2025年12月19日·1 分钟
用于边界用例的 Claude Code 测试生成提示
学习一种 Claude Code 测试生成提示,能通过针对边界、不变量和故障模式而不是 happy-path 来产生高信号测试。
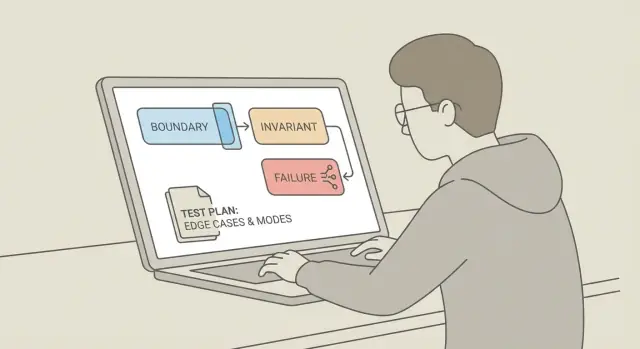
学习一种 Claude Code 测试生成提示,能通过针对边界、不变量和故障模式而不是 happy-path 来产生高信号测试。
自动生成的测试套件看起来常常很惊人:几十个测试、大量设置代码、每个函数名都出现过。但许多测试只是“在一切正常时能工作”的检查。它们容易通过,很少发现 bug,而且仍然增加阅读与维护成本。
使用典型的 Claude Code 测试生成提示时,模型倾向于反映它看到的示例输入。你会得到看似不同但覆盖相同行为的变体。结果是一个庞大的测试套件,但在关键处覆盖薄弱。
高信号测试不同。它们是能在上个月事故中发现问题的那小部分测试。它们会在行为以风险方式改变时失败,并在无害重构时保持稳定。一个高信号测试的价值可能抵得上二十个“返回期望值”式的检查。
低价值的 happy-path 生成通常有几个明显特征:
想象一个应用折扣码的函数。happy-path 测试确认 “SAVE10” 会降低价格。真正的 bug 隐藏在别处:0 或负价格、已过期的码、四舍五入边缘或最高折扣上限。这些才是导致错误总额、愤怒客户和午夜回滚的情况。
目标是从“更多测试”转向“更好的测试”,聚焦三类目标:边界、故障模式和不变量。
如果你想要高信号的单元测试,不要再要求“更多测试”,而是开始要求三类特定的测试。这就是能产生有用覆盖而不是一堆“正常输入可用”检查的 Claude Code 测试生成提示的核心。
边界是代码接受或产生的边缘。许多真实缺陷是 off-by-one、空状态或超时问题,在 happy path 下不会出现。
以最小值和最大值为思路(0、1、最大长度)、空 vs 有(""、[]、nil)、越界一位(n-1、n、n+1)和时间限制(接近截止)。
示例:如果一个 API 接受“最多 100 项”,请测试 100 和 101,而不仅仅是 3。
故障模式是系统可能崩溃的方式:错误输入、缺失依赖、部分结果或上游错误。好的故障模式测试会检查在压力下的行为,而不仅仅是理想条件下的输出。
示例:当数据库调用失败时,函数是否返回明确错误并避免写入部分数据?
不变量是在调用前后应始终为真的事实。它们把模糊的正确性变成明确的断言。
示例:
当你把注意力放在这三类目标时,你会得到更少的测试,但每个测试的信号更强。
如果你太早就请求生成测试,通常会得到一堆礼貌的“按预期工作”检查。一个简单的修正是先写一个小契约,然后基于该契约生成测试。这是把 Claude Code 测试生成提示变成能发现真实 bug 的最快方法。
一个有用的契约短到能一口气读完。目标是 5 到 10 行,回答三个问题:输入是什么、输出是什么、还有什么其他变化。
用简单语言写契约,不要用代码,并只包含你能够测试的内容。
一旦有了这些,扫描哪些地方现实会打破你的假设。那些就成为边界情况(最小/最大、零、溢出、空字符串、重复)和故障模式(超时、权限拒绝、唯一约束冲突、损坏输入)。
下面是针对类似 reserveInventory(itemId, qty) 功能的具体示例:
契约可能写明 qty 必须是正整数,函数应当原子执行,并且绝不能产生负库存。这会立刻提示高信号测试:qty = 0、qty = 1、qty 大于可用量、并发调用、以及在数据库中间故意出错的情形。
如果你使用像 Koder.ai 这样以对话驱动的工具,同样的工作流程适用:先在聊天中写契约,然后生成直接攻击边界、故障模式和“绝不发生”清单的测试。
当你想要更少但每个都很重要的测试时,使用这个 Claude Code 测试生成提示。关键步骤是先强制生成测试计划,然后在你批准计划后才生成测试代码。
You are helping me write HIGH-SIGNAL unit tests.
