2025年10月29日·2 分钟
一个 AI 生成的单一代码库,支持 Web、移动 与 API
了解如何通过单一的 AI 生成代码库,用共享逻辑、一致的数据模型和更安全的发布来驱动 Web 应用、移动应用和 API。
了解如何通过单一的 AI 生成代码库,用共享逻辑、一致的数据模型和更安全的发布来驱动 Web 应用、移动应用和 API。
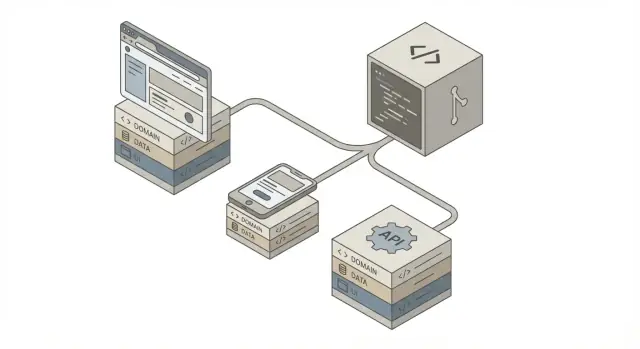
“一个代码库”很少意味着一个在任何地方都相同运行的 UI。在实践中,它通常指的是一个仓库和一套共享规则——由不同的交付面(Web 应用、移动应用、API)组成,但都依赖相同的业务决策。
一个有用的心智模型是共享那些绝不能出现分歧的部分:
与此同时,通常不会把 UI 层完全共享。Web 和移动有不同的导航模式、无障碍期望、性能约束和平台能力。在某些场景下共享 UI 是有利的,但这并不是“单一代码库”的定义。
AI 生成的代码可以显著加速:
但 AI 并不会自动产出连贯的架构。没有清晰边界时,它倾向于在应用间重复逻辑、混淆关注点(UI 直接调用数据库代码),并在多个地方创建“几乎相同”的验证。杠杆在于先定义结构——然后用 AI 填充重复部分。
一个 AI 辅助的单一代码库在能交付以下内容时才算成功:
单一代码库只有在明确它必须实现什么——以及不应试图统一什么时才有效。Web、移动和 API 服务不同的受众与使用模式,即便它们共享相同的业务规则。
大多数产品至少有三个“入口”:
目标是行为上的一致性(规则、权限、计算)——而非体验相同。
常见失败模式是把“单一代码库”当成“单一 UI”。这通常会产生一个像 Web 的移动应用或像移动的 Web 应用——两者都令人沮丧。
相反,应当追求:
离线模式: 移动端通常需要在无网络时读取(有时还要写入)。这意味着本地存储、同步策略、冲突处理以及明确的“事实来源”规则。\n 性能: Web 关注 bundle 大小与可交互时间;移动关注启动时间与网络效率;API 关注延迟与吞吐。共享代码不应意味着把不必要的模块发给每个客户端。\n 安全与合规: 认证、授权、审计轨迹、加密与数据保留必须在各面一致。如果你处于受监管的领域,从一开始就把日志、用户同意和最小权限访问等要求内置,而不是事后补丁式添加。
单一代码库在组织成明确层次并有严格职责划分时效果最佳。这种结构也让 AI 生成的代码更容易审查、测试和替换,而不会破坏不相关的部分。
下面是大多数团队最终趋向的基本形态:
Clients (Web / Mobile / Partners)
↓
API Layer
↓
Domain Layer
↓
Data Sources (DB / Cache / External APIs)
关键思想:用户界面和传输细节位于边缘,而业务规则保持在中心。
“可共享的核心”是所有在任何地方都应表现一致的部分:
当 AI 生成新功能时,最佳结果是:它只更新一次域规则,所有客户端自动受益。
某些代码强行放入共享抽象代价高且风险大:
实用规则:如果用户能“看到”它或操作系统能“打破”它,就把它保持为应用特有;如果是业务决策,就放在域层。
共享域层应该让人觉得“无聊”——最好的那种:可预测、可测试、处处可复用。如果 AI 在帮你构建系统,这一层就是你锚定项目意义的地方——因此 Web 屏幕、移动流程与 API 端点都能反映相同规则。
把产品的核心概念定义为实体(随时间有身份的事物,如 Account、Order、Subscription)和值对象(由值定义的事物,如 Money、EmailAddress、DateRange)。然后把行为捕捉为用例(有时称作应用服务):“创建订单”、“取消订阅”、“更改邮箱”。
这种结构让域对非专业人员更易理解:名词描述存在的东西,动词描述系统能做什么。
业务逻辑不应知道它是被按钮点击、网页表单提交还是 API 请求触发的。实际要做到:
当 AI 生成代码时,这种分离很容易丢失——模型会把 UI 关切塞进域代码。把这当作重构信号,而不是偏好问题。
验证是产品经常出现偏差的地方:Web 允许但 API 拒绝,或移动的验证不同。把一致的验证放到域层(或共享验证模块)以便所有端都强制相同规则。
示例:
EmailAddress 只在一处验证格式,Web/移动/API 复用\n- Money 阻止负总额,无论值从哪来\n- 用例强制跨字段规则(例如“结束日期必须晚于开始日期”)做好这些后,API 层就变成翻译器,Web/移动成为呈现者——而域层保持单一事实来源。
API 层是系统的“公共面孔”——在单一 AI 生成代码库中,它应该是锚定其他部分的那一层。如果合约清晰,Web、移动,甚至内部服务都可以从同一事实来源生成并校验。
