2025年5月05日·2 分钟
Datadog 与平台化转型:遥测、集成与工作流
当遥测、集成与工作流成为产品时,Datadog 如何演进为平台——以及你可以应用到技术栈中的实用想法。
当遥测、集成与工作流成为产品时,Datadog 如何演进为平台——以及你可以应用到技术栈中的实用想法。
一个可观测性工具帮助你回答关于系统的具体问题 —— 通常通过展示图表、日志或查询结果。它是你在出现问题时“使用”的东西。
一个可观测性平台更广泛:它标准化遥测的收集方式、团队如何探索数据,以及端到端如何处理事件。它成为组织每天“运行”的东西,跨越多个服务和团队。
大多数团队从仪表盘开始:CPU 图表、错误率图、也许几个日志搜索。这很有用,但真正的目标不是更漂亮的图表——而是更快的检测与更快的修复。
当你不再问“我们能把这个画成图吗?”而开始问:
这些都是以结果为导向的问题,需要的不只是可视化。它们需要共享的数据标准、一致的集成,以及把遥测连接到执行的工作流。
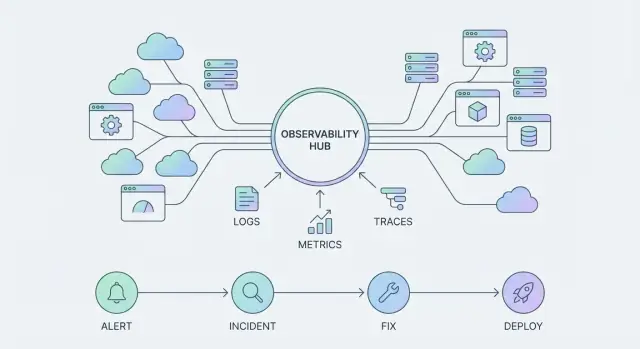
随着像 Datadog 这样的可观测性平台演进,“产品表面”不再只是仪表盘。它是三大互锁的支柱:
单个仪表盘可以帮助单个团队。平台随着每个服务的接入、每个集成的增加、每个工作流的标准化而变得更强。随着时间推移,这会复利成更少的盲点、更少重复的工具和更短的事故时间 —— 因为每次改进都可复用,而不是一次性。
当可观测性从“一个我们查询的工具”转变为“我们构建之上的平台”时,遥测不再是原始的废气,而开始作为产品表面发挥作用。你选择发送什么——以及发送得多么一致——决定了团队能看见、自动化和信任什么。
大多数团队以一小套信号为标准:
单个信号各有用途。合在一起,它们成为你系统的统一界面 —— 你在仪表盘、告警、事故时间线和事后分析中看到的东西。
一个常见失败模式是收集“所有东西”但命名不一致。如果一个服务使用 userId,另一个用 uid,第三个根本不记录,你就无法可靠地切分数据、关联信号或构建可复用的告警。
团队通过就几个约定达成一致(服务名、环境标签、请求 ID 和一套标准属性)能获得比翻倍摄入量更多的价值。
高基数字段是可能值很多的属性(比如 user_id、order_id、session_id)。它们在排查“只有某个客户受影响”的问题时很强大,但如果到处使用,会增加成本并让查询变慢。
平台化的方法是有意识地使用高基数:把它们保留在对调查有明确价值的地方,避免在用于全局聚合的地方使用。
回报是速度。当指标、日志、追踪、事件和剖析共享相同的上下文(service、version、region、request ID)时,工程师花在拼凑证据上的时间就少了,花在修复实际问题上的时间就多了。你不必在工具间跳转和猜测,而是沿着一条线索从症状追到根因。
多数团队开始可观测性时只是“把数据放进来”。这是必要的,但不是策略。遥测策略让接入保持快速并且使数据足够一致,从而驱动共享仪表盘、可靠的告警和有意义的 SLO。
Datadog 常见的遥测获取路径包括:
早期,速度会赢:团队安装 agent,打开几个集成,立刻看到价值。风险是每个团队都会发明自己的标签、服务名和日志格式——这会让跨服务视图变得混乱,告警变得难以信任。
一个简单规则:**允许“快速启动”接入,但要求“在 30 天内完成标准化”。**这既给团队动力,又不把混乱锁定下来。
你不需要庞大的分类法。先从每个信号必须携带的一小套字段开始:
service:简短、稳定、小写(例如 checkout-api)env:prod、staging、devteam:归属团队标识(例如 payments)version:部署版本或 git SHA如果想再加一个能快速带来回报的字段,可加 tier(frontend、backend、data)来简化过滤。
成本问题通常来自太慷慨的默认设置:
目标不是收集更少,而是一致地收集“正确”的数据,以便在没有意外的情况下扩展使用。
大多数人认为可观测性工具是“你安装的东西”。但实际上,它们在组织内部的传播方式更像优秀连接器的传播:一次一个集成。
集成不仅仅是数据通道。它通常有三部分:
最后一部分是将集成变成分发的关键。如果工具只“读入”,它就是一个仪表板目的地;如果它还能“写出”,它就成为日常工作的一部分。
优秀的集成减少了设置时间,因为它们带有合理的默认项:预构建的仪表盘、推荐的监控、解析规则和常见标签。你不必每个团队都重新发明“CPU 仪表盘”或“Postgres 告警”,而是有与最佳实践相符的标准起点。
团队仍然会自定义——但他们基于共享的基线进行自定义。当你在整合工具时,这种标准化很重要:集成都创建了可复制的模式,新服务可以复制,增长因此可控。
在评估选项时,问自己:它能否摄取信号并采取动作?例如在你的工单系统中打开事故、更新事故频道,或在 PR/部署视图中附上追踪链接。双向设置是工作流开始感觉“原生”的地方。
从小而可预测的开始:
经验法则:优先那些能立即改善事故响应的集成,而不是仅仅增加更多图表的集成。
标准视图是可观测性平台变得日常可用的地方。当团队共享同一心智模型——什么是“服务”、什么叫“健康”、首先点击哪里——排查速度更快,交接更清晰。
挑一小套“黄金信号”,并为每个信号做出具体、可复用的仪表盘。对大多数服务来说:
关键在于一致性:一个跨服务通用的仪表盘布局胜过十个巧妙但各不相同的自定义面板。
服务目录(即便是轻量级的)把“有人应该看这个”变为“某团队负责它”。当服务带有所有者、环境和依赖关系标签时,平台可以即时回答基本问题:哪些监控适用于该服务?我该打开哪些仪表盘?谁会被通知?
这种清晰度减少事故期间的 Slack 来回,并帮助新工程师自助排查。
把这些当作标准产物,而不是可选项:
虚荣仪表盘(漂亮但没有决策依据的图表)、一次性告警(匆忙创建从未调优)和无文档的查询(只有一个人懂得其中魔法过滤器)都会制造平台噪音。如果一个查询重要,就保存它、命名它,并把它挂到别人能找到的服务视图上。
当可观测性通过缩短问题与可信修复之间的时间为业务带来价值时,它才“真正”变得有用。这通过工作流实现——把你从信号带到行动、从行动带到学习的可复用路径。
可扩展的工作流不只是叫某人上页面。
一次告警应打开一个聚焦的评估循环:确认影响、识别受影响的服务,并拉取最相关的上下文(最近的部署、依赖健康、错误峰值、饱和信号)。从那里,沟通把技术事件变成协调的响应——谁负责该事故、用户看到了什么、下一次更新什么时候发布。
缓解环节希望把“安全操作”放在手边:功能开关、流量切换、回滚、限流或已知的变通办法。最后,学习以轻量复盘收尾,记录变更、有效措施以及下次应自动化的内容。
像 Datadog 这类平台在支持共享工作时增加价值:事故频道、状态更新、交接和一致的时间线。ChatOps 集成可以把告警变成结构化对话——创建事故、分配角色,并把关键图表和查询直接发到线程里,让每个人看到相同证据。
有用的 runbook 简短、意见明确且安全。它应包括:目标(恢复服务)、清晰的负责人/值班轮换、逐步检查、指向正确仪表盘/监控的链接,以及降低风险的“安全操作”(含回滚步骤)。如果它在凌晨三点不安全运行,那它还不够好。
当事故能自动与部署、配置变更与功能开关关联时,根因定位更快。把“发生了什么变更?”作为首要视图,让评估从证据而不是猜测开始。
一个**SLO(Service Level Objective)**是关于用户体验在一个时间窗口内的简单承诺——比如“30 天内 99.9% 的请求成功”或“p95 页面加载小于 2 秒”。
它优于“绿灯仪表盘”,因为仪表盘通常显示的是系统健康(CPU、内存、队列深度),而不是客户感受。一个服务在仪表盘上可能看起来绿油油,但用户仍在遭遇故障(例如,某个依赖超时或错误集中在某个区域)。SLO 强迫团队去衡量用户实际感知的情况。
错误预算是由你的 SLO 隐含的可接受不可用量。如果你承诺 30 天内 99.9% 的成功率,那在该窗口内你大约“被允许”有 43 分钟的错误时间。
这创造了一个实用的操作系统来做决策:
你们讨论的将不再是意见,而是大家都能看到的数字。
SLO 告警在你对燃尽率(错误预算被消耗的速度)告警时最有效,而不是对原始错误计数告警。这减少噪声:
许多团队使用两个窗口:一个快速燃尽(快速页面)和一个慢速燃尽(建工单/通知)。
从小处开始——2 至 4 个你会实际使用的 SLO:
一旦这些稳定,再扩展;否则你只会再建另一堵仪表盘墙。更多请见 /blog/slo-monitoring-basics。
告警是许多可观测性项目停滞的地方:数据在那里、仪表盘看起来不错,但值班体验变得嘈杂且不可信。如果人们学会忽略告警,你的平台就失去了保护业务的能力。
最常见的原因很一致:
在 Datadog 的语境下,重复信号常见于从不同“表面”(指标、日志、追踪)创建监控却未决定哪一个是规范页面来源。
要扩展告警,需有人类可理解的路由规则:
一个有用的默认是:对症状告警,而不是对每个指标变化告警。当用户能感受到时再页面(错误率、失败结账、持续延迟、SLO 燃尽),而不是对“输入”指标(CPU、Pod 数)告警,除非它们可靠地预测用户影响。
把告警清理作为运维的一部分:每月的监控修剪与调优。移除从未触发的监控,调整触发过于频繁的阈值,合并重复项,这样每个事故只有一个主要页面并有支撑上下文。
做得好时,告警成为人们信任的工作流,而非背景噪声生成器。
把可观测性称为“平台”不仅意味着把日志、指标、追踪和大量集成放在一个地方。它还意味着治理:当团队、服务、仪表盘和告警数量倍增时,使系统保持可用的一致性和护栏。
没有治理,Datadog(或任何可观测性平台)会变成噪杂的剪贴簿——数百个稍有差异的仪表盘、不一致的标签、不清晰的归属和没人信任的告警。
良好治理明确谁来决定什么,以及当平台变乱时谁负责:
一些轻量控制比冗长策略文档更有效:
service、env、team、tier)及可选标签的清晰规则。在 CI 中强制执行(如果可能)。扩展质量最快的方法是分享有效做法:
如果你想让治理生效,就让被治理的路径变成容易的路径——更少点击、更快设置、更清晰的归属。
一旦可观测性像平台一样运行,它会遵循平台经济学:采用的团队越多,产生的遥测越多,工具就越有用。
这形成一个飞轮:
问题是同样的循环也会推高成本。更多主机、容器、日志、追踪、合成监测和自定义指标可能比预算增长得快,如果不加以刻意管理。
你不需要“全部关掉”。先从塑形数据开始:
跟踪一小组指标以展示平台是否产生回报:
把它当成产品复盘而非审计。召集平台负责人、一些服务团队与财务,回顾:
目标是共享负责:成本成为更好打点决策的输入,而不是停止观测的理由。
如果可观测性正在变成平台,你的“工具栈”不再是一堆点解法,而开始成为共享基础设施。这个转变使工具泛滥不再只是恼人:它会产生重复的埋点、不一致的定义(什么算错误?),并因信号在日志、指标、追踪与事故间不对齐而增加值班负担。
整合并不等于“必须用一个厂商做所有事”。它意味着为遥测与响应确定更少的记录系统、更清晰的归属,以及更少的必须在宕机时查看的地方。
工具泛滥通常在三处隐藏成本:在不同 UI 间切换的时间、你必须维护的脆弱集成,以及分散的治理(命名、标签、保留、访问)。
更集中化的平台方法可以减少上下文切换、标准化服务视图并使事故工作流可重复。
在评估你的栈(包括 Datadog 或替代方案)时,施加压力测试这些问题:
选 一到两个有真实流量的服务。定义单一成功指标,例如“识别根因时间从 30 分钟降到 10 分钟”或“嘈杂告警减少 40%”。只埋点必需数据,两周后复盘结果。
把内部文档集中化以便学习复利——把试点 runbook、打标签规则和仪表盘链接放在一个地方(例如内部起点 /blog/observability-basics)。
你并不会一次性“上线 Datadog”。你从小处开始,及早设定标准,再扩展可行的方案。
第 0–30 天:接入(快速证明价值)
选择 1–2 个关键服务和一个面向客户的关键旅程。对日志、指标与追踪进行一致埋点,并连接已有的集成(云、Kubernetes、CI/CD、值班)。
第 31–60 天:标准化(让它可复用)
把学到的经验变成默认项:服务命名、打标签、仪表盘模板、监控命名与归属。创建“黄金信号”视图(延迟、流量、错误、饱和)和对最重要端点的最小 SLO 集。
第 61–90 天:扩展(有序扩大)
使用相同模板接入更多团队。引入治理(标签规则、必需元数据、新监控的审查流程),并开始跟踪成本与使用,以保持平台健康。
当你把可观测性当作平台时,通常会想要一些小型“胶水”应用:服务目录 UI、runbook 中心、事故时间线页面或把所有者 → 仪表盘 → SLO → 操作手册串联起来的内部门户。
这类轻量内部工具可以在 Koder.ai 上快速构建——一个通过聊天生成 Web 应用的 vibe-coding 平台(前端常用 React,后端 Go + PostgreSQL),支持源代码导出与部署/托管。团队通常用它快速原型并交付那些让治理与工作流更易行的操作界面,而无需把完整产品团队从 roadmap 上抽调出来。
举办两场 45 分钟的课程:
一个可观测性工具是在出现问题时咨询的东西(仪表盘、日志搜索、查询结果)。而可观测性平台是你持续运行的东西:它在团队间标准化遥测、集成、访问、归属、告警和事件工作流,从而改善结果(更快的检测与修复)。
因为最大的收益来自结果,而不是视觉:
图表有帮助,但要持续降低 MTTD/MTTR,需要共享标准和工作流。
先从每个信号都必须携带的基线开始:
serviceenv(prod、staging、dev)高基数字段(例如 user_id、order_id、session_id)意味着可能值很多,对于“只有某个客户受到影响”的排查很有用,但如果到处使用会提高成本并让查询变慢。
有意识地使用它们:
多数团队会标准化以下类型:
关键是让这些信号共享相同上下文(service/env/version/request ID),以便快速关联。
一个实用的默认是:
选择与控制需求匹配的路径,并在它们之间强制统一命名/打标签规则。
两者兼顾:
这样既保持采用速度,又避免每个团队都发明自己的模式。
因为集成不仅仅是数据通道——它们包含:
优先支持双向集成:既能摄取信号,也能触发/记录动作,这样可观测性才会成为日常工作的一部分,而不是仅仅一个终端 UI。
以一致性和可复用为中心:
避免浮于表面的仪表盘和一次性告警。一个重要查询应该保存、命名,并挂到可被他人找到的服务视图上。
基于燃尽速率(你消耗错误预算的速度)来告警,而不是每次瞬时波动。常见模式:
把 SLO 启动集保持小(每个服务 2–4 个),只有在团队真的使用后再扩展。详情见 /blog/slo-monitoring-basics。
teamversion(部署版本或 git SHA)如果想要一个额外且回报快的字段,可加 tier(frontend、backend、data)。