Context
- Language/framework: <fill in>
- Function/module under test: <name + short description>
- Inputs: <types, ranges, constraints>
- Outputs: <types + meaning>
- Side effects/external calls: <db, network, clock, randomness>
Contract (keep it small)
1) Preconditions: <what must be true>
2) Postconditions: <what must be true after>
3) Error behavior: <how failures are surfaced>
Task
PHASE 1 (plan only, no code):
A) Propose 6-10 tests max. Do not include “happy path” unless it protects an invariant.
B) For each test, state: intent, setup, input, expected result, and WHY it is high-signal.
C) Invariants: list 3-5 invariants and how each will be asserted.
D) Boundary matrix: propose a small matrix of boundary values (min/max/empty/null/off-by-one/too-long/invalid enum).
E) Failure modes: list negative tests that prove safe behavior (no crash, no partial write, clear error).
Stop after PHASE 1 and ask for approval.
PHASE 2 (after approval):
Generate the actual test code with clear names and minimal mocks.
一个实用技巧是要求以紧凑表格形式给出边界矩阵,这样明显的空缺一目了然:
| Dimension | Valid edge | Just outside | “Weird” value | Expected behavior |
|---|---|---|---|---|
| length | 0 | -1 | 10,000 | error vs clamp vs accept |
如果 Claude 提出 20 个测试,请反驳。要求它合并相似案例,只保留那些能发现真实 bug(越界一位、错误的错误类型、静默数据丢失、破坏不变量)的测试。
先用一个小且具体的契约描述你想要的行为。粘贴函数签名、对输入输出的简短描述,以及任何现有测试(即便只是 happy-path)。这可以让模型锚定在真实代码上,而不是它猜测的行为。
接着,在要求生成任何测试代码之前,先要求一个风险表。要求三个列:边界用例(输入的边缘)、故障模式(坏输入、缺失数据、超时)和不变量(必须始终为真的规则)。每行加一句“为什么这会导致失败”。一个简单表格比一堆测试文件更快地揭示空白。
然后选择最小的一组测试,使每个测试都有独特的抓 bug 目的。如果两个测试因同一原因失败,保留更强的那个。
一个实用的选择规则:
最后,为每个测试要求一段简短说明:如果该测试失败,会捕获到什么 bug。如果说明含糊(“验证行为”),该测试可能是低信号的。
不变量是无论输入为何都应保持真实的规则。用不变量驱动测试时,先把规则写成一句短句,然后把它变成一个能明显失败的断言。
挑 1–2 个实际能保护你的不变量。好的不变量通常关于安全(无数据丢失)、一致性(相同输入相同输出)或上限(不超过限制)。
把不变量写成短句,然后决定测试能观测到什么证据:返回值、持久化数据、发出的事件或对依赖的调用。强有力的断言同时检查结果和副作用,因为很多 bug 隐藏在“返回 OK 但写错了东西”里。
例如,对一个将优惠券应用于订单的函数:
现在把它们编码为具体断言:
expect(result.total).toBeGreaterThanOrEqual(0)
expect(db.getOrder(orderId).discountCents).toBe(originalDiscountCents)
避免模糊的断言如“返回期望结果”。断言具体规则(非负)和关键副作用(只记录一次折扣)。
对每个不变量,在测试中加一句简短注释说明什么数据会违背该不变量。这可以防止测试日后退化成 happy-path 检查。
一个简单且持久的模式:
高信号测试常常是确认代码能安全失败的那些测试。如果模型只写 happy-path 测试,你对功能在输入或依赖混乱时的行为几乎一无所知。
先决定对于该功能“安全”是什么意思。它是返回一个有类型的错误?回退到默认值?重试一次然后停止?把期望行为写成一句话,然后让测试证明它。
当你向 Claude Code 请求故障模式测试时,目标要严格:覆盖系统可能崩溃的方式,并断言你想要的确切响应。一句有用的话是:“偏好更少但断言更强的测试,而不是很多浅断言的测试。”
常见能产出最佳测试的故障类别:
示例:有一个创建用户并调用邮件服务发送欢迎邮件的端点。低价值的测试检查“返回 201”。高信号的故障测试检查当邮件服务超时时,你是 (a) 仍创建用户并返回 201 同时标记为“email_pending”,还是 (b) 返回明确的 503 并且不创建用户。选定一种行为,然后断言响应和副作用。
还要测试不会泄露什么信息。如果校验失败,确保没有写入数据库。如果依赖返回损坏负载,确保你不会抛出未处理异常或返回原始堆栈跟踪。
低价值的测试集通常发生在模型被奖励创造数量时。如果你的 Claude Code 测试生成提示要求“20 个单元测试”,你常会得到仅在字符串或数字上微小变化的重复测试,表面看起来覆盖很广但实际上没捕获新问题。
常见陷阱:
示例:假设有一个“创建用户”函数。十个 happy-path 测试可能只是改变邮箱字符串,仍然错过重要内容:拒绝重复邮箱、处理空密码并保证返回的用户 ID 唯一且稳定。
有助于审查的护栏:
想象一个功能:在结账时应用优惠券代码。
契约(小且可测试):给定以分为单位的购物车小计和可选优惠券,返回以分为单位的最终总额。规则:百分比优惠向下取整到最接近分,固定优惠减去固定金额,总额绝不低于 0。优惠券可能无效、过期或已被使用。
不要只问“为 applyCoupon() 写测试”。要针对该契约要求边界用例测试、故障模式测试和与该契约相关的不变量。
选择容易破坏数学或校验的输入:空的优惠码字符串、小计 = 0、刚好低于和高于最低消费、小计小于固定折扣、以及像 33% 这样的百分比导致四舍五入问题。
假设优惠券查找可能失败或状态可能错误:优惠券服务宕机、优惠券过期、或该用户已兑换该券。测试应证明接下来会发生什么(优惠被拒绝且返回明确错误、总额不变)。
一个最小但高信号的测试集合(5 个测试)以及每个测试能捕获的问题:
如果这些都通过,你就覆盖了常见的断点,而不必用重复的 happy-path 测试填满套件。
在接受模型生成结果前,做一次快速质量检查。目标是每个测试都在保护你免受具体且可能发生的 bug。
把这个检查表作为门槛:
生成后一个实用技巧:把测试重命名为“should <行为> when <边界条件>”或“should not <坏结果> when <故障>”。如果不能干净地重命名,它们通常不够聚焦。
如果你在 Koder.ai 上构建,这个清单也很适合与快照和回滚结合使用:生成测试、运行、如果新的集合带来噪音而没有提升覆盖,则回滚。
把你的提示当作可复用的工具,而不是一次性请求。保存一份蓝图提示(强制边界、故障模式和不变量的那个)并在每个新函数、端点或 UI 流中重复使用它。
一个能快速提升结果的简单习惯:要求每个测试写一句话说明它会捕获什么 bug。如果这句话很泛泛,该测试很可能是噪音。
保持一份产品域不变量的活文档。别把它存在脑子里。每当你发现真实 bug 时就把它加入。
一个轻量的重复流程:
如果你通过聊天构建应用,把这个循环在 Koder.ai (koder.ai) 内运行,这样契约、计划和生成的测试都保存在一个地方。当重构意外更改行为时,快照和回滚能让你更容易比较并迭代,直到你的高信号集合保持稳定。
默认:目标是少量但能发现真实缺陷的测试。
一个常用上限是每个单元(函数/模块)6–10 个测试。如果需要更多,通常意味着该单元职责过多或契约不清。
大量的 happy-path 测试主要证明示例仍然可行,往往错过生产中真正会出问题的情况。
高信号测试应该覆盖:
从一个能一口气读完的微型契约开始:
然后基于该契约生成测试,而不是仅靠示例。
先测试这些:
每个输入维度选 1–2 个边界,保证每个测试覆盖独特风险。
一个好的故障模式测试要证明两点:
如果涉及数据库写入,总是检查故障后的存储状态。
默认做法:把不变量转成对可观测结果的断言。
示例:
expect(total).toBeGreaterThanOrEqual(0)优先同时检查和,因为很多 bug 表现为“返回 OK 但写错了东西”。
当它保护一个不变量或关键集成时,happy-path 测试仍然有价值。
值得保留的理由:
否则,把它换成能捕获更多缺陷的边界/故障测试。
先强制模型走PHASE 1:只出计划。
要求模型提供:
只有在你批准计划后才生成代码,这样可以避免“20 个相似测试”的结果。
默认:仅模拟你不拥有的边界(DB/网络/时钟),其余保持真实。
避免过度模拟:
如果一个测试在重构后失败但行为没变,通常是过度模拟或过于耦合实现导致的。
用一个简单的删除法来判断:
还要检查重复性: