像润色草稿一样:
- 消除重复工作:如果一个值被计算了两次且之间没有变化,LLVM 可以只计算一次并重用结果。
- 简化显而易见的逻辑:常量表达式可以提前折叠(例如把
3 * 4变成12),这样 CPU 在运行时要做的更少。 - 精简循环:循环优化可以减少重复检查,把不变的工作移出循环,或识别可更高效执行的模式。
这些变换是谨慎的。一个 pass 只有在能证明重写不会改变程序含义时才会执行。
可关联的例子
如果你的程序概念上做的是:
- 在循环的每次迭代中读取相同的配置值;
- 在多个地方对相同输入执行相同计算;
- 在某个上下文里检查总是为真/假的条件;
……LLVM 会尝试把它们变成“只做一次准备工作”、“重用结果”以及“删除无用分支”。这更像是家务清理而不是魔术。
真正的权衡:编译时间 vs 运行时间
优化不是免费的:更多分析与更多 passes 通常意味着更慢的编译,即便最终程序运行更快。这就是为何工具链提供类似“少量优化”与“激进优化”的层级。
Profile 可以帮助这里。通过 基于配置文件的优化(PGO),你先运行程序收集实际使用数据,再重新编译,让 LLVM 把精力集中在真正重要的路径上——使得这种权衡更可预期。
后端:无需重写一切即可覆盖多种 CPU
发布全栈应用
在一个流程中生成 React 前端和基于 Go + PostgreSQL 的后端。
编译器有两个非常不同的工作。首先,它要理解你的源代码;其次,它要生成某个特定 CPU 能执行的机器码。LLVM 的后端专注于第二项工作。
后端实际做什么
把 LLVM IR 想象成一份“通用配方”,说明程序该做什么。后端把该配方转成某个处理器家族(桌面/服务器常见的 x86-64、许多手机与新笔记本的 ARM64,或像 WebAssembly 这样的特殊目标)的具体指令。
具体来说,一个后端负责:
- 指令选择:把 IR 操作映射到真实的 CPU 指令;
- 寄存器分配:选择哪些值放在快速的 CPU 寄存器里 vs 放到内存;
- 调度:按能让 CPU 更高效运行的顺序排列指令;
- 汇编/目标文件输出:输出链接器与操作系统能识别的代码。
共享基础设施为何让新增硬件支持更容易
没有共享核心,每门语言都要为它想支持的每种 CPU 重新实现这一切——这是巨大的工作量且需要持续维护。
LLVM 则相反:前端(例如 Clang)只需生成 LLVM IR,而后端负责每个目标的“最后一公里”。添加对新 CPU 的支持通常意味着写一个后端(或扩展已有后端),而不是重写现有的所有编译器。
向多平台发布的可移植性
对于必须在 Windows/macOS/Linux、x86 与 ARM,甚至浏览器中运行的项目来说,LLVM 的后端模型是实用优势。你可以保持一个代码库和基本统一的构建流水线,然后通过选择不同后端(或交叉编译)进行重定向。
这种可移植性是 LLVM 广泛出现的原因之一:它不仅关乎速度,也关乎避免重复的、平台特定的编译工作,从而加速团队进展。
Clang:许多开发者第一次接触 LLVM 的地方
Clang 是用于 C、C++ 和 Objective-C 的前端,插入到 LLVM。若把 LLVM 比作可做优化与生成机器码的共享引擎,Clang 则是读取源文件、理解语言规则并把你的代码转成 LLVM 能处理的形式的部分。
Clang 受到关注的原因
许多开发者并不是读编译器论文而认识 LLVM 的——他们第一次体验是在换用编译器后发现反馈明显改善。
Clang 的诊断以更可读、更具体著称。它常常指出触发问题的精确 token、显示相关行并解释预期内容,而不是含糊的错误信息。在日常工作中这很重要,因为“编译—修复—重复”的循环变得不那么令人沮丧。
Clang 还通过 libclang 与更广泛的 Clang 工具生态暴露出干净、文档良好的接口。这使编辑器、IDE 和其他开发工具能在不重写 C/C++ 解析器的情况下集成深度的语言理解。
在日常工作流中的体现
一旦工具能可靠地解析并分析你的代码,你会得到一些感觉不像纯文本编辑、而更像与结构化程序互动的特性:
- 精确的代码导航(“跳转到定义”、“查找引用”),即使在大型、宏大量的 C++ 项目里也可用;
- 理解符号与作用域的重构支持,而不仅仅是搜索替换;
- 由真实语法与类型信息驱动的内联提示与快速修复。