在生成处理器或 UI 绑定之前先定义合约:
/users、/orders/{id}),可预测的过滤与排序。\n- 错误:稳定的错误形状(code、message、details),并记录 HTTP 状态码使用。\n- 分页:选定一种方式(游标分页通常更易演进)并标准化响应字段。\n- 版本控制:尽早决定(路径如 /v1/... 或基于 header)并记录弃用规则。把 OpenAPI(或像 GraphQL SDL 这样的模式优先工具)作为规范产物。从中生成:
这对 AI 生成代码很重要:模型可快速生成大量代码,但模式能让输出保持一致。
设定一些不可谈判的规则:
snake_case 或 camelCase,不要混用;JSON 与生成类型保持一致。\n- 状态码:成功用 200/201/204,验证错误用 400,认证用 401/403,冲突用 409。\n- 幂等性:对风险操作(支付、创建订单)要求 Idempotency-Key,并定义重试策略。把 API 合约当作产品来对待。当它稳定时,其他所有东西都更容易生成、测试和发布。
Web 应用从共享业务逻辑中获益良多,但当这些逻辑与 UI 关切纠缠时就会受苦。关键是把共享域层当作一个“无头”引擎:它知道规则、验证和工作流,但不了解组件、路由或浏览器 API。
如果你使用 SSR(服务端渲染),共享代码必须安全地在服务器上运行:不能直接使用 window、document 或浏览器存储。这是个很好的强制:把浏览器依赖行为放在薄薄的 Web 适配层中。\n
使用 CSR(客户端渲染) 时,你有更多自由,但相同的纪律依然有用。仅 CSR 的项目常会“意外”把 UI 代码导入到域模块,因为一切都在浏览器运行——直到后来加入 SSR、边缘渲染或在 Node 中运行的测试时问题才暴露。
实用规则:共享模块应确定性且与环境无关;任何触碰 cookies、localStorage 或 URL 的行为都属于 Web 层。
共享逻辑可以通过普通对象和纯函数暴露域状态(例如订单总额、资格、派生标志)。Web 应用应拥有UI 状态:加载指示、表单焦点、乐观动画、模态可见性。
这让 React/Vue 的状态管理保持灵活:你可更换库而无需重写业务规则。
Web 层应处理:\n\n- 无障碍(语义化标记、键盘导航、ARIA)\n- 路由(URL 结构、深度链接、服务端重定向)\n- 浏览器存储(cookies/session、localStorage、缓存)
把 Web 应用视为把用户交互翻译为域命令的适配器,并把域结果翻译为可访问的界面。
移动应用从共享域层获益最大:定价、资格、验证和工作流的规则应与 Web 与 API 行为一致。移动 UI 成为围绕共享逻辑的“外壳”——针对触控、间歇连接与设备特性进行优化。
即便有共享业务逻辑,移动也有难以 1:1 对应 Web 的模式:
如果预期真实的移动使用,假定会离线:
如果 Web、移动和 API 各自发明数据形状与安全规则,“单一代码库”会很快崩溃。解决方法是把模型、认证与授权视为共享的产品决策,然后只做一次编码。
选一个地方让模型“驻留”,其他一切从它派生。常见选项:
关键不是工具而是一致性。如果一个客户端的 OrderStatus 有五个值,另一个有六个,AI 生成的代码会高高兴兴地编译并仍然发布 bug。
认证对用户来说应有一致感受,但各面实现不同:
设计单一路径:登录 → 短期访问 → 需要时刷新 → 注销并使服务器端状态失效。在移动端把秘密存到安全存储(Keychain/Keystore),不要放在普通偏好中;在 Web 上尽量使用 httpOnly cookie,避免令牌暴露给 JS。
权限应集中定义——最好靠近业务规则——然后在各处应用:
canApproveInvoice(user, invoice))。\n- 在 API 层强制以保证安全。\n- 在 UI 层镜像用于隐藏/禁用动作,但不要依赖它来保护数据。这能防止“在移动上工作但在 Web 上不行”的漂移,并为 AI 代码生成提供清晰、可测试的谁可以做什么的契约。
只有在构建与发布可预测时,统一代码库才能保持统一。目标是让团队可以独立发布 API、Web 和移动应用——而不会为逻辑分叉或“针对环境做特殊处理”。
单仓库(monorepo) 往往更适合单一代码库,因为共享域逻辑、API 合约与 UI 客户端可以同步演进。你得到原子性变更(一个 PR 同时更新合约及其所有消费者)和更简单的重构。\n 多仓库 仍可实现统一,但会付出协调成本:为共享包做版本控制、发布工件和同步破坏性变更。仅当组织边界、安全规则或规模使单仓库不可行时才选多仓库。
把每个交付面当作独立构建目标,消费共享包:
保持构建产物显式且可重现(锁定依赖文件、固定工具链、确定性构建)。
