2025年12月28日·1 分钟
Claude Code:用于性能调查的可测工作流
用 Claude Code 处理性能调查时遵循一个可重复的循环:测量、提出假设、只改一小件事,然后复测再发布。
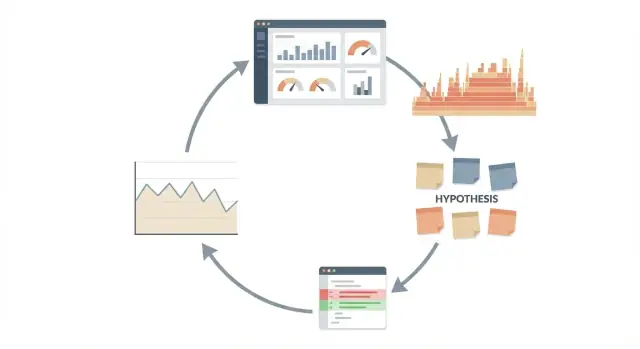
用 Claude Code 处理性能调查时遵循一个可重复的循环:测量、提出假设、只改一小件事,然后复测再发布。
性能问题很容易让人凭感觉行事。有人觉得页面变慢了或 API 超时,最直接的反应就是“清理”代码、加缓存,或重写一个循环。问题是“感觉慢”不是一个指标,“更整洁”也不等于更快。
没有测量,团队会白白浪费时间改错地方。瓶颈可能在数据库、网络,或某个意外的分配上,而团队却在打磨几乎不占时间的代码。更糟的是,看起来聪明的改动可能会让性能更差:在紧循环里增加额外日志、缓存增加内存压力,或并行工作导致锁争用。
凭感觉还可能破坏功能。当你改代码以求加速时,可能会改变结果、错误处理、顺序或重试行为。如果不同时复查正确性和速度,你可能“赢”了基准测试,却悄悄上线了一个 bug。
把性能当作实验,而不是辩论。循环很简单且可重复:
很多改进是温和的:把 p95 延迟降低 8%,把峰值内存减少 50 MB,或去掉一次数据库查询。这些改进仍然重要,但只有当它们被测量、验证并可重复时才有价值。
这最有效的方式是把它当成一个循环,而不是一次性“让它更快”的请求。循环让你保持诚实,因为每个动作都有证据和可监视的数字支撑。
清晰的步骤:
每一步都能防止不同类型的自我欺骗。先测量能阻止你去“修复”并非真实问题的东西。记录下来的假设阻止你一次改五件事然后猜哪一个有效。最小改动降低破坏行为或引入新瓶颈的风险。复测能识别安慰剂式的胜利(比如更快的一次运行是因为缓存已热)并暴露回归。
“完成”不是一种感觉。它是一个结果:目标指标朝正确方向移动,且改动没有引入明显回归(错误、更高内存、更糟的 p95,或附近端点变慢)。
知道什么时候停手也是工作流的一部分。当收益趋于平缓、指标对用户已经足够好,或下一步需要大规模重构但回报很小,就该停手。性能工作总有机会成本;循环能帮助你把时间花在有回报的地方。
如果同时测五样,你就不知道哪项改进了。为本次调查选一个主要指标,把其他作为辅助信号。对许多面向用户的问题,这个指标是延迟;对批处理工作可能是吞吐、CPU 时间、内存使用,或每次运行的云成本。
要对场景具体:"API 很慢" 太模糊。"POST /checkout 在典型购物车 3 件商品下" 是可测的。保持输入稳定,这样数字才有意义。
在你动代码之前把基线和环境细节写下来:数据集大小、机器类型、构建模式、特性开关、并发和预热步骤。这个基线是你的锚,没有它,每次改动看起来都像是进步。
对于延迟,依赖百分位而非仅看平均值。p50 显示典型体验,而 p95 和 p99 暴露用户抱怨的痛点。一个改善 p50 但恶化 p99 的改动可能仍然让人感觉更慢。
事先决定什么算“有意义”,避免把噪声当胜利:
一旦规则设定,你可以在不动目标的前提下测试想法。
从你能信任的最简单信号开始。对一次请求的单次计时能告诉你是否有真实问题,以及大致程度。只有在需要解释为何慢时才做更深的剖析。
好的证据通常来自多种来源的混合:
当问题是“是不是更慢了,慢了多少?”时用简单指标;当问题是“时间都花在哪儿?”时用剖析器。如果某次部署后 p95 延迟翻倍,先用计时和日志确认回归并限定范围。如果计时显示大部分延迟在应用代码内部(而不是数据库),CPU 剖析器或火焰图能指向具体增长的函数。
保证测量安全。只收集调试性能所需的数据,不收集用户内容。优先聚合数据(时长、计数、大小),默认对标识符脱敏。
噪声是真实存在的,因此多次取样并记录异常值。重复同一请求 10 到 30 次,记录中位数和 p95,而不是只看一次最好结果。
把精确的测试配方写下来,以便在改动后重复:环境、数据集、端点、请求体大小、并发水平,以及如何采集结果。
从可以命名的症状开始:"p95 在流量高峰时从 220 ms 跳到 900 ms"、"CPU 在两个核上持续 95%"、或"内存每小时增长 200 MB"。像“感觉慢”这样的模糊症状会导致随机改动。
接着把你测到的东西翻译成嫌疑区域。火焰图可能显示大部分时间在 JSON 编码上,追踪可能显示某条慢调用路径,或数据库统计可能显示某个查询占据了总时间。挑出能解释大部分成本的最小区域:一个函数、一条 SQL 查询或一次外部调用。
一个好的假设一句话即可,必须可测试并带有预测。你是在请求帮助检验一个想法,而不是让工具神奇地把一切变快。
使用这个格式:
示例:"因为剖析显示 SerializeResponse 占用了 38% 的 CPU,每次请求分配新缓冲区导致 CPU 激增。如果我们重用缓冲区,p95 延迟应下降约 10–20%,在相同负载下 CPU 应下降约 15%。"
在动代码前列出替代解释以保持诚实。也许慢的是上游依赖、锁争用、缓存未命中率变化,或某次发布增加了有效载荷大小。
写下 2 到 3 个备选解释,然后选你证据最支持的那个。如果你的改动没有移动指标,你已经有下一个假设可以测试。
当你把 Claude 当作慎重的分析员而不是神谕时,它在性能工作中最有用。要求每个建议都与测得的数据相关,并保证每一步都能被证伪。
给它真实的输入,而不是模糊描述。粘贴小而集中的证据:一个剖析摘要、几行慢请求相关的日志、一份查询计划,以及具体的代码路径。包含“之前”的数字(p95 延迟、CPU 时间、DB 时间)以说明你的基线。
让它解释数据暗示了什么、不支持什么。然后强制它给出竞争性解释。一个值得使用的提示语末尾写上:"给我 2–3 个假设,并为每个说明什么会证伪它。" 这能防止只锁定第一个看起来合理的故事。
在改动任何东西之前,要求最小的能够验证领先假设的实验。保持它快速且可逆:在函数周围加一个定时器,启用一个剖析器标志,或对一条 SQL 用 EXPLAIN 运行一次。
如果你想要紧凑的输出结构,可以要求:
如果它不能命名具体的指标、位置和预期结果,你又回到猜测上了。
在你有证据和假设后,抵抗“把所有东西都清理一遍”的冲动。性能工作最容易被信任时,是当代码改动很小且易于撤销。
一次只改一件事。如果你在同一次提交中改了查询、加了缓存并重构了循环,你就不知道哪个改动起作用(或导致问题)。单变量改动让下一次测量有意义。
在改代码前把你预期的数字写下来。例如:"p95 应从 420 ms 降到低于 300 ms,DB 时间应减少约 100 ms。" 如果结果没有达到目标,你会很快知道假设薄弱或不完整。
保持改动可撤销:
“最小”不等于“无用”。它意味着聚焦:缓存一个昂贵函数的结果、移除紧循环中的一次重复分配,或停止对不必要请求的工作。
在怀疑瓶颈处加轻量计时,这样你可以看到哪里动了。一次在调用前后记录时间戳(日志或指标)就能确认你的改动是否击中了慢点,还是只是把时间迁移到别处。
改动后,重跑用于基线的完全相同场景:相同输入、环境和负载形状。如果测试依赖缓存或预热,要明确说明(例如:"第一次冷启动,接下来的 5 次为热启动")。否则你会把偶然的改进误判为有效。
使用相同的指标和相同的百分位比较结果。平均值会掩盖痛点,注意 p95 和 p99 延迟,以及吞吐和 CPU 时间。做足够的重复以观察数字是否稳定。
在庆祝之前,检查不会在单一头条数字中显现的回归:
然后基于证据而非希望来决策。如果改进是真实且没有引入回归,就保留改动。如果结果混合或噪声大,回滚并形成新假设,或进一步缩小改动范围。
如果你在像 Koder.ai 这样的平台注册开发,先做快照可以把回滚变成一步操作,这使得大胆测试变得更安全。
最后,把你学到的写下来:基线、改动、新数字和结论。这个简短记录能防止下一轮重复相同的死胡同。
性能工作通常走偏是因为你丢失了“我测了什么”和“我改了什么”之间的线索。保持证据链清晰,这样你可以自信地说出是什么让事情变好或变坏。
常犯的错误:
举个小例子:某端点看起来慢,于是你优化序列化器因为在剖析中热。你用更小的数据集重测,结果看起来变快了。但在生产中 p99 更差,因为数据库仍然是瓶颈且你的改动增加了有效载荷。
如果你用 Claude Code 提出修复方案,别放松约束。要求它给出 1 到 2 个与已有证据相匹配的最小改动,并在接受补丁前坚持要重测计划。
当测试模糊时,性能声明容易崩塌。在庆祝前,确保你能解释测了什么、如何测的以及改了什么。
先写下一个指标和带环境说明的基线结果(硬件、配置、数据、冷/热缓存、并发)。如果你不能明天复现该配置,你就没有真正的基线。
清单:
当数字看起来更好后,做快速回归检查。检查正确性(输出一致)、错误率和超时。关注副作用如更高内存、CPU 峰值、更慢启动或更高的数据库负载。一个使 p95 改善但内存翻倍的改动可能并非值得。
团队报告 GET /orders 在开发环境看起来正常,但在中等负载的暂存环境变慢。用户抱怨超时,但平均延迟看起来“还行”,这是经典陷阱。
首先设基线。在稳定负载测试(相同数据集、相同并发、相同时长)下记录:
接着收集证据。快速追踪显示该端点先跑主查询获取订单,然后逐个循环按订单拉取关联项。你也注意到 JSON 响应较大,但 DB 时间占主导。
把这些转成可测试的假设清单:
对最强证据要求一个最小改动:把显而易见的 N+1 调用改成一次按订单 ID 批量获取 items(或如果慢查询计划显示全表扫描,则加缺失的索引)。保持可回滚并提交聚焦的改动。
用相同负载测试复测。结果:
决策:发布该修复(明显胜利),然后开启第二轮针对剩余差距和 CPU 峰值的调查,因为数据库不再是主要瓶颈。
掌握性能调查最快的方式是把每次运行当作一个可重复的小实验。当过程一致时,结果更容易被信任、比较和分享。
一个简单的一页模板有帮助:
决定一个固定存放位置以免笔记丢失。比起完美工具,能被发现更重要:服务旁边的 repo 文件夹、团队文档或工单备注。关键是可被检索。某人应该能在几个月后找到“缓存改动后 p95 延迟飙升”的记录。
把安全实验变成习惯。使用快照和易回滚的机制,让你可以在不担心的情况下尝试想法。如果你用 Koder.ai 开发,Planning Mode 可以是概述测量计划、定义假设并在生成紧凑 diff 前保持改动范围的便捷场所。
设定节奏。不要等到事故发生后再做。针对新查询、新端点、更大有效载荷或依赖升级,在改动后加入小型性能检查。一次 10 分钟的基线检测可以省下一天的猜测。
从一个与抱怨对应的数字开始,通常是针对特定端点和输入的 p95 延迟。在相同条件下记录基线(数据大小、并发、冷/热缓存),然后只改一件事并重新测量。
如果你无法重现基线,那你还没进入测量阶段——你只是在猜测。
一个有用的基线包括:
在动代码之前把这些写下来,避免移动靶心。
百分位比比平均值更能反映用户体验。p50 是“典型”体验,但用户抱怨的是慢尾巴,即 p95/p99。
如果 p50 提升但 p99 变差,系统仍然会让人觉得更慢,尽管平均值看起来更好。
当你问“是不是变慢了,以及变慢了多少?”时,用简单的计时/日志。当你问“时间都花在哪里?”时,才用剖析器(profiling)。
实用流程:先用请求计时确认回归是真实、已定位的,然后在需要时才做剖析。
选一个主要指标,把其他作为护栏。常见组合是:
这样可以防止你“赢”了一个图表却悄悄造成超时、内存增长或更坏的尾延迟。
把证据和一个可预测的改动连成一句话:
如果你不能说出证据和预期的指标变化,假设就不可检验。
保持改动小且可撤销:
小的改动让下次测量有意义,并降低在追求速度时破坏行为的风险。
按之前的配方重跑相同测试(相同输入、环境、负载、缓存规则)。然后检查除了“变快”之外的回归:
如果结果噪声大,多取样或回滚并收紧实验。
给它具体的证据并强制其保持可检验:
如果输出不能包含具体指标和重测计划,你就又回到凭感觉优化了。
当收益在重复测量中趋于平缓时;当指标对用户和 SLO 来说已经“足够好”时;或当下一步需要大幅重构但带来的改善很小时,就停手。
性能工作有机会成本。这个循环(测量 → 假设 → 改动 → 复测)帮助你把时间花在数字证明有价值的地方。