这就是为什么 Clang 常常是开发者接触 LLVM 的第一站:它把切实的开发体验改进带到了手边。即便你从未想过 LLVM IR 或后端,你仍因编辑器自动补全更智能、静态检查更精确、构建错误更易定位而受益。
为什么许多现代语言基于 LLVM
LLVM 对语言团队有吸引力的简单理由是:它让他们能专注于语言本身,而不用花几年时间重造一个完整的优化编译器。
更快的上市时间
构建一门新语言本身已包含解析、类型检查、诊断、包管理、文档与社区支持等任务。如果还要从头实现生产级优化器、代码生成器与平台支持,发布常常被推迟——有时是几年。
LLVM 提供了现成的编译核心:寄存器分配、指令选择、成熟的优化 passes 以及对常见 CPU 的目标支持。团队可以把前端接入并把语言降低为 LLVM IR,然后依赖现有流水线为 macOS、Linux、Windows 生成本地代码。
高性能(不用“靠英雄式优化”)
LLVM 的优化器与后端是长期工程与不断真实世界测试的结果。这意味着采用它的语言能获得较强的基础性能——通常足以在早期使用,且随着 LLVM 的改进而继续提升。
这也是为何若干知名语言选择基于它:
- Swift 使用 LLVM 在 Apple 平台上生成高度优化的本地二进制。
- Rust 依赖 LLVM 做代码生成并支持多种架构。
- Julia 利用 LLVM 实现快速数值代码,包括针对特定工作负载的运行时编译。
并非每门语言都需要 LLVM
选择 LLVM 是一种权衡,不是必须。有些语言更看重极小的二进制、超快编译或对整个工具链的严格控制。另一些已经有成熟的编译器(比如基于 GCC 的生态)或偏好更简单的后端。
LLVM 受欢迎因为它是一个强有力的默认选项——但并不是唯一可行的路径。
JIT 与运行时编译:快速反馈回路
从构建到上线
无需手动拼凑构建步骤,就可发布托管版本。
“即时编译”(JIT)最容易理解为边运行边编译。不是把所有代码提前编译成最终可执行文件,而是在某段代码真正需要时再编译该部分——常常利用运行时信息(如确切类型或数据大小)做出更好的选择。
为什么 JIT 会感觉更快
因为不需要先把所有东西都编译完,JIT 系统可以在交互式工作中提供快速反馈。你编写或生成一小段代码就能立即运行,系统只编译当前必要的部分。如果同一段代码被频繁执行,JIT 可以缓存已编译结果或对“热点”段进行更激进的重编译。
运行时代码生成在哪些场景有用
JIT 在动态或交互式负载下很有优势:
- REPL 与 notebook:即时评估代码片段,同时在计算密集循环中获得本地速度;
- 插件与扩展:应用在运行时加载用户代码并为宿主 CPU 编译;
- 动态负载:当输入高度变化时,运行时剖析可以指导哪些路径值得优化;
- 科学计算:针对特定矩阵大小、模型形状或硬件特性的生成内核可以按需编译。
LLVM 的角色(去神话化)
LLVM 并不会神奇地让每个程序都更快,它本身也不是完整的 JIT。它提供的是一个工具包:定义良好的 IR、大量优化 passes 以及面向多种 CPU 的代码生成。项目可以在这些构建块之上构建 JIT 引擎,自行在启动时间、峰值性能与复杂性之间做权衡。
性能、可预测性与现实世界的权衡
基于 LLVM 的工具链可以生成非常快的代码——但“快”并非单一且稳定的属性。它取决于编译器版本、目标 CPU、优化设置,甚至编译器所做的关于程序的假设。
为什么“相同源代码,不同结果”会发生
两个编译器读取相同的 C/C++(或 Rust、Swift 等)源代码仍可能生成显著不同的机器码。部分原因是故意的:每个编译器有自己的一组优化 passes、启发式和默认设置。即便在 LLVM 生态内,Clang 15 与 Clang 18 在内联决策、循环矢量化或指令调度上也可能不同。
另一个原因是未定义行为与未指定行为。如果你的程序意外依赖于语言标准不保证的行为(例如 C 中的带符号溢出),不同编译器或不同编译选项可能会以不同方式“优化”,从而改变结果。
确定性、调试构建与发布构建
人们常期待编译过程是确定性的:相同输入应有相同输出。实际上你会非常接近,但并非总是完全相同。构建路径、时间戳、链接顺序、基于配置文件的数据以及 LTO 选择都会影响最终产物。