典型流水线:lint → 类型检查 → 单元测试 → 契约测试 → 构建 → 安全扫描 → 部署。\n 把配置与代码分离:环境变量与秘密保存在 CI/CD 与密钥管理中,而不是仓库里。使用环境特定的覆盖层(dev/stage/prod),使得同一工件可在不重建的情况下在各环境间晋级——尤其适用于 API 与 Web 运行时。
当 Web、移动与 API 从同一代码库发布时,测试不再是“多做一项检查”,而是防止小改动破坏三端的机制。目标很简单:在修复成本最低处检测问题,并在到达用户前阻止高风险变更。
从共享域(业务逻辑)开始,因为它被最多复用且最容易在没有慢速基础设施的情况下测试。\n
这种结构把大部分信心放在共享逻辑上,同时还能捕捉层与层之间的“布线”问题。
即便在单仓库里,API 也容易在编译时变更但破坏用户体验。契约测试可以阻止无声漂移。\n
好测试很重要,但治理规则也很关键。\n
有了这些门禁,AI 辅助的变更可以频繁且不易脆弱。
AI 能加速单一代码库开发,但前提是把它当作速度很快的初级工程师:能生成草稿,但合并前必须审查。目标是用 AI 提高速度,同时由人把控架构、合约与长期一致性。
用 AI 生成那些你本来会机械性写出的“第一版”:
AI 输出应受显式规则约束,而不是凭直觉。把这些规则放在代码中:
如果 AI 建议的捷径违反边界,即便能编译也要否决。
风险不仅是糟糕的代码,还有未被追踪的决策。保持审计记录:
当团队能看到为什么生成某段代码、验证它并在需求演进时安全重生成,AI 的价值就会最大化。
如果在系统层面(Web + API + 移动)采用 AI 辅助开发,最重要的“特性”不是原始的生成速度,而是保持输出与合约和分层一致的能力。
例如,Koder.ai 是一个通过聊天界面帮助团队构建 Web、服务端和移动应用的 vibe-coding 平台——同时仍然产出真实、可导出源码。实际上,这对于本文所述的工作流很有用:你可以先定义 API 合约与域规则,然后在不丢失审查、测试和强制架构边界能力的情况下快速迭代 React Web 界面、Go + PostgreSQL 后端和 Flutter 移动应用。像计划模式、快照与回滚之类的特性也很适合“生成 → 验证 → 晋级”的发布纪律,在统一代码库中尤其有价值。
单一代码库能减少重复,但它并非默认的“最佳”选择。当共享代码开始强制妥协 UX、拖慢发布或掩盖平台差异时,你会把更多时间花在架构协商上,而非交付价值。
当以下情形存在时,分开代码库(或至少分开 UI 层)通常更划算:
在决定采用单一代码库前问自己:
如果你看到警告信号,实用的替代方案是 共享域 + API 合约,同时 分开 Web 与移动 应用。把共享代码聚焦在业务规则与验证,把每个客户端留给自己负责 UX 与平台集成。
如果你需要帮助选择路径,可在 /pricing 比较选项,或在 /blog 浏览相关架构模式。
它通常意味着 一个仓库和一套共享规则,而不是同一个完全相同的应用。
在实践中,Web、移动和 API 通常共享 域层(业务规则、验证、用例),并且往往共享一套 API 合约,而每个平台保留自己的 UI 和平台集成。
共享那些绝不能出现分歧的部分:
保留 UI 组件、导航和设备/浏览器集成为平台特有的实现。
AI 加速了脚手架和重复性工作(CRUD、客户端、测试),但不会自动创建良好的边界。
在没有刻意思路的情况下,AI 生成的代码常会:
应将 AI 用于填充已定义良好的分层,而不是由 AI 去发明分层本身。
一个简单且可靠的流程是:
这能使业务规则集中,便于测试和审查 AI 生成的补丁。
把验证放在一个地方(域层或共享验证模块),然后在所有端复用它。
实用模式:
EmailAddress、Money 这样的值对象只验证一次并复用这样可以避免“网页接受,但 API 拒绝”的差异化问题。
使用一个权威模式(如 OpenAPI 或 GraphQL SDL)并从中生成:
再加上契约测试,使模式变更在 CI 中被阻断,避免破坏性更改流入生产。
有意设计离线能力,而不是“靠缓存侥幸处理”:
把离线存储和同步留在移动应用层;把业务规则放在共享域代码中。
设计一个统一的概念流程,并根据平台做适配:
授权规则应集中定义(例如 canApproveInvoice),并在 API 端强制执行;UI 仅用于隐藏/禁用操作,不作为安全防护手段。
把每个交付面当作独立构建目标,消费共享包:
在 CI/CD 中执行:lint → 类型检查 → 单元测试 → 契约测试 → 构建 → 安全扫描 → 部署,并把密钥/配置放在 CI/密钥管理中,而不是仓库里。
把 AI 当作一个快速的初级工程师:擅长草拟,但不应直接合并。
良好约束包括:
如果 AI 输出违反架构规则,即便能编译也应被拒绝。