更实用的区分是调试构建 vs 发布构建。调试构建通常禁用许多优化以保留逐步调试与可读的堆栈跟踪。发布构建则开启激进变换,可能会重新排序代码、内联函数并移除变量——这对性能有利,但调试难度上升。
实用建议:测量,而不是猜测
把性能当作一个测量问题:
- 在具有代表性的硬件与真实数据集上基准测试。
- 预热缓存并运行多次迭代。
- 用明确的标志比较构建(例如变更
-O2vs-O3、启/禁用 LTO,或用-march选择目标)。
小的编译选项改变可能对性能产生明显影响。最稳妥的工作流是:提出假设、测量并保持基准贴近用户实际运行场景。
超越编译的工具:分析、调试与安全
先规划再编码
先梳理功能和任务,然后让 Koder.ai 生成所需的脚手架。
LLVM 常被描述为编译器工具包,但许多开发者更多是在编译以外的工具中感受到它的影响:分析器、调试器与在构建与测试中可启用的安全检查。
把分析与插装作为“附加项”
因为 LLVM 暴露了定义良好的中间表示(IR)与 pass 管道,构建用于非性能目的的额外步骤变得自然而然。一个 pass 可能插入计数器以做剖析、标记可疑内存操作或收集覆盖率数据。
关键点是这些特性可以被集成,而不是让每个语言团队都重写相同的底层管道。
Sanitizer:在源码附近捕捉错误
Clang 与 LLVM 推广了一系列运行时“sanitizer”,在测试期间通过插装程序检测常见 bug——比如越界内存访问、use-after-free、数据竞争与未定义行为模式。它们不是万能的,通常会明显减慢程序,因此主要在 CI 与预发布测试中使用。但在触发时,常能指向精确的源码位置并给出可读的解释,这正是团队追查间歇性崩溃时需要的。
更好的诊断 = 更快的入门
良好的工具质量也体现在沟通上。清晰的警告、可操作的错误信息与一致的调试信息能减少新手的“神秘感”。当工具链能解释发生了什么以及如何修复时,开发者花在记忆编译器怪癖上的时间就少了,更多时间用来学习代码库。
LLVM 本身并不保证完美的诊断或绝对安全,但它提供了一个共同基础,使这些面向开发者的工具变得实用、可维护并可在多个项目间共享。
何时使用 LLVM(何时不该用)
把 LLVM 看作“自己搭建编译器与工具链的工具包”。这种灵活性正是它为现代工具链提供动力的原因——但也意味着它并不适合每个项目。
何时 LLVM 非常适合
当你想重用成熟的编译器工程而不用重头造轮子时,LLVM 很有优势。
如果你在构建新编程语言,LLVM 能为你提供经验证的优化流水线、成熟的代码生成以及良好的调试支持路径。
如果你要发布跨平台应用,LLVM 的后端生态减少了支持不同架构所需的工作量。你可以专注于语言或产品逻辑,而不是为每个平台编写独立的代码生成器。
如果你的目标是开发者工具——linter、静态分析、代码导航、重构——LLVM(及其周边生态)是强有力的基础,因为编译器已经“理解”了代码结构与类型。
何时可能显得过重
如果你在极小的嵌入式系统上工作,且对构建体积、内存与编译时间有严格限制,LLVM 可能显得沉重。
它也可能不适合非常专用的流水线,例如你不需要通用优化,或者你的“语言”更像是一个固定的 DSL,可以直接映射到机器码。
一个简单的检查清单
问自己三个问题:
- 我们是否需要支持多平台/多 CPU?
- 我们是否从现有优化与调试信息中受益,而不是自己构建?
- 我们是否更看重生态(工具、集成、招聘)而非最小化的定制编译器?
如果大多数答案是“是”,LLVM 通常是实际可行的选择。如果你主要想要最小、最简单且只解决单一窄问题的编译器,更轻量的方案可能更优。
给产品团队的实用提示:在不成为编译器专家的情况下享用 LLVM 的好处
大多数团队并不想把“采纳 LLVM”当作一个大工程。他们关心的是结果:跨平台构建、快速二进制、良好的诊断和可靠的工具链。
这也是像 Koder.ai 这样的产品在这方面有趣的原因。如果你的工作流越来越被高层次自动化(计划、生成脚手架、在紧密循环中迭代)驱动,你仍然可以间接受益于底层的 LLVM:无论你是在构建 React 网页、带 PostgreSQL 的 Go 后端,还是 Flutter 移动客户端,现代编译器基础设施(LLVM/Clang 及其相关)都会在后台做那些不显眼但重要的优化、诊断与可移植性工作,而你可以把注意力放在更快交付产品上。